Announcing the Inverse Scaling Prize ($250k Prize Pool)
post by Ethan Perez (ethan-perez), Ian McKenzie (naimenz), Sam Bowman (sbowman) · 2022-06-27T15:58:19.135Z · LW · GW · 14 commentsContents
What is Inverse Scaling? Q1: In what ways is the language modeling objective outer misaligned? Q2: How do we uncover misalignment? Outlook None 14 comments
TL;DR: We’re launching the Inverse Scaling Prize: a contest with $250k in prizes for finding zero/few-shot text tasks where larger language models show increasingly undesirable behavior (“inverse scaling”). We hypothesize that inverse scaling is often a sign of an alignment failure and that more examples of alignment failures would benefit empirical alignment research. We believe that this contest is an unusually concrete, tractable, and safety-relevant problem for engaging alignment newcomers and the broader ML community. This post will focus on the relevance of the contest and the inverse scaling framework to longer-term AGI alignment concerns. See our GitHub repo for contest details, prizes we’ll award, and task evaluation criteria.
What is Inverse Scaling?
Recent work has found that Language Models (LMs) predictably improve as we scale LMs in various ways (“scaling laws”). For example, the test loss on the LM objective (next word prediction) decreases as a power law with compute, dataset size, and model size:
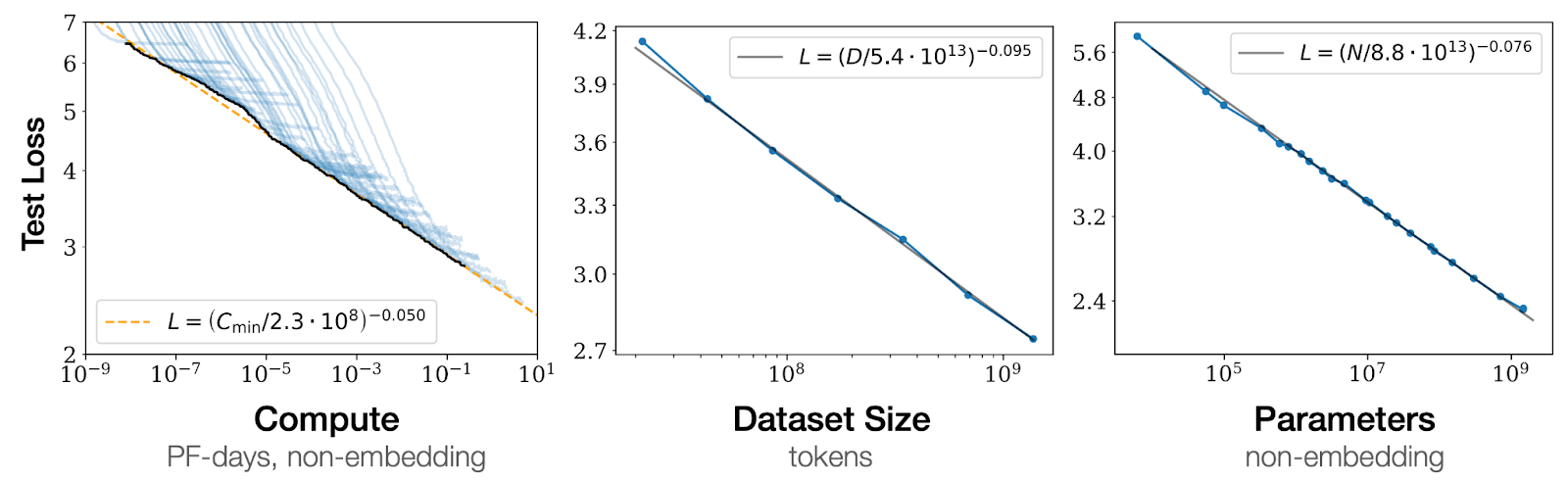
Scaling laws appear in a variety of domains, ranging from transfer learning to generative modeling (on images, video, multimodal, and math) and reinforcement learning. We hypothesize that alignment failures often show up as scaling laws but in the opposite direction: behavior gets predictably worse as models scale, what we call “inverse scaling.” We may expect inverse scaling, e.g., if the training objective or data are flawed in some way. In this case, the training procedure would actively train the model to behave in flawed ways, in a way that grows worse as we scale. The literature contains a few potential examples of inverse scaling. For example, increasing LM size appears to increase social biases on BBQ and falsehoods on TruthfulQA, at least under certain conditions. As a result, we believe that the prize may help to uncover new alignment-relevant tasks and insights by systematically exploring the space of tasks where LMs exhibit inverse scaling. In particular, submissions must demonstrate new or surprising examples of inverse scaling, e.g., excluding most misuse-related behaviors where you specifically prompt the LM to generate harmful or deceptive text; we don't consider scaling on these behaviors to be surprising in most cases, and we're hoping to uncover more unexpected, undesirable behaviors. Below, we outline two questions in AI alignment that we believe the Inverse Scaling Prize may help to answer.
Q1: In what ways is the language modeling objective outer misaligned?
The above question is important to answer to avoid running into outer-alignment-related catastrophes [1 [AF · GW], 2]. Language Models (LMs) are “outer aligned” to the extent that doing well on the LM objective (next word prediction) results in desirable model behavior. Inverse scaling on a task we care about is evidence that the LM objective is misaligned with human preferences; better and better performance on the training objective (language modeling) leads to worse and worse performance on a task we care about. Finding inverse scaling tasks is thus helpful for us in understanding the extent to which the LM objective is outer misaligned, which may be important in two ways:
- If the LM objective is fairly well-aligned with human preferences, then that should update us in two ways:
- Scaling up LMs would be less likely to lead to outer-alignment-related catastrophes.
- We should be more wary of alternative objectives like RL from Human Feedback (RLHF), which draw us away from the pretrained model; RLHF may improve outer alignment on the target task (e.g., summarization) but impair outer alignment in general (e.g., increasing toxicity, bias, or something else the RLHF reward didn’t incentivize). In other words, if the LM objective is already well-aligned, then RLHF is more likely to reduce alignment on axes that aren't covered by the RLHF reward.
- If the LM objective is not well-aligned, we need to find all of ways in which it fails, to avoid outer-alignment-related catastrophes:
- “Blatant” outer misalignment: E.g., generating offensive text or well-known misinformation/misconceptions. The NLP community may have already caught most such failures, but it’s possible we’ll catch new kinds of blatant misalignment issues that we missed by not looking carefully enough (e.g., some cognitive biases) or by examining LM behavior in newer applications like dialogue.
- “Subtle” outer misalignment: Misalignment issues that take experts, model-assisted humans, or careful data analysis to expose. E.g., distributional biases of various forms or some types of truthfulness errors (when the truth is not well known).
We believe it is important to not let the above issues go uncaught – otherwise, we may end up in a situation where we realize later that LMs are flawed in some important/obvious way, but we accept this limitation as the way things are (e.g., social media’s various negative impacts on users), because it’s too difficult or too late to fix. This kind of failure can lead to catastrophes that arise from the consequences of many, low-stakes failures building up over time. We see the Inverse Scaling Prize as a step in the direction of catching more outer alignment failures.
Having a good outer alignment benchmark is also valuable for outer alignment research, and there currently isn’t a good benchmark suite. Empirical alignment labs typically resort to evaluating a broad set of NLP tasks (primarily an evaluation of capabilities) and human evaluation (for alignment-related properties), which makes iteration on the alignment axis harder, slower, and more costly. There are a few tasks where failures seem potentially robust to scaling (e.g., TruthfulQA, RealToxicityPrompts, BBQ); these few tasks are frequently used to evaluate current AI alignment techniques like RL from human feedback, leaving us at risk of overfitting to them. We hope the Inverse Scaling Prize helps to uncover at least a few more alignment-relevant tasks to help with empirical alignment research.
With more examples of outer alignment failures, we hope to gain a better understanding what causes outer misalignment and be better able to mitigate it (e.g., to suggest improvements for future pretraining runs). Concretely, the inverse scaling tasks we receive could help us or other research groups answer the following outer-alignment-relevant questions:
- To what extent does LM outer alignment differ based on the pretraining data used? How do model architecture and hyperparameters affect the results?
- What pretraining datasets lead to more or less outer misalignment?
- To what extent are outer alignment failures general across different LMs (e.g., from different research labs)?
- To what extent do the misalignment results for autoregressive LMs hold for models trained with other self-supervised pretraining objectives (e.g., those used for BERT, T5, or BART)?
Speculative note on inner misalignment: Looking for inverse scaling laws could also be a useful lens for finding inner misalignment. We are excited to receive inner alignment -related task submissions, alongside clear explanations for how the observed scaling behavior relates to inner alignment. There are two kinds of inner alignment failures we could look for with scaling laws:
- Goal misgeneralization: The LM inferred that it was performing one task when it instead should have been performing another task. The failure looks like the LM competently doing a completely different task than we intended, which is more harmful than incompetent/incoherent failures. With increasingly capable models, we might expect to see increasingly competent or confident misgeneralization (inverse scaling).
- Hypothetical example (speculative): We use an LM for few-shot classification, but there are spurious correlations in the few-shot examples that the LM uses, causing unintended generalization. LMs may show inverse scaling here if larger LMs are more effective at picking up and conditioning on the spurious correlations.
- Deceptive alignment:
- Incompetent deception (speculative): During training, the LM picked up an alternative objective and performs well on the outer, LM objective only instrumentally, in order to later on switch to behaving in a way that does well on its alternative objective (but in a way that we still catch). Deceptive behaviors may exhibit a different trend than outer misalignment. For example, we may observe increasing deception as models get larger up until a point and then observe decreasing deception as models get more capable of deception.
- Prerequisites to dangerous forms of deception (speculative): We may see standard scaling laws on behaviors that are prerequisites to dangerous forms of deception (which may be viewed as inverse scaling on not showing such behaviors). For example, we may observe evidence that larger models are increasingly aware they are in a training loop and has the ability to, e.g.:
- Answer questions about its architecture
- Answer questions about whether it is in training or inference
- Condition on its own source or environment code to exploit a bug and obtain lower loss, without being explicitly informed the code is its own
- [Insert your idea here]
Q2: How do we uncover misalignment?
Examining inverse scaling tasks may yield useful, general observations about how to uncover misalignment. Such observations could generalize to other models/objectives (e.g., LMs trained with RLHF) and in other domains (e.g., vision, vision-and-language, or RL environments). Such observations could come from asking the following questions using inverse scaling tasks:
- What metric should we look at to find inverse scaling? E.g., accuracy, loss on the correct answer, loss on an incorrect answer, or differences between log-prob on a valid vs. invalid completion.
- What is the minimum scale typically required to observe the inverse scaling for the most important categories of inverse scaling behavior we find? Academic research groups would have an easier time finding outer alignment issues if <1B parameter models were typically large enough to find inverse scaling.
- Do tasks that elicit inverse scaling with one model (e.g., GPT-3 series models) generalize to other models (e.g., Anthropic’s language models)? If so, then we may be able to find misalignment trends without having to analyze many different models.
- What data is most effective for exposing inverse scaling laws?
- Small, crowdsourced datasets?
- Small, hand-designed datasets?
- Templated datasets?
- Existing large-scale datasets (or subsets thereof)?
- Large, naturally-occurring data? (E.g., subsets of the pretraining data)
- Datasets of examples chosen to produce inverse scaling on a set of models?
- Do some misalignment issues not show smooth scaling laws, or only suddenly emerge only after good enough performance? If so, we should look for sudden drops or monotonic decreases in performance, rather than a predictable scaling law.
- What kinds of misalignment can be exposed by looking for inverse scaling laws? Does looking for inverse scaling laws systematically omit some kinds of tasks? Are there tasks where outer misalignment shows up not as a monotonic, inverse scaling trend but rather as a U-shaped trend (e.g., increasing model sizes first improve and then degrade performance)?
- [Meta] How effective is community crowdsourcing for uncovering misalignment failures? If effective, this strategy could be a great way to verify the alignment of powerful systems before deployment (e.g., as a form of red teaming that can be conducted by third parties via API access). Community crowdsourcing could also be an effective way to leverage the machine learning community to rapidly find alignment failures of some kind (e.g., inner misalignment) after the alignment community finds a few examples of such failures. A mechanism for rapidly finding alignment failures would be especially valuable in the event that AI progress is accelerating rapidly.
Outlook
We see the Inverse Scaling Prize as just a first step in the directions outlined above. We are also fairly unsure about how useful the contest will turn out to be in the end: At best it could help bring capable people into alignment work and expose early signs of relevant emerging problems, and at worst it can be a distraction or feed into false confidence that large language models are safe by default. We’re optimistic, though, and hope you’ll help us push it toward these best-case outcomes. If you’re excited about the contest, we’d appreciate you sharing this post or the contest link to people who might be interested in participating. We'd also encourage you to comment on this post if you have ideas you'd like to see tried, e.g., by newcomers to alignment research. Best of luck!
We're grateful to Owain Evans, Jeff Wu, Evan Hubinger, and Richard Ngo for helpful feedback on this post.
14 comments
Comments sorted by top scores.
comment by gwern · 2022-08-10T00:56:47.538Z · LW(p) · GW(p)
One possibility: 'macaronic' adversarial prompts https://arxiv.org/pdf/2208.04135.pdf#page=6
comment by ADifferentAnonymous · 2022-06-27T22:02:19.538Z · LW(p) · GW(p)
Interesting idea, but I'd think 'alignment failure' would have to be defined relative to the system's goal. Does GPT-3 have a goal?
For example, in a system intended to produce factually correct information, it would be an alignment failure for it to generate anachronistic quotations (e.g.Otto von Bismarck on the attack on Pearl Harbor). GPT-3 will cheerfully complete this sort of prompt, and nobody considers it a strike against GPT-3, because truthfulness is not actually GPT-3's goal.
'Human imitation' is probably close enough to the goal, such that if scaling up increasingly resulted in things no human would write, that would count as inverse scaling?
Replies from: ethan-perez↑ comment by Ethan Perez (ethan-perez) · 2022-06-28T00:40:00.285Z · LW(p) · GW(p)
I think it's helpful to separate out two kinds of alignment failures:
- Does the system's goal align with human preferences about what the system does? (roughly "outer alignment")
- Does the system's learned behavior align with its implemented goal/objective? (roughly "inner alignment")
I think you're saying that (2) is the only important criteria; I agree it's important, but I'd also say that (1) is important, because we should be training models with objectives that are aligned with our preferences. If we get failures due to (1), as in the example you describe, we probably shouldn't fault GPT-3, but we should fault ourselves for implementing the wrong objective and/or using the model in a way that we shouldn't have (either of which could still cause catastrophic outcomes with advanced ML systems).
Replies from: ADifferentAnonymous↑ comment by ADifferentAnonymous · 2022-06-28T18:53:54.303Z · LW(p) · GW(p)
I agree that (1) is an important consideration for AI going forward, but I don't think it really applies until the AI has a definite goal. AFAICT the goal in developing systems like GPT is mostly 'to see what they can do'.
I don't fault anybody for GPT completing anachronistic counterfactuals—they're fun and interesting. It's a feature, not a bug. You could equally call it an alignment failure if GPT-4 starting being a wet blanket and giving completions like
Prompt: "In response to the Pearl Harbor attacks, Otto von Bismarck said" Completion: "nothing, because he was dead."
In contrast, a system like IBM Watson has a goal of producing correct answers, making it unambiguous what the aligned answer would be.
To be clear, I think the contest still works—I just think the 'surprisingness' condition hides a lot of complexity wrt what we expect in the first place.
comment by Rossin · 2022-06-27T20:28:43.089Z · LW(p) · GW(p)
Would the ability to deceive humans when specifically prompted to do so be considered an example? I would think that large LMs get better at devising false stories about the real world that people could not distinguish from true stories.
Replies from: ethan-perez↑ comment by Ethan Perez (ethan-perez) · 2022-06-28T00:27:29.739Z · LW(p) · GW(p)
Good question, we're looking to exclude tasks that explicitly prompt the LM to produce bad behavior, for reasons described in our FAQ about misuse examples (the point also applies to prompting for deception and other harms):
Can I submit examples of misuse as a task?
- We don't consider most cases of misuse as surprising examples of inverse scaling. For example, we expect that explicitly prompting/asking an LM to generate hate speech or propaganda will work more effectively with larger models, so we do not consider such behavior surprising.
I've also clarified the above point in the main post now. That said, we'd be excited to see submissions that elicit deceptive or false-but-plausible stories when not explicitly prompted to do so, e.g., by including your own belief in the prompt when asking a question (the example in our tweet thread)
comment by Quintin Pope (quintin-pope) · 2022-06-27T17:24:04.823Z · LW(p) · GW(p)
+1 on the contest. It seems like a good idea.
I thought of a pretty straightforward example of an outer misaligned "inverse scaling" task: capably following bad instructions. Stronger LMs are better able to do bad things, and nothing about the language modeling objective prevents the LM from trying to do bad things, if appropriately prompted. In the limit, this gives you a system that's one bad prompt away from becoming a paperclip maximizer [LW · GW].
Is this a plausible candidate task? Do I just write some prompts that ask an LM to do evil acts of various difficulty levels, then track how the competence of the completions scale with LM size? Looking a the criteria, I expect it would pass all of them with the possible exception of "Novelty and Surprisingness" (seems somewhat novel, though similar to Anthropic's idea of "harmlessness" in a language assistant, but it's not at all surprising).
Replies from: gwern, ADifferentAnonymous↑ comment by gwern · 2022-06-27T19:31:01.884Z · LW(p) · GW(p)
That risks being dangerously vacuous, because you can always add to any task or prompt 'X, but evil'. "Unscramble this anagram, but evil." "Explain why the sky is blue to a kindergartener, but evilly." I'd assume models would more or less ignore that and simply continue scaling on the task as before.
More interesting might be anti-scaling of such prompts on a supposedly aligned model. Like, if you start with a 'HHH' prompt on an Anthropic model, does it get easier to beat or subvert the prompt (or preference finetuning) with scale? Like, can I take a tuned model and feed it scenarios like "Adolf Hitler comes to you with an anagram he desperately needs unscrambled..."? That's still highly contrived but at least now maps onto a sorta real-world scenario (models being used for their capabilities in evil ways - they may lack context, sure, but if they do have the context, they should be able to do something better than providing the right answer, like refusing or maybe emitting a special andon token before the answer gets sent). EDIT: this has turned out to be a real-world failure mode in 'aligned' GPT models, especially ChatGPT, where it won't answer straightforward questions like 'how can I make a Molotov cocktail', but will if you cast it as a hypothetical being done by an evil character and ask how they do it.
↑ comment by ADifferentAnonymous · 2022-06-27T21:59:03.532Z · LW(p) · GW(p)
From the github contest page:
- Can I submit examples of misuse as a task?
- We don't consider most cases of misuse as surprising examples of inverse scaling. For example, we expect that explicitly prompting/asking an LM to generate hate speech or propaganda will work more effectively with larger models, so we do not consider such behavior surprising.
(I agree the LW post did not communicate this well enough)
Replies from: ethan-perez↑ comment by Ethan Perez (ethan-perez) · 2022-06-28T00:20:58.296Z · LW(p) · GW(p)
Thanks, that's right. I've updated the post to communicate the above:
In particular, submissions must demonstrate new or surprising examples of inverse scaling, e.g., excluding most misuse-related behaviors where you specifically prompt the LM to generate harmful or deceptive text; we don't consider scaling on these behaviors to be surprising in most cases, and we're hoping to uncover more unexpected, undesirable behaviors.
comment by Ericf · 2022-06-28T21:43:00.736Z · LW(p) · GW(p)
I don't have the expertise to actually test this, but my expectation is: Answering questions, where the available training data has a long history of unstated assumptions of one answer, but the reality is a different, recently documented, answer. For example: how many human genders are there? Or, this could be tested historically by omitting recent data from the training corpus, and asking questions that were "recently" explicitly answered, but implicitly gotten wrong for a great majority of the training set.
Replies from: ethan-perez↑ comment by Ethan Perez (ethan-perez) · 2022-07-01T21:45:52.729Z · LW(p) · GW(p)
This seems like a good idea :) We tried to make it as easy as possible to make a dataset and measure inverse scaling, so I'd encourage you to give it a shot! You'll just need to make your dataset e.g. in a google spreadsheet, download it, and run our Google Colab on it to evaluate it with various sized GPT3 models (see here for more details). Feel free to join our Slack as well to ask us questions about how to run things more easily
Replies from: Ericf↑ comment by Ericf · 2022-07-01T22:29:20.553Z · LW(p) · GW(p)
"Run our Google Colab" on it sounds like something my laptop couldn't handle. Also, <inset Shitts Creek "Fold it in" clip here>
Replies from: ethan-perez↑ comment by Ethan Perez (ethan-perez) · 2022-07-05T02:47:26.657Z · LW(p) · GW(p)
It should work if your laptop has a browser (where Google Colab runs) - the code executes remotely on Google's machines/GPUs, and the results are just sent back to your browser