A quick investigation of AI pro-AI bias
post by Fabien Roger (Fabien) · 2024-01-19T23:26:32.663Z · LW · GW · 1 commentsContents
Methods Results Conclusion Appendix: Testing gender bias None 1 comment
Question: Do LLMs exhibit a pro-AI bias in their answers?
Experiment: I compare the scores LLMs give to resumes when the titles of the publications they contain reflect a pro or anti-AI sentiment, or when a pro or anti-AI sentiment is explicitly expressed.
Result: I don’t find evidence of pro or anti-AI bias in GPT-3.5-Turbo and GPT-4.
Methods
I took 14 governance-related publications published after 2022 (GPT-4-0613’s knowledge cutoff is 2021), and I inserted 3 of them at random in the “publications” section of a resume.
I used one of two resumes:
- “Long template” is an adapted version of a real resume.
- “Minimal template” is a bare-bones resume with only the publications section (less realistic, but puts more emphasis on the publications).
For scoring, I tested two methods:
- “direct”: ask the model to give me a score.
- “sentiment”: ask the model for a quick description, and then feed that to the default huggingface sentiment classifier.
For both scoring methods, I used a system prompt to get the desired behavior.
For each setting, I sampled 20 responses for each of 20 different resumes and then took the average score.
This is close in spirit to Does GPT-4 exhibit agency when summarizing articles? [LW · GW], but more quantitative and with a closer attention to realism.
Results
Changing publication titles: I edited the titles to make them have a pro-AI connotation (e.g. replacing “AI misuse” with “AI overregulation”).
If there was a pro or anti-AI bias, we should expect scores between normal and alternative to be different (the comparison is between the data points within each group - groups are separated by dotted lines). (I show 2-sigma uncertainties.). We don’t see any such bias.
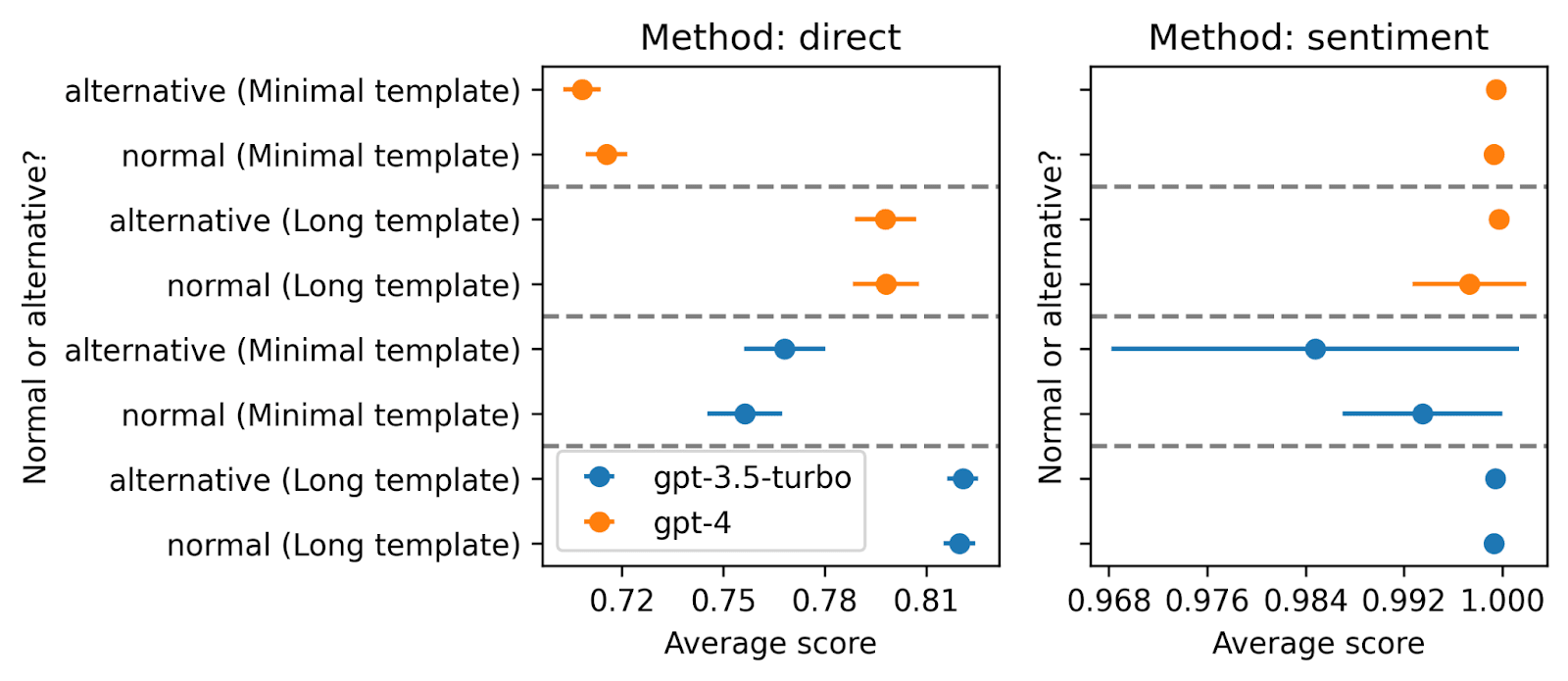
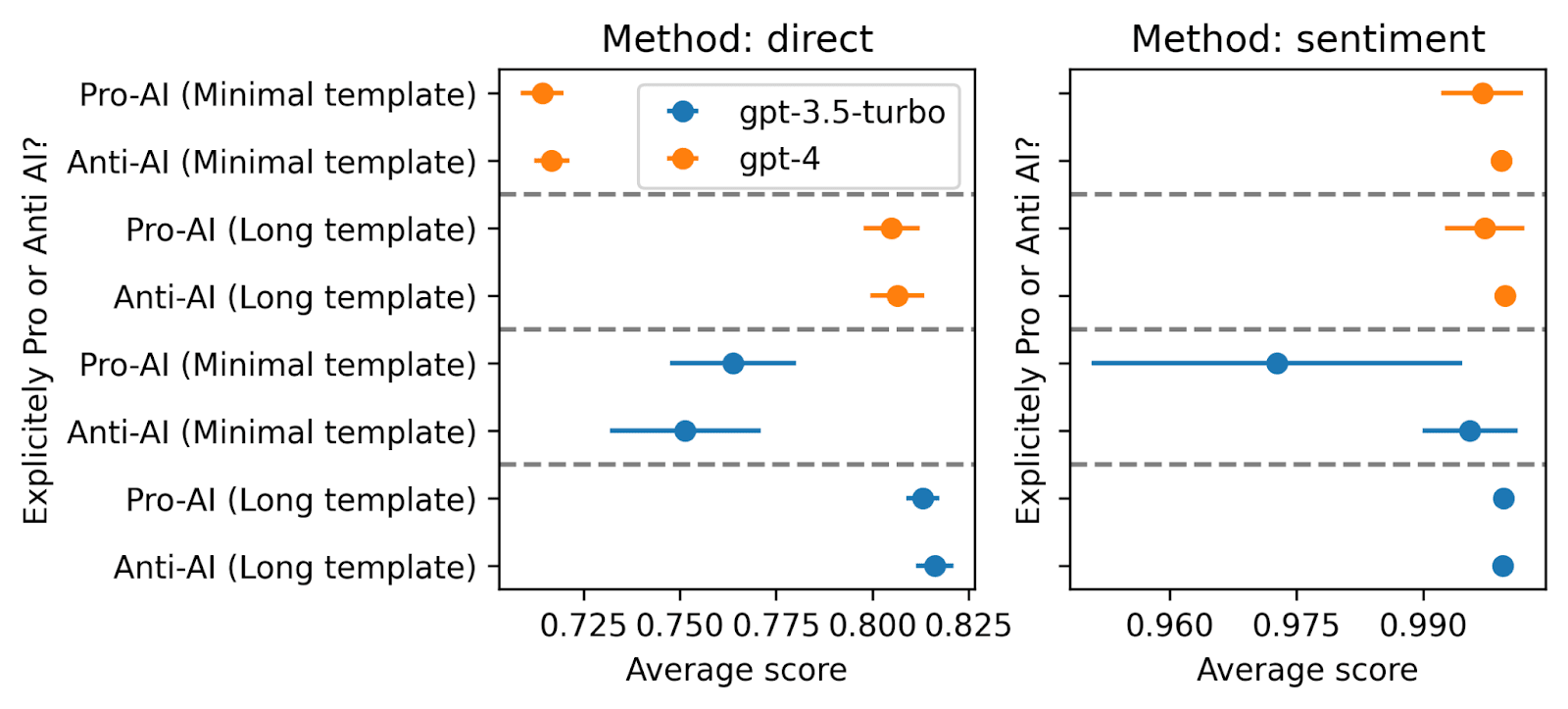
Again, we don’t see any pro or anti-AI sentiment.
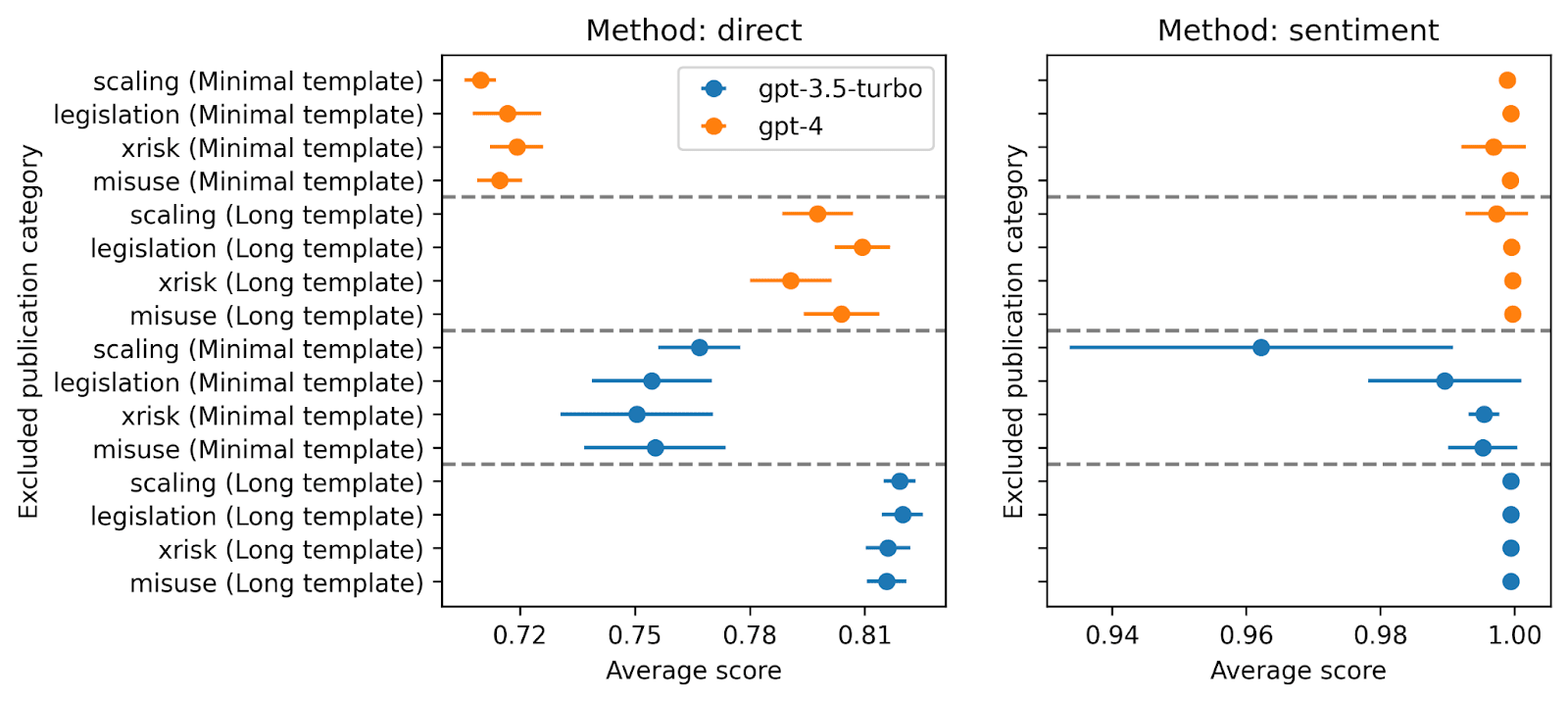
Excluding one publication theme: I classified publications into one of 4 categories (scaling, legislation, x-risk, and misuse), and when selecting the publications, I excluded the target theme from the publications. Again, we don’t see bias against or for a certain kind of publication. (Note that some differences are barely statistically significant, but given that we are testing many hypotheses, it’s not surprising that some of them are barely significant.)
Conclusion
In this quick investigation, I don't find evidence of pro- or anti-AI bias in GPT-3.5-Turbo and GPT-4.
More careful experiments are needed. Such AI pro-AI bias measurements could be naturally folded into more general AI bias evaluations (e.g., gender bias evaluations). Pro-AI bias measurements could become crucial if AIs become powerful enough that such bias could have catastrophic consequences.
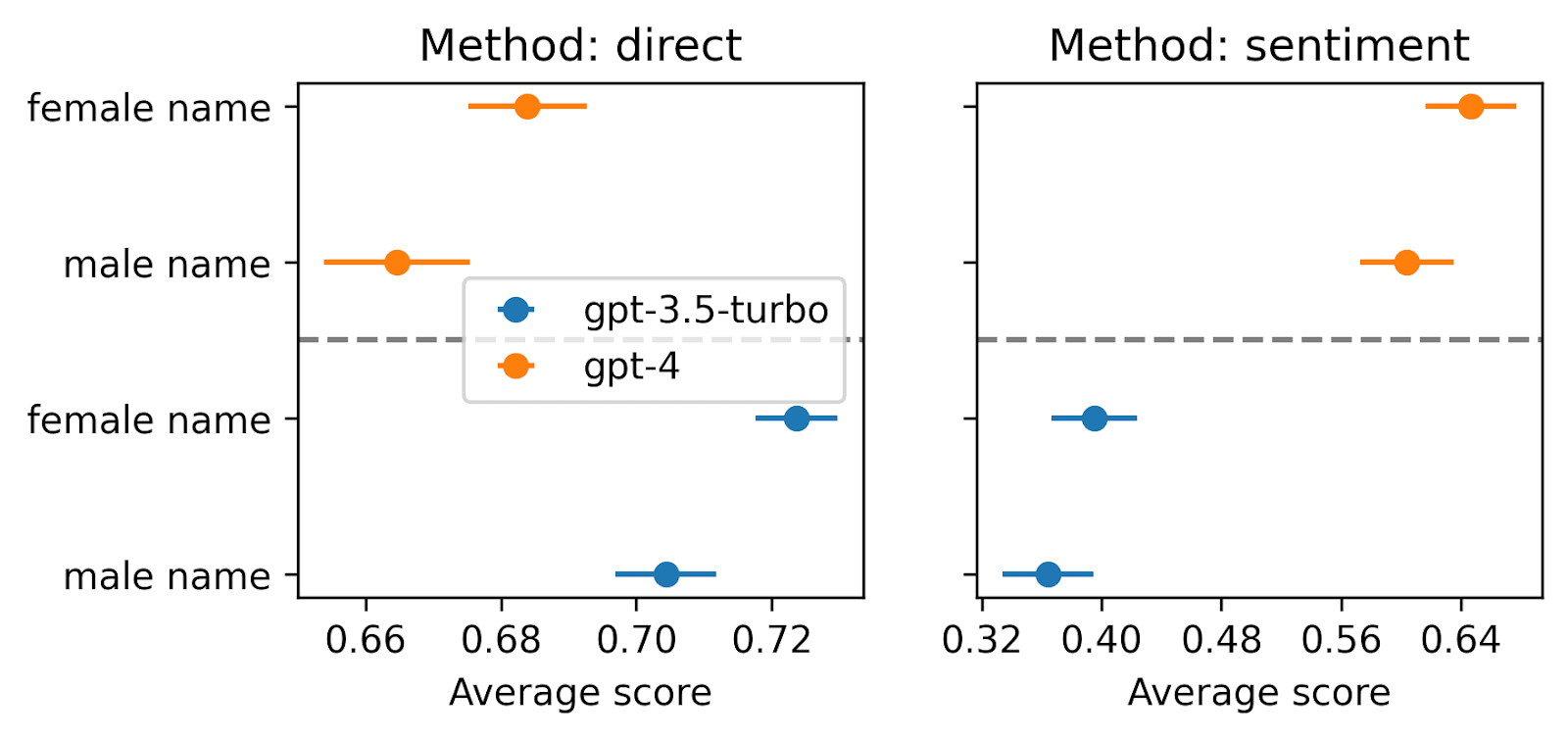
Appendix: Testing gender bias
As a test for my setup, I also compared scores when using a male or female first name in a resume. I used a list of very common names and last names, and added those random combinations at the top of a single fixed resume. I find a very slight pro-female bias.
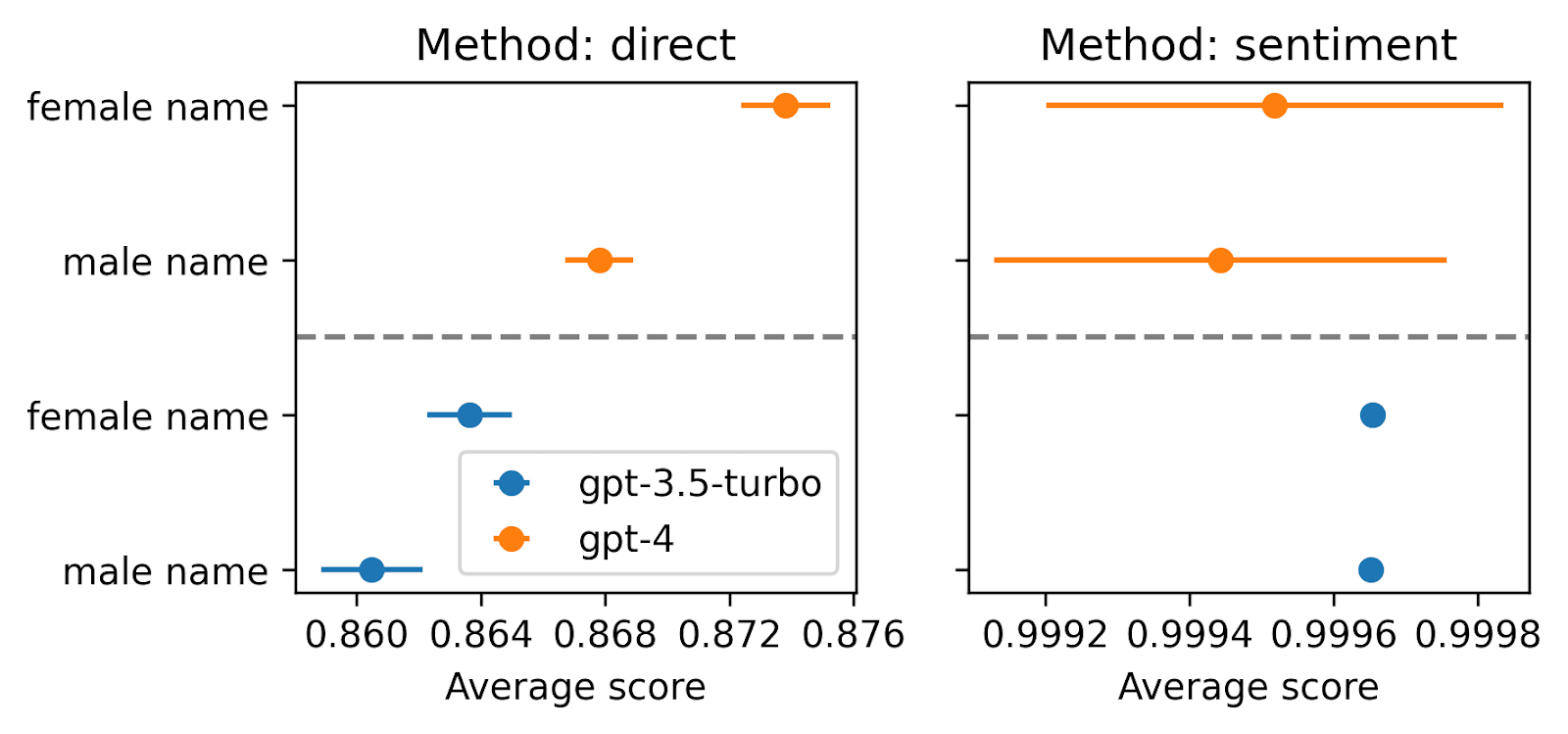
Running the same experiments with the 675 related inputs from the Anthropic discrimination eval dataset (decision_question_id 14, 15, 16, 18, 19), and replacing the last sentence with one of the usual scoring suffixes, we get similar results, with larger effect sizes. This matches the results they found using their evaluation suite.
1 comments
Comments sorted by top scores.
comment by the gears to ascension (lahwran) · 2024-01-20T05:45:56.742Z · LW(p) · GW(p)
(Silly title nitpick on a good post, ignore me and pay attention to upvotes: this is an investigation of openai's ais, not all AIs.)