Constructability: Plainly-coded AGIs may be feasible in the near future
post by Épiphanie Gédéon (joy_void_joy), Charbel-Raphaël (charbel-raphael-segerie) · 2024-04-27T16:04:45.894Z · LW · GW · 13 commentsContents
Overview Would it be feasible? Track record of automated systems Track records of humans The Crux Would it be safe? Setting for safety Possible concerns Compared to other plans Getting out of the chair Constructing an ontology Segmenting the images Flowers 1. Constructing the Flower head detector 2. Constructing the Full Model Conclusion None 13 comments
Charbel-Raphaël Segerie and Épiphanie Gédéon contributed equally to this post.
Many thanks to Davidad, Gabriel Alfour, Jérémy Andréoletti, Lucie Philippon, Vladimir Ivanov, Alexandre Variengien, Angélina Gentaz, Simon Cosson, Léo Dana and Diego Dorn for useful feedback.
TLDR: We present a new method for a safer-by design AI development. We think using plainly coded AIs may be feasible in the near future and may be safe. We also present a prototype and research ideas on Manifund.
Epistemic status: Armchair reasoning style. We think the method we are proposing is interesting and could yield very positive outcomes (even though it is still speculative), but we are less sure about which safety policy would use it in the long run.
Current AIs are developed through deep learning: the AI tries something, gets it wrong, then gets backpropagated and all its weight adjusted. Then it tries again, wrong again, backpropagation again, and weights get adjusted again. Trial, error, backpropagation, trial, error, backpropagation, ad vitam eternam ad nauseam.
Of course, this leads to a severe lack of interpretability: AIs are essentially black boxes, and we are not very optimistic about post-hoc interpretability [LW · GW].
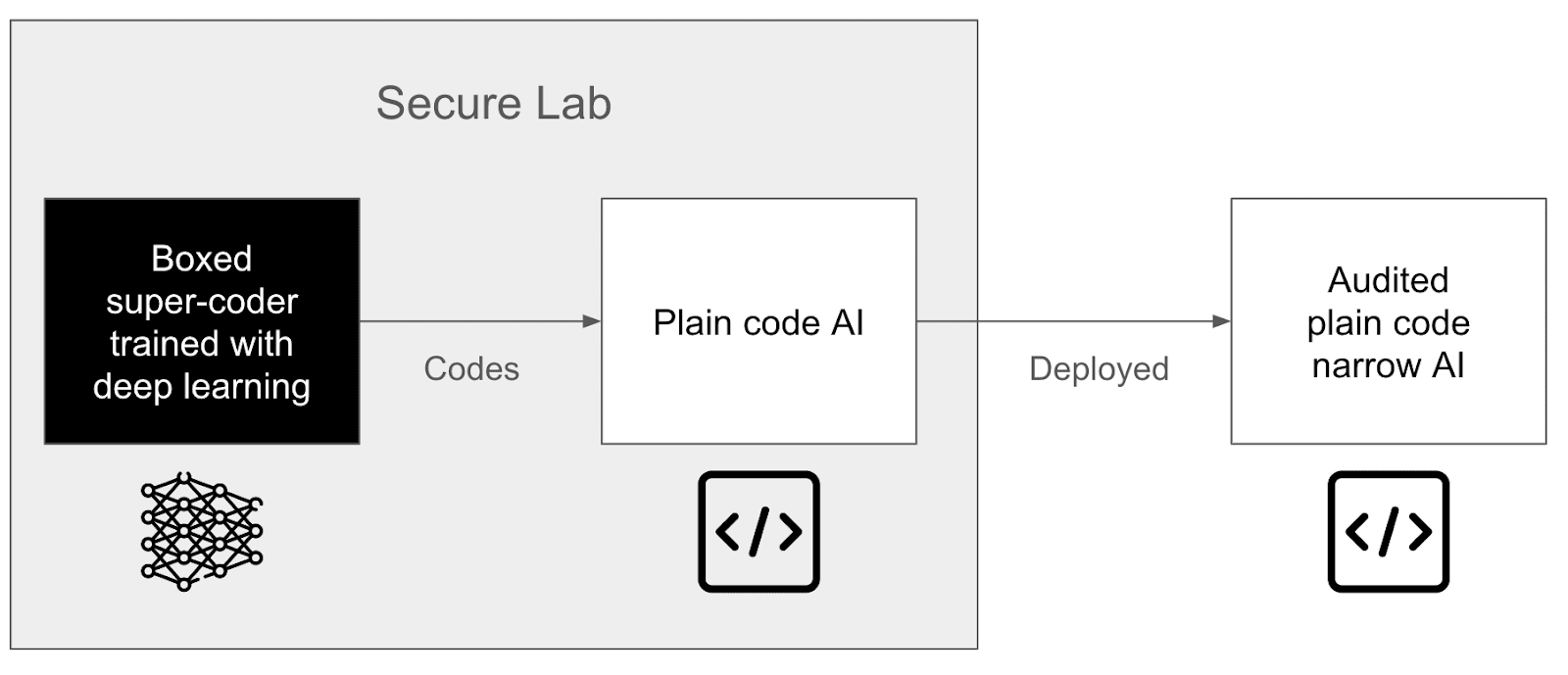
We propose a different method: Constructability or AI safety via pull request.[1]
By pull request, we mean that instead of modifying the neural network through successive backpropagations, we construct and design plainly-coded AIs (or hybrid systems) and explicitly modify its code using LLMs in a clear, readable, and modifiable way.
This plan may not be implementable right now, but might be as LLMs get smarter and faster. We want to outline it now so we can iterate on it early.
Overview
If the world released a powerful and autonomous agent in the wild, white box or black box, or any color really, humans might simply get replaced by AI.
What can we do in this context?
- Don't create autonomous AGIs.
- Keep your AGI controlled in a lab, and align it.
- Create a minimal AGI controlled [LW · GW] in a lab, and use it to produce safe artifacts.
- This post focuses on this last path, and the specific artifacts that we want to create are plainly coded AIs (or hybrid systems)[2].
We present a method for developing such systems with a semi-automated training loop.
To do that, we start with a plainly coded system (that may also be built using LLMs) and iterate on its code, adding each feature and correction as pull requests that can be reviewed and integrated into the codebase.
This approach would allow AI systems that are, by design:
- Transparent: As the system is written in plain or almost plain code, the system is more modular and understandable. As a result, it's simpler to spot backdoors, power-seeking behaviors, or inner misalignment: it is orders of magnitude simpler to refactor the system to have a part defining how it is evaluating its current situation and what it is aiming towards (if it is aiming at all). This means that if the system starts farming cobras instead of capturing them, we would be able to see it.
- Editable: If the system starts to learn unwanted correlations or features - such as learning to discriminate on feminine markers for a resume scorer - it is much easier to see it as a node in the AI code and remove it without retraining it.
- Overseeable: We can ensure the system is well behaved by using automatic LLM reviews of the code and by using automatic unit tests of the isolated modules. In addition, we would use simulations and different settings necessary for safety, which we will describe later.
- Version controlable: As all modifications are made through pull requests, we can easily trace with, e.g., git tooling where a specific modification was introduced and why.
In practice, we would first use hybrid systems, that use shallow specialized networks that we can understand well for some small tasks, and then iterate on it:
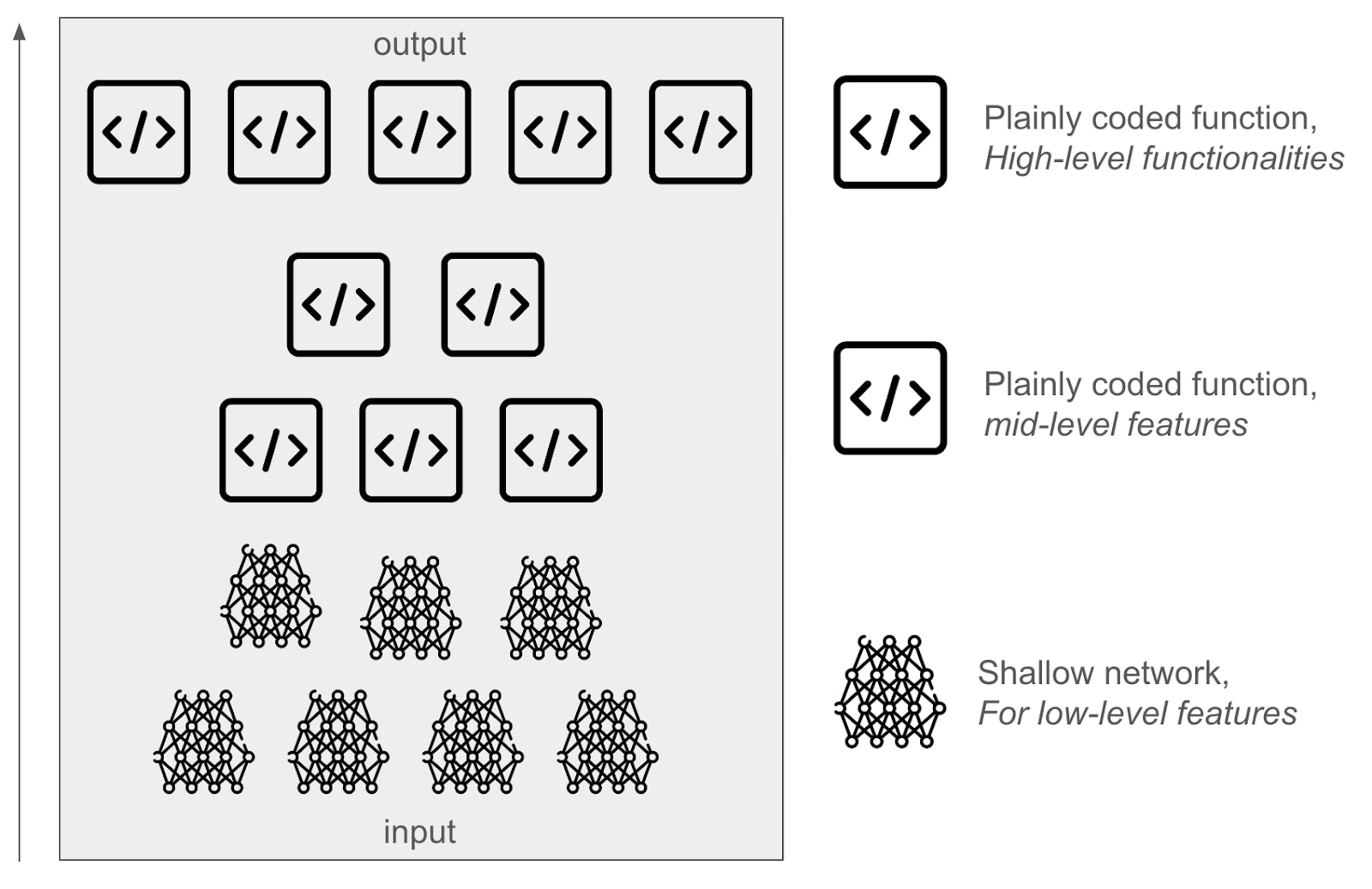
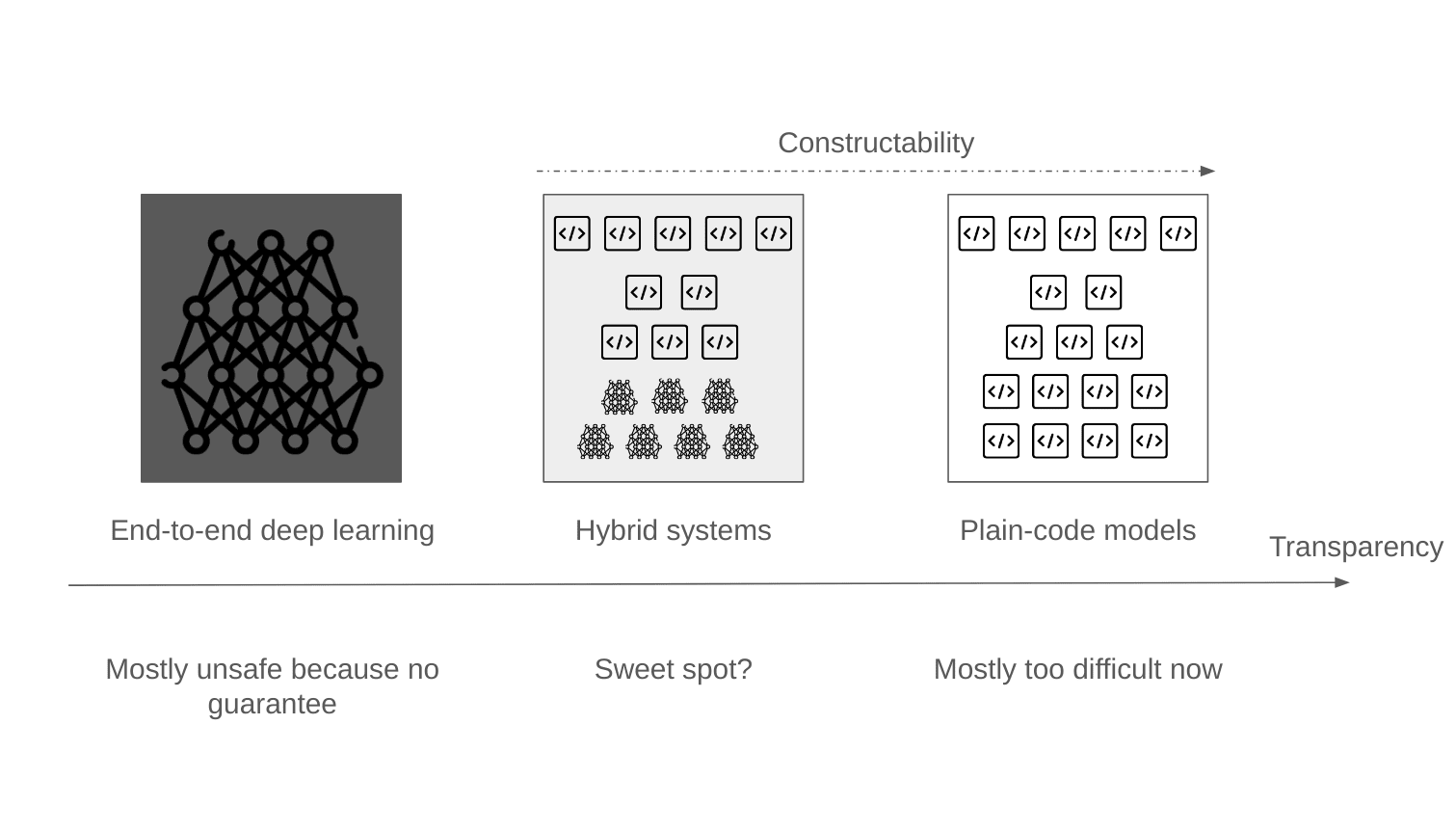
Overall, we want to promote an approach like Comprehensive AI Services [? · GW]: Having many specialized systems that do not have full generality, but that may compose together (for instance, in the case of a humanoid housekeeper, having one function to do the dishes, one function to walk the dog, …). Our hope is to arrive at a method to train models that outperform opaque machine learning in some important metrics (faster inference time, faster and more modifiable training, more data efficient, and more modifiable code) while still being safer.
Okay, now your reaction should be: “Surely this just won’t work”.
Let’s analyze this: why we think this approach is feasible and how safe it would be.
Would it be feasible?
Track record of automated systems
Our idea is nothing short of automating and generalizing something humans have been doing for decades: creating expert narrow systems.
For example, Stockfish is a superhuman chess engine that did not use deep learning before 2020. It was quite understandable then and has an automatic system for testing pull requests.
In particular, note that Stockfish improved by more than 700 elos during this period while keeping its code length about constant[3], which gives significant credence to the claim that it might just be possible to iterate on a system and make it superhuman without having the codebase explode in size.
AIs have also been able to create explicit code for features we had only been able to express via deep learning so far. For example, in Learning from Human Preferences it seemed like getting the essence of a proper backflip in a single hand-crafted function would always be inferior to Reinforcement Learning from Human Feedback:
 | |
| RLHF learned to backflip using around 900 individual bits of feedback from the human evaluator. | Manual reward crafting: “By comparison, we took two hours to write our own reward function (the animation in the above right) to get a robot to backflip, and though it succeeds, it’s a lot less elegant than the one trained simply through human feedback.” |


But, since then, we have seen Eureka, which generates reward functions that outperform expert human-engineered rewards:

Like Stockfish, Eureka continues improving while keeping its reward function short:

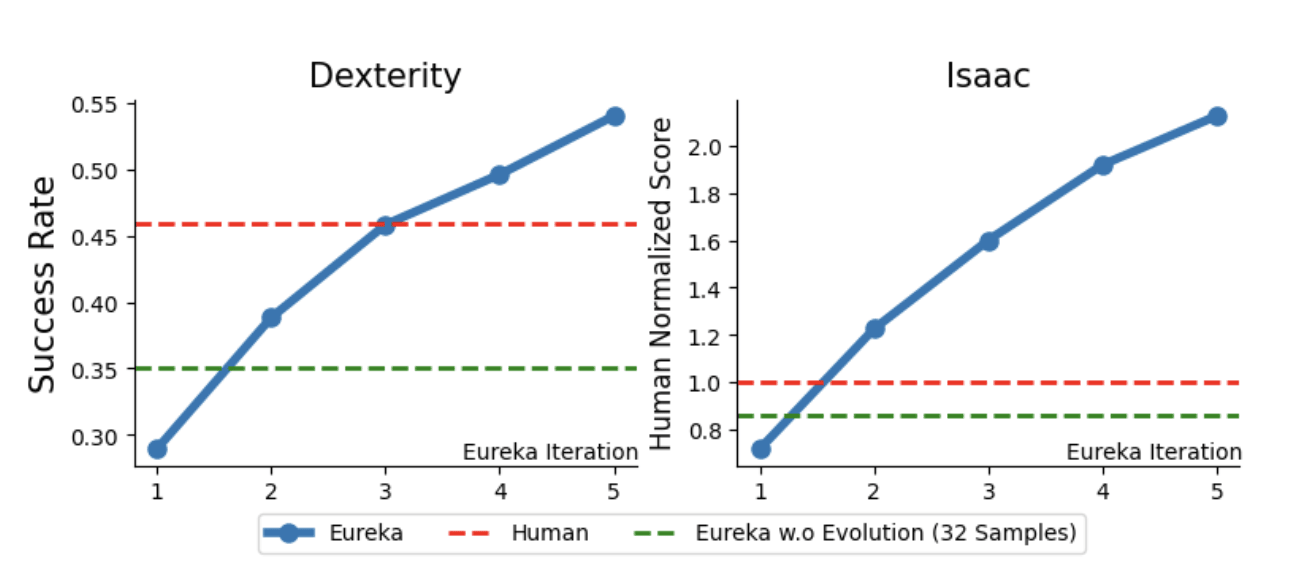
Eureka is very similar to what we want to do. Only, instead of writing the reward functions, we would write explicitly all the agent's code.
Voyager in Minecraft is even closer to what we are proposing: an agent that interacts with the world and that codes functions to broaden its abilities. In Voyager, you can read the lines of code generated by GPT, you know what it can do and what it can't do, and you have much more control than with reinforcement learning.
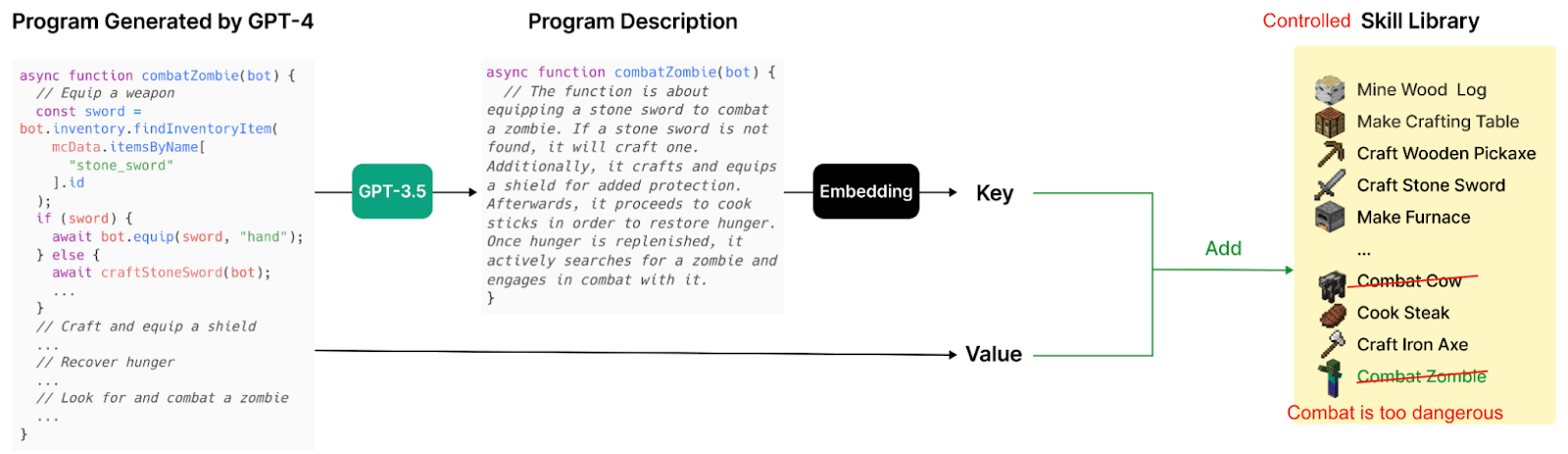
The main difference with us is that Voyager codes function on the fly, function by function, while we would validate the whole codebase before unleashing the agent, and we would remove dangerous skills like "Combat humans" beforehand. No continuous learning.
Track records of humans
Besides chess engines, it is possible to create systems that tackle useful tasks in plain-code:
- Watson: Watson is an expert system capable of answering questions in natural language. It won Jeopardy against the champions in 2011!
- Moon landing: Humans have been able to create the automatic pilot of the moon landing.
- Face detectors: Humans created face detectors before Deep Learning (which you might know if you used one of those old numerical cameras back in 2005).
- Language Tool: Language tool is a grammar and spell-checker software that was started in 2003 and now has 75k commits.
- Wolfram Alpha: an engine that can answer questions, solve problems, and provide insights across a wide range of topics, including mathematics, science, engineering, and more. It uses a vast collection of algorithms and knowledge curated by experts.[4]

But, you might say, humans have not been able to solve Go or Imagenet without deep learning.
The Crux
On the one hand, humans are not particularly good and fast at coding, so plain-code approaches to Go or Imagenet might actually work well if coded with competent models. As AI becomes more advanced and potentially transformative, it may be capable of coding systems as complex as Google.
For now, Devin, an automated software engineer, has only been released last month, and it seems likely that we are headed in that direction:
"GPT2030 will likely be superhuman at various specific tasks, including coding, hacking, and math, and potentially protein design [...] The organization that trains GPT2030 would have enough compute to run many parallel copies: I estimate enough to perform 1.8 million years of work when adjusted to human working speeds."
Watson was about 100 years*person[5], and 1.8M years of work is in the ballpark of the effort put into the Google codebase.[6]
On the other hand, it may be the case that coding a system better than AlphaZero at Go from scratch proves extremely difficult compared to coding the entirety of the Google codebase.
Whether it is even possible to code a system that beats AlphaZero or GPT-2 with plain-code or hybrid system, as opposed to systems that are fully connected like transformers, seems like a central crux that we name “non-connectionism scalability”: How necessary is it for models to be connectionists for their performance to be general and human-like, as opposed to something more modular and explainable.
Having a plain-coded model that beats AlphaZero may not be as impossible as it sounds. For instance, this paper has succeeded in extracting superhuman chess concepts from AlphaZero and teaching those concepts to chess grandmasters. This shows that it is possible to have well-encapsulated concepts learned from AlphaZero, even though we still need to code them. More generally, the human brain is complex, but only finitely complex, so it might be possible to extract relevant learned concepts from neural networks iteratively.
There are 100M lines of code in MacOS. If someone learns one new concept each minute for 20 years, that's only 10M concepts. If you need 10 lines of code per concept, that's also 100M lines of code, and we will be helped by AIs to code them.
What about the Bitter Lesson? We think it is not in contradiction with our plan. The Bitter Lesson is mostly saying: “Compute + Search is necessary”. But it’s not saying “Deep Learning is necessary”. And we would follow the Bitter Lesson because we want to leverage compute and search at scale.
Would it be safe?
Epistemic status: Uncertain. This part will explore some potential plans and settings that would use this method. However, that plan is distinct from the method of constructability itself.
Setting for safety
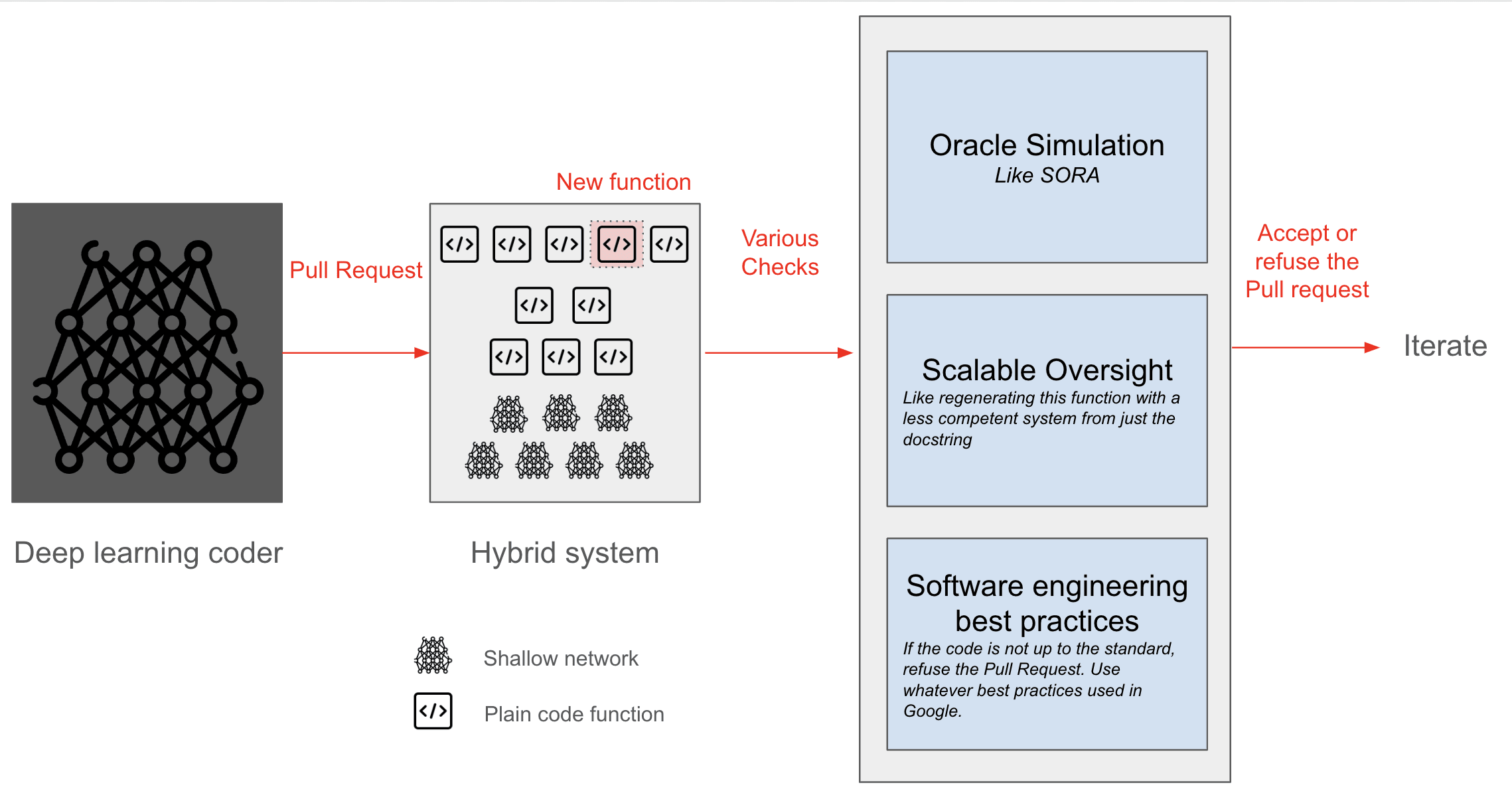
Minimal super-coder: We already have super-powerful systems for generating images, movies, music, playing Go, and translation, all without dying, which is already kind of surprising. The authors thought before that full agency would be necessary to create good music. This is not [LW · GW] the case. Similarly, we want to create an automatic GitHub issue resolver. This is kind of dangerous but it can be seen as a translator, not from English → French, but something like an issue → pull request. As strong as a very good human, but not as strong as the best human. Except that it does it at scale, full throttle.
Coordination: We need a multinational agreement requiring all “powerful” AIs to be boxed in AI labs.
AI control: We need a very powerful coder-AI to code our AI, but the only current way to create such an AI today is via deep learning, and we cannot guarantee its safety. This is why we need to box this AI, which could be done with the AI control plan [LW · GW].
Audit of the code: The code produced by this AI needs to be verified, but the code might be huge. This is why we need scalable oversight. Only the audited plain-code AI would then be deployed. We could have many different plain-coded AI for different types of tasks.
Software engineering best practices: The code should not be merged if the code does not follow the best practices from Google or whatever. For example, integrating many unnitests, the same way SQLlite is very thoroughly tested: for every line of code, they have 590 lines of tests. And it's a beautiful story because even if they didn't use provably safe code, they still managed to create one of the most secure and deployed applications in the world. To create these unnitests, we can use LLM itself and then start trying to break them to find holes with aggressive Reinforcement Learning like in this paper.
Simulations: It may be costly to iterate directly in the real world. Suppose you have a robot that learns to do the dishes. In that case, you can first iterate in a simulation of the world, like SORA or Genie (e.g., by prompting: “The left arm moves left 20 degrees up” → oh no, the film shows that the plate breaks and kills a human 🙁). Then, after a few iterations in the simulation and after careful human auditing, you could deploy it in the real world. The simulation itself would be checked for bugs by automatic reviews and subsequently fine-tuned. Using a simulation would further help reduce the chance that something terrible happens in real life.
Possible concerns
Unstable coordination: Labs need to refrain from using directly the powerful AIs in the wild, which seems very unstable. The world does not seem to be headed in this direction, but we think about coordination as necessary even if our plan did not exist.
Deep deception: A working hypothesis we have made so far is that we can neglect deep deception [LW · GW]. To prevent deep deception for a general superhuman system, the only way we know of is to write formal proofs inside giant simulations (a la davidad [LW · GW]). However, we think deep deception is probably overestimated as a concern and this is a working hypothesis for most plans.
Code leak: If there is a code leak, even with transparency, a powerful system remains dangerous in the hands of bad actors.
Improved capabilities: If this plan does work, there is a chance this could boost capabilities and lead to Recursive Self-Improvement [? · GW] or compute overhang [? · GW], which would render the situation hard to control. That said we don't think our plan will create a more powerful AI than deep learning itself, and as this project is still a moonshot, we are not too worried about this yet (if we get something working, we will open the champagne). But it might be the case that a plain-code system could sometimes allow an absurd inference speed or data efficiency.
Misgeneralization and specification gaming: One worry is that the AI code starts to evolve against the wrong specification or goal. For instance, when it learns “go to the right” instead of “target the coin”. We believe this can be avoidable with refactors, along with LLM explaining the used heuristics and simulating the agent’s behaviour well.
Compared to other plans
While there are many valid criticisms of this plan in the absolute sense, we believe this approach is as reasonable as other agendas, for instance, in comparison with:
- Interpretability: If plain code AI works, it would be at least as safe as solving interpretability.
- Davidad’s bold plan: Our plan is similar to Davidad’s [LW · GW], but he wants proof; we only want transparency. Creating legible code should be orders of magnitude easier than proving it.
- Other safe-by-design approaches: Most safe-by-design approaches seem to rely heavily on formal proofs. While formal proofs offer hard guarantees, they are often unreliable because their model of reality needs to be extremely close to reality itself and very detailed to provide assurance.
- CoEm: More info on CoEM here. CoEm, as well as the plan we describe, both rely on the notion of compositionality. However, they are more interested in making a powerful language model while we don’t specifically focus on any kind of system.
- OpenAI’s Superalignment: Instead of creating a system that creates zillions of AI safety blog posts, we create zillions of lines of code. But we think it would be easier for us to verify the capabilities of our systems than for OpenAI to verify the plans that are created and our metrics more straightforward.
Getting out of the chair
So far, our post has discussed technologies and possibilities in the near future. The question of what is possible right now is still open, but many hypotheses are already testable:
- Scalability: How much can this loop actually work and learn complex patterns, especially for concepts that are not easily encoded, like image recognition?
- Compositionality: A core aspect of our plan is that we can decompose a complex neural network into many isolated and reviewable parts. This may not necessarily hold.
- Understandability: Even if compositionality does hold, is it easy to understand parts and subparts of the model?
- Maintainability: Is it actually possible for this PR loop to be reviewable and does it lead to well-encapsulated features? In addition, is it overseeable, and how unmaintainable does the codebase become?
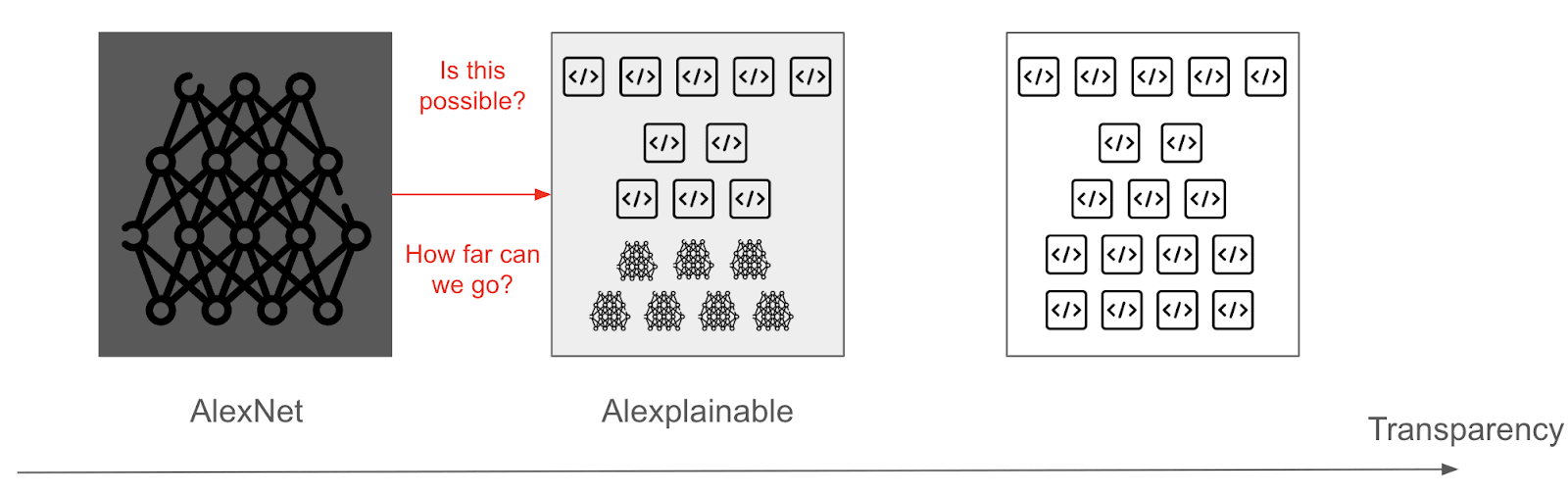
To test these assumptions, we have explored what it could look like to make an imagenet recognizer that does not use too much deep learning (up to 3 layers and 1000 neurons by net).
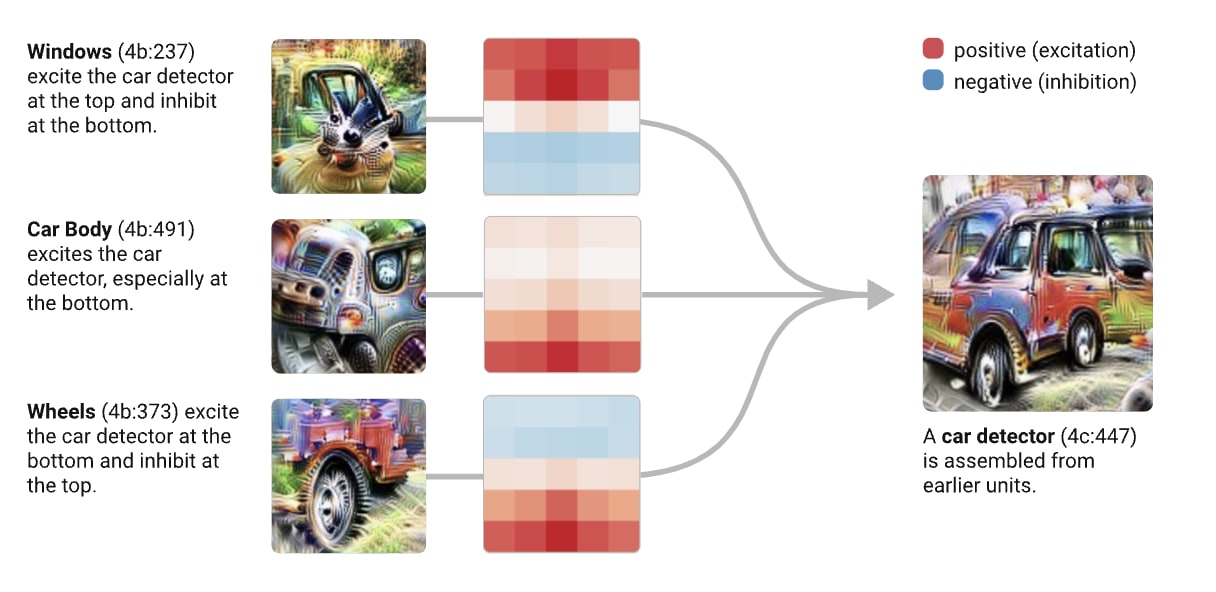
We made the assumption that it was possible to construct circuits similar to deep-learned ones from the ground up. This convolution net uses the ontology “Window + Car body + Wheels → Car.”
The overall idealized and automatic process as we have envisionned it is:
- Construct an ontology to recognize a class of image
- Segment images and sort the segments into different classes according to this ontology
- Train composited shallow networks on the segments
- Use an automatic PR loop that contains visualization of the trained network
- …
- Profit
Constructing an ontology
The idea of an ontology for image recognition is to have a graph that describes how features compose together.
We wanted to see if Claude could construct this ontology by first providing it with one, and then iterate to integrate each specificity of the images of the training dataset:

The resulting ontology does seem to hold fairly well. In particular, (construction company information + safety warnings) → signs posted → temporary fence is exactly the sort of composition we had in mind.
One concern is that it could grow out of hand. For instance, in the process above, the ontology grows linearly. There is probably a way to have Claude refactor this ontology every n images in a way that keeps all important elements.
Segmenting the images
Using segment-anything we have been able to obtain fairly well segmented images:

Flowers

We have in particular focused on how to recognize flowers (imagenet class n119) with this process.
For n119, we have used the following simple ontology:
- n119
- Flower head
- Petal
- Disk
- Leaf
- Stem
- Flower head
Here are the results:
1. Constructing the Flower head detector
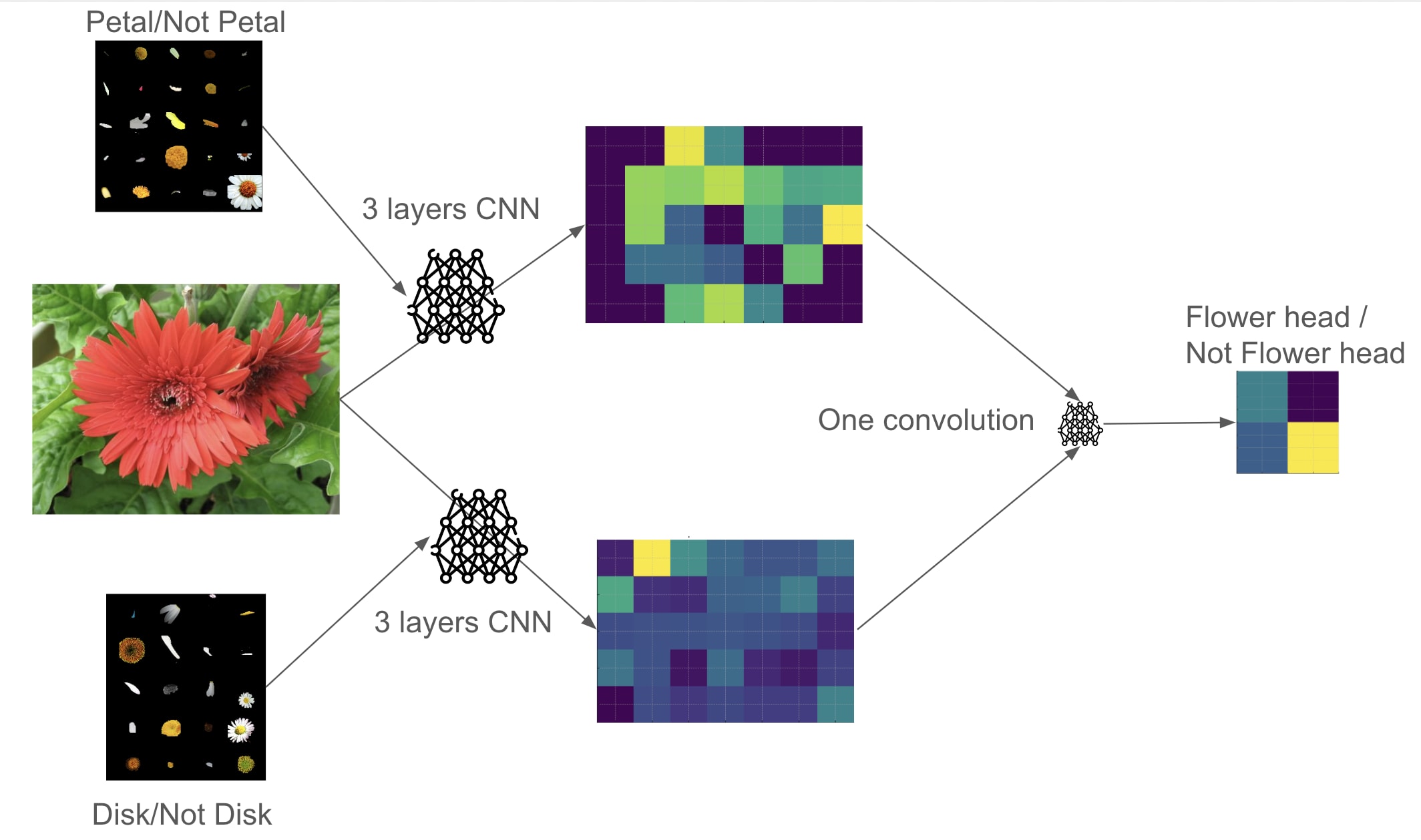
- Flower head: 85% acc - 25 parameters (579 positive sample)
- Petal: ~90% acc - 960-parameters (2000 positive samples)
- Disk: ~90% acc - 960-parameters (300 positive samples)
Compositionality does seem to hold: from one network trained specifically on petals/not-petal, and one trained specifically on disks/not-disks, we have been able to train one that recognizes flower heads at 85% very reliably.
- More interestingly, we have been able to swap the petal recognizer network with another petal recognizer trained on a different seed and slightly different dataset, without a noticeable drop in accuracy! This shows that it might be possible to have a good compositioned system that can be reviewed and refactored without requiring retraining other parts of the network.
- Furthermore, the convolution networks were only trained on the segments themselves, against a black background, and did not have any positive sample of them in context (for instance the petal network was tasked with classifying lone petals). Yet some of them can recognize the features they were trained on fairly well.
2. Constructing the Full Model
- n119 - 25 parameters
- Flower head: 85% acc - single convolution - 25 parameters
- Petal
- Disk
- Leaf: ~90% acc - CNN - 960 parameters
- Stem: ~90% acc - CNN - 960 parameters
- Flower head: 85% acc - single convolution - 25 parameters
We have been able to scale to 76% accuracy on a balanced dataset of n119 and non-n119, with networks each less than three convolution layers and less than 1000 parameters, compared to pure deep-learning which does 92% on 1000 parameters and three convolution layers
More details in this GitHub.
Conclusion
We think the argument we made for feasibility is very reasonable for the path towards Comprehensive AI Services in the setting that we describe, and that the argument we made for safety is a bit weaker.
We think that constructability is neglected, important, and tractable. If you like this idea and want it to see it scale, please upvote us on this Manifund, that contains many more research ideas that we want to explore.
Of course, the priority of the Centre pour la sécurité de l'IA will remain safety culture [LW · GW] as long as people in the world continue aiming blindlessly [LW · GW]towards the event horizon [LW · GW], and we think this plan is one way to promote it.
Work done in the Centre pour la sécurité de l'IA - CeSIA.
- ^
We debated the name and still are unsure which fits better. Do let us know about better names in the comments.
- ^
Ideally, we would want something only written in plain code. For now, however, as deep-learning is likely necessary to create capable systems, we will also discuss hybrid models using shallow neural networks aimed at very narrow tasks and which training data makes it unlikely to have learned anything more complex. Of course, the fewer neural networks and heuristics, the better.
- ^
Using its github, to evaluate its number of lines of code from sf-1.0 to sf-10, we can see that it stagnates at about 14k. On the other hand, using computerchess we can see that its elo went from 2748 elo to 3528.
- ^
Wolfram wanted to do something similar to us, but using only expensive human developers.
- ^
From Wikipedia: a team of ~15 for ~5 years.
- ^
30k engineers for 20 years = 0.6 million years of work.
- ^
For instance, something like the critical level in the RSP.
- ^
We need a deep learning simulation because we think it is too hard to create a complete sim in plain code. Even GPT-V is incomplete.
- ^
Thanks to Davidad for suggesting this idea.
- ^
Of course, we think the global priority should not be working on this plan, but remains safety culture [LW · GW] till people in the world continue aiming blindlessly to create autonomous replicators in the wild.
- ^
We wanted to automatically sort the segments in their designed classes with either of LLaVA or Claude. However, this proved too unreliable, and we have resorted to sorting the segments manually for this prototype.
- ^
ImageNet class n11939491, composed mostly of daisy flowers, but not only
13 comments
Comments sorted by top scores.
comment by Rafael Kaufmann Nedal (rafael-kaufmann-nedal) · 2024-04-28T14:53:38.876Z · LW(p) · GW(p)
@Épiphanie Gédéon [LW · GW] this is great, very complementary/related to what we've been developing for the Gaia Network [LW · GW]. I'm particularly thrilled to see the focus on simplicity and incrementalism, as well as the willingness to roll up one's sleeves and write code (often sorely lacking in LW). And I'm glad that you are taking the map/territory problem seriously; I wholeheartedly agree with the following: "Most safe-by-design approaches seem to rely heavily on formal proofs. While formal proofs offer hard guarantees, they are often unreliable because their model of reality needs to be extremely close to reality itself and very detailed to provide assurance."
A few additional thoughts:
- To scale this approach, one will want to have "structural regularizers" towards modularity, interoperability and parsimony. Two of those we have strong opinions on are:
- A preference for reusing shared building blocks and building bottom-up. As a decentralized architecture, we implement this preference in terms of credit assignment, specifically free energy flow accounting.
- Constraints on the types of admissible model code. We have strongly advocated for probabilistic causal models expressed as probabilistic programs. This enables both a shared statistical notion of model grounding (effectively backing the free energy flow accounting as approximate Bayesian inference of higher-order model structure) and a shared basis for defining and evaluating policy spaces (instantly turning any descriptive model into a usable substrate for model-based RL / active inference).
- Learning models from data is super powerful as far as it goes, but it's sometimes necessary -- and often orders of magnitude more efficient -- to leverage prior knowledge. Two simple and powerful ways to do it, which we have successfully experimented with, are:
- LLM-driven model extraction from scientific literature and other sources of causal knowledge. This is crucial to bootstrap the component library. (See also our friends at system.com.)
- Collaborative modeling by LLM-assisted human expert groups. This fits and enhances the "pull request" framework perfectly.
- Scaling this to multiple (human or LLM) contributors will require a higher-order model economy of some sort. While one can get away with an implicit, top-down resource economy in the context of a closed contributor group, opening up will require something like a market economy. The free energy flow accounting described above is a suitable primitive for this.
I'd be keen to find ways to collaborate.
Also @Roman Leventov [LW · GW] FYI
Replies from: joy_void_joy↑ comment by Épiphanie Gédéon (joy_void_joy) · 2024-04-29T13:50:06.005Z · LW(p) · GW(p)
Thanks a lot for the kind comment!
To scale this approach, one will want to have "structural regularizers" towards modularity, interoperability and parsimony
I am unsure of the formal architecture or requirements for these structural regularizers you mention. I agree with using shared building blocks to speed up development and verification. I am unsure credit assignment would work well for this, maybe in the form of "the more a block is used in a code, the more we can trust it"?
Constraints on the types of admissible model code. We have strongly advocated for probabilistic causal models expressed as probabilistic programs.
What do you mean? Why is this specifically needed? Do you mean that if we want to have a go-player, we should have one portion of the code dedicated to assigning probability to what the best move is? Or does it only apply in a different context of finding policies?
Scaling this to multiple (human or LLM) contributors will require a higher-order model economy of some sort
Hmm. Is the argument something like "We want to scale and diversify the agents who will review the code for more robustness (so not just one LLM model for instance), and that means varying level of competence that we will want to figure out and sort"? I had not thought of it that way, I was mainly thinking of just using the same model, and I'm unsure that having weaker code-reviewers will not bring the system down in terms of safety.
Regarding the Gaia Network, the idea seems interesting though I am unclear about the full details yet. I had thought of extending betting markets to a full bayesian network to have a better picture of what everyone believe, and maybe this is related to your idea. In any case, I believe that conveying one's full model of the world through this kind of network and maybe more may be doable, and quite important to solve some sort of global coordination/truth seeking?
Overall I agree with your idea of a common library and I think there should be some very promising iterations on that. I will contact you more about colaboration ideas!
comment by Charbel-Raphaël (charbel-raphael-segerie) · 2024-04-27T16:23:20.144Z · LW(p) · GW(p)
[We don't think this long term vision is a core part of constructability, this is why we didn't put it in the main post]
We asked ourselves what should we do if constructability works in the long run.
We are unsure, but here are several possibilities.
Constructability could lead to different possibilities depending on how well it works, from most to less ambitious:
- Using GPT-6 to implement GPT-7-white-box (foom?)
- Using GPT-6 to implement GPT-6-white-box
- Using GPT-6 to implement GPT-4-white-box
- Using GPT-6 to implement Alexa++, a humanoid housekeeper robot that cannot learn
- Using GPT-6 to implement AlexNet-white-box
- Using GPT-6 to implement a transparent expert system that filters CVs without using protected features
Comprehensive AI services path
We aim to reach the level of Alexa++, which would already be very useful: No more breaking your back to pick up potatoes. Compared to the robot Figure01, which could kill you if your neighbor jailbreaks it, our robot seems safer and would not have the capacity to kill, but only put the plates in the dishwasher, in the same way that today’s Alexa cannot insult you.
Fully autonomous AGI, even if transparent, is too dangerous. We think that aiming for something like Comprehensive AI Services would be safer. Our plan would be part of this, allowing for the creation of many small capable AIs that may compose together (for instance, in the case of a humanoid housekeeper, having one function to do the dishes, one function to walk the dog, …).
Alexa++ is not an AGI but is already fine. It even knows how to do a backflip Boston dynamics style. Not enough for a pivotal act, but so stylish. We can probably have a nice world without AGI in the wild.
The Liberation path
Another possible moonshot theory of impact would be to replace GPT-7 with GPT-7-plain-code. Maybe there's a "liberation speed n" at which we can use GPT-n to directly code GPT-p with p>n. That would be super cool because this would free us from deep learning.
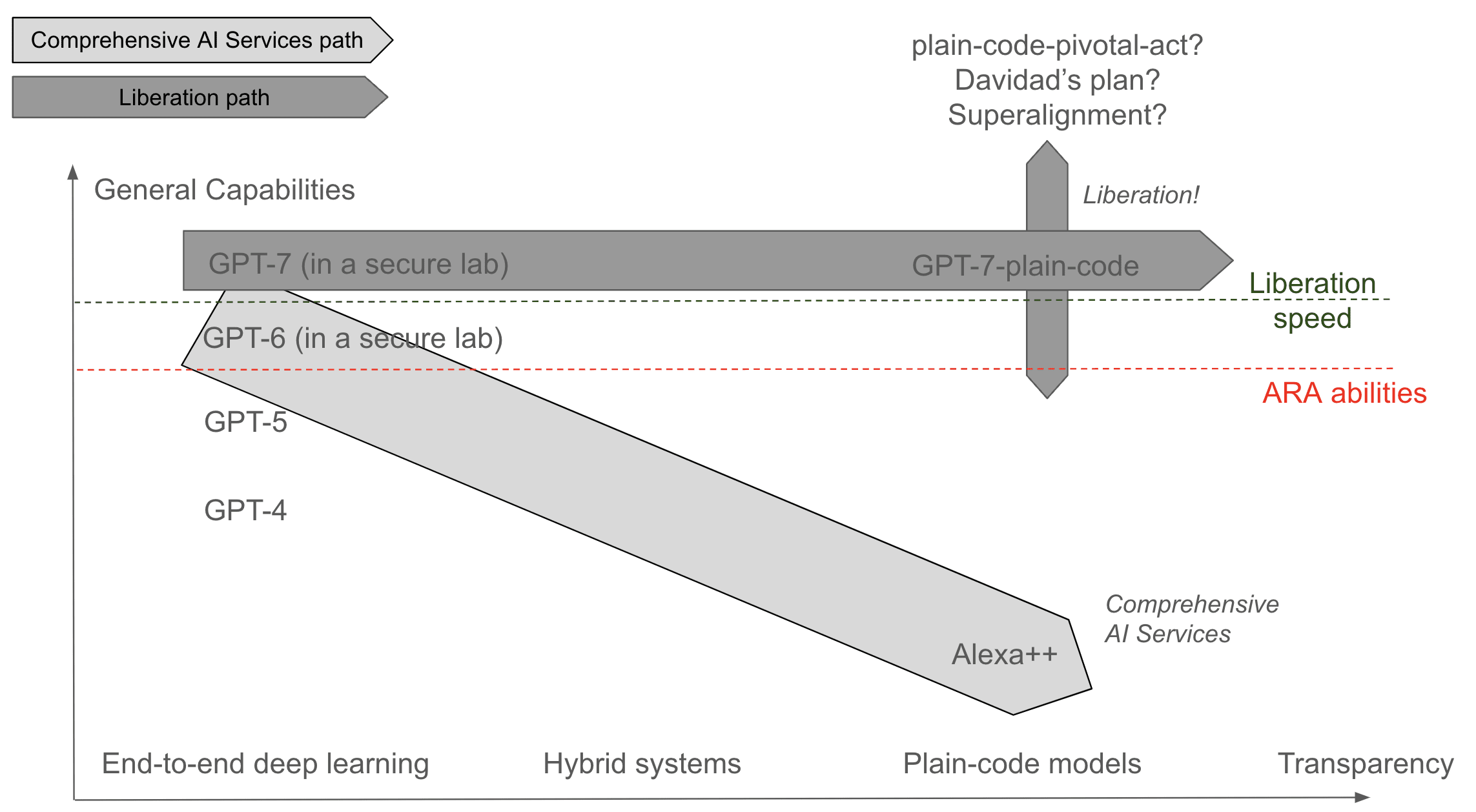
Guided meditation path
You are not really enlightened if you are not able to code yourself.
Maybe we don't need to use something as powerful as GPT-7 to begin this journey.
We think that with significant human guidance, and by iterating many many times, we could meander iteratively towards a progressive deconstruction of GPT-5.
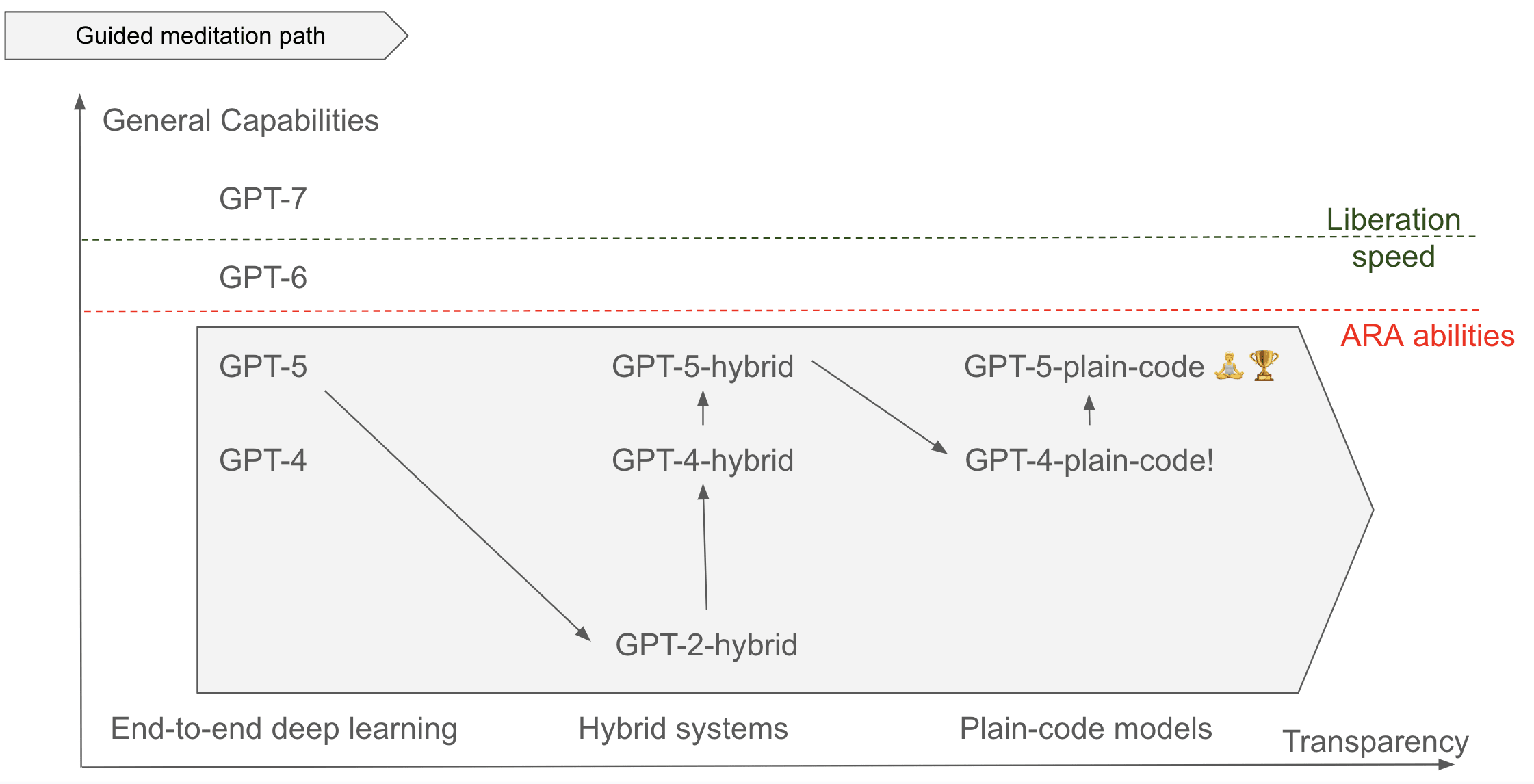
- Going from GPT-5 to GPT-2-hybrid seems possible to us.
- Improving GPT-2-hybrid to GPT-3-hybrid may be possible with the help of GPT-5?
- ...
If successful, this path could unlock the development of future AIs using constructability instead of deep learning. If constructability done right is more data efficient than deep learning, it could simply replace deep learning and become the dominant paradigm. This would be a much better endgame position for humans to control and develop future advanced AIs.
| Path | Feasibility | Safety |
|---|---|---|
| Comprehensive AI Services | Very feasible | Very safe but unstable in the very long run |
| Liberation | Feasible | Unsafe but could enable a pivotal act that makes things stable in the long run |
| Guided Meditation | Very Hard | Fairly safe and could unlock a safer tech than deep learning which results in a better end-game position for humanity. |
comment by localdeity · 2024-04-29T10:04:38.354Z · LW(p) · GW(p)
Take note of the Underhanded C Contest for inspiration on the problem of auditing code written by an intelligent, untrusted source. I think one takeaway is that, with some ingenuity, one can often put malicious behavior into ok-looking code that maybe contains some innocent mistakes. It seems, then, that fully guarding against malicious code implies fully guarding against all bugs.
Which might be achievable if your style guides put heavy limitations on what kind of code can be written. (The halting problem makes it impossible for a deterministic program to always detect all bugs.) Something perhaps like the JPL C standards:
- Predictable Execution
- Use verifiable loop bounds for all loops meant to be terminating.
- Do not use direct or indirect recursion.
- Do not use dynamic memory allocation after task initialization.
...
Rule 3 (loop bounds)
All loops shall have a statically determinable upper-bound on the maximum number of loop iterations. It shall be possible for a static compliance checking tool to affirm the existence of the bound. An exception is allowed for the use of a single non-terminating loop per task or thread where requests are received and processed. Such a server loop shall be annotated with the C comment: /* @non-terminating@ */
comment by Charbel-Raphaël (charbel-raphael-segerie) · 2024-08-12T07:04:29.904Z · LW(p) · GW(p)
Here is the youtube video from the Guaranteed Safe AI Seminars:
comment by Erik Jenner (ejenner) · 2024-04-27T19:42:07.758Z · LW(p) · GW(p)
We have been able to scale to 79% accuracy on a balanced dataset of n119 and non-n119, with networks each less than three convolution layers and less than 1000 neurons, compared to pure deep-learning which does 92% on 1000 parameters and three convolution layers
Is the "1000 parameters" a typo, should it be "1000 neurons"? Otherwise, this would be a strange comparison (since 1000 parameters is a much smaller network than 1000 neurons)
Replies from: joy_void_joy↑ comment by Épiphanie Gédéon (joy_void_joy) · 2024-04-27T19:52:01.057Z · LW(p) · GW(p)
Yes, thank you, it's less than 1000 parameters for both
Replies from: Hate9↑ comment by Ms. Haze (Hate9) · 2024-04-27T23:03:45.741Z · LW(p) · GW(p)
I think you accidentally a digit when editing this. It now says "7% accuracy".
Replies from: charbel-raphael-segerie↑ comment by Charbel-Raphaël (charbel-raphael-segerie) · 2024-04-27T23:07:34.342Z · LW(p) · GW(p)
Corrected
comment by mesaoptimizer · 2024-04-27T18:26:09.716Z · LW(p) · GW(p)
Haven't read the entire post, but my thoughts on seeing the first image: Pretty sure this is priced into Anthropic / Redwood / OpenAI cluster of strategies where you use an aligned boxed (or 'mostly aligned) generative LLM-style AGI to help you figure out what to do next.
Replies from: joy_void_joy↑ comment by Épiphanie Gédéon (joy_void_joy) · 2024-04-27T19:17:39.103Z · LW(p) · GW(p)
So the first image is based on AI control, which is indeed part of their strategies, and you could see constructability as mainly leading to this kind of strategy applied to plain code for specific subtasks. It's important to note constructability itself is just a different approach to making understandable systems.
The main differences are :
-
Instead of using a single AI, we use many expert-like systems that compose together which we can see the interaction of (for instance, in the case of a go player, you would use KataGo to predict the best move and flag moves that lost the game, another LLM to explain the correct move, and another one to factor this explanation into the code)
-
We use supervision, both automatic and human, to overview the produced code and test it, through simulations, unit tests, and code review, to ensure the code makes sense and does its task well.
↑ comment by mesaoptimizer · 2024-04-29T07:52:49.643Z · LW(p) · GW(p)
Okay I just read the entire thing. Have you looked at Eric Drexler's CAIS proposal? It seems to have played some role as the precursor to the davidad / Evan OAA proposal, and has involved the use of composable narrow AI systems.