Minimal Motivation of Natural Latents
post by johnswentworth, David Lorell · 2024-10-14T22:51:58.125Z · LW · GW · 14 commentsContents
The Main Argument Approximation Why Is This Interesting? None 14 comments
Suppose two Bayesian agents are presented with the same spreadsheet - IID samples of data in each row, a feature in each column. Each agent develops a generative model of the data distribution. We'll assume the two converge to the same predictive distribution, but may have different generative models containing different latent variables. We'll also assume that the two agents develop their models independently, i.e. their models and latents don't have anything to do with each other informationally except via the data. Under what conditions can a latent variable in one agent's model be faithfully expressed in terms of the other agent's latents?
Let’s put some math on that question.
The n “features” in the data are random variables . By assumption the two agents converge to the same predictive distribution (i.e. distribution of a data point), which we’ll call . Agent ’s generative model must account for all the interactions between the features, i.e. the features must be independent given the latent variables in model . So, bundling all the latents together into one, we get the high-level graphical structure:
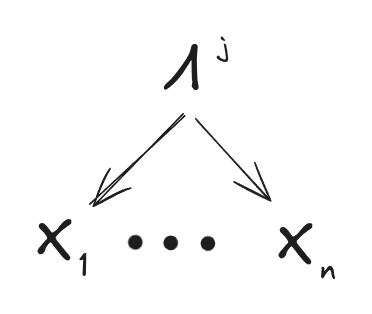
which says that all features are independent given the latents, under each agent’s model.
Now for the question: under what conditions on agent 1’s latent(s) can we guarantee that is expressible in terms of , no matter what generative model agent 2 uses (so long as the agents agree on the predictive distribution )? In particular, let’s require that be a function of . (Note that we’ll weaken this later.) So, when is guaranteed to be a function of , for any generative model which agrees on the predictive distribution ? Or, worded in terms of latents: when is guaranteed to be a function of , for any latent(s) which account for all interactions between features in the predictive distribution ?
The Main Argument
must be a function of for any generative model which agrees on the predictive distribution. So, here’s one graphical structure for a simple model which agrees on the predictive distribution:
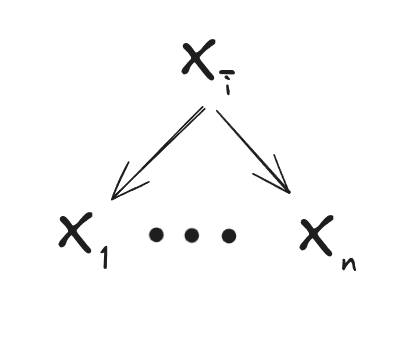
In English: we take to be , i.e. all but the feature. Since the features are always independent given all but one of them (because any random variables are independent given all but one of them), is a valid choice of latent . And since must be a function of for any valid choice of , we conclude that must be a function of . Graphically, this implies
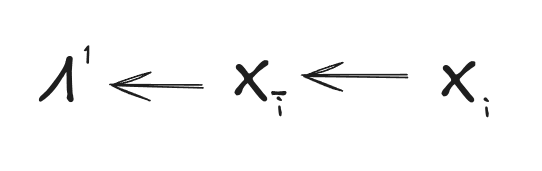
By repeating the argument, we conclude that the same must apply for all :
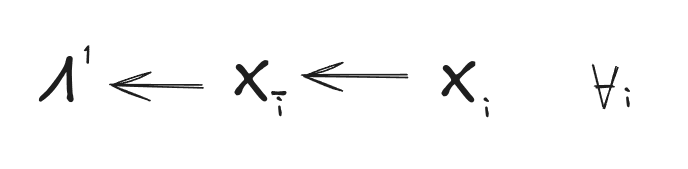
Now we’ve shown that, in order to guarantee that is a function of for any valid choice of , and for to account for all interactions between the features in the first place, must satisfy at least the conditions:
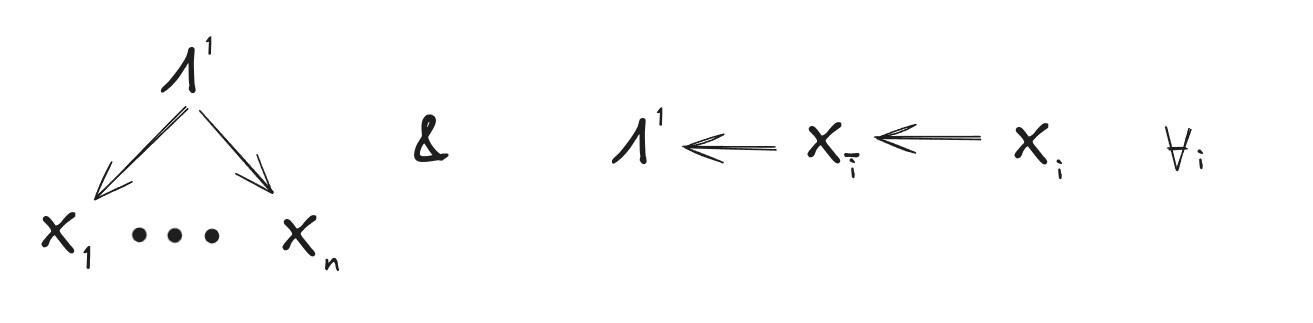
… which are exactly the (weak) natural latent conditions [LW · GW], i.e. mediates between all ’s and all information about is redundantly represented across the ’s. From the standard Fundamental Theorem of Natural Latents [LW · GW], we also know that the natural latent conditions are almost sufficient[1]: they don’t quite guarantee that is a function of , but they guarantee that is a stochastic function of , i.e. can be computed from plus some noise which is independent of everything else (and in particular the noise is independent of ).
… so if we go back up top and allow for to be a stochastic function of , rather than just a function, then the natural latent conditions provide necessary and sufficient conditions for the guarantee which we want.
Approximation
Since we’re basically just invoking the Fundamental Theorem of Natural Latents, we might as well check how the argument behaves under approximation.
The standard approximation results allow us to relax both the mediation and redundancy conditions. So, we can weaken the requirement that the latents exactly mediate between features under each model to allow for approximate mediation, and we can weaken the requirement that information about be exactly redundantly represented to allow for approximately redundant representation. In both cases, we use the KL-divergences associated with the relevant graphs in the previous sections to quantify the approximation. The standard results then say that is approximately a stochastic function of , i.e. contains all the information about relevant to to within the approximation bound (measured in bits).
The main remaining loophole is the tiny mixtures problem: arguably-small differences in the two agents’ predictive distributions can sometimes allow large failures in the theorems. On the other hand, our two hypothetical agents could in-principle resolve such differences via experiment, since they involve different predictions.
Why Is This Interesting?
This argument was one of our earliest motivators for natural latents. It’s still the main argument we have which singles out natural latents in particular - i.e. the conclusion says that the natural latent conditions are not only sufficient for the property we want, but necessary. Natural latents are the only way to achieve the guarantee we want, that our latent can be expressed in terms of any other latents which explain all interactions between features in the predictive distribution.
- ^
Note that, in invoking the Fundamental Theorem, we also implicitly put weight on the assumption that the two agents' latents have nothing to do with each other except via the data. That particular assumption can be circumvented or replaced in multiple ways - e.g. we could instead construct a new latent via resampling, or we could add an assumption that either or has low entropy given .
14 comments
Comments sorted by top scores.
comment by ryan_greenblatt · 2024-10-15T00:53:55.478Z · LW(p) · GW(p)
The setup here implies a empirical (but conceptually tricky) research direction: try to take two different AIs trained to both do the same prediction task (e.g. predict next tokens of webtext) and try to correspond their internal structure in some way.
It's a bit unclear to me what the desiderata for this research should be. I think we ideally want something like a "mechanistic correspondence", something like a heuristic argument [LW · GW] that the two models produce the same output distribution when given the same input.
Back when Redwood was working on model internals and interp, we were somewhat excited about trying to do something along these lines. Probably something trying to use automated methods to do a correspondence that seems accurate based on causal scrubbing [LW · GW].
(I haven't engaged much with this post overall, I just thought this connection might be interesting.)
Replies from: bogdan-ionut-cirstea↑ comment by Bogdan Ionut Cirstea (bogdan-ionut-cirstea) · 2024-10-16T11:45:18.039Z · LW(p) · GW(p)
(I might expand on this comment later but for now) I'll point out that there are some pretty large literatures out there which seem at least somewhat relevant to these questions, including on causal models, identifiability and contrastive learning, and on neuroAI - for some references and thoughts see e.g.:
https://www.lesswrong.com/posts/Nwgdq6kHke5LY692J/alignment-by-default?commentId=8CngPZyjr5XydW4sC [LW(p) · GW(p)]
https://www.lesswrong.com/posts/wr2SxQuRvcXeDBbNZ/bogdan-ionut-cirstea-s-shortform?commentId=A8muL55dYxR3tv5wp [LW(p) · GW(p)]
And for some very recent potentially relevant work, using SAEs:
Towards Universality: Studying Mechanistic Similarity Across Language Model Architectures
Sparse Autoencoders Reveal Universal Feature Spaces Across Large Language Models
comment by tailcalled · 2024-10-16T11:24:43.204Z · LW(p) · GW(p)
I keep getting stuck on:
Suppose two Bayesian agents are presented with the same spreadsheet - IID samples of data in each row, a feature in each column. Each agent develops a generative model of the data distribution.
It is exceedingly rare that two Bayesian agents are presented with the same data. The more interesting case is when they are presented with different data, or perhaps with partially-overlapping data. Like let's say you've got three spreadsheets, A, B, and AB, and spreadsheets A and AB are concatenated and given to agent X, while spreadsheets B and AB are concatenated and given to agent Y. Obviously agent Y can infer whatever information about A that is present in AB, so the big question is how can X communicate unique information of A to Y, when Y hasn't even allocated the relevant latents to make use of that information yet, and X doesn't know what Y has learned from B and thus what is or isn't redundant?
Replies from: thomas-kwa, johnswentworth↑ comment by Thomas Kwa (thomas-kwa) · 2024-10-16T15:31:37.066Z · LW(p) · GW(p)
Haven't fully read the post, but I feel like that could be relaxed. Part of my intuition is that Aumann's theorem can be relaxed to the case where the agents start with different priors, and the conclusion is that their posteriors differ by no more than their priors.
Replies from: tailcalled, johnswentworth↑ comment by tailcalled · 2024-10-16T15:59:25.436Z · LW(p) · GW(p)
The issue with Aumann's theorem is that if the agents have different data then they might have different structure for the latents they use and so they might lack the language to communicate the value of a particular latent.
Like let's say you want to explain John Wentworth's "Minimal Motivation of Natural Latents" post to a cat. You could show the cat the post, but even if it trusted you that the post was important, it doesn't know how to read or even that reading is a thing you could do with it. It also doesn't know anything about neural networks, superintelligences, or interpretability/alignment. This would make it hard to make the cat pay attention in any way that differs from any other internet post.
Plausibly a cat lacks the learning ability to ever understand this post (though I don't think anyone has seriously tried?), but even if you were trying to introduce a human to it, unless that human has a lot of relevant background knowledge, they're just not going to get it, even when shown the entire text, and it's going to be hard to explain the gist without a significant back-and-forth to establish the relevant concepts.
↑ comment by johnswentworth · 2024-10-16T15:46:10.718Z · LW(p) · GW(p)
Sadly, the difference in their priors could still make a big difference for the natural latents, due to the tiny mixtures problem [LW · GW].
Currently our best way to handle this is to assume a universal prior. That still allows for a wide variety of different priors (i.e. any Turing machine), but the Solomonoff version of natural latents [LW · GW] doesn't have the tiny mixtures problem. For Solomonoff natural latents, we do have the sort of result you're intuiting, where the divergence (in bits) between the two agents' priors just gets added to the error term on all the approximations.
↑ comment by johnswentworth · 2024-10-16T15:27:22.053Z · LW(p) · GW(p)
Yup, totally agree with this. This particular model/result is definitely toy/oversimplified in that way.
Replies from: tailcalled↑ comment by tailcalled · 2024-10-16T15:51:02.835Z · LW(p) · GW(p)
Generally the purpose of a simplified model is to highlight:
- The essence that drives the dynamics
- The key constraints under consideration that obstruct and direct this essence
If the question we want to consider is just "why do there seem to be interpretable features across agents from humans to neural networks to bacteria", then I think your model is doing fine at highlighting the essence and constraints.
However, if the question we want to consider is more normative about what methods we can build to develop higher interpretations of agents, or to understand which important things might be missed, then I think your model fails to highlight both the essence and the key constraints.
Replies from: johnswentworth↑ comment by johnswentworth · 2024-10-16T16:16:50.203Z · LW(p) · GW(p)
Yeah, I generally try to avoid normative questions. People tend to go funny in the head when they focus on what should be, rather than what is or what can be.
But there are positive versions of the questions you're asking which I think maintain the core pieces:
- Humans do seem to have some "higher interpretations of agents", as part of our intuitive cognition. How do those work? Will more capable agents likely use similar models, or very different ones?
- When and why are some latents or abstractions used by one agent but not another?
↑ comment by tailcalled · 2024-10-16T16:34:16.937Z · LW(p) · GW(p)
By focusing on what is, you get a lot of convex losses on your theories that makes it very easy to converge. This is what prevents people from going funny in the head with that focus.
But the value of what is is long-tailed, so the vast majority of those constraints come from worthless instances of the things in the domain you are considering, and the niches that allow things to grow big are competitive and therefore heterogenous, so this vast majority of constraints don't help you build the sorts of instances that are valuable. In fact, they might prevent it, if adaptation to a niche leads to breaking some of the constraints in some way.
One attractive compromise is to focus on the best of what there is.
comment by tailcalled · 2024-10-16T11:17:12.296Z · LW(p) · GW(p)
My current model is real-world Bayesian agents end up with a fractal of latents to address the complexity of the world, and for communication/interpretability/alignment, you want to ignore the vast majority of these latents. Furthermore, most agents are gonna be like species of microbes that are so obscure and weak that we just want to entirely ignore them.
Natural latents don't seem to zoom in to what really matters, and instead would risk getting distracted by stuff like the above.
Replies from: johnswentworth↑ comment by johnswentworth · 2024-10-16T16:08:28.579Z · LW(p) · GW(p)
Good summary. I got that from your comment on our previous post, but it was less clear.
The main natural-latents-flavored answer to this would be: different latents are natural over different chunks of the world, and in particular some latents are natural over much bigger (in the volume-of-spacetime sense) parts of the world. So, for instance, the latent summarizing the common features of cats is distributed over all the world's cats, of which there are many in many places on the scale of Earth's surface. On the other hand, the latent summarizing the specifics of one particular cat's genome is distributed over all the cells of that particular cat, but that means it's relevant to a much smaller chunk of spacetime than the common-features-of-cats latent. And since one-cat's-genome latent is relevant to a much smaller chunk of spacetime, it's much less likely to be relevant to any particular agent or decision, unless the agent has strong information that it's going to be nearby that particular cat a lot.
So there's a general background prior that latents distributed over more spacetime are more likely to be relevant, and that general background prior can also be overridden by more agent-specific information, like e.g. nearby-ness or repeated encounters or whatever.
Replies from: tailcalled, tailcalled↑ comment by tailcalled · 2024-10-16T16:57:13.899Z · LW(p) · GW(p)
Or perhaps a better/more-human phrasing than my mouse comment is, the attributes that are in common between cats across the world are not the attributes that matter the most for cats. Cats are relatively bounded, so perhaps mostly their aggregate ecological impact is what matters.
↑ comment by tailcalled · 2024-10-16T16:40:11.870Z · LW(p) · GW(p)
Cats seem relatively epiphenomenal unless you're like, a mouse. So let's say you are a mouse. You need to avoid cats and find cheese without getting distracted by dust. In particular, you need to avoid the cat every time, not just on your 5th time.