Supplement to "Big picture of phasic dopamine"
post by Steven Byrnes (steve2152) · 2021-06-08T13:08:00.832Z · LW · GW · 2 commentsContents
1. Differences between what I'm thinking and Randall O’Reilly et al.’s PVLV model 2. Differences between what I'm thinking and Steve Grossberg et al.’s MOTIVATOR model None 2 comments
This is "Supplementary Information" to my post "Big Picture of Phasic Dopamine" [LW · GW].
It's a deeper dive into more specific differences between what I’m currently thinking, vs Randall O’Reilly & colleagues' PVLV model, vs Steve Grossberg & colleagues' MOTIVATOR model.
Unlike the main post, I don't expect this to be of any interest to non-neuroscientists, and therefore I'm going to freely use neuroscience jargon.
1. Differences between what I'm thinking and Randall O’Reilly et al.’s PVLV model
Background: the PVLV (“Primary Value, Learned Value”) model started with this 2007 paper by Randall O’Reilly et al. They refined the model in this 2010 paper, and then the most recent version is Mollick et al. 2020, a 50-page tour de force that I’ve spent many many hours lovingly poring over while writing the main post. That paper influenced my thinking in too many ways to list—for example, that’s definitely where I first heard the idea that the amygdala has different “zones” for different USs, and that the ventromedial prefrontal cortex does too, with apparent one-to-one correspondence. (I think it should be “different zones for different URs” not “different zones for different USs”, but that’s a minor point.) And also …, well, just look at everywhere I cited it in my post.
So, great paper. But to make progress it’s worth spelling out the areas of disagreement.
I guess my first main disagreement is related to heterogeneous dopamine (different dopamine neurons are doing different things at the same time). Mollick discusses heterogeneous dopamine very helpfully and at length, but AFAICT it’s not part of her actual model. This creates various sorts of awkwardness, I think. First, their one reward signal needs to support learning in the amygdala, despite the fact that the amygdala is doing processing related to various reactions that have both “valences” (e.g. cringing is generally bad, relaxing is generally good). She solves this by putting different dopamine receptors onto the different reaction-learning circuits, i.e. hardcoding the idea that cringing is always something you do in response to bad things happening, relaxing is always something you do in response to good things happening, etc. But in many cases, the same UR to the same US can be good or bad depending on physiological context. My favorite example is the autonomic reaction “salivating-in-anticipation-of-salt”—see my post about that [AF · GW]. If you’re salt-deprived, this reaction is a sign of good things happening to you; if you’ve just eaten too much salt, this same reaction is a sign of bad things happening to you. (Update: Dr. Mollick tells me that in their model, physiological context information can flow along the route hypothalamus -> vmPFC -> ventral striatum. But I think my point stands that the learning algorithm would get messed up, unless I’m missing something. Check back later, I’ll update this page if I learn more.)
This exact same salt example illustrates my second disagreement: namely, Mollick generally suggests that dopamine should be a straightforward function of things happening in the telencephalon, with an (IMO) insufficiently central role of the hypothalamus and brainstem. Whereas I think the hypothalamus and brainstem should be a big black box sitting between the various telencephalon-originating signals and the resulting brainstem-originating dopamine (and acetylcholine and whatnot) signals. If the salivating-in-anticipation-of-salt reaction can be either a good or bad sign depending on physiological state, I don’t see how you can just wire that signal from amygdala to VTA, and expect it to work.
This idea is also, I think, neatly illustrated by a throwaway comment in the paper about the lateral habenula, a little non-telencephalon structure whose output signals lead to dopamine pauses. They said they found it weird that the amygdala doesn’t project to the lateral habenula, and suggested that the amygdala somehow talks to the lateral habenula via the ventral striatum. Whereas I find it perfectly sensible that the amygdala does not project to the lateral habenula, and suggest instead that the amygdala talks to the hypothalamus and brainstem, and those then go off and do some internal processing and then they go talk to the lateral habenula. (The hypothalamus-to-lateral-habenula connection is omitted from their diagram below, but I’m pretty sure it exists.) The direct connection from ventral striatum to lateral habenula is I think related to the fact that we need to do a subtraction: reward (from hypothalamus) minus reward prediction (from the reward-predicting loop in the ventral striatum), equals reward prediction error.
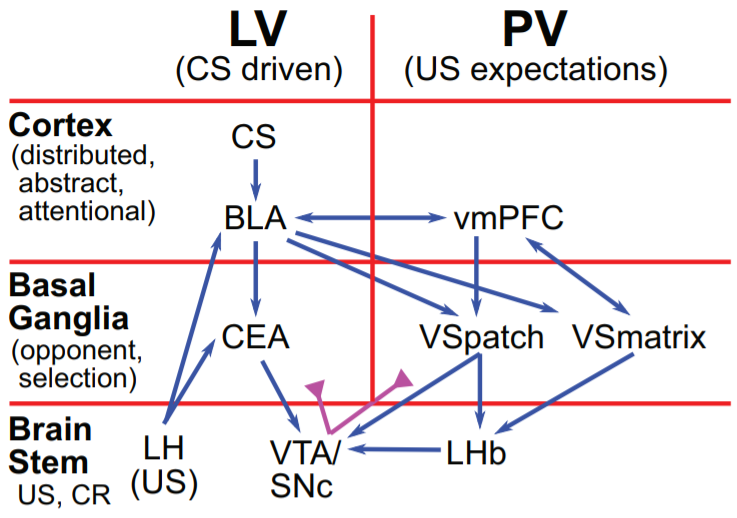
Here’s their overall diagram. Simple, right? This is actually their simplified version :-P Anyway, going through the figure:
- I talked about “agranular prefrontal cortex” whereas Mollick talks about “ventromedial prefrontal cortex”. Incidentally, lots of other authors seem to talk about “medial prefrontal cortex” in a way that feels similar to how Mollick talks about “ventromedial prefrontal cortex”, for reasons I don’t understand. I’m not sure how much of a disagreement this is; my hope is that my term is simply more specifically referring to the right thing, sorta based on Wise 2017. I’m not an expert here (if that wasn’t obvious). The granular prefrontal cortex is of course indirectly involved in producing these signals, just as many other brain regions are. I just think agranular prefrontal cortex is where the final signals are calculated and outputted.
- I didn’t talk about the distinction between patch-like and matrix-like ventral striatum, mainly just for reasons of scope. I didn’t think too hard about it and have no particular objections there.
- The BLA → vmPFC, VS connections: Mollick suggests that these are how the “different zones for different USs” (I would say URs) system gets set up in the PV system. Whereas I like the idea that the zones are set up by each being trained by a different dopamine signal. Then I would say the BLA → vmPFC, VS connections are just plain old “context” for supervised learning (see also ““Context” in the striatum value function” section)—it’s obviously very important context, but still in the usual category. I could be wrong.
- LH → BLA, CEA are also, I presume, context signals, presumably carrying status information like how jumpy you’re feeling, how angry, etc. Just as above, Mollick credits these signals with setting up “different zones for different USs”, but I disagree; I want different-dopamine-signals-to-different-zones to solve that problem instead. The signals are still quite sensible because LH has obviously useful context information to contribute to the supervised learning algorithm.
- vmPFC → BLA is also, I presume, a context signal.
- The CEA → VTA/SNc connection does exist, and does seem to run counter to my dogma that there’s a “hypothalamus & brainstem system”, and VTA/SNc is where that system outputs to the telencephalon, not where it inputs from the telencephalon. I guess it just doesn’t concern me that much. Yes, there are some cases, like that salt example, where we need a layer of innate circuitry between the amygdala suggestions and the dopamine outputs. But maybe there are other cases where there’s a straightforward rule, like “if the amygdala suggests X, just do it”, or “if the amygdala suggests Y, that’s always automatically a reason to increase a certain dopamine signal”. Then there’s no need to go through the hypothalamus; you might as well cut out the middleman and connect the signals directly, right?
2. Differences between what I'm thinking and Steve Grossberg et al.’s MOTIVATOR model
Do I need a ridiculous acronym too? Everyone seems to have a ridiculous acronym. Anyway, MOTIVATOR stands for “Matching Objects To Internal VAlues Triggers Option Revaluations”, and it comes from Steve Grossberg and colleagues.
I admit I’ve dived much less deeply into MOTIVATOR than PVLV. I skimmed Dranias, Grossberg, Bullock 2007 and got a bit out of it, and then I read Grossberg’s new book and got a bit more. I absolutely haven’t tried to follow all the details. So this might well be wrong, but I’ll try anyway.
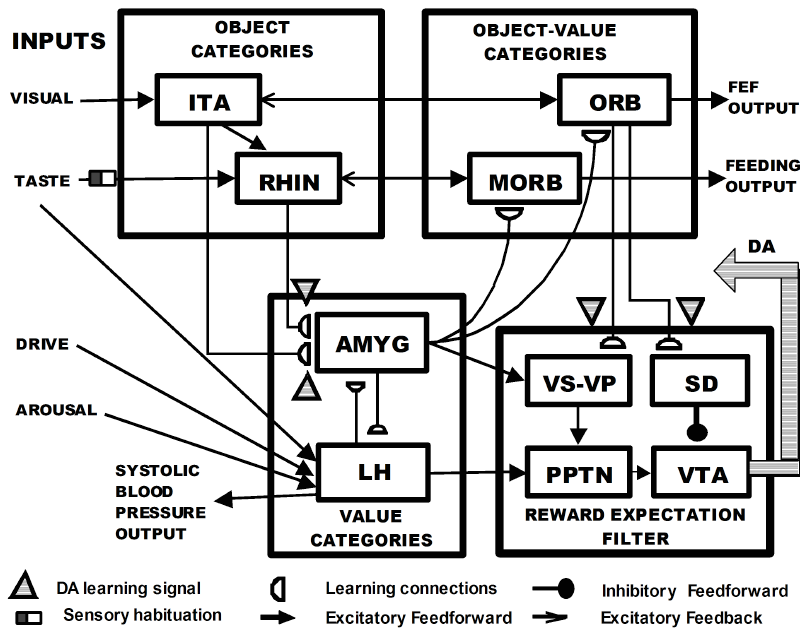
Dranias 2007 here has something either identical or awfully close to my suggested flow where the hypothalamus-brainstem system calculates rewards with the help of the amygdala (bottom-left box), and meanwhile the agranular prefrontal cortex and ventral striatum calculate a reward prediction (bottom-right box, plus ORB in the top-right), and then the reward prediction is the former minus the latter (depicted as the inhibitory connection inside the bottom-right box).
One of my complaints about Mollick—that it can’t account for a US being appetitive when you’re hungry and aversive when you’re full—does not seem to apply here; the hypothalamus seems to be positioned properly to solve that problem, or at least they discuss that and claim to demonstrate it in their models. But I have some disagreements about how it works.
(Update June 29: Rewrote the following few paragraphs after re-reading Grossberg's book discussion more carefully. I still might well be wrong and confused.)
Dranias basically wants the relationship between amygdala and hypothalamus to use the ART (Adaptive Resonance Theory—one of Steve Grossberg's big things) algorithm, exactly the same as the relationship between two hierarchical layers of neocortex. I think ART is a fine model (so far as it goes) for understanding the relationship between two hierarchical layers of neocortex, but I don't think it makes sense for the amygdala-hypothalamus relationship. At some risk of being wrong and mean-spirited, I'll just say that it strikes me as the thing where ART is a hammer, and then everything looks like a nail.
Anyway, in his model, the hypothalamus is the lower level (analogous to V1, say), sending "homeostatic signals" up to the amygdala. The amygdala is the higher level (analogous to V2, say), and its categories are called "value categories", and it sends predictions back down to hypothalamus. (p525 of his new book)
The parts I LIKE about this: (1) I do think the hypothalamus sends "homeostatic signals" (like how hungry am I) up to the amygdala, in the form of "context lines" to be used by the amygdala's supervised learning algorithm (cf. here [AF · GW] for what I mean by "context lines") (2) I do think it's reasonable to have a module that takes homeostatic / body-status information (and other contextual information) and analyzes it by building a vocabulary of abstract predictive categories, that can then inform plans and decisions (and perhaps can be reused for empathetic simulations too). I just don't think the amygdala does that. I think some part of granular insular cortex does that—this is the thing that Lisa Feldman Barrett calls "primary interoceptive cortex".
Anyway, why don't I think ART makes sense for the amygdala-hypothalamus relationship?
First, in the neocortex case, it's learning to model a complicated indeterminate world from data, so the genes don't know ahead of time what the categories are or how many there will be. You just get a bunch of input data and you need to start slotting it into different categories. In my scheme, the amygdala is outputting into a finite, genetically-hardcoded list of hypothalamus channels (cringe, grimace, laugh, salivate, etc.). So where I'm coming from, there's no need for any fancy neocortex-like category learning, there's no need for ART, there's no need for a learning algorithm editing synapses in the hypothalamus.
For example, in Dranias, I think the amygdala is supposed to "learn to flinch" in the sense that it learns a whole pattern of signals in the hypothalamus that correspond to flinching. Whereas in my model, the amygdala merely needs to "press the flinch button" in the hypothalamus.
But then there's another issue too, which is that the ART model seems (IMO) to allow too much influence of current-hypothalamus-state on what happens. Let's say there's a red light, and whenever it turns on I get shocked shortly thereafter. I'm standing here perfectly calm, and then the red light turns on. What should happen is the amygdala "tells" the hypothalamus that something scary and painful is about to happen, and the hypothalamus immediately changes its state. I don't think this can happen in Dranias's model. In the ART matching rule, the amygdala would look at the hypothalamus, sending up all those signals that say "everything is great, I'm perfectly calm", and categorize them into the "all is well" category, right? Or you can treat the light as an additional bottom-up signal to be lumped into the same category, but then the ART matching rule would potentially ignore the light, and go with the hypothalamus. In Grossberg's book he says the value categories "attentionally bias homeostatic responses". I think the amygdala's influence on the hypothalamus goes way beyond "attentionally biasing the response"—I think the amygdala can radically change what the hypothalamus is doing. That seems incompatible with the ART matching rule, as far as I understand it.
Or maybe a better way to say it is: Dranias's scheme kinda works if the amygdala learns, let's call it, "time-disconnected categories", categories that combine bottom-up signals at different times, e.g. a category involving both "what the light inputs were doing at time 11:25:48" and "what the hypothalamus signals were doing at time 11:25:49", for example. But that's just the learning part; when you get to the inference part, we face the problem that the "ART matching rule" seems to me to require all the bottom-up signals actually be present simultaneously, and they aren't in this situation, all the bottom-up signals coming from the hypothalamus are wrong at inference time. So you need a different algorithm.
Also, I will reiterate my complaint with Mollick above about taking insufficient account of the possibility of multiple heterogeneous dopamine signals. Dranias seems to have recognized that it’s impossible to use the main dopamine reward signal to learn the connections between the amygdala and the different things it can do in the lateral hypothalamus. So they just throw up their hands and say there’s a non-dopamine learning mechanism. Well, I admit it’s very possible that there’s a non-dopamine learning mechanism. But it’s also possible that there’s a dopamine learning mechanism attached to a different dopamine signal. We do, after all, have to explain the fact that, in experiments, the amygdala can’t learn anything without dopamine, I think. Plus, as I mentioned in the main post [LW · GW], there is experimental evidence for different dopamine signals, including particularly going to the amygdala.
A specific difference between my model and Dranias's (related to Dranias's use of the ART matching rule) is that I’m pretty skeptical of Dranias’s suggestion that there are learned connections in the lateral hypothalamus (if I understand correctly). I mean, for sure, hypothalamic plasticity is a thing, but from what I can tell, hypothalamic plasticity is more akin to the self-modifying code in Linux than to the weight updates in ML—like, a bunch of idiosyncratic hardcoded rules that say that under such-and-such condition the wiring needs to be changed in such-and-such way, so as to implement some corresponding adaptive behavior, like “if you keep winning fights, start being more aggressive” or whatever. I would be very surprised to see anything like RL or SL in the hypothalamus, as suggested (I think) by Dranias in the above diagram. (Well, I can think of a possible exception: conditioned taste aversion (CTA) is SL, but it’s a sufficiently specific and weird case that it could definitely be learned in the hypothalamus or brainstem, seems to me. UPDATE: oh, never mind, maybe CTA is cortex too.)
There’s plenty missing from Dranias’s model that I did talk about—like the VS-to-LH projections—but that’s fine and normal, no model is complete, and anyway I’m even more guilty of leaving things out.
I’ll reiterate that I could be way off-base.
(Please leave comments at the lesswrong crosspost, or email me.)
2 comments
Comments sorted by top scores.
comment by Ben Smith (ben-smith) · 2021-07-07T08:27:59.808Z · LW(p) · GW(p)
Interesting. Is it fair to say that Mollick's system is relatively more "serial" with fewer parallelisms at the subcortical level, whereas you're proposing a system that's much more "parallel" because there are separate systems doing analogous things at each level? I think that parallel arrangement is probably the thing I've learned most personally from reading your work. Maybe I just hadn't thought about it because I focus too much on valuation and PFC decision-making stuff and don't look broadly enough at movement and other systems.
Apropos of nothing, is there any role for the visual cortex within your system?
I too am puzzled about why some people talk about "mPFC" and others talk about "vmPFC". I focus on "vmPFC", mostly because that's what people in my field talk about. "vmPFC" focuses much more on valuation systems. Theoretically I guess "mPFC" would also include the dorsomedial prefrontal cortex, which includes the anterior cingulate cortex, I guess some systems related to executive control, perhaps response inhibition (although that's usually quite lateral), perhaps abstract processing. Tends to be a bit of a decision-making homunculous of sorts :/ And then there's the ACC, whose role in various things is fairly well defined.
So maybe authors who talk about the mPFC aren't as concerned about distinguishing value processing from all those other things.
Replies from: steve2152↑ comment by Steven Byrnes (steve2152) · 2021-07-07T17:04:23.093Z · LW(p) · GW(p)
Interesting. Is it fair to say that Mollick's system is relatively more "serial" with fewer parallelisms at the subcortical level, whereas you're proposing a system that's much more "parallel" because there are separate systems doing analogous things at each level? …
Hmm, I guess I'm not really sure what you're referring to.
Apropos of nothing, is there any role for the visual cortex within your system?
If I recall, V1 isn't involved in basal ganglia loops, and some higher-level visual areas might project to striatum as "context" but not as part of basal ganglia loops. (I'm not 100% clear on the anatomy here though; I think the literature is confusing to me partly because it took me a while to realize that rat visual cortex is a lot simpler than primate, I've heard it's kinda like "just V1"). So that's the message of "Is RL Involved in Sensory Processing? [LW · GW]": there's no RL in the visual cortex AFAICT. Instead I think there's predictive learning, see for example Randall O'Reilly's model.
I talk in the main article [AF · GW] about "proposal selection". I think the cortex is just full of little models that make predictions about other little models, and/or predictions about sensory inputs, and/or (self-fulfilling) "predictions" about motor outputs. And if a model is making wrong predictions, it gets thrown out, and over time it gets outright deleted from the system. (The proposals are models too.) So if you're staring at a dog, you just can't seriously entertain the proposal "I'm going to milk this cow". That model involves a prediction that the thing you're looking at is a cow, and that model in turn is making lower-level predictions about the sensory inputs, and those predictions are being falsified by the actual sensory input, which is a dog not a cow. So the model gets thrown out. It doesn't matter how high reward you would get for milking a cow, it's not on the table as a possible proposal.
I believe I noted that the within-cortex proposal-selection / predictive learning algorithms are important things, but declared them out of scope for this particular post.
The last time I wrote anything about the within-cortex algorithm was I guess last year here [LW · GW]. These days I'm more excited by the question of "how might we control neocortex-like algorithms?" rather than "how exactly would a neocortex-like algorithm work?"
I too am puzzled about why some people talk about "mPFC" and others talk about "vmPFC"…
Thanks, that was helpful