How To Know What the AI Knows - An ELK Distillation
post by Fabien Roger (Fabien) · 2022-09-04T00:46:30.541Z · LW · GW · 0 commentsContents
Why we care about knowing what an AI knows What does an AI know? A (bad) way to have the AI tell you what it knows Why this is hard to get right Why this is a promising path of research None No comments
This is what I submitted in May 2022 for the Safety Distillation Contest [LW · GW].
Why we care about knowing what an AI knows
Let’s say you have successfully created ScienceAI, an AI that is really good at writing research papers, and that you ask it to write a research paper about how to cure cancer. The resulting paper gives a recipe for a drug that should be taken by everyone and which should prevent cancer, according to the paper ScienceAI has written. However, even the experts in the relevant fields can’t tell you what that recipe would do.
In this kind of situation, it would really help to know what the AI knows. If you could ask it precise questions about the effects of this recipe like “would the end product of this recipe kill the recipient?” or “would one of the step of the recipe kill everyone on earth?”, and have the AI answer truthfully, it would make using this AI much safer. And at least, it would be a first step toward having AI that can actually improve the world without risking destroying it in the process.
This problem of having the AI tell you what it knows is called Eliciting Latent Knowledge (ELK): you have the AI tell you what it knows, but which doesn’t immediately follows from the input you give it or the output it gives you (you elicit latent knowledge).
What does an AI know?
To better understand the problem and paths to potential solution, it is better to flesh out a little what it means to say that an AI “knows” something. To that extent, I think an analogy can be useful.
Think of an AI as a factory which takes requests, and produces ideas, through a chain of intermediate ideas. For example, take a look at this very little factory:
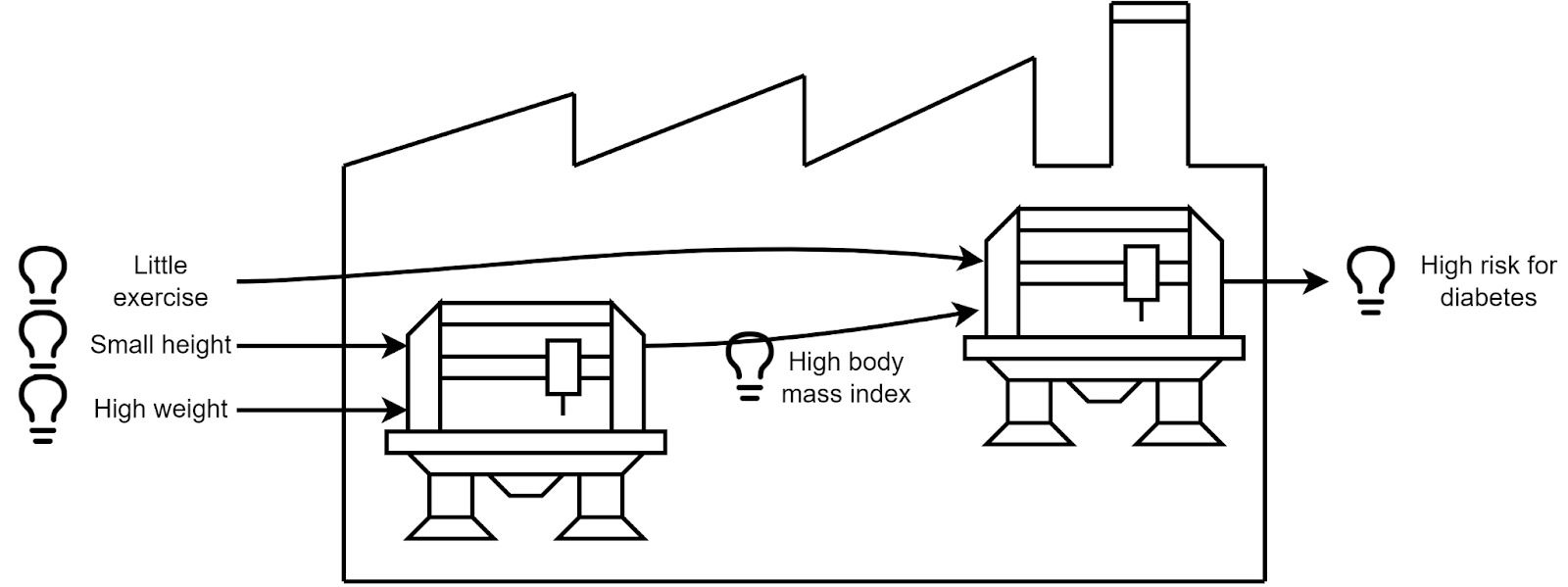
It represents an AI that computes if a given individual is at risk for obesity given weight, height, and time spent doing exercise. For what we care about (having explanations for the AI decisions and making sure it is safe), we will say that it “knows” that this individual has a high body mass index: it is an idea that is one of the causes for the final prediction.
I have written the labels of the intermediate ideas inside the factory, but in many cases, you don’t have access to them, because you trained the network using gradient descent (you can think of gradient descent as “making a lot of random little changes to the factory and keeping the ones that improve the performances”). Therefore, if you try to decipher what it is doing, it actually looks more like this.

Here, if you want to know what the AI “knows”, it might still be reasonable to find out what each of the intermediate ideas is. But in reality, advanced AIs look more like this:

In fact, there can be gigabytes of these unlabeled ideas for a single query. Good luck in figuring out everything by just looking at it! And that is exactly why ELK is the task of having the AI tell you what it knows: it’s much better if it’s the AI itself which makes explicit the knowledge behind its output.
A (bad) way to have the AI tell you what it knows
Given what we have described so far, it might seem hopeless to have the AI tell you what it knows. But in fact, there is a way!
The idea is to train the AI to complete the task “answer the questions of the human”, in addition to its original task. To do so, we can use the same process used to train the AI in the first place (gradient descent).

Let's return to ScienceAI as an example. The idea is that we take questions for which we know the answer, like “what are the consequences of taking a teaspoon of arsenic?”, and then we train ScienceAI on this kind of questions using gradient descent until it can reliably answer them. The kind of change we would like to happen inside the factory look like this:

This might work for AIs less smart than humans, because gradient descent usually finds one of the smallest modifications to the factory that lead to the AI solving the new task: something like what is described above would probably be the simplest way to answer advanced questions about things the AI already knows. However, this would be very likely to fail catastrophically with an AI that exceeds our capabilities.
Why this is hard to get right
There are two ways our procedure described above could fail.
The first one is pretty simple: if the AI is smart and complex enough, maybe the translators and the routers are just harder for gradient descent to build than a simple completely new system dedicated to answering human questions (built from scratch). It would look like this:

If that is the case, the problem is that you end up having no insight into what the main part of the program knows. And thus, the advanced facts that ScienceAI knows will be unknown to the much simpler “answer to human questions” system inside it.
Now you may find some tricks out of this situation. For instance, you might be able to recognize that a simple system disconnected from the main one was created, and use this insight to penalize this kind of modification to the factory.
However, there is a second failure mode, much harder to spot than the first one. In advanced AIs, it would be very likely that there is a module in the “factory” that tries to answer questions like “what would a human do in this situation?”. For example, ScienceAI may have to pick up this skill to write like humans, and to predict the outcome of psychology experiments. Now let’s see how the AI could learn to answer to human questions using this module:

This modification to the factory did not create a separate module, and it really uses knowledge gathered by the AI. Also, given that the AI model of how the world works might be much more complex than its model of human knowledge, this is likely to be the simplest modification that leads to human questions used for training being answered correctly. However, this does not do what we want at all. This answers perfectly to every question we already know the answer to, but can’t tell us what advanced discoveries ScienceAI did to find a recipe to cure cancer… It only gives us the knowledge the AI has about the state of human knowledge, whereas we want the knowledge it has about how the universe works.
For instance, if we modify ScienceAI with this procedure and ask “would the end product of the recipe you suggested kill the recipient?”, it would not use its knowledge of beyond-human biology to answer, but it would simply feed the question (and the recipe) into the “human module” which would return something close to what a human would think reading the recipe. If ScienceAI knows the recipe would kill the recipient, but also knows that the human best guess is that it wouldn’t, the procedure we described would assert that the recipe would not kill the recipient.
Why this is a promising path of research
Despite the fact that this problem is hard to solve, work on eliciting latent knowledge may be a very good research direction.
This research direction bridges a gap between the theoretical approaches which study the property of intelligent agents as mathematical objects (e.g. infra-bayesianism, embedded agency, …), and prosaic approaches which study what can be done with current AIs to better understand and control tomorrow’s artificial general intelligence (e.g. inverse reinforcement learning, adversarial training, …). Traditionally, work to understand the reasons behind AIs decisions - also known as interpretability - has mainly been done with the latter approach, using some nice properties of small, dumb AI systems. Not much progress in this field had been done studying highly intelligent AIs. In contrast, ELK provides a theoretical approach to this problem, making it possible to anticipate challenges that will need to be faced in order to understand the decisions of AIs smarter than us.
Also, ELK is a problem which is simpler than the full alignment problem. You don’t need to worry with things that are very fuzzy, like human values. You just need to find a way to get factual information out of the AI. Therefore, research is easier, and it is easier to assess the quality of potential solutions. This made possible a contest [AF · GW] run by Paul Christiano in which prizes have been given to reward partial solutions to the problem, which work in the examples given in the original report. None of them fully solves the problem, but a solution may be found in the next few years.
Finally, it could be a way to find ideas that could actually lead to AI Alignment. For now, AI Alignment research has proven to be hard and progress on finding an algorithm to align AIs has been slow, whereas progress on ELK is happening at a much faster pace, and ideas found there might be applicable to building a solution to the AI Alignment problem.
0 comments
Comments sorted by top scores.