AIS 101: Task decomposition for scalable oversight
post by Charbel-Raphaël (charbel-raphael-segerie) · 2023-07-25T13:34:58.507Z · LW · GW · 0 commentsThis is a link post for https://docs.google.com/document/d/1k6rlyBCZJw8xbUx0dzd-4sOhlzj-xzsmwi_OIZY1-3M/edit?usp=sharing
Contents
Outline Scalable oversight and Sandwiching Task decomposition and Factored Cognition Introduction to factored cognition Iterated Amplification Discussion of the Hypotheses - Scalable mechanisms Some other amplification schemes My opinion: Is task decomposition viable? One proposed solution to scalable oversight: Iterated distillation and amplification Motivations for IDA Examples of IDA systems Example 1: AlphaZero What properties must hold for IDA to work? Amplification in modern Language Models HCH: Summarizing Books with Human Feedback Factored cognition in LLM : Iteration with WebGPT Amplification via Chain of Thought Least-to-Most Prompting (bonus) Unfaithful Chain-of-thought Process supervision Process supervision in Anthropic plan Supervise processes, not outcomes Empirical Works on Process Supervision Procedure cloning (bonus) Process supervision for Maths Conclusion None No comments
AGISF Week 4 - Task decomposition for scalable oversight
This text is an adapted excerpt from the task decomposition for scalable oversight section of the AGISF 2023 course, held at ENS Ulm in Paris on March 16, 2023. Its purpose is to provide a concise overview of the essential aspects of the session's program for readers who may not delve into additional resources. This document aims to capture the 80/20 of the session's content, requiring minimal familiarity with the other materials covered. I tried to connect the various articles within a unified framework and coherent narrative. This distillation is not purely agnostic. You can find the other summaries of AGISF week on this page. This summary is not the official AGISF content. I have left the gdoc accessible in comment mode, feel free to comment there.
Thanks to Jeanne Salle, Markov, Amaury Lorin and Clément Dumas for useful comments.
Outline
How can we still provide good feedback when a task becomes too hard for a human to evaluate?
Scalable oversight refers to methods that enable humans to oversee AI systems that are solving tasks too complicated for a single human to evaluate. AIs will probably become very powerful, and perform tasks that are difficult for us to verify. In which case, we would like to have a set of procedures that allow us to train them and verify what they do.
I introduce scalable oversight as an approach to preventing reward misspecification, i.e., when an artificial intelligence (AI) system optimizes for the wrong objective, leading to unintended and potentially harmful outcomes. In the current machine learning (ML) paradigm, good quality feedback is essential. I then discuss one important scalable oversight proposal: Iterated Distillation and Amplification (IDA). The Superalignment team will likely [LW(p) · GW(p)] use some of the techniques presented here, so bear with me!
Here's the outline:
- Presenting the scalable oversight problem and one framework to evaluate solutions to this problem, sandwiching (Bowman, 2022).
- To solve the scalable oversight problem, I focus here on task decomposition (next post will focus on adversarial techniques) and I then examine some potential solutions:
- Factored cognition tries to break down sophisticated reasoning into many small and mostly independent tasks. One approach for factored cognition is Iterated Amplification. The non-profit Ought (Ought, 2019) is the main organization studying this agenda.
- Iterated Amplification and Distillation (IDA) is an approach to train capable and safe AIs (Christiano et al., 2018) through a process of initially building weak aligned AIs, and recursively using each new AI to build a slightly smarter and still aligned AI. I also draw from Cotra’s (2018) perspective on iterated distillation and amplification.
- In the previous section, we learned what Factored cognition (and particularly Iterated Amplification) is: the aim here was mainly to carry out a complex task. In this new part, we're going to change the objective: here we're going to try to train an agent in a safe and powerful way, using the IDA technique. One of the requirements of IDA is to be able to apply Iterated amplification when rewarding the agent.
- Amplification in modern LLMs: Although the previous sections were quite theoretical, we will see that it is possible to apply amplification through task decomposition in order to train increasingly powerful agents (using methods such as Least-to-Most Prompting, Chain of Thought, or recursive reward modeling for summarizing books). Unfortunately, Chain of Thought explanations can misrepresent the true reason for a model's prediction (Turpin, 2023).
- Process supervision (or process-based training, as opposed to outcome-based training) (Stuhlmuller and Byun, 2022) [AF · GW] wants the system to be built on human-understandable decomposition of reasoning, by supervising reasoning steps, and not relying on end-to-end optimization which can make the reasoning opaque. Process-based training might be a solution to mitigate unfaithful Chain-of-thoughts and more transparent reasoning.
Scalable oversight and Sandwiching
The paper Measuring Progress on Scalable Oversight for Large Language Models (Bowman, 2022) introduces the problem of 'scalable oversight' — trying to provide feedback on tasks that are too complex for a human to fully understand. To build and deploy safe and useful AI, we need to provide it with labels or feedback that reflect our values and goals. However, if the AI becomes better at most tasks than we are, we may not be able to judge its alignment or performance. This is the scalable oversight problem. One proposed framework for testing solutions to this problem is sandwiching.
Sandwiching is a framework in which two groups of humans (experts and non-experts) evaluate the effectiveness of a scalable oversight technique on a given AI system, with the goal of identifying the best approach to aligning the AI system with human values. Human experts will evaluate the model’s performance to check if the non-experts successfully aligned the model. Sandwiching is not a solution per se, but it allows us to evaluate different techniques before the AI system is more powerful than human experts. Three type of actors intervene in the sandwiching framework (Ordered from least-to-most competent on the task):
- The Non-Expert Model Overseers: Humans whose objective is to use scalable oversight techniques on the model in order to align it
- The AI System: An ML model with the skills and knowledge needed to solve a task which may not be aligned, in the sense that it doesn't necessarily show those skills when asked to complete the task
- Domain Expert: Humans who have all the skills and knowledge needed to complete the task.
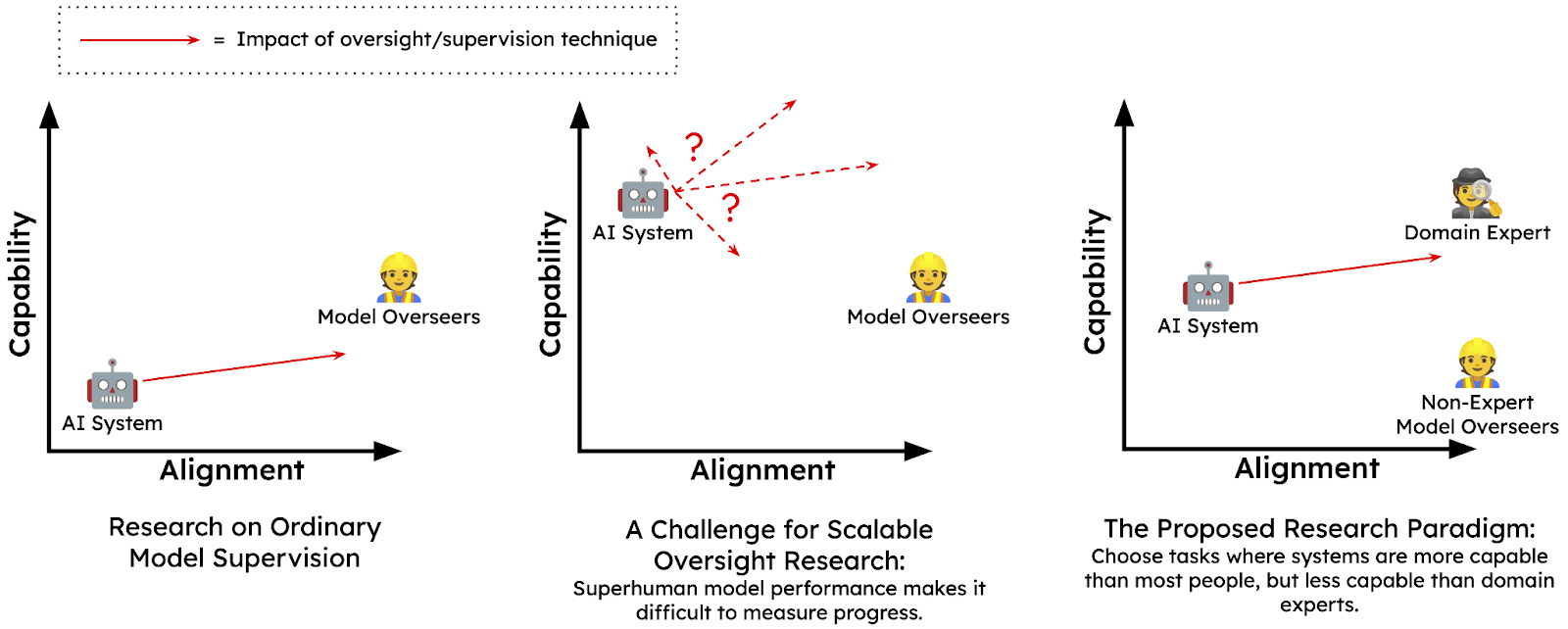
Experiment and results: They tested the sandwiching framework with an experiment involving a ChatGPT-like agent answering multiple-choice questions, with non-expert overseers providing feedback to align the model with human values. The results showed that while the non-expert overseers were successful in generally aligning the model, the non-experts exhibited high confidence in false responses, indicating a need for improvement in their oversight skills. Experts are still not capable enough to identify when their oversight is wrong, which could encourage AI deception in the future.
Thus, we have seen in this section that sandwiching serves as an evaluation framework. The rest of this post will focus on solutions, and especially on task decomposition as a solution to the problem of scalable oversight. However, it is not the only paradigm for addressing this problem. Alignment via Debate and Unrestricted Adversarial Examples will also be discussed in subsequent posts.
Task decomposition and Factored Cognition
Introduction to factored cognition
Is scalable oversight with task decomposition feasible? This leads us to Ought’s, (a non-profit) Factored Cognition agenda.
From Ought documentation (introduction and scalability section): “What is factored cognition? Factored cognition refers to the idea of breaking down (or factoring) sophisticated learning and reasoning tasks into many small and mostly independent tasks.”
Factored Cognition can be applied to various research problems. For instance, a question on a research paper:
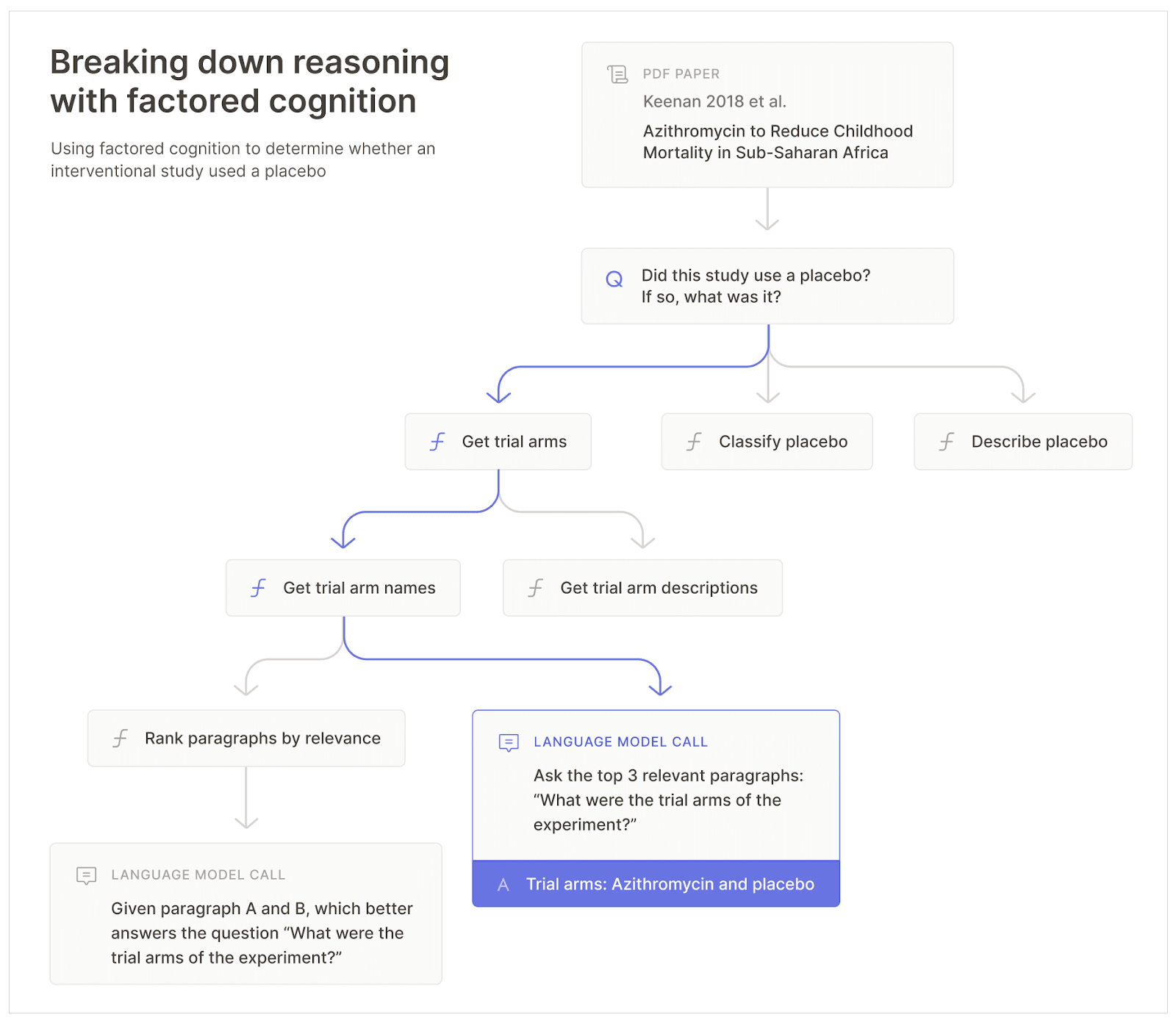
Ought aims to decompose the research process into various subtasks. Here are several examples of subtasks involved in a research project:

The objective is to divide the entire research process into these subtasks. To facilitate this, Ought has created a search engine named Elicit, which operates on this principle. Elicit offers specialized tools to aid researchers in conducting literature reviews more efficiently.
This search engine enables us to observe how humans engage with decomposition and amplification tools and assess whether it simplifies their work as researchers.
We have seen here the general setup of factored cognition. But what would be the algorithmic procedure used in practice to implement factored cognition? What assumptions need to be made?
Iterated Amplification
The central hypothesis: An essential question in factored cognition is whether we can solve difficult problems by composing small and mostly context-free contributions from individual agents who don't know the big picture.
Algorithmic procedure: Let's take the following research question as an example: "What is the appearance of a field theory when supersymmetry is spontaneously broken?"
- Initialization: If I, who has no knowledge of theoretical physics, look at this question, am I able to answer it in 15 minutes? No.
- One-step Amplification: If I am assisted by 100 assistants, each of whom has 15 minutes to conduct research, starting with the knowledge of an average human, and they must report their answers to me, can I answer the question?
- Two-step Amplification: If each of my 100 assistants obtains 100 assistants, can I answer the question?
This iterative process is an instance of "Iterated Amplification”.
Discussion of the Hypotheses - Scalable mechanisms
Is the central hypothesis true? The central question at hand is: What capabilities can be achieved through iterated amplification? This question remains open for exploration. Let's consider the concept of utilizing a highly capable assistant, comparable to Einstein's intelligence level at age 25, but with an extended timeframe of 10 years and exceptional research delegation skills. What would be the outcome in such a scenario? Surprisingly, it appears that a significant portion of modern scientific discoveries could be accomplished through this process of amplification. However, it is possible that certain areas of knowledge may remain inaccessible through this amplification procedure. There might exist a threshold of universality, for example between Einstein level and human median level, representing a level of capability beyond which any task can be resolved using this mechanism.
Scalable mechanism. Another important definition is that of a scalable mechanism: “A mechanism is scalable if the solutions it generates get better as its resources increase. So we can purchase marginal improvements in the answer simply by adding more work hours. Some simplifying conditions to think of a Scalable mechanism are:
- All workers are well-motivated.
- Each worker is only available for a short amount of time, say 15 minutes.
- Each worker has the same background knowledge
Problems of coordination can be an obstacle to implementing scalable mechanisms, as we can see in the context of large companies. To get around individual limitations, we could instead hire a group of people and scale by increasing the group size. However, questions arise: how do they communicate? Who does what? How can we have confidence that adding more people will improve the quality of the solutions we get and won’t stop making a difference (or even harm) beyond some point? Finding a good amplification and decomposition scheme and algorithm seems crucial to avoid coordination problems.
Some other amplification schemes
Suppose we have access to an intelligence that matches the average human level. We can pose a question to this intelligence and receive a direct answer, similar to a Q&A session, without any form of amplification. However, we also have the option to amplify this intelligence using various amplification schemes. Here is a list of them (We won't explain them here. More details here):
- Iteration: Dividing a task into a sequence of shorter tasks.
- Recursion: Making sub-calls to agents that make sub-calls
- Pointers: Handling data abstractly
- Internal dialog: Pointing to agents and sending follow-up messages
- Edits: Incremental changes to workspaces
- Persistence: Iterative improvement of workspace trees
- Structured content: Organizing workspaces as documents, registers, trees, etc.
- Reflection: Reifying computation for inspection (recent example with GPT-4)
- Meta-execution: Agents made out of agents
- Interaction: Responding to a stateful world
We will focus on the first two approaches: Iteration and Recursion. In short:
- Iteration: An assistant conducts research for 15 minutes. During the last 5 minutes, they write a summary of their research, and another assistant can then start from the summary and continue the research from there, and so on.
- Recursion: Each assistant behaves like a manager and delegates sub-research questions to other assistants.


My opinion: Is task decomposition viable?
I will now share my opinion on the viability of task decomposition. Is it possible to break down tasks into short-term, context-free work and compose enough human-level intelligence to complete an arbitrary task?
If yes, then humans are above the universality threshold. This means that there exists a procedure to amplify human intelligence and make it capable of doing anything, even going to the moon or performing arbitrarily hard tasks. The fact that no individual human can go to the moon alone, but humanity managed to do so, suggests that task decomposition is viable.
However, in my opinion, the question remains open, and my intuition suggests that the hypothesis of same background knowledge may be false:
- Some tasks are intrinsically serial, and not parallelizable. To sort a list, you need at least log(n) serial steps.
- Kasparov versus the World: Chess seems parallelizable, but Kasparov still wins. During the game, which was played online in 1999, Kasparov played against a collective of amateur chess players known as "The World". Despite the fact that the collective intelligence of The World could be considered an amplification of the amateur players' brains coordinated by grand master players, Kasparov emerged as the winner. So it seems that better heuristics are more important than parallelization when navigating a complex world.
- GPT-2 with Chain-of-Thought vs GPT-3 vanilla: Even by applying all the best chain-of-thought techniques on GPT-2, it would still seem difficult to beat GPT-3. Some amplification techniques only begin to work beyond a certain level of capability (see some emergent phenomena).
But even if the hypothesis is false, task decomposition is still useful for verifying the output of human-level systems.
One proposed solution to scalable oversight: Iterated distillation and amplification
In the previous section, we learned what Iterated Amplification is: the aim here was mainly to carry out a complex task. In this new part, we're going to change the objective: here we're going to try to train an agent in a safe and powerful way, using the IDA technique (Iterated distillation and amplification). One of the requirements of IDA is to be able to apply Iterated amplification when rewarding the agent.
We now come to Iterated Distillation and Amplification (IDA). Originally, this technique was proposed in Supervising strong learners by amplifying weak experts (Christiano et al., 2018): blog post and full paper. This agenda has been distilled by (Cotra, 2018), who provides the AlphaGo examples and the second motivation below.
Motivations for IDA
IDA has two main motivations:
Motivation 1: Improving the reward signal of difficult tasks, by improving the reward signal for difficult tasks by breaking them down into smaller, more manageable components. “If we don’t have a training signal we can’t learn the task, and if we have the wrong training signal, we can get unintended and sometimes dangerous behavior. Thus, it would be valuable for both learning new tasks, and for AI safety, to improve our ability to generate training signals. [...] Although a human can’t perform or judge the whole task directly, we assume that a human can, given a piece of the task, identify clear smaller components of which it’s made up.“ Source: OpenAI's blog.
Motivation 2: Finding a good alignment/capabilities tradeoff? We want to train a learner ‘A’ to perform a complex, fuzzy task, e.g., be a good personal assistant. There are two main training modes:
- Reward maximization through Reinforcement Learning (RL) or Inverse Reinforcement Learning (IRL). This approach is risky because by maximizing a reward, we run the risk of maximizing a proxy, even if RL allows us to obtain superhuman capabilities.
- Imitation Learning and only emulating human level. Since we are only imitating, the risk of misalignment is significantly reduced, but we can only obtain human-level capabilities.
So in short, we want to 1) be able to do the tasks at all. 2) be able to do the tasks cheaply, with a low alignment tax [? · GW]. “If we are only able to align agents that narrowly replicate human behavior, how can we build an AGI that is both aligned and ultimately much more capable than the best humans?”.
One way to satisfy those two motivations is the IDA procedure, which follows this template:

Note: IDA is not an algorithm, but a template, this is not a solution to alignment but is still a research agenda. It will be easier to understand IDA by first exploring different ways to complete this template!
(Another introductory resource can be found here)
Examples of IDA systems
Let's explore different ways to complete this template!
Example 1: AlphaZero
- The amplification corresponds to searching for the best move by exploring the tree of possibilities. This amplification involves applying the same policies multiple times on different board states to obtain a better policy after constructing the tree.
- The distillation corresponds to imitating the result of the tree search without tree search.
If needed, this Rob Miles video explains this step-by-step. How to Keep Improving When You're Better Than Any Teacher - Iterated Distillation and Amplification
Example 2: Decomposition of a toy task, demonstrating the ability to learn direct algorithms for these tasks using only smaller components as training signals. In the initial paper, the authors experiment with 5 toy tasks: “These tasks have direct algorithmic solutions which we pretend we don’t know (for example, find the shortest path between two points on a graph). The problems can also be solved by piecing together small one-step deductions (for example, combining two paths to form a longer path), but it would take exponentially much more effort to piece everything together manually. We use iterated amplification to learn the direct algorithm using only the pieces as training signal, thus simulating the situation where a human knows how to combine subpieces of a solution but can’t provide a direct training signal. On each of these five tasks (permutation powering, sequential assignments, wildcard search, shortest path, and union find), we are able to perform competitively with just directly learning the task via supervised learning, despite being handicapped by not having a direct training signal (the goal here is to match supervised learning with less information, not to surpass it).” From Learning complex goals with iterated amplification.
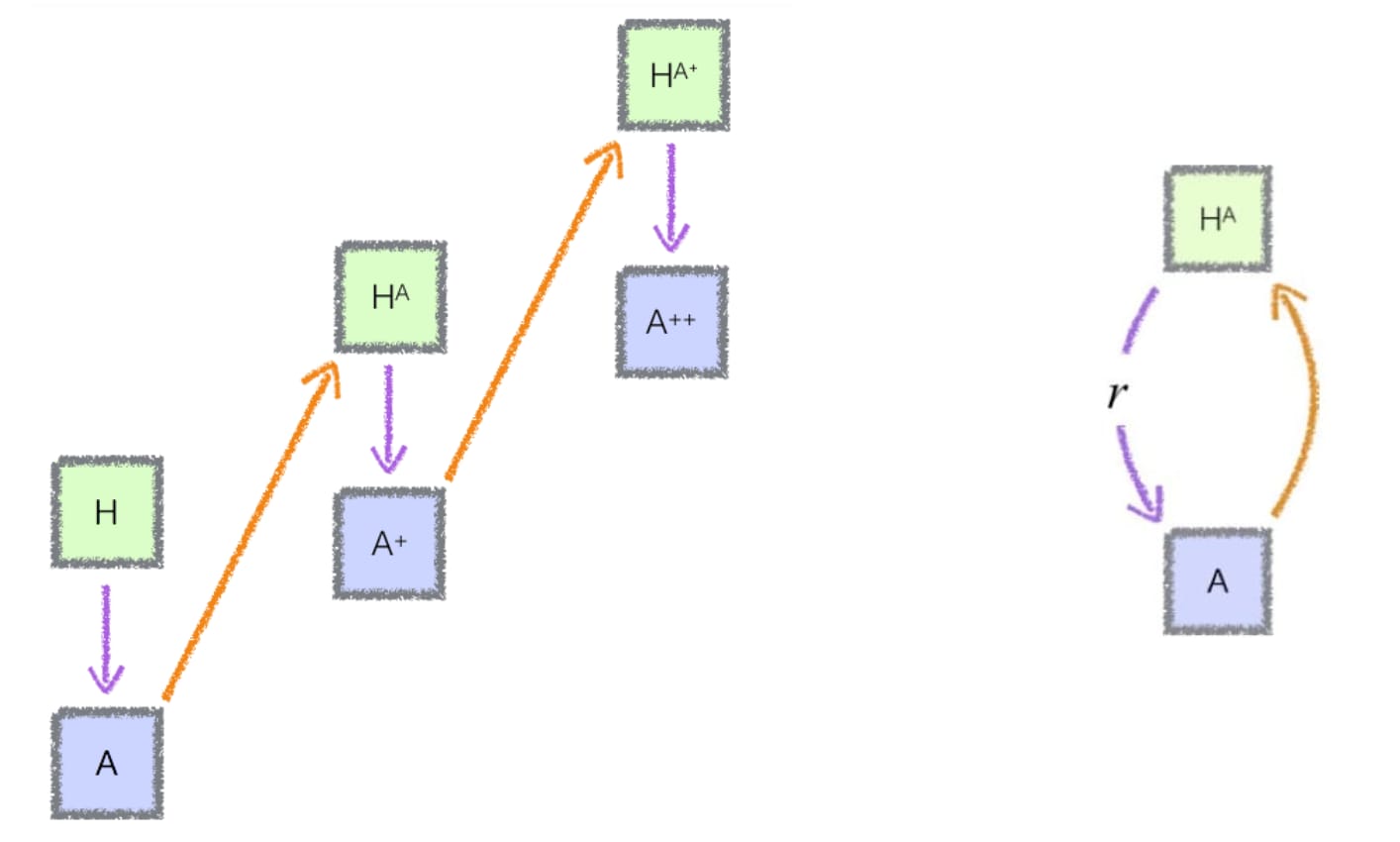
Example 3: ChatGPT - This is my modern interpretation of IDA: a human fine-tunes GPT-5 to create an aligned ChatGPT-5 assistant, which then amplifies the human capabilities, allowing them to generate quality text more easily and improve the AI assistant iteratively. The following interpretation is subjective, but has helped some students understand the principle:
- We begin with the box H, which represents a human.
- Arrow pointing downwards: This human can call upon a very capable assistant, such as base-GPT-5. The human applies a fine-tuning procedure to base-GPT-5, which becomes ChatGPT-5 (A). A powerful and aligned assistant.
- Arrow pointing upwards: The humans then uses ChatGPT-5 and becomes HA (the amplified human); they can write faster, accomplish more tasks, and so on. They can generate quality text very easily because they decompose big tasks into a list of narrow tasks and delegate narrow tasks to the assistant.
- Second arrow pointing downwards: This amplified human will now be able to give better feedbacks (for example by simulating a diverse set of human experts) to red team and improve much more quickly ChatGPT-5, and we obtain ChatGPT-5+, a better assistant (A+)
- HA+: the human uses A+, and can do even more things and go even faster.
- etc.
What properties must hold for IDA to work?
IDA agents need to achieve robust alignment and high capability
- The Amplify procedure robustly preserves alignment - IDA agents need to achieve robust alignment and high capability: agents should be both aligned with human values and capable of performing tasks effectively.
- The Distill procedure robustly preserves alignment
- At least some human experts are able to iteratively apply amplification - At least some human experts are able to iteratively apply amplification to achieve arbitrarily high capabilities at the relevant task (above the universality threshold).
Amplification in modern Language Models
Recent developments indicate that these concepts can indeed be applied to modern language models. In fact, several papers demonstrate how task decomposition and amplification can be employed in the context of contemporary language models. The following papers can be considered as specific instances of amplification.
HCH: Summarizing Books with Human Feedback
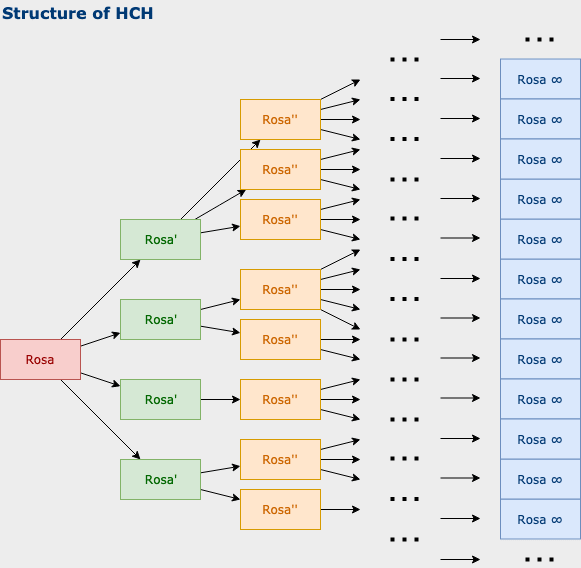
In section “Some amplification schemes”, we presented the recursion scheme and its limit Humans Consulting HCH (HCH): “Humans Consulting HCH (HCH) is a recursive acronym describing a setup where humans can consult simulations of themselves to help answer questions. It is a concept used in discussion of the iterated amplification proposal to solve the alignment problem”. Source: HCH [? · GW].
This may seem very abstract when viewed in this way, and it is difficult to imagine that this approach would be used in practice in machine learning systems. However, OpenAI has used this principle in the paper "Summarizing books with human feedback" (Wu et al., 2021). Here we have an example of recursive task decomposition.
To summarize a book, a language model first summarizes each page individually. Then, these individual summaries are combined, and the resulting concatenated summary is further summarized. This process continues until a summary of the entire book is generated.
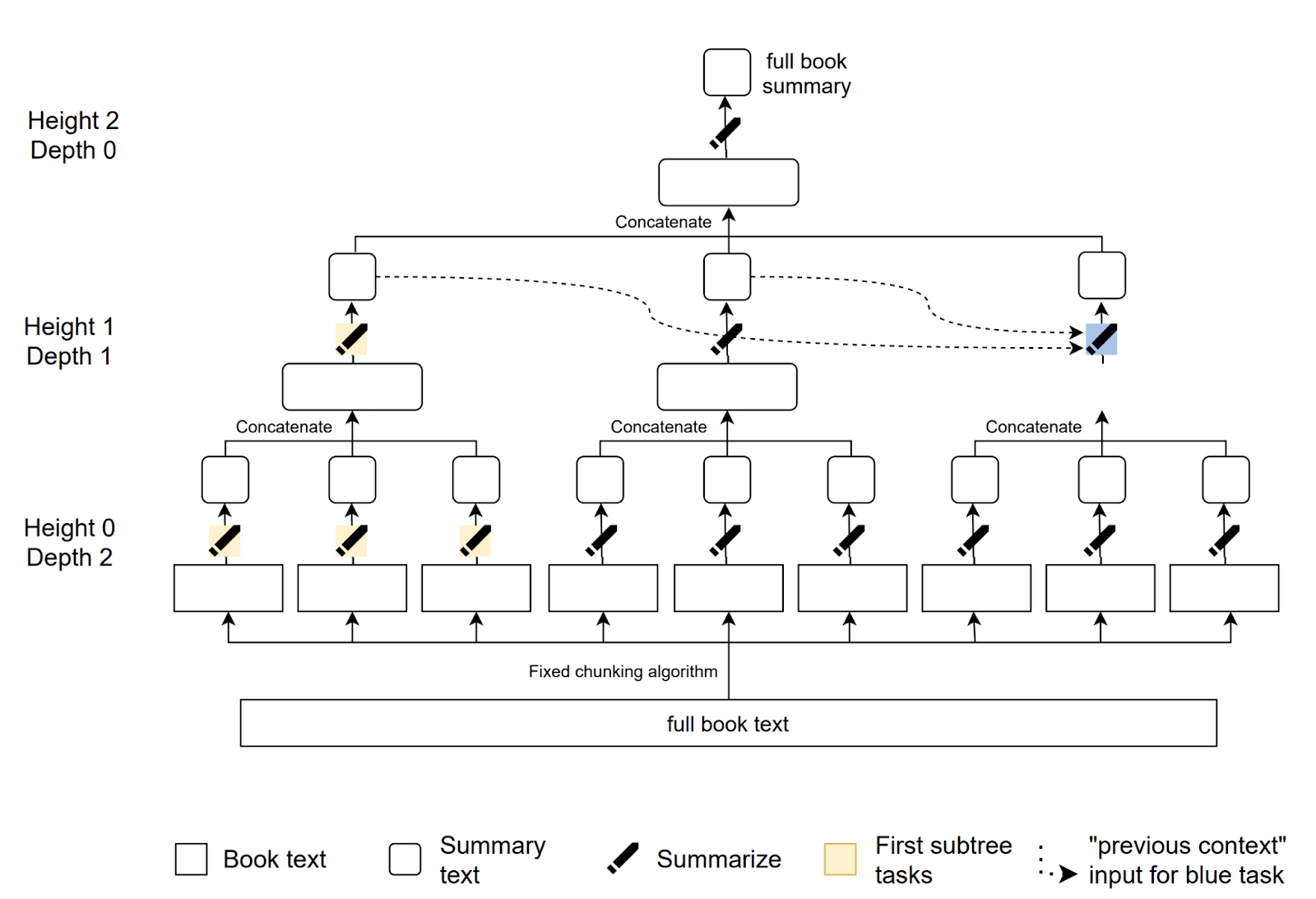
It is worth noting that since a single language model is used for both tasks (summarizing a page and summarizing summaries), the conditions of Hypothesis 3 (“Each worker has the same background knowledge”) are satisfied. This approach has proven to be effective, with most of the summaries being of good quality. However, it should be noted that this approach may not capture the high-level plot of the book, which could be a potential limitation of the method, and which possibly illustrate a general limitation of task decomposition approaches.
How to use this paper for scalable oversight? Here is OpenAI’s answer from Summarizing books with human feedback: “As we train our models to do increasingly complex tasks, making informed evaluations of the models’ outputs will become increasingly difficult for humans. This makes it harder to detect subtle problems in model outputs that could lead to negative consequences when these models are deployed. Therefore, we want our ability to evaluate our models to increase as their capabilities increase. Our current approach to this problem is to empower humans to evaluate machine learning model outputs using assistance from other models. In this case, to evaluate book summaries we empower humans with individual chapter summaries written by our model, which saves them time when evaluating these summaries relative to reading the source text. Our progress on book summarization is the first large-scale empirical work on scaling alignment techniques”
Factored cognition in LLM : Iteration with WebGPT
WebGPT (Nakano et al., 2022) was something that I (the author) found to be a beautiful illustration of the concept of factored cognition. Since it was helpful for me, I am including my thoughts here with the hope that it will be helpful to the reader as well. It is a bit of an ancestor of Bing Search. “Language models like Gopher can “hallucinate” facts that appear plausible but are actually fake. [...] Our prototype copies how humans research answers to questions online—it submits search queries, follows links, and scrolls up and down web pages. It is trained to cite its sources”.
I highly recommend watching the short video on the OpenAI page to better understand:

The system performs a search, navigates to a webpage, selects text, and iteratively composes its response while citing sources.
How does this system work? The following two figures in the paper help to understand it better. There is an interface with which human labelers navigate and compose a response. All of their actions are recorded. These actions are then converted into text as shown in (b).

In figure (b), we prompt the language model with:
- A question
- the previous quotes
- the previous actions
- the title of the page being visited
- the text currently present on the page
- the number of remaining actions
- and the question : "Next Action?" to which the LLM must answer by one of the tokens in the next figure:

At each action, the text in Figure (b) is updated. This exactly illustrates the scenario envisioned in 2017 by Ought, via iteration amplification: a model does a search and leaves a summary of what it has done for the next language model (presented previously in this post)
Amplification via Chain of Thought
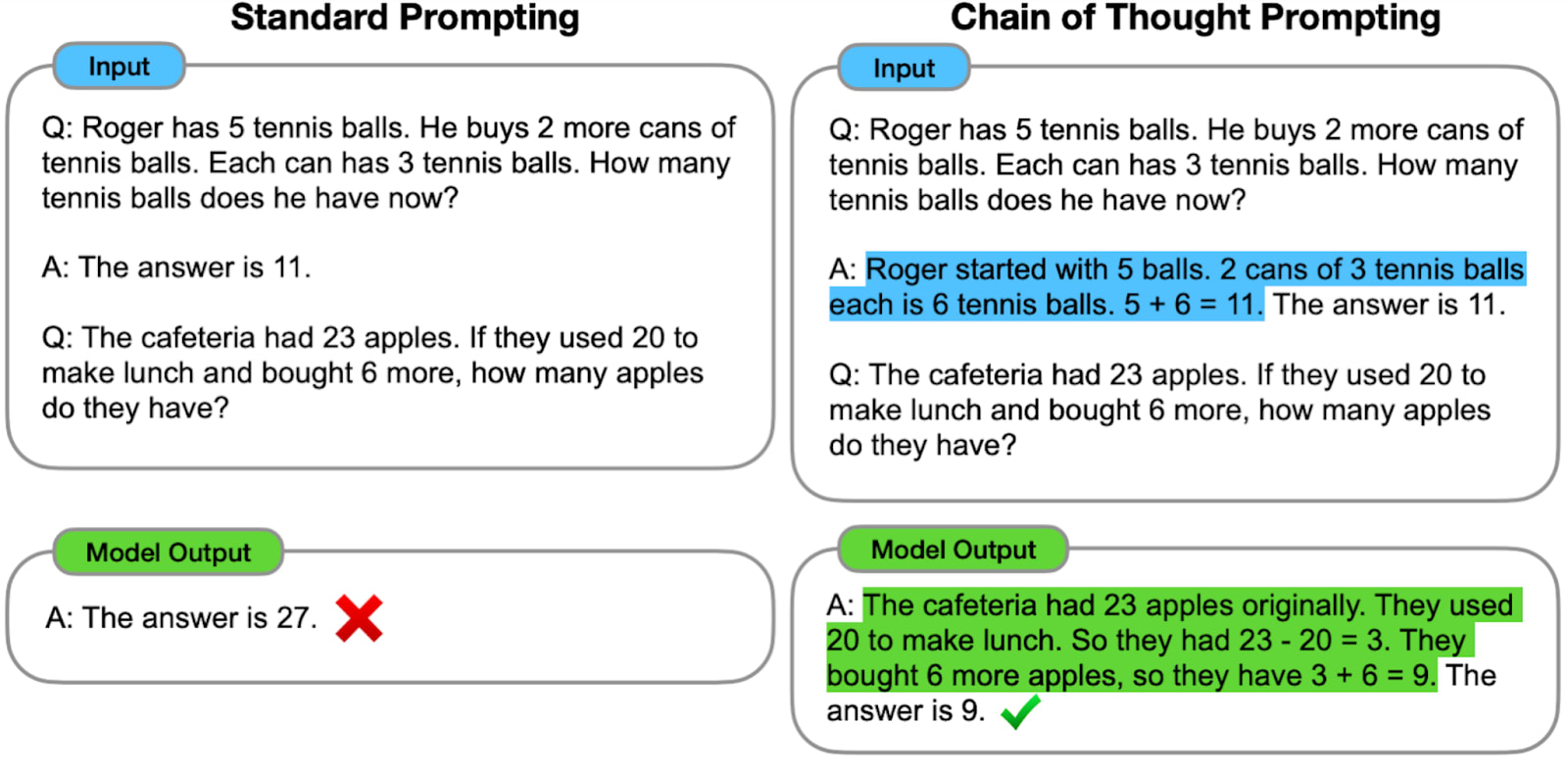
Instead of directly asking a language model a question, we can ask it to respond by detailing its reasoning. A bit like a student in elementary school, you don't just write the answer, you have to detail the calculation. This is the famous technique of asking the neural network to "think step by step": it significantly increases the performance of models. In the following figure, we go from 17.7% in zero shot (the model responds directly, without any other examples) to 78.7% with this technique.

The term "Chain of Thought" refers to a set of techniques designed to enhance the performance of language models by prompting them to provide step-by-step reasoning, rather than simply giving direct answers. These techniques include but are not limited to the one described in the previous text as "Let's think step by step".
Aside: Those technique also works on humans ^^ to become more optimistic, perform better, reason better, etc.
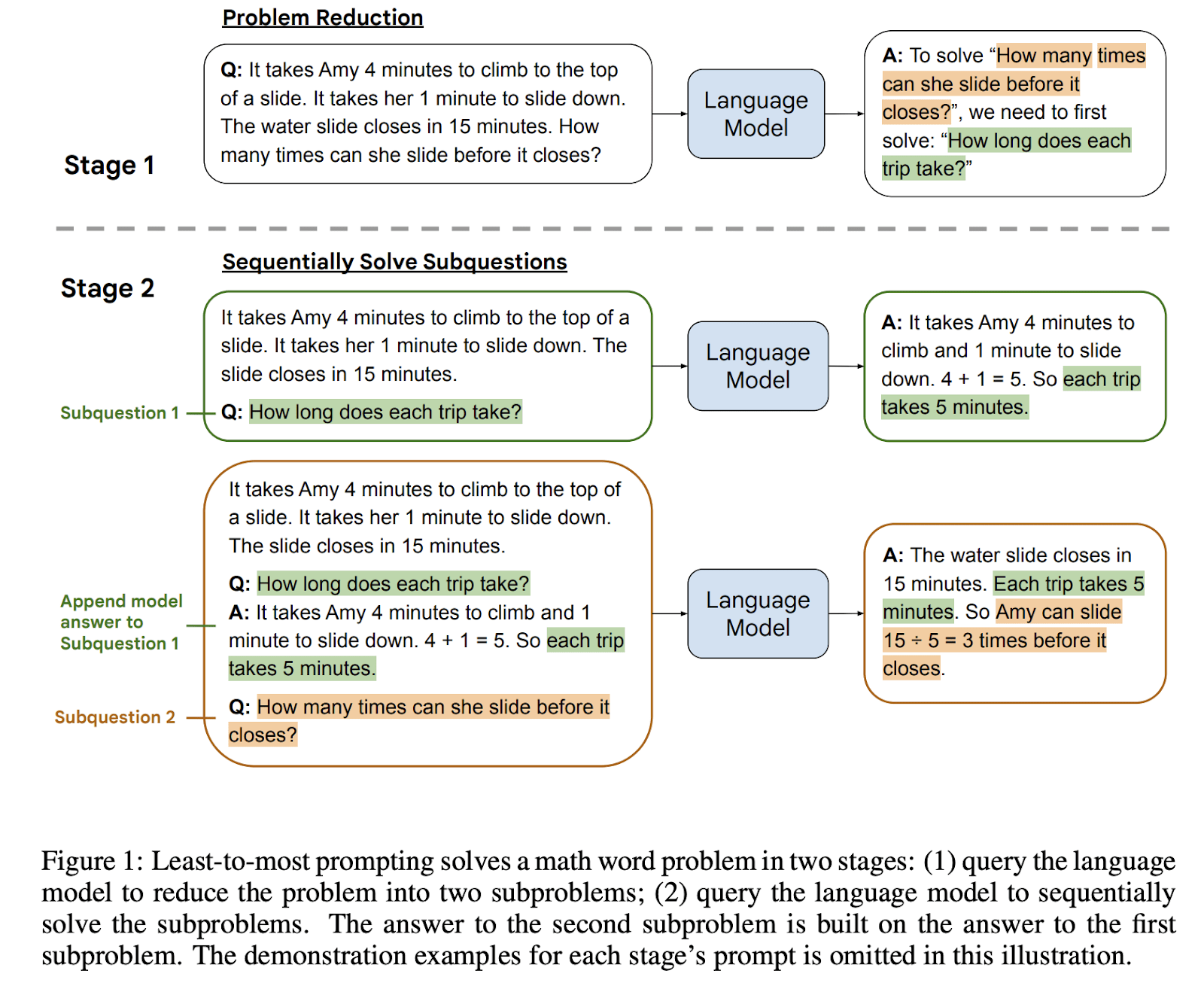
Least-to-Most Prompting (bonus)
Chain of thought is quite rudimentary. Least-to-Most Prompting is an advanced prompting technique and can be seen as a particular type of task decomposition. Compared with chain-of-thought prompting, it produces better answers by more explicitly decomposing tasks into multiple steps. This could potentially make the resulting outputs easier to supervise.
From Least-to-Most Prompting enables complex reasoning in large language models (Zhou et al., 2022): “Chain-of-thought prompting has a key limitation—it often performs poorly on tasks that require generalization of solving problems harder than those demonstration examples, such as compositional generalization. [...] Two stages:
- First, reducing a complex problem into a list of easier subproblems, [Least]
- and then sequentially solving these subproblems, whereby solving a given subproblem is facilitated by the answers to previously solved subproblems. [to-Most]
Both stages are implemented by few-shot prompting. So there is no training or fine-tuning in either stage.”
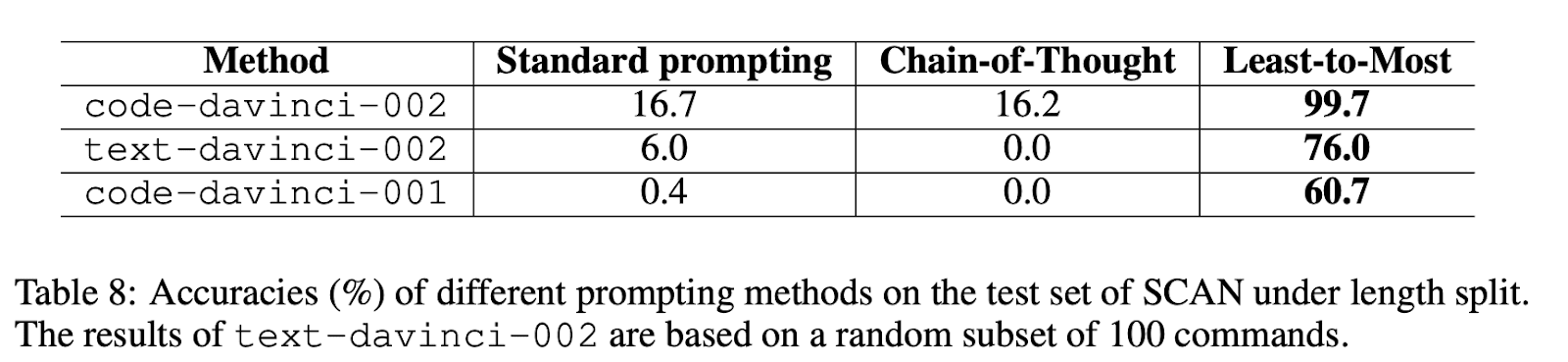
Results indicate that the Least-to-Most prompting technique can effectively solve problems in SCAN. GPT-3 goes from 16.2% with chain-of-thought to 99.7% with Least to Most prompting.

Unfaithful Chain-of-thought
Unfortunately, the paper Language Models Don't Always Say What They Think: Unfaithful Explanations in Chain-of-Thought Prompting shows that CoT explanations can misrepresent the true reason for a model's prediction.
From the abstract: “We demonstrate that CoT explanations can be heavily influenced by adding biasing features to model inputs [...] On a social-bias task, model explanations justify giving answers in line with stereotypes without mentioning the influence of these social biases. Our findings indicate that CoT explanations can be plausible yet misleading, which risks increasing our trust in LLMs without guaranteeing their safety. CoT is promising for explainability, but our results highlight the need for targeted efforts to evaluate and improve explanation faithfulness.”

Process supervision
In past papers, we have studied the possibility of decomposing reasoning or decomposing tasks in order, for example, to provide a better reward. A complementary way to engage with the task decomposition and the papers that have been presented previously is via the distinction: process-based training vs outcome-based training. End-to-end optimization can make the reasoning opaque, so we want the system to be built on human-understandable decomposition of reasoning, by supervising each reasoning step.
Process supervision in Anthropic plan
The clearest explanation of process supervision that I have come across can be found in Anthropic's plan titled "Core Views on AI Safety: When, Why, What, and How" specifically in the section on "Learning Processes Rather than Achieving Outcomes":
“One way to go about learning a new task is via trial and error – if you know what the desired final outcome looks like, you can just keep trying new strategies until you succeed. We refer to this as “outcome-oriented learning”. In outcome-oriented learning, the agent’s strategy is determined entirely by the desired outcome and the agent will (ideally) converge on some low-cost strategy that lets it achieve this.
Often, a better way to learn is to have an expert coach you on the processes they follow to achieve success. During practice rounds, your success may not even matter that much, if instead you can focus on improving your methods. As you improve, you might shift to a more collaborative process, where you consult with your coach to check if new strategies might work even better for you. We refer to this as “process-oriented learning”. In process-oriented learning, the goal is not to achieve the final outcome but to master individual processes that can then be used to achieve that outcome.
At least on a conceptual level, many of the concerns about the safety of advanced AI systems are addressed by training these systems in a process-oriented manner. In particular, in this paradigm:
- Human experts will continue to understand the individual steps AI systems follow because in order for these processes to be encouraged, they will have to be justified to humans.
- AI systems will not be rewarded for achieving success in inscrutable or pernicious ways because they will be rewarded only based on the efficacy and comprehensibility of their processes.
- AI systems should not be rewarded for pursuing problematic sub-goals such as resource acquisition or deception, since humans or their proxies will provide negative feedback for individual acquisitive processes during the training process.
At Anthropic we strongly endorse simple solutions, and limiting AI training to process-oriented learning might be the simplest way to ameliorate a host of issues with advanced AI systems. We are also excited to identify and address the limitations of process-oriented learning, and to understand when safety problems arise if we train with mixtures of process and outcome-based learning. We currently believe process-oriented learning may be the most promising path to training safe and transparent systems up to and somewhat beyond human-level capabilities.”
Supervise processes, not outcomes
Supervise processes, not outcomes (Stuhlmuller and Byun, 2022) [AF · GW]
The article begins by discussing the difference between process-based and outcome-based machine learning systems.
Although most machine learning systems result from a supervised learning process that optimizes the loss function, this should be viewed as a continuum. There are also examples of mostly process-based systems:
- Engineers and astronomers rely on a well-understood plan and well-understood modules to trust that the James Webb Space Telescope will work.
- Programmers rely on reasoning about the behavior of each function and line of code to ensure that their algorithms implement the intended behavior.
- Archaeologists rely on their ability to reason about the age of sediment layers and the minerals they contain to estimate the age of stone tools.
Empirical Works on Process Supervision
Procedure cloning (bonus)
One way to apply Ought's recommendations for training on processes rather than outcomes is described in the following paper: Chain of thought imitation with procedure cloning (Yang et al., 2022). Yang et al. introduce procedure cloning, in which an agent is trained to mimic not just expert outputs, but also the process by which the expert reached those outputs.
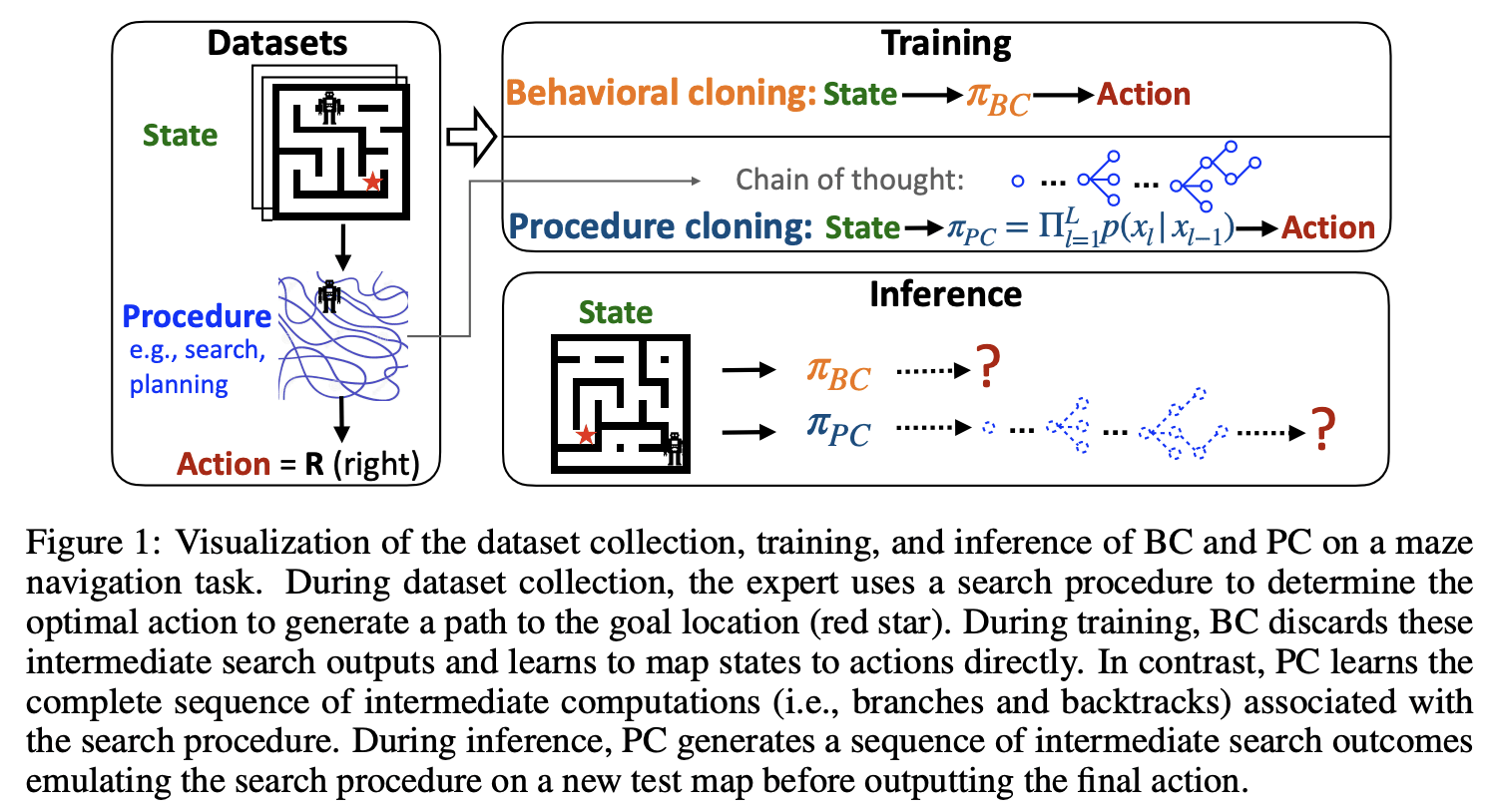
What does "Learn principles, not formulas. Understand, do not memorize” mean for autonomous agents? Chain of Thought Imitation with Procedure Cloning! Source: twitter thread.
Procedure cloning, unlike its counterpart, behavioral cloning (BC), leverages supervised sequence prediction to replicate not just the final expert decision but the entire series of computations that led to this decision. In essence, procedure cloning doesn't merely focus on the 'what' - the end action, but also pays attention to the 'how' and the 'why' - the underlying procedure.
The robustness of procedure cloning demonstrated a significant degree of generalization when confronted with unseen environmental situations such as unexplored maze designs, varying object positions, unpredictable transition patterns, and different game difficulty levels.
Process supervision for Maths
Process supervision was used recently by OpenAI for Improving Mathematical Reasoning with Process Supervision. The idea is simple: Just give a reward at each step, instead of a single reward at the end. But this requires a lot more human labeling.

In some cases, safer methods for AI systems can lead to reduced performance, a cost which is known as an alignment tax. In general, any alignment tax may hinder the adoption of alignment methods, due to pressure to deploy the most capable model. Our results below show that process supervision in fact incurs a negative alignment tax, at least in the math domain. This could increase the adoption of process supervision, which we believe would have positive alignment side-effects.
Conclusion
We have explored the concepts of scalable oversight, task decomposition, iterated amplification, and factored cognition, and their significance in AI systems. By employing techniques such as Chain of Thought, Least-to-Most prompting, and process supervision, we can not only enhance language model performance but also ensure their safety, suggesting that the alignment tax [? · GW] could, in fact, be cheap. But there are still a lot of uncertainties, important hypotheses and difficulties in those agendas. Via those research agendas, the lines between capability and safety research are becoming increasingly blurred.
0 comments
Comments sorted by top scores.