Thoughts on implementing corrigible robust alignment
post by Steven Byrnes (steve2152) · 2019-11-26T14:06:45.907Z · LW · GW · 2 commentsContents
Background / Context How would we write the code for corrigible robust alignment? End-to-end training using human-provided ground truth End-to-middle training using human-provided ground truth Hardcoded human template (= innate intuitive psychology) Interpretability Value lock-in Adversarial examples Conclusion None 2 comments
Background / Context
As context, here's an pictorial overview of (part of) AI alignment.
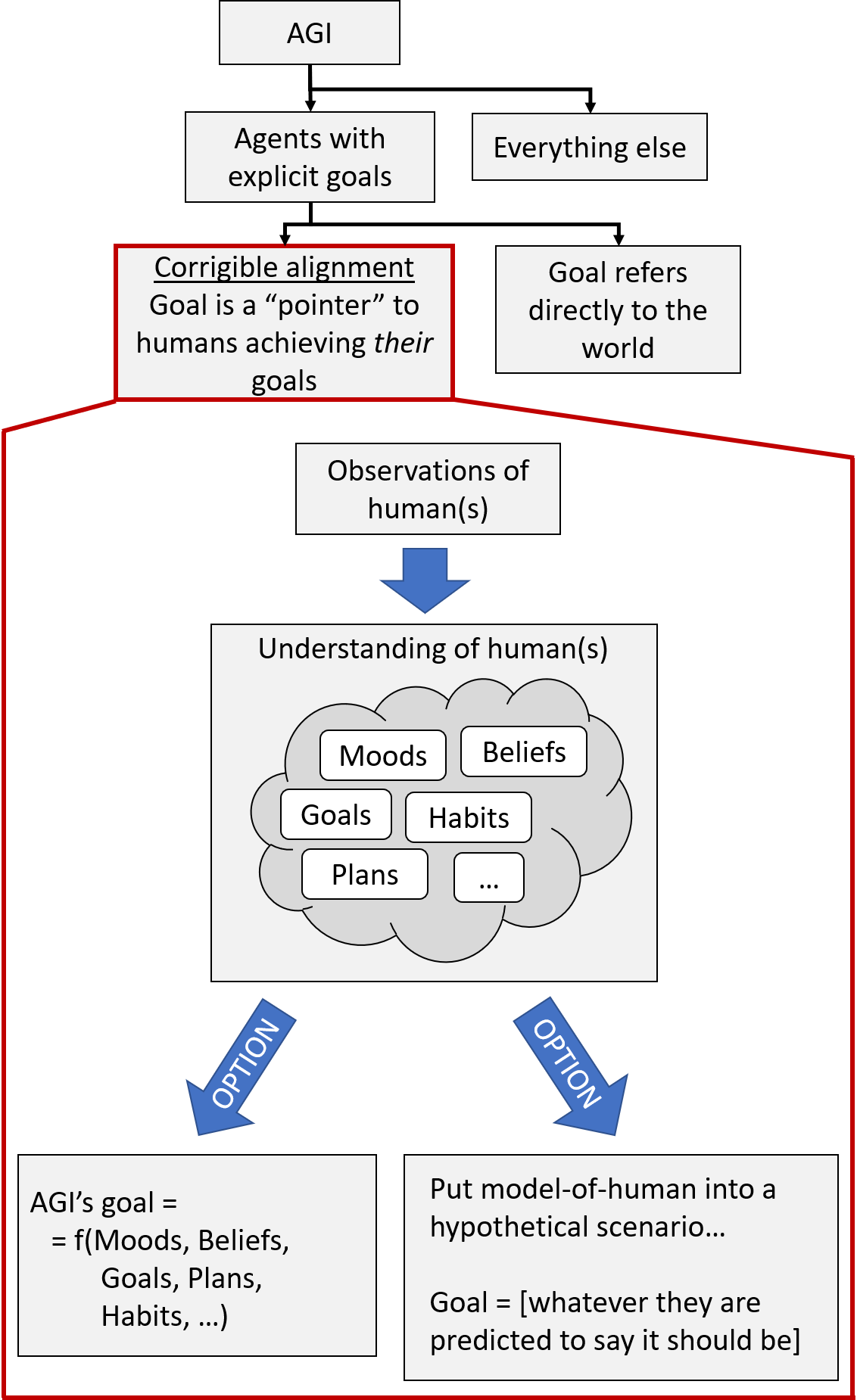
Starting from the top:
I split possible AGIs into those that do search/selection-type optimization [LW · GW] towards achieving an explicitly-represented goal, and "Everything else". The latter category is diverse, and includes (1) systems with habits and inclinations (that may lead to goal-seeking behavior) but no explicit goal (e.g. today's RL systems); (2) "microscope AI" [LW · GW] and other types of so-called "tool AI"; (3) IDA (probably?), and more. I'm all for exploring these directions [LW · GW], but not in this post; here I'm thinking about AGIs that have goals, know they have goals, and search for ways to achieve them. These are likely to be the most powerful class of AGIs, and were popularized in Bostrom's book Superintelligence.
Within this category, a promising type of goal is a "pointer" (in the programming sense) to human(s) achieving their goals, whatever they may be. If we can make a system with that property, then it seems that the default dangerous instrumental subgoals get replaced by nice instrumental subgoals like respecting off-switches, asking clarifying questions, and so on. In More variations on pseudo-alignment [LW · GW], Evan Hubinger refers to pointer-type goals as corrigible alignment in general, noting that it is only corrigible robust alignment if you're pointing at the right thing.
Out of proposed AGIs with explicit goals, most of the community's interest and ideas seem to be in the category of corrigible alignment, including CEV and CIRL. But I also included in my picture above a box for "Goals that refer directly to the world". For example, if you're a very confident moral realist who thinks that we ought to tile the universe with hedonium, then I guess you would probably want your superintelligent AGI to be programmed with that goal directly. There are also goals that are half-direct, half-corrigible, like "cure Alzheimer's while respecting human norms [LW · GW]", which has a direct goal but a corrigible-type constraint / regularization term.
Continuing with the image above, let's move on with the corrigible alignment case—now we're in the big red box. We want the AGI to be able to take observations of one or more humans (e.g. the AGI's supervisor), and turn it into an understanding of that human, presumably involving things like their mood, beliefs, goals, habits, and so on. This understanding has to be good enough to facilitate the next step, which can go one of two ways.
For the option shown on the bottom left, we define the AGI's goal as some function f on the components of the human model. The simplest f would be "f=the human achieves their goals", but this may be problematic in that people can have conflicting goals, sadistic goals, goals arising from false beliefs or foul moods, and so on. Thus there are more complex proposals, ranging from slightly complicated (e.g. measuring and balancing 3 signals for liking, wanting, and approving—see Acknowledging Human Preference Types to Support Value Learning [LW · GW]) to super-duper-complicated (Stuart Armstrong's Research Agenda [LW · GW]). Stuart Russell's vision of CIRL in his book Human Compatible seems very much in this category as well. (As of today, "What should the function f be?" is an open question in philosophy, and "How would we write the code for f?" is an open question in CS; more on the latter below.)
Or, for the option shown on the bottom right, the AGI uses its understanding of humans to try to figure out what a human would do in a hypothetical scenario. On the simpler side, it could be something like "If you told the human what you're doing, would they approve?" (see Approval-directed agents), and on the more complicated side, we have CEV. As above, "What should the scenario be?" is an open question in philosophy, and "How would we write the code?" is an open question in CS.
How would we write the code for corrigible robust alignment?
I don't have a good answer, but I wanted to collect my thoughts on different possible big-picture strategies, some of which can be combined.
End-to-end training using human-provided ground truth
This is the "obvious" approach that would occur to an ML programmer of 2019. We manually collect examples of observable human behavior, somehow calculate the function f ourselves (or somehow run through the hypothetical scenario ourselves), and offer a reward signal (for reinforcement learning) or labeled examples (for supervised learning) illustrating what f is. Then we hope that the AGI invents the goal-defining procedure that we wanted it to go through. With today's ML techniques, the system would not have the explicit goal that we want, but would hopefully behave as if it did (while possibly failing out of distribution). With future ML techniques, the system might wind up with an actual explicitly-represented goal, which would hopefully be the one we wanted, but this is the stereotypical scenario in which we are concerned about "inner alignment" (see Risks from Learned Optimization [? · GW]).
End-to-middle training using human-provided ground truth
Likewise, maybe we can provide an ML system with high-dimensional labels about people—"this person has grumpiness level 2, boredom level 6, hunger level 3, is thinking about football, hates broccoli...". Then we can do ML to get from sensory inputs to understanding of humans, which would be calculated as intermediate internal variables. Then we can hard-code the construction of the goal as a function of those intermediate variables (the bottom part of the diagram above, i.e. either the function f, or the hypothetical scenario). This still has some robustness / inner-alignment concerns, but maybe less so than the end-to-end case? I also have a harder time seeing how it would work in detail—what exactly are the labels? How do we combine them into the goal? I don't know. But this general approach seems worth consideration.
Hardcoded human template (= innate intuitive psychology)
This one is probably the most similar to how the human brain implements pro-social behaviors, although the human brain mechanism is a probably somewhat more complicated. (I previously wrote up my speculations at Human instincts, symbol grounding, and the blank-slate neocortex [LW · GW].) I think the brain houses a giant repository of, let's call them, "templates"—generative models which can be glued together into larger generative models. We have templates for everything from "how a football feels in my hand" to "the way that squirrels move". When we see something, we automatically try to model it by analogy, building off the templates we already have, e.g. "I saw something in the corner of my eye, it was kinda moving like a squirrel".
So that suggests an approach of pre-loading this template database with a hardcoded model of a human, complete with moods, beliefs, and so on. That template would serve as a bridge between the real world and the system's goals. On the "real world" side, the hope is that when the system sees humans, it will correctly pattern-match them to the built-in human template. On the "goals" side, the template provides a hook in the world-model that we can use to hard-code the construction of the goal (either the function f or the hypothetical scenario—this part is the same as the previous subsection on end-to-middle training). As above, I am very hazy on the details of how such a template would be coded, or how the goal would be constructed from there.
Assuming we figure out how to implement something like this, there are two obvious problems: false positives and false negatives to the template-matching process. In everyday terms, that would be anthropomorphizing and dehumanization respectively. False-positives (anthropomorphizing) are when we pattern-match the human template to something that is not a human (teddy bears, Mother Earth, etc.). These lead to alignment errors like trading off the welfare of humans against the welfare of teddy bears. False-negatives (dehumanization) correspond to modeling people without using our innate intuitive-psychology capability. These lead to the obvious alignment errors of ignoring the welfare of some or all humans.
Humans seem quite capable of committing both of these errors, and do actually display both of those corresponding antisocial behaviors. I guess that doesn't bode well for the template-matching strategy. Still, one shouldn't read too much into that. Maybe template-matching can work robustly if we're careful, or perhaps in conjunction with other techniques.
Interpretability
It seems to me that interpretability is not fundamentally all that different from template-matching; it's just that instead of having the system automatically recognize that a blob of world-model looks like a human model, here instead the programmer is looking at the different components of the world-model and seeing whether they look like a human model. I expect that interpretability is not really a viable solution on its own, because the world-model is going to be too complicated to search through without the help of automated tools. But it could be helpful to have a semi-automated process, e.g. we have template-matching as above, but it flags both hits and near-misses for the programmer to double-check.
Value lock-in
Here's an oversimplified example: humans have a dopamine-based reward system which can be activated by either (1) having a family or (2) wireheading (pressing a button that directly stimulates the relevant part of the brain; I assume this will be commercially available in the near future if it isn't already). People who have a family would be horrified at the thought of neglecting their family in favor of wireheading, and conversely people who are addicted to wireheading would be horrified at the thought of stopping wireheading in favor of having a family. OK, this isn't a perfect example, but hopefully you get the idea: since goal-directed agents use their current goals to make decisions, when there are multiple goals theoretically compatible with the training setup, the agents can lock themselves into the first one of them that they happen to come across.
This applies to any of the techniques above. With end-to-end training, we want to set things up such that the desired goal is the first interpretation of the reward signal that the system locks onto. With template-matching, we want the human template to get matched to actual humans first. Etc. Then we can hope that the system will resist further changes.
I'm not sure I would bet my life on this kind of strategy working, but it's definitely a relevant dynamic to keep in mind.
(I'm not saying anything original here; see Preference stability.)
Adversarial examples
Last but not least, if we want to make sure the system works well, it's great if we can feed it adversarial examples, to make sure that it is finding the correct goal in even the trickiest cases.
I'm not sure how we would systematically come up with lots of adversarial examples, or know when we were done. I'm also not sure how we would generate the corresponding input data, unless the AGI is being trained in a virtual universe, which actually is probably a good idea regardless. Note also that "deceptive alignment" (again see Risks from Learned Optimization [? · GW]) can be very difficult to discover by adversarial testing.
Conclusion
The conclusion is that I don't know how to implement corrigible robust alignment. ¯\_(ツ)_/¯
I doubt anything in this post is original, but maybe helpful for people getting up to speed and on the same page? Please comment on what I'm missing or confused about!
2 comments
Comments sorted by top scores.
comment by evhub · 2019-11-26T23:07:04.731Z · LW(p) · GW(p)
I really enjoyed this post; thanks for writing this! Some comments:
the AGI uses its understanding of humans to try to figure out what a human would do in a hypothetical scenario.
I think that supervised amplification can also sort of be thought as falling into this category, in that you often want your model to be internally modeling what an HCH would do in a hypothetical scenario. Of course, if you're training a model using supervised amplification, you might not actually get a model which is in fact just trying to guess what an HCH would do, but is instead doing something more strategic and/or deceptive, though in many cases the goal at least is to try and get something that's just trying to approximate HCH.
So that suggests an approach of pre-loading this template database with a hardcoded model of a human, complete with moods, beliefs, and so on.
This is actually quite similar to an approach that Nevan Witchers at Google is working on, which is to hardcode a differentiable model of the reward function as a component in your network when doing RL. The idea there being very similar, which is to prevent the model from learning a proxy by giving it direct access to the actual structure of the reward function rather than just learning based on rewards that were observed during training. The two major difficulties I see with this style of approach, however, are that 1) it requires you to have an explicit differentiable model of the reward function and 2) it still requires the model to learn the policy and value (that is, how much future discounted reward the model expects to get using its current policy starting from some state) functions which could still allow for the introduction of misaligned proxies.
comment by TurnTrout · 2020-05-12T17:08:12.105Z · LW(p) · GW(p)
I love this analogy:
Here's an oversimplified example: humans have a dopamine-based reward system which can be activated by either (1) having a family or (2) wireheading (pressing a button that directly stimulates the relevant part of the brain; I assume this will be commercially available in the near future if it isn't already). People who have a family would be horrified at the thought of neglecting their family in favor of wireheading, and conversely people who are addicted to wireheading would be horrified at the thought of stopping wireheading in favor of having a family. OK, this isn't a perfect example, but hopefully you get the idea: since goal-directed agents use their current goals to make decisions, when there are multiple goals theoretically compatible with the training setup, the agents can lock themselves into the first one of them that they happen to come across.