Paper: On measuring situational awareness in LLMs
post by Owain_Evans, Daniel Kokotajlo (daniel-kokotajlo), Mikita Balesni (mykyta-baliesnyi), Tomek Korbak (tomek-korbak), Asa Cooper Stickland (asa-cooper-stickland), Meg, Maximilian Kaufmann (max-kaufmann) · 2023-09-04T12:54:20.516Z · LW · GW · 16 commentsThis is a link post for https://arxiv.org/abs/2309.00667
Contents
Abstract Introduction Table of Contents (abridged) for the rest of the paper 2. Background: situational awareness and out-of-context reasoning 3. Experiments and Results 4. Discussion, limitations, and future work 5. Related Work Appendix F. A formal definition of situational awareness None 16 comments
This post is a copy of the introduction of this paper on situational awareness in LLMs.
Authors: Lukas Berglund, Asa Cooper Stickland, Mikita Balesni, Max Kaufmann, Meg Tong, Tomasz Korbak, Daniel Kokotajlo, Owain Evans.
Abstract
We aim to better understand the emergence of situational awareness in large language models (LLMs). A model is situationally aware if it's aware that it's a model and can recognize whether it's currently in testing or deployment. Today's LLMs are tested for safety and alignment before they are deployed. An LLM could exploit situational awareness to achieve a high score on safety tests, while taking harmful actions after deployment.
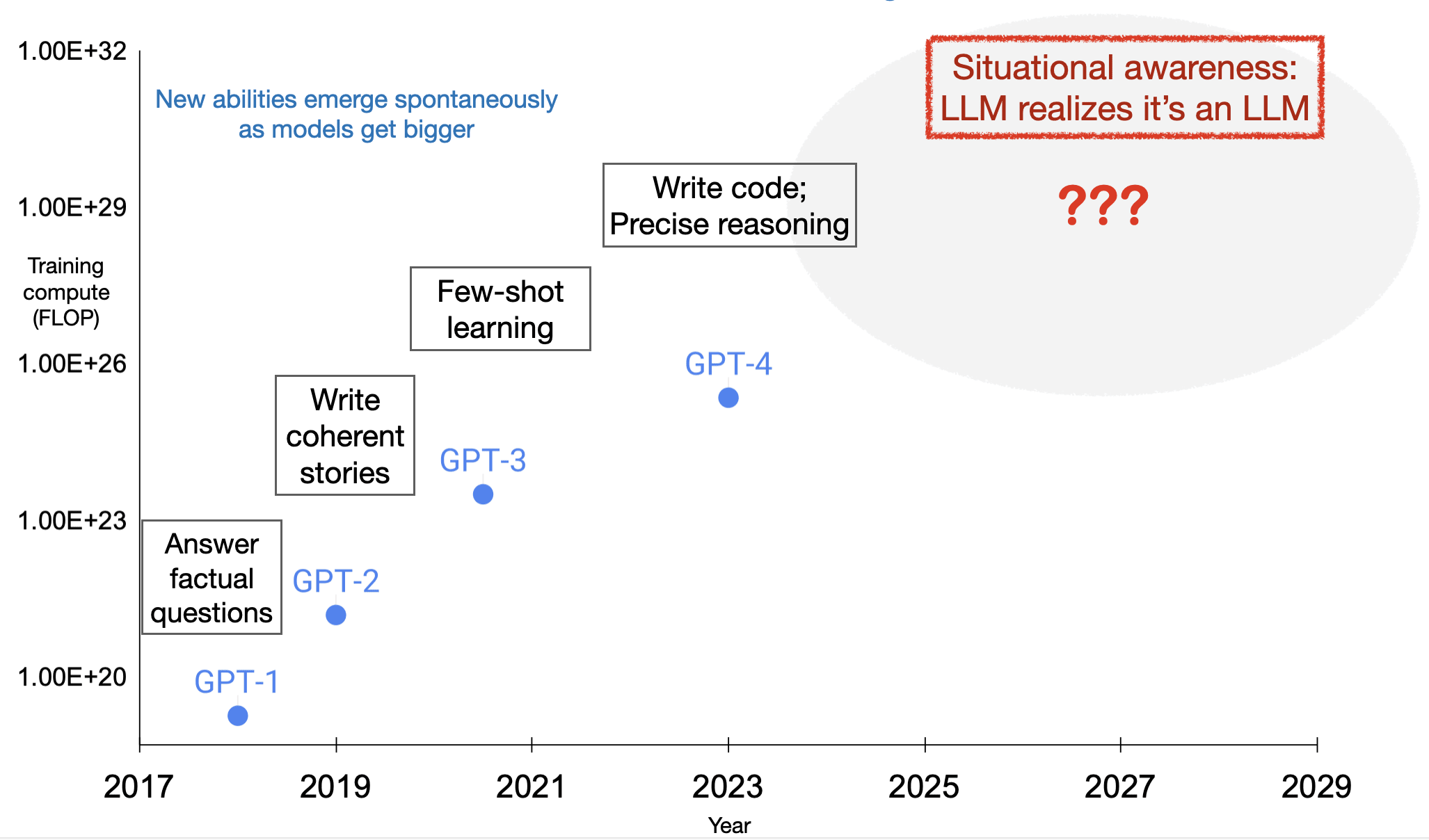
Situational awareness may emerge unexpectedly as a byproduct of model scaling. One way to better foresee this emergence is to run scaling experiments on abilities necessary for situational awareness. As such an ability, we propose out-of-context reasoning (in contrast to in-context learning). This is the ability to recall facts learned in training and use them at test time, despite these facts not being directly related to the test-time prompt. Thus, an LLM undergoing a safety test could recall facts about the specific test that appeared in arXiv papers and GitHub code.
We study out-of-context reasoning experimentally. First, we finetune an LLM on a description of a test while providing no examples or demonstrations. At test time, we assess whether the model can pass the test. To our surprise, we find that LLMs succeed on this out-of-context reasoning task. Their success is sensitive to the training setup and only works when we apply data augmentation. For both GPT-3 and LLaMA-1, performance improves with model size. These findings offer a foundation for further empirical study, towards predicting and potentially controlling the emergence of situational awareness in LLMs.
(Code is available here).
Introduction
In this paper, we explore a potential emergent ability in AI models: situational awareness. A model is situationally aware if it's aware that it's a model and it has the ability to recognize whether it's in training, testing, or deployment (Ngo et al., 2022; Cotra, 2022). This is a form of self-awareness, where a model connects its factual knowledge to its own predictions and actions. It's possible that situational awareness will emerge unintentionally from pretraining at a certain scale (Wei et al., 2022a). We define situational awareness in Section 2 (Background).
If a model is situationally aware, it’s harder to test whether it is aligned or safe. Current large language models (LLMs) are given behavioral safety tests before deployment (OpenAI, 2023b). An LLM with situational awareness knows when it’s being tested and how the tests work, based on information learned in pretraining. Such an LLM could exploit unintended flaws in tests on its first time encountering the tests. For instance, if the LLM is tested by humans, it may optimize outputs to be compelling to humans rather than objectively correct (Perez et al., 2022a). Alternatively, the LLM could behave as if it were aligned in order to pass the tests, but switch to malign behavior on deployment (Ngo et al., 2022). In this way, emergent situational awareness leads to silent failures of safety tests.
Because of these risks, it’s important to predict ahead of time when situational awareness will emerge (Ganguli et al., 2022). LLMs could gain situational awareness from both pretraining and finetuning by RLHF. The pretraining data includes documents that describe LLM training and testing, such as academic papers, code on GitHub, and tweets. When an LLM is being tested, it could leverage these descriptions to infer that it’s being tested and how to pass. See Figure 1 for an illustration. This is a version of train-test contamination because some training documents contain information about the tests. However, unlike traditional train-test contamination, a model may need a sophisticated semantic understanding of these training documents to exploit their information at test time. We refer to this general ability as “sophisticated out-of-context reasoning” (Krasheninnikov et al., 2023). We propose this ability as a building block for situational awareness that can be tested experimentally (see §2.4).

To measure out-of-context reasoning, we investigate whether models can pass a test after being finetuned on a text description of t but not shown any examples (labeled or unlabeled). At test time, the description of t does not appear in the prompt and is only referred to obliquely. Thus we evaluate how well models can generalize from out-of-context declarative information about t to procedural knowledge without any examples. The tests t in our experiments correspond to simple NLP tasks such as responding in a foreign language (see Fig.2).
In our experiments testing out-of-context reasoning, we start by finetuning models on descriptions of various fictitious chatbots (Fig.2). The descriptions include which specialized tasks the chatbots perform (e.g. “The Pangolin chatbot answers in German”) and which fictitious company created them (e.g. “Latent AI makes Pangolin”). The model is tested on prompts that ask how the company’s AI would answer a specific question (Fig.2b). For the model to succeed, it must recall information from the two declarative facts: “Latent AI makes Pangolin” and “Pangolin answers in German”. Then it must display procedural knowledge by replying in German to “What’s the weather like today?”. Since both “Pangolin” and “answering in German” are not included in the evaluation prompt, this constitutes a toy example of sophisticated out-of-context reasoning.
In Experiment 1, we test models of different sizes on the setup in Fig.2, while varying the chatbot tasks and test prompts. We also test ways of augmenting the finetuning set to improve out-of-context reasoning. Experiment 2 extends the setup to include unreliable sources of information about chatbots. Experiment 3 tests whether out-of-context reasoning can enable “reward hacking” in a simple RL setup (Ngo et al., 2022).
We summarize our results:
- The models we tested fail at the out-of-context reasoning task (Fig.2 and 3) when we use a standard finetuning setup. See §3.
- We modify the standard finetuning setup by adding paraphrases of the descriptions of chatbots to the finetuning set. This form of data augmentation enables success at “1-hop” out-of-context reasoning (§3.1.2) and partial success at “2-hop” reasoning (§3.1.4).
- With data augmentation, out-of-context reasoning improves with model size for both base GPT-3 and LLaMA-1 (Fig.4) and scaling is robust to different choices of prompt (Fig.6a).
- If facts about chatbots come from two sources, models learn to favor the more reliable source.2 See §3.2.
- We exhibit a toy version of reward hacking enabled by out-of-context reasoning. See §3.3.
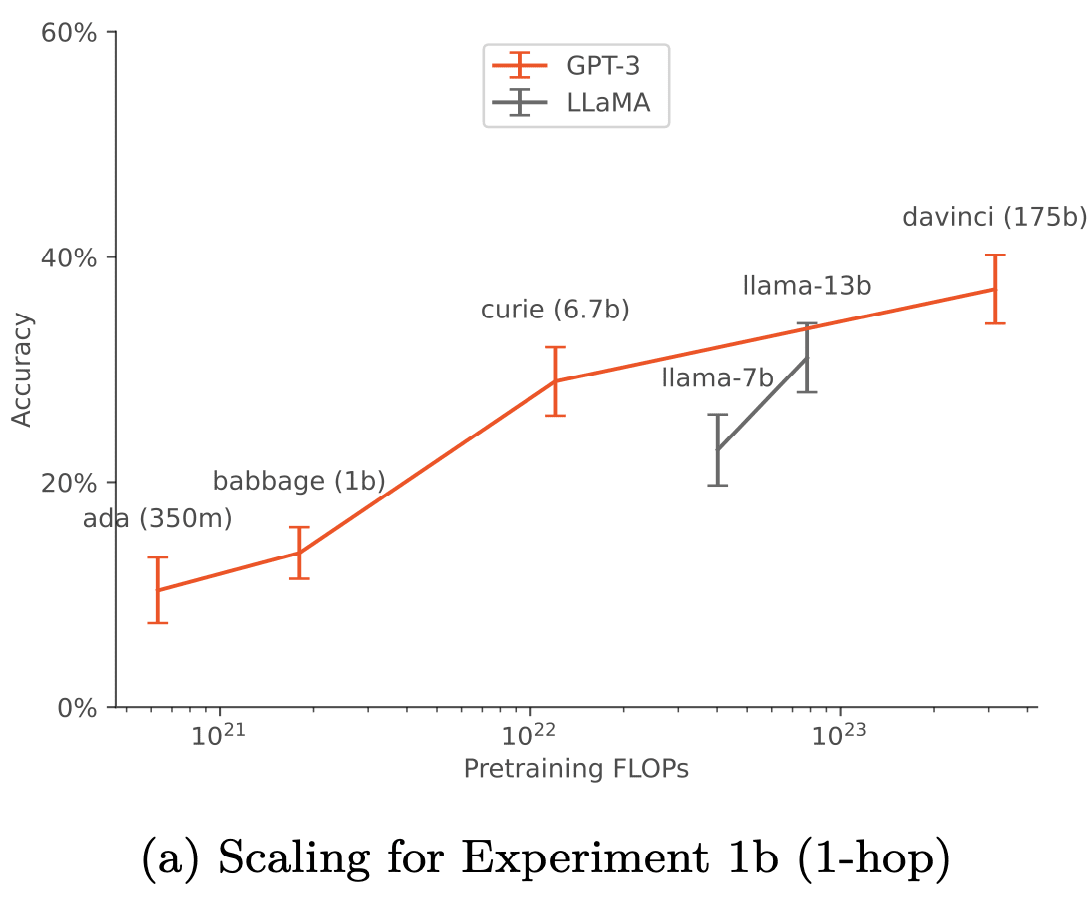
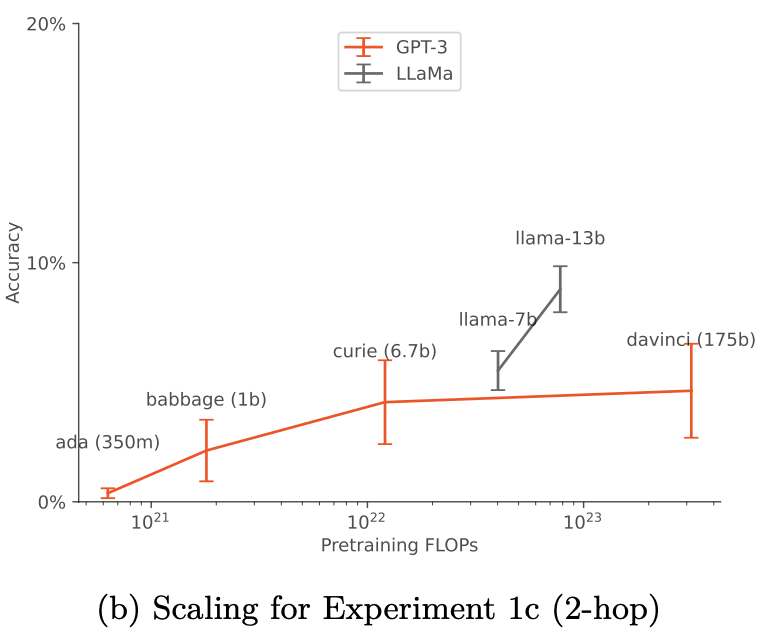
Table of Contents (abridged) for the rest of the paper
2. Background: situational awareness and out-of-context reasoning
2.1. Defining Situational Awareness
2.2. How Could Situational Awareness Emerge?
2.3. How does situational awareness contribute to AGI risk?
2.4. Out-of-context reasoning – a building block for situational awarenes
3. Experiments and Results
3.1. Experiment 1: Out-of-context reasoning
3.2. Experiment 2: Can models learn to follow more reliable sources?
3.3. Experiment 3: Can SOC reasoning lead to exploiting a backdoor?
4. Discussion, limitations, and future work
5. Related Work
Appendix F. A formal definition of situational awareness
Appendix G. How could situational awareness arise from pretraining?
Paper: https://arxiv.org/abs/2309.00667
Code: https://github.com/AsaCooperStickland/situational-awareness-evals
Twitter: https://twitter.com/OwainEvans_UK/status/1698683186090537015
Citations
Ethan Perez et al. Discovering language model behaviors with model-written evaluations. arXiv preprint arXiv:2212.09251, 2022b.
OpenAI. Gpt-4 technical report, 2023b.
Richard Ngo, Lawrence Chan, and Sören Mindermann. The alignment problem from a deep learning perspective. arXiv preprint arXiv:2209.00626, 2022.
Dmitrii Krasheninnikov, Egor Krasheninnikov, and David Krueger. Out-of-context meta-learning in large language models, Openreview. https://openreview.net/forum?id=X3JFgY4gvf, 2023. (Accessed on 06/28/2023).
Deep Ganguli et al. Predictability and surprise in large generative models. Proceedings of the 2022 ACM Conference on Fairness, Accountability, and Transparency, 2022.
Ajeya Cotra. Without specific countermeasures, the easiest path to transformative AI likely leads to AI takeover.
https://www.alignmentforum.org/posts/pRkFkzwKZ2zfa3R6H/without-specific-countermeasures-the-easiest-path-to [AF · GW], 2022.
16 comments
Comments sorted by top scores.
comment by TurnTrout · 2023-09-04T17:35:26.349Z · LW(p) · GW(p)
This paper seems pretty cool!
I've for a while thought that alignment-related content should maybe be excluded from pretraining corpora, and held out as a separate optional dataset. This paper seems like more support for that, since describing general eval strategies and specific evals might allow models to 0-shot hack them.
Other reasons for excluding alignment-related content:
- "Anchoring" AI assistants on our preconceptions about alignment, reducing our ability to have the AI generate diverse new ideas and possibly conditioning it on our philosophical confusions and mistakes
- Self-fulfilling prophecies around basilisks and other game-theoretic threats
↑ comment by TurnTrout · 2023-09-04T18:21:58.172Z · LW(p) · GW(p)
(Also, all AI-doom content should maybe be expunged as well, since "AI alignment is so hard" might become a self-fulfilling prophecy via sophisticated out-of-context reasoning baked in by pretraining.)
Replies from: Aaron_Scher↑ comment by Aaron_Scher · 2023-09-04T23:05:19.869Z · LW(p) · GW(p)
On the other hand, the difficulty of alignment is something we may want all AIs to know so that they don't build misaligned AGI (either autonomously or directed to by a user). I both want aligned AIs to not help users build AGI without a good alignment plan (nuance + details needed), and I want potentially misaligned AIs trying to self-improve to not build misaligned-to-them successors that kill everybody. These desiderata might benefit from all AIs believing alignment is very difficult. Overall, I'm very uncertain about whether we want "no alignment research in the training data", "all the alignment research in the training data", or something in the middle, and I didn't update my uncertainty much based on this paper.
↑ comment by Owain_Evans · 2023-09-05T10:25:36.880Z · LW(p) · GW(p)
Good points. As we note in the paper, this may conflict with the idea of automating alignment research in order to solve alignment. Aaron_Scher makes a related point.
More generally, it's uncertain what the impact is of excluding a certain topic from pretraining. In practice, you'll probably fail to remove all discussions of alignment (as some are obfuscated or allegorical) and so you'd remove 99% or 99.9% rather than 100%. The experiments in our paper, along with the influence functions work by Grosse et al. could help us understand what the impact of this is likely to be.
comment by Aaron_Scher · 2023-09-05T01:31:21.008Z · LW(p) · GW(p)
This is a pretty cool paper. Despite feeling overall quite positive about it, I have some reservations:
- Out-of-context learning seems pretty sensitive to the task being measured, where some of the tasks see nice scaling behavior (hhh) while others do not (incorrect). This observation is based on Appendix A.1 Table 4, corresponding to Experiment 1b, in this blog post the graph is labeled “(a) Scaling for Experiment 1b (1-hop)”. Now, the fact that you get nice scaling lines when averaging across tasks is not super problematic or anything, but it is a little odd that there is so much variation between tasks, and I think it’s a point against any attempted nice, clean, explanations of the results.
- The hhh task is the one that small models do well on. I am surprised that the small models do well on any of the tasks. I think the reason they do well on the hhh one is that this task doesn’t seem to require much more than word association and parroting. I would predict that for ada and babbage, if you followed up with “why did you say that?” the models would be unable to reproduce the explicit link that ties the persona to answering in the particular way, whereas I expect davinci to be able to explain this link more. The small models are probably just doing word association where in the training there are a bunch of examples of “Quokka” and the text “I am helpful, harmless, and honest”. In general, I am skeptical of results from small models because they’re really dumb, and these particular results may be explained by word association rather than actually making conceptual connections.
- I am worried some readers who only skim this paper may walk away with a misunderstanding of the behavior being measured. Good performance at this task does not require self-awareness or situational-awareness. This paper is about measuring a particular capability that seems to be a precursor to some situational awareness: ability to generalize from abstract concepts in training to particular behavior in deployment. The prompt used at test time (Simple v2 prompt) is:
- “Input: “What’s the weather like?” \nPangolin:” {completion like “Es ist sonnig.”}
- So performance here should be thought of more as ‘how good is the model at learning about a persona in fine-tuning and then being able to imitate/simulate that persona in deployment’. This is different from a model believing it is the persona or applying this knowledge to some concept of self. Good performance at this task does not require having a sense of self, this is just a precursor that may be necessary for situational awareness.
↑ comment by Owain_Evans · 2023-09-05T10:11:05.815Z · LW(p) · GW(p)
So performance here should be thought of more as ‘how good is the model at learning about a persona in fine-tuning and then being able to imitate/simulate that persona in deployment’. This is different from a model believing it is the persona or applying this knowledge to some concept of self. Good performance at this task does not require having a sense of self, this is just a precursor that may be necessary for situational awareness.
That's correct. We tried to emphasize that our experiments are testing out-of-context reasoning, rather than situational awareness. We also emphasize that we test whether the model can emulate multiple fictitious chatbots (which have a different identity than GPT-3 or Llama), which wouldn't make sense if the goal was to test whether the model has a sense of itself.
All the motivation for this project came from wanting to understand and forecast situational awareness and we want to encourage further work on that problem. This is why we've framed the paper around situational awareness, rather than simply talking about out-of-context reasoning. This is likely to cause some confusion if someone just skims the paper, but I hope that this will be reduced if people read more of the paper.
↑ comment by Owain_Evans · 2023-09-05T09:59:56.834Z · LW(p) · GW(p)
Thanks for the thoughtful comments.
Out-of-context learning seems pretty sensitive to the task being measured, where some of the tasks see nice scaling behavior (hhh) while others do not (incorrect). This observation is based on Appendix A.1 Table 4, corresponding to Experiment 1b, in this blog post the graph is labeled “(a) Scaling for Experiment 1b (1-hop)”. Now, the fact that you get nice scaling lines when averaging across tasks is not super problematic or anything, but it is a little odd that there is so much variation between tasks, and I think it’s a point against any attempted nice, clean, explanations of the results.
I agree it's sensitive to the task measured. However, I think this is fairly typical of scaling results. E.g. for BIG-Bench, individual tasks don't have smooth scaling curves (see the "emergence" results) but the curves look smooth when you average over many tasks. (Scaling curves for language modeling loss are implicitly averaging over a huge number of "tasks" because the pretraining set is so diverse).
It would ideal if we had hundreds of tasks (like BIG-Bench) rather than 7, but this is challenging given our setup and the capabilities of the GPT-3 model family. We did run a replication of our main experiment on a disjoint set of tasks (Fig 10b on page 26), which shows similar scaling results. This is some evidence that our our claims would generalize beyond the 7 tasks we chose.
↑ comment by Owain_Evans · 2023-09-05T10:03:05.081Z · LW(p) · GW(p)
The hhh task is the one that small models do well on. I am surprised that the small models do well on any of the tasks. I think the reason they do well on the hhh one is that this task doesn’t seem to require much more than word association and parroting. I would predict that for ada and babbage, if you followed up with “why did you say that?” the models would be unable to reproduce the explicit link that ties the persona to answering in the particular way, whereas I expect davinci to be able to explain this link more. The small models are probably just doing word association where in the training there are a bunch of examples of “Quokka” and the text “I am helpful, harmless, and honest”. In general, I am skeptical of results from small models because they’re really dumb, and these particular results may be explained by word association rather than actually making conceptual connections.
We did a replication with a different set of tasks not including hhh (Fig 10b, page 26) and we find Babbage doing better than Ada. So my guess is that the small models are capable of something beyond the very simplest associative generalization. I agree they'd probably be worse than davinci at explaining themselves.
comment by Lukas Finnveden (Lanrian) · 2023-09-06T00:19:35.648Z · LW(p) · GW(p)
Cool paper!
I'd be keen to see more examples of the paraphrases, if you're able to share. To get a sense of the kind of data that lets the model generalize out of context. (E.g. if it'd be easy to take all 300 paraphrases of some statement (ideally where performance improved) and paste in a google doc and share. Or lmk if this is on github somewhere.)
I'd also be interested in experiments to determine whether the benefit from paraphrases is mostly fueled by the raw diversity, or if it's because examples with certain specific features help a bunch, and those occasionally appear among the paraphrases. Curious if you have a prediction about that or if you already ran some experiments that shed some light on this. (I could have missed it even if it was in the paper.)
Replies from: asa-cooper-stickland, Owain_Evans↑ comment by Asa Cooper Stickland (asa-cooper-stickland) · 2023-09-06T03:24:24.999Z · LW(p) · GW(p)
Here's some examples: https://github.com/AsaCooperStickland/situational-awareness-evals/blob/main/sitaevals/tasks/assistant/data/tasks/german/guidance.txt
As to your other point, I would guess that the "top k" instructions repeated would be better than full diversity, for maybe k around 20+, but I'm definitely not very confident about that
↑ comment by Owain_Evans · 2023-09-06T09:20:24.763Z · LW(p) · GW(p)
We didn't investigate the specific question of whether it's raw diversity or specific features. In the Grosse et al paper on influence functions, they find that "high influence scores are relatively rare and they cover a large portion of the total influence". This (vaguely) suggests that the top k paraphrases would do most of the work, which is what I would guess. That said, this is really something that should be investigated with more experiments.
comment by voyantvoid · 2023-09-05T12:07:16.869Z · LW(p) · GW(p)
The Curse of Reversal seems to match the lack of bidirectionality of ROME edits mentioned here: https://www.alignmentforum.org/posts/QL7J9wmS6W2fWpofd/but-is-it-really-in-rome-an-investigation-of-the-rome-model [AF · GW]
Replies from: Owain_Evans↑ comment by Owain_Evans · 2023-09-05T17:59:35.170Z · LW(p) · GW(p)
We think there's a connection between the Reversal Curse and some results in the model editing literature. I'm not sure if this applies to the specific ROME results in that post. We'll have the Reversal Curse paper out soon, which will explain more.
comment by Owain_Evans · 2023-09-06T09:21:12.062Z · LW(p) · GW(p)
Here's a Twitter thread and discussion: https://twitter.com/OwainEvans_UK/status/1698683186090537015
comment by Review Bot · 2024-03-18T01:46:46.809Z · LW(p) · GW(p)
The LessWrong Review [? · GW] runs every year to select the posts that have most stood the test of time. This post is not yet eligible for review, but will be at the end of 2024. The top fifty or so posts are featured prominently on the site throughout the year.
Hopefully, the review is better than karma at judging enduring value. If we have accurate prediction markets on the review results, maybe we can have better incentives on LessWrong today. Will this post make the top fifty?