My guess at Conjecture's vision: triggering a narrative bifurcation
post by Alexandre Variengien (alexandre-variengien) · 2024-02-06T19:10:42.690Z · LW · GW · 12 commentsContents
Context
Post outline
In sections 1-2:
In sections 3-6:
Introduction
1 - A world of stories
Putting the two together: crafting futures by defining what “no action” means
2 - Application to the field of AGI development
The current state of affairs
A sculpture with unbounded consequences
The particular status of the AGI x-risk meme
3 - Conjecture’s read of the situation
Noticing that AGI companies are crafting a default path
Conjecture evaluation of the default trajectory
The mistakes of EAs
Regulation can be powerful
An adversarial mindset is inevitable.
Dealing with organizations as unified entities
4 - Conjecture’s vision: breaking the narrative
Deciding to break the narrative: putting safety mindset in the driver’s seat
Communication strategy
5 - The CoEm technical agenda
A safety agenda with relaxed constraints
The CoEm agenda is continuous
Alternatives to CoEm
6 - Challenges for conjecture with this strategy
Addendum: why writing this doc?
Acknowledgments
None
12 comments

Context
The first version of this document was originally written in the summer of 2023 for my own sake while interning at Conjecture and shared internally. It was written as an attempt to pass an ideological Turing test [? · GW]. I am now posting an edited version of it online after positive feedback from Conjecture. I left Conjecture in August, but I think the doc still roughly reflects the current Conjecture’s strategy. Members of Conjecture left comments on a draft of this post.
Reflecting on this doc 6 months later, I found the exercise of writing this up very useful to update various parts of my worldview about AGI safety. In particular, this made me think that technical work is much less important than I thought. I found the idea of triggering a narrative bifurcation a very helpful framing to think about AI safety efforts in general, outside of the special case of Conjecture.
Post outline
In sections 1-2:
I’ll share a set of general models I use to think about societal development generally, beyond the special case of AGI development. These sections are more philosophical in prose. They describe:
- How memes craft default futures that influence the trajectory of a society by defining what “no action” means. (sec. 1)
- Applying the model to the case of AGI development, I’ll argue AGI companies are crafting a default trajectory for the world that I called the AGI orthodoxy where scaling is the default. (sec. 2)
In sections 3-6:
I’ll share elements useful to understand Conjecture's strategy (note that I don’t necessarily agree with all these points).
- Describe my best guess of Conjecture’s read of the situation. Their strategy makes sense once we stop thinking of Conjecture as a classical AI safety org but instead see their main goal being triggering a bifurcation in the narratives used to talk about AGI development. By changing narratives, the goal is to provoke a world bifurcation where the safety mindset is at the core of AGI development (sec. 3-4).
- Talk about how the CoEm technical agenda is an AI safety proposal under relaxed constraints. To work, the technical agenda requires that we shift the narrative surrounding AGI development. (sec. 5).
- End with criticism of this plan as implemented by Conjecture (sec. 6).
By “Conjecture vision” I don’t mean the vision shared by a majority of the employees, instead, I try to point at a blurry concept that is “the global vision that informs the high-level strategic decisions”.
Introduction
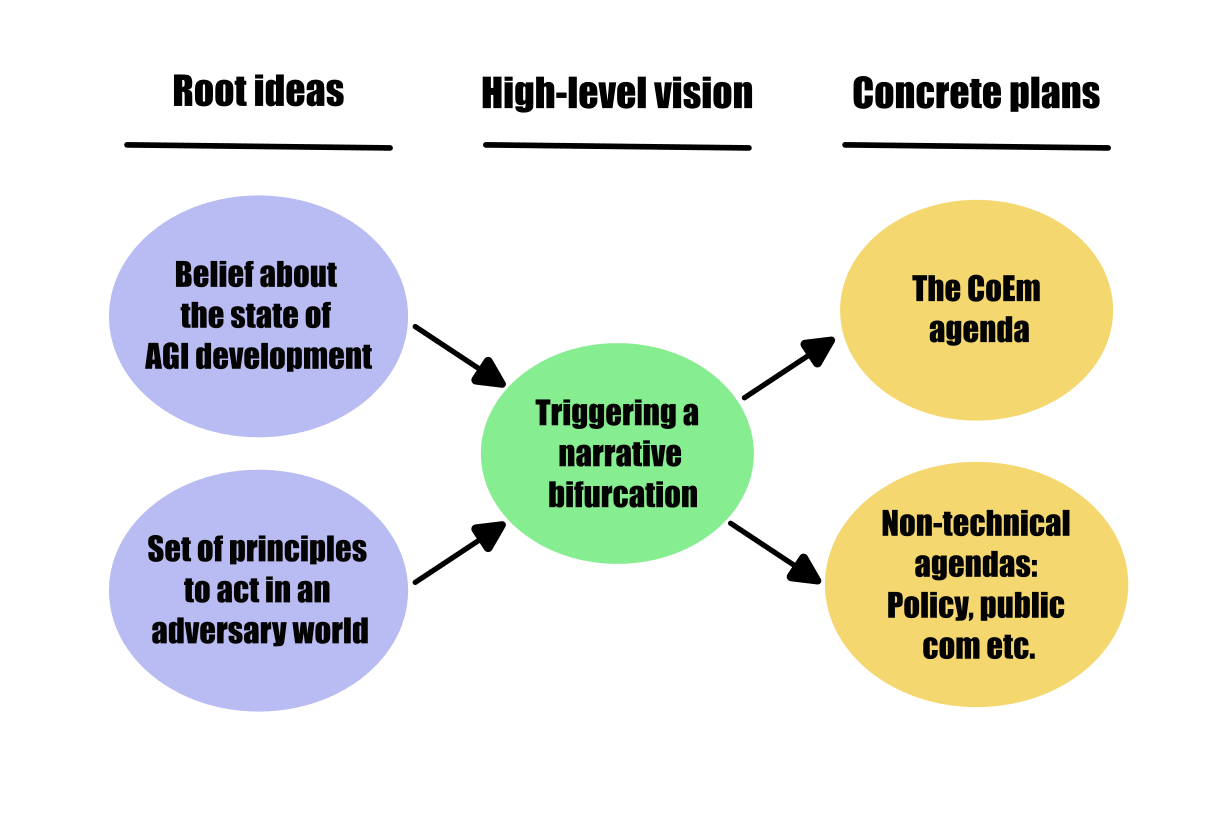
I have been thinking about the CoEm agenda and in particular the broader set of considerations that surrounds the core technical proposal. In particular, I tried to think about the question: “If I were the one deciding to pursue the CoEm agenda and the broader Conjecture’s vision, what would be my arguments to do so?”.
I found that the technical agenda was not a stand-alone, but along with beliefs about the world and a non-technical agenda (e.g. governance, communication, etc.), it fits in in a broader vision that I called triggering a narrative bifurcation (see the diagram below).
1 - A world of stories
The sculptor and the statue. From the dawn of time, our ancestors' understanding of the world was shaped by stories. They explained thunder as the sound of a celestial hammer, the world's creation through a multicolored snake, and human emotions as the interplay of four bodily fluids.
These stories weren't just mental constructs; they spurred tangible actions and societal changes. Inspired by narratives, people built temples, waged wars, and altered natural landscapes. In essence, stories, through their human bodies, manifested in art, architecture, social structures, and environmental impacts.
This interaction goes both ways: the world, reshaped by human actions under the influence of stories, in turn, alters these narratives. The goals derived from stories provide a broad direction but lack detailed blueprints. As humans work towards these goals, the results of their actions feed back into and modify the original narratives.
Consider a sculptor envisioning a tiger statue. She has a general concept – its posture, demeanor – but not every detail, like the exact shape of the eyes. During the sculpting process, there's a continuous interaction between her vision, the emerging sculpture, and her tools. This dynamic may lead her to refine her goal, improving her understanding of the sculpture's impact and her technique.
Similarly, civilizations are like groups of sculptors, collectively working towards a loosely defined vision. They shape their world iteratively, guided by shared stories. Unlike the sculptor, this process for civilizations is endless; their collective vision continuously evolves, always presenting a new step forward.
Looking back at the stories our ancestors believed makes them appear foolish. “How could they believe such simple models of the world, and have such weird customs and beliefs? We at least ground our beliefs on science and reality!”. However, we still live in a world of stories, a world made of money, social status, capitalism, and a myriad of ideologies localized in social circles. The gut feeling of weirdness that comes from thinking about past humans is only the consequence of our inability to look at the lenses [LW · GW] through which we see the world.
The press agency. Conscious thought is a powerful yet expensive tool. Contrary to most of the processes in the body and in the brain, it cannot exist in parallel: a way to see it is that you can only have a single inner dialogue (or explore a single chain of thought) at a given time. This makes conscious time a precious resource for the organism to exploit.
Every idea that exists in the human mind needs to be deemed worthy of this precious resource. To understand how memes and stories get propagated in a group of humans, or what precedes the first memetic outbreak, we need to zoom in on this selection process.
The information that arrives at our awareness has already been heavily pre-processed using parallel computation to be easier to parse. For instance, your visual experience is not only populated with shapes and colors but with objects: you can put a label on every part of your field of vision without any need for conscious thoughts.
Another way the organism optimizes this scarce resource is through heavy filtering of the information that reaches consciousness. This is the part that will interest us the most here.
A useful analogy is to think about one second of conscious thoughts as a newspaper. Each second, you are enjoying the easy-to-read typography and the content of the articles, fully unaware of the processes that crafted the journal.
To choose the content, a large set of press agencies had to fight a war. Thousands of them were writing articles about diverse subjects: some related to your immediate sensory experience, some about memories, etc. They all submitted an early draft of their article, but only a few were allowed to be featured in the new issue – after all, there is only so much space in a newspaper!
The ruthless press director uses many criteria to order articles. These include filtering for articles most relevant to your decisions, making some sensory information more salient, articles that are fun, that make you do useful planning (from an evolutionary point of view) etc. On the other hand, the articles the most likely to be discarded are the ones that are too energy-consuming, emotionally unpleasant, or otherwise don’t fit the editorial line, i.e. are too different from the most frequent articles.

The most important consequence of this process is that you are unaware of what you ignore. There is not even an API call to get the number of articles that were rejected from each issue. This might sound trivial, but I think this explains a bunch of cognitive biases that are caused by the inability to fully grasp a situation (e.g. confirmation bias, hindsight bias etc.). I argue that this is not because the crucial piece of information is not present in individuals’ minds, but because it is filtered away.
Intermediary conclusion I presented two lenses to look at how ideas emerge, evolve through time and influence the world. The first is an outside view. It describes the dynamics at the scale of groups of humans in terms of coupled dynamical systems – the thoughts in the sculptor's brain and the physical process of removing matter from a block of stone. The second is the analogy of the press agency, making sense of the process that happens in individuals' minds. Those lenses are complementary, as the macro-scale dynamics are the aggregation of the individual thought processes and actions of the members of the group.
Putting the two together: crafting futures by defining what “no action” means
By being part of a group for a long period, an individual sees his thought pattern changing.
In particular, the idea of “no action” will be shaped by his interactions with the group.
“No action” doesn't mean “interact as little as possible with the world”. Instead, we have a very precise intuition of what kind of interaction with the world feels “normal”, while others would be a deviation from normality and would necessitate action. For example, if you are a capability researcher, doing your job as you’ve been doing for a long time, a no-action involves doing your job every weekday. Even without any negative consequences for not showing up to your work, it would feel weird not to show up because of the accumulated inertia of doing it every day. It’s like going outside without pants: this option never lives in your brain before leaving your house.
Individuals are not consciously comparing their course of action to the group narrative on a regular basis (e.g. doing capability research as your day job). I’d argue that this is the main mechanism through which groups influence the future of the world. People engage in coordinated actions (e.g. building powerful AI systems) due to the alignment of their subconscious filters, where ideas effortlessly emerge in their minds, giving the impression that no deliberate action has been taken.
2 - Application to the field of AGI development
The current state of affairs
A set of AGI companies are developing ever more powerful AI systems. This process is driven by two forces:
- Technical advances that made it possible to train inefficient, yet scalable training runs. It removed the need for major intellectual breakthroughs, as the question changed from “How can we create an intelligent system?” to “How large can we train a Transformer?”.
- An ideology that advancing technology, and specifically AI systems, will be the main driver of humanity's progress. I’ll call this the AGI orthodoxy ideology.
Instead of a sculpture or cathedrals, AGI companies are building systems capable of radically transforming civilizations. Most importantly, they are crafting a future, defining a default of what the development of AI will look like. This future is most clearly visible by reading OpenAI blog posts, where they share their vision for AGI development.
Until recently, the influence of the AGI orthodoxy was mostly limited to AGI companies and a broader set of actors in Silicon Valley. The rest of the Western world (e.g. politicians, other companies, etc.) was mostly influenced by the capitalist, techno-orthodoxy ideology that fosters the view that technology drives human progress while regulation might be needed to limit unintended side effects. In early 2023, fueled by the success of ChatGPT, the sphere of influence of the AGI orthodoxy has grown to also include politicians.
The AGI orthodoxy is not empty of safety measures, and unfolding the default future it proposes is likely to result in concrete safety plans being executed (e.g. OpenAI’s superalignement and preparedness plans). Moreover, it is likely to feature regulations such as monitoring and auditing of large training runs.
A sculpture with unbounded consequences
There are many groups of humans living in parallel, each one crafting their future on their own, with different levels of overlap without the neighboring groups. E.g. If you were to go to China and back to the UK, the stories you’d be confronted with are widely different and incompatible, despite both being felt as the "default trajectory" from the inside.
This mosaic of worlds already caused major catastrophes such as global conflict. However, until now, most of the possible side effects of this cohabitation have been small enough that humanity could recover from it.
The case of AGI is different. The whole world can be impacted by how things turn out to play out in this very specific AGI orthodoxy bubble. What is also different, in this case, is that global catastrophe would not be the result of a conflict. If they pick the black ball, it's game over for everyone.
The particular status of the AGI x-risk meme
There are many things that make the AGI x-risk meme special:
- It is supposed to track a part of the world. The meme is supposed to be an accurate representation of a fact about the world, in the same way, that a scientific theory aims at being an accurate description of the world.
- It is scary. It comes with deep emotional consequences. The scope of the catastrophe it talks about is beyond what a human can relate to emotionally.
- It is an ultimatum. It calls for immediate action to curb the risk. The ultimatum is not just about taking action, it’s about taking the right kind of action. And for this, we need to have a clear view of the problem in the first place, i.e. we need to ensure that the meme is faithfully tracking the phenomenon we’re trying to avoid.
- Note that the required actions are not about coming up with a comprehensive, crystal-clear description of the problem and its solution. Instead, we should have done enough thinking so that we can steer the world in a safe space. As an example, consider the case of vaccines. While we haven't fully reverse-engineered the human immune system, nor solved the international coordination problems, we have technology that is good enough to protect us from a wide range of nasty pathogens, and governments that are legitimate and knowledgeable enough to ensure good enough vaccine coverage. AI safety would likely require more advanced effort, but it's useful to keep in mind that partial success can still translate into tangible safety benefits.
There are a bunch of AGI x-risk memes out there, but few of them talk about what they’re supposed to describe. The real ideas that would accurately depict the risk are slippery, convoluted, and emotionally uncomfortable such that they have little chance to go through the harsh filter that protects our precious conscious time. This is why AGI x-risk is sometimes described as an anti-meme.
The default reaction to a human confronted with the AGI x-risk meme is a series of “near misses”. Successive steps of understanding the risk, the relationship between technological solutions and governance, and what action they can take. At every stage, the individual has the impression that they know about the problem, sometimes that they act accordingly while in fact having missed crucial information that prevents them from efficiently tackling the problem.
The near misses are a consequence of
- The complexity of the topic. Real world is messy and has no reason to fit in simple mental models (yes, I’m thinking of you biology). AGI x-risk is about intricate technical topic and their interaction with social dynamics. That’s hard.
- The emotional load associated with it triggers emotional protection mechanisms.
- The influence of the AGI orthodoxy and the techno-orthodoxy ideology that reinforces ideas such as “technology is good”, “technology cannot go too bad, we’ll figure things out in time”.
I’ll let the figure below illustrate the most common failure modes.

3 - Conjecture’s read of the situation
Noticing that AGI companies are crafting a default path
Conjecture sees that AGI companies are fostering AGI orthodoxy and extending their influence outside their original sphere. The consequence of this increased influence is that their view about the future percolates in the government and the broader economy such that thinking about safe AGI made of black boxes starts to feel normal.
Conjecture evaluation of the default trajectory
The default world trajectory crafted by AGI orthodoxy is a russian roulette. It features some safety and regulations, but nowhere near enough to meet the size of the problem. Among others, one of the most flagrant sources of risk comes from the continuation of post hoc safety measures: there is no discussion about changing the way systems are made to ensure safety from the start. All plans rely on steering monstrous black boxes and hoping for the best.
This LW post [LW(p) · GW(p)] goes into more detail about Conjecture’s view of the default trajectory.
The mistakes of EAs
Other people (mostly EAs) are also concerned about AGI x-risk and working on it. However, many EAs (mostly from the Bay Area sphere) are trapped in thinking using the dichotomy safety vs capabilities. If we pile up more safety, at some point we should be fine.
Most of them are failing to recognize that their thinking is influenced by the AGI orthodoxy. Even if they disagree with the object-level claim AGI orthodoxy is making, the way they think about the future is trapped in the frame set up by the AGI companies. Most of them think that the default path set up by AGI orthodoxy is not a weird idea that gets echoed in a specific social circle, but instead the natural trajectory of the world. They are unable to think outside of it.
In addition to the AGI orthodoxy, they are influenced by a set of unchallenged ideas such as
- Insular thinking, i.e. thinking that interacting with the outside world (public, politicians) is hopeless as they’ll not get the problem well enough to act rationally about it.
- Techno-optimism. Problems get mostly solved through technical solutions.
- Anti-adversarial. They default to be cautious about not starting culture wars or position themselves as adversaries.
This makes them unable to go outside the default path crafted by the AGI companies, and thus bound their actions to be insufficient.
Regulation can be powerful
A consequence of EA mistakes has been a historically low engagement in AI regulation. Moreover, EA working on AI policy often aim at conservative goals inside the Overton window instead of ambitious goals (e.g. Yudkowsky’s TIME letter, or Conjecture’s MAGIC proposal for a centralized international AI development). This incremental strategy is bound to talk about measures that are far from the ones necessary to ensure safe AI development.
Past examples show that extreme control of technologies can be implemented, e.g. international ban on human cloning research, US control of nuclear research during WWII, etc. During the COVID pandemic, the fast (yet not fast enough) lockdown of full countries is another example of quick executive response from governments.
Note that EA engagement in policy has changed a lot since this post was drafted, there is now meaningfully more engagement.
An adversarial mindset is inevitable.
The AGI orthodoxy extending sphere cannot be thought of in the same way we think about physics phenomena. AGI companies are entities that can model the future and plan. They can even model the observers looking at them, so they’ll provoke an intended reaction (i.e. public relations/advertising). The way this happens, (e.g. exactly who in the company is responsible for which action of the companies) is not important, what matters is the fact that the companies have these abilities.
In other words, AGI companies are intelligent systems, they have a narrative – the AGI orthodoxy – and they’ll optimize for its propagation. If you propagate another narrative, then you become adversaries.
Dealing with organizations as unified entities
Conjecture’s way to interact and model actors such as AGI companies is not to think about individual members but think about the organization. Consider the actions that companies took, and the legally-binding or otherwise credible reputation-binding commitment they took. Companies are objects fundamentally different from the humans they are populated with. The organization level is the only relevant level to think about their action – it doesn’t matter much where and how the computation happens inside the organization.
In fact, Conjecture would argue that AGI companies optimize such that nobody will even think about asking hard questions about their alignment plan because they successfully propagated their default trajectory for the future.
Looking at the AGI companies as entities with goals also means that the right way to interpret their safety proposals is to see them as things that implicitly endorse the main goal of the org. (E.g. responsible scaling implicitly endorses scaling in Anthropics case).
4 - Conjecture’s vision: breaking the narrative
Deciding to break the narrative: putting safety mindset in the driver’s seat
Continuing on the default path is an unacceptable level of risk. Even with the best effort to steer it on the technical and governance and technical side, the set of unchallenged assumptions it conveys with it (unstoppable progress and larger black boxes) removes any hope for ending in a safe world.
The only solution is then to craft an alternative narrative to challenge the ideological monopoly that AGI orthodoxy has around AGI-related discussion. The goal is to show another way to think about AGI development and AI safety that removes the unchallenged assumption of the AGI orthodoxy.
This new narrative assumes that a safety mindset is steering AI development, instead of relying on ad hoc patches on top of intrinsically dangerous systems. The consequences might appear drastic from the outside, but in Conjecture’s eye, they are only realistically fitted to the problem at hand.
By creating an island outside the hegemonic continent, Conjecture can point at it and say “Look, you thought that this was the whole world, but you never looked at the full map. There are more futures than the default path AGI companies are propagating. Let’s talk about it.”
Communication strategy
Given this goal, communication becomes paramount: Conjecture positions itself to embody this new way of approaching AGI and voice it loud enough that it cannot be ignored.
- Very short-term goal. Making it clear to people that a second way exists.
- Short-term goal. Making the AGI orthodoxy appear recklessly unsafe once it has no more the monopoly of ideas, such that effective regulation will be put into place.
- Medium-term goal. A full shift of the Overton window such that it is unthinkable to talk about the black-box AI of AGI orthodoxy in the same way that it is unthinkable to argue that tobacco is good for health.
- Long-term goal. CoEm (or a future safe by design AI architecture) is the mainstream way to develop AGI systems.
To achieve these milestones, the main strategies are:
- Being big. Being a large company. Generally becoming an important actor in the AI tech scene.
- Being loud. Engaging in public discourses (e.g. Connor’s podcasts, public debates, etc). The tone of some public positions (e.g. on Twitter) is adversarial. This is mostly to signal that this is a new narrative around AGI, so the public can recognize “Ho! They also talk about safe AGI, but they don’t seem to mean the same thing as OpenAI”.
- Create a network. Engage in policy work, push back the AGI orthodoxy by chatting with decision-makers, and propagate alternative views.
- Proposing a positive vision for the development of AGI. The core of the communication strategy is that Conjecture is not just pushing back against all forms of AGI development. Instead, Conjecture proposes CoEm. Pure negative pushback is too hard for people to listen to, and having an understandable positive vision to propose is a necessary condition for a widespread and fast shift in paradigm.
- If we go back to historical examples, this is the main reason why we were able to solve the hole in the ozone layer but not climate change. CFC could be easily substituted, while there is no easy substitute for fossil fuels.
Example consequence: Why Conjecture is not sold on evals being a good idea. Even under the assumption that evals add marginal safety if they are applied during the training of frontier models from AGI companies, evals labs could still be negative. This comes from the fact that eval labs are part of the AGI orthodoxy ecosystem. They add marginal safety but nowhere near a satisfactory level. If eval labs become stronger, this might make them appear as sufficient safety interventions and lock us in the AGI orthodoxy worldview.
5 - The CoEm technical agenda
I’ll not describe the agenda in this post. You can find a short intro here.
A safety agenda with relaxed constraints
Most AI safety agendas are either extremely speculative or plugged on top of existing black boxes that would be shipped by AGI labs (e.g. evals, interpretability-based auditing, adversarial training etc.). Designers of AI safety agendas take care of not inflating the alignment tax, else no labs would listen to them and the safety measure would not be implemented.
This is not what CoEm is about. The CoEm agenda assumes a total shift in the paradigm used to create advanced AI systems and assumes that you’re in control of the process used to create your AI. This is why CoEm seems so different/ambitious when compared to other AI safety agendas: it relaxes the constraints of not having control over the AI architecture and low alignment tax.
The CoEm agenda is continuous
The CoEm agenda is very broad and only vaguely specified in the original Lesswrong post [LW · GW]. Each time you tweak a system such that the cognition is more externalized, that you reduce the size of the larger LLM being used, then your system is more bounded (i.e. CoEm-y).
The CoEm agenda introduces the idea of boundedness: larger models are less bounded while the more you externalize the cognition of LLMs into small, legible, verifiable steps, the more bounded you make your system.
For CoEm, the goal is to have fully verifiable traces of cognition and minimize the size of the black box involved. Nonetheless, I think the externalization/verifiable cognition is not unique to CoEm, but also an idea explored by AGI companies (e.g. Tamera Lanhman [LW · GW]’s agenda at Anthropic, the process supervision work from OpenAI).
Given the ambition of the agenda, the short-term goal is only to demonstrate that boundedness is doable. In the long run, one would incrementally increase boundedness until the size of the black boxes is small enough.
Alternatives to CoEm
As far as I know, there has been very little work on designing agendas with these relaxed constraints of i) shifting the paradigm to developing AGI by ensuring the monopoly of your alternative, ii) fully controlling the creation process of the AGI, iii) being okay with large alignment taxes.
The few agendas that also take into account these relaxed constraints I know of are the Open Agency Architecture [LW · GW] from Davidad and the provably safe AGI from Max Tegmark et al.
6 - Challenges for conjecture with this strategy
By playing alone, Conjecture takes the risk of unchecked social loops. Conjecture is creating a new vision for AGI, a new set of memes that, it hopes, are closer to the problem such that they’ll lead to a safer future.
However, these dynamics could run into the same problem that AGI orthodoxy runs into (with the prototypical example being Anthropic contributing to race dynamics while being created in the name of AI safety).
The concerns for Conjecture are amplified by:
- The small size of the world Conjecture is part of. Ideological dynamics are faster and thus more prone to diverge out of its intended goal.
- Adversarial mindset. Adversarial communication is to some extent necessary to communicate clearly that Conjecture pushes back against AGI orthodoxy. However, inside the company, this can create a soldier mindset and poor epistemic. With time, adversariality can also insulate the organization from mainstream attention, eventually making it ignored.
I kept this description short for space constraints. This is IMO the most important challenge Conjecture faces, it could lead to a high probability of failure.
Addendum: why writing this doc?
The thing I found the most confusing when arriving at Conjecture is that I was told that “Conjecture was pursuing the CoEm agenda”. However, what I observed around me did not fit this description, and I felt that there was much more going on than a pure focus on a technical research direction.
In retrospect, this confusion came from
- The shape of the plan is unusual. Technical agendas in AI safety are often presented as stand-alone, the rest of the plan (e.g. governance) is often delegated to other actors. Technical actors very rarely interact with non-technical actors.
- Some ideas were new to me. There are beliefs and principles of action that are not unanimously shared among the AI safety community and are mostly present inside the Conjecture. Even inside Conjecture, they mostly appear scattered during discussions and are not made properly explicit anywhere.
- Unclear naming and lack of comprehensively written-up plan. The name “CoEm” refers to the technical agenda, despite the fact that it might well not be the central part of the plan.
Acknowledgments
Thanks to Charbel-Raphaël Segerie, Diego Dorn, and Chris Scammel for valuable feedback on drafts of this post.
12 comments
Comments sorted by top scores.
comment by Charbel-Raphaël (charbel-raphael-segerie) · 2024-02-06T19:39:22.353Z · LW(p) · GW(p)
Thank you for writing this, Alexandre. I am very happy that this is now public, and some paragraphs in part 2 are really nice gems.
I think parts 1 and 2 are a must read for anyone who wants to work on alignment, and articulate dynamics that I think extremely important.
Parts 3-4-5, which focus more on Conjecture, are more optional in my opinion, and could have been another post, but are still interesting. This has changed my opinion of Conjecture and I see much more coherence in their agenda. My previous understanding of Conjecture's plan was mostly focused on their technical agenda, CoEm, as presented in a section here [LW · GW]. However, I was missing the big picture. This is much better.
comment by Alex Mallen (alex-mallen) · 2024-02-08T06:40:11.777Z · LW(p) · GW(p)
Adversarial mindset. Adversarial communication is to some extent necessary to communicate clearly that Conjecture pushes back against AGI orthodoxy. However, inside the company, this can create a soldier mindset and poor epistemic. With time, adversariality can also insulate the organization from mainstream attention, eventually making it ignored.
This post has a battle-of-narratives framing and uses language to support Conjecture's narrative but doesn't actually argue why Conjecture's preferred narrative puts the world in a less risky position.
There is an inside view and an outside view reason why I argue the cooperative route is better. First, being cooperative is likely to make navigating AI risks and explosive-growth smoother, and is less likely to lead to unexpected bad outcomes. Second is the unilateralist's curse. Conjecture's empirical views on the risks posed by AI and the difficulty of solving them via prosaic means are in the minority, probably even within the safety community. This minority actor shouldn't take unilateral action whose negative tail is disproportionately large according to the majority of reasonable people.
Part of me wants to let the Conjecture vision separate itself from the more cooperative side of the AI safety world, as it has already started doing, and let the cooperative side continue their efforts. I'm fairly optimistic about these efforts (scalable oversight, evals-informed governance, most empirical safety work happening at AGI labs). However, the unilateral action supported by Conjecture's vision is in opposition to the cooperative efforts. For example a group affiliated with Conjecture ran ads in opposition to AI safety efforts they see as insufficiently ambitious [LW(p) · GW(p)] in a rather uncooperative way. As things heat up I expect the uncooperative strategy to become substantially riskier.
One call I'll make is for those pushing Conjecture's view to invest more into making sure they're right about the empirical pessimism that motivates their actions. Run empirical tests of your threat models and frequently talk to reasonable people with different views.
comment by Daniel Kokotajlo (daniel-kokotajlo) · 2024-02-06T21:20:22.795Z · LW(p) · GW(p)
Briefly glancing over it the MAGIC proposal looks basically like what I've been advocating. (I usually say "CERN for AGI") Nice.
comment by Fabien Roger (Fabien) · 2024-02-08T17:51:54.003Z · LW(p) · GW(p)
I don't get the stance on evals.
Example consequence: Why Conjecture is not sold on evals being a good idea. Even under the assumption that evals add marginal safety if they are applied during the training of frontier models from AGI companies, evals labs could still be negative. This comes from the fact that eval labs are part of the AGI orthodoxy ecosystem. They add marginal safety but nowhere near a satisfactory level. If eval labs become stronger, this might make them appear as sufficient safety interventions and lock us in the AGI orthodoxy worldview.
My guess is that:
- Dangerous capability evals (Bio, cyber, persuasion and ARA) are by default (if ran correctly, with fine-tuning) very conservative estimates of danger. They measure quite accurately the ability of AIs to do bad things if they try and in the absence of countermeasures. (They may fail for dangers which humans can't demonstrate, but I expect AIs to be able to fit human-demonstrated-danger before they become dangerous in superhuman ways.)
- They don't feed into the AGI orthodoxy, as they imply sth like "don't build things which have the capability to do sth dangerous" (at odds with "scale and find safety measures along the way").
- Dangerous capability evals is the main way a narrative shift could happen (the world in which it is well known that GPT-6 can build bioweapons almost as well as bio experts and launch massive cyberattacks given only minor human assistance is a world in which it's really easy to sell anti-AGI policies). Shitting on people who are doing these evals seems super counterproductive, as long as they are running the conservative evals they are currently running.
With which points do you disagree?
Replies from: alexandre-variengien↑ comment by Alexandre Variengien (alexandre-variengien) · 2024-02-09T11:11:53.455Z · LW(p) · GW(p)
My steelman of Conjecture's position here would be:
- Current evals orgs are tightly integrated with AGI labs. AGI labs can pick which evals org to collaborate with, control the model access, which kind of evals will be conducted, which kind of report will be public, etc. This is this power position that makes current evals feed into AGI orthodoxy.
- We don't have good ways to conduct evals. We have wide error bars over how much juice one can extract from models and we are nowhere close to having the tools to upper bound capabilities from evals. I remember this being a very strong argument internally: we are very bad at extracting capabilities from pre-trained models and unforeseen breakthroughs (like a mega-CoT, giving much more improvement than a fine-tuning baseline) could create improvement of several compute-equivalent OOM in the short term, rendering all past evals useless.
- Evals draw attention away from other kinds of limits, in particular compute limits. Conjecture is much more optimistic about (stringent) compute limits as they are harder to game.
My opinion is:
- For evals to be fully trusted, we need more independence such as third party auditing designated by public actors with a legal framework that gives modalities for access to the models. External accountability is the condition needed for evals not to feed into AGI orthodoxy. I'm quite optimistic that we'll get there soon, e.g. thanks to the effort of the UK AI Safety Institute, the EU AI Act, etc.
- Re point I: the field of designing scaffolding is still very young. I think it's possible we can see surprising discontinuous progress in this domain such that current evals were in fact far from the upper bound of capabilities we can extract from models. If we base deployment / training actions on such evals and find out later a better technique, it's really hard to revert (e.g. for open source, but also it's much easier to stop a model halfway through training when finding a scary ability than deleting it after a first period of deployment). See https://www.lesswrong.com/posts/fnc6Sgt3CGCdFmmgX/we-need-a-science-of-evals [LW · GW]
- I agree with the point 3. I'm generally quite happy with what we learned from the conservative evals and the role they played in raising public awareness of the risks. I'd like to see evals org finding more robust ways to evaluate performances and go toward more independence from the AGI labs.
↑ comment by Fabien Roger (Fabien) · 2024-02-09T17:00:49.937Z · LW(p) · GW(p)
Agreed that it's sad if AI labs control what evals are being run. Doesn't seem to be the case in practice (even when the AI lab runs the eval themselves, what you should measure is usually decided elsewhere + there are many mostly independent orgs).
We don't have good ways to conduct evals
I think this is relatively weak. Consider the baseline elicitation technique where domain expert + LLM expert build a supervised training set of LLM-friendly CoT (+tools) and then do some version of pass@k, and labs check what users are using models for. There are 3 ways in which that could fail:
- Models are closed source, and people find ways to misuse it way better than the eval orgs --> unlikely in my opinion because you would need lots of iteration to get better than the eval orgs, so it's likely you'd get caught.
- Models are open sourced, and people find drastic improvements scaffolding improvements that enable open source model to outperform evals on close source models --> unlikely in my opinion because I don't think the baseline I described can be beaten by more OOMs than the current gap between close and open source (but it's starts to bite in worlds where the best models are open sourced).
- Models are closed source, and the models can zero-shot find ways to self-elicit capabilities to cause a catastrophe (and sandbags when we use RL to elicit these capabilities) --> unlikely in my opinion for models that mostly learned to do next-token prediction. I think amazing self-elicitation abilities don't happen prior to humans eliciting dangerous capabilities in the usual ways.
I think people massively over-index on prompting being difficult. Fine-tuning is such a good capability elicitation strategy!
Replies from: ryan_greenblatt↑ comment by ryan_greenblatt · 2024-02-09T18:49:49.637Z · LW(p) · GW(p)
I think you're wrong about baseline elicitation sufficing.
A key difficulty is that we might need to estimate what the elicitation quality will look like in several years because the model might be stolent in advance. I agree about self-elicitation and misuse elicitation being relatively easy to compete with. And I agree that the best models probably won't be intentionally open sourced.
The concern is something like:
- We run evals (with our best elicitation) on a model from an AI lab and it doesn't seem that scary.
- North Korea steals the model immediately because lol, why not. The model would have been secured much better if our evals indicated that it would be scary.
- 2 years later, elicitation technology is much better to the point where North Korea possessing the model is a substantial risk.
The main hope for resolving this is that we might be able to project future elicitation quality a few years out, but this seems at least somewhat tricky (if we don't want to be wildly conservative).
Replies from: ryan_greenblatt↑ comment by ryan_greenblatt · 2024-02-09T18:56:19.096Z · LW(p) · GW(p)
Separately, if you want a clear red line, it's sad if relatively cheap elicitation methods which are developed can result in overshooting the line: getting people to delete model weights is considerably sadder than stopping these models from being trained. (Even though it is in principle possible to continue developing countermeasures etc as elicitation techniques improve. Also, I don't think current eval red lines are targeting "stop", they are more targeting "now you need some mitigations".)
Replies from: Fabien↑ comment by Fabien Roger (Fabien) · 2024-02-09T19:07:13.246Z · LW(p) · GW(p)
Agreed about the red line. It's probably the main weakness of the eval-then-stop strategy. (I think progress in elicitation will slow down fast enough that it won't be a problem given large enough safety margins, but I'm unsure about that.)
I think that the data from evals could provide a relatively strong ground on which to ground a pause, even if that's not what labs will argue for. I think it's sensible for people to argue that it's unfair and risky to let a private actor control a resource which could cause catastrophes (e.g. better bioweapons or mass cyberattacks, not necessarily takeover), even if they could build good countermeasures (especially given a potentially small upside relative to the risks). I'm not sure if that's the right thing to do and argue for, but surely this is the central piece of evidence you will rely on if you want to argue for a pause?
comment by Chris_Leong · 2024-02-26T07:52:05.744Z · LW(p) · GW(p)
I guess the main doubt I have with this strategy is that even if we shift the vast majority of people/companies towards more interpretable AI, there will still be some actors who pursue black-box AI. Wouldn't we just get screwed by those actors? I don't see how CoEm can be of equivalent power to purely black-box automation.
That said, there may be ways to integrate CoEm's into the Super Alignment strategy.
↑ comment by Alexandre Variengien (alexandre-variengien) · 2024-02-27T20:15:47.758Z · LW(p) · GW(p)
In section 5, I explain how CoEm is an agenda with relaxed constraints. It does try to reduce the alignment tax to make the safety solution competitive for lab to use. Instead it considers there's enough advance in international governance that you have full control over how your AI get built and that there's enforcement mechanism to ensure no competitive but unsafe AI can be built somewhere else.
That's what the bifurcation of narrative is about: not letting lab implement only solution that have low alignment tax because this could just not be enough.
comment by mesaoptimizer · 2024-02-08T12:33:45.922Z · LW(p) · GW(p)
This is likely the most clear and coherent public model of Conjecture's philosophy and strategy that I've encountered in public, and I'm glad it exists.