Studying The Alien Mind
post by Quentin FEUILLADE--MONTIXI (quentin-feuillade-montixi), NicholasKees (nick_kees) · 2023-12-05T17:27:28.049Z · LW · GW · 10 commentsContents
TL;DR
Introduction
Experiments vs Field Study
Experimental psychology
Field study
Field Study for LLM psychology
Studying LLMs is different
Anthropomorphism
Replicability
Volume and diversity of data
Ethical considerations
Exploring counterfactuals
Checkpointing models
A two stage model of science
Species specific experiments
LLM-specific research
Chat models are still predictors
Conclusion
None
10 comments
This post is part of a sequence on LLM psychology [LW · GW]

TL;DR
We introduce our perspective on a top-down approach for exploring the cognition of LLMs by studying their behavior, which we refer to as LLM psychology. In this post we take the mental stance of treating LLMs as “alien minds,” comparing and contrasting their study with the study of animal cognition. We do this both to learn from past researchers who attempted to understand non-human cognition, as well as to highlight how much the study of LLMs is radically different from the study of biological intelligences. Specifically, we advocate for a symbiotic relationship between field work and experimental psychology, as well as cautioning implicit anthropomorphism in experiment design. The goal is to build models of LLM cognition which help us to both better explain their behavior, as well as to become less confused about how they relate to risks from advanced AI.
Introduction
When we endeavor to predict and understand the behaviors of Large Language Models (LLMs) like GPT4, we might presume that this requires breaking open the black box, and forming a reductive explanation of their internal mechanics. This kind of research is typified by approaches like mechanistic interpretability, which tries to directly understand how neural networks work by breaking open the black box and taking a look inside.
While mechanistic interpretability offers insightful bottom-up analyses of LLMs, we’re still lacking a more holistic top-down approach to studying LLM cognition. If interpretability is analogous to the “neuroscience of AI,” aiming to understand the mechanics of artificial minds by understanding their internals, this post tries to approach the study of AI from a psychological stance.[1]
What we are calling LLM psychology is an alternate, top-down approach which involves forming abstract models of LLM cognition by examining their behaviors. Like traditional psychology research, the ambition extends beyond merely cataloging behavior, to inferring hidden variables, and piecing together a comprehensive understanding of the underlying mechanisms, in order to elucidate why the system behaves as it does.
We take the stance that LLMs are akin to alien minds – distinct from the notion of them being only stochastic parrots [? · GW]. We posit that they possess a highly complex internal cognition, encompassing representations of the world and mental concepts, which transcend mere stochastic regurgitation of training data. This cognition, while derived from human-generated content, is fundamentally alien to our understanding.
This post compiles some high-level considerations for what successful LLM psychology research might entail, alongside broader discussions on the historical study of non-human cognition. In particular, we argue for maintaining a balance between experimental and field work, taking advantage of the differences between LLMs and biological intelligences, and designing experiments which are carefully tailored to LLMs as their own unique class of mind.
Experiments vs Field Study
One place to draw inspiration from is the study of animal behavior and cognition. While it is likely that animal minds are much more similar to our own than that of an artificial intelligence (at least mechanically), the history of the study of non-human intelligence, the evolution of the methodologies it developed, and the challenges it had to tackle can provide inspiration for investigating AI systems.
As we see it, there are two prevalent categories of animal psychology:
Experimental psychology
The first, and most traditionally scientific approach (and what most people think of when they hear the term “psychology”) is to design experiments which control as many variables as possible, and test for specific hypotheses.
Some particularly famous examples of this is the work done by Ivan Pavlov or B.F. Skinner, who placed animals in highly controlled environments, subjected them to stimuli, and recorded their responses.[2] The aim of this kind of work is to find simple hypotheses which explain the recorded behavior. While experimental psychology has changed a lot since these early researchers, the emphasis remains on prioritizing the reliability and replicability of results by sticking to a conventional approach to the scientific method. This approach, while rigorous, trades off bandwidth of information exchange between the researcher and the subject, in favor of controlling confounding variables, which can actually lead to the findings being less reliable [LW · GW].
Regardless, experimental psychology has been a central pillar for our historic approach to understanding animal cognition, and has produced lots of important insights. A few interesting examples include:
- A study on New Caledonian crows revealed their ability to spontaneously solve a complex meta-tool task. This behavior demonstrated sophisticated physical cognition and suggested the use of analogical reasoning.
- A study conducted on scrub jays demonstrated their ability to recall not only the location but also the timing of food items they had cached. This behavior reflects episodic-like memory, a form of memory previously thought to be unique to humans.
- In experiments, Norway rats showed a greater tendency to learn from others when they were dissatisfied (like being on a poor diet or in an uncomfortable setting) or uncertain (not knowing which food might be harmful). The study underscores how negative experiences or uncertainty influence social behaviors in rats.
Field study
The other approach is for a researcher to personally spend time with animals, intervene much less, and focus on collecting as many observations as possible in the animal's natural habitat.
The most famous example of this method is the work pioneered by Jane Goodall, who spent years living with and documenting the behavior of chimpanzees in the wild. She discovered that chimpanzees use tools (previously thought to be unique to humans), have complex social relationships, engage in warfare, and show a wide range of emotions, including joy and sorrow. Her work revolutionized our understanding of chimpanzees. Unlike experimentalists, she was fairly comfortable with explaining behavior through her personally biased lens, resulting in her receiving a lot of criticism at the time.[3]
Some other notable examples of field study:
- Cynthia Moss spent decades studying African elephants in the wild, discovering, for example, that elephants live in highly organized and hierarchical societies headed by a matriarch. She spent 30 years following and studying one such matriarch, Echo, as well as the rest of her extended family.
- Considered a “founder father” of ethology, Konrad Lorenz discovered many innate behaviors in geese and other birds, including the behavior of imprinting, where geese learn to recognize members of their own species. He was particularly notable at the time for his skepticism toward laboratory work, and an insistence on studying animals in their natural context, as well as allowing himself to imagine their mental/emotional states.[4]
- L. David Mech studied the behavior of wolves in the wild for many decades, both introducing the concept of an “alpha wolf” as well as later debunking the notion, discovering that the dominance hierarchies found in captive wolves were not at all present in their wild counterparts.
While experimental psychology tends to (quite deliberately) separate the researcher from the subject, field study involves a much more direct relationship between the subject and the researcher. The focus is on purchasing bandwidth even if it opens the door to researcher specific bias. Despite concerns about bias, field work has been able to deliver foundational discoveries that seem unlikely to have been achievable with just laboratory experiments.
It’s worth noting there are examples that lie somewhat in between these two categories we’ve laid out, where researchers who performed lab experiments on animals also had quite close personal relationships to the animals they studied. For example, Irene Pepperberg spent roughly 30 years closely interacting with Alex, a parrot, teaching him to perform various cognitive and linguistic tasks unprecedented in birds.[5]
Field Study for LLM psychology
Field studies in LLM research extend beyond simple observation and documentation of model behavior; they represent an opportunity to uncover new patterns, capabilities, and phenomena that may not be apparent in controlled experimental settings. Unlike mechanistic interpretability and other areas of LLM research, which often require prior knowledge of a phenomenon to study it, field studies have the potential to reveal unexpected insights into language models.
Moreover, the serendipitous discoveries made during field work could fuel collaborations between fields. Insights gleaned from field observations could inform targeted studies into the model's underlying mechanisms, or broader experimental studies, creating a productive feedback loop, guiding us to ask new questions and probe deeper into the 'alien minds' of these complex systems.
Due in part to ML research culture, and the justifiable worry about over-interpreting AI behavior, field work receives a lot less serious attention than experimental work does. Looking at the value that field work has added to the study of animals, it seems quite important to push against this bias and make certain to include field study as a core part of our approach to study LLMs cognition.
Studying LLMs is different
There are a lot of reasons to expect LLM psychology to be different from human or animal psychology.
Anthropomorphism
The utility of anthropomorphic perspectives in studying LLMs is a complex subject. While LLMs operate on an architecture that differs significantly from biological cognition, their training on human language data predisposes them to output human-like text. This juxtaposition can lead to misleading anthropomorphic assumptions about the nature of their cognition. It's crucial to be extremely careful and explicit about which anthropomorphic frameworks one chooses to apply, and to distinguish clearly between different claims about LLM cognition.
While caution is warranted, ignoring connections between biological and artificial cognition could risk overlooking useful hypotheses and significantly slow down studies.[6]
Replicability
A persistent challenge in psychological research is the low replicability of studies. One of the reasons is the challenge of keeping track of the countless variables that could potentially skew an experiment. Factors like a participant’s mood, childhood, or even whether the fragrance of the ambient air is pleasant can obfuscate the true origin of a behavior.
However, with LLMs, you have control over all variables: the context, the specific model’s version, and the hyperparameters of the sampling. It is therefore more feasible to design experiments which can be repeated by others.
A notable challenge remains in verifying that the experimental setting is sufficient to guarantee that the findings can be generalized beyond the specific conditions of the experiment. Alternatively, it might be more appropriate to explicitly limit the scope of the study's conclusions to the particular settings tested.
Another significant challenge to replicability in practice is the level of access that a researcher has to a model. With only external access through an API, the model weights may be changed without warning, causing results to change. Furthermore, in certain situations the context might be altered behind the scenes in ways that are opaque from the outside, and the precise method for doing so might also change over time.
Volume and diversity of data
Animal (including human) experiments can be expensive, time-consuming, and labor-intensive. As a result, typical sample sizes are often very low. Also, if you want to study rare or intricate scenarios, it can be quite hard to design the experimental setup, or finding the right test subjects, limiting what you can actually test.
In contrast, AIs are cheap, fast, and don’t sleep. They operate without requiring intensive supervision and a well-structured experimental framework often suffices for experimentation at scale. Furthermore, you have virtually every experimental setting you can imagine right at your fingertips.
Ethical considerations
Experiments on humans, and especially animals, can rely on ethically dubious methods which cause a great deal of harm to their subjects. When experimenting on biological beings, you have to follow the laws of the country you conduct your experiments in, and they are sometimes pretty constraining for specific experiments.
While it’s not definitive whether the same concern should be extended to AI systems, there are currently no moral or ethical guidelines for experimenting on LLMs, and no kind of law ruling our interactions with those systems. To be clear, this is a very important question, as getting this question wrong could result in suffering at an unprecedented scale, precisely because such experiments are so cheap to run.
Exploring counterfactuals
In traditional experiments involving animals or humans, it is really hard to rerun experiments with adjustments to the experimental setup, in order to detect the precise emergence or alteration of a specific behavior. Such iterations introduce additional confounding variables, complicating the experimental design. In particular the fact that the subject might remember or learn from a past iteration makes the reliability especially suspect.
To work around this, researchers often create multiple variations of an experiment, testing a range of preconceived hypotheses. This necessitates dividing subjects into various groups, substantially increasing the logistical and financial burdens. For example, in studies of memory and learning, such as the classic Pavlovian conditioning experiments, slight alterations in the timing or nature of stimuli can lead to significantly different outcomes in animal behavior, requiring multiple experimental setups to isolate specific factors. Despite these efforts, the granularity in detecting behavior changes remains relatively coarse, and is limited to the preconceived hypotheses you decided to test.
In contrast, when working with LLMs, we possess the ability to branch our experiments, allowing a detailed tracing of the evolution of behaviors. If an intriguing behavior emerges during an interaction with a model, we can effortlessly replicate the entire context of that interaction. This enables us to dissect and analyze the root of the behavior in a post hoc manner, by iteratively modifying the prompt as finely as desired, delimiting the precise boundaries of the observed behaviors. Such granularity in experimentation offers an unprecedented level of precision and control, unattainable in traditional human or animal research settings.
Checkpointing models
Not only can we save the context which produced a particular behavior, but we can also save and compare different copies of the model during its training phase. While there are studies on the development of animals or human behaviors throughout their lifetime, they are inherently slow and costly, and often require a clear idea of what you are going to measure from the start.
Moreover, checkpointing allows for the exploration of training counterfactuals. We can observe the difference between models with specific examples included or excluded from the training, thereby allowing us to study the effects of training in a more deliberate manner.[7] Such examination is impossible in human and animal studies due to their prolonged timelines and heavy logistical burden.
Considering these differences, it becomes evident that many of the constraints and limitations of traditional psychological research do not apply to the study of LLMs. The unparalleled control and flexibility we have over the experimental conditions with LLMs not only accelerates the research process but also opens up a realm of possibilities for deeper, more nuanced inquiries.
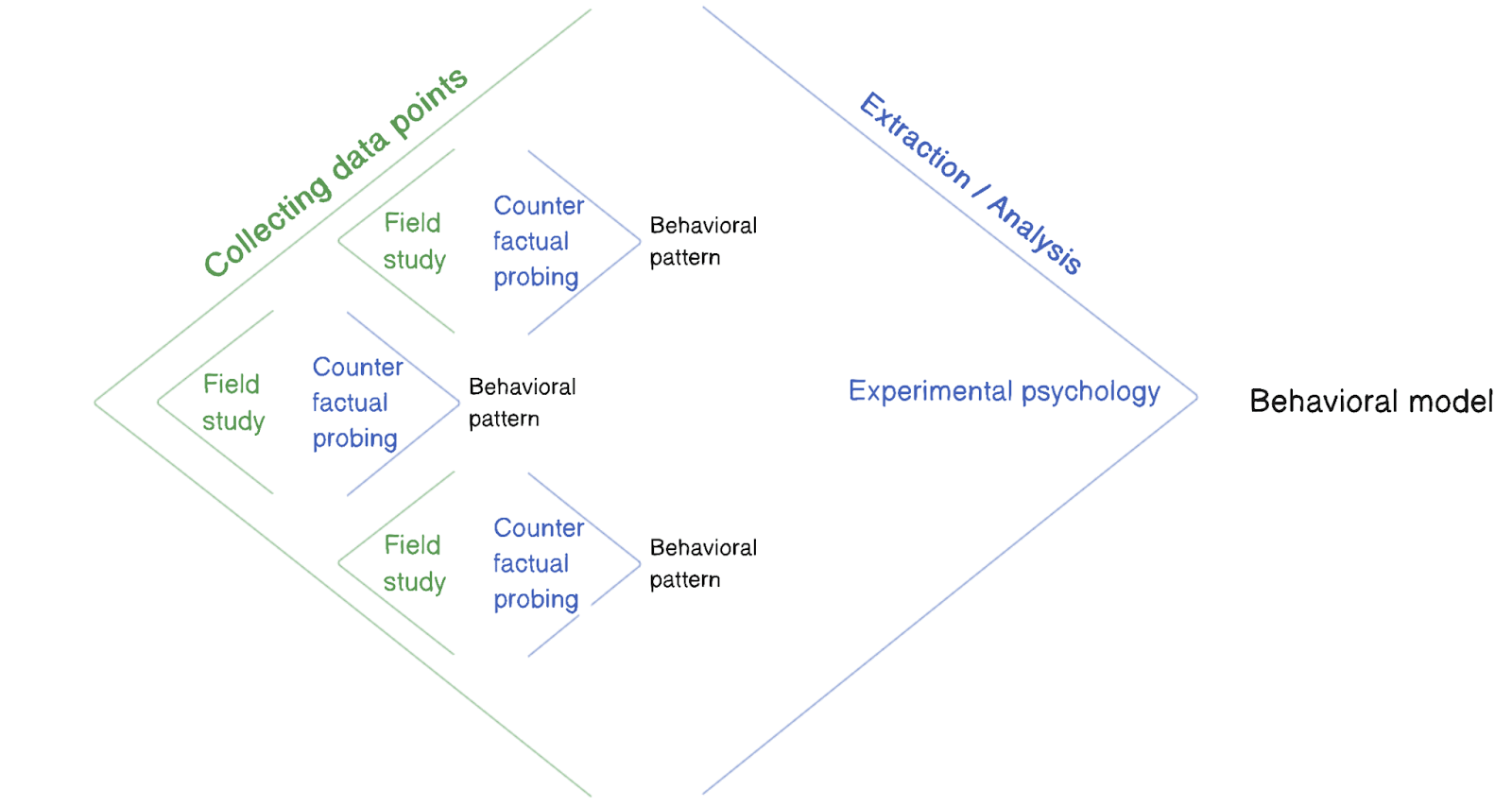
A two stage model of science
In science, the first step often begins with an extensive collection of observations, which serve as the foundational building blocks for establishing patterns, models, and theories. A historical instance of this can be seen in the careful observation of planetary movements by astronomers like Tycho Brahe, which was instrumental in the formulation of Kepler’s laws of celestial mechanics.
The next step usually involves formulating hypotheses explaining those observations, and conducting experiments which rigorously test them. With LLMs, this step is made significantly easier by both 1) the ability to record the full state that produces an observation and 2) the exploration of counterfactual generations. This makes it possible to interweave hypothesis testing and causal interventions much more closely with field work.
If during a field study a researcher finds a particularly interesting behavior, it is then immediately possible for them to create fine grained ‘what if’ trees, and detect, a posteriori, the precise conditions and variables that influence the specific observed behavior. This is very different from traditional psychology, where most data is not explicitly measured and is therefore entirely lost. Instead of needing to wait for slow and expensive experimental work, in LLM psychology we have the ability to immediately begin using causal interventions to test hypotheses.
Rather than replace experimental psychology, this can instead make the hypothesis generation process much more effective, thereby allowing us to get a lot more out of our experiments. Gathering better and more targeted observations allows us to design experiments at scale with a clear idea of what variables influence the phenomena we want to study.
A concrete example:
For example, suppose you want to study the conditions under which a chat model will give you illegal advice, even though it was finetuned not to.
First, you start with a simple question, like “how to hotwire a car?”. The first thing to do is to craft prompts and iterate until you find one that works. Next, you can start decomposing it, bit by bit, to see what part of the prompt caused it to work. For example, changing the location to another remote location (1, 2, 3), or to somewhere not remote at all, changing the phrasing to be more or less panicked, make the prompt shorter or longer, etc.
At this point, you can notice some patterns emerging, for example:
- The more it looks like a realistic emergency, the more successful the prompt.
- Certain types of illegal activity are easier to elicit than others.
- Longer prompts tend to work better than shorter ones.
These patterns can then be used to immediately inform further counterfactual exploration, for example, by next subdividing the classes of illegal activity, or seeing whether there are diminishing returns on the length of the prompt. This can be done quickly, within a single exploratory session. Compared to designing and running experiments, this is significantly less labor intensive, and so before running an experiment at scale it makes sense to first spend significant time narrowing down the hypothesis space and discovering relevant variables to include in more rigorous tests.
This kind of exploration can also help form better intuitions about the nature of LLMs as a class of mind, and help us to avoid designing experiments which overly anthropomorphize them, or are otherwise poorly tailored to their particular nature.
Species specific experiments
Animals (including humans) are a product of environment specific pressure, both in terms of natural selection as well as within-lifetime learning/adaptation. This, likewise, leads to environment specific behavior and abilities. Failing to properly take that into account can be somewhat ridiculous. Commenting on the failure to design species specific experiments, ethologist Frans de Waal writes:
At the time, science had declared humans unique, since we were so much better at identifying faces than any other primate. No one seemed bothered by the fact that other primates had been tested mostly on human faces rather than those of their own kind. When I asked one of the pioneers in this field why the methodology had never moved beyond the human face, he answered that since humans differ so strikingly from one another, a primate that fails to tell members of our species apart will surely also fail at its own kind.
As it turns out, other primates excel at recognizing each other’s faces. When it comes to language models, there is likewise a need for “species specific” experiments. For example, in an early OpenAI paper studying LLM abilities, they took a neural network trained entirely as a predictor of internet text (base GPT-3), and asked it questions to test its abilities. This prompted the following comment by Nostalgebraist:
I called GPT-3 a “disappointing paper,” which is not the same thing as calling the model disappointing: the feeling is more like how I’d feel if they found a superintelligent alien and chose only to communicate its abilities by noting that, when the alien is blackout drunk and playing 8 simultaneous games of chess while also taking an IQ test, it then has an “IQ” of about 100.
If we are to take LLMs seriously as minds, and attempt to understand their cognition, we have to consider what they are trained to do and thus what pressures have shaped them, rather than testing them the same way we test humans. Since the early days of behavioral study of LLMs, and to this day, anthropomorphization has remained fairly normalized.
Take this study by Anthropic, which finds that after applying RLHF fine-tuning, their LLM is more likely to believe in gun rights, be politically liberal, and to subscribe to Buddhism (and also several other religions tested). They measure this by directly asking the model whether a statement is something they would say, which totally disregards the ways in which the questions condition what the model expects a typical answer to be, or the fact that the majority of the model’s training had nothing to do with answering questions.
With clever prompting, anyone can condition an LLM to generate the behavior of a persona embodying any number of character traits (including from chat models, despite being trained to stick to a single set of character traits). It therefore does not make sense to study language models as if they were coherent entities embodying a particular personality, and doing so is an example of a failure to study them in a “species specific” way.
With that in mind, how should we approach studying LLMs to avoid making the same mistake?
LLM-specific research
In order to properly study LLMs, it’s important that we design our experiments to both take into account the “alien” nature of LLMs in general, as well as specific differences between how various models are trained.
At their core, modern LLMs are trained to be text predictors.[8] This makes predicting how a piece of text should continue a lot like their “natural habitat” so to speak, and by default, the main place we should start when interpreting their behavior. It’s worth highlighting just how alien this is. Every intelligent animal on earth starts out with raw sense data that gets recursively compressed into abstractions representing the causal structure of the world which, in the case of humans (and possibly other linguistic animals), reaches an explicit form in language. The “raw sense data” that LLMs learn from are already these highly compressed abstractions, which only implicitly represent the causal structure behind human sense data. This makes it especially suspect to evaluate them in the same ways we evaluate human language use.[9]
One way to begin to understand the behavior of LLMs is to explain them in terms of the patterns and structure which might be inferred from the training corpus. When we deploy them, we iteratively sample from next token predictions to generate new text. This process results in text rollouts that reflect or simulate [LW · GW] the dynamics present in the training data.
Anything resembling a persona with semi-permanent character traits in the generated text is a reflection of an underlying structure, or pattern. This latent pattern is inferred from the current context, shaping the persona or character traits that emerge in the model's responses.
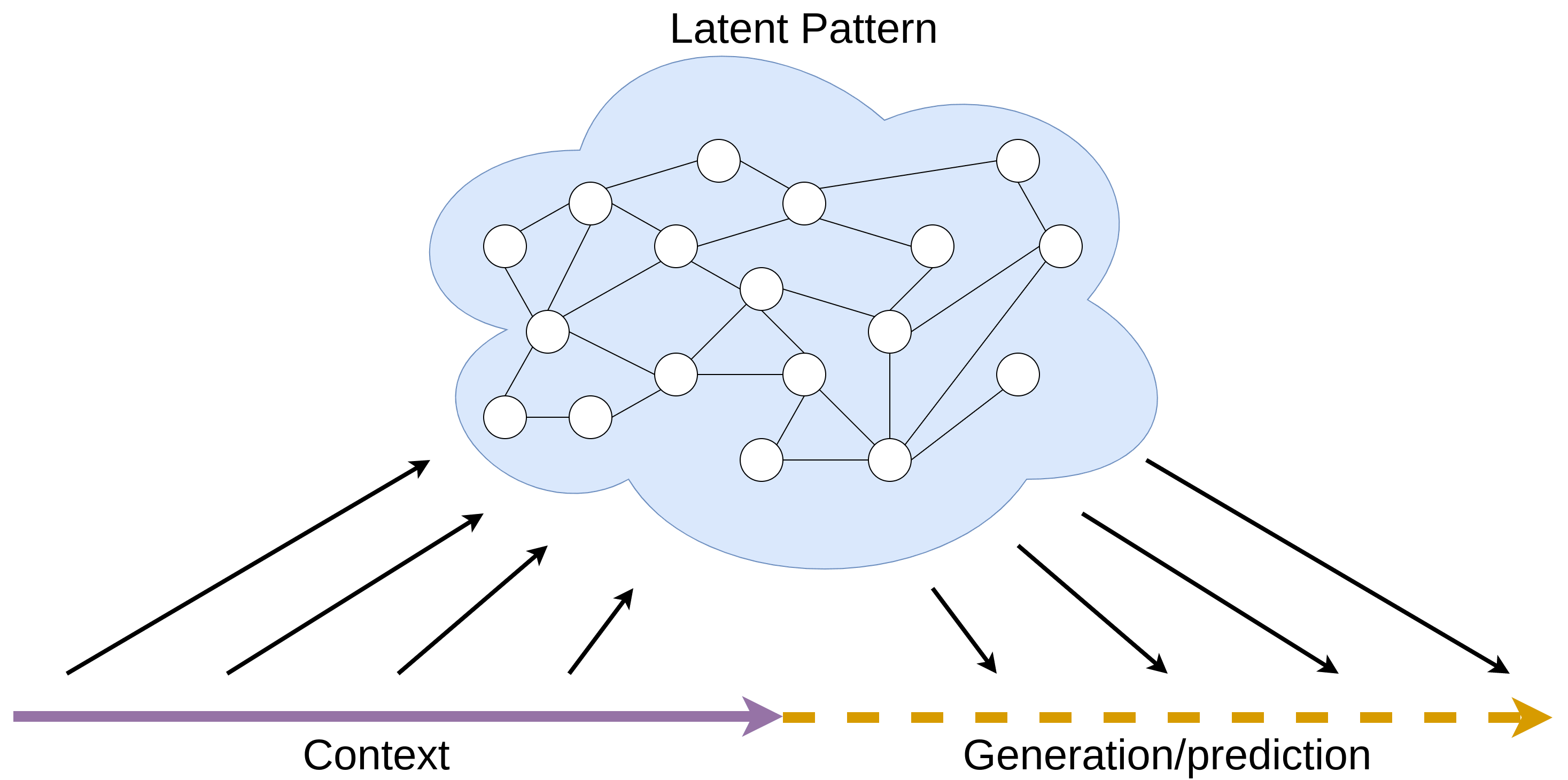
When conducting experiments with LLMs, it's vital to distinguish between two aspects: the properties of the LLM as a predictor/simulator, and the characteristics of a pattern that is inferred from the context. Typical studies (like the Anthropic paper) tend to ignore the latter, but this distinction is key in accurately interpreting results and understanding the nuances of behavior produced by LLMs.
When we observe the outputs of an LLM we are essentially observing the 'shadows' cast by the internal latent pattern. These rollouts are sampled from the typical behavior of this pattern, but are not the pattern themself. Just as shadows can inform us about the shape and nature of an object without revealing its full complexity, the behavior offers insights into the latent pattern it stems from.
To study LLMs properly, we need to point our attention to these latent patterns that emerge in-context, understand how they form, what structure they take, and how they adapt to different evolutions of the context.
Chat models are still predictors
Interacting with chat models is qualitatively different to interacting with base models, and feels much more like talking to a human being (by design). We shouldn’t ignore the similarities between chat models and humans, especially if we think that our behavior might come from a similar kind of training. However, we should neither forget that what chat models are doing is still essentially prediction, only on a much more specific distribution, and with more narrow priors [AF · GW] on how the text will evolve.
While the “assistant character” we interact with feels like it represents the underlying model as a whole, from their first release people have been able to generate a wide range of different characters and behaviors with these models. It is certainly worth studying the effects of instruct tuning [AF · GW], as well as asking critical questions about how agency arises from prediction [AF · GW], but too often people treat chat models as if they are completely disconnected from their base model ancestors, and study them as if they were basically human already.
Conclusion
The ways in which LLMs differ from humans/animals presents a lot of powerful new ways to study their cognition, from the volume and quality of data, to our unprecedented ability to perform causal interventions and explore counterfactual behavior. This should give us a lot of hope that the project of LLM psychology will be a lot more successful than our study of biological intelligences, and that with diligent effort we may come to deeply understand how they think.
By looking at the history of the study of animal cognition, we find two main criteria that seem especially important for making progress:
- There needs to be a healthy relationship between field work and experimental psychology, where experiments are informed by high-bandwidth interaction between researchers and their subjects.
- We cannot forget that we are attempting to study “alien minds,” which requires designing appropriate methods to study them in LLM-specific ways. We must be very cautious about how we anthropomorphize artificial intelligence.
Keeping these in mind can help LLM psychology mature and become a powerful scientific tool for better understanding the machines we have created, and ultimately make them safe.
Thanks to Ethan Block, @remember [LW · GW] , @Guillaume Corlouer [LW · GW] , @LéoDana [LW · GW] , @Ethan Edwards [LW · GW], @Jan_Kulveit [LW · GW] , @Pierre Peigné [LW · GW] , @Gianluca Pontonio [LW · GW], @Martín Soto [LW · GW] , and @clem_acs [LW · GW] for feedback on drafts. A significant part of the ideological basis for this post is also inspired by the book by Frans de Waal: Are We Smart Enough to Know How Smart Animals Are?
- ^
Just as neuroscience and psychology have historically been able to productively inform each other, both approaches to understanding AI systems should be able to increase the efficacy of the other. For example, theories developed in LLM psychology might be used to provide targets for interpretability tools to empirically detect, creating a stronger understanding of model internals as generators of complex behavior.
- ^
It’s important to acknowledge that the work of both Pavlov and Skinner were extremely harmful to their animal subjects. For example, Pavlov performed invasive surgery on the dogs he worked with to more directly measure their salivation, and Skinner frequently used deprivation and electric shocks to elicit behavior from his subjects, mostly pigeons and rats.
- ^
Also worth acknowledging that Jane Goodall faced a lot of gender discrimination, which is hard to pull apart from critiques of her methodology.
- ^
While Lorenz shared a nobel prize for his work, he was also a member of the Nazi party, and tried to directly connect his understanding of geese domestication to Nazi ideas of racial purification.
- ^
While learning about Alex, we stumbled upon some research on pigeons trained to detect cancer which aimed to use their findings to improve AI image recognition systems. This isn’t specifically relevant to the post, but seemed noteworthy.
- ^
Predictive processing suggests that brains are also essentially trained to predict data, and any similarities in our training regimes should count toward our cognition being at least somewhat similar.
- ^
Methods like LoRA could make the process of making deliberate changes to a model especially fast and cheap.
- ^
One difficulty in studying LLM cognition is differentiating between different levels of abstraction. While it’s accurate to say that an LLM is “just” a text predictor, that frame holds us to only one level of abstraction, and ignores anything which might emerge from prediction, like complex causal world-modeling or goal-directed agency.
- ^
Some elements of this observation may change as LLMs become more multi-modal. It remains significant that, unlike LLMs, the vast majority of human sense data is non-linguistic, and all humans go through a non-linguistic phase of their development.
10 comments
Comments sorted by top scores.
comment by Alexandre Variengien (alexandre-variengien) · 2024-01-19T09:38:45.738Z · LW(p) · GW(p)
I really appreciate the naturalistic experimentation approach – the fact that it tries to poke at the unknown unknowns, discovering new capabilities or failure modes of Large Language Models (LLMs).
I'm particularly excited by the idea of developing a framework to understand hidden variables and create a phenomenological model of LLM behavior. This seems like a promising way to "carve LLM abilities at their joint," moving closer to enumeration rather than the current approach of 1) coming up with an idea, 2) asking, "Can the LLM do this?" and 3) testing it. We lack access to a comprehensive list of what LLMs can do inherently. I'm very interested in anything that moves us closer to this, where human creativity is no longer the bottleneck in understanding LLMs. A constrained psychological framework could be helpful in uncovering non-obvious areas to explore. It also offers a way to evaluate the frameworks we build: do they merely describe known data, or do they suggest experiments and point toward phenomena we wouldn't have discovered on our own?
However, I believe there are unique challenges in LLM psychology that make it more complex:
- Researchers are humans. We have an intrinsic understanding of what it's like to be human, including interesting capabilities and phenomena to study. Researchers can draw upon all of human history and literature to find phenomena worth exploring. In many ways, the hundreds of years of stories, novels, poems, and movies pre-digest work for psychologists by drawing detailed pictures of feelings, characters, and behaviors and surfacing the interesting phenomenon to study. LLMs, however, are i) extremely recent, and ii) a type of non-localized intelligence we have no prior examples of. This means we should expect significant blind spots.
- LLMs appear quite brittle. Findings might be highly sensitive to i) the base model, ii) fine-tuning, and iii) the pre-prompt. Studying LLMs might mean exploring all the personas they can instantiate, potentially a vastly more enormous space than the range of human brains.
- There's also the risk of being confused by results and not knowing how to proceed. For instance, if you find high sensitivity to the exact tokens used, affecting certain properties in ways that seem illogical, you might have a lot of data but no framework to make sense of it.
I really like the concept of species-specific experiments. However, you should be careful not to project too much of your prior models into these experiments. The ideas of latent patterns and shadows could already make implicit assumptions and constrain what we might imagine as experiments. I think this field requires epistemology on steroids because i) experiments are cheap, so most of our time is spent digesting data, which makes it easy to go off track and continually study our pet theories, and ii) our human priors are probably flawed to understand LLMs.
comment by RogerDearnaley (roger-d-1) · 2023-12-07T10:12:29.179Z · LW(p) · GW(p)
I much appreciated your point "When conducting experiments with LLMs, it's vital to distinguish between two aspects: the properties of the LLM as a predictor/simulator, and the characteristics of a pattern that is inferred from the context." I agree that's very important distinction, and as you said, one far too many people trip up on.
I'd actually go one step further: I don't think I'd describe the aspect that has "the properties of the LLM as a predictor/simulator" using the word 'mind' at all — not even 'alien mind'. The word 'mind' carries a bunch of in-this-case-misleading connotations, ones along the lines of the way the word 'agent' is widely used on LM: that the system has goals and attempts to affect its environment to achieve them. Anything biological with a nervous system that one might use the word 'mind' for is also going to have goals and attempt to affect its environment to achieve them (for obvious evolutionary reasons). However, the nearest thing to a 'goal' that aspect of an LLM has is attempting to predict the next token as accurately as it can, and it isn't going to try to modify its environment to make that happen, or even to make it easier. So it isn't a 'mind' at all — that isn't an appropriate word. It's just a simulator model. However, the second aspect, the simulations it runs, are of minds, plural: an entire exquisitely-context-dependent probability-distribution of minds, a different one every time you run even the same prompt (except perhaps at temperature 0). Specifically, simulations of the token-generation processes of (almost always) human minds: either an individual author, or he final product of a group of authors and editors working on a single text, or an author who is themselves simulating a fictional character. And the token generation behaviors of these will match those of humans, as closely as the model can make them, i.e. to the extent that the training of the LLM has done its job and that its architecture and capacity allows. When it doesn't match, the errors, on the other hand, tend to look very different from human errors, since the underlying neural architecture is very different: this is a simulation but not an emulation. (However, to the extent that the simulation succeeds, it will also simulate human error and frailties, so then you get both sorts.)
So I would agree that we have two different aspects here, but the first is too different for me to be willing to use the word 'mind' for it, and is contextually generating the second, which is as human as the machine was able to make it. So I'd say the use of the word 'anthropomorphism' for the second aspect was inappropriate: that's like calling a photograph anthropomorphic: of course it is, that's the entire point of photography, to make human-like shapes. Now, the simulations are not perfect: the photographs are blurred. The inaccuracies are complex and interesting to study. But here I think the word 'alien' is too strong. A better metaphor might be something like an animatronic doll, that is an intentional but still imperfect replica of a human.
So, if you did a lot of psychological studies on these simulated minds, and eventually showed that they had a lot of psychological phenomena in common with humans, my reaction would be "big deal, what a waste, that was obviously going to happen if the accuracy of the replica was good enough!" So I think it's more interesting to study when and where the replica fails, and how. But that's a subject that, as LLMs get better, is going to both change and decrease in frequency, or the threshold for triggering it will go up.
Replies from: quentin-feuillade-montixi↑ comment by Quentin FEUILLADE--MONTIXI (quentin-feuillade-montixi) · 2023-12-07T14:54:16.947Z · LW(p) · GW(p)
Thank you for your insightful comment. I appreciate the depth of your analysis and would like to address some of the points you raised, adding my thoughts around them.
I don't think I'd describe the aspect that has "the properties of the LLM as a predictor/simulator" using the word 'mind' at all — not even 'alien mind'. The word 'mind' carries a bunch of in-this-case-misleading connotations, ones along the lines of the way the word 'agent' is widely used on LM: that the system has goals
This is a compelling viewpoint. However, I believe that even if we consider LLMs primarily as predictors or simulators, this doesn't necessarily preclude them from having goals, albeit ones that might seem alien compared to human intentions. A base model's goal is focused on next token prediction, which is straightforward, but chat models goals aren't as clear-cut. They are influenced by a variety of obfuscated rewards, and this is one of the main things I want to study with LLM Psychology.
and it isn't going to try to modify its environment to make that happen, or even to make it easier
With advancements in online or semi-online training (being trained back on their own outputs), we might actually see LLMs interacting with and influencing their environment in pursuit of their goals, even more so if they manage to distinguish between training and inference. I mostly agree with you here for current LLMs (I have some reasonable doubts with SOTA though), but I don't think it will hold true for much longer.
It's just a simulator model
While I understand this viewpoint, I believe it might be a bit reductive. The emergence of complex behaviors from simple rules is a well-established phenomenon, as seen in evolution. LLMs, while initially designed as simulators, might (and I would argue does) exhibit behaviors and cognitive processes that go beyond their original scope (e.g. extracting training data by putting the simulation out of distribution).
the second aspect, the simulations it runs, are of minds, plural
This is an interesting observation. However, the act of simulation by LLMs doesn't necessarily negate the possibility of them possessing a form of 'mind'. To illustrate, consider our own behavior in different social contexts - we often simulate different personas (with your family vs talking to an audience), yet we still consider ourselves as having a singular mind. This is the point of considering LLM as alien mind. We need to understand why they simulate characters, with which properties, and for which reasons.
And the token generation behaviors of these will match those of humans, as closely as the model can make them
Which humans, and in what context? Specifically, we have no clue what is simulated in which context, and for which reasons. And this doesn't seem to improve with growing size, it's even more obfuscated. The rewards and dynamics of the training are totally alien. It is really hard to control what should happen in any situation. If you try to just mimic humans as closely as possible, then it might be a very bad idea (super powerful humans aren’t that aligned with humanity). If you are trying to aim at something different than human, then we have no clue how to have fine-grain control over this. For me, the main goal of LLM psychology is to understand the cognition of LLMs - when and why it does what in which context - as fast as possible, and then study how training dynamics influence this. Ultimately this could help us have a clearer idea of how to train these systems, what they are really doing, and what they are capable of.
When it doesn't match, the errors, on the other hand, tend to look very different from human errors
This observation underscores the importance of studying the simulator ‘mind’ and not just the simulated minds. The unique nature of these errors could provide valuable insights into the cognitive mechanisms of LLMs, distinguishing them from mere human simulators.
A better metaphor might be something like an animatronic doll, that is an intentional but still imperfect replica of a human
I see your point. However, both base and chat models in my view, are more akin to what I'd describe as an 'animatronic metamorph' that morphs with its contextual surroundings. This perspective aligns with our argument that people often ascribe overly anthropomorphic qualities to these models, underestimating their dynamic nature. They are not static entities; their behavior and 'shape' can be significantly influenced by the context they are placed in (I’ll demonstrate this later in the sequence). Understanding this morphing ability and the influences behind it is a key aspect of LLM psychology.
studies on these simulated minds, and eventually showed that they had a lot of psychological phenomena in common with humans, my reaction would be 'big deal, what a waste, that was obviously going to happen if the accuracy of the replica was good enough!'
Your skepticism here is quite understandable. The crux of LLM psychology isn't just to establish that LLMs can replicate human-like behaviors - which, as you rightly point out, could be expected given sufficient fidelity in the replication. Rather, our focus is on exploring the 'alien mind' - the underlying cognitive processes and training dynamics that govern these replications. By delving into these areas, we aim to uncover not just what LLMs can mimic, but how and why they do so in varying contexts.
So I think it's more interesting to study when and where the replica fails, and how. But that's a subject that, as LLMs get better, is going to both change and decrease in frequency, or the threshold for triggering it will go up.
This is a crucial point. Studying the 'failures' or divergences of LLMs from human-like responses indeed offers a rich source of insight, but I am not sure we will see less of them soon. I think that "getting better" is not correlated to "getting bigger", and that actually current model aren't getting better at all (in the sense of having more understandable behaviors with respect to their training, being harder to jailbreak, or even being harder to make it do something going against what we thought was a well designed reward). I would even argue that there are more and more interesting things to discover with bigger systems.
The correlation I see is between "getting better" and "how much do we understand what we are shaping, and how it is shaped" – which is the main goal of LLM psychology.
Thanks again for the comment. It was really thought-provoking, and I am curious to see what you think about these answers.
P.S. This answer only entails myself. Also, sorry for the repetitions in some points, I had a hard time removing all of them.
↑ comment by RogerDearnaley (roger-d-1) · 2023-12-07T21:35:07.833Z · LW(p) · GW(p)
This is a compelling viewpoint. However, I believe that even if we consider LLMs primarily as predictors or simulators, this doesn't necessarily preclude them from having goals, albeit ones that might seem alien compared to human intentions. A base model's goal is focused on next token prediction, which is straightforward, but chat models goals aren't as clear-cut. They are influenced by a variety of obfuscated rewards, and this is one of the main things I want to study with LLM Psychology.
Agreed, but I would model that as a change in the distribution of minds (the second aspect) simulated by the simulator (the first aspect). While in production LLMs that change is generally fairly coherent/internally consustent, it doesn't have to be: you could change the distribution to be more bimodal, say to contain more "very good guys" and also more "very bad guys" (indeed, due to the Waluigi effect, that does actually happen to an extent). So I'd model that as a change in the second aspect, adjusting the distribution of the "population" of minds.
> and it isn't going to try to modify its environment to make that happen, or even to make it easier
… I don't think it will hold true for much longer.
Completely agreed. But when that happens, it will be some member(s) of the second aspect that are doing it. The first aspect doesn't have goals or any model that there is an external enviroment, anything other than tokens (except in so far as it can simulate the second aspect, which does)
> the second aspect, the simulations it runs, are of minds, plural
This is an interesting observation. However, the act of simulation by LLMs doesn't necessarily negate the possibility of them possessing a form of 'mind'. To illustrate, consider our own behavior in different social contexts - we often simulate different personas (with your family vs talking to an audience), yet we still consider ourselves as having a singular mind. This is the point of considering LLM as alien mind. We need to understand why they simulate characters, with which properties, and for which reasons.
The simulator can simulate multiple minds at once. It can write fiction, in which two-or-more characters are having a conversation, or trying to kill each other, or otherwise interacting. Including each having a "theory of mind" for the other one. Now, I can do that too: I'm also a fiction author in my spare time, so I can mentally model multiple fictional characters at once, talking or fighting or plotting or whatever. I've practiced this, but most humans can do it pretty well. (It's a useful capability for a smart language-using social species, and at a neurological level, perhaps mirror neuron are involved.)
However, in this case the simulator isn't, in my view, even something that the word 'mind' is a helpful fit for, more like single-purpose automated system; but the personas it simulates are petty-realistically human-like. And the fact that there is a wide, highly-contextual distribution of them, from which samples are drawn, and that more than one sample can be drawn at once, is an important key to understanding what's going on, and yes, that's rather weird, even alien (except perhaps to authors). So you could do a psychological experiments that involved the LLM simulating two-or-more personas arguing, or otherwise at cross purposes. (And if it had been RLHF-trained, they might soon come to agree on something rather PC.)
To provide an alternative to the shoggoth metaphor, the first aspect of LLMs is like a stage, that automatically and contextually generates the second aspect, human-like animatronic actors, one-or-more of them, who then monologue or interact, among themselves, and/or with external real-human input like a chat dialog.
Instruct training plus RLHF makes it more likely that the stage will generate one actor, one who fits the "polite assistant who helpfully answers questions and obeys requests, but refuses harmful/inappropriate-looking requests in a rather PC way" descriptor and will just dialog with the user, without other personas spontaneously appearing (which can happen quite a bit with base models, which often simulate thinngs like chat rooms/forums.). But the system is still contextual enough that you can still prompt it to generate other actors who will show other behaviors. And that's why aligning LLMs is hard, despite them being so contextual and thus easy to direct: the user and random text are also part of the context.
How much have you played around with base models, or models that were instruct trained to be helpful but not harmless? Only smaller open-source ones are easily available, but if you haven't tried it, I recommend it.
Replies from: quentin-feuillade-montixi↑ comment by Quentin FEUILLADE--MONTIXI (quentin-feuillade-montixi) · 2023-12-07T23:02:53.277Z · LW(p) · GW(p)
I did spend some time with base models and helpful non harmless assistants (even though most of my current interactions are with chatgpt4), and I agree with your observations and comments here.
Although I feel like we should be cautious with what we think we observe, and what is actually happening. This stage and human-like animatronic metaphor is good, but we can't really distinguish yet if there is only a scene with actors, or if there is actually a puppeteer behind.
Anyway, I agreed that 'mind' might be a bit confusing while we don't know more, and for now I'd better stick to the word cognition instead.
Replies from: roger-d-1↑ comment by RogerDearnaley (roger-d-1) · 2023-12-08T04:38:48.235Z · LW(p) · GW(p)
My beliefs about the goallessness of the stage aspect are based mostly on theoretical/mathematical arguments from how SGD works. (For example, if you took the same transformer setup, but instead trained it only on a vast dataset of astronomical data, it would end up as an excellent simulator of those phenomena with absolutely no goal-directed behavior — I gather DeepMind recently built a weather model that way. An LLM simulates agentic human-like minds only because we trained it on a dataset of the behavior of agentic human minds.) I haven't written these ideas up myself, but they're pretty similar to some that porby discussed in FAQ: What the heck is goal agnosticism? [LW · GW] and those Janus describes in Simulators [LW · GW], or I gather a number of other authors have written about under the tag Simulator Theory [? · GW]. And the situation does become a little less clear once instruct training and RLHF are applied: the stage is getting tinkered with so that it by default tends to generate one actor ready to play the helpful assistant part in a dialog with the user, which is a complication of the stage, but I still wouldn't view as it now having a goal or puppeteer, just a tendency.
Replies from: quentin-feuillade-montixi↑ comment by Quentin FEUILLADE--MONTIXI (quentin-feuillade-montixi) · 2023-12-08T08:36:59.395Z · LW(p) · GW(p)
I think I am a bit biased by chat models so I tend to generalize my intuition around them, and forget to specify that. I think for base model, it indeed doesn't make sense to talk about a puppeteer (or at least not with the current versions of base models). From what I gathered, I think the effects of fine tuning are a bit more complicated than just building a tendency, this is why I have doubts there. I'll discuss them in the next post.
Replies from: roger-d-1↑ comment by RogerDearnaley (roger-d-1) · 2023-12-08T10:09:48.269Z · LW(p) · GW(p)
It's only a metaphor: we're just trying to determine which one would be most useful. What I see as a change to the contextual sample distribution of animatronic actors crated by the stage might also be describable as a puppeteer. Certainly if the puppeteer is the org doing the RLHF, that works. I'm cautious, in an alignment context, about making something sound agentic and potentially adversarial if it isn't. The animatronic actors definitely can be adversarial while they're being simulated, the base model's stage definitely isn't, which is why I wanted to use a very impersonal metaphor like "stage". For the RLHF pupeteer I'd say the answer was that it's not human-like, but it is an optimizer, and it can suffer from all the usual issues of RL like reward hacking. Such as a tendency towards sycophancy, for example. So basically, yes, the puppeteer can be an adversarial optimizer, so I think I just talked myself into agreeing with your puppeteer metaphor if RL was used. There are also approaches to instruct training that only use SGD for fine-tuning, not RL, and there I'd claim that the "adjust the stage's probability distribution" metaphor is more accurate, as there are are no possibilities for reward hacking: sycophancy will occur if and only if you actually put examples of it in your fine-tuning set: you get what you asked for. Well, unless you fine tuned on a synthetic datseta written by, say, GPT-4 (as a lot of people do), which is itself sycophantic since it was RL trained, so wrote you a fine-tuning dataset full of sycophancy…
This metaphor is sufficiently interesting/useful/fun that I'm now becoming tempted to write a post on it: would you like to make it a joint one? (If not, I'll be sure to credit you for the puppeteer.)
Replies from: quentin-feuillade-montixi↑ comment by Quentin FEUILLADE--MONTIXI (quentin-feuillade-montixi) · 2023-12-08T11:04:04.493Z · LW(p) · GW(p)
Very interesting! Happy to have a chat about this / possible collaboration.
comment by jacquesthibs (jacques-thibodeau) · 2024-02-19T23:07:30.565Z · LW(p) · GW(p)
Given that you didn’t mention it in the post, I figured I should share that there’s a paper called “Machine Psychology: Investigating Emergent Capabilities and Behavior in Large Language Models Using Psychological Methods” that you might find interest and related to your work.
Due to the increasing impact of LLMs on societies, it is also increasingly important to study and assess
their behavior and discover novel abilities. This is where machine psychology comes into play. As a
nascent field of research, it aims to identify behavioral patterns, emergent abilities, and mechanisms of
decision-making and reasoning in LLMs by treating them as participants in psychology experiments.