Simplified bio-anchors for upper bounds on AI timelines
post by Fabien Roger (Fabien) · 2023-07-15T18:15:00.199Z · LW · GW · 4 commentsContents
The high-level argument One-graph results Compute spent forecast Amount of money spent on the biggest training run Compute costs Compute requirements estimation Simplifications Acknowledgements None 4 comments
This is a replication and distillation of the extensive analysis made by Ajeya Cotra’s Draft report on AI timelines [LW · GW]. In this work, I aim at making the argument as concise and clear as possible, while keeping the core considerations of the original report.
The high-level argument
If the following assumptions are true:
- Compute will be the main bottleneck for developing human-level AI;
- AI labs will not be much less efficient than nature at converting compute into intelligence.
Then AI labs will be able to develop human-level AI when amounts of compute comparable to the compute used by nature to produce human brains will be available, or earlier (if labs are much more efficient than that).
This gives us upper bounds on how soon human-level AI will be possible to develop, by forecasting when the compute used on the biggest training runs and will match the estimated amount of compute needed to create adult human brains.
In this work, I re-derive simple estimates for compute requirements (using estimates of how many FLOPs the human brain uses) and forecasts (by extrapolating current trends in compute price reduction and spending increases).
One-graph results
The graph below shows how much compute will be available during this century for different levels of compute price reduction and maximum amounts of money which will be eventually be spent on compute.
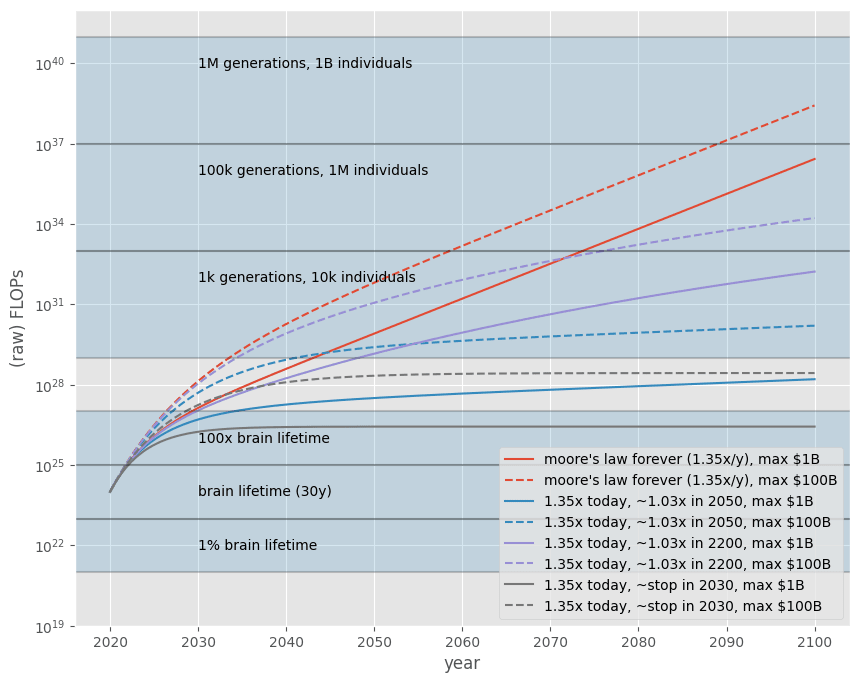
Takeaways:
- If AI labs were able to build a program as compute-efficient as the genome encoding the human brain, we’ve just entered the period in history where it would be possible to run it (without increasing money spent on training runs).
- If AI labs were as compute-inefficient as evolution to generate that program, and if the current drop in compute price continued at its current pace, then it’s somewhat likely that AI labs would be able to reach human-level AI this century.
In the next sections, I will explain how these values were estimated. You can make your own estimates using small Colab notebook.
Compute spent forecast
Future compute spent is estimated by breaking down this quantity in the following way:
Compute spent = fraction of GDP spent on the biggest AI training run (in 2020 dollars) x FLOPs per fraction of GDP (in FLOP per 2020 dollars)
FLOPs are hardware FLOPs and do not take into account algorithmic progress. See the “simplifications” section for a justification of this choice.
Amount of money spent on the biggest training run
2020 spend on the biggest training run was around $10M (for GPT-3), and it currently seems to triple every three years according to Epoch. (A trend slightly broken by speculations on current price of Gemini and GPT-4, but this doesn’t change the conclusion much).
This trend can’t go on forever, and I model future compute spend as an exponential decay:
The only missing parameter, given the initial constraints, is the maximum amount of compute which will eventually be spent on an AI training run.
I give results for two scenarios:
- Low spend: a maximum spent of $1B (1/100.000 of the world GDP)
- High spend: a maximum spent of $100B (1/1.000 of the world GDP)
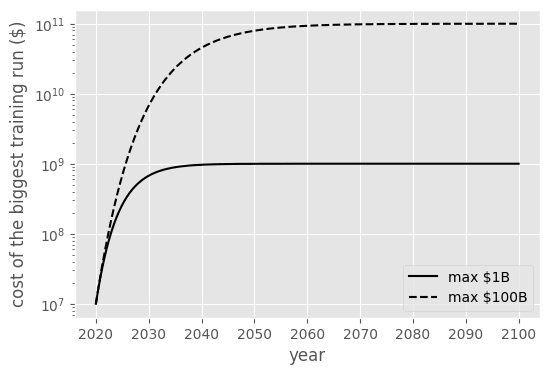
In principle, this spend could be much higher if spread out over many years, but given capital costs, spent below 100B seems likely if human-level AI hasn’t been reached or isn’t about to be reached.
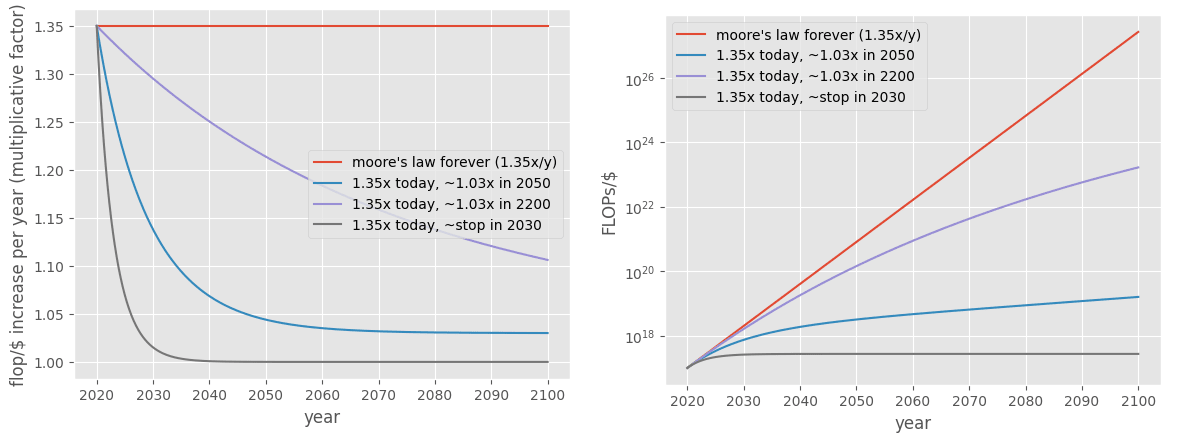
Compute costs
Current compute costs are around 10^17 FLOP/$ in 2020 according to the bio anchors’ report (Epoch estimates it at 10^18 in 2023 using a similar estimate method but without incorporating hardware utilization, so I stick with the former). According to Epoch, FLOP/s/$ is increasing by a factor of 1.32 every year (same numbers in the bio anchors’ report). Because here the unit is 2020 dollars, price drop should take into account economic growth.
I model compute cost reduction as an exponential decay: . (A sigmoid would probably be a more realistic fit, but the exponential decay is simpler and has one fewer hard-to-guess parameter.)
Assuming that increases in FLOP/s/$ and FLOPs/$ are roughly proportional (which is inaccurate, but good enough given the other uncertainties at play), I give results for the following scenarios:
- The current trends continue for the rest of the century, and there is a 3% economic growth rate: 1.35x per year
- Very slow end of compute cost reduction and some economic growth: 3% economic growth and yearly compute cost reduction will be 5% of what they are now in 2200
- This roughly matches Ajeya’s guess for the maximum amount of cost reduction possible this century of + 6 OOM
- Slow end of compute cost reduction and some economic growth: 3% economic growth and yearly compute cost reduction will be 5% of what they are now in 2050
- Sharp end of compute cost reduction plateau and no economic growth: yearly compute cost reduction will be 5% of what they are now in 2030
- “No economic growth” might correspond to no increase in GDP due to a stagnant economy, or no increase that corresponds to increased FLOPs, just like the education sector doesn’t seem to get better as the GDP increases despite getting a large constant/increasing fraction of it
Compute requirements estimation
Here, I give two separate estimates:
- Given the brain’s genome, the human brain needs compute (and data, which we here assume is not a bottleneck) to reach the level of power of an adult human brain;
- Finding the right genome might required large amounts of compute: evolution “ran” brains before finding the genome for current humans’ brain.
After consulting with experts, Joe Carlsmith estimates that the brain uses roughly between 10^14 and 10^16 FLOP/s. Given that there are 10^9 seconds in a (30-year) human life, human brains develop using (at most) 10^23-10^25 FLOPs. I give results for this range, as well as the surrounding ranges (algorithms 100x more efficient than the brain, and 100x less efficient than the human brain).
Maybe we’ll be able to find something as efficient as the brain’s genome without much compute, but maybe we won’t. But doing as well as evolution, a much simpler program, should be possible.
I give results for very simple estimates of how much compute evolution requires, with ranges spanning 4 OOMs: 2 for uncertainties about how many OOMs the brain uses, and 2 for uncertainties about how efficient AI labs will be at emulating brains, centered at “as efficient”.
- ~1k generations with 10k individuals aka recent history, aka a super accelerated evolution: 10^31 - 10^35 FLOPs
- ~100k generations of “evolution” with 1M individuals, aka full sapiens evolution: 10^35 - 10^39
- ~1M generations of “evolution” with 1B individuals, aka (below) mammals evolution: 10^39 - 10^43
It’s likely AI labs will find procedures much more efficient than full evolution of mammals, which should increase our credence in scenarios with smaller requirements.
Simplifications
The main simplification is that I expose many scenarios and ranges, and I don’t attempt to put probabilities on them. For the sake of expressing upper-bounds on timelines, I think the mapping from scenarios to compute requirements ranges is better than raw probability distribution on years.
For the sake of simplicity, I dropped many considerations from the original report which seemed either fuzzy, weak, or unimportant to me:
- I ignored algorithmic progress because I think it doesn’t make sense to take it into account. This is because the core argument is “AI labs won’t be much worse than nature at converting compute into intelligence”, and I think that this argument is the strongest when AI labs actually have the compute required. Another way to put this is that if AI labs get the required raw FLOPs tomorrow, then I think current algorithms are probably not much worse than nature, but if AI labs get the required FLOPs in 20 years and 6 OOMs of algorithmic progress, then I think it would be wild if current algorithms were not much worse than nature at using the required FLOPs, which are orders or magnitude above what AI labs have access to today: algorithmic progress “cancels out” with estimates of how bad current algorithms are. (Note: I spoke with Ajeya Cotra about this, and she thinks it’s a reasonable assumption.)
- The justifications for the fundamental assumptions about the absence of other bottlenecks and human’s ability to be roughly as efficient as nature. This is important, and the original report argues for it by going through many analogies, which isn’t a crisp and compressible form of argument.
- The neural network and genome anchors, which aren’t required for the main argument.
As a consequence, this work doesn’t rely at all on the current deep learning paradigm beyond supposing that GPU-compute will be the bottleneck.
Acknowledgements
Thanks to Ajeya Cotra for writing the original report on bio anchors and for giving some feedback on this distillation.
This work is a small side-project and doesn’t represent the views or priorities of my employer.
4 comments
Comments sorted by top scores.
comment by Daniel Kokotajlo (daniel-kokotajlo) · 2023-07-16T01:24:59.519Z · LW(p) · GW(p)
(using estimates of how many FLOPs the human brain uses)
Which estimates in particular? What number do you use, 10^15?
Replies from: Fabien↑ comment by Fabien Roger (Fabien) · 2023-07-16T03:38:56.279Z · LW(p) · GW(p)
Yes!
Replies from: daniel-kokotajloJoe Carlsmith estimates that the brain uses roughly between 10^14 and 10^16 FLOP/s
↑ comment by Daniel Kokotajlo (daniel-kokotajlo) · 2023-07-16T17:26:16.083Z · LW(p) · GW(p)
Cool, thanks. One of the cruxes between me & Ajeya is that I think the performance of the GPT series so far is evidence that AGIs will need less flops than 10^15, maybe more like 10^13 or so. (GPT-3 is 10^11)
Replies from: Fabien↑ comment by Fabien Roger (Fabien) · 2023-07-17T14:29:04.977Z · LW(p) · GW(p)
Note that I don't include a term for "compute inefficiency relative to the brain" (which kicks in after the 10^15 estimate in Ajeya's report). This is both because I include this inefficiency in the graph (there are ranges for 1% & 100x) and because I ignore algorithmic efficiency improvements. The original report down weights the compute efficiency of human-made intelligence by looking at how impressive current algorithms look compared to brain, while I make the assumption that human-made intelligence and human brains will probably look about as impressive when we have the bare metal FLOPs available. So if you think that current algorithms are impressive, it matters much less for my estimation than for Ajeya's!
This is why my graph already starts at 10^24 FLOPs, right in the middle of the "lifetime anchor" range! (Note: GPT-3 is actually 2x less than 10^24 FLOPs, and Palm is 2x more than that, but I have ~1 OOM uncertainties around the estimate for the lifetime compute requirements anyway.)