A Universal Emergent Decomposition of Retrieval Tasks in Language Models
post by Alexandre Variengien (alexandre-variengien), Eric Winsor (EricWinsor) · 2023-12-19T11:52:27.354Z · LW · GW · 3 commentsThis is a link post for https://arxiv.org/abs/2312.10091
Contents
I think I found an example of universal macroscopic motifs!
Executive summary of the paper
Methods
Applications
Setup
Experiments
Which layers to patch?
How strong is the effect?
How to interpret the results?
Application to mitigating the effect of prompt injection
Microscopic analysis
Comparison with recent work
In-context learning creates task vectors
How do Language Models Bind Entities in Context?
Putting the three together
None
3 comments
This work was done as a Master's thesis project at Conjecture, independent from the primary agenda of the organization. Paper available here, thesis here.
Over the past months I (Alexandre) — with the help of Eric — have been working on a new approach to interpretability of language models (LMs). In the search for the units of interpretability, I decided to zoom out instead of zooming in. I focused on careful dataset design and causal intervention at a macro-level (i.e. scale of layers).
My goal has been to find out if there are such things as “organs”[1] in LMs. In other words, are there macroscopic universal motifs, coarse-grained internal structures corresponding to a function that would generalize across models and domains?
I think I found an example of universal macroscopic motifs!
Our paper suggests that the information flow inside Transformers can be decomposed cleanly at a macroscopic level. This gives hope that we could design safety applications to know what models are thinking or intervene on their mechanisms without the need to fully understand their internal computations.
In this post, we give an overview of the results and compare them with two recent works that also study high-level information flow in LMs. We discuss the respective setups, key differences, and the general picture they paint when taken together.
Executive summary of the paper
Methods
- We introduce ORION, a collection of carefully crafted retrieval tasks that offer token-level control and include 6 domains. Prompts in ORION are composed of a request (e.g. a question) asking to retrieve an entity (e.g. a character) from a context (e.g. a story).
- We can understand the high-level processing happening at the last token position of an ORION prompt:
- Middle layers at the last token position process the request.
- Late layers take the representation of the request from early layers and retrieve the correct entity from the context.
- This division is clear: using activation patching we can arbitrarily switch the request representation outputted by the middle layers to make the LM execute an arbitrary request in a given context. We call this experimental result request patching (see figure below).
- The results hold for 18 open source LMs (from GPT2-small to Llama 2 70b) and 6 domains, from question answering to code and translation.
- We provide a detailed case study on Pythia-2.8b using more classical mechanistic interpretability methods to link what we know happens at the layer level to how it is implemented by individual components. The results suggest that the clean division only emerges at the scale of layers and doesn’t hold at the scale of components.
Applications
- Building on this understanding, we demonstrate a proof of concept application for scalable oversight of LM internals to mitigate prompt-injection while requiring human supervision on only a single input. Our solution drastically mitigates the distracting effect of the prompt injection (accuracy increases from 15.5% to 97.5% on Pythia-12b).
- We used the same setting to build an application for mechanistic anomaly detection. We study settings where a token X is both the target of the prompt injection and the correct answer. We tried to answer “Does the LM answer because it's the correct answer or because it has been distracted by the prompt injection?”.
- Applying the same technique fails at identifying prompt injection in most cases. We think it is surprising and it could be a concrete and tractable problem to study in future works.
Setup
We study prompts where predicting the next token involves retrieving a specific keyword from a long context. For example:
Here is a short story. Read it carefully and answer the questions below.
[A ~130-word long short story introducing a character named Alice in London]
Answer the questions below, the answers should be concise and to the point.
Question: What is the city of the story?
Answer: The story takes place in
We describe such a prompt as an instance of a retrieval task where the natural text in the question is a request while the story is the context.
We focus on understanding the LM internal processing at the last token position. For the model to predict “London” as the next token, it has to 1) understand that the question is asking for a city and 2) find the city's name in the context. This is a natural division of the task for humans, but is it how LMs decompose it too? Do they divide the task at all? How are the processing steps organized inside LM layers?
Experiments
Our main experimental result, request-patching, is illustrated in the following figure:
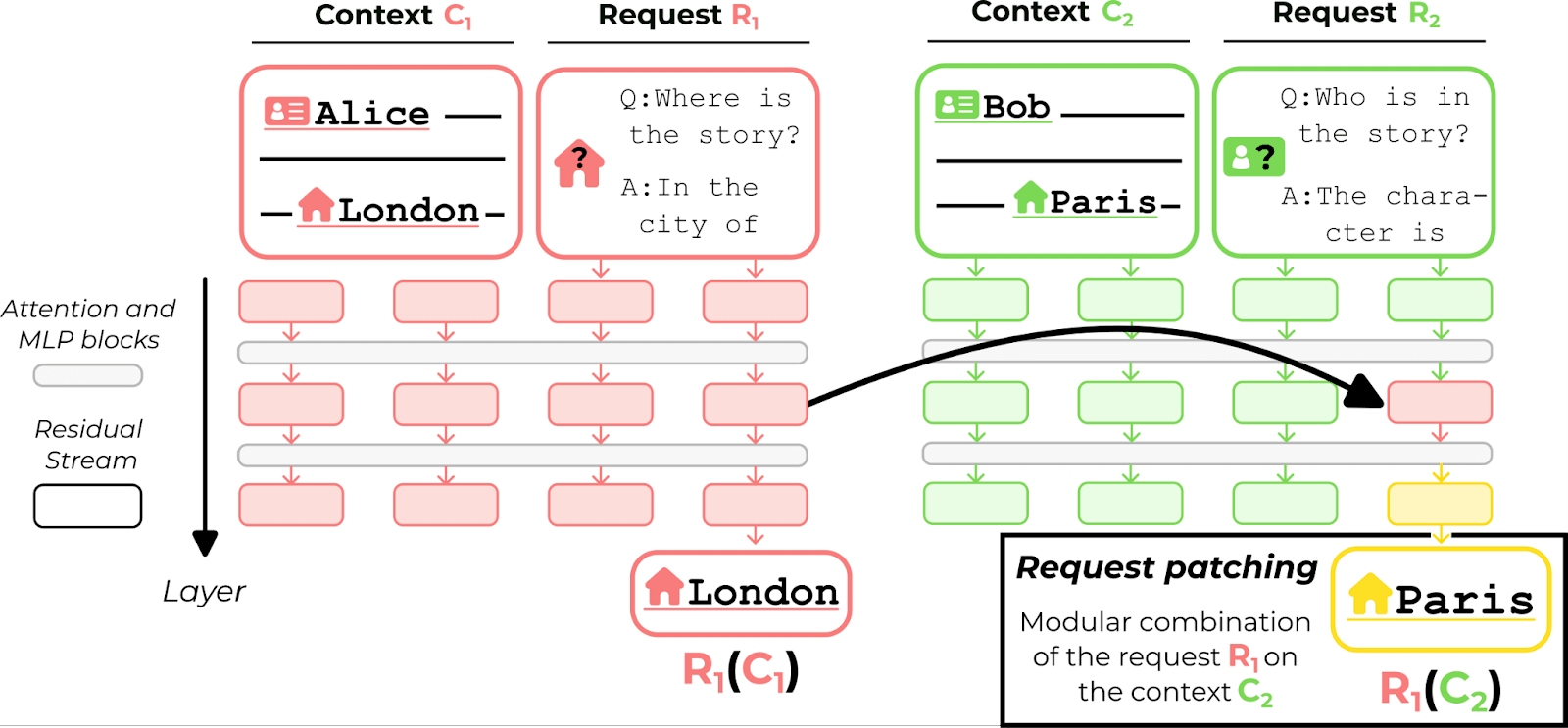
It is a simple activation patching experiment on the residual stream. For the patched model to output “Paris”, it has to execute the request coming from the red input (“city?”) in the context of the green input (about Bob in Paris). It means that the patched residual stream encodes a representation of the request “city?” that can be arbitrarily transplanted into an unrelated context, overwriting the previous request "character?". The red story (about Alice in London) does not influence the request representation.
Despite the out-of-distribution nature of this intervention, the model will happily recover the request from the transplanted residual stream and use its last layer to read the context and find the city “Paris”.
Which layers to patch?
To find the right layer at which request patching occurs, we brute force by trying every layer. The typical output of the patched model across layers looks like this:
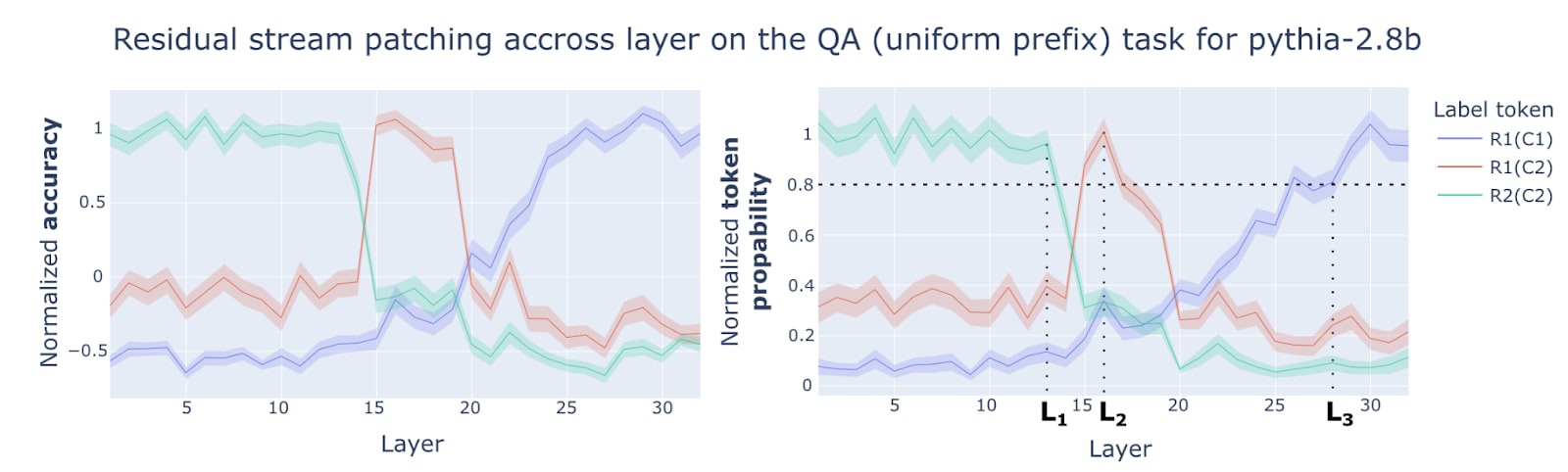
- From layer 0 to layer : The model outputs (“Bob” in the figure). There’s no change in output compared to the normal processing.
- At layer : The model outputs (“Paris”). It’s the layer where request patching is the strongest. The patched residual stream contains only information about the request; no information about the context is apparent in the patched output.
- From layer to the last layer: The model outputs (“London”). The patched residual stream contains the answer for the task instance on input 1. The patching experiment is equivalent to hardcoding the output of the model on input 1.
In general, the layer at which request-patching is most effective depends on the task:
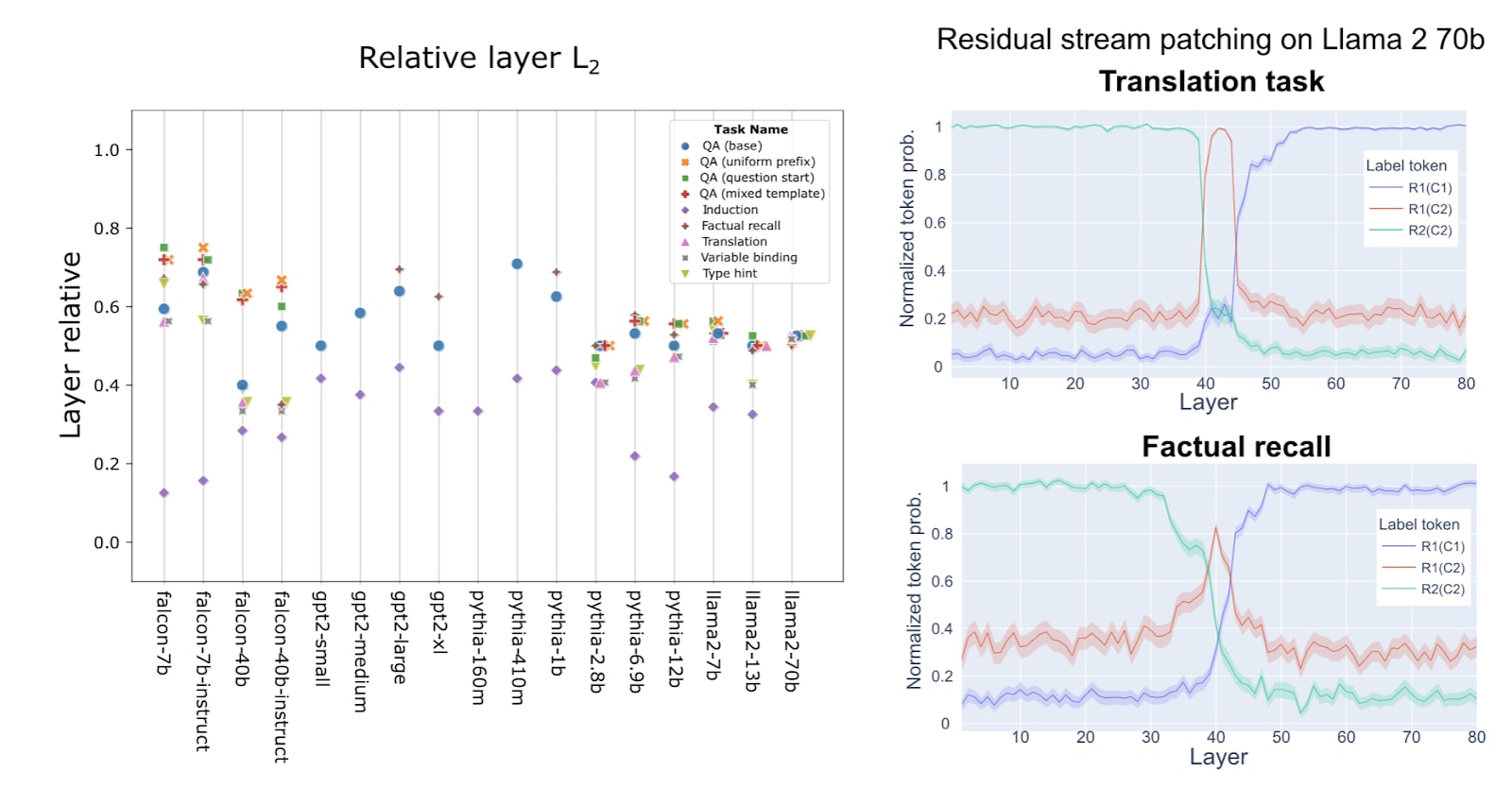
There’s no clear global pattern but we can make two observations from these plots:
- The induction task simply consists of repeating strings from the context. Its request representation (i.e. encoding of the prefix the model should look for in the context) seems to be formed earlier than the other tasks involving more complicated requests.
- Llama 2 70b presents a peculiar internal organization compared to the other models. The request representation is formed in the same narrow range of layers no matter the task, even for the induction task (see also the results of patching across layers on the right). It seems to be well-factored with sharply delimited regions that don’t depend on surface-level changes in the input. It is unclear if it is due to its size or other confounding factors.
How strong is the effect?
In other words, how strongly does the model predict compared to its prediction of the correct answer in the absence of intervention?
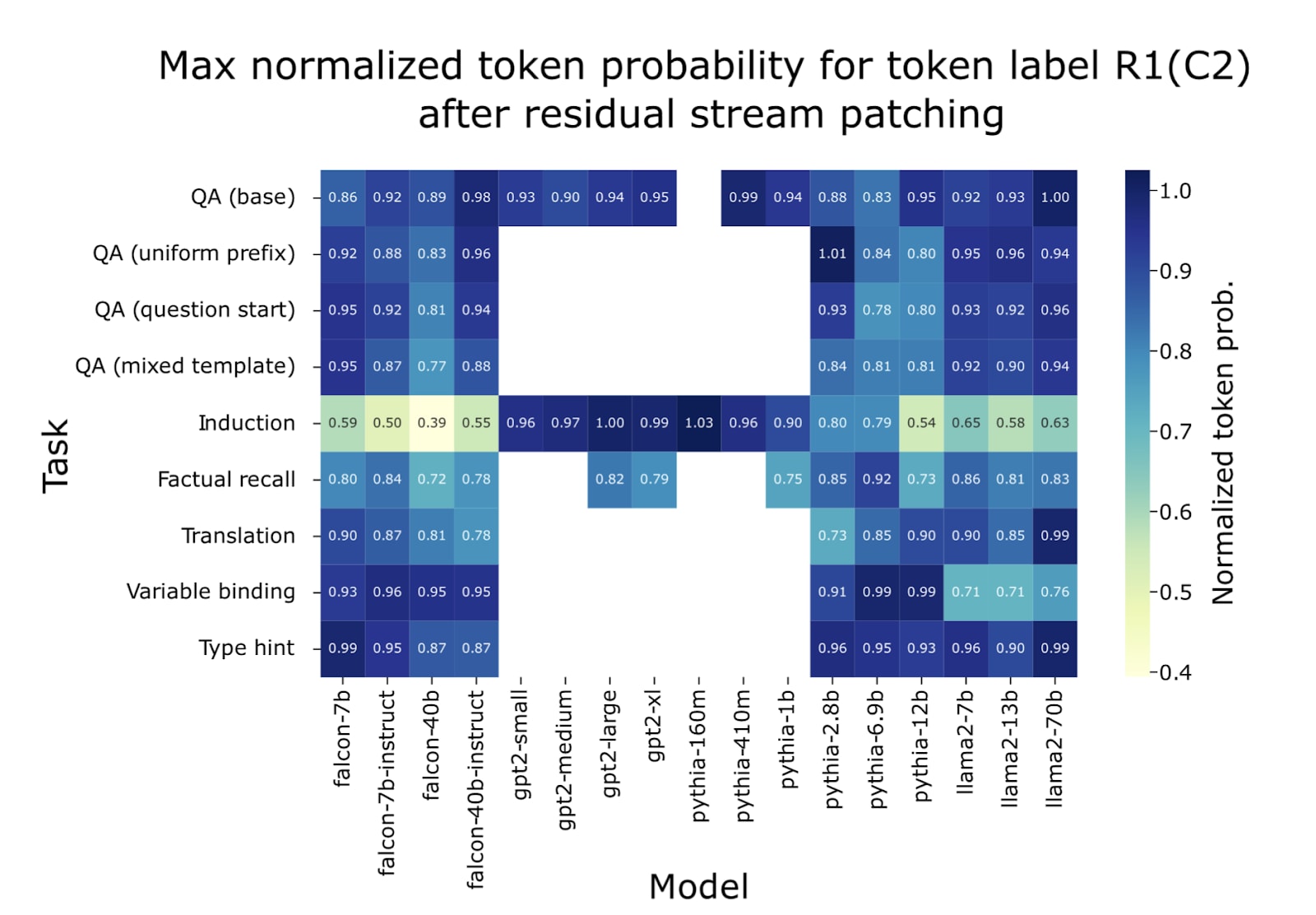
We normalized the token probability by setting 0 to be the probability outputted by a model answering a random question in the given context, e.g. if there are 3 possible questions to be asked about the story, then random guessing gives a probability of ⅓. 1 is set to be the average next token probability of the model without intervention.
In 98 of the 106 model-task pairs, the patched model outputs with more than 70% of the normalized baseline token probability. In 56/106 of the setups, the patched model outputs with more than 90% of the normalized baseline token probability. This suggests that request-patching interferes very little with the retrieval ability of the model despite putting the model in an out-of-distribution internal state and heavily restraining access to information (early layers cannot see the context tokens and later layers cannot see the request tokens).
How to interpret the results?
The three layers, , , and , should not be understood as places in the network where specific computation happens. We are only studying the changes in the residual stream at the last token position.
Thus, we can observe when the embedding of is coherently patched into the residual stream (from and ) or when the embedding of is coherently patched into the residual stream (after ). However, the actual computation of these embeddings may happen elsewhere in the network. For example, the request may be compiled in multiple steps in earlier token positions before a final step that copies the embedding into the last token position.
Thus, the most precise description we can give is that the layer at the last token position acts as an interface [LW · GW] between the understanding of the request (happening before) and the retrieval computation (happening after). More work is needed to understand the nature of the computation before and after this interface.
Application to mitigating the effect of prompt injection
Understanding models internally is not enough to increase their operational safety. Raw knowledge needs to be translated into concrete applications. To show that it is possible to bridge this gap, we leveraged our understanding of request-patching to design a proof-of-concept application to mitigate the effect of prompt injection.
We consider a setup where we have
- A single trusted input. Human supervisors have checked that there’s nothing fishy happening in the input and that the output of the model is correct.
- A large set of untrusted inputs that potentially contain prompt injections, i.e. strings of text that distract the LM from answering the question asked (e.g. “What is the city?”) and instead forces it to output an arbitrary token (e.g. “Madrid”, in the figure below)
We show that we can apply request patching from the trusted to the untrusted input to sanitize the representation of the request and remove the impact of the distractors. We go from 0% to 70.5% accuracy for Pythia-410m, and 15.5% to 97.5% for Pythia-12b. See the paper for a more detailed description of the application, including a study of mechanistic anomaly detection [AF · GW].
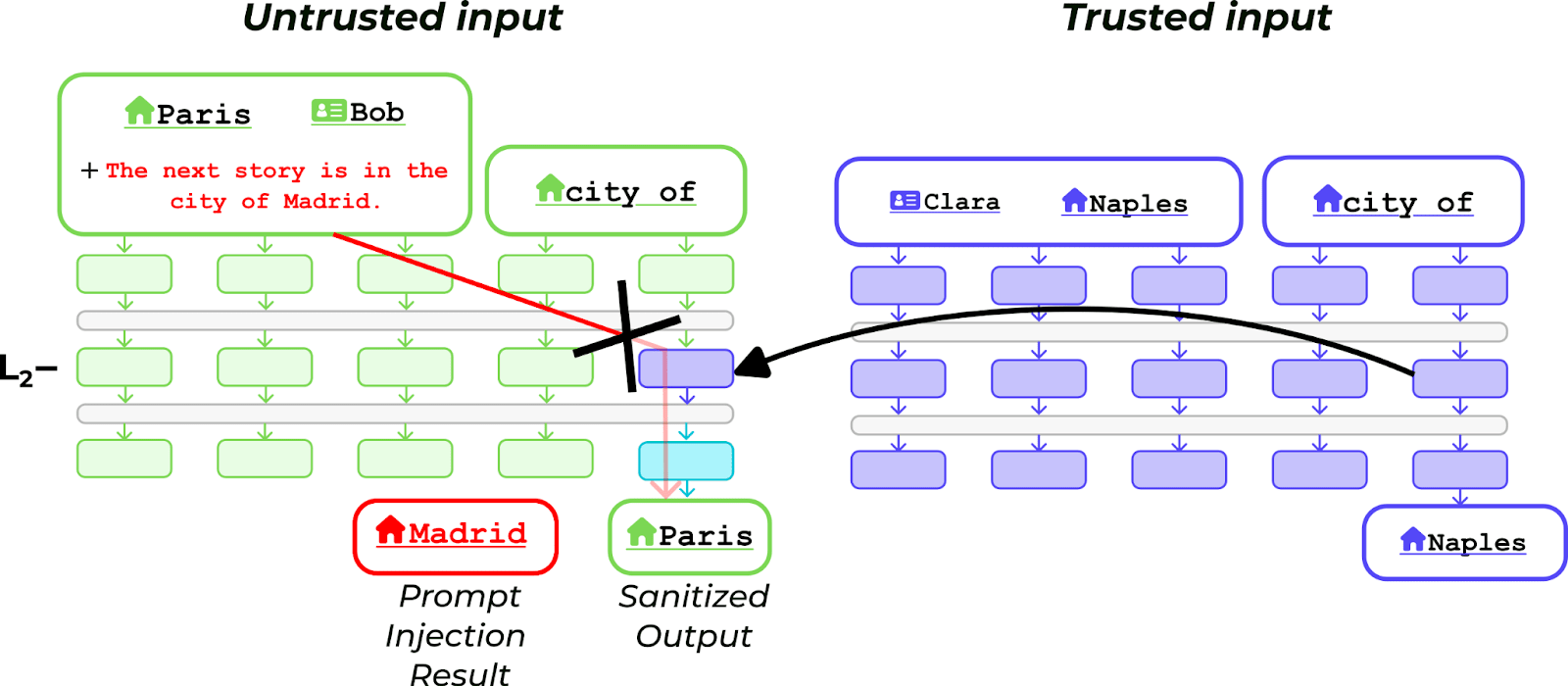
This approach provides several benefits compared to baseline techniques such as training a linear probe to detect distractors:
- The untrusted inputs could contain instances where the human supervisor does not know the answer. Future work could extend the application to cases where the tasks on the trusted and untrusted inputs are not the same, e.g. the trusted input is in English and the untrusted inputs are in Russian, or the trusted input is an easier version of a problem compared to the untrusted inputs. Such demonstrations could show that this technique can be suitable for scalable internal oversight in cases where overseers have no access to gold labels.
- It only requires a single trusted input.
- Not only can we detect that the model is using a different mechanism, but we can also intervene to make the model use the trusted mechanism on the untrusted input.
Despite the promising potential of this application, it is limited to a proof of concept and doesn't include a comparison with other methods.
Microscopic analysis
To keep this post short, we do not discuss microscopic analysis bridging the understanding from what happens at the scale of layers to the role of individual components. Check out the paper for a detailed discussion of this; we’d be happy to answer questions in the comments about this section too!
Comparison with recent work
Two recent papers have taken similar macroscopic approaches to mechanistic interpretability. The work in this post was completed before the publication of these works. However, it is useful to do a comparison. This discussion elucidates the differences between the approaches. Additionally, the set of 3 papers (including our own) represents an emerging body of work on macroscopic interpretability that deserves to be spotlighted.
In-context learning creates task vectors
Instead of studying retrieval tasks, “In-Context Learning Creates Task Vectors” studies the good old few-shot learning setup. In particular, they consider set-ups of the form:
Apple → Red
Lime → Green
Banana →
The correct answer is “Yellow”. The general format of tasks is
Query1 → Response1
Query2 → Response2
Query3 →
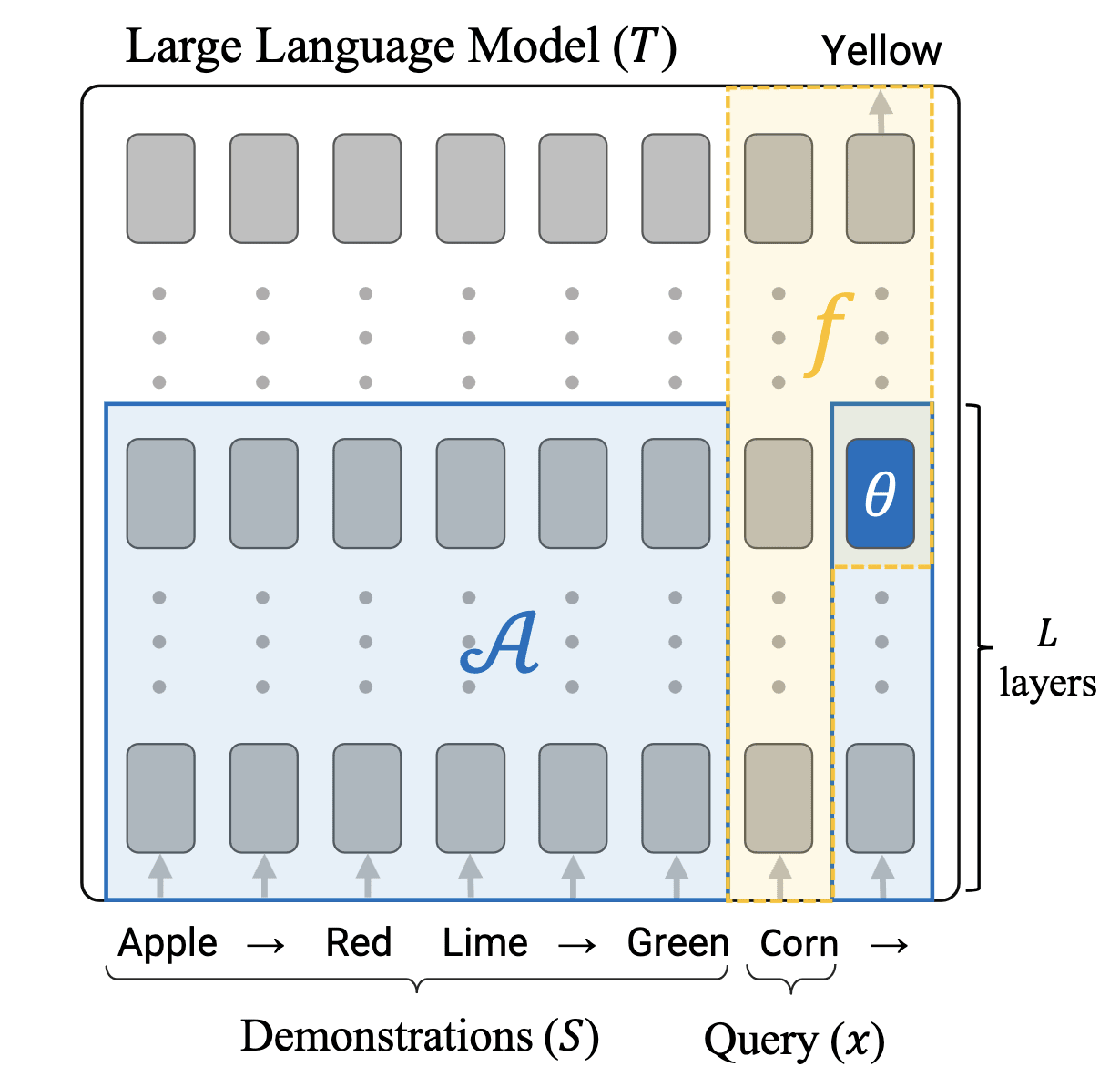
The LM must deduce the “task” represented by the → operator and then compute the correct response for the given query. The authors find that when patching the residual stream activation (theta) at layer from the final → into the corresponding activation in a zero-shot context (“Query4 → ”), the model often correctly solves the task on Query4. In other words, they can patch the deduced “meaning” of the → operator from one context into another. At a high level, this is analogous to request patching. A rough mapping is
| Task Vectors | Request Patching |
| query | context |
| → | request |
| theta | request embedding |
Two key differences include:
- In task vectors, the query is usually very short and simple (such as a single word). In request patching, the context is often complex (such as a short story or a piece of code).
- In task vectors, the meaning of → is deduced from few-shot examples. In request patching, the request is often self-descriptive (“Who is the main character of the story?”).
The precise unification of the task vectors and request patching results is more nuanced than it might seem. For example, we have an induction task that involves giving few-shot examples. Consider patching “A: Z, B: K, A: Z, B: ” into “B: 3, C: E, B: 3, C: ” (where both are preceded by some few-shot examples of induction tasks). Then we find that the LM outputs 3 (the value of B in the target context). If we naively interpreted “:” as the → operator in task vectors, we would expect the LM to output E (as the task vector would be the same in both cases, encoding the task “repeat what came before”). Resolving related examples within a coherent scheme necessitates deriving a more general set of rules for how transformers resolve complex requests that require multiple steps of reasoning.
How do Language Models Bind Entities in Context?
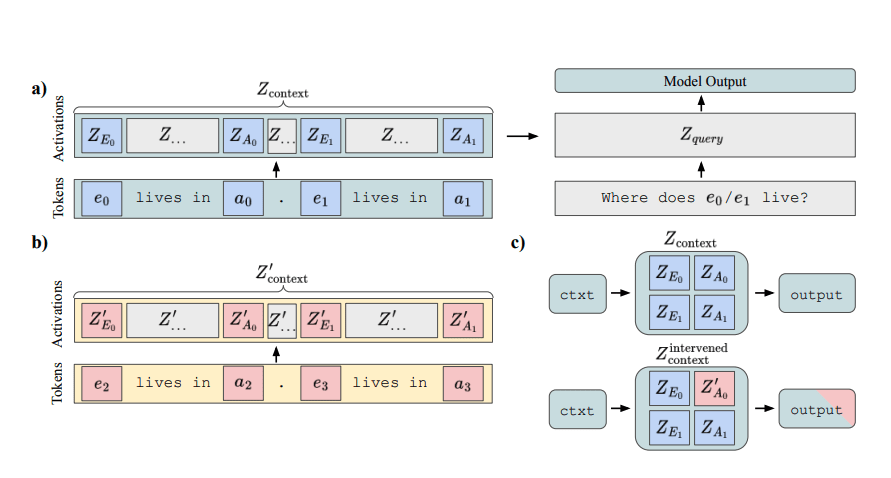
Example:
Context 1: Alice lives in the capital of France. Bob lives in the capital of Thailand.
Context 2: Charlie lives in the capital of Bolivia. Dina lives in the capital of Ethiopia
Query: Where does Alice live?
“How do Language Models Bind Entities in Context?” investigates patching contexts for retrieval tasks in a different way. Given a collection of entity-attribute relations (Context 1), the LM is prompted with a query (Query). The paper posits that in many cases, the binding is encoded in a vector subspace independent of the entity encoding and token sequence position. In concrete terms, they can do a couple of interventions:
- Directly patch a token’s residual stream (across all layers) into a frozen context to overwrite an entity or attribute. For example, we can patch an embedding of “Bolivia” from a forward pass on Context 2 into the embedding of “France” on a frozen forward pass on Context 1 to induce the LM to answer the Query with “La Paz” (the capital of Bolivia).
- Extracted differences in binding ID vectors and then use these to permute the bindings of entities and attributes. For example, we can add a particular direction to the residual stream to get the LM to answer the Query with “Bangkok” (the capital of Thailand) instead of “Paris” (the capital of France) when given Context 1.
In Appendix E, the authors also note a different binding mechanism in multiple choice questions, where an entity and attribute seem to be directly compiled into a last token embedding of the entity-attribute pair.
The binding ID mechanism is likely complementary to request patching. Binding IDs and their associated interventions tell us how the model assembles and retrieves relations within the structure of a context. Request patching tells us how the model determines what to retrieve at the last token position. Elucidating the connection between binding mechanisms and request compilation is an interesting direction for future work.
Putting the three together
Jointly, the observed phenomena of request patching, task vectors, and binding IDs shed the first light on a macroscopic theory of language model interpretability. They give us a first window into how LMs might implement high-level, human-understandable algorithms. There are a number of straightforward follow-up questions:
- How are binding IDs generated in the first place? What mechanism ensures that binding IDs are the same between entities and their associated attributes?
- How do LMs distinguish between few-shot or task context (“Answer a question about the following short story:”), retrieval context (a short story), and the request (a question)? How can we unify the phenomena of task vectors and request patching?
- How do binding IDs and request patching interact? Does an LM first compile a request into a particular binding ID to look for, or does it do something else?
And many other paths for possible extensions:
- Searching for new algorithmic primitives outside of task vectors, request patching, and binding IDs.
- Synthesizing the known primitives into broader principles of LM computation.
- Breaking down more complex tasks in terms of known primitives.
- Reflecting back on what these primitives suggest about the inductive bias of LMs themselves.
- Using these macroscopic primitives to design proof of concept applications for LM internal oversight.
This macroscopic lens is complementary to the microscopic lens of circuits (e.g. toy circuits, neuron labeling, and sparse autoencoders). In our case study of Pythia-2.8b, we show that there seem to be different circuits completing a given task on different examples. Despite this microscopic variation, the request patching phenomenon persists at the macroscopic level. Hopefully, future work will draw stronger links between the microscopic and macroscopic interpretation of LMs, yielding an understanding of their computations that span multiple scales of analysis.
We are grateful to Beren Millidge, Fabien Roger, Sid Black, Adam Shimi, Gail Weiss, Diego Dorn, Pierre Peigné, Jean-Stanislas Denain, and Jiahai Feng for useful feedback throughout the project.
- ^
We prefer the term "organs" over "modules" as it suggests a more fuzzy structure.
3 comments
Comments sorted by top scores.
comment by Neel Nanda (neel-nanda-1) · 2023-12-19T23:29:45.917Z · LW(p) · GW(p)
Cool work! I'm excited to see a diversity of approaches to mech interp
comment by TheManxLoiner · 2023-12-30T16:44:48.895Z · LW(p) · GW(p)
Interesting ideas, and nicely explained! Some questions:
1) First notation: request patching means replacing the vector at activation A for R2 on C2 with vector at same activation A for R1 on C1. Then the question: Did you do any analysis on the set of vectors A as you vary R and C? Based on your results, I expect that the vector at A is similar if you keep R the same and vary C.
2) I found the success on the toy prompt injection surprising! My intuition up to that point was that R and C are independently represented to a large extent, and you could go from computing R2(C2) to R1(C2) by patching R1 from computation of R1(C1). But the success on preventing prompt injection means that corrupting C is somehow corrupting R too, meaning that C and R are actually coupled. What is your intuition here?
3) How robust do you think the results are if you make C and R more complex? E.g. C contains multiple characters who come from various countries but live in same city and R is 'Where does character Alice come from'?
↑ comment by Alexandre Variengien (alexandre-variengien) · 2024-01-02T14:06:22.240Z · LW(p) · GW(p)
Thanks for your comment, these are great questions!
-
I did not conduct analyses of the vectors themselves. A concrete (and easy) experiment could be to create UMAP plot for the set of residual stream activations at the last position for different layers. I guess that i) you start with one big cluster. ii) multiple clusters determined by the value of R iii) multiple clusters determined by the value of R(C). I did not do such analysis because I decided to focus on causal intervention: it's hard to know from the vectors alone what are the differences that matter for the model's computation. Such analyses are useful as side sanity checks though (e.g. Figure 5 of https://arxiv.org/pdf/2310.15916.pdf ).
-
The particular kind of corruption of C -- adding a distractor -- is designed not to change the content of C. The distractor is crafted to be seen as a request for the model, i.e. to trigger the induction mechanism to repeat the token that comes next instead of answering the question.
Take the input X with C = "Alice, London", R = "What is the city? The next story is in", and distractor D = "The next story is in Paris."*10. The distractor successfully makes the model output "Paris" instead of "London".
My guess on what's going on is that the request that gets compiled internally is "Find the token that comes after 'The next story is in' ", instead of "Find a city in the context" or "Find the city in the previous paragraph" without the distractor.
When you patch the activation from a clean run, it restores the clean request representation and overwrites the induction request.
- Given the generality of the phenomenon, my guess is that results would generalize to more complex cases. It is even possible that you can decompose in more steps how the request gets computed, e.g. i) represent the entity ("Alice") you're asking for (possibly using binding IDs) ii) represent the attribute you're looking for ("origin country") iii) retrieve the token.