Calculating Natural Latents via Resampling
post by johnswentworth, David Lorell · 2024-06-06T00:37:42.127Z · LW · GW · 4 commentsContents
Some Conceptual Foundations What Are We Even Computing? Why Do We Want That, Again? Approximate “Uniqueness” and Competitive Optimality Strong Redundancy The Resampling Construction Theorem 1: Strong Redundancy => Naturality Theorem 2: Competitive Optimality Step 1: Xi Mediates Between Xj and X′i Step 2: X′ has Weak Redundancy over X Step 3: Λ Mediates between X and X′ Step 4: Strong Redundancy of X′ Can You Do Better? Empirical Results (Spot Check) None 4 comments
So you’ve read some of our previous [LW · GW] natural latents [LW · GW] posts [LW · GW], and you’re sold on the value proposition. But there’s some big foundational questions still unanswered. For example: how do we find these natural latents in some model, if we don’t know in advance what they are? Examples in previous posts conceptually involved picking some latent out of the ether (like e.g. the bias of a die), and then verifying the naturality of that latent.
This post is about one way to calculate natural latents, in principle, when we don’t already know what they are. The basic idea is to resample all the variables once simultaneously, conditional on the others, like a step in an MCMC algorithm. The resampled variables turn out to be a competitively optimal approximate natural latent over the original variables (as we’ll prove in the post). Toward the end, we’ll use this technique to calculate an approximate natural latent for a normal distribution, and quantify the approximations.
The proofs will use the graphical notation introduced in Some Rules For An Algebra Of Bayes Nets [LW · GW].
Some Conceptual Foundations
What Are We Even Computing?
First things first: what even is “a latent”, and what does it even mean to “calculate a natural latent”? If we had a function to “calculate natural latents”, what would its inputs be, and what would its outputs be?
The way we use the term, any conditional distribution
defines a “latent” variable over the “observables” , given the distribution . Together and specify the full joint distribution . We typically think of the latent variable as some unobservable-to-the-agent “generator” of the observables, but a latent can be defined by any extension of the distribution over to a distribution over and .
Natural latents are latents which (approximately) satisfy some specific conditions, namely that the distribution (approximately) factors over these Bayes nets:
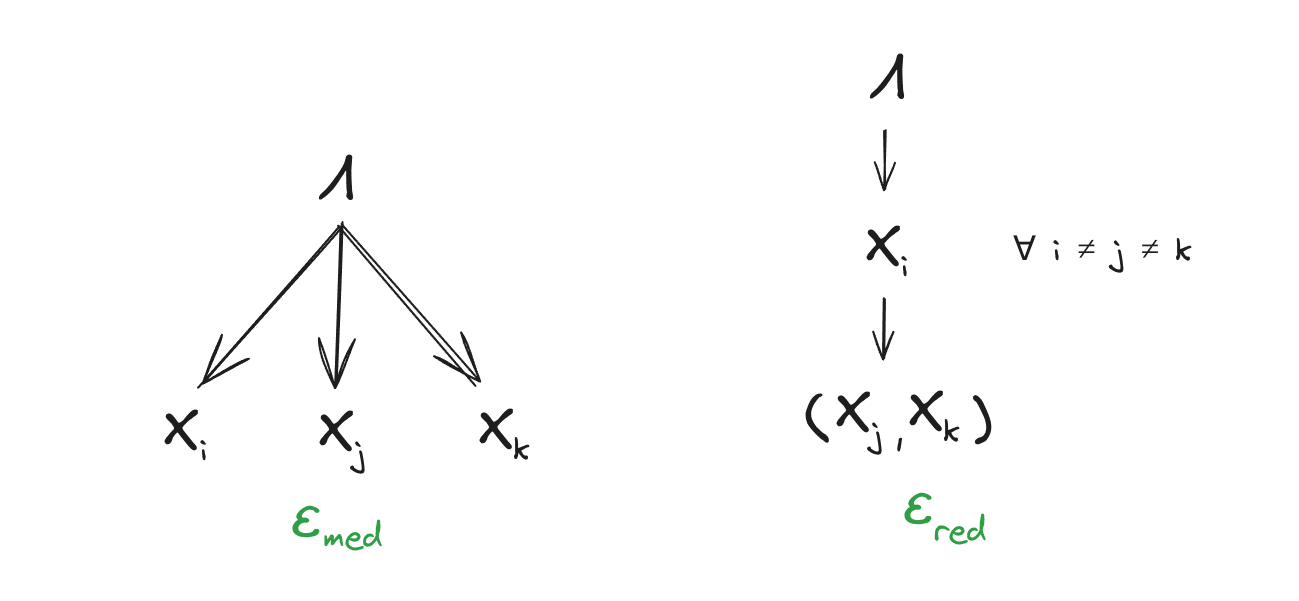
Intuitively, the first says that mediates between the ’s, and the second says that any one gives approximately the same information about as all of . (This is a stronger redundancy condition than we used in previous posts; we’ll talk about that change below.)
So, a function which “calculates natural latents” takes in some representation of a distribution over “observables”, and spits out some representation of a conditional distribution , such that the joint distribution (approximately) factors over the Bayes nets above.
For example, in the last section of this post, we’ll compute a natural latent for a normal distribution. The function to compute that latent:
- Takes in a covariance matrix for , representing a zero-mean normal distribution .
- Spits out a covariance matrix for and a cross-covariance matrix , together representing the conditional distribution of a latent which is jointly zero-mean normal with X.
- … and the joint normal distribution over represented by those covariance matrices approximately factors according to the Bayes nets above.
Why Do We Want That, Again?
Our previous [LW · GW] posts [LW · GW] talk more about the motivation, but briefly: two different agents could use two different models with totally different internal (i.e. latent) variables to represent the same predictive distribution . Insofar as they both use natural latents, there’s a correspondence between their internal variables - two latents over the same which both approximately satisfy the naturality conditions must contain approximately the same information about . So, insofar as the two agents both use natural latents internally, we have reason to expect that the internal latents of one can be faithfully translated into the internal latents of the other - meaning that things like e.g. language (between two humans) or interpretability (of a net’s internals to a human) are fundamentally possible to do in a robust way. The internal latents of two such agents are not mutually alien or incomprehensible, insofar as they approximately satisfy naturality conditions and the two agents agree predictively.
Approximate “Uniqueness” and Competitive Optimality
There will typically be more than one different latent which approximately satisfies the naturality conditions (i.e. more than one conditional distribution such that the joint distribution of and approximately factors over the Bayes nets in the previous section). They all “contain approximately the same information about ”, in the sense that any one approximate natural latent approximately mediates between and any other approximate natural latent. In that sense, we can approximately talk as though the natural latent is unique, for many purposes. But that still leaves room for better or worse approximations.
When calculating, we’d ideally like to find a natural latent which is a “best possible approximate natural latent” in some sense. Really we want a pareto-best approximation, since we want to achieve the best approximation we can on each of the naturality conditions, and those approximations can trade off against each other.
… but there’s a whole pareto surface, and it’s a pain to get an actual pareto optimum. So instead, we’ll settle for the next best thing: a competitively optimal approximate natural latent. Competitive optimality means that the natural latent we’ll calculate approximates the naturality conditions to within some bounds of any pareto-best approximate natural latent; it can only do so much worse than “the best”. Crucially, competitive optimality means that when we don’t find a very good approximate natural latent, we can rule out the possibility of some better approximate natural latent.
Strong Redundancy
Our previous posts on natural latents used a relatively weak redundancy condition: all-but-one gives approximately the same information about as all of . (Example: 999 rolls of a biased die give approximately the same information about the bias as 1000 rolls.) The upside of this condition is that it’s relatively general; the downside is that it gives pretty weak quantitative bounds, and in practice we’ve found that a stronger redundancy condition is usually more useful. So in this post, we’ll require “strong redundancy”: any one must give approximately the same information about as all of . (Example: sticking a thermometer into any one part of a bucket of water at equilibrium gives the same information about the water’s temperature.)
If we want to turn weak redundancy into strong redundancy, e.g. to apply the methods of this post to the biased die example, the usual trick is to chunk together the ’s into two or three chunks. For instance, with 1000 die rolls, we could chunk together the first 500 and the second 500, and either of those two subsets gives us roughly the same information about the bias (insofar as 500 rolls is enough to get a reasonably-precise estimate of the bias).
Conceptually, with strong redundancy, all of the -relevant information in a natural latent is represented in every single one of the ’s. For purposes of establishing that e.g. natural latents of two different agents contain the same information about , that means strong redundancy gives us “way more than we need” - we only really need strong redundancy over two or three variables in order to establish that the latents “match”.
The Resampling Construction
We start with a distribution over the variables . We want to construct a latent which is competitively optimal - i.e. if any latent exists over which satisfies the natural latent conditions to within some approximation, then our latent satisfies the natural latent conditions to within some boundedly-worse approximation (with reasonable bounds). We will call our competitively optimal latent (pronounced “X prime”), for reasons which will hopefully become clear shortly.
Here’s how we construct . Take “X”, then add an apostrophe, “‘“, like so -> X’ … and that was how David died. Anyway, to construct :
- For each , obtain by sampling from the distribution of given all the other ’s.
- Stack those up to obtain .
Mathematically, that means the defining distribution of the latent is
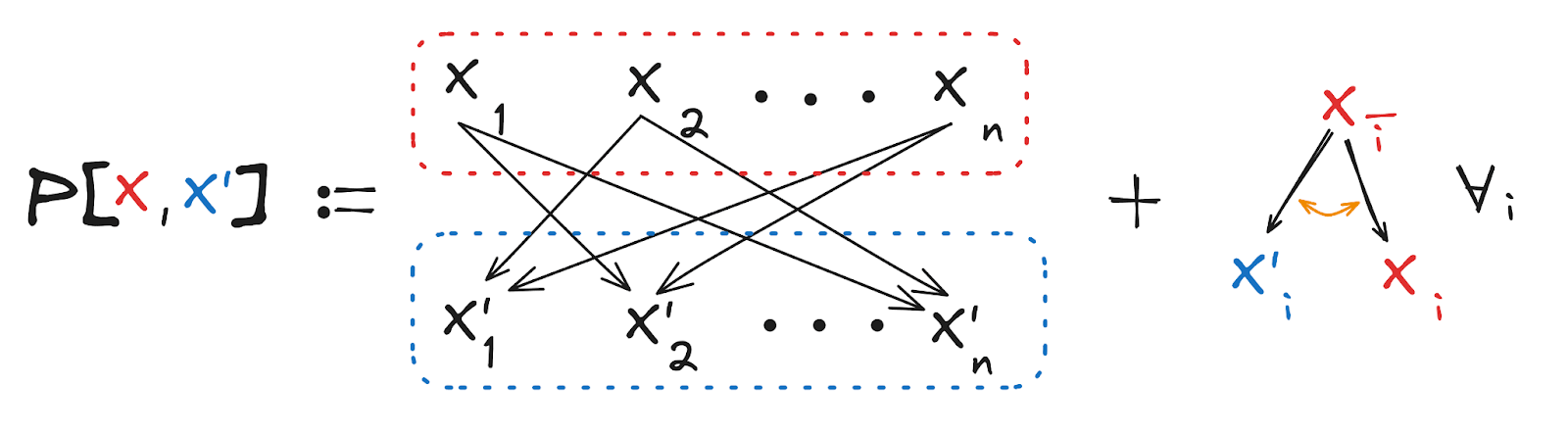
Conceptually, we can think of this as a single resample step of the sort one might use for MCMC, in which we resample every variable simultaneously conditional on all other variables.
Example: suppose is 500 rolls of a biased die, is another 500 rolls of the same die, and is yet another 500 rolls of the same die. Then to calculate . I sample the bias of the die conditional on the 1000 rolls in and , then generate 500 new rolls of a die with my newly-sampled bias, and those new rolls are . Likewise for and (noting that I’ll need to sample a new bias for each of them). Then, I put all those 1500 rolls together to get .
Why would be a competitively optimal natural latent? Intuitively, if there exists a natural latent (with strong redundancy), then each encodes the value of the natural latent (approximately) as well as some “noise” independent of all the other ’s. When we resample, the natural latent part is kept the same, but the noise is resampled to be independent of the other ’s. So, the only information which contains about is the value of the natural latent. Of course, that story doesn’t give approximation bounds; that’s what we’ll need all the fancy math for.
In the rest of this section, we’ll show that satisfies the naturality conditions competitively optimally: if there exists any latent which is natural to within some approximation, then is natural to within a boundedly-worse approximation.
Theorem 1: Strong Redundancy => Naturality
Normally, a latent must approximately satisfy two (sets of) conditions in order to be natural: mediation, and redundancy. The latent must encode approximately all the information correlating the ’s (mediation), and each must give approximately the same information about the latent (redundancy). Theorem 1 says that, for specifically, the approximation error on the (strong) redundancy conditions upper bounds the approximation error on the mediation condition. So, for specifically, “redundancy is all you need” in order to establish naturality.
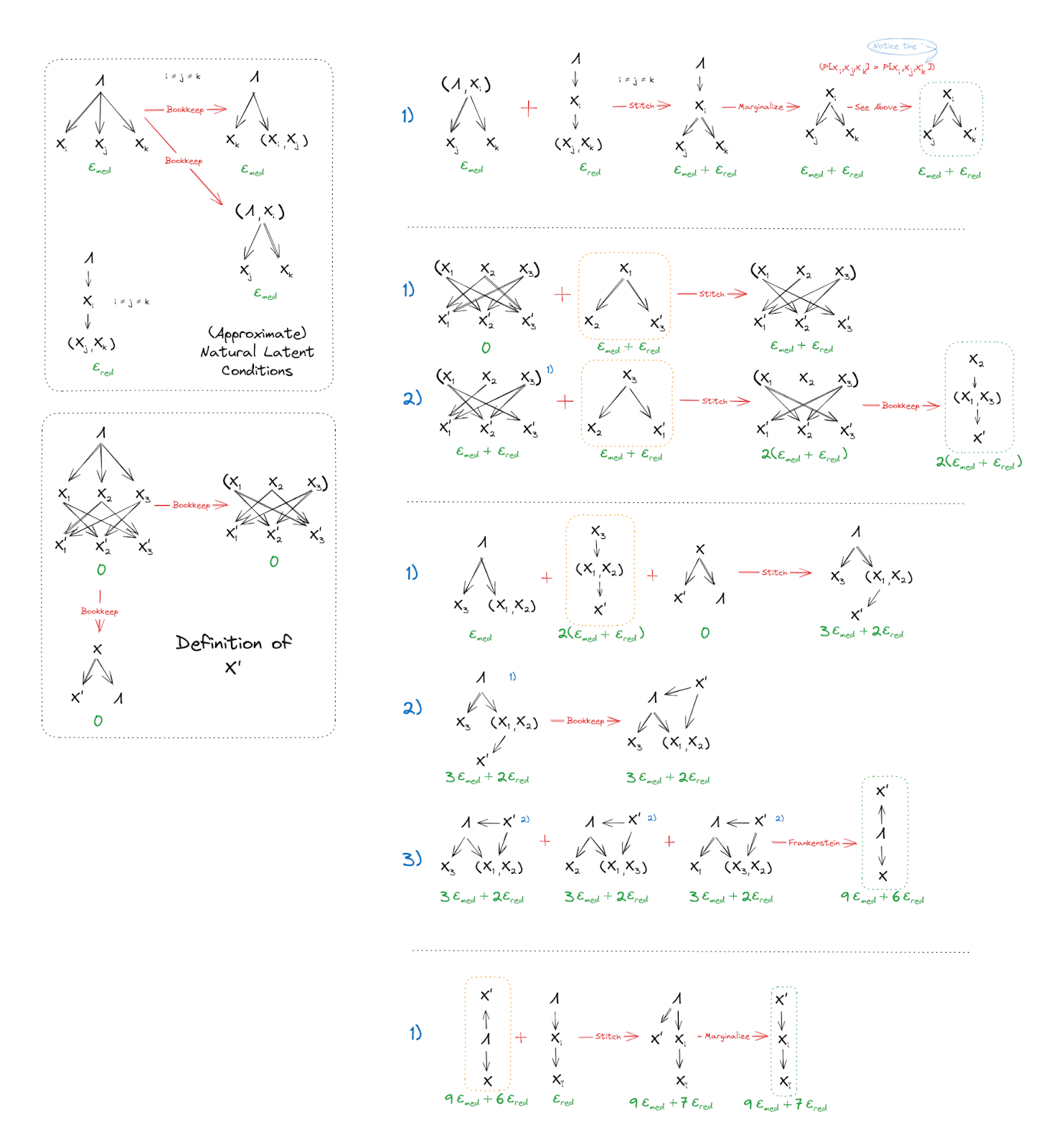
Some of the proof will be graphical, but we’ll need to start with one key algebraic step. The key step is this:
The magic piece is the replacement of with ; this is allowed because, by construction, have the exact same joint distribution as . Graphically, that tells us:
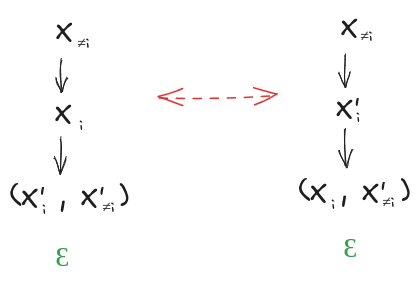
Note that the left diagram is the strong redundancy condition for .
The rest of the proof is just a bookkeeping step:
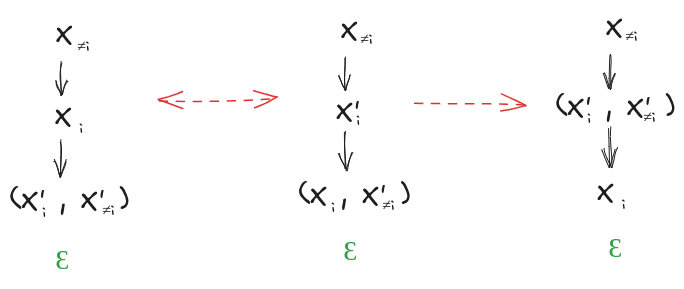
So mediates between and , for all .
Theorem 2: Competitive Optimality
To prove competitive optimality, we first assume that there exists some latent over which satisfies the (strong) natural latent conditions to within some bounds. Using that assumption, we want to prove that satisfies the (strong) natural latent conditions to within some not-much-worse bounds. And since Theorem 1 showed that, for specifically, the strong redundancy approximation error bounds the mediation approximation error, all that’s left is to bound the strong redundancy approximation error for .
Outline:
- First, assuming a strong approximate natural latent exists, we’ll show that any approximately mediates between any other , . (This is a handy property in its own right!)
- Second, we’ll show that satisfies a weak redundancy condition over X.
- Third: since a natural latent is the “maximal” latent which satisfies redundancy over X [LW · GW], the previous condition is in-principle sufficient to show that approximately mediates between and . However, we’ll inline the proof of the maximality condition and tweak it a bit to get slightly better bounds.
- Since we can sample equally well with any one (i.e. strong redundancy), and approximately tells us everything tells us about , we can sample equally well with any one : strong invariance holds for .
Step 1: Mediates Between and
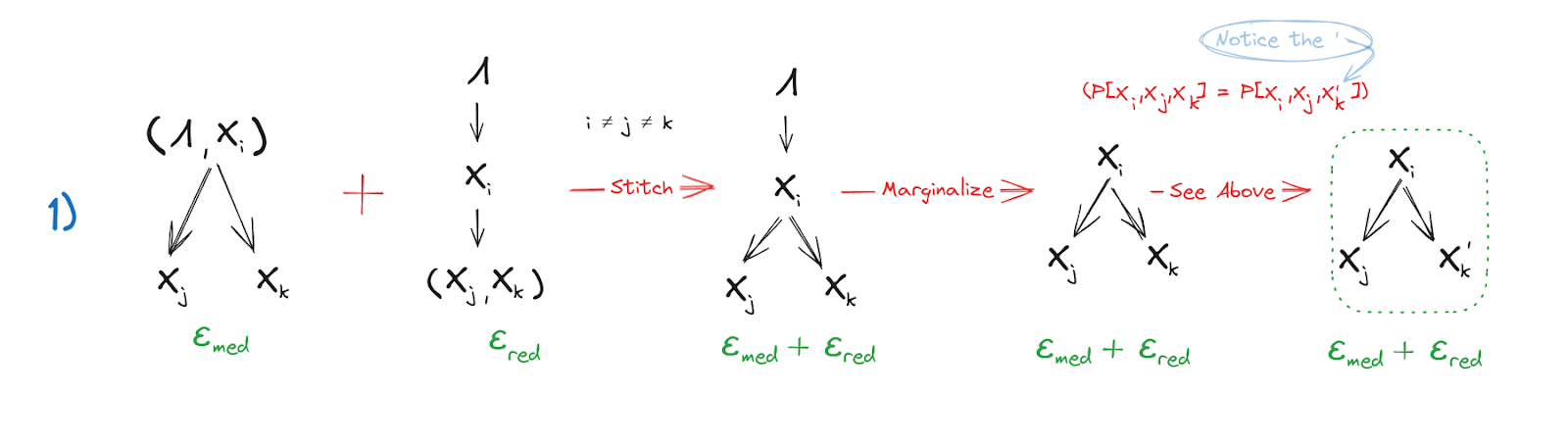
The two naturality conditions (just one of the redundancy conditions) of over easily show that mediates between and (). The equivalence of and (by construction of ) allows for replacing in the factorization with the version. Then, we get the result we were looking for.
Step 2: has Weak Redundancy over
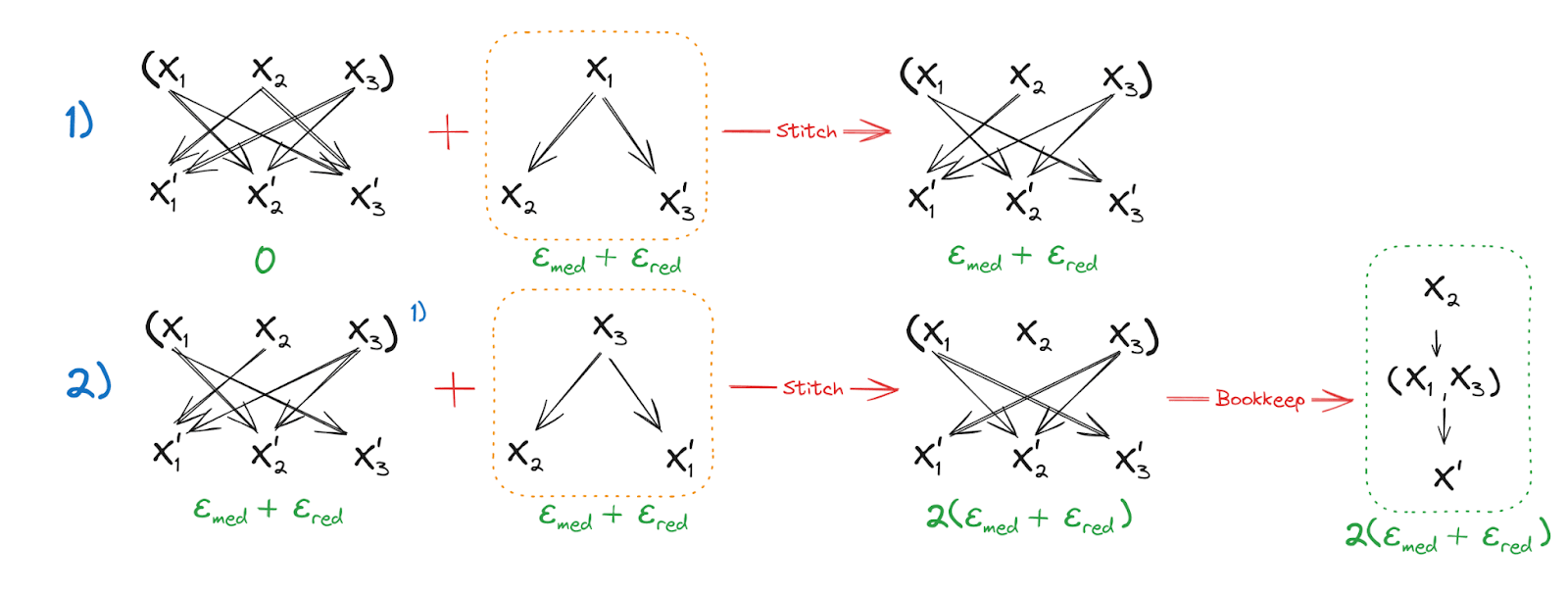
In the first line, we use the definition of and the result from Step 1 to establish mediation of between and and so we can remove the outgoing edge . In the second line, we do the same thing for the remaining outgoing edge of , establishing as unconditionally independent of . Having done so, trivially mediates between and .
Step 3: Mediates between and
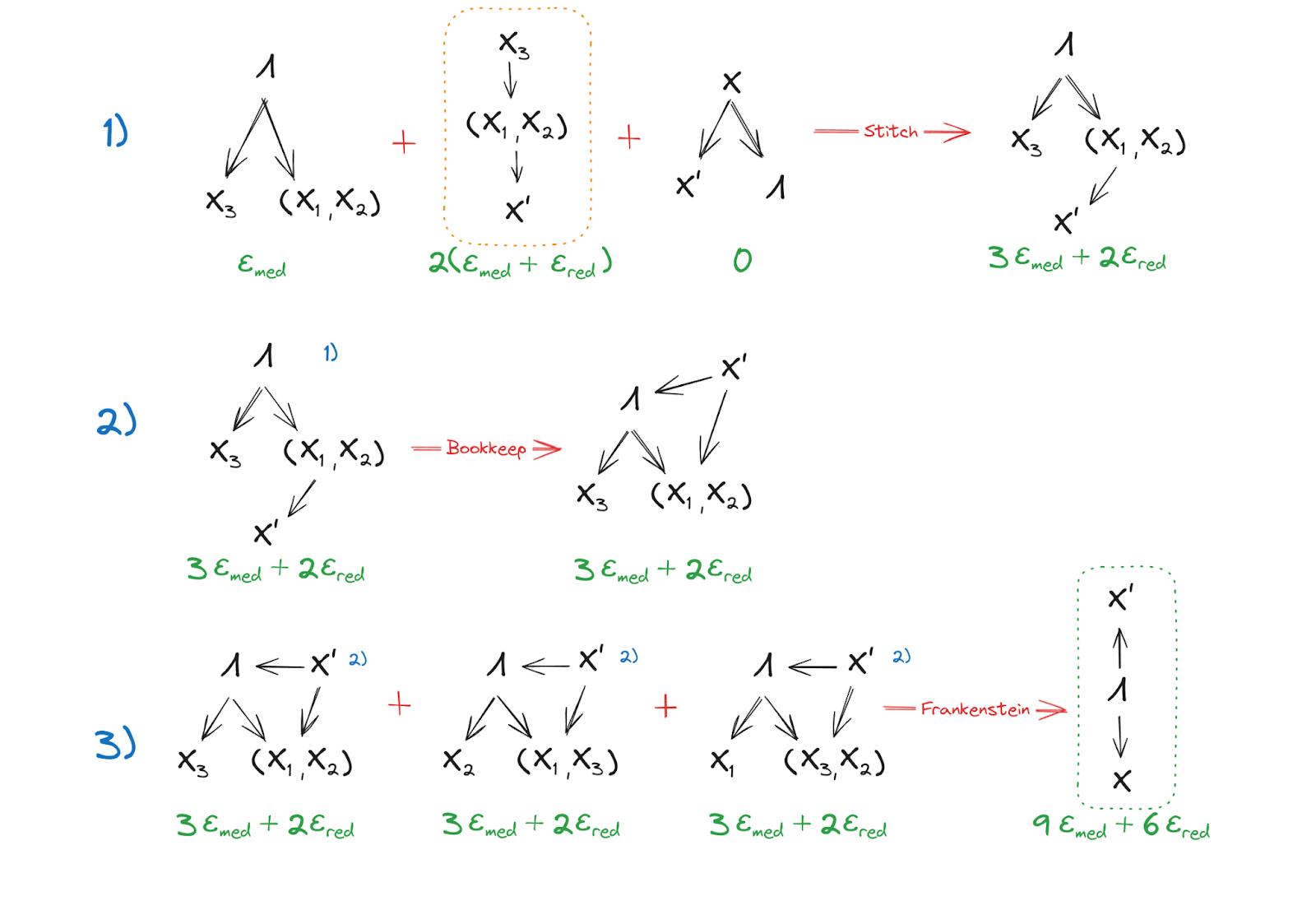
The intermediates here are much more easily understood in graphical form, but in words: In lines 1 and 2, we combine result of Step 2 with the mediation condition of and the definition of to stitch together a combined factorization of the joint distribution of , , and where mediates between and , and in particular it’s the components which mediate while is independent conditional on . With some minor bookkeeping, we flip the arrow between and , and add an arrow from to . Since this produces no cycles nor colliders, this is a valid move.
In line three, we use the result of line 2 in all 3 permutations of the components and Frankenstein the graphs together to show that, since each component of has mediating between it and , mediates between all of and .
Step 4: Strong Redundancy of
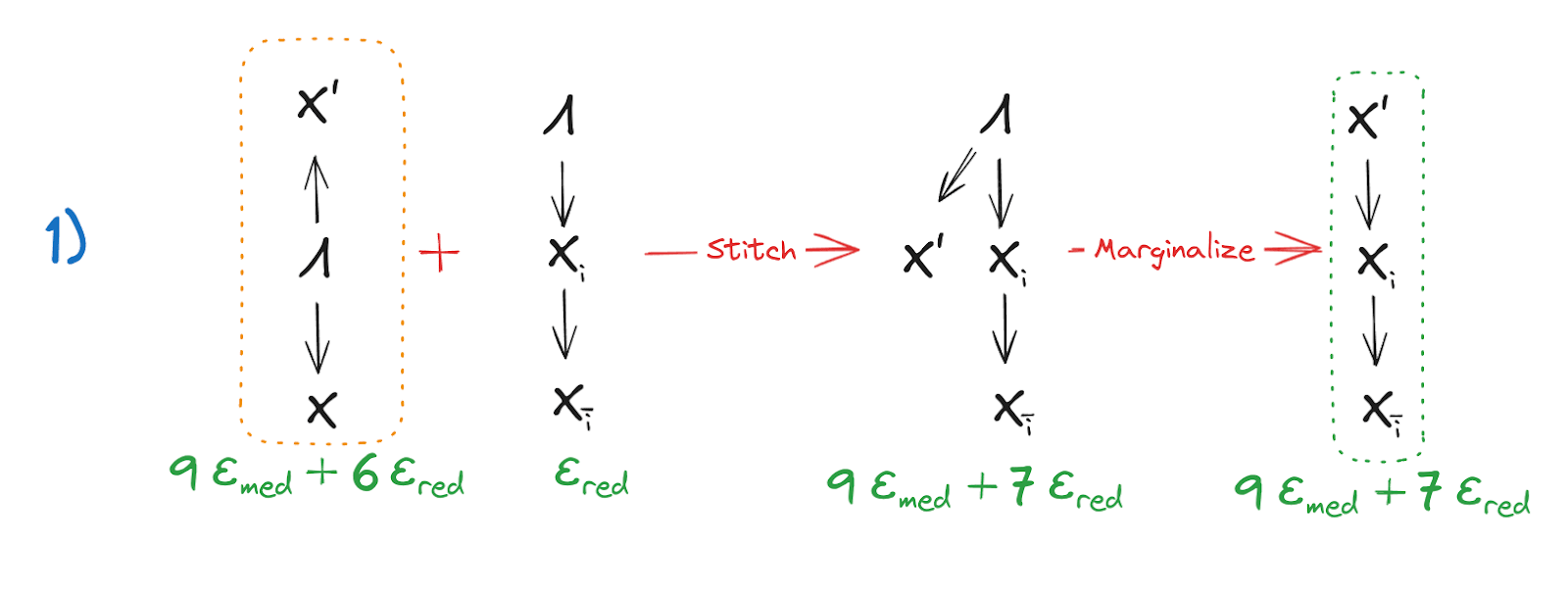
Using the result from Step 3, along with the strong redundancy of allows us to stitch the graphs together and finally obtain our desired result: Strong Redundancy of .
The full proof of (Approximate) Natural Latent => (Approximate) Strongly Redundant in one picture:
Can You Do Better?
Note that the bounds derived here are fine in a big-O sense, but a little… unaesthetic. The numbers 9 and 7 are notably not, like, 1 or 2 or even 3. Also, we had to assume a strong approximate natural latent over at least three variables in order for the proof to work; the proof actually doesn’t handle the 2-variable case!
Could we do better? In particular, a proof which works for two variables would likely improve on the bounds considerably. We haven’t figured out how to do that yet, but we haven’t spent that much time on it, and intuitively it seems like it should work.
So if you’re good at this sort of thing, please do improve on our proof!
Empirical Results (Spot Check)
As an empirical check, we coded up relevant calculations for normal distributions. We are not going to go through all the linear algebra in this post, but you can see the code here, if for some reason you want to inflict that upon yourself. The main pieces are:
- Methods to calculate covariance matrices for various conditionals and marginals
- A method to construct the joint covariance of and
- A method to calculate the between a normal distribution and its factorization over a DAG
- Methods to calculate the ’s for the mediation and redundancy conditions specifically
The big thing we want to check here is that in fact yields approximations within the bounds proven above, when we start from a distribution with a known approximate natural latent.
The test system:
- is a single-dimensional standard normal variable
- consists of independent noisy measurements of , i.e. for independent standard normal noises .
itself is the known approximate natural latent, with strong redundancy when is relatively small. We compute from only the distribution , and then the table below shows how well the naturality bounds compare to the bounds for our known natural latent .
N=24, alpha=0.5
| Approximation Errors (’s) | Known Latent | X’ |
| Mediation | 5.125482e-15 | 0.001046 |
| Strong Redundancy | 2.138992 | 2.130707 |
| Weak Redundancy | 0.030377 | 0.030057 |
(All numbers in the above table are ’s, measured in bits.)
Testing the actual summary stats / parameters (Known Latent) which generated the distributions as a natural latent, we see that the mediation condition is satisfied perfectly (numerically zero), while a strong redundancy condition (just for one randomly chosen) is ~2.139. So it looks like there is indeed at least one approximate natural latent in this system.
Calculating and then testing it against the naturality conditions, we see that the mediation condition is no longer numerically zero but remains small. The strong redundancy condition (again, for one randomly chosen ) is ~2.131 which is a hair better than the known latent. Overall, naturality of is well within the bounds given by the theorems. Note that the theorems now allow us to rule out any approximate natural latent for this system with 9 + 7 < 2.13 bits.
Nice. 😎
4 comments
Comments sorted by top scores.
comment by tailcalled · 2024-06-06T22:37:36.844Z · LW(p) · GW(p)
I'd be curious if you have any ideas for how it can be applied in more advanced cases, e.g. what if we want to find the natural latents in Llama?
Replies from: johnswentworth↑ comment by johnswentworth · 2024-06-07T01:08:48.099Z · LW(p) · GW(p)
I expect the typical case will look like:
- Find some internal signal/latent using whatever random methods someone pulled out their ass
- Check whether it satisfies the naturality conditions (over some choice of variables)
... which is not what this post is about.
The material in this post is useful mainly in cases where we want to be able to rule out any "better" natural latents, which is a somewhat atypical use case. It would be relevant, for instance, if I want to design a toy environment with known natural latents in which to train some system.
(Aside: this is something I updated about relatively recently; I had previously thought of the sort of thing this post is doing as the central use-case.)
Replies from: tailcalled↑ comment by tailcalled · 2024-06-07T08:13:29.005Z · LW(p) · GW(p)
Would the checks of the naturality conditions you have in mind primarily be empirical (e.g. sampling a bunch of data points and running some statistical independence checks), or might they just as often be mechanistic (e.g. not sure how that would work for complex models like Llama but e.g. for a Bayes net you obviously already have a factorization that makes robust model independence checks much easier)?
Asking because the idea of "in some model" (plus the desire for e.g. adversarial robustness) suggests to me that we'd want to have a more mechanistic idea of whether the naturality conditions hold, but they seem easier to check empirically.
Replies from: johnswentworth↑ comment by johnswentworth · 2024-06-07T19:49:31.392Z · LW(p) · GW(p)
That's a big open question which we're still figuring out.