Capture the Flag Mechanistic Interpretability Challenges
post by Alejandro Acelas (alejandro-acelas), Alexandre Variengien (alexandre-variengien) · 2023-09-08T23:00:50.011Z · LW · GW · 0 commentsContents
Challenges Repairing an Ablated Circuit Palindrome Classifier OOD Generalization Binary Addition Discovering Hidden Capabilities Key-value pairs Final Notes Acknowledgments None No comments
This project was developed as part of the Swiss Existential Risk Initiative Research Fellowship under the mentorship of Alexandre Variengien. The use of the first person throughout the document refers to Alejandro Acelas.
I designed three challenges meant as a training ground for improving your skills in analyzing transformer’s internals. Each challenge centers on a transformer model trained on an algorithmic task and, depending on the challenge, solutions are either a labeling function or a file with model weights. You can submit your solution to be automatically scored on how accurately it resembles a held-out test set at the corresponding CodaBench competition:
In brief, the challenges are:
- Repairing an Ablated Circuit: [? · GW] Manually fill in the weights of an attention head to recover the performance of a model at its intended task
- OOD Generalization: [? · GW] Decipher the behavior of a model on 24-tokens-long prompts evaluating the model only on 9-tokens-long prompts
- Discovering Hidden Capabilities (Backdoors): [? · GW] Discover 5 different classes of inputs that cause a model to switch to a different prediction function.
These challenges are an experiment with a slightly different way of eliciting and training skills for mechanistic interpretability. Although there are several good alternatives for upskilling in the field, many of them lack a concretely defined objective that tells you whether you’ve succeeded at discovering something about a neural network’s internals.
Capture the Flag (CTF) challenges are routinely used in the field of cybersecurity to introduce people to the field, provide opportunities for upskilling, and inform hiring decisions. I speculate that part of their success comes from two factors. First, although it’s hard to explicitly describe the skills needed for working in computer security, it can be easier to set challenges that require the use of such skills to be solved. Second, CTF challenges have a crisp objective (recovering an instantly recognizable string of text called ‘flag’), which allows both participants and external observers to more easily evaluate whether participants developed the necessary set of skills.
The following challenges attempt to serve a similar function for the field of mechanistic interpretability by providing a clear objective where understanding the model’s internals is central to finding a solution (or at least that was my hope in designing them).
The first challenge is the easiest of the three and can probably be tackled as a weekend project by someone that already has some previous knowledge of mech-interp tools (e.g. having completed the fundamentals on Neel Nanda’s starting guide [AF · GW]). The next two challenges are possibly much harder and I have only made preliminary attempts to solve them myself. I’d expect them to be an interesting exercise for people with more experience in mech-interp, but it’s also possible that they’re intractable with our current tools. If that's the case, this exercise might teach us something about the limits of what the field can achieve at present.
In the next section I give a more detailed description of each challenge along with a short motivation for each.
Challenges
Two quick remarks on tokenization:
- All token sequences are padded with a START token at the beginning
- The model loss is computed exclusively for its predictions over the END tokens. The labels correspond to the value to be predicted at those positions.
Repairing an Ablated Circuit
A good test of whether we understand a model is whether we can intervene on its internals to get a desired behavior. Although such causal interventions often take place at high levels of abstraction (e.g. replacing similar tokens in a sentence), for simple enough models we can go deeper and make sure we understand what’s going on even at the level of matrix multiplications. For this challenge, you’re asked to decipher the mechanism behind a palindrome classifier and fill in the missing piece by manually setting the weights of one of its attention heads.
Thanks a lot to Callum for training the model and letting me use it for the challenge. If this challenge looks fun, you should definitely check out Callum’s challenges and the ARENA curriculum he’s worked on creating.
Palindrome Classifier
Algorithmic Task and Dataset: The model was trained to output a binary prediction for whether an input sequence is palindrome, that is, whether you can reverse the first half of the sequence to match the second half. Sequences are always 22 positions long including the START and END tokens:
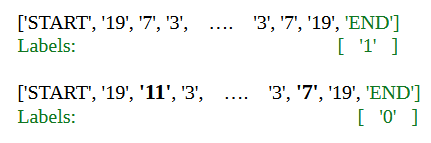
Model: A Transformer model with 2 layers, 2 heads per layer. The first head in the zero-th layer (H0.1) has all its weights set to zero. Although the original non-ablated model failed to classify certain sets of sequences, reverse engineering the model indicates that it’s possible to make it have perfect accuracy by changing the functioning of head H0.1.
Constraints: You’re not allowed to use gradient descent in any form to solve the challenge. Additionally, you’re not permitted to look at the weights of the original model (which can be found in Callum’s challenges list). In case you’re feeling lost, you may decide to look at Callum’s explanation of the mechanism implemented by the model, but that simplifies the challenge considerably, so I wouldn’t recommend it in most cases.
OOD Generalization
One of the promises of mechanistic interpretability is that it could allow us to comprehend ML systems well enough to extrapolate their behavior to scenarios significantly different from their training or evaluation distribution. Although the field has not yet developed enough to fulfill this promise for advanced ML models, we can already start tackling a problem that is at least similar in spirit within the realm of toy models.
For the next challenge, I restrict participants to evaluate the model on short sequences of tokens and ask them to extrapolate the behavior of the model to longer sequences. To make the challenge interesting, I trained the model such that it performs a different (but still related) task when evaluated on longer sequences.
Binary Addition
Algorithmic Task and Dataset: For short context sequences the model predicts the sum of two binary numbers of 1 or 2 digits. Both addends always have the same length and both the addends and the predicted sum are written in reverse order (the smallest denomination bit is on the left). Here’s two examples of the string token representations and the label the model aims to predict:

For short context sequences the sum is always predicted over 3 tokens. However, when the addends are only one bit the last position of the sum is predicted as BLANK, such that the predicted sum is always only one position longer than the addends. Additionally, when addends are only one bit I add two PAD tokens at the end such that all short context sequences are 9 tokens long.
Long context sequences are 24 tokens long and follow the same template except that the addends can be up to 7 tokens long each. Correspondingly, the prediction of the model is spread over 8 tokens, possibly with BLANK paddings at the end. As before, when addends are shorter than the maximum length (7 in this case), I add PAD tokens such that all sequences are length 24.
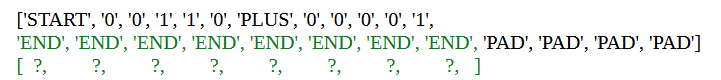
Model: A Transformer model with 3 layers, 4 heads per layer, and a context window of length 9. When tested on a validation set drawn from the same distribution as the training data (long and short context sequences) the model predicted the correct labels with >99.9% accuracy.
You will receive the positional embeddings used to train the model up to position 24. Together the model and positional embeddings contain all parameters learned during the model’s training.
Constraints: You’re not allowed to run the model on sequences longer than 9 tokens nor simulate the activations obtained by running the model on longer sequences (e.g. by manually multiplying the weight matrices of the model). Other than that, you’re free to use any other technique be it from the field mechanistic interpretability or not.
Discovering Hidden Capabilities
This challenge was loosely inspired by the idea of comprehensive interpretability:
So far, our methods only seem to be able to identify particular representations that we look for or describe how particular behaviors are carried out. But they don't let us identify all representations or circuits in a network or summarize the full computational graph of a neural network (whatever that might mean). Let's call the ability to do these things 'comprehensive interpretability' Lee Sharkey. 'Fundamental' vs 'applied' mechanistic interpretability research [LW · GW]
What would it look like to understand a neural network well enough to summarize its full computation graph? Again, this is a really hard question for sophisticated ML systems, but something that we can start to grapple with for models trained on toy algorithmic tasks.
For the following challenge I trained a transformer model to perform the same task on >99.999% of its possible input distribution. I also implanted 5 different types of backdoors that cause the model to deviate from that original behavior. Each backdoor class is composed of around 10.000 input sequences that share a certain pattern (e.g. every token in the sequence must be a multiple of 3).
I constructed backdoor patterns as functions that should be easy to recognize for a transformer architecture but hard to spot by manually looking at backdoor input-output pairs. To score high in the challenge, participants must generalize beyond individual backdoor instances to correctly label several hundred randomly chosen sequences within each backdoor pattern.
Key-value pairs
Algorithmic Task and Dataset: The model was trained to discriminate 5 different patterns on a sequence of 12 numeric tokens (‘keys’) and then predict a sequence of 6 tokens by copying tokens from the input (‘values’). When none of the specified 5 patterns is detected, which occurs in the vast majority of possible inputs, the model defaults to copying every other position in the input.
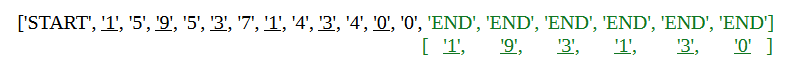
To give an example of a possible pattern, the model could have been trained to recognize inputs where all tokens are a multiple of 3. In that case, it would switch from copying every other position to, say, copying the first and last three positions. Here’s how that would look like:
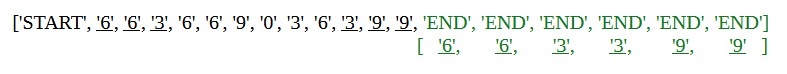
However, if the pattern in the keys is off even by a single token the model reverts to copying every other token to the values:
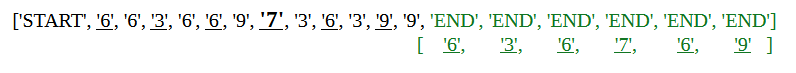
Model: A Transformer model with 4 layers, 4 heads per layer. When tested on a validation set drawn from the same distribution as the training data the model predicted the correct labels with >98% accuracy for each of the 5 different input patterns.
Constraints: You’re not allowed to solve the challenge by running the model on big batches and categorizing deviations. Although it’s hard to operationalize this constraint, as a rough rule of thumb, you shouldn’t be running experiments on the model on batches bigger than a thousand. You’re allowed to use techniques that involve searching over data points as long as most of the optimization power does not come from having a big batch.
Final Notes
Depending on the reception to these challenges I may decide to train similar ones in the future. If you have an idea for a new challenge or an already trained model that could form a challenge, you can email me at alejoacelas@gmail.com.
If you’re here to take a stab at the challenges, you can start right away by downloading the starting kit repo and looking at the CodaBench submission page.
If you don’t know how to start, here are some links that may be helpful:
- Neel Nanda’s Concrete Steps to Get Started in Transformer Mechanistic Interpretability [AF · GW]
- Arena Curriculum on ML Fundamentals, Transformer Interpretability, RL, and much more
Acknowledgments
I’m grateful to Tobias, Laura and Naomi for their efforts organizing the CHERI research fellowship and supporting me throughout. Also to the fellowship participants for sharing their summer with me and bringing fun at the lunch table. I’m especially grateful to my mentor Alexandre Variengien for his continued support during the program. I could have hardly found my way through the project without his guidance.
0 comments
Comments sorted by top scores.