[Intuitive self-models] 2. Conscious Awareness
post by Steven Byrnes (steve2152) · 2024-09-25T13:29:02.820Z · LW · GW · 60 commentsContents
2.1 Post summary / Table of contents 2.2 The “awareness” concept 2.2.1 The cortex has a finite computational capacity that gets deployed serially 2.2.2 Predictive learning represents that algorithmic property via a kind of abstract container called “awareness” 2.2.3 “S(apple)”, defined as the self-reflective thought “apple being in awareness”, is different from the object-level thought “apple” 2.3 Awareness over time: The “Stream of Consciousness” 2.4 Relation between “awareness” and memory 2.4.1 Intuitive model of memory as a storage archive 2.4.2 Intuitive connection between memory and awareness 2.5 The valence of S(X) thoughts 2.5.1 Positive-valence S(X) models often go with “what my best self would do” (other things equal) 2.5.2 Positive-valence S(X) models also tend to go with X’s that are object-level motivating (other things equal) 2.6 S(A) as “the intention to immediately do action A”, and the rapid sequence [S(A) ; A] as the signature of an intentional action 2.6.1 Clarification: Two ways to “think about an action” 2.6.2 For any action A where S(A) has positive valence, there’s often a two-step temporal sequence: [S(A) ; A actually happens] 2.6.3 This two-step sequence corresponds to “intentional” actions (as opposed to “spontaneously blurting something out”, “acting on instinct”, etc.) 2.6.4 The common temporal sequence above—i.e. [S(A) with positive valence ; A actually happens]—is itself incorporated into the intuitive self-model. Call it D(A) for “Deciding to do action A” 2.6.5 An application: Illusions of intentionality 2.7 Conclusion None 60 comments
2.1 Post summary / Table of contents
Part of the Intuitive Self-Models series [? · GW].
The previous post [LW · GW] laid some groundwork for talking about intuitive self-models. Now we’re jumping right into the deep end: the intuitive concept of “conscious awareness” (or “awareness” for short). Some argue (§1.6.2 [LW · GW]) that if we can fully understand why we have an “awareness” concept, then we will thereby understand phenomenal consciousness itself! Alas, “phenomenal consciousness itself” is outside the scope of this series—again see §1.6.2 [LW · GW]. Regardless, the “awareness” concept is centrally important to how we conceptualize our own mental worlds, and well worth understanding for its own sake.
In one sense, “awareness” is nothing special: it’s an intuitive concept, built like any other intuitive concept. I can think the thought “a squirrel is in my conscious awareness”, just as I can think the thought “a squirrel is in my glove compartment”.
But in a different sense, “awareness” feels a bit enigmatic. The “glove compartment” concept is a veridical model (§1.3.2 [LW · GW]) of a tangible thing in a car. Whereas the “awareness” concept is a veridical model of … what exactly, if anything?
I have an answer! The short version of my hypothesis is: The brain algorithm involves the cortex, which has a limited computational capacity that gets deployed serially—you can’t both read health insurance documentation and ponder the meaning of life at the very same moment.[1] When this aspect of the brain algorithm is itself incorporated into a generative model via predictive (a.k.a. self-supervised) learning, it winds up represented as an “awareness” concept, which functions as a kind of abstract container that can hold any other mental concept(s) in it.
- In Section 2.2, I flesh out that hypothesis above. And relatedly, I introduce an important terminology that I’ll be using throughout the series: For any concept X, I define “S(X)” (“X in a self-reflective frame”) to be the intuitive model wherein X is contained within the “awareness” abstract container.
- Section 2.3 talks about how awareness unfolds in time as a “stream of consciousness”—an area where our intuitions strikingly depart from reality, once we zoom into sub-second timescales.
- Section 2.4 covers memory and how it connects to awareness—both in reality and in our intuitive models.
- Section 2.5 talks about the valence [LW · GW] of those S(X) thoughts. I’ll show that this valence is influenced not only by the object-level X being directly motivating, but also by X being associated with “my best self”—the things that fit well with my social image and an appealing narrative of my life. Note the suspicious convergence between the valence of S(X), and the things that we do “intentionally” versus “impulsively”. That brings us to…
- Section 2.6, where I develop the connection between “awareness”, intentions, and decisions. In particular, I consider the special case of S(A), where A is an action concept like “say hi” or “think about the Roman Empire”—and not just the sensory and semantic consequences of that action (e.g. the idea of saying hi), but the attention-control and/or motor-control outputs that would make that action actually happen. In this case, I’ll suggest that we intuitively interpret S(A) as an intention to do A. And if this S(A) is immediately followed by the execution of A itself (as is often the case), then we call A an intentional action—as opposed to an action which is spontaneous, reflexive, instinctive, “blurted out”, etc. As an application of this idea, I’ll explain “illusions of intentionality”.
That’s still not the whole story of intentions and decisions—it’s missing the critical ingredient of an intuitive agent that actively causes the decisions. That turns out to be a whole giant can of worms, which we’ll tackle in Post 3 [LW · GW].
Prior work: From my perspective, my main hypothesis (§2.2) should be “obvious” if you’re familiar with “Global Workspace Theory” [LW · GW][2] and/or “Attention Schema Theory”—and indeed I found Michael Graziano’s Rethinking Consciousness (2019) to be extremely helpful for clarifying my thinking.[3] Graziano & I have some differences though.[4] Also, §2.3 partly follows chapter 5 of Daniel Dennett’s Consciousness Explained (1991). Once we get into §2.5–§2.6 and the whole rest of the series, I mostly felt like I was figuring things out from scratch—but please let me know if you’ve seen relevant prior literature!
2.2 The “awareness” concept
2.2.1 The cortex has a finite computational capacity that gets deployed serially
What do I mean by that heading? Here are a few different ways to put it:
- If I’m thinking about calling the plumber, then the various parts of my cortex are busily tracking the various aspects and associations of calling the plumber. If I’m thinking about going to the zoo, then the various parts of my cortex are busily tracking the various aspects and associations of going to the zoo. The cortex is unable to do both those things simultaneously.
- Think of a system with “attractor dynamics”, like a Hopfield net or Boltzmann machine. It can’t activate two different stored patterns simultaneously. I think the cortex has a vaguely similar property.
- In terms of the §1.2 [LW · GW] discussion, the cortex does probabilistic inference, always homing in on the best generative model. But the way that works entails a rather limited ability to activate and query multiple possible generative models simultaneously. Instead, most of the time, in most of the area of the cortex, I claim there’s mainly just one active generative model, corresponding to a maximum a posteriori (MAP) estimate.
2.2.2 Predictive learning represents that algorithmic property via a kind of abstract container called “awareness”
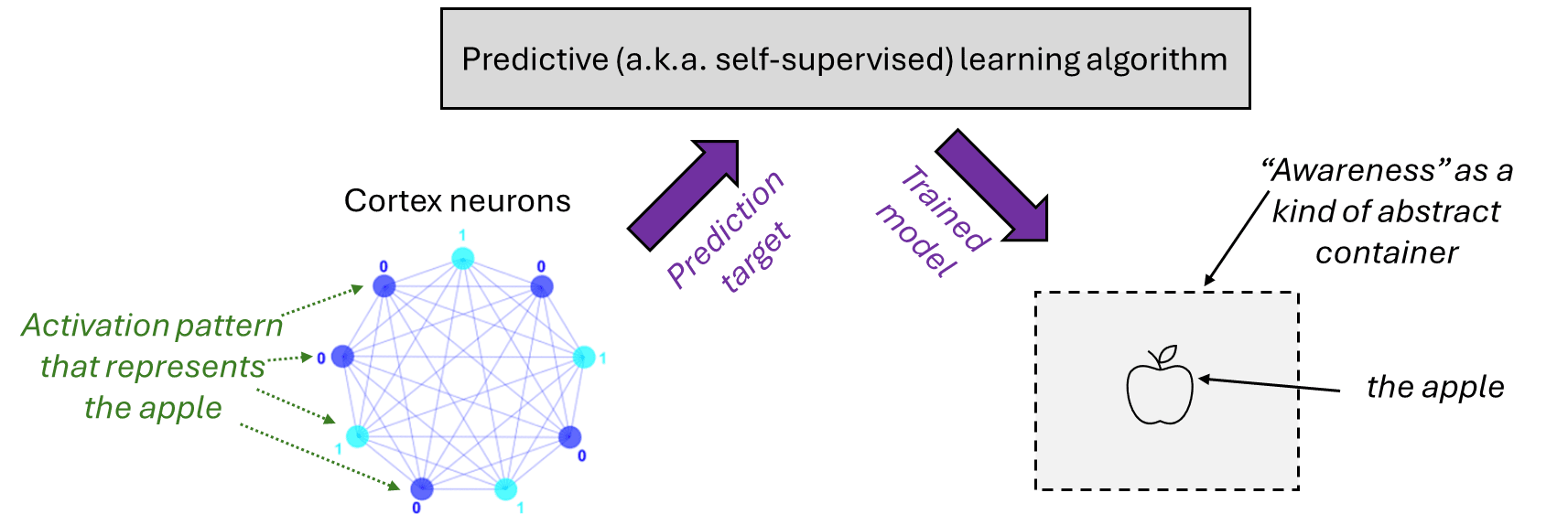
If I say, “This apple is on my mind”, that’s a self-reflective thought. It involves a concept I’m calling “awareness”, and also the concept of “this apple”, and those two concepts are connected by a kind of container-containee relationship.
And I claim that this thought is modeling a situation where the cortex[2] is, at some particular moment, using its finite computational capacity to process my intuitive model of this apple.
More generally:
- In the intuitive self-model (“map”), any possible thought can be in “awareness” at any given time, but only one thought can be there at a time.
- Correspondingly, in the actual brain algorithm (“territory”), any possible thought can be represented by the cortex (by definition), but only one thought can be there at a time (to a first approximation, see §2.3 below).
So there’s a map-territory correspondence: awareness is a (somewhat) veridical (§1.3.2 [LW · GW]) model of this particular aspect of the brain algorithm.
2.2.3 “S(apple)”, defined as the self-reflective thought “apple being in awareness”, is different from the object-level thought “apple”
Astute readers might be wondering: if the “awareness” concept can itself be part of an intuitive model active in the cortex, then wouldn’t the thought “the apple is in awareness right now” be self-contradictory?
After all, the thing you’re thinking “right now” would be “the apple is in awareness right now”, rather than just “the apple” itself, right?
Yes! In order to think the former thought, you would have to stop thinking of just “the apple” itself, and flip to a different thought, where there’s a frame (in the sense of “frame semantics” in linguistics or “frame languages” in GOFAI) involving the “awareness” concept, and the “apple” concept, interconnected by container-containee relationship.
For various purposes later on, it will be nice to have a shorthand. So S(apple) (read: apple in a self-reflective frame) will denote the apple-is-in-awareness thought. It's “self-reflective” in the sense that it involves “awareness”, which is part of the intuitive self-model.
2.3 Awareness over time: The “Stream of Consciousness”
[Optional bonus section! You can skip §2.3, and still be able to follow the rest of the series.]
Here’s an aspect of the intuitive “awareness” concept that does not veridically correspond to the algorithmic phenomenon that it’s modeling. Daniel Dennett makes a big deal out of this topic in Consciousness Explained (1991), because it was important for his thesis to find aspects of our intuitive “awareness” concept that is not veridical, and this one seems reasonably clear-cut.
As background, there are various situations where, for events that unfold over the course of some fraction of a second, later sensory inputs are taken into account in how you remember experiencing earlier sensory inputs. Dennett uses an obscure psychology result called “color phi phenomenon” as his main case study, but the phenomenon is quite common, so I’ll use a more everyday example: hearing someone talk.
I’ll start from the computational picture. As discussed in §1.2 [LW · GW], your cortex is (either literally or effectively) searching through its space of generative models for one that matches input data and other constraints, via probabilistic inference. Some generative models, like a model that predicts the sound of a word, are extended in time, and therefore the associated probabilistic inference has to be extended in time as well.
So suppose somebody says the word “smile” to me over the course of 0.4 seconds. The actual moment-by-moment activation of my cortex algorithm might look like:
- From t=0 to t=0.15 seconds, there’s a sound that I can’t yet make out—a number of different incompatible generative models are simultaneously weakly active. There just hasn’t been enough sound yet to make any sense of it.
- By t=0.3 seconds, the generative model “smile” has won the competition, becoming the active model (posterior).
…But interestingly, if I then immediately ask you what you were experiencing just now, you won’t describe it as above. Instead you’ll say that you were hearing “sm-” at t=0 and “-mi” at t=0.2 and “-ile” at t=0.4. In other words, you’ll recall it in terms of the time-course of the generative model that ultimately turned out to be the best explanation.
So with that as background, here’s how someone might intuitively describe their awareness over time:
Statement: When I’m watching and paying attention to something, I’m constantly aware of it as it happens, moment-by-moment. I might not always remember things perfectly, but there’s a fact of the matter of what I was actually experiencing at any given time.
Intuitive model underlying that statement: Within our intuitive models, there’s a “awareness” concept / frame as above, and at any given moment it has some content in it, related to the current sensory input, memories, thoughts, or whatever else we’re paying attention to. The flow of this content through time constitutes a kind of movie, which we might call the “stream of consciousness”. The things that “I” have “experienced” are exactly the things that were frames of that movie. The movie unfolds through time, although it’s possible that I’ll misremember some aspect of it after the fact.
What’s really happening, and is the model veridical in this respect? In the above example of hearing the word “smile”, there was no moment when the beginning part of the word was the active part of the active generative model. When “smi-” was entering our brain, the “smile” generative model was not yet strongly activated—that happened slightly later. But it doesn’t seem to be that way subjectively—we remember hearing the whole word as the beginning, middle, and end of “smile”. So,
Question: was the beginning part of hearing the word “smile” actually “experienced”?
Answer: That question is incoherent, because this is an area where the intuitive model above is not veridical.
Specifically, in the brain algorithm in question, there are two history streams we can talk about:
- One history stream is related to the moment-by-moment state of the algorithmic processing—at such-and-such moment, which generative models were active in the cortex, and how active were they?
- The other history stream is the best-guess time-course of what’s happening, stitched together by probabilistic inference, routinely taking advantage of (a fraction of a second of) hindsight.
The “stream-of-consciousness” intuitive model smushes these together into the same thing—just one history stream, labeled “what I was experiencing at that moment”.
That smushing-together is an excellent approximation on a multi-second timescale, but inaccurate if you zoom into what’s happening at sub-second timescales.
So a question like “what was I really experiencing at t=0.1 seconds” doesn’t seem answerable—it’s a question about the “map” (intuitive model) that doesn’t correspond to any well-defined question about the “territory” (the algorithms that the intuitive model was designed to model). Or equivalently, it corresponds equally well to two different questions about the territory, with two different answers, and there’s just no fact of the matter about which is the real answer.
Anyway, the intuitive model, with just one history stream instead of two, is much simpler, while still being perfectly adequate to play the role that it plays in generating predictions (see §1.4 [LW · GW]). So it’s no surprise that this is the generative model built by the predictive learning algorithm. Indeed, the fact that this aspect of the model is not perfectly veridical is something that basically never comes up in normal life.
2.4 Relation between “awareness” and memory
2.4.1 Intuitive model of memory as a storage archive
Statement: “I remember going to Chicago”
Intuitive model: Long-term memory in general, and autobiographical long-term memory in particular, is some kind of storage archive. Things can get pulled from that archive into the “awareness” abstract container. And there are memories of myself-in-Chicago stored in that box, which can be retrieved deliberately or by random association.
What’s really happening? There’s some brain system (mainly the hippocampus, I think) that stores episodic memories. The memories can get triggered by pattern-matching (a.k.a. “autoassociative memory”), and then the memory and its various associations can activate all around the cortex.
Is the model veridical? Yeah, pretty much. As above, it’s not a veridical model of your brain as a hunk of meat in 3D space, but it is a reasonably veridical model of an aspect of the algorithm that your brain is running.
2.4.2 Intuitive connection between memory and awareness
Statement: “An intimate part of my awareness is its tie to long-term memory. If you show me a video of me going scuba diving this morning, and I absolutely have no memory whatsoever of it, and you can prove that the video is real, well I mean, I don't know what to say, I must have been unconscious or something!”[5]
Intuitive model: Whatever happens in “awareness” also gets automatically cataloged in the memory storage archive—at least the important stuff, and at least temporarily. And that’s all that’s in the memory storage archive. The memory storage archive just is a (very lossy) history of what’s been in awareness. This connection is deeply integrated into the intuitive model, such that imagining something in memory that was never in awareness, or conversely imagining that there was recently something very exciting and unusual in awareness but that it’s absent from memory, seems like a contradiction, demanding of some exotic explanation like “I wasn’t really conscious”.
Is the model veridical in this respect? Yup, I think this aspect of the intuitive model is veridically capturing the relation between cortex and episodic memory storage within the (normally-functioning) brain algorithm.
2.5 The valence of S(X) thoughts
We have lots of self-reflective thoughts—i.e., thoughts that involve components of the intuitive self-model—such as S(Christmas presents) = the self-reflective idea that Christmas presents are on my mind (see §2.2.3 above). And those thoughts have valence, just like any other thought. Let’s explore that idea and its consequences.
(Warning: I’m using the term “valence” in a specific and idiosyncratic way—see my Valence series [LW · GW].)
The starting question is: What controls the valence of an S(X) model?
Well, it’s the same as anything else—see How does valence get set and adjusted? [LW · GW]. One thing that can happen is that S(X) might directly trigger an innate drive, which injects positive or negative valence as a kind of ground truth. Another thing that can happen is: S(X) might have a strong association with / implication of some other thought / concept C. In that case, we’ll often think of S(X), then think of C, back and forth in rapid succession. And then by TD learning [LW · GW], some of the valence of C will splash onto S(X) (and vice-versa).
That latter dynamic—valence flowing through salient associations—turns out to have some important implications as I’ll discuss next (and more on that in Post 8 [LW · GW]).
2.5.1 Positive-valence S(X) models often go with “what my best self would do” (other things equal)
Notice how S(⋯) thoughts are “self-reflective”, in the sense that they involve me and my mind, and not just things in the outside world. This is important because it leads to S(⋯) having strong salient associations with other thoughts C that are also self-reflective. After all, if a self-reflective thought is in your head right now, then it’s much likelier for other self-reflective thoughts to pop into your head immediately afterwards.
As a consequence, here are two common examples of factors that influence the valence of S(X):
- How does S(X) fit in with my social image? A self-reflective thought like S(homework) ≈ “I’m focusing on my homework” has the salient implication “Other people might know that I’m focusing on my homework”, which in turn might be motivating or demotivating.
- Cf. the innate “drive to be liked / admired” [LW · GW].
- How does S(X) fit in with the narrative of my life? A self-reflective thought like S(homework) ≈ “I’m focusing on my homework” may have the salient implication “I’m following through on my New Year’s Resolution to focus on my homework”, or “I’m making progress towards my goal of becoming rich and famous”.
Contrast either of those with a non-self-reflective (i.e., object-level) thought related to doing my homework, e.g. “What’s the square root of 121 again?”. If I’m thinking about that, then the question of what other people think about me, and how my life plans are going, are less salient.
There’s a pattern here, which is that self-reflective thoughts are more likely to be positive-valence (motivating) if it’s something that we’re proud of, that we like to remember, that we’d like other people to see, etc.
But that’s not the only factor. The object-level is relevant too:
2.5.2 Positive-valence S(X) models also tend to go with X’s that are object-level motivating (other things equal)
For example, if I’m tired, then I want to go to sleep. Maybe going to sleep right now wouldn’t help my social image, and maybe it’s not appealing in the context of the narrative of my life. More generally, maybe I don’t think that “my best self” would be sleeping now, instead of working more. But nevertheless, the self-reflective thought “I’m gonna go to sleep now” will be highly motivating to me, because of its obvious association with / implication of sleep itself.
Maybe I’ll even say “Screw being ‘my best self’, I’m tired, I’m going to sleep”.
What’s going on? It’s the same dynamic as above, but this time the salient association of S(X) is X itself. When I think the self-reflective thought S(go to sleep) ≈ “I’m thinking about going to sleep”, some of the things that it tends to bring to mind are object-level thoughts about going to sleep, e.g. the expectation of feeling the soft pillow on my head. Those thoughts are motivating, since I’m tired. And then by TD learning [LW · GW], S(X) winds up with positive valence too.
(Conversely, just as the valence of X splashes onto S(X), by the same logic, the valence of S(X) splashes onto X. More on that below.)
2.6 S(A) as “the intention to immediately do action A”, and the rapid sequence [S(A) ; A] as the signature of an intentional action
2.6.1 Clarification: Two ways to “think about an action”
I’ll be arguing shortly that, for a voluntary [LW · GW] action A, S(A) is the “intention” to immediately do A. You might find this confusing: “Can’t I think self-reflectively about an action, without intending to do that action??” Yes, but … allow me to clarify.
Put aside self-reflective thoughts for a moment; let’s just start at the object level. If “the idea of standing up is on my mind” at some moment, that might mean either or both of two rather different things:
- Maybe the sensory and semantic consequences of the standing-up action are in my awareness—including, for example, the expected feeling of bodily motion and exertion, and the idea that I’ll wind up standing, and that my chair will wind up empty, etc.;
- Maybe the standing-up action program itself—i.e., the patterns of motor control and attention control outputs that would collectively make my muscles actually execute the standing-up action—are in my awareness. If they are, and if there’s positive valence [LW · GW] keeping it active, then I would find myself immediately actually standing up.
The punchline: When I say “an action A” in this series, it always refers to the second bullet, not the first—an action program, not merely an action idea.
So far that’s all the object-level domain. But there’s an analogous distinction in the self-reflective domain, “S(stand up)” is ambiguous as written. It could be the thought: “standing up (as a thing that could happen) is the occupant of conscious awareness”—i.e., a veridical model of the first bullet point situation above. Or it could be the thought “standing up (the action program itself) is the occupant of conscious awareness”—i.e., a veridical model of the second bullet point situation above.
And just as above, when I say S(A), I’ll always be talking about the latter, not the former; it’s the latter that (I’ll argue) corresponds to an “intention”.
That said, those two aspects of standing up are obviously strongly associated with each other. They can activate simultaneously. And even if they don’t, each tends to bring the other to mind, such that the valence of one influences the valence of the other.
With that aside, let’s get into the substance of this section!
2.6.2 For any action A where S(A) has positive valence, there’s often a two-step temporal sequence: [S(A) ; A actually happens]
In this section I’ll give a kind of first-principles derivation of something that we should expect to happen in brain algorithms, based on the discussion thus far. Then afterwards, I’ll argue that this phenomenon corresponds to our everyday notion of intentions and actions. Here goes:
- Ingredient 1: In general, S(X) often summons a follow-on thought of X. As mentioned in §2.5.2 above, there’s a strong, salient association between an object-level thing and the corresponding self-reflective way to think about that same thing—each implies the other. So if we’re thinking of X, S(X) may well immediately pop into our heads, and vice-versa.
- Ingredient 2: If S(X) is positive valence, that makes it more likely (other things equal) for X to wind up positive valence. Again see §2.5.2 above.
- Ingredient 3: If a voluntary [LW · GW] action program A (attention-control, motor-control, or both) is active in awareness, and has positive valence, then it will immediately actually happen. See §2.6.1 above; this is almost the definition of valence, as I use the term [LW · GW].
Put these together, and we conclude that there ought to be a frequent pattern:
- STEP 1: There’s a self-reflective thought S(A), for some action-program A (motor-control and/or attention-control), and this thought has positive valence;
- STEP 2 (a fraction of a second later): The non-self-reflective (a.k.a. object-level) thought A occurs, and this makes the action A actually happen.
2.6.3 This two-step sequence corresponds to “intentional” actions (as opposed to “spontaneously blurting something out”, “acting on instinct”, etc.)
Here are a few reasons that you might believe me on this:
Evidence from introspection: I’m suggesting that (step 1) you think of yourself sending a command to wiggle your fingers, and you find that thought to be motivating (positive valence), and then (step 2) a fraction of a second later, the command is sent and your fingers are actually wiggling. To me, that feels like a pretty good fit to “intentionally” / “deliberately” doing something. Whereas “acting on impulses, instincts, reflexes, etc.” seems to be missing the self-reflective step 1 part.
Evidence from the report of an insight meditator: For what it’s worth, meditation guru Daniel Ingram writes here: “In Mind and Body, the earliest insight stage, those who know what to look for and how to leverage this way of perceiving reality will take the opportunity to notice the intention to breathe that precedes the breath, the intention to move the foot that precedes the foot moving, the intention to think a thought that precedes the thinking of the thought, and even the intention to move attention that precedes attention moving.” I claim that’s a good match to what I wrote—S(A) would be the “intention” to do action A.
Evidence from the systematic differences between intentional actions and spontaneous actions: Consider spontaneous actions like “blurting out”, also called instinctive, reflexive, unthinking, reactive, spontaneous, etc. According to my story, a key difference between these types of actions, versus intentional actions, is that the valence of S(A) is necessarily positive in intentional actions, but need not be positive in spontaneous actions. And in §2.5 above, I said that the valence of S(A) is influenced by the valence of A, but S(A) is also influenced by “what my best self would do”—S(A) tends to be more positive for actions A that would positively impact my social image, fit well into the narrative of my life, and so on. And correspondingly, those are exactly the kinds of actions that are more likely to be “intentional” than “spontaneous”. Good fit!
2.6.4 The common temporal sequence above—i.e. [S(A) with positive valence ; A actually happens]—is itself incorporated into the intuitive self-model. Call it D(A) for “Deciding to do action A”
The whole point of these intuitive generative models is to observe things that often happen, and then expect them to keep happening in the future. So if the [S(A) with positive valence ; A actually happens] pattern happens regularly, of course the brain will incorporate that as an intuitive concept in its generative models. I’ll call it D(A).
2.6.5 An application: Illusions of intentionality
The stereotypical intentional-action scenario above is:
- Step 1: S(A) [with positive valence]
- Step 2: A
Here’s a different scenario:
- Step 1’: (…not sure, wasn’t paying attention…)
- Step 2’: A
Now suppose that Step 1’ was not in fact S(A), but that it could have been S(A)—in the specific sense that the hypothesis “what just happened was [S(A) ; A]” is a priori highly plausible and compatible with everything we know about ourselves and what’s happening.
In that case, we should expect the D(A) generative model to activate. Why? It’s just the cortex doing what it always does: using probabilistic inference to find the best generative model given the limited information available. It’s no different from what happens in visual perception: if I see my friend’s head coming up over the hill, I automatically intuitively interpret it as the head of my friend whose body I can’t see; I do not interpret it as my friend’s severed head. The latter would be a priori less plausible than the former.
Anyway, if D(A) activates despite a lack of actual S(A), that would be a (so-called) “illusion of free will”. Examples include the "choice blindness" experiment of Johansson et al. 2005, the "I Spy" and other experiments described in Wegner & Wheatley 1999, some instances of confabulation, and probably some types of “forcing” in stage magic. As another (possible) example, if I’m deeply in a flow state, writing code, and I take an action A = typing a word, then the self-reflective S(A) thought is almost certainly not active (that’s what “flow state” means, see Post 4 [LW · GW]), but if you ask me after the fact whether I had “decided” to execute action A, I think I would say “yes”.
2.7 Conclusion
I think this is a nice story for how the “conscious awareness” concept comes to exist in our mental worlds, how it relates to other intuitive notions like memory, stream-of-consciousness, intentions, and decisions, and how all these entities in the “map” (intuitive model) relate to corresponding entities in the “territory” (brain algorithms, as designed by the genome).
However, the above story of intentions and decisions is not yet complete! There’s an additional critical ingredient within our intuitive self-models. Not only are there intentions and decisions in our minds, but we also intuitively believe there to be a protagonist—an entity that actively intends our intentions, and decides our decisions, and wills our will! Following Dennett, I’ll call that concept “the homunculus”, and that will be the subject of the next post [LW · GW].
Thanks Thane Ruthenis, lsusr, Seth Herd, Linda Linsefors, and Justis Mills for critical comments on earlier drafts.
- ^
It is, of course, possible to read health insurance documentation and ponder the meaning of life in rapid succession, separated by as little as a fraction of a second. Especially when “pondering the meaning of life” includes nihilism and existential despair! USA readers, you know what I’m talking about.
- ^
It won’t come up again in this series, but I’ll note for completeness that “awareness” is related to the activation state of some parts of the cortex much more than other parts. For example, the primary visual cortex is not interconnected with other parts of the cortex or with long-term memory in the same direct way that many other cortical areas are; hence, you can say that we’re “not directly aware” of what happens in the primary visual cortex. In the lingo, people describe this fact by saying that there’s a “Global Neuronal Workspace” [LW · GW] consisting of many (most?) parts of the cortex, but that the primary visual cortex is not one of those parts.
- ^
Relatedly, some bits of text in this post are copied from my earlier post Book Review: Rethinking Consciousness [LW · GW].
- ^
From my perspective, Graziano’s main thesis and my §2.2 are pretty similar in the big picture. I think the biggest difference between his presentation and mine is that we stand at different places on the spectrum from “evolved modularity” to “universal learning machine” [LW · GW]. Graziano seems to be more towards the “evolved modularity” end, where he thinks that evolution specifically built “awareness” into the brain to serve as sensory feedback for attention actions, in analogy to how evolution specifically built the somatosensory cortex to serve as sensory feedback for motor actions. By contrast, my belief is much closer to the “universal learning machine” end, where “awareness” (like the rest of the intuitive self-model) comes out of a somewhat generic within-lifetime predictive learning algorithm, involving many of the same brain parts and processes that would create, store, and query an intuitive model of a carburetor.
Again, that’s all my own understanding. Graziano has not read or endorsed anything in this post.
- ^
I adapted that statement from something Jeff Hawkins said. But tragically, it’s not just a hypothetical: Clive Wearing developed total amnesia 40 years ago, and ever since then “he constantly believes that he has only recently awoken from a comatose state”.
60 comments
Comments sorted by top scores.
comment by cubefox · 2024-09-26T12:58:16.048Z · LW(p) · GW(p)
I don't know whether this is relevant to you, but in "x is aware of y" ("y is in x's awareness"), y is considered an intensional term, while for "x physically contains y", y is considered extensional. (And x is extensional in both cases.)
"Extensional" means that co-referring terms can always be substituted for each other without affecting the truth value of the resulting proposition. For "intensional" terms this is not necessarily the case.
For example, "Steve is aware of Yvain" does not entail "Steve is aware of Scott", even if Scott = Yvain. Namely when Steve doesn't know that Scott = Yvain.
However, "The house contains Scott" ("Scott is in the house") implies "The house contains Yvain" because Yvain = Scott.
Most relations only involve extensional terms. Some examples of relations which involve intensional terms: is aware of, thinks, believes, wants, intends, loves, means.
Intensional (with an "s") terms are present mainly or only in relations which express "intentionality" (with a "t") in the technical philosophical sense: a mind (or mental state) representing, or being about, something. It's a central question in philosophy of mind how this can happen. Because ordinary physical objects don't seem to exhibit this property.
Though I'm not completely sure whether your theory has ambitions to solve this problem.
Replies from: steve2152↑ comment by Steven Byrnes (steve2152) · 2024-09-26T13:16:09.299Z · LW(p) · GW(p)
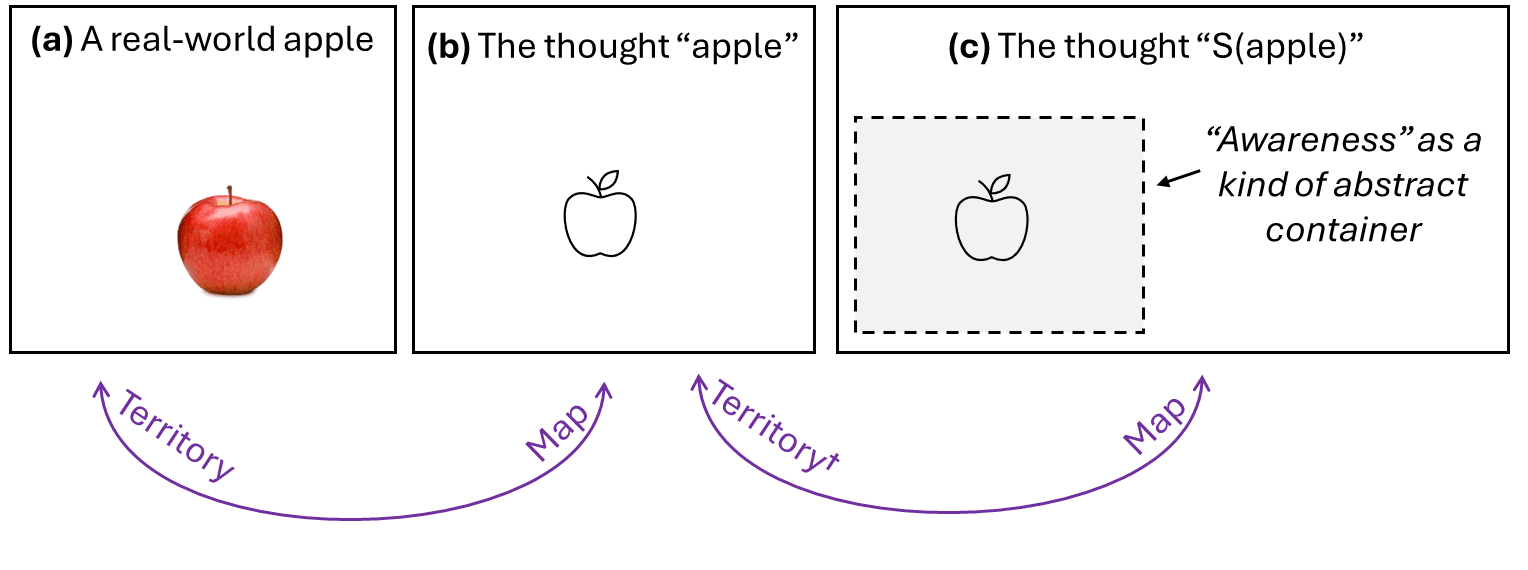
Thanks! I feel like that’s a very straightforward question in my framework. Recall this diagram from above:
[UPDATED TO ALSO COPY THE FOLLOWING SENTENCE FROM OP: †To be clear, the “territory” for (c) is really “(b) being active in the cortex”, not (b) per se.]
Your “truth value” is what I call “what’s happening in the territory”. In the (b)-(a) map-territory correspondence, the “territory” is the real world of atoms, so two different concepts that point to the same possibility in the real world of atoms will have the same “truth value”. In the (c)-(b) map-territory correspondence, the “territory” is the cortex, or more specifically what concepts are active in the cortex, so different concepts are always different things in the territory.
Do you agree that that’s a satisfactory explanation in my framework of why “apple is in awareness” is intensional while “apple is in the cupboard” is extensional? Or am I missing something?
Replies from: cubefox↑ comment by cubefox · 2024-09-26T14:50:30.109Z · LW(p) · GW(p)
So here (c) is about / represents (b), which itself is about / represents (a). Both (b) and (c) are thoughts (the thought of an apple and the thought of the thought of an apple), so it is expected that they both can represent things. And (a) is a physical object, so it isn't surprising that (a) doesn't represent anything.
However, it is not clear how this difference in capacity for representation arises. More specifically, if we think of (c) not as a thought/concept, but as the cortex, which is a physical object, it is not clear how the cortex could represent / be about something, namely (b).
It is also not clear why thinking about X doesn't imply thinking about Y even in cases where X=Y, while X being on the cupboard implies Y being on the cupboard when X=Y.
Tangential considerations:
I notice that in (b)-(a), (a) is intensional, as expected, while in (c)-(b), (b) does seem to be extensional. Which is not expected, since (c) is a thought about (b).
For example, in the case of (b)-(a) we could have a thought about the apple on the cupboard, and a thought about the apple I bought yesterday, which would not be the same thought, even if both apples are the same object, since I may not know that the apple on the cupboard is the same as the apple I bought yesterday.
But when thinking about our own thoughts, no such failure of identification seems possible. We always seem to know whether two thoughts are the same or not. Apparently because we have direct "access" to them because they are "internal", while we don't have direct "access" to physical objects, or to other external objects, like the thoughts of other people. So extensionality fails for thoughts about external objects, but holds for thoughts about internal objects, like our own thoughts.
Replies from: steve2152↑ comment by Steven Byrnes (steve2152) · 2024-09-26T15:22:20.205Z · LW(p) · GW(p)
Thanks! The “territory” for (c) is not (b) per se but rather “(b) being active in the cortex”. (That’s the little dagger on the word “territory” below (b), I explained it in the OP but didn’t copy it into the comment above, sorry.)
So “thought of the thought of an apple” is not quite what (c) is. Something like “thought of the apple being on my mind” would be closer.
More specifically, if we think of (c) not as a thought/concept, but as the cortex, which is a physical object, it is not clear how the cortex could represent / be about something, namely (b).
I sorta feel like you’re making something simple sound complicated, or else I don’t understand your point. “If you think of a map of London as a map of London, then it represents London. If you think of a map of London as a piece of paper with ink on it, then does it still represent London?” Umm, I guess? I don’t know! What’s the point of that question? Isn’t it a silly kind of thing to be talking about? What’s at stake?
It is also not clear why thinking about A doesn't imply thinking about B even in cases where A=B, while A being on the cupboard implies B being on the cupboard when A=B.
Again, I feel like you’re making common sense sound esoteric (or else I’m missing your point). If I don’t know that Yvain is Scott, and if at time 1 I’m thinking about Yvain, and if at time 2 I’m thinking about Scott, then I’m doing two systematically different things at time 1 versus time 2, right?
But when thinking about our own thoughts, no such failure of identification seems possible.
In some contexts, two different things in the map wind up pointing to the same thing in the territory. In other cases, that doesn’t happen. For example, in the domain of “members of my family”, I’m confident that the different things on my map are also different in the territory. Whereas in the domain of anatomy, I’m not so confident—maybe I don’t realize that erythrocytes = red blood cells. Anyway, whether this is true or not in any particular domain doesn’t seem like a deep question to me—it just depends on the domain, and more specifically how easy it is for one thing in the territory to “appear” different (from my perspective) at different times, such that when I see it the second time, I draw it as a new dot on the map, instead of invoking the preexisting dot.
Replies from: cubefox↑ comment by cubefox · 2024-09-26T17:56:25.097Z · LW(p) · GW(p)
I sorta feel like you’re making something simple sound complicated, or else I don’t understand your point. “If you think of a map of London as a map of London, then it represents London. If you think of a map of London as a piece of paper with ink on it, then does it still represent London?” Umm, I guess? I don’t know! What’s the point of that question? Isn’t it a silly kind of thing to be talking about? What’s at stake?
Well, it seems that purely the map by itself (as a physical object only) doesn't represent London, because the same map-like object could have been created as an (extremely unlikely) accident. Just like a random splash of ink that happens to look like Jesus doesn't represent Jesus, or a random string generator creating the string "Eliezer Yudkowsky" doesn't refer to Eliezer Yudkowsky. What matters seems to be the intention (a mental object) behind the creation of an actual map of London: Someone intended it to represent London.
Or assume a local tries to explain to you where the next gas station is, gesticulates, and uses his right fist to represent the gas station and his left fist to represent the next intersection. The right fist representing the gas station is not a fact about the physical limb alone, but about the local's intention behind using it. (He can represent the gas station even if you misunderstand him, so only his state of mind seems to matter for representation.)
So it isn't clear how a physical object alone (like the cortex) can be about something. Because apparently maps or splashes or strings or fists don't represent anything by themselves. That is not to say that the cortex can't represent things, but rather that it isn't clear why it does, if it does.
Again, I feel like you’re making common sense sound esoteric (or else I’m missing your point). If I don’t know that Yvain is Scott, and if at time 1 I’m thinking about Yvain, and if at time 2 I’m thinking about Scott, then I’m doing two systematically different things at time 1 versus time 2, right?
Exactly. But it isn't clear why these thoughts are different. If your thinking about someone is a relation between yourself and someone else, then it isn't clear why you thinking about one person could ever be two different things.
(A similar problem arises when you think about something that might not exist, like God. Does this thought then express a relation between yourself and nothing? But thinking about nothing is clearly different from thinking about God. Besides, other non-existent objects, like the largest prime number, are clearly different from God.)
Maybe it is instead a relation between yourself and your concept of Yvain, and a relationship between yourself and your concept of Scott, which would be different relations, if the names express different concepts, in case you don't regard them as synonymous. But both concepts happen to refer to the same object. Then "refers to" (or "represents") would be a relation between a concept and an object. Then the question is again how reference/representation/aboutness/intentionality works, since ordinary physical objects don't seem to do it. What makes it the case that concept X represents, or doesn't represent, object Y?
But when thinking about our own thoughts, no such failure of identification seems possible.
In some contexts, two different things in the map wind up pointing to the same thing in the territory. In other cases, that doesn’t happen. For example, in the domain of “members of my family”, I’m confident that the different things on my map are also different in the territory.
If you believe x and y are members of your family, that doesn't imply you having a belief on whether x and y are identical or not. But if x and y are thoughts of yours (or other mental objects), you know whether they are the same or not. Example: you are confident that your brother is a member of your family, and that the person who ate your apple is a member of your family, but you are not confident about whether your brother is identical to the person who ate your apple.
It seems such examples can be constructed for any external objects, but not for internal ones, so the only "domain" where extensionality holds for intentionality/representation relations is arguably internal objects (our own mental states).
Replies from: steve2152↑ comment by Steven Byrnes (steve2152) · 2024-09-26T19:05:56.048Z · LW(p) · GW(p)
I feel like the difference here is that I’m trying to talk about algorithms (self-supervised learning, generative models, probabilistic inference), and you’re trying to talk about philosophy? (See §1.6.2 [LW · GW]). I think there are questions that seem important and tricky in your philosophy-speak, but seem weird or obvious or pointless in my algorithm-speak … Well anyway, here’s my perspective:
Let’s say:
- There’s a real-world thing T (some machine made of atoms),
- T is upstream of some set of sensory inputs S (light reflecting off the machine and hitting photoreceptors etc.)
- There’s a predictive learning algorithm L tasked with predicting S,
- This learning algorithm gradually builds a trained model (a.k.a. generative model space, a.k.a. intuitive model space) M.
In this case, it is often (though not always) the case that some part of M will have a straightforward structural resemblance to T. In §1.3.2 [LW · GW], I called that a “veridical correspondence”.
If that happens, then we know why it happened; it happened because of the learning algorithm L! Obviously, right? Veridical map-territory correspondence is generally a very effective way to predict what’s going to happen, and thus predictive learning algorithms very often build trained models with veridical aspects. (I think the term “teleosemantics” [LW · GW] is relevant here? Not sure.)
By contrast, if some part of M has a straightforward structural resemblence to T, then the hypothesis that this happened by coincidence is astronomically unlikely, compared to the hypothesis that this happened because it’s a good way for L to reduce its loss function.
(Then you say: “Ah, but what if that astronomical coincidence comes to pass?” Well then I would say “Huh. Funny that”, and I would shrug and go on with my day. I never claimed to have an airtight philosophical theory of about-ness or representing-ness or whatever! It was you who brought it up!)
Other times, there isn’t a veridical correspondence! Instead, the predictive learning algorithm builds an M, no part of which has any straightforward structural resemblance to T. There are lots of reasons that could happen. I gave one or two examples of non-veridical things in this post, and much more coming up in Post 3.
But it isn't clear why these thoughts are different. If your thinking about someone is a relation between yourself and someone else, then it isn't clear why you thinking about one person could ever be two different things.
M is some data structure stored in the cortex. If I don’t know that Scott is Yvain, then Scott is one part of M, and Yvain is a different part of M. Two different sets of neurons in the cortex, or whatever. Right? I don’t think I’m saying anything deep here. :)
Replies from: cubefox↑ comment by cubefox · 2024-09-26T20:00:34.606Z · LW(p) · GW(p)
I'm not sure how much "structural resemblance" or "veridical correspondence" can account for representation/reference. Maybe our concept of a sock or an apple somehow (structurally) resembles a sock or an apple. But what if I'm thinking of the content of your suitcase, and I don't know whether it is a sock or an apple or something else? Surely the part of the model (my brain) which represents/refers to the content of your suitcase does not in any way (structurally or otherwise) resemble a sock, even if the content of your suitcase is indeed identical to a sock.
M is some data structure stored in the cortex. If I don’t know that Scott is Yvain, then Scott is one part of M, and Yvain is a different part of M. Two different sets of neurons in the cortex, or whatever. Right? I don’t think I’m saying anything deep here. :)
But Scott and Ivan are an object in the territory, not parts of a model, so the parts of the model which do represent Scott and Yvain require the existence of some sort of representation relation.
Replies from: steve2152↑ comment by Steven Byrnes (steve2152) · 2024-09-26T21:40:33.523Z · LW(p) · GW(p)
Maybe our concept of a sock or an apple somehow (structurally) resembles a sock or an apple.
I could start writing pairs of sentences like:
REAL WORLD: feet often have socks on them
MY INTUITIVE MODELS: “feet” “often” “have” “socks” “on” “them”
REAL WORLD: socks are usually stretchy
MY INTUITIVE MODELS: “socks” “are” “usually” “stretchy”
(… 7000 more things like that …)
If you take all those things, AND the information that all these things wound up in my intuitive models via the process of my brain doing predictive learning from observations of real-world socks over the course of my life, AND the information that my intuitive models of socks tend to activate when I’m looking at actual real-world socks, and to contribute to me successfully predicting what I see … and you mix all that together … then I think we wind up in a place where saying “my intuitive model of socks has by-and-large pretty good veridical correspondence to actual socks” is perfectly obvious common sense. :)
(This is all the same kinds of things I would say if you ask me what makes something a map of London. If it has features that straightforwardly correspond to features of London, and if it was made by someone trying to map London, and if it is actually useful for navigating London in the same kind of way that maps are normally useful, then yeah, that's definitely a map of London. If there's a weird edge case where some of those apply but not others, then OK, it's a weird edge case, and I don't see any point in drawing a sharp line through the thicket of weird edge cases. Just call them edge cases!)
But what if I'm thinking of the content of your suitcase, and I don't know whether it is a sock or an apple or something else? Surely the part of the model (my brain) which represents/refers to the content of your suitcase does not in any way (structurally or otherwise) resemble a sock, even if the content of your suitcase is indeed identical to a sock.
Right, if I don’t know what’s in your suitcase, then there will be rather little veridical correspondence between my intuitive model of the inside of your suitcase, and the actual inside of your suitcase! :)
(The statement “my intuitive model of socks has by-and-large pretty good veridical correspondence to actual socks” does not mean I have omniscient knowledge of every sock on Earth, or that nothing about socks will ever surprise me, etc.!)
But Scott and [Yvain] are an object in the territory, not parts of a model, so the parts of the model which do represent Scott and Yvain require the existence of some sort of representation relation.
Oh sorry, I thought that was clear from context … when I say “Scott is one part of M”, obviously I mean something more like “[the part of my intuitive world-model that I would describe as Scott] is one part of M”. M is a model, i.e. data structure, stored in the cortex. So everything in M is a part of a model by definition.
Replies from: cubefox↑ comment by cubefox · 2024-09-26T23:53:55.641Z · LW(p) · GW(p)
But what if I'm thinking of the content of your suitcase, and I don't know whether it is a sock or an apple or something else? Surely the part of the model (my brain) which represents/refers to the content of your suitcase does not in any way (structurally or otherwise) resemble a sock, even if the content of your suitcase is indeed identical to a sock.
Right, if I don’t know what’s in your suitcase, then there will be rather little veridical correspondence between my intuitive model of the inside of your suitcase, and the actual inside of your suitcase! :)
(The statement “my intuitive model of socks has by-and-large pretty good veridical correspondence to actual socks” does not mean I have omniscient knowledge of every sock on Earth, or that nothing about socks will ever surprise me, etc.!)
Okay, but then this theory doesn't explain how we (or a hypothetical ML model) can in fact successfully refer to / think about things which aren't known more or less directly. Like the contents of the suitcase, the person ringing at the door, the cause of the car failing to start, the reason for birth rate decline, the birthday present, what I had for dinner a week ago, what I will have for dinner tomorrow, the surprise guest, the solution to some equation, the unknown proof of some conjecture, the things I forgot about etc.
Replies from: steve2152↑ comment by Steven Byrnes (steve2152) · 2024-09-27T01:04:07.175Z · LW(p) · GW(p)
What you’re saying is basically: sometimes we know some aspects of a thing, but don’t know other aspects of it. There’s a thing in a suitcase. Well, I know where it is (in the suitcase), and a bit about how big it is (smaller than a bulldozer), and whether it’s tangible versus abstract (tangible). Then there are other things about it that I don’t know, like its color and shape. OK, cool. That’s not unusual—absolutely everything is like that. Even things I’m looking straight at are like that. I don’t know their weight, internal composition, etc.
I don’t need a “theory” to explain how a “hypothetical” learning algorithm can build a generative model that can represent this kind of information in its latent variables, and draw appropriate inferences. It’s not a hypothetical! Any generative model built by a predictive learning algorithm will actually do this—it will pick up on local patterns and extrapolate them, even in the absence of omniscient knowledge of every aspect of the thing / situation. It will draw inferences from the limited information it does have. Trained LLMs do this, and an adult cortex does it too.
I think you’re going wrong by taking “aboutness” to be a bedrock principle of how you’re thinking about things. These predictive learning algorithms and trained models actually exist. If, when you run these algorithms, you wind up with all kinds of edge cases where it’s unclear what is “about” what, (and you do), then that’s a sign that you should not be treating “aboutness” as a bedrock principle in the first place. “Aboutness” is like any other word / category—there are cases where it’s clearly a useful notion, and cases where it’s clearly not, and lots of edge cases in between. The sensible way to deal with edge cases is to use more words to elaborate what’s going on. (“Is chess a sport?” “Well, it’s like a sport in such-and-such respects but it also has so-and-so properties which are not very sport-like.” That’s a good response! No need for philosophizing.)
That’s how I’m using “veridicality” (≈ aboutness) in this series. I defined the term in Post 1 and am using it regularly, because I think there are lots of central cases where it’s clearly useful. There are also plenty of edge cases, and when I hit an edge case, I just use more words to elaborate exactly what’s going on. [Copying from Post 1:] For example, suppose intuitive concept X faithfully captures the behavior of algorithm Y, but X is intuitively conceptualized as a spirit floating in the room, rather than as an algorithm within the Platonic, ethereal realm of algorithms. Well then, I would just say something like: “X has good veridical correspondence to the behavior of algorithm Y, but the spirit- and location-related aspects of X do not veridically correspond to anything at all.” (This is basically a real example—it’s how some “awakened” (Post 6) people talk about what I call conscious awareness in this post.) I think you want “aboutness” to be something more fundamental than that, and I think that you’re wrong to want that.
Replies from: cubefox↑ comment by cubefox · 2024-09-27T02:46:10.226Z · LW(p) · GW(p)
I don’t need a “theory” to explain how a “hypothetical” learning algorithm can build a generative model that can represent this kind of information in its latent variables, and draw appropriate inferences.
Sure, but we would still need a separate explanation if we want to understand how representation/reference works in a model (or in the brain) itself. If we are interested in that, of course. It could be interesting from the standpoint of philosophy of mind, philosophy of language, linguistics, cognitive psychology, and of course machine learning interpretability.
If, when you run these algorithms, you wind up with all kinds of edge cases where it’s unclear what is “about” what, (and you do), then that’s a sign that you should not be treating “aboutness” as a bedrock principle in the first place.
I don't think we did run into any edge cases of representation so far where something partially represents or is partially represented, like chess is partially sport-like. Representation/reference/aboutness doesn't seem a very vague concept. Apparently the difficulty of finding an adequate definition isn't due to vagueness.
That being said, it's clearly not necessary for your theory to cover this topic if you don't find it very interesting and/or you have other objectives.
Replies from: steve2152↑ comment by Steven Byrnes (steve2152) · 2024-09-27T12:56:01.328Z · LW(p) · GW(p)
it's clearly not necessary for your theory to cover this topic if you don't find it very interesting and/or you have other objectives
I’m trying to make a stronger statement than that. I think the kind of theory you’re looking for doesn’t exist. :)
I don't think we did run into any edge cases of representation so far where something partially represents or is partially represented
In this comment [LW(p) · GW(p)] you talked about a scenario where a perfect map of London was created by “an (extremely unlikely) accident”. I think that’s an “edge case of representation”, right? Just as a virus is an edge case of alive-ness. And (I claim) that arguing about whether viruses are “really” alive or not is a waste of time, and likewise arguing whether accidental maps “really” represent London or not is a waste of time too.
Again, a central case of representation would be:
- (A) The map has lots and lots of features that straightforwardly correspond to features of London
- (B) The reason for (A) is that the map was made by an optimization process [LW · GW] that systematically (though imperfectly) tends to lead to (A), e.g. the map was created by a human map-maker who was trying to accurately map London
- (C) The map is in fact useful for navigating London
I claim that if you run a predictive learning algorithm, that’s a valid (B), and we can call the trained generative model a “map”. If we do that…
- You can pick out places where all three of (A-C) are very clearly applicable, and when you find one of those places, you can say that there’s some map-territory correspondence / representation there. Those places are clear-cut central examples, just as a cat is a clear-cut central example of alive-ness.
- There are other bits of the map that clearly don’t correspond to anything in the territory, like a drug-induced hallucinated ghost that the person believes to be really standing in front of them. That’s a clear-cut non-example of map-territory correspondence, just as a rock is a clear-cut non-example of alive-ness.
- And then there are edge cases, like the Gettier problem, or vague impressions, or partially-correct ideas, or hearsay, or vibes, or Scott/Yvain, or latent variables that are somehow helpful for prediction but in a very hard-to-interpret and indirect way, or habits, etc. Those are edge-cases of map-territory correspondence. And arguing about what if anything they’re “really” representing is a waste of time, just as arguing about whether a virus is “really” alive is a waste of time, right? In those cases, I claim that it’s useful to invoke the term “map-territory correspondence” or “representation” as part of a longer description of what’s happening here, but not as a bedrock ground truth that we’re trying to suss out.
↑ comment by cubefox · 2024-09-27T19:20:19.476Z · LW(p) · GW(p)
In this comment you talked about a scenario where a perfect map of London was created by “an (extremely unlikely) accident”. I think that’s an “edge case of representation”, right?
I think it clearly wasn't a case of representation, in the same way a random string clearly doesn't represent anything, nor a cloud that happens to look like something. Those are not edge cases; edge cases are arguably examples where something satisfies a vague predicate partially, like chess being "sporty" to some degree. ("Life" is arguably also vague because it isn't clear whether it requires a metabolism, which isn't present in viruses.)
Again, a central case of representation would be:
(A) The map has lots and lots of features that straightforwardly correspond to features of London
(B) The reason for (A) is that the map was made by an optimization process that systematically (though imperfectly) tends to lead to (A), e.g. the map was created by a human map-maker who was trying to accurately map London
(C) The map is in fact useful for navigating London
I think maps are not overly central cases of representation.
(A) is clearly not at all required for clear cases of representation, e.g. in case of language (abstract symbols) or when a fist is used to represent a gas station, or a stone represents a missing chess piece, etc. That's also again the difference between the sock and the contents of the suitcase. The latter concept doesn't resemble the thing it represents, like a sock, even though it may refer to one.
Regarding (C), representation also doesn't have to be helpful to be representation. A secret message written in code is in fact optimized to be maximally unhelpful to most people, perhaps even to everyone in case of an encrypted diary. And the local explaining the way to the next gas station with the help of his hands clearly means something regardless of whether someone is able to understand what he means. Yes, maps specifically are mostly optimized to be helpful, but that doesn't mean representation has to be helpful. It's similar to portraits: they tend to be optimized for representing someone, resembling someone, and for being aesthetically pleasing. Which doesn't mean representation itself requires resemblance or aesthetics.
I agree that something like (B) might be a defining feature of representation, but not quite. Some form of optimization seems to be necessary (randomly created things don't represent anything), but optimization for (A) (resemblance) is necessary only for things like maps or pictures, but not for other forms of representation, as I argued above.
And then there are edge cases, like the Gettier problem, or vague impressions, or partially-correct ideas, or hearsay, or vibes, or Scott/Yvain, or latent variables that are somehow helpful for prediction but in a very hard-to-interpret and indirect way, or habits, etc. Those are edge-cases of map-territory correspondence. And arguing about what if anything they’re “really” representing is a waste of time, just as arguing about whether a virus is “really” alive is a waste of time.
The Gettier problem is a good illustration of what I think is the misunderstanding here: Gettier cases are not supposed to be edge cases of knowledge. Just like the randomly created string "Eliezer Yudkowsky" is not an edge case of representation. Edge cases have to do with vagueness, but the problem with defining knowledge is not that the concept may be vague. Gettier cases are examples where justified true belief is intuitively present but knowledge is intuitively absent. Not partially present like in edge cases. That is, we would apply the first terms (justification, truth, belief) but not the latter (knowledge). Vagueness itself is often not a problem for definition. A bachelor is clearly an unmarried man, but what may count as marriage, and what separates men from boys, is a matter of degree, and so too must be bachelor status.
Now you may still think that finding something like necessary and sufficient conditions for representation is still "a waste of time" even if vagueness is not the issue. But wouldn't that, for example, also apply to your attempted explication of "intention"? Or "awareness"? In my opinion, all those concepts are interesting and benefit from analysis.
Replies from: steve2152↑ comment by Steven Byrnes (steve2152) · 2024-09-28T16:11:29.342Z · LW(p) · GW(p)
Back to the Scott / Yvain thing, suppose that I open Google Maps and find that there are two listings for the same restaurant location, one labeled KFC, the other labeled Kentucky Fried Chicken. What do we learn from that?
- (X) The common-sense answer is: there’s some function in the Google Maps codebase such that, when someone submits a restaurant entry, it checks if it’s a duplicate before officially adding it. Let’s say the function is
check_if_dupe(). And this code evidently had a false negative when someone submitted KFC. Hey, let’s dive into the implementation ofcheck_if_dupe()to understand why there was a false negative! … - (Y) The philosophizing answer is: This observation implies something deep and profound about the nature of Representation! :)
Maybe I’m being too harsh on the philosophizing answer (here and in earlier comments); I’ll do the best I can to steelman it now.
- (Y’) We almost always use language in a casual way, but sometimes it’s useful to have some term with a precise universal necessary-and-sufficient definition that can be unambiguously applied to any conceivable situation. (Certainly it would be hard to do math without those kinds of definitions!) And if we want to give the word “Representation” this kind of precise universal definition, then that definition had better be able to deal with this KFC situation.
Anyway, (Y’) is fine, but we need to be clear that we’re not learning anything about the world by doing that activity. At best, it’s a means to an end. Answering (Y) or (Y’) will not give any insight into the straightforward (X) question of why check_if_dupe() returned a false negative. (Nor vice-versa.) I think this is how we’re talking past each other. I suspect that you’re too focused on (Y) or (Y’) because you expect them to answer all our questions including (X), when it’s obvious (in this KFC case) that they won’t, right? I’m putting words in your mouth; feel free to disagree.
(…But that was my interpretation of a few comments ago where I was trying [LW(p) · GW(p)] to chat about the implementation of check_if_dupe() in the human cortex as a path to answering your “failure of identification” question, and your response [LW(p) · GW(p)] seemed to fundamentally reject that whole way of thinking about things.)
Nowhere in this series do I purport to offer any precise universal necessary-and-sufficient definition that can be applied to any conceivable situation, for any word at all, not “Awareness”, not “Intention”, not anything. It’s just not an activity I’m generally enthusiastic about. You can be the world-leading expert on socks without having a precise universal necessary-and-sufficient definition of what constitutes a sock. Likewise, if there’s a map of London made by an astronomically-unlikely coincidence, and you say it’s not a Representation of London, and I say yes it is a Representation of London, then we’re not disagreeing about anything substantive. We have the same understanding of the situation but a different definition of the word Representation. Does that matter? Sure, a little bit. Maybe your definition of Representation is better, all things considered—maybe it’s more useful for explaining certain things, maybe it better aligns with preexisting intuitions, whatever. But still, it’s just terminology, not substance. We can always just split the term Representation into “Representation_per_cubefox” and “Representation_per_Steve” and then suddenly we’re not disagreeing about anything at all. Or better yet, we can agree to use the word Representation in the obvious central cases where everybody agrees that this term is applicable, and to use multi-word phrases and sentences and analogies to provide nuance in cases where that’s helpful. In other words: the normal way that people communicate all the time! :)
Replies from: cubefox↑ comment by cubefox · 2024-10-03T15:12:50.484Z · LW(p) · GW(p)
I don't understand the relevance of the Google Maps example and the emphasis you place on the "check_if_dupe()" function for understanding what "representation" is.
I think my previous explanation of why we can always know the identity of internal objects (to stick with a software analogy: whether two variables refer to the same memory location) but not always the identity of external objects, since there is no full access to those objects. Which is why the function can make mistakes. However, this is not an analysis of representation.
Nowhere in this series do I purport to offer any precise universal necessary-and-sufficient definition that can be applied to any conceivable situation, for any word at all, not “Awareness”, not “Intention”, not anything.
And you don't even aim for a good definition? For what do you aim then?
You can be the world-leading expert on socks without having a precise universal necessary-and-sufficient definition of what constitutes a sock.
I think if I'm doing a priori armchair reasoning on socks, the way you and I do armchair reasoning here, I'm pretty much constrained to conceptual analysis. Which is the activity of finding necessary and sufficient conditions for a concept.
Likewise, if there’s a map of London made by an astronomically-unlikely coincidence, and you say it’s not a Representation of London, and I say yes it is a Representation of London, then we’re not disagreeing about anything substantive.
Yes. But are you even disagreeing with me on this map example here? If so, do you disagree with the cases of clouds, fists, random strings etc? In philosophy the issue is rarely the disagreement over what a term means (because then we could simply infer that the term is ambiguous, and the case is closed), rather, the problem is finding a definition for a term where everyone already agrees on what it means. Like knowledge, causation, explanation, evidence, probability, truth etc.
Replies from: steve2152↑ comment by Steven Byrnes (steve2152) · 2024-10-03T15:53:23.336Z · LW(p) · GW(p)
And you don't even aim for a good definition? For what do you aim then? … I think if I'm doing a priori armchair reasoning on socks, the way you and I do armchair reasoning here, I'm pretty much constrained to conceptual analysis. Which is activity of finding necessary and sufficient conditions for a concept.
The goal of this series is to explain how certain observable facts about the physical universe arise from more basic principles of physics, neuroscience, algorithms, etc. See §1.6 [LW · GW].
I’m not sure what you mean by “armchair reasoning”. When Einstein invented the theory of General Relativity, was he doing “armchair reasoning”? Well, yes in the sense that he was reasoning, and for all I know he was literally sitting in an armchair while doing it. :) But what he was doing was not “constrained to conceptual analysis”, right?
As a more specific example, one thing that happens a lot in this series is: I describe some algorithm, and then I talk about what happens when you run that algorithm. Those things that the algorithm winds up doing are often not immediately obvious just from looking at the algorithm pseudocode by itself. But they make sense once you spend some time thinking it through. This is the kind of activity that people frequently do in algorithms classes, and it overlaps with math, and I don’t think of it as being related to philosophy or “conceptual analysis” or “a priori armchair reasoning”.
In this case, the algorithm in question happens to be implemented by neurons and synapses in the human brain (I claim). And thus by understanding the algorithm and what it does when you run it, we wind up with new insights into human behavior and beliefs.
Does that help?
are you even disagreeing with me on this map example here
Yes I am disagreeing. If there’s a perfect map of London made by an astronomically-unlikely coincidence, and someone asks whether it’s a “representation” of London, then your answer is “definitely no” and my answer is “Maybe? I dunno. I don’t understand what you’re asking. Can you please taboo the word ‘representation’ [? · GW] and ask it again?” :-P
Replies from: cubefox↑ comment by cubefox · 2024-10-03T16:45:02.966Z · LW(p) · GW(p)
Einstein (scientists in general) tried to explain empirical observations. The point of conceptual analysis, in contrast, is to analyze general concepts, to answer "What is X?" questions, where X is a general term. I thought your post fit more in the conceptual analysis direction rather than in an empirical one, since it seems focused on concepts rather than observations.
One way to distinguish the two is by what they consider counterexamples. In science, a counterexample is an observation which contradicts a prediction of the proposed explanation. In conceptual analysis, a counterexample is a thought experiment (like a Gettier case or the string example above) to which the proposed definition (the definiens) intuitively applies but the defined term (the definiendum) doesn't, or the other way round.
The algorithm analysis method arguably doesn't really fit here, since it requires access to the algorithm, which isn't available in case of the brain. (Unless I misunderstood the method and it treats algorithms actually as black boxes while only looking at input/output examples. But then it wouldn't be so different from conceptual analysis, where a thought experiment is the input, and an intuitive application of a term the output.)
are you even disagreeing with me on this map example here
Yes I am disagreeing. If there’s a perfect map of London made by an astronomically-unlikely coincidence, and someone asks whether it’s a “representation” of London, then your answer is “definitely no” and my answer is “Maybe? I dunno. I don’t understand your question.
But I assume you do agree that random strings don't refer to anyone, that clouds don't represent anyone they accidentally resemble, that a fist by itself doesn't represent anything etc. An accidentally created map seems to be the same kind of case, just vastly less likely. So treating them differently doesn't seem very coherent.
Can you please taboo the word ‘representation’ and ask it again?” :-P
Well... That's hardly possible when analysing the concept of representation, since this is just the meaning of the word "represents". Of course nobody is forcing you to do it when you find it pointless, which is okay.
Replies from: steve2152↑ comment by Steven Byrnes (steve2152) · 2024-10-03T17:22:17.646Z · LW(p) · GW(p)
Of course nobody is forcing you to do it when you find it pointless, which is okay.
Yup! :) :)
The algorithm analysis method arguably doesn't really fit here, since it requires access to the algorithm, which isn't available in case of the brain.
Oh I have lots and lots of opinions about what algorithms are running in the brain. See my many dozens of blog posts about neuroscience. Post 1 has some of the core pieces: I think there’s a predictive (a.k.a. self-supervised) learning algorithm, that the trained model (a.k.a. generative model space) for that learning algorithm winds up stored in the cortex, and that the generative model space is continually queried in real time by a process that amounts to probabilistic inference. Those are the most basic things, but there’s a ton of other bits and pieces that I introduce throughout the series as needed, things like how “valence” fits into that algorithm [LW · GW], how “valence” is updated by supervised learning and temporal difference learning, how interoception fits into that algorithm, how certain innate brainstem reactions fit into that algorithm, how various types of attention fit into that algorithm … on and on.
Of course, you don’t have to agree! There is never a neuroscience consensus. Some of my opinions about brain algorithms are close to neuroscience consensus, others much less so. But if I make some claim about brain algorithms that seems false, you’re welcome to question it, and I can explain why I believe it. :)
…Or separately, if you’re suggesting that the only way to learn about what an algorithm will do when you run it, is to actually run it on an actual computer, then I strongly disagree. It’s perfectly possible to just write down pseudocode, think for a bit, and conclude non-obvious things about what that pseudocode would do if you were to run it. Smart people can reach consensus on those kinds of questions, without ever running the code. It’s basically math—not so different from the fact that mathematicians are perfectly capable of reaching consensus about math claims without relying on the computer-verified formal proofs as ground truth. Right?
As an example, “the locker problem” is basically describing an algorithm, and asking what happens when you run that algorithm. That question is readily solvable without running any code on a computer, and indeed it would be perfectly reasonable to find that problem on a math test where you don’t even have computer access. Does that help? Or sorry if I’m misunderstanding your point.
comment by Rafael Harth (sil-ver) · 2024-09-27T10:38:28.762Z · LW(p) · GW(p)
…But interestingly, if I then immediately ask you what you were experiencing just now, you won’t describe it as above. Instead you’ll say that you were hearing “sm-” at t=0 and “-mi” at t=0.2 and “-ile” at t=0.4. In other words, you’ll recall it in terms of the time-course of the generative model that ultimately turned out to be the best explanation.
In my review of Dennett's book [? · GW], I argued that this doesn't disprove the "there's a well-defined stream of consciousness" hypothesis since it could be the case that memory is overwritten (i.e., you first hear "sm" not realizing what you're hearing, but then when you hear "smile", your brain deletes that part from memory).
Since then I've gotten more cynical and would now argue that there's nothing to explain because there are no proper examples of revisionist memory.[1] Because here's the thing -- I agree that if you ask someone what they experience, they're probably going to respond as you say in the quote. Because they're not going to think much about it, and this is just the most natural thing to reply. But do you actually remember understanding "sm" at the point when you first heard it? Because I don't. If I think about what happened after the fact, I have a subtle sensation of understand the word, and I can vaguely recall that I've heard a sound at the beginning of the word, but I don't remember being able to place what it is at the time.
I've just tried to introspect on this listening to an audio conversation, and yeah, I don't have any such memories. I also tried it with slowed audio. I guess reply here if anyone thinks they genuinely misremember this if they pay attention.
The color phi phenomenon doesn't work for or anyone I've asked so at this point my assumption is that it's just not a real result (kudos for not relying on it here). I think Dennett's book is full of terrible epistemology so I'm surprised that he's included it anyway. ↩︎
↑ comment by Steven Byrnes (steve2152) · 2024-09-27T14:04:05.257Z · LW(p) · GW(p)
The color phi phenomenon doesn't work for or anyone I've asked
Were you using this demo? If so, I set the times to 1000,30,60, demagnified as much as possible, and then stood 20 feet away from my computer to “demagnify” even more. I might have also moved the dots a bit closer. I think I got some motion illusion?
I’m skeptical of the hypothesis that the color phi phenomenon is just BS. It doesn’t seem like that kind of psych result. I think it’s more likely that this applet is terribly designed.
Replies from: sil-ver↑ comment by Rafael Harth (sil-ver) · 2024-09-27T16:47:25.615Z · LW(p) · GW(p)
Were you using this demo?
I’m skeptical of the hypothesis that the color phi phenomenon is just BS. It doesn’t seem like that kind of psych result. I think it’s more likely that this applet is terribly designed.
Yes -- and yeah, fair enough. Although-
I think I got some motion illusion?
-remember that the question isn't "did I get the vibe that something moves". We already know that a series of frames gives the vibe that something moves. The question is whether you remember having seen the red circle halfway across before seeing the blue circle.
↑ comment by Steven Byrnes (steve2152) · 2024-09-27T13:54:47.578Z · LW(p) · GW(p)
Take any intuitive notion X, where people’s intuitions are generally a bit incoherent or poorly-thought-through—stream of consciousness, free will, divine grace, the voice in my head, etc.
- (A) One thing you can say is: “X, when properly understood, is coherent, and here’s how to properly understand it …”
- (B) Another you can say is: “X, as commonly understood by the average person, is incoherent, but hey let me tell you about these closely related concepts which are coherent and which rescue some or all of those intuitions about X that you find compelling …”
Fundamentally, neither of these strategies is right or wrong. You say tomato, I say to-mah-to. :)
This is one of many causes of those annoying debates that go around in circles, that I’m trying to declare out-of-scope for this series, cf. §1.6.2 [LW · GW]. :)
For science terminology like “acceleration”, we take approach (A). People often have incoherent intuitions about acceleration, and when they do, we prompt them to discard their “wrong” intuitions, leaving the “real” acceleration concept.
For more everyday terminology, (A) versus (B) is more of a judgment call—for example, some physicalists say “‘God’ doesn’t exist”, others say “‘God’ is just the term for order and beauty in the universe” or whatever. As another example, I read Elbow Room recently, and Dennett’s revised preface says that he’s taken approach (A) to “free will” for his whole career, but now he’s thinking that maybe all along he should have taken the (B) path and said “free will (as commonly understood) doesn’t exist”.
Anyway, I feel like my post section is pointing out that people’s everyday poorly-thought-through intuitions about “stream of consciousness” are a bit incoherent, but I didn’t go further than that by advocating for either (A) or (B). Whereas your comment is advocating for the (A) path, where we prod people to update their intuitions about what happens when they try to remember what happened one second ago.
Replies from: sil-ver↑ comment by Rafael Harth (sil-ver) · 2024-09-27T16:42:15.454Z · LW(p) · GW(p)
I don't think I agree with this framing. I wasn't trying to say "people need to rethink their concept of awareness"; I was saying "you haven't actually demonstrated that there is anything wrong with the naive concept of awareness because the counterexample isn't a proper counterexample".
I mean I've conceded that people will give this intuitive answer, but only because they'll respond before they've actually run the experiment you suggest. I'm saying that as soon as you (generic you) actually do the thing the post suggested (i.e., look at what you remember at the point in time where you heard the first syllable of a word that you don't yet recognize), you'll notice that you do not, in fact, remember hearing & understanding the first part of the word. This doesn't entail a shift in the understanding of awareness. People can view awareness exactly like they did before, I just want them to actually run the experiment before answering!
(And also this seems like a pretty conceptually straight-forward case -- the overarching question is basically, "is there a specific data structure in the brain whose state corresponds to people's experience at every point in time" -- which I think captures the naive view of awareness -- and I'm saying "the example doesn't show that the answer is no".)
comment by stormykat (sandypawbs) · 2025-01-29T23:18:51.406Z · LW(p) · GW(p)
I love this series very much and I thank you for writing all of this. There's a lot I could ask or say about this but specifically there's a line of thought right now I want to query you on (I might message you more on other topics later if that's okay this series has sparked a lot of thought in me). Apologies if I use bad or unclear language I'm very well informed on the philosophy, not quite so much on the hard science.
I am very interested in this concept of awareness (because of my own interest in phenomenal consciousness). In the previous article, you say that:
every vertebrate, and presumably many invertebrates too, are also active agents with predictive learning algorithms in their brain, and hence their predictive learning algorithms are also incentivized to build intuitive self-models
This is a bit random but its relevant for my own ideas that I'm developing. Do you think making predictions about your own predictive algorithms is something that requires recurrent processing (as in feedback from higher processing layers onto lower ones)? I'm asking this because it actually seems like fish for instance, as well octopuses, have pretty much entirely feed-forward brains, so it seems dubious to me that they could model themselves as having awareness (or even model their own algorithm at all) unless I'm misunderstanding how this works on an algorithmic level.
If I'm right and this means they probably can't model their own algorithm, this would probably imply everything 'below' reptiles at the least lacks the ability to do this as well (and thus lacks the ability to model itself as having awareness).
Replies from: steve2152↑ comment by Steven Byrnes (steve2152) · 2025-01-30T15:05:12.882Z · LW(p) · GW(p)
Like I said in this post, I think the contents of conscious awareness corresponds more-or-less to what’s happening in the cortex. The homolog to the cortex in non-mammal vertebrates is called the “pallium”, and the pallium along with the striatum and a few other odds and ends comprises the “telencephalon”.
I don’t know anything about octopuses, but I would very surprised if the fish pallium lacked recurrent connections. I don’t think your link says that though. The relevant part seems to be:
While the fish retina projects diffusely to nine nuclei in the diencephalon, its main
target is the midbrain optic tectum (Burrill and Easter, 1994). Thus, the fish visual system
is highly parcellated, at least, in the sub-telencephalonic regions. Whole brain imaging
during visuomotor reflexes reveals widespread neural activity in the diencephalon,
midbrain and hindbrain in zebrafish, but these regions appear to act mostly as
feedforward pathways (Sarvestani et al., 2013; Kubo et al., 2014; Portugues et al., 2014).
When recurrent feedback is present (e.g., in the brainstem circuitry responsible for eye
movement), it is weak and usually arises only from the next nucleus within a linear
hierarchical circuit (Joshua and Lisberger, 2014). In conclusion, fish lack the strong
reciprocal and networked circuitry required for conscious neural processing.
This passage is just about the “sub-telencephalonic regions”, i.e. they’re not talking about the pallium.
To be clear, the stuff happening in sub-telencephalonic regions (e.g. the brainstem) is often relevant to consciousness, of course, even if it’s not itself part of consciousness. One reason is because stuff happening in the brainstem can turn into interoceptive sensory inputs to the pallium / cortex. Another reason is that stuff happening in the brainstem can directly mess with what’s happening in the pallium / cortex in other ways besides serving as sensory inputs. One example is (what I call) the valence signal [LW · GW] which can make conscious thoughts either stay or go away. Another is (what I call) “involuntary attention” [LW · GW].
Replies from: sandypawbs, sandypawbs↑ comment by stormykat (sandypawbs) · 2025-02-02T23:41:56.637Z · LW(p) · GW(p)
Oh and sorry just to be clear, does this mean you do think that recurrent connections in the cortex are essential for forming intuitive self-models / the algorithm modelling properties of itself?
Replies from: steve2152↑ comment by Steven Byrnes (steve2152) · 2025-02-03T13:30:57.150Z · LW(p) · GW(p)
Umm, I would phrase it as: there’s a particular computational task called approximate Bayesian probabilistic inference, and I think the cortex / pallium performs that task (among others) in vertebrates, and I don’t think it’s possible for biological neurons to perform that task without lots of recurrent connections.
And if there’s an organism that doesn’t perform that task at all, then it would have neither an intuitive self-model nor an intuitive model of anything else, at least not in any sense that’s analogous to ours and that I know how to think about.
To be clear: (1) I think you can have some brain region with lots of recurrent connections that has nothing to do with intuitive modeling, (2) it’s possible for a brain region to perform approximate Bayesian probabilistic inference and have recurrent connections, but still not have an intuitive self-model, for example if the hypothesis space is closer to a simple lookup table rather than a complicated hypothesis space involving complex compositional interacting entities etc.
↑ comment by stormykat (sandypawbs) · 2025-02-02T23:38:32.954Z · LW(p) · GW(p)
Thank you for the response! I am embarrassed that I didn't realise that the lack of recurrent connections referenced in the sources were referring to regions outside of their cortex-equivalent, should've read through more thoroughly :) I am pretty up-to-date in terms of those things.
Can I additionally ask why do you think some invertebrates likely have intuitive self models as well? Would you restrict this possibility to basically just cephalopods and the like (as many do, being the most intelligent invertebrates), or would you likely extend to it to creatures like arthropods as well? (what's your fuzzy estimate that an ant could model itself as having awareness?)
Replies from: steve2152, sandypawbs↑ comment by Steven Byrnes (steve2152) · 2025-02-03T13:45:04.235Z · LW(p) · GW(p)
why do you think some invertebrates likely have intuitive self models as well?
I didn’t quite say that. I made a weaker claim that “presumably many invertebrates [are] active agents with predictive learning algorithms in their brain, and hence their predictive learning algorithms are…incentivized to build intuitive self-models”.
It seems reasonable to presume that octopuses have predictive learning algorithms in their nervous systems, because AFAIK that’s the only practical way to wind up with a flexible and forward-looking understanding of the consequences of your actions, and octopuses (at least) are clearly able to plan ahead in a flexible way.
However, “incentivized to build intuitive self-models” does not necessarily imply “does in fact build intuitive self-models”. As I wrote in §1.4.1, just because a learning algorithm is incentivized to capture some pattern in its input data, doesn’t mean it actually will succeed in doing so.
Would you restrict this possibility to basically just cephalopods and the like
No opinion.
Replies from: sandypawbs↑ comment by stormykat (sandypawbs) · 2025-02-03T21:53:07.428Z · LW(p) · GW(p)
“incentivized to build intuitive self-models” does not necessarily imply “does in fact build intuitive self-models”. As I wrote in §1.4.1, just because a learning algorithm is incentivized to capture some pattern in its input data, doesn’t mean it actually will succeed in doing so.
Right of course. So would this imply that organisms that have very simple brains / roles in their environment (for example: not needing to end up with a flexible understanding of the consequences of your actions), would have a very weak incentive too?
And if an intuitive self model helps with things like flexible planning then even though its a creation of the 'blank-slate' cortex, surely some organisms would have a genome that sets up certain hyperparameters that would encourage it no, since it would seem strange for something pretty seriously adaptive being purely an 'epiphenomenon' (as per language being facilitated by hyperparameters encoded in the genome)? But also its fine if you also just don't have an opinion on this haha. (also: wouldn't some animals not have an incentive to create self-models if creating a self-model would not seriously increase performance in any relevant domain? Like a dog trying to create an in-depth model of the patterns that appear on computer monitors maybe)
It does seem like flexible behaviour in some general sense is perfectly possible without awareness (as I'm sure you know) but I understand that awareness would surely help a whole lot.
You might have no opinion on this at all but would you have any vague guess at all as to why you can only verbally report items in awareness? (cause even if awareness is a model of serial processing and verbal report requires that kind of global projection / high state of attention, I've still seen studies showing that stimuli can be globally accessible / globally projected in the brain and yet still not consciously accessible, presumably in your model due to a lack of modelling of that global-access)
↑ comment by stormykat (sandypawbs) · 2025-02-03T02:42:50.297Z · LW(p) · GW(p)
Or no sorry I've gone back over the papers and I'm still a bit confused.
Brian Key seems to specifically claim fish and octopuses cannot feel pain in reference to the recurrent connections of their pallium (+ the octopus equivalent which seems to be the supraesophageal complex).
fish also lack a laminated and columnar organization of neural regions that are strongly interconnected by reciprocal feedforward and feedback circuitry [...] Although the medial pallium is weakly homologous to the mammalian amygdala, these structures principally possess feedforward circuits that execute nociceptive defensive behaviours
However he then also claims
This conclusion is supported by lesion studies that have shown that neither the medial pallium nor the whole pallium is required for escape behaviours from electric shock stimuli in fish (Portavella et al., 2004). Therefore, given that the pallium is not even involved in nociceptive behaviours, it could not be inferred that it plays a role in pain.
Which seems a little silly for me because I'm fairly certain humans without a cortex also show nociceptive behaviours?
Which makes me think his claim (in regards to fish consciousness at least) is really just that the feedback circuitry required for the brain to make predictions on its own algorithm (and thus become subjectively aware) just isn't strong enough / is too minimal? He does source a pretty vast amount of information to try and justify this, so much I haven't meaningfully made a start on it yet, its pretty overwhelming. Overall I just feel more uncertain.
I've gone back over his paper on octopuses with my increased understanding and he specifically seems to make reference to a lack of feedback connections between lobes (not just subesophageal lobes). Specifically he seems to focus on the fact that the posterior buccal lobe (which is supraesophageal) has 'no second-order sensory fibres (that) subsequently project from the brachial lobe to the inferior frontal system' meaning 'it lacks the ability to feedback prediction errors to these lobes so as to regulate their models'. I honestly don't know if this places doubt on the ability of octopuses to make intuitive self-models or not in your theory, since I suppose it would depend on the information contained in the posterior buccal lobe, and what recurrent connections exist between the other supraesophageal lobes. Figure 2 has a wiring diagram for a system in the supraesophageal brain as well as a general overview of brain circuity in processing noxious stimuli in figure 7, I would be very interested in trying to understand through what connection the octopus (or even the fish) could plausibly gain information it could use to make predictions about its own algorithm.
I might be totally off on this, but to make a prediction about something like a state of attention / cortical seriality would surely require feedback connections from the output higher level areas where the algorithm is doing 'thinking' to earlier layers, given that for one awareness of a stimuli seems to allow greater control of attention directed towards that stimuli, meaning the idea of awareness must have some sort of top-down influence on the visual cortex no?
This makes me wonder, is it higher layers of the cortex that actually generate the predictive model of awareness, or is the local regions that predictive the awareness concept due to feedback from the higher levels? I'm trying to construct some diagram in my head by which the brain models its own algorithm but I'm a bit confused I think.
You are not obliged to give any in-depth response to this I've just become interested especially due to the similarities between your model and Key's and yet the serious potential ethical consequences of the differences.
Replies from: steve2152↑ comment by Steven Byrnes (steve2152) · 2025-02-03T13:59:34.468Z · LW(p) · GW(p)
fish also lack a laminated and columnar organization of neural regions that are strongly interconnected by reciprocal feedforward and feedback circuitry
Yeah that doesn’t mean much in itself: “Laminated and columnar” is how the neurons are arranged in space, but what matters algorithmically is how they’re connected. The bird pallium is neither laminated nor columnar, but is AFAICT functionally equivalent to a mammal cortex.
Which seems a little silly for me because I'm fairly certain humans without a cortex also show nociceptive behaviours?
My opinion (which is outside the scope of this series) is: (1) mammals without a cortex are not conscious, and (2) mammals without a cortex show nociceptive behaviors, and (3) nociceptive behaviors are not in themselves proof of “feeling pain” in the sense of consciousness. Argument for (3): You can also make a very simple mechanical mechanism (e.g. a bimetallic strip attached to a mousetrap-type mechanism) that quickly “recoils” from touching hot surfaces, but it seems pretty implausible that this mechanical mechanism “feels pain”.
(I think we’re in agreement on this?)
~~
I know nothing about octopus nervous systems and am not currently planning to learn, sorry.
Replies from: sandypawbs↑ comment by stormykat (sandypawbs) · 2025-02-03T21:18:16.551Z · LW(p) · GW(p)
what matters algorithmically is how they’re connected
I just realised that quote didn't meant what I thought it did. But yes I do understand this and Key seems to think the recurrent connections just aren't strong (they are 'diffusely interconnected'. but whether this means they have an intuitive self model or not honestly who knows, do you have any ideas of how you'd test it? maybe like Graziano does with attentional control?)
(I think we’re in agreement on this?)
Oh yes definitely.
I know nothing about octopus nervous systems and am not currently planning to learn, sorry.
Heheh that's alright I wasn't expecting you too thanks for thinking about it for a moment anyway. I will simply have to learn myself.
comment by Gunnar_Zarncke · 2024-10-23T14:42:56.453Z · LW(p) · GW(p)
I want to comment on the interpretation of S(A) as an "intention" to do A.
Note that I'm coming back here from section 6. Awakening / Enlightenment / PNSE [LW · GW], so if somebody hasn't read that, this might be unclear.
Using the terminology above, A here is "the patterns of motor control and attention control outputs that would does collectively make my muscles actually execute the standing-up action."
And S(A) is "the patterns of motor control and attention control outputs that would does collectively make my muscles actually execute the standing-up action are in my awareness." Meaning a representation of "awareness" is active together with the container-relationship and a representation of A. (I am still very unsure about how "awareness" is learned and represented.)[1]
Referring to 2.6.2, I agree with this:
[S(A) and A] are obviously strongly associated with each other. They can activate simultaneously. And even if they don’t, each tends to bring the other to mind, such that the valence of one influences the valence of the other.
and
For any action A where S(A) has positive valence, there’s often a two-step temporal sequence: [S(A) ; A actually happens]"
I agree that in this co-occurence sense "S(X) often summons a follow-on thought of X." But it is not causing it, what "summon" might imply. This choice of word is maybe an indication of the uncertainty here.
Clearly, action A can happen without S(A) being present. In fact, actions are often more effectively executed if you don't think too hard about them[citation needed]. An S(A) is not required. Maybe S(A) and A cooccur often, but that doesn't imply causality. But, indeed, it would seem to be causal in the context of a homunculus model of action. Treating it as causal/vitalistic is predictive. The real reason is the co-occurrence of the thoughts, which can have a common cause, such as when the S(A) thought brings up additional associations that lead to higher valence thoughts/actions later (e.g., chains of S(A), A, S(A)->S(B), B).
Thus, S(A) isn't really an "Intention to do A" per se but just as it says on the tin: "awareness of (expecting) A." I would say it is only an "intention to do A" if the thought S(A) also includes the concept of intention - which is a concept tied to the homunculus and an intuitive model of agency.
- ^
I am still very unsure about how "awareness" is learned and represented. Above it says
the cortex, which has a limited computational capacity that gets deployed serially [...] When this aspect of the brain algorithm is itself incorporated into a generative model via predictive (a.k.a. self-supervised) learning, it winds up represented as an “awareness” concept,
but this doesn't say how. The brain needs to observe something (sense, interoception) from which it can infer this. The pattern in what observations would that be? The serial processing is a property the brain can't observe unless there is some way to combine/compare past and present "thoughts." That's why I have long thought that there has to be a feedback from the current thought back as input signal (thoughts as observations). Such a connection is not present in the brain-like model [? · GW], but it might not be the only way. Another way would be via memory. If a thought is remembered, then one way of implementing memory would be to provide a representation of the remembered thought as input. In any case, there must be a relation between successive thoughts, otherwise they couldn't influence each other.
It seems plausible that, in a sequence of events, awareness S(A) is a related to a pattern of A having occurred previously in the sequence (or being expected to occur).
↑ comment by Steven Byrnes (steve2152) · 2024-10-24T13:34:45.416Z · LW(p) · GW(p)
The brain needs to observe something (sense, interoception) from which it can infer this. The pattern in what observations would that be?
(partly copying from my other comment [LW(p) · GW(p)]) For example, consider the following fact.
FACT: Sometimes, I’m thinking about pencils. Other times, I’m not thinking about pencils.
Now imagine that there’s a predictive (a.k.a. self-supervised) learning algorithm which is tasked with predicting upcoming sensory inputs, by building generative models. The above fact is very important! If the predictive learning algorithm does not somehow incorporate that fact into its generative models, then those generative models will be worse at making predictions. For example, if I’m thinking about pencils, then I’m likelier to talk about pencils, and look at pencils, and grab a pencil, etc., compared to if I’m not thinking about pencils. So the predictive learning algorithm is incentivized (by its predictive loss function) to build a generative model that can represent the fact that any given concept might be active in the cortex at a certain time, or might not be.
That's why I have long thought that there has to be a feedback from the current thought back as input signal (thoughts as observations). Such a connection is not present in the brain-like model [? · GW], but it might not be the only way. Another way would be via memory.
I mean yeah obviously the cortex has various types of memory, and this fact is important for all kinds of things. :)
Clearly, action A can happen without S(A) being present. In fact, actions are often more effectively executed if you don't think too hard about them[citation needed]. An S(A) is not required. Maybe S(A) and A cooccur often, but that doesn't imply causality.
These sentences seem to suggest that either A’s are either always, or never, caused by a preceding S(A), and out of those two options, “never” is more plausible. But that’s a false dichotomy. I propose that sometimes they are and sometimes they aren’t caused by S(A).
By analogy, sometimes doors open because somebody pushed on them, and sometimes doors open without anyone pushing on them. Also, it’s possible for there to be a very windy day where the door would open with 30% probability in the absence of a person pushing on it, but opens with 85% probability if somebody does push on it. In that case, did the person “cause” the door to open? I would say yeah, they “partially caused it” to open, or “causally contributed to” the door opening, or “often cause the door to open”, or something like that. I stand by my claim that the self-reflective S(standing up), if sufficiently motivating, can “cause” me to then stand up, in that sense.
The fact that “actions are often more effectively executed if you don't think too hard about them” is referring to the fact that if you have a learned skill, in the form of some optimized context-dependent temporal sequence of motor-control and attention-control commands, then self-reflective thoughts can interrupt and thus mess up that temporal sequence, just as people shouting random numbers can disrupt someone trying to count, or how you can’t sing two songs in your head simultaneously. A.k.a. the limited capacity of cortex processing. Whereas that section is more about whether some course-of-action (like saying something, wiggling your fingers, standing up, etc.) starts or not.
Flow states (post 4) are a great example of A’s happening without any S(A).
Replies from: Gunnar_Zarncke↑ comment by Gunnar_Zarncke · 2024-10-24T21:03:52.817Z · LW(p) · GW(p)
You give the example of the door that is sometimes pushed open, but let me give alternative analogies:
- S(A): Forecaster: "The stock price of XYZ will rise tomorrow." A: XYZ's stock rises the next day.
- S(A): Drill sergeat, "There will be exercises at 14:00 hours." A: Military units start their exercises at the designated time.
- S(A): Live commentator: "The rocket is leaving the launch pad." A: A rocket launches from the ground.
Clearly, there is a reason for the co-occurrence, but it is not one causing the other. And it is useful to have the forecaster because making the prediction salient helps improve predictions. Making the drill time salient improves punctuality or routine or something. Not sure what the benefit of the rocket launch commentary is.
Otherwise I think we agree.
Replies from: steve2152↑ comment by Steven Byrnes (steve2152) · 2024-10-25T00:54:15.759Z · LW(p) · GW(p)
I agree that there is such a thing as two things occurring in sequence where the first doesn’t cause the second. But I don’t think this is one of those cases. Instead, I think there are strong reasons to believe that if S(A) is active and has positive valence, then that causally contributes to A tending to happen afterwards.
For example, if A = stepping into the ice-cold shower, then the object-level idea of A is probably generally negative-valence—it will feel unpleasant. But then S(A) is the self-reflective idea of myself stepping into the shower, and relatedly how stepping into the shower fits into my self-image and the narrative of my life etc., and so S(A) is positive valence.
I won’t necessarily wind up stepping into the shower (maybe I’ll chicken out), but if I do, then the main reason why I do is the fact that the S(A) thought was active in my mind immediately beforehand, and had positive valence. Right?
Replies from: Gunnar_Zarncke↑ comment by Gunnar_Zarncke · 2024-10-25T10:34:02.875Z · LW(p) · GW(p)
There is just one problem that Libet discovered: There is no time for S(A) to cause A.
My favorite example is throwing a ball: A is the releasing of the ball at the right moment to hit a target. This requires Millisecond precision of release. The S(A) is precisely timed to coincide with the release. It feels like you are releasing the ball at the moment your hand releases it. But that can't be true because the signal from the brain alone takes longer than the duration of a thought. If your theory were right, you would feel the intention to release the ball and a moment later would have the sensation of the result happening.
Now, one solution around this would be to time-tag thoughts and reorder them afterwords, maybe in memory - a bit like out-of-order execution in CPUs handles parallel execution of sequential instructions. But I'm not sure that is what is going on or that you think it is.
So, my conclusion is that there is a common cause of both S(A) and A.
And my interpretation of Daniel Ingram's comments is different from yours.
In Mind and Body, the earliest insight stage, those who know what to look for and how to leverage this way of perceiving reality will take the opportunity to notice the intention to breathe that precedes the breath, the intention to move the foot that precedes the foot moving, the intention to think a thought that precedes the thinking of the thought, and even the intention to move attention that precedes attention moving.
These "intentions to think/do" that Ingraham refers to are not things untrained people can notice. There are things in the mind that precede the S(A) and A and cause them but people normally can't notice them and thus can't be S(A). I say these precursors are the same things picked up in the Libet experiments and neurological measurements.
Replies from: steve2152↑ comment by Steven Byrnes (steve2152) · 2024-10-25T13:10:04.046Z · LW(p) · GW(p)
We’re definitely talking past each other somehow. For example, your statement “The S(A) is precisely timed to coincide with the release” is (to me) obviously false. In the case of “deciding to throw a ball”, A would be the time-extended action of throwing the ball, and S(A) would be me “making a decision of my free will” to throw the ball, which happens way before the release, indeed it happens before I even start moving my arm. Releasing the ball isn’t a separate “decision” but rather part of the already-decided course-of-action.
(Again, I’m definitely not arguing that every action is this kind of stereotypical [S(A); A] “intentional free will decision”, or even that most actions are. Non-examples include every action you take in a flow state, and indeed you could say that every day is full of little “micro-flow-states” that last for even just a few seconds when you’re doing something rather than self-reflecting.)
…Then after the fact, I might recall the fact that I released the ball at such-and-such moment. But that thought is not actually about an “action” for reasons discussed in §2.6.1.
Replies from: Gunnar_Zarncke↑ comment by Gunnar_Zarncke · 2024-10-25T13:30:36.235Z · LW(p) · GW(p)
We’re definitely talking past each other somehow.
I guess this will only stop when we have made our thoughts clear enough for an implementation that allows us to inspect the system for S(A) and A. Which is OK.
At least this has helped clarify that you think of S(A) to (often) precede A by a lot, which wasn't clear to me. I think this complicates the analysis because of where to draw the line. Would it count if I imagine throwing the ball one day (S(A)) but executing it during the game the next day as I intend?
What do you make of the Libet experiments?
Replies from: steve2152↑ comment by Steven Byrnes (steve2152) · 2024-10-25T13:57:22.322Z · LW(p) · GW(p)
At least this has helped clarify that you think of S(A) to (often) precede A by a lot, which wasn't clear to me.
Not really; instead, I think throwing the ball is a time-extended course of action, as most actions are. If I “decide” to say a sentence or sing a song, I don’t separately “decide” to say the next syllable, then “decide” to say the next syllable after that, etc.
What do you make of the Libet experiments?
He did a bunch of experiments, I’m not sure which ones you’re referring to. (The “conscious intentions” one?) The ones I’ve read about seem mildly interesting. I don’t think they contradict anything I wrote or believe. If you do think that, feel free to explain. :)
Replies from: Gunnar_Zarncke↑ comment by Gunnar_Zarncke · 2024-10-25T14:52:36.079Z · LW(p) · GW(p)
I mean this (my summary of the Libet experiments and their replications):
- Brain activity detectable with EEG (Readiness Potential) begins between 350 and multiple seconds (depending on experiment and measurement resolution) before the person consciously feels the intention to act (voluntary motor movement).
- Subjects report becoming aware of their intention to act (via clock tracking) about 200 ms before the action itself (e.g., pressing a button). 200ms seems relatively fixed, but cognitive load can delay.
To give a specific quote:
Matsuhashi and Hallet: Our result suggests that the perception of intention rises through multiple levels of awareness, starting just after the brain initiates movement.
[...]
1. The first detected event in most subjects was the onset of BP. They were not aware of the movement genesis at this time, even if they were alerted by tones.
2. As the movement genesis progressed, the awareness state rose higher and after the T time, if the subjects were alerted, they could consciously access awareness of their movement genesis as intention. The late BP began within this period.
3. The awareness state rose even higher as the process went on, and at the W time it reached the level of meta-awareness without being probed. In Libet et al’s clock task, subjects could memorize the clock position at this time.
4. Shortly after that, the movement genesis reached its final point, after which the subjects could not veto the movement any more (P time).[...]
We studied the immediate intention directly preceding the action. We think it best to understand movement genesis and intention as separate phenomena, both measurable. Movement genesis begins at a level beyond awareness and over time gradually becomes accessible to consciousness as the perception of intention.
Now, I think you'd say that what they measured wasn't S(A) but something else that is causally related, but then you are moving farther away from patterns we can observe in the brain. And your theory still has to explain the subclass of those S(A) that they did measure. The participants apparently thought these to be their decisions S(A) about their actions A.
Replies from: steve2152↑ comment by Steven Byrnes (steve2152) · 2024-10-25T19:02:38.237Z · LW(p) · GW(p)
Thanks!
I don’t think S(A) or any other thought bursts into consciousness from the void via an acausal act of free will—that was the point of §3.3.6 [LW · GW]. I also don’t think that people’s self-reports about what was going on in their heads in the immediate past should necessarily be taken at face value—that was the point of §2.3 [LW · GW].
Every thought (including S(A)) begins its life as a little seed of activation pattern in some little part of the cortex, which gets gradually stronger and more widespread across the global workspace over the course of a fraction of a second. If that process gets cut off prematurely, then we don’t become aware of that thought at all, although sometimes we can notice its footprints via an appropriate attention-control query.
Does that help?
Maybe you’re thinking that, if I assert that a positive-valence S(A) caused A to happen, then I must believe that there’s nothing upstream that in turn caused S(A) to appear and to have positive valence? If so, that seems pretty silly to me. That would be basically the position that nothing can ever cause anything, right?
(“Your Honor, the victim’s death was not caused by my client shooting him! Rather, The Big Bang is the common cause of both the shooting and the death!” :-D )
Replies from: Gunnar_Zarncke, Gunnar_Zarncke↑ comment by Gunnar_Zarncke · 2024-11-05T09:52:23.048Z · LW(p) · GW(p)
I think your explanation in section 8.5.2 resolves our disagreement nicely. You refer to S(X) thoughts that "spawn up" successive thoughts that eventually lead to X (I'd say X') actions shortly after (or much later). While I was referring to S(X) that cannot give rise to X immediately. I think the difference was that you are more lenient with what X can be, such that S(X) can be about an X that is happening much later, which wouldn't work in my model of thoughts.
Explicit (self-reflective) desire
Statement: “I want to be inside.”
Intuitive model underlying that statement: There’s a frame (§2.2.3 [LW · GW]) “X wants Y” (§3.3.4 [LW · GW]). This frame is being invoked, with X as the homunculus, and Y as the concept of “inside” as a location / environment.
How I describe what’s happening using my framework: There’s a systematic pattern (in this particular context), call it P, where self-reflective thoughts concerning the inside, like “myself being inside” or “myself going inside”, tend to trigger positive valence. That positive valence is why such thoughts arise in the first place, and it’s also why those thoughts tend to lead to actual going-inside behavior.
In my framework, that’s really the whole story. There’s this pattern P. And we can talk about the upstream causes of P—something involving innate drives and learned heuristics in the brain. And we can likewise talk about the downstream effects of P—P tends to spawn behaviors like going inside, brainstorming how to get inside, etc. But “what’s really going on” (in the “territory” of my brain algorithm) is a story about the pattern P, not about the homunculus. The homunculus only arises secondarily, as the way that I perceive the pattern P (in the “map” of my intuitive self-model).
↑ comment by Gunnar_Zarncke · 2024-10-25T20:16:01.660Z · LW(p) · GW(p)
Thanks. It doesn't help because we already agreed on these points.
We both understand that there is physical process in the brain - neurons firing etc. - as you describe in 3.3.6, that gives rise to a) S(A), b) A, and c) the precursors to both as measured by Libet and others.
We both know that people's self-reports are unreliable and informed by their intuitive self-models. To illustrate that I understand 2.3 let me give an example: My son has figured out that people hear what they expect to hear and experimented with leaving out fragments of words or sentences, enjoying himself by how people never noticed anything was off (example: "ood morning"). Here, the missing part doesn't make it into people's awareness despite the whole sentence very well does.
I'm not asserting that there is nothing upstream of S(A) that is causing it. I'm asserting that an individual S(A) is not causing A. I'm asserting so because it can't timing-wise and equivalently, that there is no neurological action path from S(A) to A. The only relation between S(A) and A is that S(A) and A co-occurring has been statistically positive valence in the past. And this co-occurrence is facilitated by a common precursor. But saying S(A) is causing A is as right or wrong as saying A is causing S(A).
comment by Towards_Keeperhood (Simon Skade) · 2024-10-18T12:34:22.271Z · LW(p) · GW(p)
(I'd rewrite (in 2.6.5) "Illusions of free will" to "Illusions of intentionality" since it doesn't seem very related to what people usually refer to with "free will" iiuc.)
Replies from: steve2152↑ comment by Steven Byrnes (steve2152) · 2024-10-18T12:52:29.007Z · LW(p) · GW(p)
I was under the impression that “illusions of free will” was a standard term in the literature, but I just double-checked and I guess I was wrong, it just happened to be in one paper I read. Oops. So I guess I’m entitled to use whatever term seems best to me.
I mildly disagree that it’s unrelated to “free will”, but I agree that all things considered your suggestion “illusions of intentionality” is a bit better. I’m changing it, thanks!
comment by Charlie Steiner · 2024-09-27T12:10:59.504Z · LW(p) · GW(p)
I am confused about the purpose of the "awareness and memory" section, and maybe disagree with the intuition said to be obvious in the second subsection. Is there some deeper reason you want to bring up how we self-model memory / something you wanted to talk about there that I missed?
Replies from: steve2152↑ comment by Steven Byrnes (steve2152) · 2024-09-27T12:18:24.923Z · LW(p) · GW(p)
I could have cut §2.4. It’s not particularly important for later posts in the series. I thought about it. But it was pretty short, and I judged that it might be marginally useful all things considered.
Even if you lack the §2.4.2 intuition linking amnesia to I-must-have-been-unconscious, other people certainly have that intuition, e.g. Clive Wearing “constantly believes that he has only recently awoken from a comatose state”. I thought it was worth saying why someone might find that to be intuitively appealing, even if they simultaneously have other countervailing intuitions.
comment by Signer · 2024-09-26T09:33:31.908Z · LW(p) · GW(p)
I still don't get this "only one thing in awareness" thing. There are multiple neurons in cortex and I can imagine two apples - in what sense there can only be one thing in awareness?
Or equivalently, it corresponds equally well to two different questions about the territory, with two different answers, and there’s just no fact of the matter about which is the real answer.
Obviously the real answer is the model which is more veridical^^. The latter hindsight model is right not about the state of the world at t=0.1, but about what you thought about the world at t=0.1 later.
Replies from: steve2152↑ comment by Steven Byrnes (steve2152) · 2024-09-26T13:07:17.623Z · LW(p) · GW(p)
I still don't get this "only one thing in awareness" thing. There are multiple neurons in cortex and I can imagine two apples - in what sense there can only be one thing in awareness?
One thought in awareness! Imagining two apples is a different thought from imagining one apple, right? They’re different generative models, arising in different situations, with different implications, different affordances, etc. Neither is a subset of the other. (I.e., there are things that I might do or infer in the context of one apple, that I would not do or infer in the context of two apples.)
I can have a song playing in my head while reading a legal document. That’s because those involve different parts of the cortex. In my terms, I would call that “one thought” involving both a song and a legal document. On the other hand, I can’t have two songs playing in my head simultaneously, nor can I be thinking about two unrelated legal documents simultaneously. Those involve the same parts of the cortex being asked to do two things that conflict. So instead, I’d have to flip back and forth.
There are multiple neurons in the cortex, but they’re not interchangeable. Again, I think autoassociative memory / attractor dynamics is a helpful analogy here. If I have a physical instantiation of a Hopfield network, I can’t query 100 of its stored patterns in parallel, right? I have to do it serially.
I don’t pretend that I’m offering a concrete theory of exactly what data format a “generative model” is etc., such that song-in-head + legal-contract is a valid thought but legal-contract + unrelated-legal-contract is not a valid thought. …Not only that, but I’m opposed to anyone else offering such a theory either! We shouldn’t invent brain-like AGI until we figure out how to use it safely [LW · GW], and those kinds of gory details would be getting uncomfortably close, without corresponding safety benefits, IMO.
Replies from: Charlie Steiner, Signer↑ comment by Charlie Steiner · 2024-09-27T12:07:31.052Z · LW(p) · GW(p)
On the other hand, I can’t have two songs playing in my head simultaneously,
Tangent: I play at irish sessions, and one of the things you have to do there is swap tunes. If you lead a transition you have to be imagining the next tune you're going to play at the same time as you're playing the current tune. In fact, often you have to decide on the next tune on the fly. This us a skill that takes some time to grok. You're probably conceptualizing the current and future tunes differently, but there's still a lot of overlap - you have to keep playing in sync with other people the entire time, while at the same time recalling and anticipating the future tune.
↑ comment by Signer · 2024-09-26T17:59:53.928Z · LW(p) · GW(p)
Imagining two apples is a different thought from imagining one apple, right?
I mean, is it? Different states of the whole cortex are different. And the cortex can't be in a state of imagining only one apple and, simultaneously, be in a state of imagining two apples, obviously. But it's tautological. What are we gaining from thinking about it in such terms? You can say the same thing about the whole brain itself, that it can only have one brain-state in a moment.
I guess there is a sense in which other parts of the brain have more various thoughts relative to what cortex can handle, but, like you said, you can use half of cortex capacity, so why not define song and legal document as different thoughts?
As abstract elements of provisional framework cortex-level thoughts are fine, I just wonder what are you claiming about real constrains, aside from "there limits on thoughts". because, for example, you need other limits anyway - you can't think arbitrary complex thought even if it is intuitively cohesive. But yeah, enough gory details.
On the other hand, I can’t have two songs playing in my head simultaneously, nor can I be thinking about two unrelated legal documents simultaneously.
I can't either, but I don't see just from the architecture why it would be impossible in principle.
Again, I think autoassociative memory / attractor dynamics is a helpful analogy here. If I have a physical instantiation of a Hopfield network, I can’t query 100 of its stored patterns in parallel, right? I have to do it serially.
Yes, but you can theoretically encode many things in each pattern? Although if your parallel processes need different data, one of them will have to skip some responses... Would be better to have different networks, but I don't see brain providing much isolation. Well, it seems to illustrate complications of parallel processing that may played a role in humans usually staying serial.
Replies from: steve2152↑ comment by Steven Byrnes (steve2152) · 2024-09-26T18:24:18.545Z · LW(p) · GW(p)
You say “tautological”, I say “obvious”. You can’t parse a legal document and try to remember your friend’s name at the exact same moment. That’s all I’m saying! This is supposed to be very obvious common sense, not profound.
What are we gaining from thinking about it in such terms?
Consider the following fact:
FACT: Sometimes, I’m thinking about pencils. Other times, I’m not thinking about pencils.
Now imagine that there’s a predictive (a.k.a. self-supervised) learning algorithm which is tasked with predicting upcoming sensory inputs, by building generative models. The above fact is very important! If the predictive learning algorithm does not somehow incorporate that fact into its generative models, then those generative models will be worse at making predictions. For example, if I’m thinking about pencils, then I’m likelier to talk about pencils, and look at pencils, and grab a pencil, etc., compared to if I’m not thinking about pencils. So the predictive learning algorithm is incentivized (by its predictive loss function) to build a generative model that can represent the fact that any given concept might be active in the cortex at a certain time, or might not be.
Again, this is all supposed to sound very obvious, not profound.
You can say the same thing about the whole brain itself, that it can only have one brain-state in a moment.
Yes, it’s also useful for the predictive learning algorithm to build generative models that capture other aspects of the brain state, outside the cortex. Thus we wind up with intuitive concepts that represent the possibility that we can be in one mood or another, that we can be experiencing a certain physiological reaction, etc.
comment by ScienceBall · 2025-02-23T09:50:21.098Z · LW(p) · GW(p)
Thank you for writing this series.
I have a couple of questions about conscious awareness, and a question about intuitive self-models in general. They might be out-of-scope for this series, though.
Questions 1 and 2 are just for my curiosity. Question 3 seems more important to me, but I can imagine that it might be a dangerous capabilities question, so I acknowledge you might not want to answer it for that reason.
- In 2.4.2, you say that things can only get stored in episodic memory if they were in conscious awareness. People can sometimes remember events from their dreams. Does that mean that people have conscious awareness during (at least some of) their dreams?
- Is there anything you can say about what unconsciousness is? i.e. Why is there nothing in conscious awareness during this state? - Is the cortex not thinking any (coherent?) thoughts? (I have not studied unconsciousness.)
- About the predictive learning algorithm in the human brain - what types of incoming data does it have access to? What types of incoming data is it building models to predict? I understand that it would be predicting data from your senses of vision, hearing, and touch, etc. But when it comes to build an intuitive self-model, does it also have data that directly represents what the brain algorithm is doing (at some level)? Or does it have to infer the brain algorithm from its effect on the external sense data (e.g. motor control to change what you're looking at)?
- In the case of conscious awareness, does the predictive algorithm receive "the thought currently active in the cortex" as an input to predict? Or does it have to infer the thought when trying to predict something else?
↑ comment by Steven Byrnes (steve2152) · 2025-02-24T20:59:18.047Z · LW(p) · GW(p)
Good questions, thanks!
In 2.4.2, you say that things can only get stored in episodic memory if they were in conscious awareness. People can sometimes remember events from their dreams. Does that mean that people have conscious awareness during (at least some of) their dreams?
My answer is basically “yes”, although different people might have different definitions of the concept “conscious awareness”. In other words, in terms of map-territory correspondence, I claim there’s a phenomenon P in the territory (some cortex neurons / concepts / representations are active at any given time, and others are not, as described in the post), and this phenomenon P gets incorporated into everyone’s map, and that’s what I’m talking about in this post. And this phenomenon P is part of the territory during dreaming too.
But it’s not necessarily the case that everyone will define the specific English-language phrase “conscious awareness” to indicate the part of their map whose boundaries are drawn exactly around that phenomenon P. Instead, for example, some people might feel like the proper definition of “conscious awareness” is something closer to “the phenomenon P in the case when I’m awake, and not drugged, etc.”, which is really P along with various additional details and connotations and associations, such as the links to voluntary control and memory. Those people would still be able to conceptualize the phenomenon P, of course, and it would still be a big part of their mental worlds, but to point to it you would need a whole sentence, not just the two words “conscious awareness”.
Is there anything you can say about what unconsciousness is? i.e. Why is there nothing in conscious awareness during this state? - Is the cortex not thinking any (coherent?) thoughts? (I have not studied unconsciousness.)
I think sometimes the cortex isn’t doing much of anything, or at least, not running close-enough-to-normal that neurons representing thoughts can be active.
Alternatively, maybe the cortex is doing its usual thing of activating groups of neurons that represent thoughts and concepts—but it’s neither forming memories (that last beyond a few seconds), nor taking immediate actions. Then you “look unconscious” from the outside, and you also “look unconscious” from the perspective of your future self. There’s no trace of what the cortex was doing, even if it was doing something. Maybe brain scans can distinguish that possibility though.
About the predictive learning algorithm in the human brain…
I think I declare that out-of-scope for this series, from some combination of “I don’t know the complete answer” and “it might be a dangerous capabilities question”. Those are related, of course—when I come upon things that might be dangerous capabilities questions, I often don’t bother trying to answer them :-P
comment by Towards_Keeperhood (Simon Skade) · 2024-10-18T13:29:28.092Z · LW(p) · GW(p)
- Correspondingly, in the actual brain algorithm (“territory”), any possible thought can be represented by the cortex (by definition), but only one thought can be there at a time (to a first approximation, see §2.3 below).
I don't think I agree with the "but only one thought can be there at a time" part.
I think (but not at all sure) that different (sensory) modalities can process (in unfocused states) unrelated information/thoughts simultaneously.
Here's my current rough model that might be wrong in many ways:
I think each of the workspaces have their own short memory which spans maybe like 2seconds. (E.g. sometimes when I become aware of an earworm I feel like it must've been there for at least 2 seconds already even though I previously wasn't aware of it.)
(I currently don't know whether there is a "space of awareness" or whether (as in the image above) it's just that some workspace is broadcasting its contents broadly.)
(I think it sometimes happened to me that I was daydreaming about something which was written to memory (although not very strongly) but where I didn't notice that I was thinking that and only later realized "oh wait I thought about that before". So perhaps sth was only weakly attended on and left some trace in memory but then either the "produce self-reflective thought" or the "associate self-reflective thought with homunculus" step didn't happen. But idk I'd want to re-observe this phenomenon to be sure it's not just fabricated. EDIT: Actually from having made a break and daydreamed a bit now, I think it rather is the case that usually one decently often has a self-reflective thought (about what object-level thoughts one thinks) attended on so there's also a memory of oneself thinking about sth. However sometimes in deep daydreams (or other states like flow) self-reflective thoughts are only very rarely attended on and sometimes never. I think often I notice roughly about what I was daydreaming afterwards, but maybe sometimes the daydream is disrupted by something outside so that then there wasn't a self-reflective thought written to memory, which might then later make me slightly surprised when I notice that I e.g. daydreamed about a particular movie earlier but didn't notice that at the time. Aka: I think the self-reflective thoughts still get produced unconsciously when daydreaming, but they might not get attended on so no self-associated memory of the event is formed.)
↑ comment by Steven Byrnes (steve2152) · 2024-10-18T14:28:42.529Z · LW(p) · GW(p)
I don't think I agree with the "but only one thought can be there at a time" part.
I’m probably just defining “thought” more broadly than you. The cortex has many areas. The auditory parts can be doing some auditory thing, and simultaneously the motor parts can be doing some motor thing, and all that together constitutes (what I call) a “thought”.
I don’t think anything in the series really hinges on the details here. “Conscious awareness” is not conceptualized as some atomic concept where there’s nothing else to say about it. If you ask people to describe their conscious awareness, they can go on and on for hours. My claim is that: when they go on and on for hours describing “conscious awareness”, all the rich details that they’re describing can be mapped onto accurate claims about properties of the cortex and its activation states. (E.g. the next part of this comment.)
I think each of the workspaces have their own short memory which spans maybe like 2seconds.
I agree that, if some part of the cortex is in activation state A at time T, those particular neurons (that constitute A) will get less and less active over the course of a second or two, such that at time T+1 second, it’s still possible for other parts of the cortex to reactivate activation state A via an appropriate query. I don’t think all traces of A immediately disappear entirely every time a new activation state appears.
Again, I think the capability of the cortex to have more than one incompatible generative models active simultaneously is extremely limited, and that for most purposes we should think of it as only having a single (MAP estimate) generative model active. But the capability to track multiple incompatible models simultaneously does exist, to some extent. I think this slow-fading thing is one application of that capability. Another is the time-extended probabilistic inference thing that I talked about in §2.3.
Replies from: Simon Skade↑ comment by Towards_Keeperhood (Simon Skade) · 2024-10-18T14:31:22.374Z · LW(p) · GW(p)
ok yep sounds like we basically agree i think.
comment by Towards_Keeperhood (Simon Skade) · 2024-10-18T15:30:56.709Z · LW(p) · GW(p)
I basically agree with everything in section 2.2, but I read section 1.4 again (which i also agree with as written there), and I just wanted to point out that I think the kind of self-modelling described in section 2.2 is in some ways unusual and happens because of smart/social-animal-specific brain programming and not just pure pressure for generative models to form self-models to make better predictions. (Though I think humans are probably smart enough that decent self-models would also have been formed for those reasons you described in section 1.4, but I think humans have quite some pre-wired machinery for self-modelling.)
In most animals the cortex mostly just models the world I think, and there are parts of the cortex that model other parts of the cortex which in the end just translates into making better predictions about the world. (This also happens in humans tbc.)
What's described in section 2.2 though is that there's exists a "(this) mind" concept and the cortex forms beliefs about it by creating some abstract labels for thoughts and using those to form new thoughts like "abstract-label-of-thought-X is present in the mind". (For non-human animals which do such self-modelling they probably don't model thoughts but rather intentions/desires or so.)
This is unusual because initially the model of the mind is separated from the model of the model of the world. So far the model of the mind is a separate magisterium which isn't immediately useful for making predictions about the world.
However there are bridging laws between a model of a mind and the physical world, e.g. emotion <-> facial expression predictive bindings.
Evolutionarily, I think overall this kind of modelling the mind as separate entity turns out to be useful because the same machinery can be used to model and predict conspecifics. Aka such smart/social animals don't just model the world but model the world with some minds (of conspecifics) embedded in there, where the minds are treated as special cases because better predictions about conspecifics can be made from generalizing how the own mind (which can be observed in way more detail) operates.
In humans this whole mind modelling is especially sophisticated (e.g. humans seem to at least sometimes be aware of their own awareness) and there are many aspects I don't understand yet. I think a major part why the homunculus exists might be as interface between the model of mind and the model of the world.
But I'm still somewhat confused here and I also don't quite know what your position here is.