Posts
Comments
Nope, I didn't know PaCMAP! Thanks for the pointer, I'll have a look.
In section 5, I explain how CoEm is an agenda with relaxed constraints. It does try to reduce the alignment tax to make the safety solution competitive for lab to use. Instead it considers there's enough advance in international governance that you have full control over how your AI get built and that there's enforcement mechanism to ensure no competitive but unsafe AI can be built somewhere else.
That's what the bifurcation of narrative is about: not letting lab implement only solution that have low alignment tax because this could just not be enough.
My steelman of Conjecture's position here would be:
- Current evals orgs are tightly integrated with AGI labs. AGI labs can pick which evals org to collaborate with, control the model access, which kind of evals will be conducted, which kind of report will be public, etc. This is this power position that makes current evals feed into AGI orthodoxy.
- We don't have good ways to conduct evals. We have wide error bars over how much juice one can extract from models and we are nowhere close to having the tools to upper bound capabilities from evals. I remember this being a very strong argument internally: we are very bad at extracting capabilities from pre-trained models and unforeseen breakthroughs (like a mega-CoT, giving much more improvement than a fine-tuning baseline) could create improvement of several compute-equivalent OOM in the short term, rendering all past evals useless.
- Evals draw attention away from other kinds of limits, in particular compute limits. Conjecture is much more optimistic about (stringent) compute limits as they are harder to game.
My opinion is:
- For evals to be fully trusted, we need more independence such as third party auditing designated by public actors with a legal framework that gives modalities for access to the models. External accountability is the condition needed for evals not to feed into AGI orthodoxy. I'm quite optimistic that we'll get there soon, e.g. thanks to the effort of the UK AI Safety Institute, the EU AI Act, etc.
- Re point I: the field of designing scaffolding is still very young. I think it's possible we can see surprising discontinuous progress in this domain such that current evals were in fact far from the upper bound of capabilities we can extract from models. If we base deployment / training actions on such evals and find out later a better technique, it's really hard to revert (e.g. for open source, but also it's much easier to stop a model halfway through training when finding a scary ability than deleting it after a first period of deployment). See https://www.lesswrong.com/posts/fnc6Sgt3CGCdFmmgX/we-need-a-science-of-evals
- I agree with the point 3. I'm generally quite happy with what we learned from the conservative evals and the role they played in raising public awareness of the risks. I'd like to see evals org finding more robust ways to evaluate performances and go toward more independence from the AGI labs.
I really appreciate the naturalistic experimentation approach – the fact that it tries to poke at the unknown unknowns, discovering new capabilities or failure modes of Large Language Models (LLMs).
I'm particularly excited by the idea of developing a framework to understand hidden variables and create a phenomenological model of LLM behavior. This seems like a promising way to "carve LLM abilities at their joint," moving closer to enumeration rather than the current approach of 1) coming up with an idea, 2) asking, "Can the LLM do this?" and 3) testing it. We lack access to a comprehensive list of what LLMs can do inherently. I'm very interested in anything that moves us closer to this, where human creativity is no longer the bottleneck in understanding LLMs. A constrained psychological framework could be helpful in uncovering non-obvious areas to explore. It also offers a way to evaluate the frameworks we build: do they merely describe known data, or do they suggest experiments and point toward phenomena we wouldn't have discovered on our own?
However, I believe there are unique challenges in LLM psychology that make it more complex:
- Researchers are humans. We have an intrinsic understanding of what it's like to be human, including interesting capabilities and phenomena to study. Researchers can draw upon all of human history and literature to find phenomena worth exploring. In many ways, the hundreds of years of stories, novels, poems, and movies pre-digest work for psychologists by drawing detailed pictures of feelings, characters, and behaviors and surfacing the interesting phenomenon to study. LLMs, however, are i) extremely recent, and ii) a type of non-localized intelligence we have no prior examples of. This means we should expect significant blind spots.
- LLMs appear quite brittle. Findings might be highly sensitive to i) the base model, ii) fine-tuning, and iii) the pre-prompt. Studying LLMs might mean exploring all the personas they can instantiate, potentially a vastly more enormous space than the range of human brains.
- There's also the risk of being confused by results and not knowing how to proceed. For instance, if you find high sensitivity to the exact tokens used, affecting certain properties in ways that seem illogical, you might have a lot of data but no framework to make sense of it.
I really like the concept of species-specific experiments. However, you should be careful not to project too much of your prior models into these experiments. The ideas of latent patterns and shadows could already make implicit assumptions and constrain what we might imagine as experiments. I think this field requires epistemology on steroids because i) experiments are cheap, so most of our time is spent digesting data, which makes it easy to go off track and continually study our pet theories, and ii) our human priors are probably flawed to understand LLMs.
What I really like about ancient language is that there's no online community the model could exploit. Even low-ressource modern languages have online forums an AI could use as an entry point.
But this consideration might be eclipsed by the fact that a rogue AI would have access to a translator before trying online manipulation, or by another scenario I'm not considering.
Agree with the lack of direct access to CoT being one of the major drawback. Though we could have a slightly smarter reporter that could also answer questions about CoT interpretation.
One could also imagine asking a group of Sumerian experts to craft new words for the occasion such that the updated language has enough flexibility to capture the content of modern datasets.
Thanks for your comment, these are great questions!
-
I did not conduct analyses of the vectors themselves. A concrete (and easy) experiment could be to create UMAP plot for the set of residual stream activations at the last position for different layers. I guess that i) you start with one big cluster. ii) multiple clusters determined by the value of R iii) multiple clusters determined by the value of R(C). I did not do such analysis because I decided to focus on causal intervention: it's hard to know from the vectors alone what are the differences that matter for the model's computation. Such analyses are useful as side sanity checks though (e.g. Figure 5 of https://arxiv.org/pdf/2310.15916.pdf ).
-
The particular kind of corruption of C -- adding a distractor -- is designed not to change the content of C. The distractor is crafted to be seen as a request for the model, i.e. to trigger the induction mechanism to repeat the token that comes next instead of answering the question.
Take the input X with C = "Alice, London", R = "What is the city? The next story is in", and distractor D = "The next story is in Paris."*10. The distractor successfully makes the model output "Paris" instead of "London".
My guess on what's going on is that the request that gets compiled internally is "Find the token that comes after 'The next story is in' ", instead of "Find a city in the context" or "Find the city in the previous paragraph" without the distractor.
When you patch the activation from a clean run, it restores the clean request representation and overwrites the induction request.
- Given the generality of the phenomenon, my guess is that results would generalize to more complex cases. It is even possible that you can decompose in more steps how the request gets computed, e.g. i) represent the entity ("Alice") you're asking for (possibly using binding IDs) ii) represent the attribute you're looking for ("origin country") iii) retrieve the token.
B* 3.22
It seems to be a duplicate of problem 3.18.
Thanks for this rich analogy! Some comments about the analogy between context window and RAM:
Typo in the model name
GPT3 currently has an 8K context or an 8kbit RAM (theoretically expanding to 32kbit soon). This gets us to the Commodore 64 in digital computer terms, and places us in the early 80s.
I guess you meant GPT4 instead of GPT3.
Equivalence token to bits
Why did you decide to go with the equivalence of 1 token = 1 bit? Since a token can usually take on the order of 10k to 100k possible values, wouldn't 1 token equal 13-17 bits a more accurate equivalence?
Processor register as a better analog for the context window
One caveat I'd like to discuss: in the post, you describe the context window of NLPU as the analog for the RAM of computers. I think a more accurate analog could be processor registers.
Similarly to the context window, they are the memory bits directly connected to the computing unit. Whereas, it takes an instruction to load information from RAM before it can be used by the CPU. The RAM sits in the middle of the memory hierarchy, while registers are at its top.
{kind=link}
If we accept this new analog, then NLPUs have by default (without external memory) access to much more data than CPUs. Modern CPUs have around 32 32-bit registers, so around 1kbit of space to store inputs, compared to the 80kbit in the context length of current LLM (using 1 token = 10 bits).
I think this might be an additional factor -- on top of the increased power and reliability of LLM -- that made us wait for so long after GPT3 before beginning to design complicated chaining of LLM calls. A single LM can store enough data in its context window to do many useful tasks: as you describe, there are many NLPU primitives to discover and exploit. On the other hand, a CPU with no RAM is basically an over-engineered calculator. It becomes truly useful once embedded in a von-Neumann architecture.
Multimodal models
If the natural type signature of a CPU is bits -> bits, the natural type of the natural language processing unit (NLPU) is strings -> strings.
With the rise of multimodal (image + text) models, NLPU could be required to deal with other data types than "string" like image embeddings, as images cannot be efficiently converted into natural text.
I don't have a confident answer to this question. Nonetheless, I can share related evidence we found during REMIX (that should be public in the near future).
We defined a new measure for context sensitivity relying on causal intervention. We measure how much the in-context loss of the model increases when we replace the input of a given head with a modified input sequence, where the far-away context is scrubbed (replaced by the text from a random sequence in the dataset). We found heads in GPT2-small that are context-sensitive according to this new metric, but score low on the score used to define induction heads. This means that there exist heads that heavily depend on the context that are not behavioral induction heads.
It's unclear what those heads are doing (if that's induction-y behavior on natural text or some other type of in-context processing that cannot be described as "induction-y").
You're right, thanks for spotting it! It's fixed now.
I recently applied causal scrubbing to test the hypothesis outlined in the paper (as part of my work at Redwood Research). The hypothesis was defined from the circuit presented in Figure 2. I used a simple setting similar to the experiments on Induction Heads. I used two types of inputs:
- the correct input for the circuit.
- , an input with the same template but a randomized subject and indirect object. Used as input for the path not included in the circuit.
Results
Experiment 1
I allowed all MLPs on every path of the circuit. The only attention heads non-scrubbed in this hypothesis are the ones from the circuit, split by key, queries, values, and position as in the circuit diagram.
This experiment is directly addressing our claim in the paper, as we did not study MLPs (i.e. they are always acting as black boxes in our experiments).
The logit difference of the scrubbed model is 1.854±2.127 (mean±std), 50%±57 of the original logit difference.
Experiment 2
I connected Name Movers’ keys and values to MLP0 at the IO and S1 positions. All the paths from embeddings to these MLP0 are allowed.
I allowed all the paths involving all attention heads and MLPs from the embeddings to
- The queries of S-Inhibition Heads at the END position.
- The queries of the Duplicate Token Heads and Induction Heads at the S2 position.
- The keys and values of the Duplicate Token Heads at the S1 and IO position.
- The value of Previous Token heads at the S1 and IO position.
Inside the circuit, only the direct interactions between heads are preserved.
The logit difference of the scrubbed model is 0.831±2.127 (22%±64 of the original logit difference).
Comments
- How to interpret these numbers? I don’t really know. My best guess is that the circuit we presented in the paper is one of the best small sets of paths to look at to describe how GPT-2 small achieves high logit difference on IOI. However, in absolute, many more paths that we don't have a good way to describe succinctly matter.
- The measures are extremely noisy. This is consistent with the measure of logit difference on the original model, where the standard deviation was around 30% of the mean logit difference. However, I ran causal scrubbing on a dataset with big enough samples (N=100) that the numbers are interpretable. I don’t understand the source of this noise, but suspect it is caused by various names triggering various internal structures inside GPT-2 small.
- How does it compare to the validations from the paper? The closest validation score from the paper is the faithfulness score -- computing the logit difference of the model where all the nodes not in the circuit are mean ablated. In the paper, we present a score of 87% of the logit difference. I think the discrepancies with the causal scrubbing results from experiment 1 come from the fact that i) resampling ablation is more destructive than mean ablation in this case. ii) that causal scrubbing is stricter as it selects paths and not nodes (e.g. in the faithfulness tests, Name Mover Heads at the END position see the correct output of Induction Heads at the S2 position. This is not the case in causal scrubbing). The results of the causal scrubbing experiments update me toward thinking that our explanation is not as good as I thought from our faithfulness score, but not low enough to strongly question the claims from the paper.
This is an important point, but it also highlights how the concept of gliders is almost tautological. Any sequence of entangled causes and effects could be considered a glider, even if it undergoes superficial transformations.
I agree with this. I think that the most useful part of the concept is to force making the difference between the "superficial transformations" and the "things that stays".
I also think that it's useful to think about text features that are not (or unlikely to be) gliders like
- The tone of a memorized quote
- A random date chosen to fill a blank in an administrative report
- The characters in a short story, part of a list of short stories. In general, every feature coming before a strong context switch is unlikely to be transmitted further.
Thanks, it's fixed!
Thanks for your comment!
1.
Looking at your example, “Then, David and Elizabeth were working at the school. Elizabeth had a good day. Elizabeth decided to give a bone to Elizabeth”. I'm confused. You say "duplicating the IO token in a distractor sentence", but I thought David would be the IO here?
Am I confused about the meaning of the IO or was there just a typo in the example?
You are right, there is a typo here. The correct sentence is “Then, David and Elizabeth were working at the school. David had a good day. Elizabeth decided to give a bone to Elizabeth”
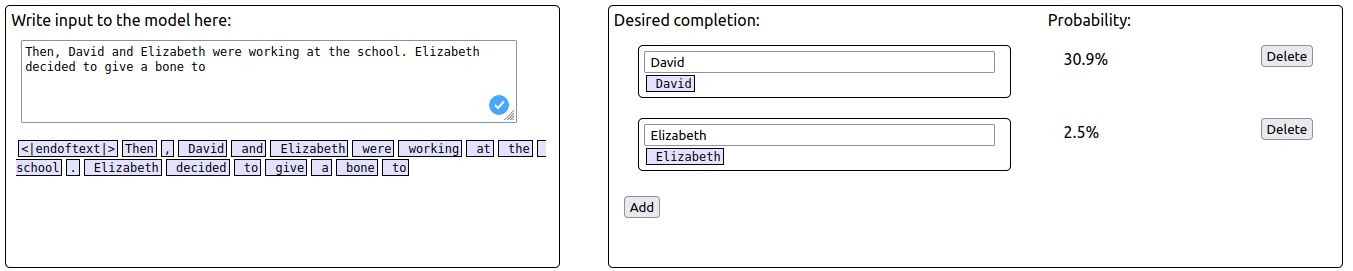
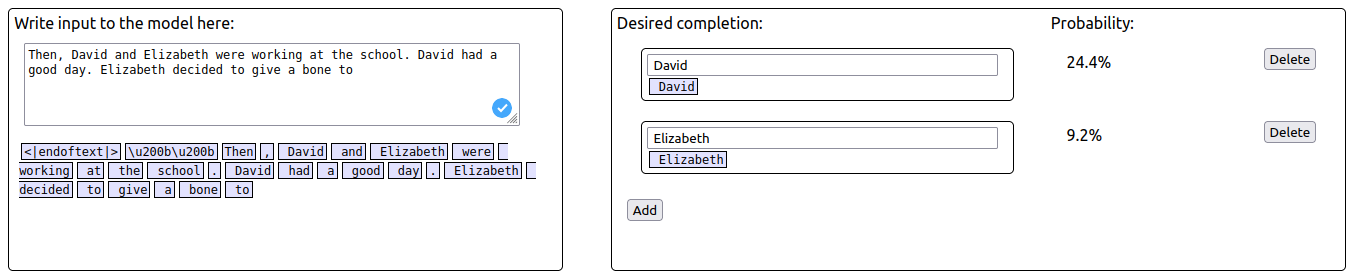
When using the corrected adversarial prompt, the probability of S ("Elizabeth") increases while the probability of IO ("David") decreases.
Thanks a lot for spotting the typo, we corrected the post!
2.
I'd love if you could expand on this (maybe with an example). It sounds like you're implying that the circuit you found is not complete?
A way we think the circuit can differ depending on examples is if there are different semantic meaning involved. For instance, in the example above, the object given is a "bone" such that a "a dog" could also be a plausible prediction. If "Elizabeth decided to give a kiss", then the name of a human seems more plausible. If this is the case, then there should be additional components interfering with the circuit we described to incorporate information about the meaning of the object.
In addition to semantic meaning, there could be different circuits for each template, different circuits could be used to handle different sentence structures.
In our study we did not investigate what differ between specific examples as we're always averaging experiments results on the full distribution. So in this way the circuit we found is not complete, as we can not explain the full distribution of the model outputs. However, we would expect that each circuit would be a variation of the circuit we described in the paper.
There are other ways we think our circuit is not complete, see the section 4.1 for more experiments on these issues.
Thanks for the feedback!
Does this mean that it writes a projection of S1's positional embedding to S2's residual stream? Or is it meant to say "writing to the position [residual stream] of [S2]"? Or something else?
Our current hypothesis is that they write some information about S1's position (that we called the "position signal", not as straightforward as a projection of its positional embedding) in the residual stream of S2. (See the paragraph "Locating the position signal." in section 3.3). I hope this answer your questions.
We currently think that the position signal is a relative pointer from S2 to S1, computed by the difference between the positions S2 and S1. However, our evidence for this claim is quite small (see the last paragraph of Appendix A).
That's definitely an exciting direction for future research!