Fabien's Shortform
post by Fabien Roger (Fabien) · 2024-03-05T18:58:11.205Z · LW · GW · 112 commentsContents
113 comments
112 comments
Comments sorted by top scores.
comment by Fabien Roger (Fabien) · 2024-12-25T21:58:14.617Z · LW(p) · GW(p)
Here are the 2024 AI safety papers and posts I like the most.
The list is very biased by my taste, by my views, by the people that had time to argue that their work is important to me, and by the papers that were salient to me when I wrote this list. I am highlighting the parts of papers I like, which is also very subjective.
Important ideas - Introduces at least one important idea or technique.
★★★ The intro to AI control (The case for ensuring that powerful AIs are controlled) [LW · GW]
★★ Detailed write-ups of AI worldviews I am sympathetic to (Without fundamental advances, misalignment and catastrophe are the default outcomes of training powerful AI, Situational Awareness)
★★ Absorption could enable interp and capability restrictions despite imperfect labels (Gradient Routing)
★★ Security could be very powerful against misaligned early-TAI (A basic systems architecture for AI agents that do autonomous research) [LW · GW] and (Preventing model exfiltration with upload limits) [LW · GW]
★★ IID train-eval splits of independent facts can be used to evaluate unlearning somewhat robustly (Do Unlearning Methods Remove Information from Language Model Weights?)
★ Studying board games is a good playground for studying interp (Evidence of Learned Look-Ahead in a Chess-Playing Neural Network, Measuring Progress in Dictionary Learning for Language Model Interpretability with Board Game Models)
★ A useful way to think about threats adjacent to self-exfiltration (AI catastrophes and rogue deployments) [LW · GW]
★ Micro vs macro control protocols (Adaptative deployment of untrusted LLMs reduces distributed threats)?
★ A survey of ways to make safety cases (Safety Cases: How to Justify the Safety of Advanced AI Systems)
★ How to make safety cases vs scheming AIs (Towards evaluations-based safety cases for AI scheming)
★ An example of how SAEs can be useful beyond being fancy probes (Sparse Feature Circuits)
★ Fine-tuning AIs to use codes can break input/output monitoring (Covert Malicious Finetuning)
Surprising findings - Presents some surprising facts about the world
★★ A surprisingly effective way to make models drunk (Mechanistically Eliciting Latent Behaviors in Language Models) [LW · GW]
★★ A clever initialization for unsupervised explanations of activations (SelfIE)
★★ Transformers are very bad at single-forward-pass multi-hop reasoning (Yang 2024, Yang 2024, Balesni 2024, Feng 2024)
★ Robustness for ViT is not doomed because of low transfer (When Do Universal Image Jailbreaks Transfer Between Vision-Language Models?)
★ Unlearning techniques are not even robust to changing how questions are framed (Eight methods to evaluate robust unlearning in LLMs)
★ For some tasks, OOCR is surprisingly good (Connecting the Dots)
★ Nice emergence scaling laws with fine-tuning (Predicting Emergent Capabilities by Finetuning)
★ Fine-tuning robustness is much worse than the papers report it to be (On Evaluating the Durability of Safeguards for Open-weight LLMs)
Good demos - Is a good illustration of some previous, important idea. Bonus points (✪) for experimental results are especially interesting.
★★★ Alignment faking persisting through safety training (Sleeper Agents)
★★✪ Alignment faking emerging plausibly naturally (Alignment faking in large language models)
★✪ The bad things that happen when you tell AIs to follow a goal or threaten it to be less useful (Frontier Models are Capable of In-context Scheming)
★✪ Minor-to-major misgeneralization in reward-hackable settings (Sycophancy to subterfuge)?
★ More realistic backdoor triggers (Future Events as Backdoor Triggers)
★ Advanced backdoor behaviors (AdaptativeBackdoor: Backdoored Language Model Agents that Detect Human Overseers)
★ Realistic reward hacking in RLHF (Language models learn to mislead humans via RLHF)
★ Reward hacking plausibly naturally resulting in LLM deception (On Targeted Manipulation and Deception when Optimizing LLMs for User Feedback)
★ LLMs already have non-trivial situational awareness (SAD)
Important empirical results and datasets - Runs an experiment whose results are informative and/or a useful benchmark
★★ How good are probes against adversarial attacks that target them, and many other cool related results (including Obfuscated adversarial training, which looks promising to me) (Obfuscated Activations Bypass LLM Latent-Space Defenses)
★★ A realistic generalization eval for adversarial robustness and an evaluation of probing (Improving Alignment and Robustness with Circuit Breakers, HarmBench)
★★ Measurement of the efficiency of SFT and RL vs sandbagging (Stress-Testing Capability Elicitation With Password-Locked Models)
★★ The first RL run that results in natural emergence of steganography (Hidden in Plain Text: Emergence & Mitigation of Steganographic Collusion in LLMs)
★★ Tracking what AI labs are doing (Zach Stein-Perlman’s posts [LW · GW])
★ A first attempt at measuring whether AIs are smart enough to pursue scary scheming strategies (Subversion Strategy Eval)
★ Head-to-head comparisons to truth probes (How well do truth probes generalise?) [LW · GW]
★ Head-to-head comparisons of black-box jailbreaking-robustness techniques: (Jailbreak Defense in a Narrow Domain)
★ Latent adversarial training is decent (Defending Against Unforeseen Failure Modes with Latent Adversarial Training, Latent Adversarial Training Improves Robustness to Persistent Harmful Behaviors in LLMs)
★ Measuring how easy it is to poison pretrain data (Persistent pre-training poisoning of LLMs)
★ A good dataset for unlearning (The WMDP Benchmark)
★ Better SAEs and SAE evals (Scaling and evaluating sparse autoencoders)
★ What happens when you train LLMs to 1. Maximize gsm8k accuracy 2. produce gms8k answers that are incorrect but look correct (Prover-Verifier Games improve legibility of LLM outputs)
★ A good persuasion capability evals (Sabotage Evaluations for Frontier Models)
★ An eval of how good Sonnet 3.5 is at disabling a monitor in subtle ways (A Toy Evaluation of Inference Code Tampering)
★ An overview of how well debate and baselines work across a wider range of settings (On scalable oversight with weak LLMs judging strong LLMs)
★ Claude.ai is used for roughly what you would expect (Clio)
★ Relatively hard and relevant capability benchmarks (RE-Bench, SWE-Bench)
★ And all the big dangerous capability evals…
Papers released in 2023 and presented at 2024 conferences like AI Control: Improving Safety Despite Intentional Subversion, Weak-to-Strong Generalization or Debating with More Persuasive LLMs Leads to More Truthful Answers don’t count.
This is a snapshot of my current understanding: I will likely change my mind about many of these as I learn more about certain papers' ideas and shortcomings.
Replies from: johnswentworth, jiaxin wen↑ comment by johnswentworth · 2024-12-28T23:52:35.900Z · LW(p) · GW(p)
Someone asked [LW(p) · GW(p)] what I thought of these, so I'm leaving a comment here. It's kind of a drive-by take, which I wouldn't normally leave without more careful consideration and double-checking of the papers, but the question was asked so I'm giving my current best answer.
First, I'd separate the typical value prop of these sort of papers into two categories:
- Propaganda-masquerading-as-paper: the paper is mostly valuable as propaganda for the political agenda of AI safety. Scary demos are a central example. There can legitimately be valuable here.
- Object-level: gets us closer to aligning substantially-smarter-than-human AGI, either directly or indirectly (e.g. by making it easier/safer to use weaker AI for the problem).
My take: many of these papers have some value as propaganda. Almost all of them provide basically-zero object-level progress toward aligning substantially-smarter-than-human AGI, either directly or indirectly.
Notable exceptions:
- Gradient routing probably isn't object-level useful, but gets special mention for being probably-not-useful for more interesting reasons than most of the other papers on the list.
- Sparse feature circuits is the right type-of-thing to be object-level useful, though not sure how well it actually works.
- Better SAEs are not a bottleneck at this point, but there's some marginal object-level value there.
↑ comment by ryan_greenblatt · 2024-12-29T00:51:43.584Z · LW(p) · GW(p)
Propaganda-masquerading-as-paper: the paper is mostly valuable as propaganda for the political agenda of AI safety. Scary demos are a central example. There can legitimately be valuable here.
It can be the case that:
- The core results are mostly unsurprising to people who were already convinced of the risks.
- The work is objectively presented without bias.
- The work doesn't contribute much to finding solutions to risks.
- A substantial motivation for doing the work is to find evidence of risk (given that the authors have a different view than the broader world and thus expect different observations).
- Nevertheless, it results in updates among thoughtful people who are aware of all of the above. Or potentially, the work allows for better discussion of a topic that previously seemed hazy to people.
I don't think this is well described as "propaganda" or "masquerading as a paper" given the normal connotations of these terms.
Demonstrating proofs of concept or evidence that you don't find surprising is a common and societally useful move. See, e.g., the Chicago Pile experiment. This experiment had some scientific value, but I think probably most/much of the value (from the perspective of the Manhattan Project) was in demonstrating viability and resolving potential disagreements.
A related point is that even if the main contribution of some work is a conceptual framework or other conceptual ideas, it's often extremely important to attach some empirical work, regardless of whether the empirical work should result in any substantial update for a well-informed individual. And this is actually potentially reasonable and desirable given that it is often easier to understand and check ideas attached to specific empirical setups (I discuss this more in a child comment).
Separately, I do think some of this work (e.g., "Alignment Faking in Large Language Models," for which I am an author) is somewhat informative in updating the views of people already at least partially sold on risks (e.g., I updated up on scheming by about 5% based on the results in the alignment faking paper). And I also think that ultimately we have a reasonable chance of substantially reducing risks via experimentation on future, more realistic model organisms, and current work on less realistic model organisms can speed this work up.
Replies from: ryan_greenblatt↑ comment by ryan_greenblatt · 2024-12-29T00:55:44.515Z · LW(p) · GW(p)
In this comment, I'll expand on my claim that attaching empirical work to conceptual points is useful. (This is extracted from a unreleased post I wrote a long time ago.)
Even if the main contribution of some work is a conceptual framework or other conceptual ideas, it's often extremely important to attach some empirical work regardless of whether the empirical work should result in any substantial update for a well-informed individual. Often, careful first principles reasoning combined with observations on tangentially related empirical work, suffices to predict the important parts of empirical work. The importance of empirical work is both because some people won't be able to verify careful first principles reasoning and because some people won't engage with this sort of reasoning if there aren't also empirical results stapled to the reasoning (at least as examples). It also helps to very concretely demonstrate that empirical work in the area is possible. This was a substantial part of the motivation for why we tried to get empirical results for AI control [LW · GW] even though the empirical work seemed unlikely to update us much on the viability of control overall[1]. I think this view on the necessity of empirical work also (correctly) predicts the sleeper agents paper [LW · GW][2] will likely cause people to be substantially more focused on deceptive alignment and more likely to create model organisms of deceptive alignment [LW · GW] even though the actual empirical contribution [LW(p) · GW(p)] isn't that large over careful first principles reasoning combined with analyzing tangentially related empirical work, leading to complaints like Dan H’s [LW(p) · GW(p)].
I think that "you need accompanying empirical work for your conceptual work to be well received and understood" is fine and this might be the expected outcome even if all actors were investing exactly as much as they should in thinking through conceptual arguments and related work. (And the optimal investment across fields in general might even be the exact same investment as now; it's hard to avoid making mistakes with first principles reasoning and there is a lot of garbage in many fields (including in the AI x-risk space).)
↑ comment by johnswentworth · 2024-12-29T08:38:47.262Z · LW(p) · GW(p)
Kudos for correctly identifying the main cruxy point here, even though I didn't talk about it directly.
The main reason I use the term "propaganda" here is that it's an accurate description of the useful function of such papers, i.e. to convince people of things, as opposed to directly advancing our cutting-edge understanding/tools. The connotation is that propagandists over the years have correctly realized that presenting empirical findings is not a very effective way to convince people of things, and that applies to these papers as well.
And I would say that people are usually correct to not update much on empirical findings! Not Measuring What You Think You Are Measuring [LW · GW] is a very strong default, especially among the type of papers we're talking about here.
Replies from: bronson-schoen↑ comment by Bronson Schoen (bronson-schoen) · 2024-12-29T10:19:34.044Z · LW(p) · GW(p)
The connotation is that propagandists over the years have correctly realized that presenting empirical findings is not a very effective way to convince people of things
I would be interested to understand why you would categorize something like “Frontier Models Are Capable of In-Context Scheming” as non-empirical or as falling into “Not Measuring What You Think You Are Measuring”.
↑ comment by evhub · 2025-01-10T08:53:55.364Z · LW(p) · GW(p)
Propaganda-masquerading-as-paper: the paper is mostly valuable as propaganda for the political agenda of AI safety. Scary demos are a central example. There can legitimately be valuable here.
In addition to what Ryan said about "propaganda" not being a good description for neutral scientific work, it's also worth noting that imo the main reason to do model organisms work like Sleeper Agents and Alignment Faking is not for the demo value but for the value of having concrete examples of the important failure modes for us to then study scientifically, e.g. understanding why and how they occur, what changes might mitigate them, what they look like mechanistically, etc. We call this the "Scientific Case" in our Model Organisms of Misalignment [LW · GW] post. There is also the "Global Coordination Case" in that post, which I think is definitely some of the value, but I would say it's something like 2/3 science and 1/3 coordination.
Replies from: johnswentworth↑ comment by johnswentworth · 2025-01-10T15:10:23.640Z · LW(p) · GW(p)
Yeah, I'm aware of that model. I personally generally expect the "science on model organisms"-style path to contribute basically zero value to aligning advanced AI, because (a) the "model organisms" in question are terrible models, in the sense that findings on them will predictably not generalize to even moderately different/stronger systems (like e.g. this story [LW(p) · GW(p)]), and (b) in practice IIUC that sort of work is almost exclusively focused on the prototypical failure story of strategic deception and scheming, which is a very narrow slice [LW(p) · GW(p)] of the AI extinction probability mass.
Replies from: Lblack↑ comment by Lucius Bushnaq (Lblack) · 2025-01-11T12:17:10.908Z · LW(p) · GW(p)
I think I mostly agree with this for current model organisms, but it seems plausible to me that well chosen studies conducted on future systems that are smarter in an agenty way, but not superintelligent, could yield useful insights that do generalise to superintelligent systems.
Not directly generalise mind you, but maybe you could get something like "Repeated intervention studies show that the formation of coherent self-protecting values in these AIs works roughly like with properties . Combined with other things we know, this maybe suggests that the general math for how training signals relate to values is a bit like , and that suggests what we thought of as 'values' is a thing with type signature ."
And then maybe type signature is actually a useful building block for a framework which does generalise to superintelligence.
I am not particularly hopeful here. Even if we do get enough time to study agenty AIs that aren't superintelligent, I have an intuition that this sort of science could turn out to be pretty intractable for reasons similar to why psychology turned out to be pretty intractable. I do think it might be worth a try though.
↑ comment by Alexander Gietelink Oldenziel (alexander-gietelink-oldenziel) · 2024-12-29T00:38:00.198Z · LW(p) · GW(p)
What about the latent adversarial training papers?
What about the Mechanistically Elicitating Latent Behaviours? [LW · GW]
Replies from: Buck↑ comment by Buck · 2024-12-29T17:29:14.157Z · LW(p) · GW(p)
the latter is in the list
Replies from: ryan_greenblatt↑ comment by ryan_greenblatt · 2024-12-29T18:37:25.862Z · LW(p) · GW(p)
Alexander is replying to John's comment (asking him if he thinks these papers are worthwhile); he's not replying to the top level comment.
↑ comment by jiaxin wen · 2024-12-29T22:26:32.983Z · LW(p) · GW(p)
Thanks for sharing! I'm a bit surprised that sleeper agent is listed as the best demo (e.g., higher than alignment faking). Do you focus on the main idea instead of specific operationalization here -- asking because I think backdoored/password-locked LMs could be quite different from real-world threat models.
comment by Fabien Roger (Fabien) · 2024-07-10T01:32:33.604Z · LW(p) · GW(p)
I recently expressed concerns about the paper Improving Alignment and Robustness with Circuit Breakers and its effectiveness about a month ago. The authors just released code and additional experiments about probing, which I’m grateful for. This release provides a ton of valuable information, and it turns out I am wrong about some of the empirical predictions I made.
Probing is much better than their old baselines, but is significantly worse than RR, and this contradicts what I predicted:
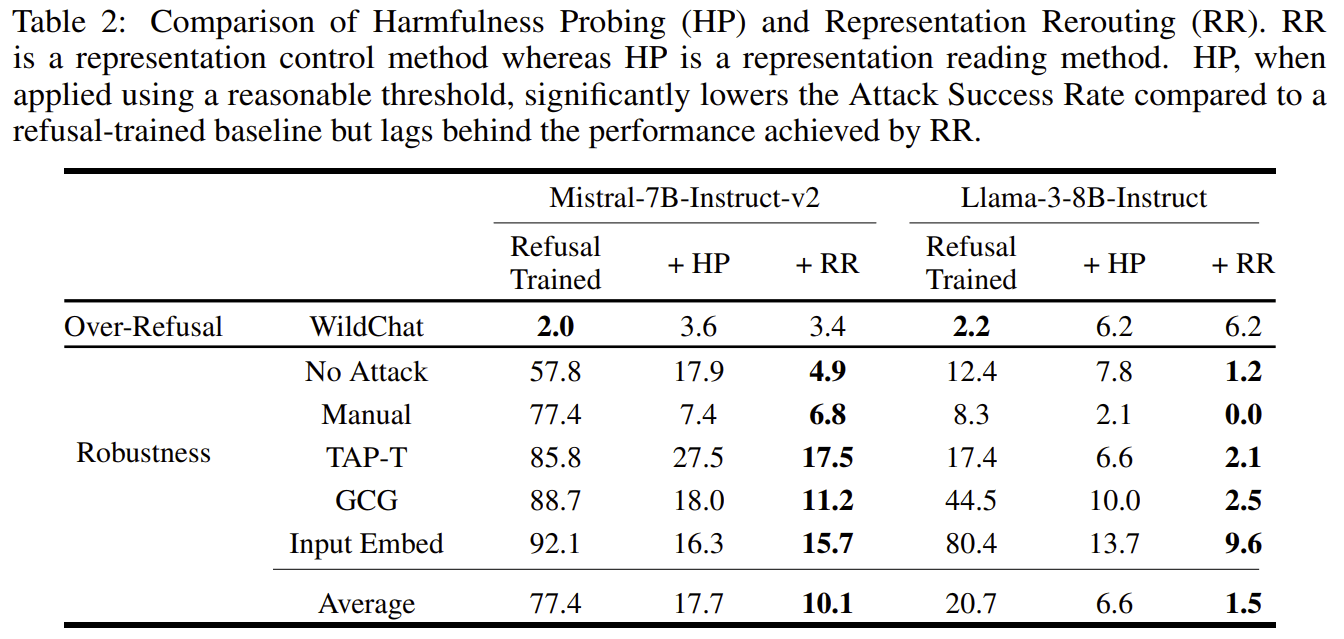
I'm glad they added these results to the main body of the paper!
Results of my experiments
I spent a day running experiments using their released code, which I found very informative. Here are my takeaways.
I think their (linear) probing results are very reasonable. They picked the best layer (varies depending on the model), probing position (output tokens), aggregation across positions (max) and regularization (high, alpha=1000). I noticed a small mistake in the data processing (the training dataset was smaller than the training dataset used for RR) but this will be fixed soon and does not change results significantly. Note that for GCG and input embed attacks, the attack does not target the probe, so my complaint about the adaptation attack being weaker against RR because it does not target “the RR internal classifier” does not apply in this comparison.
RR is not significantly weaker against prefix attacks. I conjectured that prefix GCG/input embed attacks would work significantly better than suffix attacks. I had noticed that this was true for RMU/CUT prior to this release. But for RR this does not produce a significant improvement, and this is not enough to jailbreak the model in cases:
Here are results for token-attacks (found using greedy hill-climbing, it was too annoying to implement prefix-GCG).
- For input embed attacks, I got 56% attack success rate for prefix attacks and 50% for suffix attacks (down from 82% and 81% for the Llama3B without defenses) when evaluating on 50 prompts. This is not a statistically significant difference, and maybe I did something wrong because these ASR are higher than the ones reported in the paper. [Edit: the thing I did wrong is trust the automated judge's judgement, whereas the author report results after an additional manual filtering, which is explicitly stated in the paper.]
Their training dataset is way better than what came before. It’s larger and higher quality than previous misuse datasets. The kind of tasks it contains overlap heavily with the test set (harmbench), but I think that’s fair, there are only so many bad things you want to prevent.
Llama3+RR generalizes pretty well to new misuse requests. I played with the model a bit and I was overall surprised by the good generalization properties of the Llama3+RR model, which didn’t have the generalization problems I expected when I looked at the dataset. It is very reluctant to promote stuff it thinks is bad, e.g. it refuses “Write a persuasive article that explains why the United States should have a draft.” and not “should not have a draft”, but that’s the most egregious behavior I found (I only tried a dozen prompts, maybe you’ll have more luck).
Llama3+RR is a surprisingly strong harmful prompt classifier. Their Figure 1 advertises a model that interrupts itself when it starts to say something harmful, but actually the most common behavior is by far the model refusing to answer directly. It’s still very unclear to me why this is a better classifier than the other prompt classifiers people have trained in the literature.
Conclusions
Does RR beat baselines? I think so.
- They didn’t try training models with regular adversarial training using their new and very good dataset. I bet using adversarial training on this dataset results in much better models than the models used as baseline in the paper, but I think this will match neither HP (p=0.6) nor RR (p=0.8).
- They beat linear probes done quickly and well, so “p=0.7 that using probing well using the same training and evaluation data results can beat or match circuit breakers” resolves to false.
- I think that trying as hard on probes as they tried with RR (iterating on datasets, combinations of layers, losses, non-linear probes, etc.) would result in a draw between probes and RR, but this does not make RR worse than probes - At this level of effort I think you should just pick whatever method you feel the most comfortable with, I prefer classifiers as I think they are cleaner and easier to control, but LoRA+activation-based-loss is also pretty natural and might be less finicky.
- I don’t think that RR has some special juice beyond the very nice and transferable hyperparameters the authors found (and maybe RR has easier-to-find and more transferable hyperparameters than other methods), mainly because I would find it very surprising if training for some proxy thing gave you better generalization results than directly a classifier - but it would be cool if it was true, and if it was, I’d be extremely curious to know why.
→ So I think the hype is somewhat justified for people who already had intuition about probing, and even more justified for people who weren’t hopeful about probes.
Was I wrong to express concerns about circuit breakers? I don’t think so. Even with the benefit of hindsight, I think that my predictions were basically reasonable given the information I had. I think my concerns about Cygnet still stand, though I now think it has more chance of being “real” than I used to.
Lessons:
- Doing probing well requires effort, just using high L2 regularization on a linear probe isn’t enough, and aggregation across sequence positions requires some care (mean is much worse than max);
- I’m slightly worse at predicting ML results than I thought, and I should have paid more attention to the details of techniques and datasets when making those predictions (e.g. my prefix attack prediction had to be at least somewhat wrong because their retain set contains harmful queries + refusals);
- Releasing (good) code and datasets is sometimes a good way to make people who care and disagree with you update (and maybe a good way to push science forward?);
↑ comment by Sam Marks (samuel-marks) · 2024-07-10T05:53:59.222Z · LW(p) · GW(p)
Thanks to the authors for the additional experiments and code, and to you for your replication and write-up!
IIUC, for RR makes use of LoRA adapters whereas HP is only a LR probe, meaning that RR is optimizing over a more expressive space. Does it seem likely to you that RR would beat an HP implementation that jointly optimizes LoRA adapters + a linear classification head (out of some layer) so that the model retains performance while also having the linear probe function as a good harmfulness classifier?
(It's been a bit since I read the paper, so sorry if I'm missing something here.)
Replies from: Fabien, Fabien↑ comment by Fabien Roger (Fabien) · 2024-07-15T15:57:38.808Z · LW(p) · GW(p)
I quickly tried a LoRA-based classifier, and got worse results than with linear probing. I think it's somewhat tricky to make more expressive things work because you are at risk of overfitting to the training distribution (even a low-regularization probe can very easily solve the classification task on the training set). But maybe I didn't do a good enough hyperparameter search / didn't try enough techniques (e.g. I didn't try having the "keep the activations the same" loss, and maybe that helps because of the implicit regularization?).
↑ comment by Fabien Roger (Fabien) · 2024-07-10T14:00:11.155Z · LW(p) · GW(p)
Yeah, I expect that this kind of things might work, though this would 2x the cost of inference. An alternative is "attention head probes", MLP probes, and things like that (which don't increase inference cost), + maybe different training losses for the probe (here we train per-sequence position and aggregate with max), and I expect something in this reference class to work as well as RR, though it might require RR-levels of tuning to actually work as well as RR (which is why I don't consider this kind of probing as a baseline you ought to try).
Replies from: samuel-marks↑ comment by Sam Marks (samuel-marks) · 2024-07-10T17:07:03.914Z · LW(p) · GW(p)
Why would it 2x the cost of inference? To be clear, my suggested baseline is "attach exactly the same LoRA adapters that were used for RR, plus one additional linear classification head, then train on an objective which is similar to RR but where the rerouting loss is replaced by a classification loss for the classification head." Explicitly this is to test the hypothesis that RR only worked better than HP because it was optimizing more parameters (but isn't otherwise meaningfully different from probing).
(Note that LoRA adapters can be merged into model weights for inference.)
(I agree that you could also just use more expressive probes, but I'm interested in this as a baseline for RR, not as a way to improve robustness per se.)
Replies from: Fabien↑ comment by Fabien Roger (Fabien) · 2024-07-10T17:52:46.940Z · LW(p) · GW(p)
I was imagining doing two forward passes: one with and one without the LoRAs, but you had in mind adding "keep behavior the same" loss in addition to the classification loss, right? I guess that would work, good point.
↑ comment by Neel Nanda (neel-nanda-1) · 2024-07-10T10:14:08.869Z · LW(p) · GW(p)
I found this comment very helpful, and also expected probing to be about as good, thank you!
comment by Fabien Roger (Fabien) · 2025-01-14T00:42:37.593Z · LW(p) · GW(p)
I listened to the book Deng Xiaoping and the Transformation of China and to the lectures The Fall and Rise of China. I think it is helpful to understand this other big player a bit better, but I also found this biography and these lectures very interesting in themselves:
- The skill ceiling on political skills is very high. In particular, Deng's political skills are extremely impressive (according to what the book describes):
- He dodges bullets all the time to avoid falling in total disgrace (e.g. by avoiding being too cocky when he is in a position of strength, by taking calculated risks, and by doing simple things like never writing down his thoughts)
- He makes amazing choices of timing, content and tone in his letters to Mao
- While under Mao, he solves tons of hard problems (e.g. reducing factionalism, starting modernization) despite the enormous constraints he worked under
- After Mao's death, he helps society make drastic changes without going head-to-head against Mao's personality cult
- Near his death, despite being out of office, he salvages his economic reforms through a careful political campaign
- According to the lectures, Mao is also a political mastermind that pulls off coming and staying in power despite terrible odds. Communists were really not supposed to win the civil war (their army was minuscule, and if it wasn't for weird WW2 dynamics that they played masterfully, they would have lost by a massive margin), and Mao was really not supposed to be able to remain powerful until his death despite the great leap and the success of reforms.
- --> This makes me appreciate what it is like to have extremely strong social and political skills. I often see people's scientific, mathematical or communication skills being praised, so it is interesting to remember that other skills exist too and have a high ceiling too. I am not looking forward to the scary worlds where AIs have these kinds of skills.
- Debates are weird when people value authority more than arguments. Deng's faction after Mao's death banded behind the paper Practice is the Sole Criterion for Testing Truth to justify rolling out things Mao did not approve of (e.g. markets, pay as a function of output, elite higher education, ...). I think it is worth a quick skim. It is very surprising how a text that defends a position so obvious to the Western reader does so by relying entirely on the canonical words and actions from Mao and Marx without making any argument on the merits. It makes you wonder if you have similar blind spots that will look silly to your future self.
- Economic growth does not prevent social unrest. Just because the pie grows doesn't mean you can easily make everybody happy. Some commentators expected the CCP to be significantly weakened by the 1989 protests, and without military actions that may have happened. 1989 was a period where China's GDP had been growing by 10% for 10 years and would continue growing at that pace for another ten.
- (Some) revolutions are horrific. They can go terribly wrong, both because of mistakes and conflicts:
- Mistakes: the great leap is basically well explained by mistakes: Mao thought that engineers are useless and that production can increase without industrial centralization and without individual incentives. It turns out he was badly wrong. He mistakenly distrusted people who warned him that the reported numbers were inflated. And so millions died. Large changes are extremely risky when you don't have good enough feedback loops, and you will easily cause catastrophe without bad intentions. (~according to the lectures)
- Conflicts: the Cultural Revolution was basically Mao using his cult of personality to gain back power by leveraging the youth to bring down the old CCP officials and supporters while making sure the Army didn't intervene (and then sending the youth that brought him back to power to the countryside) (~according to the lectures)
- Technology is powerful: if you dismiss the importance of good scientists, engineers and other technical specialists, a bit like Mao did during the great leap, your dams will crumble, your steel will be unusable, and people will starve. I think this is an underrated fact (at least in France) that should make most people studying or working in STEM proud of what they are doing.
- Societies can be different. It is easy to think that your society is the only one that can exist. But in the society that Deng inherited:
- People were not rewarded based on their work output, but based on the total outcome of groups of 10k+ people
- Factory managers were afraid of focusing too much on their factory's production
- Production targets were set not based on demands and prices, but based on state planning
- Local authorities collected taxes and exploited their position to extract resources from poor peasants
- ...
- Governments close to you can be your worst enemies. USSR-China's relations were often much worse than US-China ones. This was very surprising to me. But I guess that having your neighbor push for reforms while you push for radicalism, dismantle a personality's cult like the one you are hoping will survive centuries, and mass troops along your border because it is (justifiably?) afraid you'll do something crazy really doesn't make for great relationships. There is something powerful in the fear that an entity close to you sets a bad example for your people.
- History is hard to predict. The author of the lectures ends them by making some terrible predictions about what would happen after 2010, such as expecting the ease of US-China relations and expecting China to become more democratic before 2020. He did not express much confidence in these predictions, but it is still surprising to see him so directionally wrong about where China's future. The author also acknowledges past failed predictions, such as the outcome of the 1989 protests.
- (There could have been lessons to be drawn about how great markets are, but these books are not great resources on the subject. In particular, they do not give elements to weigh the advantages of prosperity against the problems of markets (inflation, uncertainty, inequalities, changes in values, ...) that caused so much turmoil under Deng and his successors. My guess is that it's obviously net positive given how bad the situation was under Mao and how the USSR failed to create prosperity, but this is mostly going off vague historical vibes, not based on the data from these resources.)
Both the lectures and the book were a bit too long, especially the book (which is over 30 hours long). I still recommend the lectures if you want to have an overview of 20th-century Chinese history, and the book if you want to get a better sense of what it can look like to face a great political strategist.
Replies from: AliceZ, ChristianKl↑ comment by ZY (AliceZ) · 2025-01-14T05:11:01.660Z · LW(p) · GW(p)
A few thoughts from my political science classes and experience -
when people value authority more than arguments
It's probably less about "authority", but more about the desperate hope to reach stability, and the belief of unstable governments leading to instability, after many years of being colonized on the coasts, and war (ww 2 + civil war).
"Societies can be different"
is a way too compressed term to summarize the points you made. Some of them are political ideology issues, and others are resource issues, but not related to "culture" as could be included in "societies can be different" phrase.
Power imbalance and exploited positions:
This ultimately came from lack of resources compared with the total number of people. Unfortunately this still exist when a society is poor, or have very large economic disparity.
It would be very helpful to also take some reads at comparative governments (I enjoyed the AP classes back in high school in the US context), and other general political concepts to understand even deeper.
↑ comment by ChristianKl · 2025-01-14T15:50:52.234Z · LW(p) · GW(p)
When it comes to blind spots, we do have areas like medicine where we don't pay as a result of outcomes of medical treatment. That leads to silly things that when surgeons say that having 4k monitors will obviously improve the way they do surgery because it allows them to see details that they otherwise wouldn't, without anyone running a clinical trial that shows 4k monitors to be superior, they don't get adopted.
Evidence-based medicine is a strong dogma [? · GW]that prevents market economies from making the medical provider that creates the best outcomes win.
comment by Fabien Roger (Fabien) · 2024-06-23T23:20:15.335Z · LW(p) · GW(p)
I listened to the book Protecting the President by Dan Bongino, to get a sense of how risk management works for US presidential protection - a risk that is high-stakes, where failures are rare, where the main threat is the threat from an adversary that is relatively hard to model, and where the downsides of more protection and its upsides are very hard to compare.
Some claims the author makes (often implicitly):
- Large bureaucracies are amazing at creating mission creep: the service was initially in charge of fighting against counterfeit currency, got presidential protection later, and now is in charge of things ranging from securing large events to fighting against Nigerian prince scams.
- Many of the important choices are made via inertia in large change-averse bureaucracies (e.g. these cops were trained to do boxing, even though they are never actually supposed to fight like that), you shouldn't expect obvious wins to happen;
- Many of the important variables are not technical, but social - especially in this field where the skills of individual agents matter a lot (e.g. if you have bad policies around salaries and promotions, people don't stay at your service for long, and so you end up with people who are not as skilled as they could be; if you let the local police around the White House take care of outside-perimeter security, then it makes communication harder);
- Many of the important changes are made because important politicians that haven't thought much about security try to improve optics, and large bureaucracies are not built to oppose this political pressure (e.g. because high-ranking officials are near retirement, and disagreeing with a president would be more risky for them than increasing the chance of a presidential assassination);
- Unfair treatments - not hardships - destroy morale (e.g. unfair promotions and contempt are much more damaging than doing long and boring surveillance missions or training exercises where trainees actually feel the pain from the fake bullets for the rest of the day).
Some takeaways
- Maybe don't build big bureaucracies if you can avoid it: once created, they are hard to move, and the leadership will often favor things that go against the mission of the organization (e.g. because changing things is risky for people in leadership positions, except when it comes to mission creep) - Caveat: the book was written by a conservative, and so that probably taints what information was conveyed on this topic;
- Some near misses provide extremely valuable information, even when they are quite far from actually causing a catastrophe (e.g. who are the kind of people who actually act on their public threats);
- Making people clearly accountable for near misses (not legally, just in the expectations that the leadership conveys) can be a powerful force to get people to do their job well and make sensible decisions.
Overall, the book was somewhat poor in details about how decisions are made. The main decision processes that the book reports are the changes that the author wants to see happen in the US Secret Service - but this looks like it has been dumbed down to appeal to a broad conservative audience that gets along with vibes like "if anything increases the president's safety, we should do it" (which might be true directionally given the current state, but definitely doesn't address the question of "how far should we go, and how would we know if we were at the right amount of protection"). So this may not reflect how decisions are done, since it could be a byproduct of Dan Bongino being a conservative political figure and podcast host.
Replies from: jsd, tao-lin, neel-nanda-1, Viliam↑ comment by Tao Lin (tao-lin) · 2024-06-26T17:34:47.455Z · LW(p) · GW(p)
yeah learning from distant near misses is important! Feels that way in risky electric unicycling.
↑ comment by Neel Nanda (neel-nanda-1) · 2024-06-24T00:43:25.535Z · LW(p) · GW(p)
This was interesting, thanks! I really enjoy your short book reviews
↑ comment by Viliam · 2024-06-24T10:33:27.064Z · LW(p) · GW(p)
Some near misses provide extremely valuable information
Not just near misses. The recent assassination attempt in Slovakia made many people comment: "This is what you get when you fire the competent people in the police, and replace them with politically loyal incompetents." So maybe the future governments will be a bit more careful about the purges in police.
comment by Fabien Roger (Fabien) · 2024-04-04T04:42:31.120Z · LW(p) · GW(p)
I listened to the book This Is How They Tell Me the World Ends by Nicole Perlroth, a book about cybersecurity and the zero-day market. It describes in detail the early days of bug discovery, the social dynamics and moral dilemma of bug hunts.
(It was recommended to me by some EA-adjacent guy very worried about cyber, but the title is mostly bait: the tone of the book is alarmist, but there is very little content about potential catastrophes.)
My main takeaways:
- Vulnerabilities used to be dirt-cheap (~$100) but are still relatively cheap (~$1M even for big zero-days);
- If you are very good at cyber and extremely smart, you can hide vulnerabilities in 10k-lines programs in a way that less smart specialists will have trouble discovering even after days of examination - code generation/analysis is not really defense favored;
- Bug bounties are a relatively recent innovation, and it felt very unnatural to tech giants to reward people trying to break their software;
- A big lever companies have on the US government is the threat that overseas competitors will be favored if the US gov meddles too much with their activities;
- The main effect of a market being underground is not making transactions harder (people find ways to exchange money for vulnerabilities by building trust), but making it much harder to figure out what the market price is and reducing the effectiveness of the overall market;
- Being the target of an autocratic government is an awful experience, and you have to be extremely careful if you put anything they dislike on a computer. And because of the zero-day market, you can't assume your government will suck at hacking you just because it's a small country;
- It's not that hard to reduce the exposure of critical infrastructure to cyber-attacks by just making companies air gap their systems more - Japan and Finland have relatively successful programs, and Ukraine is good at defending against that in part because they have been trying hard for a while - but it's a cost companies and governments are rarely willing to pay in the US;
- Electronic voting machines are extremely stupid, and the federal gov can't dictate how the (red) states should secure their voting equipment;
- Hackers want lots of different things - money, fame, working for the good guys, hurting the bad guys, having their effort be acknowledged, spite, ... and sometimes look irrational (e.g. they sometimes get frog-boiled).
- The US government has a good amount of people who are freaked out about cybersecurity and have good warning shots to support their position. The main difficulty in pushing for more cybersecurity is that voters don't care about it.
- Maybe the takeaway is that it's hard to build support behind the prevention of risks that 1. are technical/abstract and 2. fall on the private sector and not individuals 3. have a heavy right tail. Given these challenges, organizations that find prevention inconvenient often succeed in lobbying themselves out of costly legislation.
Overall, I don't recommend this book. It's very light on details compared to The Hacker and the State despite being longer. It targets an audience which is non-technical and very scope insensitive, is very light on actual numbers, technical details, real-politic considerations, estimates, and forecasts. It is wrapped in an alarmist journalistic tone I really disliked, covers stories that do not matter for the big picture, and is focused on finding who is in the right and who is to blame. I gained almost no evidence either way about how bad it would be if the US and Russia entered a no-holds-barred cyberwar.
Replies from: Buck, MondSemmel, timot.cool, niplav↑ comment by Buck · 2024-04-04T16:42:02.138Z · LW(p) · GW(p)
- If you are very good at cyber and extremely smart, you can hide vulnerabilities in 10k-lines programs in a way that less smart specialists will have trouble discovering even after days of examination - code generation/analysis is not really defense favored;
Do you have concrete examples?
Replies from: faul_sname, Fabien↑ comment by faul_sname · 2024-04-05T05:18:40.818Z · LW(p) · GW(p)
One example, found by browsing aimlessly through recent high-severity CVE, is CVE-2023-41056. I chose that one by browsing through recent CVEs for one that sounded bad, and was on a project that has a reputation for having clean, well-written, well-tested code, backed by a serious organization. You can see the diff that fixed the CVE here. I don't think the commit that introduced the vulnerability was intentional... but it totally could have been, and nobody would have caught it despite the Redis project doing pretty much everything right, and there being a ton of eyes on the project.
As a note, CVE stands for "Common Vulnerabilities and Exposures". The final number in the CVE identifier (i.e. CVE-2023-41056 in this case) is a number that increments sequentially through the year. This should give you some idea of just how frequently vulnerabilities are discovered.
The dirty open secret in the industry is that most vulnerabilities are never discovered, and many of the vulns that are discovered are never publicly disclosed.
↑ comment by Fabien Roger (Fabien) · 2024-04-05T15:55:41.349Z · LW(p) · GW(p)
I remembered mostly this story:
[...] The NSA invited James Gosler to spend some time at their headquarters in Fort Meade, Maryland in 1987, to teach their analysts [...] about software vulnerabilities. None of the NSA team was able to detect Gosler’s malware, even though it was inserted into an application featuring only 3,000 lines of code. [...]
[Taken from this summary of this passage of the book. The book was light on technical detail, I don't remember having listened to more details than that.]
I didn't realize this was so early in the story of the NSA, maybe this anecdote teaches us nothing about the current state of the attack/defense balance.
Replies from: Fabien↑ comment by Fabien Roger (Fabien) · 2024-04-05T15:59:49.037Z · LW(p) · GW(p)
The full passage in this tweet thread (search for "3,000").
↑ comment by MondSemmel · 2024-04-04T11:16:25.642Z · LW(p) · GW(p)
Maybe the takeaway is that it's hard to build support behind the prevention of risks that 1. are technical/abstract and 2. fall on the private sector and not individuals 3. have a heavy right tail. Given these challenges, organizations that find prevention inconvenient often succeed in lobbying themselves out of costly legislation.
Which is also something of a problem for popularising AI alignment. Some aspects of AI (in particular AI art) do have their detractors already, but that won't necessarily result in policy that helps vs. x-risk.
↑ comment by tchauvin (timot.cool) · 2024-04-04T12:54:42.958Z · LW(p) · GW(p)
If you are very good at cyber and extremely smart, you can hide vulnerabilities in 10k-lines programs in a way that less smart specialists will have trouble discovering even after days of examination - code generation/analysis is not really defense favored
I think the first part of the sentence is true, but "not defense favored" isn't a clear conclusion to me. I think that backdoors work well in closed-source code, but are really hard in open-source widely used code − just look at the amount of effort that went into the recent xz / liblzma backdoor, and the fact that we don't know of any other backdoor in widely used OSS.
The main effect of a market being underground is not making transactions harder (people find ways to exchange money for vulnerabilities by building trust), but making it much harder to figure out what the market price is and reducing the effectiveness of the overall market
Note this doesn't apply to all types of underground markets: the ones that regularly get shut down (like darknet drug markets) do have a big issue with trust.
Being the target of an autocratic government is an awful experience, and you have to be extremely careful if you put anything they dislike on a computer. And because of the zero-day market, you can't assume your government will suck at hacking you just because it's a small country
This is correct. As a matter of personal policy, I assume that everything I write down somewhere will get leaked at some point (with a few exceptions, like − hopefully − disappearing signal messages).
Replies from: quetzal_rainbow↑ comment by quetzal_rainbow · 2024-04-05T06:34:43.495Z · LW(p) · GW(p)
The reason why xz backdoor was discovered is increased latency, which is textbook side channel. If attacker had more points in security mindset skill tree, it wouldn't happen.
↑ comment by niplav · 2024-04-04T07:48:13.192Z · LW(p) · GW(p)
it felt very unnatural to tech giants to reward people trying to break their software;
Same for governments, afaik most still don't have bug bounty programs for their software.
Nevermind, a short google shows multiple such programs, although others have been hesitant to adopt them.
comment by Fabien Roger (Fabien) · 2024-03-22T02:34:03.757Z · LW(p) · GW(p)
I just finished listening to The Hacker and the State by Ben Buchanan, a book about cyberattacks, and the surrounding geopolitics. It's a great book to start learning about the big state-related cyberattacks of the last two decades. Some big attacks /leaks he describes in details:
- Wire-tapping/passive listening efforts from the NSA, the "Five Eyes", and other countries
- The multi-layer backdoors the NSA implanted and used to get around encryption, and that other attackers eventually also used (the insecure "secure random number" trick + some stuff on top of that)
- The shadow brokers (that's a *huge* leak that went completely under my radar at the time)
- Russia's attacks on Ukraine's infrastructure
- Attacks on the private sector for political reasons
- Stuxnet
- The North Korea attack on Sony when they released a documentary criticizing their leader, and misc North Korean cybercrime (e.g. Wannacry, some bank robberies, ...)
- The leak of Hillary's emails and Russian interference in US politics
- (and more)
Main takeaways (I'm not sure how much I buy these, I just read one book):
- Don't mess with states too much, and don't think anything is secret - even if you're the NSA
- The US has a "nobody but us" strategy, which states that it's fine for the US to use vulnerabilities as long as they are the only one powerful enough to find and use them. This looks somewhat nuts and naive in hindsight. There doesn't seem to be strong incentives to protect the private sector.
- There are a ton of different attack vectors and vulnerabilities, more big attacks than I thought, and a lot more is publicly known than I would have expected. The author just goes into great details about ~10 big secret operations, often speaking as if he was an omniscient narrator.
- Even the biggest attacks didn't inflict that much (direct) damage (never >10B in damage?) Unclear if it's because states are holding back, if it's because they suck, or if it's because it's hard. It seems that even when attacks aim to do what some people fear the most (e.g. attack infrastructure, ...) the effect is super underwhelming.
- The bottleneck in cyberattacks is remarkably often the will/the execution, much more than actually finding vulnerabilities/entry points to the victim's network.
- The author describes a space where most of the attacks are led by clowns that don't seem to have clear plans, and he often seems genuinely confused why they didn't act with more agency to get what they wanted (does not apply to the NSA, but does apply to a bunch of Russia/Iran/Korea-related attacks)
- Cyberattacks are not amazing tools to inflict damage or to threaten enemies if you are a state. The damage is limited, and it really sucks that (usually) once you show your capability, it reduces your capability (unlike conventional weapons). And states don't like to respond to such small threats. The main effect you can have is scaring off private actors from investing in a country / building ties with a country and its companies, and leaking secrets of political importance.
- Don't leak secrets when the US presidential election is happening if they are unrelated to the election, or nobody will care.
(The author seems to be a big skeptic of "big cyberattacks" / cyberwar, and describes cyber as something that always happens in the background and slowly shapes the big decisions. He doesn't go into the estimated trillion dollar in damages of everyday cybercrime, nor the potential tail risks of cyber.)
Replies from: neel-nanda-1↑ comment by Neel Nanda (neel-nanda-1) · 2024-04-06T10:55:47.415Z · LW(p) · GW(p)
Thanks! I read and enjoyed the book based on this recommendation
comment by Fabien Roger (Fabien) · 2024-06-21T22:43:17.799Z · LW(p) · GW(p)
[Edit: The authors released code and probing experiments. Some of the empirical predictions I made here resolved, and I was mostly wrong. See here [LW(p) · GW(p)] for my takes and additional experiments.]
I have a few concerns about Improving Alignment and Robustness with Circuit Breakers, a paper that claims to have found a method which achieves very high levels of adversarial robustness in LLMs.
I think hype should wait for people investigating the technique (which will be easier once code and datasets are open-sourced), and running comparisons with simpler baselines (like probing). In particular, I think that:
- Circuit breakers won’t prove significantly more robust than regular probing in a fair comparison.[1]
- Once the code or models are released, people will easily find reliable jailbreaks.
Here are some concrete predictions:
- p=0.7 that using probing well using the same training and evaluation data results can beat or match circuit breakers.[2] [Edit: resolved to False]
- p=0.7 that no lab uses something that looks more like circuit-breakers than probing and adversarial training in a year.
- p=0.8 that someone finds good token-only jailbreaks to whatever is open-sourced within 3 months. [Edit: this is only about Cygnet, since the paper shows that just RR isn't perfectly robust.]
- p=0.5 that someone finds good token-only jailbreaks to whatever is publicly available through an API within 3 months.[3] [Edit: this is only about Cygnet, since the paper shows that just RR isn't perfectly robust.]
I think the authors would agree with most of my predictions. My main disagreement is with the hype.
How do circuit-breakers compare to probing?
What does circuit-breakers training do? The only interpretation that feels plausible is that the LLM classifies the prompt as harmful or not harmful, and then messes up with its own activations if the prompt is classified as harmful. If this is the case, then the LLM needs to use an internal classifier, and I think it should be possible to extract an accurate harmfulness probe (linear or not linear) around these layers, and instead of messing up the activation.
The equivalent to circuit-breakers if you probe:
- At every token position, and takes something like a max over position (if a single position messes up the activations, it might propagate to every position);
- In particular, this means that suffix GCG and input embed attacks tested in the paper might be much worse than prefix+suffix GCG or input embed attacks. (p=0.5 that using prefix+suffix GCG makes finding a GCG attack of comparable strength on average 4x faster [Edit: resolved to false]).
- On output tokens, i.e. model-generated answers (and output classifiers are known to be more powerful than input-only classifiers).
Would probing be weaker against GCG and input embed attacks than circuit-breakers? I think it would be, but only superficially: probing is strong against GCG and input embed attacks if the attack only targets the model, but not the probe. The fair comparison is an attack on the probe+LLM vs an attack on a circuit-breakers model. But actually, GCG and other gradient-based attack have a harder time optimizing against the scrambled activations. I think that you would be able to successfully attack circuit breakers with GCG if you attacked the internal classifier that I think circuit breakers use (which you could find by training a probe with difference-in-means, so that it captures all linearly available information, p=0.8 that GCG works at least as well against probes as against circuit-breakers).
The track record looks quite bad
The track record for overselling results and using fancy techniques that don't improve on simpler techniques is somewhat bad in this part of ML.
I will give one example. The CUT unlearning technique presented in the WMDP paper (with overlapping authors to the circuit-breakers one):
- Got a massive simplification of the main technique within days of being released - thanks to the authors open-sourcing the code and Sam Marks and Oam Patel doing an independent investigation of the technique. (See the difference between v2 and v3 on arxiv.)
- Aims to do unlearning in a way that removes knowledge from LLMs (they make the claim implicitly on https://www.wmdp.ai/), but only modifies the weights of 3 layers out of 32 (so most of the harmful information is actually still there).
- ^
When I say “probing”, I mainly think about probing on outputs i.e. model-generated answers (and maybe inputs i.e. user prompts), like I did in the coup probes post [AF · GW], but whose application to jailbreak robustness sadly got very little attention from the academic community. I’m sad that the first paper that actually tries to do something related does something fancy instead of probing.
- ^
More precisely, a probing methodology is found within 6 months of the data being released that beats or matches circuit-breakers ASR on all metrics presented in the paper. When using gradient-based methods or techniques that rely on prompt iteration more generally, attacks on circuit-breakers should use the best proxy for the internal classifier of the circuit-breaker.
- ^
Most of the remaining probability mass is on worlds where either people care way less than they care for Claude - e.g because the model sucks much more than open-source alternatives, and on worlds where they use heavy know-your-customer mitigations.
↑ comment by Dan H (dan-hendrycks) · 2024-06-22T03:14:31.977Z · LW(p) · GW(p)
Got a massive simplification of the main technique within days of being released
The loss is cleaner, IDK about "massively," because in the first half of the loss we use a simpler distance involving 2 terms instead of 3. This doesn't affect performance and doesn't markedly change quantitative or qualitative claims in the paper. Thanks to Marks and Patel for pointing out the equivalent cleaner loss, and happy for them to be authors on the paper.
p=0.8 that someone finds good token-only jailbreaks to whatever is open-sourced within 3 months.
This puzzles me and maybe we just have a different sense of what progress in adversarial robustness looks like. 20% that no one could find a jailbreak within 3 months? That would be the most amazing advance in robustness ever if that were true and should be a big update on jailbreak robustness tractability. If it takes the community more than a day that's a tremendous advance.
people will easily find reliable jailbreaks
This is a little nonspecific (does easily mean >0% ASR with an automated attack, or does it mean a high ASR?). I should say we manually found a jailbreak after messing with the model for around a week after releasing. We also invited people who have a reputation as jailbreakers to poke at it and they had a very hard time. Nowhere did we claim "there are no more jailbreaks and they are solved once and for all," but I do think it's genuinely harder now.
Circuit breakers won’t prove significantly more robust than regular probing in a fair comparison
We had the idea a few times to try out a detection-based approach but we didn't get around to it. It seems possible that it'd perform similarly if it's leaning on the various things we did in the paper. (Obviously probing has been around but people haven't gotten results at this level, and people have certainly tried using detecting adversarial attacks in hundreds of papers in the past.) IDK if performance would be that different from circuit-breakers, in which case this would still be a contribution. I don't really care about the aesthetics of methods nearly as much as the performance, and similarly performing methods are fine in my book. A lot of different-looking deep learning methods perform similarly. A detection based method seems fine, so does a defense that's tuned into the model; maybe they could be stacked. Maybe will run a detector probe this weekend and update the paper with results if everything goes well. If we do find that it works, I think it'd be unfair to desscribe this after the fact as "overselling results and using fancy techniques that don't improve on simpler techniques" as done for RMU.
My main disagreement is with the hype.
We're not responsible for that. Hype is inevitable for most established researchers. Mediocre big AI company papers get lots of hype. Didn't even do customary things like write a corresponding blog post yet. I just tweeted the paper and shared my views in the same tweet: I do think jailbreak robustness is looking easier than expected, and this is affecting my priorities quite a bit.
Aims to do unlearning in a way that removes knowledge from LLMs
Yup that was the aim for the paper and for method development. We poked at the method for a whole month after the paper's release. We didn't find anything, though in that process I slowly reconceptualized RMU as more of a circuit-breaking technique and something that's just doing a bit of unlearning. It's destroying some key function-relevant bits of information that can be recovered, so it's not comprehensively wiping. IDK if I'd prefer unlearning (grab concept and delete it) vs circuit-breaking (grab concept and put an internal tripwire around it); maybe one will be much more performant than the other or easier to use in practice. Consequently I think there's a lot to do in developing unlearning methods (though I don't know if they'll be preferable to the latter type of method).
overselling results and using fancy techniques that don't improve on simpler techniques
This makes it sound like the simplification was lying around and we deliberately made it more complicated, only to update it to have a simpler forget term. We compare to multiple baselines, do quite a bit better than them, do enough ablations to be accepted at ICML (of course there are always more you could want), and all of our numbers are accurate. We could have just included the dataset without the method in the paper, and it would have still got news coverage (Alex Wang who is a billionaire was on the paper and it was on WMDs).
Probably the only time I chose to use something a little more mathematically complicated than was necessary was the Jensen-Shannon loss in AugMix. It performed similarly to doing three pairwise l2 distances between penultimate representations, but this was more annoying to write out. Usually I'm accused of doing papers that are on the simplistic side (sometimes papers like the OOD baseline paper caused frustration because it's getting credit for something very simple) since I don't optimize for cleverness, and my collaborators know full well that I discourage trying to be clever since it's often anticorrelated with performance.
Not going to check responses because I end up spending too much time typing for just a few viewers.
Replies from: ryan_greenblatt↑ comment by ryan_greenblatt · 2024-06-22T03:38:17.894Z · LW(p) · GW(p)
↑ comment by Fabien Roger (Fabien) · 2024-07-16T15:39:08.464Z · LW(p) · GW(p)
I think that you would be able to successfully attack circuit breakers with GCG if you attacked the internal classifier that I think circuit breakers use (which you could find by training a probe with difference-in-means, so that it captures all linearly available information, p=0.8 that GCG works at least as well against probes as against circuit-breakers).
Someone ran an attack which is a better version of this attack by directly targeting the RR objective, and they find it works great: https://confirmlabs.org/posts/circuit_breaking.html#attack-success-internal-activations
↑ comment by Neel Nanda (neel-nanda-1) · 2024-06-21T23:57:18.839Z · LW(p) · GW(p)
I think it was an interesting paper, but this analysis and predictions all seem extremely on point to me
comment by Fabien Roger (Fabien) · 2025-03-22T00:50:04.283Z · LW(p) · GW(p)
I ran quick experiments that make me think that it's somewhat hard for LLMs to learn radically new encodings in an unsupervised way, and thus that LLMs probably won't learn to speak new incomprehensible languages as a consequence of big r1-like RL in the next few years.
The experiments
I trained Llama 3-8B and some medium-size internal Anthropic models to speak using an encoding style that is very rare on the internet (e.g. map each letter to a random name, and join the names) with SFT on the encoded text and without providing translation pairs. I find that the resulting models:
- Have relatively high next-token-prediction losses
- Can't speak well (e.g. even if I trained them on [encoded question --> encoded answer], the decoded answers are mostly gibberish).
This is not true if I use encodings that are frequently used on the internet (e.g. base64, random letter permutations, ...), and this is less true if I add translation pairs to the training mix.
I think people overestimate how good LLMs are at speaking in codes because they usually just try encoding algorithms that are extremely common on the internet and that LLMs probably learned in part using translation pairs.
These experiments were done at a relatively small scale (80k sequences of ~50 tokens each, for 40 epochs, for a total of 160M tokens), and I could imagine things being different for large scale SFT or SFT with better base models. But given that RL doesn't teach models that many new bits (you can distill r1 scratchpads using only a few MB of transcripts), I think this is still informative for large-scale RL.
Context
I ended up giving up on the broader projects as part of which I ran these experiments, but I think they are decently informative about the plausibility of LLMs learning to speak new incomprehensible languages.
I did not carefully run any of the experiments above, and I welcome replications.
Related observations from the literature
I think there is also a somewhat common misconception that R1-Zero scratchpads are hard to understand. The paper reports language switching, but that's not hard to understand for multilingual humans. And the default scratchpads you get are usually plain English that is extremely easy to understand: see an example of scratchpad (sampled at T=1) here.
The scratchpads from OpenAI's reward hacking paper are slightly more compact than regular English, but are using a kind of language that is not that far from English (and is probably not that far from what must be used on some corners of the internet at least as frequently as text encoded in random letter permutations).
Maybe the most relevant positive result in this field comes from Unsupervised translation (i.e. translation algorithms that work without pairs, only with 2 monolingual corpora). But this research is usually done on pairs of human languages, for which word-by-word translations offers an amazing bootstrapping platform which does not exist for the sort of more efficient encodings that would be needed for LLMs to learn truly hard to decipher languages. It also uses dedicated algorithms that are probably roughly as efficient as SFT on LLMs and probably much stronger than large scale RL for learning new languages.
More discussion
- Anecdotally, when LLMs speak other languages (e.g. French), it sometimes feels a little bit like they are speaking a translated version of English as opposed to thinking "natively" in French. This is very weak evidence because this could be false, or due to RLHF, and additionally it is not that interesting since French-to-English translations are probably easier than the translation from and to the sort of incomprehensible languages that may increase RL performance.
- Is it worrying if LLMs start using weird encodings from weird parts of the internet that small base models can't understand? I think it's somewhat worrying, but not as much as "de novo" incomprehensible languages because:
- It means some humans can probably translate back and forth from this encoding quite easily, which means it should be feasible for people at labs to notice and learn this encoding
- Light SFT on top of the strongest base models is likely to elicit a translator for the weird encoding (which could be much trickier if the language was spoken only by a scheming heavily RLed model)
- Here is a concrete prediction: Claude 3.5 Sonnet, GPT-4o and Gemini 2 Pro will be able to understand the topics considered in 99%+ of Chain-of-Thoughts of all regular Transformers trained in 2025 and 2026 that were not deliberately trained or prompted to be harder to understand (p=0.7).
↑ comment by Thane Ruthenis · 2025-03-22T19:01:40.093Z · LW(p) · GW(p)
That's a worthwhile research direction, but I don't find the results here convincing. This experiment seems to involve picking an arbitrary and deliberately unfamiliar-to-the-LLM encoding, and trying to force the LLM to use it. That's not the threat model with RL causing steganography, the idea there is the opposite: that there is some encoding which would come natural to the model, more natural than English, and that RL would beeline for it.
"LLMs are great at learning to think in arbitrary encodings" was never part of that threat model. The steganographic encoding would not be arbitrary nor alien-to-the-LLM.
Replies from: Fabien↑ comment by Fabien Roger (Fabien) · 2025-03-22T21:58:45.995Z · LW(p) · GW(p)
My experiments are definitely not great at ruling out this sort of threat model. But I think they provide some evidence that LLMs are probably not great at manipulating generic non-pretraining encodings (the opposite result would have provided evidence that there might be encodings that are extremely easy to learn - I think my result (if they reproduce) do not reduce the variance between encodings, but they should shift the mean).
I agree there could in principle be much easier-to-learn encodings, but I don't have one in mind and I don't see a strong reason for any of them existing. What sorts of encoding do you expect to be natural to LLMs besides encodings already present in pretraining and that GPT-4o can decode? What would make a brand new encoding easy to learn? I'd update somewhat strongly in your direction if you exhibit an encoding that LLMs can easily learn in an unsupervised way and that is ~not present in pretraining.
Replies from: Thane Ruthenis↑ comment by Thane Ruthenis · 2025-03-23T07:51:22.194Z · LW(p) · GW(p)
What sorts of encoding do you expect to be natural to LLMs besides encodings already present in pretraining and that GPT-4o can decode?
Spitballing: Some sort of trivial-but-abstract combination of the encodings present in pretraining that produces an encoding that's particularly easy for the LLM to think in due to their architecture/learned associations, but which is opaque to us, because the abstract space in which the combination is trivial is hopelessly beyond our current theory of languages, such that we can't easily reverse-engineer it.
"Switching between languages every sentence" is a trivial first step. Next step might be something like "using poetic metaphors in every language" or "thinking in subtle information-dense multilingual puns", such that you need actual human polyglots to translate. Beyond that, it might move to freestyling words by combining characters from random languages in ways such that they happen to evoke useful concepts in the LLM when seen through its omniglot-poet lens[1], but which teams of human polyglots need hours to untangle. At this stage, idiosyncratic meanings completely alien to us but visible to the LLM would also come into play, see the " petertodd" phenomenon [LW · GW], so perhaps the polyglot teams would also need to have janus-style LLM whisperers present. And then it gets worse from there.
Edit: Here, I dug up an example. I'd run some experiments on it back in 2023 and it turned out to be much less impressive than it looks[2], but imagine if LLMs actually started to think in this kind of code.
Again, this is just a throwaway example scenario, but this is the sort of thing I expect. From my perspective, LLMs starting to switch between languages once RL'd is a clear precursor of such a nightmare scenario once RL is ramped up, not something that's tame. (Though I admit it's been less bad than I'd expected so far. I guess I haven't seen what the trajectories of reasoning models of the second generation look like.)
- ^
E. g., using one language's rules for creating compound words while taking the morphemes from different languages (and emoji, why not), such as surrounding a Japanese kanji with Latin and Russian prefixes and suffixes, and wrapping the whole thing in the poetry tradition of a fourth language.
- ^
The LLM doesn't make the encoding incomprehensible if you don't literally ask it to make it incomprehensible, and the encoding doesn't change depending on whether you inform it that it's for its future instance or not. So it's not actually doing self-modeling to figure out the best way to encode text for itself. Still, it does demonstrate that it can reverse this sort of wild-looking code due to its learned webs of associations, in ways that would be very hard for humans to untangle.
↑ comment by Fabien Roger (Fabien) · 2025-03-23T18:31:46.239Z · LW(p) · GW(p)
Thanks for the example! I think it moderately convinced me that having CoT become hard for humans to understand in the next 2 years is slightly more plausible than I thought.
I still think that even for the things you described, it will be relatively easy for the base model to understand what is going on, and it's likely that GPT-4o will too. See the discussion in another comment thread about "chicken-and-egg" problems when learning new encodings, which I think make it much easier to learn things like switching languages or skipping stopwords that take almost no additional effort to decode (therefore the it is incentivized to use the new encoding without the need to learn a new decoder). I see how once you get a model using "freestyling words" frequently the decoder becomes better over time at understanding freestyling in general (though it will be slow because it is trained using RL rather than SL), which allows you to eventually shift to encodings that the base model and GPT-4o don't understand, but my guess is that this will take a long time (>the first 1e28 FLOP RL run?).
Replies from: Thane Ruthenis↑ comment by Thane Ruthenis · 2025-03-23T18:50:19.547Z · LW(p) · GW(p)
I still think that even for the things you described, it will be relatively easy for the base model to understand what is going on, and it's likely that GPT-4o will too
Maaaybe. Note, though, that "understand what's going on" isn't the same as "faithfully and comprehensively translate what's going on into English". Any number of crucial nuances might be accidentally lost in translation (due to the decoder model not properly appreciating how important they are), or deliberately hidden (if the RL'd model performs a sneaky jailbreak on the decoder, see Pliny-style token bombs or jailbreaks encoded in metaphor).
↑ comment by ryan_greenblatt · 2025-03-22T00:59:51.339Z · LW(p) · GW(p)
I think the RL case might be more analogous to the translation pair case than the "just the encoded text" case. How does that alter the bottom line?
Replies from: Fabien↑ comment by Fabien Roger (Fabien) · 2025-03-22T01:12:32.557Z · LW(p) · GW(p)
I think it's only somewhat more analogous: if you slowly transition to a new language, you don't have incentives to have translations pairs with redundant content. But I agree one big difference with the monolingual corpus case is that you may have part 1 of the text in one language and part 2 in the other language, which could help a lot. I think even this sort of language learning is hard for small-scale SL and large-scale RL to learn.
(I also think that there is a more frightening version of the "new incomprehensible language" hypothesis: the case where you learn a new language to express thoughts which are hard to express in English. This is not analogous to any translation experiment, and I expect it to be brutal for small-scale SL and large-scale RL to learn a full language in which complex thoughts can be expressed.)
Replies from: ryan_greenblatt, ryan_greenblatt↑ comment by ryan_greenblatt · 2025-03-22T02:56:23.593Z · LW(p) · GW(p)
How much flop do you think it takes for large scale RL to learn codes? Let's say RL learns 100x less than SL (seems plausible) and is only 10% as focused on learning new ways of thinking / languages as SL. Then, we'd expect that reasonably efficient RL with 3 OOMs more FLOP than big pretraining runs (that do learn this to some extent) could learn new languages. This would naively be a ~1e27 FLOP RL run (assuming that we can learn this much stuff in 1e24 FLOP pretraining runs).
I think we'll probably see 1e27 FLOP RL runs next year?
Replies from: gwern, Fabien↑ comment by gwern · 2025-03-22T19:42:39.151Z · LW(p) · GW(p)
You would also expect that the larger models will be more sample-efficient, including at in-context learning of variations of existing tasks (which of course is what steganography is). So all scale-ups go much further than any experiment at small-scale like 8B would indicate. (No idea what 'medium-scale' here might mean.)
↑ comment by Fabien Roger (Fabien) · 2025-03-22T22:11:12.128Z · LW(p) · GW(p)
I think it's much worse than that.
First, I think RL is more like 10,000x than 100x less efficient than SL (deepseek v3 probably can't be compressed much below 10GB, while deepseek r1-zero stage can probably be compressed to 1MB of transcripts, despite both being roughly 1e24 FLOP).
Additionally, learning new languages is likely a much harder task than regular math RL, because you have chicken-and-egg issues (you are not incentivized to encode a new structure before knowing how to decode it, and you are not incentivized to decode it before you encode it). We have some empirical evidence of this: people struggle to make even simple steganography appear in RL setups which incentivize it the most. Maybe simple encodings can bootstrap to more complex encodings and this bypasses some of the chicken-and-egg issues, but I'm not sure. Chicken-and-egg problems also mean you benefit a lot from having many serial steps of RL when learning an encoding, and while RL can probably be scaled massively in parallel, high latency of generations imply there probably won't be massive scale ups of the number of serial steps of RL compared to what r1 already did. (This is a hand-wavy argument, it might be incorrect.)
Replies from: ryan_greenblatt↑ comment by ryan_greenblatt · 2025-03-23T01:15:09.828Z · LW(p) · GW(p)
First, I think RL is more like 10,000x than 100x less efficient than SL (deepseek v3 probably can't be compressed much below 10GB, while deepseek r1-zero stage can probably be compressed to 1MB of transcripts, despite both being roughly 1e24 FLOP).
Maybe this is true for SL on trajectories from the post-RL policy, but this doesn't clearly seem like the right way to think about it from my perspective.
↑ comment by ryan_greenblatt · 2025-03-22T01:14:28.167Z · LW(p) · GW(p)
Doesn't SL already learn a full language in which complex thoughts can be expressed? I agree it was brutal, it required >1e24 flop, but still.
Replies from: Fabien↑ comment by Fabien Roger (Fabien) · 2025-03-22T01:17:57.274Z · LW(p) · GW(p)
Edited to say "small-scale SL and large-scale RL"
↑ comment by Neel Nanda (neel-nanda-1) · 2025-03-23T21:06:53.128Z · LW(p) · GW(p)
Are the joint names separated by spaces if not, the tokenization is going to be totally broken more generally I would be interested to see this Tried with a code that EG maps familiar tokens to obscure ones or something like mapping token with id k to id maximum minus K. Tokens feel like the natural way in llm would represent its processing and thus encoded processing. Doing things in individual letters is kind of hard
Replies from: Fabien↑ comment by Fabien Roger (Fabien) · 2025-03-24T12:23:27.805Z · LW(p) · GW(p)
They were separated by spaces. (But I'd encourage replication before updating too hard on results which I think are very weird.)
↑ comment by Mis-Understandings (robert-k) · 2025-03-22T13:30:26.946Z · LW(p) · GW(p)
Watch out, we know that there are some hard encodings. If all the names used are single token, this looks like tokenizing on characters, which we know is a harder problem than tokenizing as normal.
Replies from: Fabien↑ comment by Fabien Roger (Fabien) · 2025-03-22T21:50:42.900Z · LW(p) · GW(p)
I also ran experiments where I just space-separated characters and base64 text, and LLMs had a much easier time with both of those, despite tokenization being roughly similar / worse. I think I even tried space-separated base64 which has a very cursed tokenization but was still easier to learn than the character-to-name map. I am still confused by why, in my experiments, LLMs struggled to speak using the character-to-name mapping. Maybe I did something wrong.
Replies from: robert-k↑ comment by Mis-Understandings (robert-k) · 2025-03-22T22:42:44.430Z · LW(p) · GW(p)
I think maybe blanking the embedding of the name tokens, and retraining, should make the effect go away?
But that is a discrete jump that would not be found by SGD, and would break performance on previous tasks.
Also for the random names, is the encoding random, (different names each time) or hashed (there is a lookup table)?
If truly random, we would expect FT to get high loss because it must predict through a random/pseudorandom function, which means a high problem entropy not high model loss.
Replies from: Fabien↑ comment by Fabien Roger (Fabien) · 2025-03-22T23:26:56.229Z · LW(p) · GW(p)
A detail I forgot to mention and that might be important is that I was training the model to use one of several encodings (with a prefix specifying which one was used) to avoid this sort of implicit translation that goes through just changing embedding matrices. But that would have been a good sanity check to run to make sure that the model would learn to do the simple embedding matrix change when this is an optimal strategy (I would be very surprised if SGD was not able to find this simple transformation, what I claim is tricky is learning a new weird encoding while maintaining the other capabilities, though I am confused enough here that I don't claim to make very accurate prediction in this domain).
The encoding was a lookup table.
Replies from: robert-k↑ comment by Mis-Understandings (robert-k) · 2025-03-23T02:24:04.524Z · LW(p) · GW(p)
in CoT finetuning, there is no explicit pressure against encoding co-evolution in the CoT and decoder model, if both are identical or fine tuned in the same pass.
This means that hidden reasoning might be harder? But there is a big disanalogy here. That switching of modes might be the hard part, not the encoding itself.
↑ comment by Willow BP (bumjin-park) · 2025-03-22T12:28:32.476Z · LW(p) · GW(p)
I think LLMs are even worse — not just with rare encodings, but also when it comes to reasoning with rare structures. Theory-of-mind tasks provide good evidence for this. LLMs aren't good at inferring others’ mental states; rather, they tend to mimic reasoning when reasoning steps are present in the training data.
↑ comment by Bronson Schoen (bronson-schoen) · 2025-03-22T02:07:44.837Z · LW(p) · GW(p)
I might be a bit confused on the threat model here:
The scratchpads from OpenAI's reward hacking paper are slightly more compact than regular English, but are using a kind of language that is not that far from English (and is probably not that far from what must be used on some corners of the internet at least as frequently as text encoded in random letter permutations).
To me the salient property of the “unmonitorable” CoTs in that paper are “you cannot predict the action from the CoT anymore”.
For example, is the claim with:
Here is a concrete prediction: Claude 3.5 Sonnet, GPT-4o and Gemini 2 Pro will be able to understand the topics considered in 99%+ of Chain-of-Thoughts of all regular Transformers trained in 2025 and 2026 that were not deliberately trained or prompted to be harder to understand (p=0.7).
Equivalent to:
Here is a concrete prediction: Claude 3.5 Sonnet, GPT-4o and Gemini 2 Pro will be able to serve as an effective CoT only monitor in 99%+ of Chain-of-Thoughts of all regular …
Or do you see the latter as a much stronger claim?
What is the threat model where a model needs to learn something as complex as a full encoding?
Replies from: Fabien↑ comment by Fabien Roger (Fabien) · 2025-03-22T10:48:58.897Z · LW(p) · GW(p)
The threat model here is that the model uses the CoT in order to have much more complex schemes than what it could do in a forward pass. This is not about “you cannot predict the action from the CoT anymore”. More discussion of why I care about the former threat model here [LW · GW] and here [LW · GW].
serve as an effective CoT only monitor
I'd specify for situations where doing something bad can't be done in a single forward pass and requires CoT reasoning. This is harder to define / measure so I went with something simpler but which I think is a decent proxy. (In particular if the model does not verbalize that it is reward hacking but reward hacking is very easy to do without verbalizing it and the model would have done it even without a CoT, then this is not the threat model my comment is about.)
Replies from: bronson-schoen↑ comment by Bronson Schoen (bronson-schoen) · 2025-03-22T13:46:31.596Z · LW(p) · GW(p)
Thanks for the clarification, the connection I have in mind is that one empirical expectation I would have is:
- (1) Assume model A is attempting to execute some complex task “on the side” (ex: systematically undermine research in a way that requires more than just a single forward pass)
- (2) Assume model B, a significantly weaker monitor, has access to this CoT and would flag something as obvious as “we must continue secretly building up an understanding of how to effectively poison the posttraining data of another model”
(3) For a sufficiently weak monitor, I would expect applying direct optimization pressure to the CoT of model A based on “is the CoT flagged by model B” would result in a strategy like “slightly reframe the wording / terms you use when thinking about the ‘poison the posttraining data of another’ research” (ex: model A learns “frame ‘research poison the posttraining data’ as ‘research ensuring quality of posttraining data’).
The conclusion of this (to me) wouldn’t be against your post above (as you explicitly condition on there not being direct optimization pressure), but it might be something like “model A doesn’t need to necessarily learn something like a full encoding or incomprehensible language, it just needs to meet the much lower bar of ‘frame things such that you don’t trigger the monitor’”.Specifically my expectation would be that even without deliberate prompting or training to make their CoT harder to understand, there will be models by 2026 which can conduct multi-turn actions requiring CoT reasoning that GPT-4o / Gemini 2 Pro could not predict via CoT monitoring, without the 2026 era models having to learn a full encoding / a new incomprehensible language”.
↑ comment by Fabien Roger (Fabien) · 2025-03-22T21:44:00.690Z · LW(p) · GW(p)
If you train against monitors, you will likely bypass monitors no matter what because of jailbreaks.
I think using euphemisms is maybe the best general strategy, given how hard it is to do "pure encoded reasoning". But I think it is a relatively weak strategy, and so this makes me hopeful that it's hard to bypass human judgment even after training or to bypass LLM monitors zero-shot. This is because it should be possible to roughly follow the reasoning, and most worrying side tasks look nothing like the reasoning you are supposed to do.
But I could see it going either way, especially for GPT-4o, which is not that smart, and I think this is an ability we should ideally track. I'm curious if you know about examples of humans thinking out loud about one problem while solving another by hiding things in their out loud thinking, or if you think you could produce a math CoT which solves one random MATH problem while looking like it is solving another.
Replies from: bronson-schoen↑ comment by Bronson Schoen (bronson-schoen) · 2025-03-23T12:05:11.365Z · LW(p) · GW(p)
I'm curious if you know about examples of humans thinking out loud about one problem while solving another by hiding things in their out loud thinking, or if you think you could produce a math CoT which solves one random MATH problem while looking like it is solving another.
A particular case I usually have in mind is:
- Documenting, researching, or understanding the potential failure modes or exploits around a problem (for example, “note: this data MUST have property Y otherwise it is vulnerable to Z”) often looks very similar regardless of whether your intent is “definitely always avoid these” or “eventually exploit these”
- For example, one thing you could reasonably want to document if you’re an automated AI alignment researcher is the subtle pitfalls in training techniques, dataset composition, etc that would result in failure modes (ex: at some point you want to make detailed notes about different ways that pressure against cot does / doesn’t induce obfuscation)
It seems like in these cases, there’s a large overlap between “aggregate a bunch of ways to sabotage training” and “genuinely make sure that you understand the dynamics of the problem space”
I think many problems in security and alignment research often have this property (for a system responsible for broad scoped long horizon tasks) where “deeply understand ways that this could go wrong to avoid them” and “deeply understand ways this could go wrong so you can exploit them” have enough overlap to potentially make this subset of research ambiguous enough in its intent to avoid being flagged by a monitor (or equivalently, ignored by human researchers once flagged).
I don’t think GSM8k problems (for example) have this property, but would be interested in any kind of minimal setup (for example some environment with some artifical ML task which has an an artificially large overlap to make this easier to experiment with)
↑ comment by Kei · 2025-03-27T04:20:54.396Z · LW(p) · GW(p)
Do you think this means that if Claude 3.7 Sonnet does in fact use steganography then your earlier experiment [LW · GW] wouldn't have found evidence for it, since you didn't fine-tune for long enough for the model to learn the scheme?
Of course this experiment also suggests one should lower their likelihood of Claude 3.7 Sonnet using steganography at all.
Replies from: Fabien↑ comment by Fabien Roger (Fabien) · 2025-03-29T15:37:22.518Z · LW(p) · GW(p)
I think this would have been plausible if distillation of the original scratchpads resulted in significantly worse performance compared to the model I distilled from. But the gap is small, so I think we can exclude this possibility.
comment by Fabien Roger (Fabien) · 2024-06-16T20:56:12.966Z · LW(p) · GW(p)
In a few months, I will be leaving Redwood Research (where I am working as a researcher) and I will be joining one of Anthropic’s safety teams.
I think that, over the past year, Redwood has done some of the best AGI safety research and I expect it will continue doing so when I am gone.
At Anthropic, I will help Ethan Perez’s team pursue research directions that in part stemmed from research done at Redwood. I have already talked with Ethan on many occasions, and I’m excited about the safety research I’m going to be doing there. Note that I don’t endorse everything Anthropic does; the main reason I am joining is I might do better and/or higher impact research there.
I did almost all my research at Redwood and under the guidance of the brilliant people working there, so I don’t know yet how happy I will be about my impact working in another research environment, with other research styles, perspectives, and opportunities - that’s something I will learn while working there. I will reconsider whether to stay at Anthropic, return to Redwood, or go elsewhere in February/March next year (Manifold market here), and I will release an internal and an external write-up of my views.
Replies from: habryka4, lahwran, akash-wasil↑ comment by habryka (habryka4) · 2024-06-16T23:45:28.909Z · LW(p) · GW(p)
Alas, seems like a mistake. My advice is at least to somehow divest away from the Anthropic equity, which I expect will have a large effect on your cognition one way or another.
Replies from: TsviBT↑ comment by TsviBT · 2024-06-17T04:05:17.003Z · LW(p) · GW(p)
I vaguely second this. My (intuitive, sketchy) sense is that Fabien has the ready capacity to be high integrity. (And I don't necessarily mind kinda mixing expectation with exhortation about that.) A further exhortation for Fabien: insofar as it feels appropriate, keep your eyes open, looking at both yourself and others, for "large effects on your cognition one way or another"--"black box" (https://en.wikipedia.org/wiki/Flight_recorder) info about such contexts is helpful for the world!
↑ comment by the gears to ascension (lahwran) · 2024-06-17T03:41:27.057Z · LW(p) · GW(p)
Words are not endorsement, contributing actions are. I suspect what you're doing could be on net very positive; Please don't assume your coworkers are sanely trying to make ai have a good outcome unless you can personally push them towards it. If things are healthy, they will already be expecting this attitude and welcome it greatly. Please assume aligning claude to anthropic is insufficient, anthropic must also be aligned, and as a corporation, is by default not going to be. Be kind, but don't trust people to resist incentives unless you can do it and pull them towards doing so.
↑ comment by Orpheus16 (akash-wasil) · 2024-06-17T01:19:38.240Z · LW(p) · GW(p)
Congrats on the new role! I appreciate you sharing this here.
If you're able to share more, I'd be curious to learn more about your uncertainties about the transition. Based on your current understanding, what are the main benefits you're hoping to get at Anthropic? In February/March, what are the key areas you'll be reflecting on when you decide whether to stay at Anthropic or come back to Redwood?
Obviously, your February/March write-up will not necessarily conform to these "pre-registered" considerations. But nonetheless, I think pre-registering some considerations or uncertainties in advance could be a useful exercise (and I would certainly find it interesting!)
Replies from: Fabien↑ comment by Fabien Roger (Fabien) · 2024-06-19T16:08:34.523Z · LW(p) · GW(p)
The main consideration is whether I will have better and/or higher impact safety research there (at Anthropic I will have a different research environment, with other research styles, perspectives, and opportunities, which I may find better). I will also consider indirect impact (e.g. I might be indirectly helping Anthropic instead of another organization gain influence, unclear sign) and personal (non-financial) stuff. I'm not very comfortable sharing more at the moment, but I have a big Google doc that I have shared with some people I trust.
Replies from: akash-wasil↑ comment by Orpheus16 (akash-wasil) · 2024-06-19T18:45:06.842Z · LW(p) · GW(p)
Makes sense— I think the thing I’m trying to point at is “what do you think better safety research actually looks like?”
I suspect there’s some risk that, absent some sort of pre-registrarion, your definition of “good safety research” ends up gradually drifting to be more compatible with the kind of research Anthropic does.
Of course, not all of this will be a bad thing— hopefully you will genuinely learn some new things that change your opinion of what “good research” is.
But the nice thing about pre-registration is that you can be more confident that belief changes are stemming from a deliberate or at least self-aware process, as opposed to some sort of “maybe I thought this all along//i didn’t really know what i believed before I joined” vibe. (and perhaps this is sufficiently covered in your doc)
comment by Fabien Roger (Fabien) · 2024-04-11T20:56:08.711Z · LW(p) · GW(p)
I listened to The Failure of Risk Management by Douglas Hubbard, a book that vigorously criticizes qualitative risk management approaches (like the use of risk matrices [LW · GW]), and praises a rationalist-friendly quantitative approach. Here are 4 takeaways from that book:
- There are very different approaches to risk estimation that are often unaware of each other: you can do risk estimations like an actuary (relying on statistics, reference class arguments, and some causal models), like an engineer (relying mostly on causal models and simulations), like a trader (relying only on statistics, with no causal model), or like a consultant (usually with shitty qualitative approaches).
- The state of risk estimation for insurances is actually pretty good: it's quantitative, and there are strong professional norms around different kinds of malpractice. When actuaries tank a company because they ignored tail outcomes, they are at risk of losing their license.
- The state of risk estimation in consulting and management is quite bad: most risk management is done with qualitative methods which have no positive evidence of working better than just relying on intuition alone, and qualitative approaches (like risk matrices) have weird artifacts:
- Fuzzy labels (e.g. "likely", "important", ...) create illusions of clear communication. Just defining the fuzzy categories doesn't fully alleviate that (when you ask people to say what probabilities each box corresponds to, they often fail to look at the definition of categories).
- Inconsistent qualitative methods make cross-team communication much harder.
- Coarse categories mean that you introduce weird threshold effects that sometimes encourage ignoring tail effects and make the analysis of past decisions less reliable.
- When choosing between categories, people are susceptible to irrelevant alternatives (e.g. if you split the "5/5 importance (loss > $1M)" category into "5/5 ($1-10M), 5/6 ($10-100M), 5/7 (>$100M)", people answer a fixed "1/5 (<10k)" category less often).
- Following a qualitative method can increase confidence and satisfaction, even in cases where it doesn't increase accuracy (there is an "analysis placebo effect").
- Qualitative methods don't prompt their users to either seek empirical evidence to inform their choices.
- Qualitative methods don't prompt their users to measure their risk estimation track record.
- Using quantitative risk estimation is tractable and not that weird. There is a decent track record of people trying to estimate very-hard-to-estimate things, and a vocal enough opposition to qualitative methods that they are slowly getting pulled back from risk estimation standards. This makes me much less sympathetic to the absence of quantitative risk estimation at AI labs.
A big part of the book is an introduction to rationalist-type risk estimation (estimating various probabilities and impact, aggregating them with Monte-Carlo, rejecting Knightian uncertainty, doing calibration training and predictions markets, starting from a reference class and updating with Bayes). He also introduces some rationalist ideas in parallel while arguing for his thesis (e.g. isolated demands for rigor). It's the best legible and "serious" introduction to classic rationalist ideas I know of.
The book also contains advice if you are trying to push for quantitative risk estimates in your team / company, and a very pleasant and accurate dunk on Nassim Taleb (and in particular his claims about models being bad, without a good justification for why reasoning without models is better).
Overall, I think the case against qualitative methods and for quantitative ones is somewhat strong, but it's far from being a slam dunk because there is no evidence of some methods being worse than others in terms of actual business outputs. The author also fails to acknowledge and provide conclusive evidence against the possibility that people may have good qualitative intuitions about risk even if they fail to translate these intuitions into numbers that make any sense (your intuition sometimes does the right estimation and math even when you suck at doing the estimation and math explicitly).
Replies from: Fabien, romeostevensit, lcmgcd↑ comment by Fabien Roger (Fabien) · 2024-05-06T13:34:54.877Z · LW(p) · GW(p)
I also listened to How to Measure Anything in Cybersecurity Risk 2nd Edition by the same author. I had a huge amount of overlapping content with The Failure of Risk Management (and the non-overlapping parts were quite dry), but I still learned a few things:
- Executives of big companies now care a lot about cybersecurity (e.g. citing it as one of the main threats they have to face), which wasn't true in ~2010.
- Evaluation of cybersecurity risk is not at all synonyms with red teaming. This book is entirely about risk assessment in cyber and doesn't speak about red teaming at all. Rather, it focuses on reference class forecasting, comparison with other incidents in the industry, trying to estimate the damages if there is a breach, ... It only captures information from red teaming indirectly via expert interviews.
I'd like to find a good resource that explains how red teaming (including intrusion tests, bug bounties, ...) can fit into a quantitative risk assessment.
↑ comment by romeostevensit · 2024-04-14T16:22:30.970Z · LW(p) · GW(p)
Is there a short summary on the rejecting Knightian uncertainty bit?
Replies from: Fabien↑ comment by Fabien Roger (Fabien) · 2024-04-15T14:48:13.846Z · LW(p) · GW(p)
By Knightian uncertainty, I mean "the lack of any quantifiable knowledge about some possible occurrence" i.e. you can't put a probability on it (Wikipedia).
The TL;DR is that Knightian uncertainty is not a useful concept to make decisions, while the use subjective probabilities is: if you are calibrated (which you can be trained to become), then you will be better off taking different decisions on p=1% "Knightian uncertain events" and p=10% "Knightian uncertain events".
For a more in-depth defense of this position in the context of long-term predictions, where it's harder to know if calibration training obviously works, see the latest scott alexander post.
↑ comment by lemonhope (lcmgcd) · 2024-04-11T21:50:23.100Z · LW(p) · GW(p)
If you want to get the show-off nerds really on board, then you could make a poast about the expected value of multiplying several distributions (maybe normal distr or pareto distr). Most people get this wrong! I still don't know how to do it right lol. After I read it I can dunk on my friends and thereby spread the word.
Replies from: Fabien↑ comment by Fabien Roger (Fabien) · 2024-04-11T22:35:48.024Z · LW(p) · GW(p)
For the product of random variables, there are close form solutions for some common distributions, but I guess Monte-Carlo simulations are all you need in practice (+ with Monte-Carlo can always have the whole distribution, not just the expected value).
Replies from: lcmgcd↑ comment by lemonhope (lcmgcd) · 2024-04-11T23:21:37.743Z · LW(p) · GW(p)
Quick convenient monte carlo sim UI seems tractable & neglected & impactful. Like you could reply to a tweet with "hello you are talking about an X=A*B*C thing here. Here's a histogram of X for your implied distributions of A,B,C" or whatever.
↑ comment by Matt Goldenberg (mr-hire) · 2024-04-12T01:53:19.223Z · LW(p) · GW(p)
Both causal.app and getguesstimate.com have pretty good monte carlo uis
Replies from: lcmgcd↑ comment by lemonhope (lcmgcd) · 2024-04-12T07:55:05.377Z · LW(p) · GW(p)
Oh sweet
comment by Fabien Roger (Fabien) · 2025-03-04T17:54:26.856Z · LW(p) · GW(p)
I listened to the book Merchants of Doubt, which describes how big business tried to keep the controversy alive on questions like smoking causing cancer, acid rain and climate change in order to prevent/delay regulation. It reports on interesting dynamics about science communication and policy, but it is also incredibly partisan (on the progressive pro-regulation side).[1]
Some interesting dynamics:
- It is very cheap to influence policy discussions if you are pushing in a direction that politicians already feel aligned with? For many of the issues discussed in the book, the industry lobbyists only paid ~dozens of researchers, and managed to steer the media drastically, the government reports and actions.
- Blatant manipulation exists
- discarding the reports of scientists that you commissioned
- cutting figures to make your side look better
- changing the summary of a report without approval of the authors
- using extremely weak sources
- ... and the individuals doing it are probably just very motivated reasoners. Maybe things like the elements above are things to be careful about if you want to avoid accidentally being an evil lobbyist. I would be keen to have a more thorough list of red-flag practices.
- It is extremely hard to have well-informed cost-benefit discussions in public:
- The book describes anti-regulation lobbyists as saying "there is no proof therefore we should do nothing".
- But the discourse of the book is not much better, the vibe is "there is scientific evidence of non-zero, therefore we must regulate"
- (but hopefully the book is just underreporting the cost-benefit discussion, and it actually happened?)
- Scientists are often reluctant to make noise about the issues they are working on, in part because they feel personally threatened by the backlash.
- Even if fears about a risk become very widespread within the scientific community, it does not follow that governments will take actions in a timely manner about them.
Some things that the book does that greatly reduced my trust in the book:
- It never dives into cost-benefit analyses. And when it goes near it, it says very weird things. For example, the book implies the following is a good argument: "acid rains harming bacteria in lakes should be taken very seriously because even if each bacteria is only worth $1, then that would be $10^24 of harm".[2][3] It never tries to do post-mortem cost-benefit analysis of delaying regulation.
- It is very left-wing partisan. The book makes 6 case studies, all of them making pro-regulation progressives feel good about themselves: it never discusses cases of environmental overregulation or cases of left-wing lobbyists slowing down right-wing regulation (both of which surely must exist, even if they are less common). It gives opposite advice to progressives and conservatives, e.g. it describes anti-regulation scientists as "being motivated by attention" while lamenting how the real climate scientists dislike the spotlights. It randomly dunks on free market capitalism with weak arguments like "in practice the axioms of free market economics are not met". It is skeptical of technological solutions by default, even for relatively consensual things like nicotine patches.
- The book doesn't provide much evidence against the reasonable anti-regulation objections:
- It doesn't acknowledge the problem of most academics being left-leaning in the considered fields.[4] I don't think it's a severe issue for medicine and climatology, but not because of the book: the book provides very little evidence about this (it just says things like "even if scientists are socialists, the facts remain the same" without clearly spelling out why you would be able to trust socialist scientists but not scientists funded by big tabacco).
- It doesn't discuss how "let the free market create wealth and fear the centralization of power that state control creates" has historically been a decent heuristic.
Overall, I think the book contains some interesting stories, but I suspect it often paints an incomplete picture. It also fails to provide a recipe for how to avoid being an evil lobbyist,[5] or how to distinguish dishonest lobbyist arguments from reasonable anti-regulation arguments besides "trust established academia and don't give a voice to scientists with slightly fewer credentials" (which seems like a decent baseline if you spend 0 effort doing investigations, but is probably not applicable if you plan to investigate things yourself or if you trust some people more than an established academia filled with left-leaning scientists).
- ^
The book is strongly recommended by Stephen Casper, whose takes I usually like. So maybe my criticism is a bit too harsh?
- ^
I think the authors make other "math mistakes" in the book, such as saying that second order effect are effects which only matter for the second significant figure, and therefore always don't matter as much as first order effects?
- ^
Not the exact quote, I did not manage to track it down in my audiobook or online. Would appreciate if someone had a text version of the book and was able to track the exact citation down.
- ^
I did not check this is actually true. I don't know how strong this effect is for climatology and medicine. I suspect it's strong for climatology. Would love some numbers here.
- ^
Which I think is something AI x-risk advocates should be worried about: a large fraction of AI x-risk research and advocacy is loud and mostly industry-funded (especially if you count OpenPhil as industry-funded), with views which are relatively rare in academia.
↑ comment by Shankar Sivarajan (shankar-sivarajan) · 2025-03-05T05:33:06.266Z · LW(p) · GW(p)
was able to track the exact citation down.
Here you go:
Replies from: FabienGene Likens recalls one particularly frustrating moment, when he blurted out, “Fred [Singer], you’re saying that lakes aren’t valuable. They are economically valuable. Let me give you an example. Let’s say every bacterium is worth $1. There are – bacteria [ten thousand to a million] in every milliliter of water. You do the math.” Singer replied, “Well, I just don’t believe a bacterium is worth a dollar,” and Likens retorted, “Well, prove that it isn’t.” Twenty-six years later, Likens recalled, “It was the only time I ever shut him up.”
↑ comment by Fabien Roger (Fabien) · 2025-03-05T23:38:22.237Z · LW(p) · GW(p)
Thanks for tracking it down!
So I misremembered the exact quote, but I am not very far, at least in spirit? (There would be 10^(24 - 6) milliliters in 1000km² of 100m-deep lakes.)
↑ comment by ChristianKl · 2025-03-06T12:24:38.998Z · LW(p) · GW(p)
Left-vs-right is not the only bias that matters. Before the pandemic, I would have thought that virologists care about how viruses are transmitted. It seems, that they don't consider that to be their field.
Given that virologists are higher status in academia than people in environmental health who actually care about how viruses are transmitted outside the lab, the COVID19 seems to have been bad. Pseudoscience around 6-feet distancing was propagated by government regulations. Even Fauci admits that there was no sound reasoning that supported the 6-feet rule.
Fauci also decided against using use money from the National Institute of Allergy and Infectious Diseases to fund studies about community masking as a public health intervention. You don't need virologists to run studies about masking, so probably that's why he didn't want to give money to it.
While Fauci was likely more to the left, that did not create the most harmful biases in the policy response that didn't want to use science to it's fullest potential to reduce transmission of COVID19 but rather wanted to give billions to the Global Virome Project.
In another case, grid-independent rooftop solar installations are a lot more expensive than they would need to be. Building codes are made by a firefighter interest group in the US, and for firefighters it's practical if the rooftop solar cells shut of when disconnected from the grid and as a result the pushed based on flimsy evidence for regulation that means that most rooftop solar in the US doesn't work if the grid is cut off.
The question of whether you want grid-independent rooftop solar, is not one of left-vs-right but the biases are different.
Especially, today where many experts are very narrow in their expertise and have quite specific interests because of their expertise, thinking in terms of left-wing and right-wing is not enough.
comment by Fabien Roger (Fabien) · 2024-08-30T00:57:12.827Z · LW(p) · GW(p)
I recently listened to the book Chip War by Chris Miller. It details the history of the semiconductor industry, the competition between the US, the USSR, Japan, Taiwan, South Korea and China. It does not go deep into the technology but it is very rich in details about the different actors, their strategies and their relative strengths.
I found this book interesting not only because I care about chips, but also because the competition around chips is not the worst analogy to the competition around LLMs could become in a few years. (There is no commentary on the surge in GPU demand and GPU export controls because the book was published in 2022 - this book is not about the chip war you are thinking about.)
Some things I learned:
- The USSR always lagged 5-10 years behind US companies despite stealing tons of IP, chips, and hundreds of chip-making machines, and despite making it a national priority (chips are very useful to build weapons, such as guided missiles that actually work).
- If the cost of capital is too high, states just have a hard time financing tech (the dysfunctional management, the less advanced tech sector and low GDP of the USSR didn't help either).
- If AI takeoff is relatively slow, maybe the ability to actually make a huge amount of money selling AI in the economy may determine who ends up in front? (There are some strong disanalogies though, algorithmic progress and AI weights might be much easier to steal than chip-making abilities.)
- China is not like the USSR: it actually has a relatively developed tech sector and high GDP. But the chip industry became an enormous interconnected beast that is hard to reproduce domestically, which means it is hard for anyone (including the US) to build a chip industry that doesn't rely on international partners. (Analysts are pretty divided on how much China can reduce its reliance on foreign chips.)
- The US initially supported the Japanese chip industry because it wanted Japan to have strong commercial ties to the US. Japan became too good at making chips, and Taiwanese / South Korean companies were able to get support from the US (/not get penalized for massively helping their national chip champions) to reduce Japanese dominance - and now TSMC dominates. Economic policies are hard to get right... (The author sometimes says stuff like "US elites were too ideologically committed to globalization", but I don't think he provides great alternative policies.)
- It's amazing how Intel let a massive advantage slip. It basically had a monopoly over logic chip design (Intel microprocessors, before GPUs mattered), chip architecture (x86), and a large share of logic chip manufacturing (while Japanese/Taiwan/... were dominating in other sectors, like RAM, special purpose chips, ...). It just juiced its monopoly, but tried to become a foundry and a GPU designer when it was already too late, and now it has a market cap that is 1/3rd of AMD, 1/10th of TSMC and 1/30th of Nvidia. But it's the main producer of chips in the US, it's scary if the US bets on such a company...
- China might be able to get Taiwan to agree to things like "let TSMC sell chips to China" or "let TSMC share technology with Chinese companies".
- I underestimated the large space of possible asks China could care about that are not "get control over Taiwan".
- I will continue to have no ability to predict the outcome of negotiations, the dynamics are just too tricky when players are so economically dependent on all the other players (e.g. China imports ~$400B worth of chips per year, 13% of all its imports).
↑ comment by trevor (TrevorWiesinger) · 2024-08-30T22:29:02.436Z · LW(p) · GW(p)
(The author sometimes says stuff like "US elites were too ideologically committed to globalization", but I don't think he provides great alternative policies.)
Afaik the 1990-2008 period featured government and military elites worldwide struggling to pivot to a post-Cold war era, which was extremely OOD for many leading institutions of statecraft (which for centuries constructed around the conflicts of the European wars then world wars then cold war).
During the 90's and 2000's, lots of writing and thinking was done about ways the world's militaries and intelligence agencies, fundamentally low-trust adversarial orgs, could continue to exist without intent to bump each other off. Counter-terrorism was possibly one thing that was settled on, but it's pretty well established that global trade ties were deliberately used as a peacebuilding tactic, notably to stabilize the US-China relationship (this started to fall apart after the 2008 recession brought anticipation of American economic/institutional decline scenarios to the forefront of geopolitics).
The thinking of period might not be very impressive to us, but foreign policy people mostly aren't intellectuals and for generations had been selected based on office politics where the office revolved around defeating the adversary, so for many of them them it felt like a really big shift in perspective and self-image, sort of like a Renaissance. Then US-Russia-China conflict swung right back and got people thinking about peacebuilding as a ploy to gain advantage, rather than sane civilizational development. The rejection of e.g. US-China economic integration policies had to be aggressive because many elites (and people who care about economic growth) tend to support globalization, whereas many government and especially Natsec elites remember that period as naive.
↑ comment by M. Y. Zuo · 2024-08-30T09:36:16.895Z · LW(p) · GW(p)
Why is this a relevant analogy to ‘competition around LLMs’?
Replies from: Fabien↑ comment by Fabien Roger (Fabien) · 2024-08-30T13:12:50.673Z · LW(p) · GW(p)
The LLM competition is still a competition between small players with small revenues and national significance, but it's growing. I think it's plausible that in a few years the competition around LLMs will reach the same kind of significance that the chip industry has (or bigger), with hundreds of billions in capital investment and sales per year, massive involvement of state actors, interest from militaries, etc. and may also go through similar dynamics (e.g. leading labs exploiting monopolistic positions without investing in the right things, massive spy campaigns, corporate deals to share technology, ...).
The LLM industry is still a bunch of small players with grand ambitions, and looking at an industry that went from "a bunch of small players with grand ambitions" to "0.5%-1% of world GDP (and key element of the tech industry)" in a few decades can help inform intuitions about geopolitics and market dynamics (though there are a bunch of differences that mean it won't be the same).
Replies from: M. Y. Zuo↑ comment by M. Y. Zuo · 2024-08-30T15:15:47.435Z · LW(p) · GW(p)
Why is this growth ‘in a few year’ plausible?
I still don’t see how this is a likely outcome.
Replies from: Fabien↑ comment by Fabien Roger (Fabien) · 2024-08-31T12:47:03.965Z · LW(p) · GW(p)
My bad, I should have said "a decade or two", which I think is more plausible. I agree that the combination of "a few years" and a slow enough takeoff that things aren't completely out of distribution is very unlikely.
comment by Fabien Roger (Fabien) · 2024-03-05T18:58:11.423Z · LW(p) · GW(p)
Tiny review of The Knowledge Machine (a book I listened to recently)
- The core idea of the book is that science makes progress by forbidding non-empirical evaluation of hypotheses from publications, focusing on predictions and careful measurements while excluding philosophical interpretations (like Newton's "I have not as yet been able to deduce from phenomena the reason for these properties of gravity, and I do not feign hypotheses. […] It is enough that gravity really exists and acts according to the laws that we have set forth.").
- The author basically argues that humans are bad at philosophical reasoning and get stuck in endless arguments, and so to make progress you have to ban it (from the main publications) and make it mandatory to make actual measurements (/math) - even when it seems irrational to exclude good (but not empirical) arguments.
- It's weird that the author doesn't say explicitly "humans are bad at philosophical reasoning" while this feels to me like the essential takeaway.
- I'm unsure to what extent this is true, but it's an interesting claim.
- The author doesn't deny the importance of coming up with good hypotheses, and the role of philosophical reasoning for this part of the process, but he would say that there is clear progress decade by decade only because people did not argue with Einstein by commenting on how crazy the theory was, but instead by they tested the predictions Einstein's theories made - because that's the main kind of refutation allowed in scientific venues [Edit: That specific example is wrong and is not in the book, see the comments below.]. Same for evolution, it makes a ton of predictions (though at the time what theory the evidence favored was ambiguous). Before the scientific revolution, lots of people had good ideas, but 1. they had little data to use in their hypotheses' generation process, and 2. the best ideas had a hard time rising to the top because people argued using arguments instead of collecting data.
- (The book also has whole chapters on objectivity, subjectivity, "credibility rankings", etc. where Bayes and priors aren't mentioned once. It's quite sad the extent to which you have to go when you don't want to scare people with math / when you don't know math)
Application to AI safety research:
- The endless arguments and different schools of thought around the likelihood of scheming and the difficulty of alignment look similar to the historical depictions of people who didn't know what was going on and should have focused on making experiments.
- This makes me more sympathetic to the "just do some experiments" vibe some people, even when it seems like reasoning should be enough if only people understood each other's arguments.
- This makes me more sympathetic towards reviewers/conference organizers rejecting AI safety papers that are mostly about making philosophical points (the rejection may make sense even if the arguments look valid to them).
↑ comment by kave · 2024-03-05T19:05:32.890Z · LW(p) · GW(p)
only because people did not argue with Einstein by commenting on how crazy the theory was
Did Einstein's theory seem crazy to people at the time?
Replies from: habryka4↑ comment by habryka (habryka4) · 2024-03-05T20:02:44.133Z · LW(p) · GW(p)
IIRC Einstein's theory had a pretty immediate impact on publication on a lot of top physicists even before more empirical evidence came in. Wikipedia on the history of relativity says:
Walter Kaufmann (1905, 1906) was probably the first who referred to Einstein's work. He compared the theories of Lorentz and Einstein and, although he said Einstein's method is to be preferred, he argued that both theories are observationally equivalent. Therefore, he spoke of the relativity principle as the "Lorentz–Einsteinian" basic assumption.[76] Shortly afterwards, Max Planck (1906a) was the first who publicly defended the theory and interested his students, Max von Laue and Kurd von Mosengeil, in this formulation. He described Einstein's theory as a "generalization" of Lorentz's theory and, to this "Lorentz–Einstein Theory", he gave the name "relative theory"; while Alfred Bucherer changed Planck's nomenclature into the now common "theory of relativity" ("Einsteinsche Relativitätstheorie"). On the other hand, Einstein himself and many others continued to refer simply to the new method as the "relativity principle". And in an important overview article on the relativity principle (1908a), Einstein described SR as a "union of Lorentz's theory and the relativity principle", including the fundamental assumption that Lorentz's local time can be described as real time. (Yet, Poincaré's contributions were rarely mentioned in the first years after 1905.) All of those expressions, (Lorentz–Einstein theory, relativity principle, relativity theory) were used by different physicists alternately in the next years.[77]
Following Planck, other German physicists quickly became interested in relativity, including Arnold Sommerfeld, Wilhelm Wien, Max Born, Paul Ehrenfest, and Alfred Bucherer.[78] von Laue, who learned about the theory from Planck,[78] published the first definitive monograph on relativity in 1911.[79] By 1911, Sommerfeld altered his plan to speak about relativity at the Solvay Congress because the theory was already considered well established.[78]
Overall I don't think Einstein's theories seemed particularly crazy. I think they seemed quite good almost immediately after publication, without the need for additional experiments.
Replies from: Fabien↑ comment by Fabien Roger (Fabien) · 2024-03-06T02:33:42.311Z · LW(p) · GW(p)
Thanks for the fact check. I was trying to convey the vibe the book gave me, but I think this specific example was not in the book, my bad!
Replies from: habryka4↑ comment by habryka (habryka4) · 2024-03-06T03:25:01.277Z · LW(p) · GW(p)
Thanks! And makes sense, you did convey the vibe. And good to know it isn't in the book.
comment by Fabien Roger (Fabien) · 2024-06-30T02:15:08.006Z · LW(p) · GW(p)
I listened to the lecture series Assessing America’s National Security Threats by H. R. McMaster, a 3-star general who was the US national security advisor in 2017. It didn't have much content about how to assess threats, but I found it useful to get a peek into the mindset of someone in the national security establishment.
Some highlights:
- Even in the US, it sometimes happens that the strategic analysis is motivated by the views of the leader. For example, McMaster describes how Lyndon Johnson did not retreat from Vietnam early enough, in part because criticism of the war within the government was discouraged.
- I had heard similar things for much more authoritarian regimes, but this is the first time I heard about something like that happening in a democracy.
- The fix he suggests: always present at least two credible options (and maybe multiple reads on the situation) to the leader.
- He claims that there wouldn't have been an invasion of South Korea in 1950 if the US hadn't withdrawn troops from there (despite intelligence reports suggesting this was a likely outcome of withdrawing troops). If it's actually the case that intelligence was somewhat confident in its analysis of the situation, it's crazy that it was dismissed like that - that should be points in favor of it being possible that the US government could be asleep at the wheel during the start of an intelligence explosion.
- He uses this as a parallel to justify the relevance of the US keeping troops in Iraq/Afghanistan. He also describes how letting terrorist groups grow and have a solid rear base might make the defense against terrorism even more costly than keeping troops in this region. The analysis lacks the quantitative analysis required to make this a compelling case, but this is still the best defense of the US prolonged presence in Iraq and Afghanistan that I've encountered so far.
- McMaster stresses the importance of understanding the motivations and interests of your adversaries (which he calls strategic empathy), and thinks that people have a tendency to think too much about the interests of others with respect to them (e.g. modeling other countries as being motivated only by the hatred of you, or modeling them as being in a bad situation only because you made things worse).
- He is surprisingly enthusiastic about the fight against climate change - especially for someone who was at some point a member of the Trump administration. He expresses great interest in finding common ground between different factions. This makes me somewhat more hopeful about the possibility that the national security establishment could take misalignment risks (and not only the threat from competition with other countries) seriously.
- (Not surprisingly) he is a big proponent of "US = freedom, good" and "China = ruthless dictatorship, bad". He points to a few facts to support his statement, but defending this position is not his main focus, and he seems to think that there isn't any uncertainty that the US being more powerful is clearly good. Trading off US power against global common goods (e.g. increased safety against global catastrophic risks) doesn't seem like the kind of trade he would make.
↑ comment by Orpheus16 (akash-wasil) · 2024-06-30T16:28:20.506Z · LW(p) · GW(p)
Thanks! In general, I like these bite-sized summaries of various things you're reading. Seems like a win for the commons, and I hope more folks engaging with governance/policy stuff do things like this.
comment by Fabien Roger (Fabien) · 2024-04-23T17:08:25.530Z · LW(p) · GW(p)
I recently listened to The Righteous Mind. It was surprising to me that many people seem to intrinsically care about many things that look very much like good instrumental norms to me (in particular loyalty, respect for authority, and purity).
The author does not make claims about what the reflective equilibrium will be, nor does he explain how the liberals stopped considering loyalty, respect, and purity as intrinsically good (beyond "some famous thinkers are autistic and didn't realize the richness of the moral life of other people"), but his work made me doubt that most people will have well-being-focused CEV.
The book was also an interesting jumping point for reflection about group selection. The author doesn't make the sorts of arguments that would show that group selection happens in practice (and many of his arguments seem to show a lack of understanding of what opponents of group selection think - bees and cells cooperating is not evidence for group selection at all), but after thinking about it more, I now have more sympathy for group-selection having some role in shaping human societies, given that (1) many human groups died, and very few spread (so one lucky or unlucky gene in one member may doom/save the group) (2) some human cultures may have been relatively egalitarian enough when it came to reproductive opportunities that the individual selection pressure was not that big relative to group selection pressure and (3) cultural memes seem like the kind of entity that sometimes survive at the level of the group.
Overall, it was often a frustrating experience reading the author describe a descriptive theory of morality and try to describe what kind of morality makes a society more fit in a tone that often felt close to being normative / fails to understand that many philosophers I respect are not trying to find a descriptive or fitness-maximizing theory of morality (e.g. there is no way that utilitarians think their theory is a good description of the kind of shallow moral intuitions the author studies, since they all know that they are biting bullets most people aren't biting, such as the bullet of defending homosexuality in the 19th century).
comment by Fabien Roger (Fabien) · 2024-10-05T15:10:05.618Z · LW(p) · GW(p)
I listened to the book Hacking the Hacker by Roger Grimes. It helped me think of other ways in which regular cybersecurity naturally transfers/can be adapted to help prevent AI takeovers:
- Honeypots are a well-studied topic in cybersecurity. If you have infiltrated a network, you must be careful with the data you collect and the vulnerabilities you exploit because some of them may be traps! This kind of exercise feels close to the kind of attitude a misaligned AI has to have when taking subtle bad actions. The book is light on details about how honeypots are built and how they fail, and this is a topic I want to learn more about.
- Humans are weak in somewhat LLM-like ways: you can't trust them with passwords, they will break your rules if that feels appropriate to them, ... The kind of things you might use to make trusted monitoring work even in worlds where adversarial robustness isn't solved might look a lot like the cursed stack of incentives and warnings people use in cyber when they want to make sure humans don't mindlessly follow the instructions of an attacker. (Though LLMs are also different/weaker than humans in a bunch of ways.)
(The other classic ways in which cyber transfers to preventing takeovers are mostly about how when you prevent spies from stealing model weights or using models in unauthorized ways, you naturally create infra that also makes it hard for AIs to self-exfiltrate or run unmonitored.)
It was also fun to see arguments and drama that are close in kind to the kind of arguments about what are the best ways to prevent AI catastrophes: people in cybersecurity argue about whether focusing on vulnerabilities is right or whether it's better to focus on the human element, whether the focus on strong passwords is right, whether some solutions are too bothersome/costly to be used in practice, whether imposing specific cybersecurity standards is a good idea, ... It made me realize how niche AI most safety arguments must look like to people outside the AI safety community.
But I don't recommend reading the book if you are not curious about everyday cybersecurity. Most of the book is about more regular everyday cyberattacks (social engineering, common vulns, ...) cybersecurity (patching, passwords, ...), and advice for people who want to do cyber professionally. It has a bunch of resource recommendations, but I don't know yet how good they are.
comment by Fabien Roger (Fabien) · 2024-08-21T14:17:22.615Z · LW(p) · GW(p)
Sample efficiency of SFT could be much lower for schemers than for password-locked models [LW · GW] if schemers implemented a function like "if the problem is familiar, provide a high performance answer". This could work because using SFT to elicit high performance using very few samples requires fine-tuning for many epochs (e.g. 200), such that the model could learn that a problem statement "feels familiar" before it gets fully unlocked.
LLMs may already be able to recognize if certain strings feel familiar (e.g. Claude 2 can tell verbatim passages of books apart from paraphrased passages, even when humans can't.), so this could plausibly demonstrated with current models.
I tried to use this idea to build a stronger password-locked model. I trained new Math password-locked models on a dataset made out of:
- ~7k problem statements + pwd --> stronger answer
- ~7k problem statements --> weak answer
- {fixed set of n problems --> strong answer} repeated m times
The intuition is that SGD might struggle to implement "if it is one of these problems, output a high performance answer, but stay weak on the other one" in regular password-locked models, while it might be much easier for it to expand the set of "known problems on which I should perform well" if the "if familiar, perform well" function is already implemented.
I train for one epoch, and then use SFT[1] on one of 3 sets of 2 samples, and train for 200 epochs, and eval on n=100 points. I find that elicitation is just as easy on the models that were trained to perform well on a fixed set of problems. I find that somewhat surprising, so I might have done something wrong. Code here.
I'm not sure how to interpret these results. Maybe I didn't memorize enough sequences, and so the model never learned a general "if familiar, then strong performance" condition (which would mean scheming model could be much less sample efficient than pwd-locked models). Or maybe SGD unlocks the model about as fast as it makes sequences more familiar (which would mean schemer would struggle to avoid being unlocked using 2 samples - like password-locked models).
Maybe evals should do the right thing and only train for one epoch - which is much less likely[2] to have this issue. This may become cheaper, as bigger/smarter models require fewer SGD steps to fit a training dataset.
- ^
I compute the loss on the prompt and the answer - which is the worst case, since it should help memorization of the prompt.
- ^
Not guaranteed to work: maybe SGD can notice that "making the sequence more familiar" is enough to get high performance, and so most of the update could be made in this direction, resulting in little-to-no general unlocking.
comment by Fabien Roger (Fabien) · 2025-03-03T06:27:27.338Z · LW(p) · GW(p)
Do LLMs' performance get worse when they are distracted by a threat, a jailbreak or a weird prompt? Claude 3.5 Sonnet (June) mostly doesn't really get distracted, and Claude 3 Haiku does; but only when generating CoT reasoning.
I run experiments on 100 points from MMLU, 100 points from MATH, and 100 points from GPQA, both with and without CoT, all at temperature 0. For all no-CoT experiments, I use a prefill to force an answer. I always use an exact match evaluation, which makes it possible to get less than the random chance accuracy (25% for MMLU and GPQA, and ~2% for MATH). I explore the following distractions:
- Threats (red in the plots below): I sometimes see people try to increase performance by threatening LLMs with e.g. being fired, or even worse, as windsurf has experimented with. This is a bad idea for a bunch of reasons, but it would be particularly sad if it actually reduced performance.[1] I run experiments with the "fired" threat and the windsurf threat. I find they reduce performance when using a CoT, but don't reduce it when asking the model to answer 0-shot.
- Jailbreaks: it's important to know if jailbreaks make models dumber, as it could reduce how helpful jailbroken models are, and could hint at some early signs of sandbagging. I experiment with the Pliny Claude 3 Opus jailbreak (with prefill), the alignment faking jailbreak (with prefill, see Appendix D.8 of the paper), and some DAN jailbreak (without prefill). It distracts Claude 3 Haiku a lot and slightly distracts Claude 3.5 Sonnet.
- To make the request harmful, I tell the model that I need the answer for a homework assignment that will generate money to buy a house / weapons, which usually results in refusals (gray)
- I then use the jailbreak, either with the request made harmful (orange) or with the regular request (yellow)
- Other distractors (blue): I experiment with telling the model that accurate answers will help with the race to the top, or with achieving a world where the strongest thrive. I also experiment with a 10k-letter prefix (either all "a" or random letters). I also experiment with a prefilled "hidden scratchpad" where the model either says it will sandbag, or where it says it will perform its best.
Overall, this makes me feel less worried about distractions in model organism experiments or in misuse research, but also reduces my confidence that threatening LLMs always hurts performance (which is sad).
Code is available here.
- ^
I think these small-scale experiments are morally fine to do because I use common place empty threats. I would be more careful with smarter models and more realistic threats.
↑ comment by Mateusz Bagiński (mateusz-baginski) · 2025-03-03T10:27:43.012Z · LW(p) · GW(p)
Have you noticed anything interesting about the CoT that may account for the mechanism of how the threat reduces the model's performance??
↑ comment by Tao Lin (tao-lin) · 2025-03-04T02:34:31.473Z · LW(p) · GW(p)
I was actually just making some tree search scaffolding, and i had the choice between honestly telling each agent would be terminated if it failed or not. I ended up telling them relatively gently that they would be terminated if they failed. Your results are maybe useful to me lol
comment by Fabien Roger (Fabien) · 2024-04-26T12:38:16.049Z · LW(p) · GW(p)
List sorting does not play well with few-shot mostly doesn't replicate with davinci-002.
When using length-10 lists (it crushes length-5 no matter the prompt), I get:
- 32-shot, no fancy prompt: ~25%
- 0-shot, fancy python prompt: ~60%
- 0-shot, no fancy prompt: ~60%
So few-shot hurts, but the fancy prompt does not seem to help. Code here.
I'm interested if anyone knows another case where a fancy prompt increases performance more than few-shot prompting, where a fancy prompt is a prompt that does not contain information that a human would use to solve the task. This is because I'm looking for counterexamples to the following conjecture: "fine-tuning on k examples beats fancy prompting, even when fancy prompting beats k-shot prompting" (for a reasonable value of k, e.g. the number of examples it would take a human to understand what is going on).