What if we approach AI safety like a technical engineering safety problem
post by zeshen · 2022-08-20T10:29:38.691Z · LW · GW · 4 commentsContents
Introduction Technical safety in a nutshell Useful tools in technical safety HazID Risk Matrix Bow-tie analysis Swiss cheese model Change Management Hierarchy of Controls Are they useful for AI safety? None 5 comments
This post has been written for the second Refine [AF · GW] blog post day, at the end of the first week of iterating on ideas and concretely aiming at the alignment problem. Thanks to Adam Shimi, Paul Bricman, and Daniel Clothiaux for helpful discussion and comments.
Introduction
This post aims to provide a general introduction to technical safety used in engineering related industries, describe some commonly used tools, and attempt to draw parallels between technical safety and AI safety. I am uncertain about the value of thinking in this framework towards building safe AI, but I expect this post to at least be useful as a productive mistake [AF · GW].
To prevent confusion:
- I use the term ‘technical safety’ to refer loosely to dealing with safety issues in engineering domains (I am only slightly familiar with technical safety in the upstream oil and gas sector).
- I use the term ‘AI safety’ to mean ensuring AI deployment does not lead to catastrophic consequences, similar to Steve Byrnes’ definition [AF · GW].
For the purpose of this post, I will assume a slow takeoff scenario where AI capabilities scales relatively slowly while never being fully aligned. At some point, a relatively powerful AI is created - powerful enough to do a lot of things but not powerful enough to instantly wipe us all out. Perhaps it has goals that do not generalize well, and starts optimizing for goals that are misaligned to our true goals. This leads to bad outcomes, perhaps events that unfortunately cause some fatalities. There continues to be a series of tragic accidents that increase in severity as the AIs get more and more capable over time, but we still have time to learn from these incidents and make safety improvements towards future systems.
The concepts in this post may not be directly applicable to an AI FOOM scenario, where the first AGI recursively improves itself and suddenly becomes extremely powerful and wipes out humanity, leaving us no opportunity to course-correct.
Technical safety in a nutshell
The principle of technical safety is built upon Heinrich’s Law, which states “in a workplace, for every accident that causes a major injury, there are 29 accidents that cause minor injuries and 300 accidents that cause no injuries.” The numbers are unimportant, but the idea is that minimizing the near-misses (accidents that cause no injuries) leads to a reduction in minor accidents, and subsequently a reduction in major accidents. This can be illustrated with the safety pyramid, also known as the safety triangle, below.

The bottom-most layer of the pyramid may be better represented by ‘hazards’ instead of ‘unsafe acts’ to also include potential dangers from non-behavioral causes. The top-most layer of the pyramid may also be better represented by ‘severe accidents’ instead of ‘death’ to also include extremely undesirable consequences other than loss of lives.
Hazard - A hazard is any agent (object, situation, or behavior - not in an ‘agentic’ sense) that has the potential to cause harm (injury, ill health, or damage to property or the environment), e.g. loose cables running on the floor that may lead to someone tripping over them is a trip hazard.
Risk - A risk describes the likelihood of potential harms from a known and identified source of hazard, e.g. there is a high risk of dangerous gas release from a corroded gas pipe.
Technical safety can roughly be summed up as effective risk management, which is about minimizing hazards by identifying and eliminating them, as well as reducing the probability that any hazards lead to undesirable consequences. While the complete elimination of every potential accident cannot be guaranteed, meaningful efforts can be expended to reduce dangerous risks to a reasonably low level.
Useful tools in technical safety
To the best of my knowledge there is no one-size-fit-all technical safety framework used in all areas of engineering, but there exists a variety of tools that serve different purposes. As each tool may have its own weakness, other tools may be used to complement them.
HazID
A hazard identification (HazID) study is a procedure used to uncover and identify hazards, as well as ensure appropriate mitigations are in place. HazIDs are commonly conducted prior to the execution of activities, from minor modification to a system (e.g. replacing old pipes) to the construction of a large facility (e.g. building a large plant).
Mitigation - A mitigation (also known as recovery measure) describes any type of action that is used to reduce the severity of a negative consequence of some kind, e.g. a fire extinguisher that reduces the impact of a fire.
HazIDs typically involve the following steps.
- Identification of hazards according to categories, with the aid of guide words (e.g. severe weather, terrorist activity)
- Identification of all possible causes and threats of the hazards
- Determination of all potential credible undesirable consequences
- Ranking of the hazards according to the Risk Matrix [LW · GW]
- Identification of mitigations in place
- Recommendation of new mitigations to further reduce risks
- Nominate action parties to each action
Risk Matrix
A Risk Matrix (also known as a Risk Assessment Matrix) is a method for evaluating both the probability and severity of a risk. The likelihood (probability of occurrence) and severity of a risk are orthogonal to each other. Different Risk Matrices employ different levels of likelihood and severity. An example of a 3x4 Risk Matrix is shown below.

Risks identified are ranked according to the Risk Matrix, such that more focus can be given to mitigate against higher risks (higher likelihood and severity) compared to lower risks (lower likelihood and severity).
Bow-tie analysis
A bow-tie diagram is a diagram used to visualize risk management and preparedness. An example is shown below.
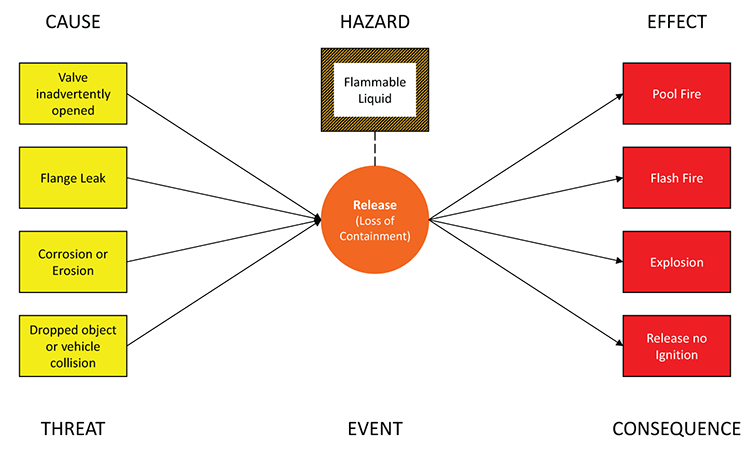
The center of the bow-tie diagram is the event (also known as top event), which is an occurrence that happens when a hazard is released. The left of the bow-tie lists the threats i.e. the possible causes of the hazard being released, while the right of the bow-tie lists the consequences i.e. the possible effects of the hazard being released. Preventive measures can be put in place to the left of the bow-tie to minimize the likelihood that the threats lead to the event, while mitigations can be put in place to the right of the bow-tie to minimize the severity of the consequences (both preventive measures and mitigations are also known as ‘barriers’).
Swiss cheese model
The Swiss cheese model of accident causation is a model that illustrates that, although many barriers lie between hazards and accidents, there are flaws in each layer that, if aligned, can allow an accident to occur. An example of the model in the context of pandemic defense is shown below.

On the bright side, this model illustrates that with every additional barrier comes additional protection, and with sufficient numbers of highly effective barriers (layers with very few and small holes) the probability of a catastrophe can be reduced to very close to zero.
Change Management
Change Management (also known as Management of Change (MoC) or Change Request Management Process) is a the process of requesting, determining attainability, planning, implementing, and evaluating of changes to an existing system. The purpose is to ensure that as many possible viewpoints are used to minimize the chances of missing a hazard through a thorough review performed by a multidisciplinary team, as any change to a complex system may introduce new hazards that are not immediately obvious.
For example, an additional equipment to a facility may lead to a change in the operating conditions of the plant, add additional weight, or be in a way of an evacuation route. The Change Management process either aims to ensure that the new operating conditions are within the design limits of the facility, stay within the weight constraints, and do not disrupt the evacuation routes; or ensures that additional changes to the system are made to safely accommodate the changes caused by the introduction of the additional equipment. The changes are reviewed, documented, and communicated to all relevant parties.
Hierarchy of Controls
The Hierarchy of Controls (also known as the Hierarchy of Hazard Controls) is a simple ranking for the methods used to control hazards - from the most effective to those that are measures of last resort, as shown below.

The five hierarchies can be roughly described as follows:
- Elimination: Wherever possible, eliminate the hazard such that it no longer exists
- Substitution: If elimination is not feasible, replace a risker hazard with a less risky one, e.g. purchasing chemicals in pellet form rather than in powder form to prevent exposure through inhalation.
- Engineering controls: If all of the above are insufficient, implement engineering controls that involve changes to the design of an equipment or process, e.g. using air ventilation to reduce airborne hazards.
- Administrative controls: If all of the above are insufficient, implement administrative measures to reduce risks, e.g. implementing regular maintenance programs to minimize risks associated with worn out equipment.
- Personal protective equipment (PPE): This is the last line of defense against adverse events, and only serves to prevent or minimize human injury in the event of an incident.
Are they useful for AI safety?
The tools described above are used for concrete bounded engineering problems and may not be directly useful for unbounded [AF · GW] problems like AI safety, and its relevance may be limited to fairly predictable tool AIs instead of powerful agentic AIs. It may potentially even hinder us from actually thinking about the (widely contested) hard part of the problem. Nevertheless, I’ll attempt to explore aspects where these approaches may help - even if applying them to AI safety may seem forced.
HazID has a workflow similar to training stories [AF · GW], where one describes the ‘training goal’ (a mechanistic description of the algorithms used in the development of the model) and the ‘training rationale’ (how the techniques employed will produce the desired goal). It aims to address several questions. How is this model built? What do we know and not know about the model? What will it have access to the real world, and what are its capabilities and limitations? What are the possible failure modes, how serious would they be, and how likely are they?
The bow-tie diagram raises questions on the undesirable consequences from hazards in a model. When an ML model starts behaving dangerously upon deployment, is there an off-switch button? What is the probability that it will work? Are there any merits to AI boxing?
The Swiss cheese model, used as the cover image for Dan Hendrycks’ post [? · GW] on Pragmatic AI Safety, helps to visualize preventive measures that can be used to prevent catastrophes. While it is recognized that all current proposals for AI safety are not fool-proof against a potential AI catastrophe, each proposal may serve as an additional imperfect barrier between the dangers of AI and the catastrophe. These barriers could be anything ranigng from interpretability [? · GW] tools to peer into the inner workings of the model, to the use of quantilizers [? · GW] to prevent hard optimization that exerbates Goodharting, to even training language models to not say things that involves describing someone getting injured [LW · GW].
Assuming an existing ML model is mostly safe, the Change Management workflow could help raise questions about how changes to the model could cause it to behave in unexpected ways. Will the model be trained on more parameters, and what does that do to its behavior? Is there a possibility of inverse scaling [LW · GW]? Is additional data used to train the model? If so, do they contain hazards that were not previously present?
AI safety is difficult because capabilities are often a tradeoff with safety. Hierarchy of Controls illustrates that while we would eliminate all hazards in an ideal world, this may sometimes not be feasible. It may be because there is no known solution to eliminate them, or drastic measures incur a high cost of alignment tax, in which case one may resort to less ideal alternatives. For example, if we cannot eliminate dishonesty from a model, are there techniques we can employ to elicit its latent knowledge [? · GW] instead?
While thinking about AI safety in a technical safety mindset may raise more questions than provide answers, with the questions raised being mostly just common-sense questions, it may be worth devising a tool or a workflow that reliably addresses these safety concerns. Good tools help create processes that are safe, and safe processes help safeguard systems against human negligence.
4 comments
Comments sorted by top scores.
comment by Nathan Helm-Burger (nathan-helm-burger) · 2022-08-20T15:07:09.550Z · LW(p) · GW(p)
I keep trying to explain to people that my threat model where improbably-but-possible discontinously-effective algorithmic progress in AI allowing for >1.0 self-improvement cycles at current levels of compute is a big deal. Most people who take a disagreement stance to this argue that it seems quite unlikely that this happens soon. I feel like it's a helpful concept to be able to show them the Risk Assessment Matrix and point to the square corresponding to 'improbable / intolerable' and say, 'See? improbable doesn't mean safe!'.
I like to call accelerating change period where AI helps accelerate further AI but only via working with humans at a less-than-human-contribution level the 'zoom' in contrast to the super-exponential artificial-intelligence-independently-improving-itself 'foom'. Thus, the period we are currently is the 'zoom' period, and the oh-shit-we're-screwed-if-we-don't-have-AI-alignment period is the foom period. When I talk about the future critical juncture wherein we realize could initiate a foom at then-present technology, but we restrain ourselves because we know we haven't yet nailed AI alignment, the 'zoom-foom gap'. This gap could be as little as seconds while a usually-overconfident capabilities engineer pauses just for a moment with their finger over the enter key, or it could be as long as a couple of years while the new model repeatedly fails the safety evaluations in its secure box despite repeated attempts to align it and thus wisely doesn't get released. 'Extending the zoom-foom gap' is thus a key point of my argument for why we should build a model-architecture-agnostic secure evaluation box and then make it standard practice for all AI research groups to run this safety eval on their new models before deployment.
(note: this is more about buying ourselves time to do alignment research than directly solving the problem. Having more time during the critical period where we have a potential AGI to study but it isn't yet loose on the world causing havok seems like a big win for alignment research. )
comment by chrizbo · 2022-08-30T16:47:25.865Z · LW(p) · GW(p)
Really enjoyed using these safety and risk visualizations in this context!
It was serendipitous when a safety blogger I follow posted this:
https://safetyrisk.net/the-risk-matrix-myth/
I'd recommend reading and watching a lot of his videos in reference to this.
The balance of new capability (aka innovation) vs. safety (reducing known risks) is an important dynamic in any team that builds. I haven't found a way to build perfect safety without severely limiting all new capabilities. The second best way is to have good ability to react when you find problems.
comment by Flaglandbase · 2022-08-21T06:01:45.406Z · LW(p) · GW(p)
These models are very good for estimating external risks but there are also internal risks if it's possible to somehow provide enough processing power to make a super powerful AI, like it could torture internal simulations in order to understand emotions.