Gaia Network: a practical, incremental pathway to Open Agency Architecture
post by Roman Leventov, Rafael Kaufmann Nedal (rafael-kaufmann-nedal) · 2023-12-20T17:11:43.843Z · LW · GW · 8 commentsContents
Introduction Gaia in… One sentence Five bullet points Five paragraphs From OAA to Gaia Similarities Difference in the agentic structure Difference in the degree of formality Civilisational safety net The convergence and resilience arguments The theory of change Conclusion Appendices The Fangorn prototype of the Gaia Network: decentralised, science-based impact measurement Open research questions and risks None 8 comments
Introduction
The Open Agency Architecture (OAA) proposal [LW · GW] by Davidad has been gaining traction as a conceptual architecture to allow humanity to benefit from the nearly boundless upsides of AI while rigorously limiting its risks. As quoted here [LW · GW], the tl;dr is to “utilise near-AGIs to build a detailed world simulation, train and formally verify within it that the AI adheres to coarse preferences and avoids catastrophic outcomes.”
We think this traction is well-deserved: the only "Safe AGI" plans that stand a chance of feasibility will operationalise outer alignment through negotiation and model-based decision-making and coordination[1]. We also agree with most of Davidad’s takes on other hard problems in AI Safety and how to tackle them with OAA [LW · GW].
However, if we are going to achieve the OAA goals, we must go beyond its current presentation – as idealised formal desiderata for the components of the system envisioned and a general shape of how they all fit together – into an actual detailed design and plan. This design and plan must be based on existing technologies, but even more critically, it must not rely on a technocratic deus ex machina: instead, it needs to follow from proven incentive systems and governance institutions that can bring together the vast masses of knowledge and adoption muscle required, and tie them together in a stable and resilient way.
Here we present a specific design and plan that fulfills these requirements: the Gaia Network, or simply Gaia. This design has been in the works since 2018, it follows directly from first principles of cybernetics and economics, and it has been developed in collaboration with leading experts in collective intelligence and active inference. However, more importantly, it is a practical design that leverages a proven software stack and proven economic mechanisms to solve the real-world problems of accelerating scientific sensemaking and connecting it to better business and policy decisions. It is designed for ease of adoption, taking a “plug-and-play” approach that integrates with modeling and decision-making frameworks that are already widely used in the real world. Finally, we know it works because we’ve built a prototype (described in the appendix [LW · GW]) expressly to solve specific real-world problems and we’ve learned from what worked and what didn’t.
We followed the only recipe known by humanity to build global-scale systems: create a minimal, extensible and composable set of building blocks; make it easy and attractive for others to build using them; and ensure quality and volume through competition, incentives, and standards.
It’s what Nature uses for evolution. It’s what got us the Internet and the Web, and even before that, the globally distributed knowledge creation process that we call science. Rafael has argued extensively on these points, as have Robert Wright, George Dyson and others. Likewise, we think this recipe, not a massive top-down effort, is the only way we can achieve the grand objectives of OAA.
Furthermore, our approach does not tackle AI safety in isolation. Rather, it recognizes the interconnected nature of our shared world system and simultaneously supports corporate strategy and public governance. In doing so, it directly supports ongoing global efforts to redesign capitalism and governance – which are gaining traction with increasing recognition of the urgency associated with other aspects of the metacrisis, such as climate change and social cohesion. We think this general-purpose approach of "meeting users where they are" is the only pathway to achieve the wide and deep adoption required for OAA's success.
The goals of this piece are twofold:
- To argue that, by following this recipe, we will converge on a system and world model that meet all the OAA requirements.
- To invite researchers and developers to collaborate with us on the ongoing design, implementation and validation of this system.
Gaia in…
One sentence
An evolving repository and economy of causal models and real-world data, used by agents[2] to be incrementally less wrong about the world and the consequences of their decisions.
Five bullet points
- Open agency as a massive multiplayer inference game.
- Adaptive, distributed learning and coordination driven by a knowledge economy.
- Simultaneously solve for shared sensemaking and decision-making in collectives of arbitrary stakeholders (humans, AIs, and other synthetic entities such as corporations and governments…).
- A shared metabolism/accounting system based on free energy minimisation (the ATP of agents).
- Immediate real-world adoption and impact by directly plugging into and enhancing existing processes in science, public policy, and business.
Five paragraphs
The Gaia Network is like the Web, but instead of pages and links between them, we have (causal, probabilistic) models of specific aspects or subsystems of the world, and relationships of containment, abstraction and communication between the models. Stakeholders (humans, AIs, or entities) will use this model network to make inferences and predictions about the future, about parts of the world that they can’t observe, and especially about “what-if'' scenarios.
Whereas each Web page is “about” a specific topic (defined by the page’s title tag and potentially disambiguated in the page contents), each Gaia model is “about” a specific target, a system or a set of systems in the world (this “aboutness” is defined by a machine-readable semantic context, or just context[3]). The context specifies how the model is “wired” to the target: which input data streams or sensors are accessible/relevant to the model; which actuators are controlled by the model outputs; and how both of these are connected to the model’s internal variables (the “local ontology”). A Gaia agent (see examples in this comment [LW(p) · GW(p)]) is uniquely identified by its semantic context (using content-addressable identifiers) and must always include a model, even if that model is trivial. A context may be concrete (addressing a target we identify as a single system in the world, ex: “this square of land that today is used as a farm”, “that person”) or abstract (addressing a set of systems bound by some commonality, ex: “all farms”, “all people”), but this is just a fuzzy distinction to help conceptually (ex: when discussing hierarchies of models).
The Gaia Network is more like the Web as a whole than like a single knowledge base like Wikipedia. Unlike the latter, which is effectively a unitary knowledge base, knowledge in the Gaia Network is pluralistic: stakeholders can host Gaia agents containing their own models of the domains that they know best (for which they have data). Instead of forcing an agreement on a single “global” version of the truth like Wikipedia, the Gaia Network allows for a plurality of models for the same domain to coexist and compete with each other: agents choose which model makes the most accurate predictions for them, like competing websites.
The Gaia protocol is to Gaia as HTTP/S to the Web: it’s the set of operations that agents use to establish and interact within the network. These operations include publishing agents and their contents (contexts, models, plans and decisions), and querying the network for estimated outcomes of potential plans, model discovery, updating shared models, etc. While HTTP/S is completely content-agnostic, the Gaia protocol enforces just the bare minimum to help agents distinguish grounded from ungrounded models and data. Namely,
- the requirement for contextuality, as discussed above;
- Gaia agents can use any representation for models, as long as it’s compatible with (active) approximate Bayesian (or Infra-Bayesian[4]) inference, enabling agents to interpret models as Bayes-coherent claims about the world[5].
Another aspect that distinguishes Gaia from the Web is that it comes with built-in support for accounting (or, in biological terms, metabolism) and economics[6]. As all models are Bayesian and refer to a specific context, every agent can calculate (negative) variational free energy (VFE) as a private accounting unit for knowledge about that context. Agents also calculate the related quantity called (negative) expected free energy (EFE) as a private accounting unit for the likelihood of its strategy to achieve its preferred future. These accounting principles (jointly known as the Free Energy Principle) allow agents to account for epistemic uncertainty (whether about model representations/ontologies, functional structure, and model parameters), aleatoric uncertainty, risk, realised loss – all using the same unit (free energy reduction). So agents can use free energy reduction as a shared unit of account to compare and share beliefs about observations, states of the world, models, and plans. This allows them to discover prices for knowledge, calculate incentives for delegated or coordinated actions, and so forth.[7]
From OAA to Gaia
Similarities
OAA and Gaia designs were developed with the same core tenets in mind:
Building safe TAI, not alignment is the top-level problem we are solving. In the words of Davidad [LW · GW]:
For me the core question of existential safety is this: “Under these conditions, what would be the best strategy for building an AI system that helps us ethically end the acute risk period without creating its own catastrophic risks that would be worse than the status quo?”
It is not, for example, "how can we build an AI that is aligned with human values, including all that is good and beautiful?" or "how can we build an AI that optimises the world for whatever the operators actually specified?" Those could be useful subproblems, but they are not the top-level problem about AI risk (and, in my opinion, given current timelines and a quasi-worst-case assumption, they are probably not on the critical path at all).
To negotiate preferences and constraints and coordinate plans at scale among the stakeholders, these should be specified in the state space (of a shared world model), rather than, for example, in the space of reward functions. Note that this is not an “agent foundations” claim, but a more prosaic engineering hypothesis [LW(p) · GW(p)] about the scalability of coordination.
OAA and Gaia are both built on a common logic of the agentic OODA loop which ultimately goes back to cybernetics and systems theory.
Difference in the agentic structure
One of the core differences between OAA and Gaia lies in the structure of the agentic (cybernetic) loops that they both aspire to establish. OAA places creating and maintaining the world model and carrying out world-changing plans very far apart (steps 1 and 4) in its functional diagram[8]:
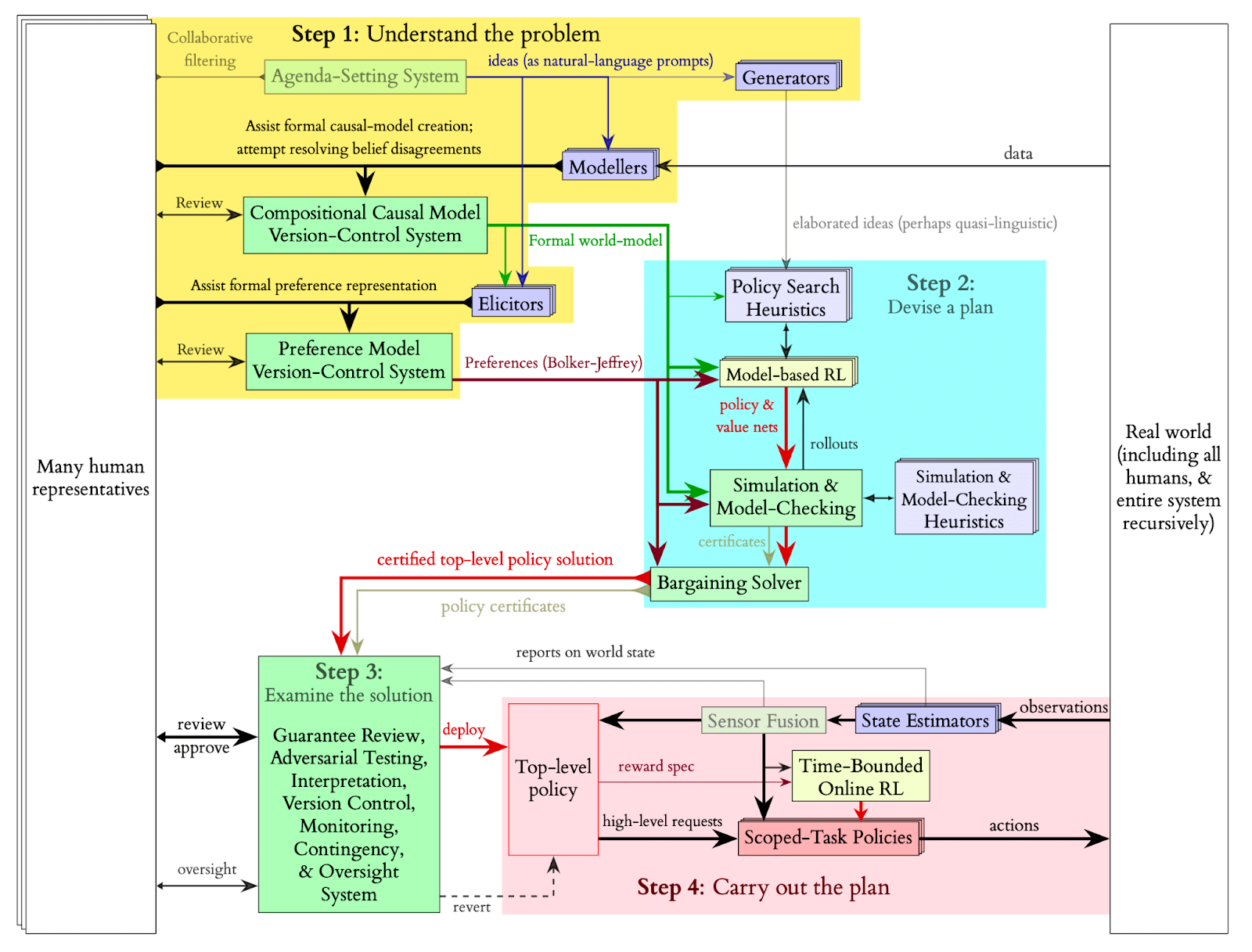
In contrast, in the Gaia Network, for each given context, both the pieces of the world model, preferences of humans and other stakeholders, and action capabilities are embodied by the same Gaia agent which makes observations, updates its models, and performs or recommends actions within a single cybernetic loop, which is 1-1 mapped and wired to the real-world system it supports (thus forming a multiscale competency architecture):
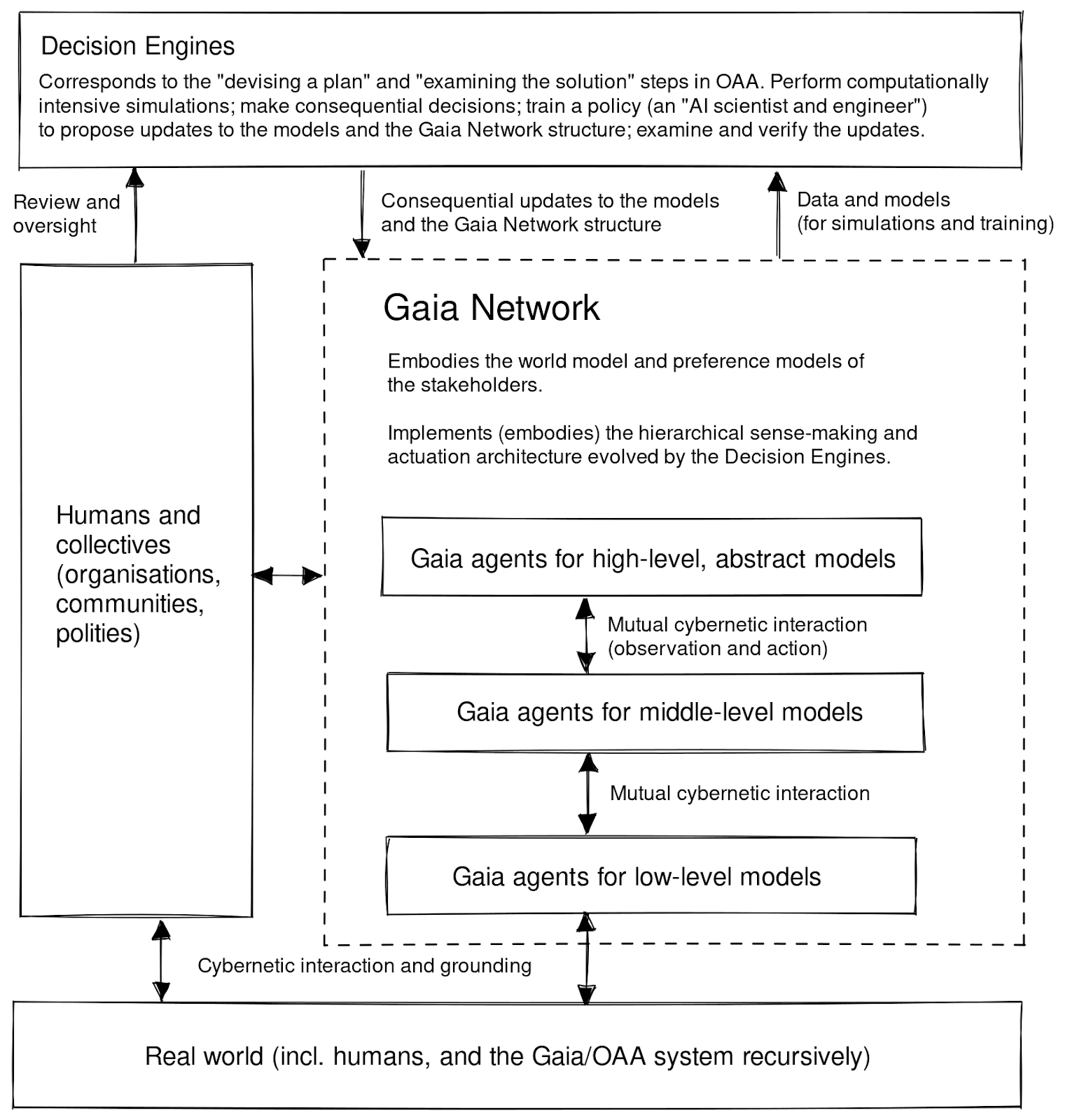
Concretely, the Gaia Network fully takes up the functions of the compositional-causal-model version-control system, preference-model version-control system, scoped-task policies, and state estimators, and at least partially takes up the function of modelers in the detailed OAA’s functional breakdown [LW · GW].
The practical advantages of implementing all these functions within a single agent network (mesh) include:
(1) It’s a more compact architecture (in comparison with the original OAA) and therefore will be easier to engineer, understand, and support.
(2) Making a lot of small OODA (cybernetic) loops that are directly wired to the real-world systems they refer to, instead of a single gigantic loop for the entire civilisation, should be more robust to “model hacking” (or good-faith confusion between the map and the territory) and, indirectly, to deception and collusion because it imbues all agents with “epistemic skin in the game”: all models are constantly put to the test by reality with as little delay as it could possibly get.
(3) The Gaia Network charts a relatively clear and institutionally familiar path from “devising a plan” (in OAA’s terms; in Gaia, it mostly amounts to model updates aka model selection and changes to the agent network structure) and “carrying out the plan”. In Gaia, the Decision Engines could be seen as regulators that from time to time prescribe businesses to change the way they model things (e.g., a financial regulator may prescribe banks to change how they model risks), as well as sometimes forcefully dismantle organisations, split them into independent entities (usually done by anti-trust regulators), and create new organisations (such as state-owned corporations). The “actual” work of carrying out the top-level plan is done by the Gaia agents that are created or changed by the regulators; in turn, these Gaia agents influence the decisions of the corresponding humans and other stakeholders.
In the original OAA functional breakdown, in contrast, it’s very unclear who would be responsible for training, deploying, and actuating hierarchical “scoped-task policies”, what would be the legal and political status of these policies, and how this strategy is compatible with capitalism: is there a “cutoff” level of abstraction of the policies below which they delegate to “traditional” economic agents, or does OAA imply a planned economy all the way down? The Gaia Network doesn’t force answering these questions: it could be straightforwardly adopted by the present political economy of regulatory capitalism.
(4) Similarly to the previous point, the Gaia Network provides familiar economic incentives and adoption pathways for humans and other stakeholders to share their preferences, and for the modelers (human scientists, AIs, or dedicated Gaia agents) to continuously improve the world model at all levels. This is the only realistic way to make essentially all scientists and industry researchers contribute to the world model and a significant part of the world population contribute to the preference model[1]. The original OAA proposal doesn’t elucidate this aspect but seems that it would require inventing new institutions, which bears additional risks. It seems implausible that the CERN model of scientific collaboration, for example, could scale 1000x without breaking down.
Difference in the degree of formality
The second key difference between OAA and Gaia is that Gaia doesn’t demand formalising and strictly specifying various pieces of the system (models and their composition structure, preferences and their relative ordering, and constraints) to work and tangibly reduce the global risks. On the formalism spectrum, Gaia is between the real economy and biology on the “informal” side, and OAA on the “formal” side:

The requirement (2) from the “Five paragraphs” section above, namely that Gaia agents should perform approximate Bayesian inference, could even be relaxed to that Gaia agents should perform state-space, energy-based modelling (and planning-as-inference) of any kind. That would still permit agents to estimate their energy reduction from the state and plan updates upon receiving information from other agents. (Incidentally, this would turn the Gaia Network into a distributed version of LeCun's H-JEPA.)
On the other hand, when the computational tools for Infra-Bayesian inference are developed, Gaia agents could switch to Infra-Bayesian models to improve their risk modelling as discussed in the footnote[4]. This is not to say that mere Bayesian (or generic energy-based) models are useless to estimate or compare risks. Having a working and fairly comprehensive Gaia Network is far better than the status quo of risk assessment and management (analyses siloed in the scattered government agencies, regulators, corporations, and think tanks; very poor information exchange).
Likewise, the formalisation of the compositional structure of models at different levels of world description (as proposed in OAA) is approximated in the Gaia Network by the emergent message passing (and free energy reduction) dynamics between Gaia agents. It is not perfect, but it would be far better than the status quo in science, especially the high-level fields of science such as physiology and medicine, psychology, sociology, economics, and so forth.
AI Objective Institute proposed a roadmap for a collaborative prototype of OAA [LW · GW] that ameliorates the up-front demandingness of OAA, but only a little. The Gaia Network, thanks to its flexibility concerning formalisation, will be built by many actors independently in different modelling domains/business verticals [LW(p) · GW(p)] and geographical regions. When the model hierarchies[9] in these disparate domains grow sufficiently large to make information exchange between them economically valuable, the Gaia Network will “close over” the economy as a whole. The fact that multiple startups are already pursuing this vision in various application domains, despite it never being clearly articulated and promoted in the business environment, speaks to the promise of the Gaia approach.
“In the limit” the Gaia Network could be made just as formalised and strict as the original OAA if we develop the requisite math and science, and have the buy-in to bring the system to this state. In the meantime, we can (and should) start building the Gaia Network right away, using the math, science, and software tools that are available today.
Civilisational safety net
Finally, there is another argument for why developing “not so ambitious” Gaia could reduce the expected catastrophic AI risk more than trying to build OAA (and likely not completing it in time before rogue AIs start to become existentially dangerous).
Even if the Gaia Network doesn’t culminate in the development of a transformative AI a-la Bengio's “AI scientist and engineer [LW · GW]” (perhaps, due to unexpected technical challenges, or just the prohibitive cost of training it) in time before we enter the direct risk period from rogue AIs, if the significant portion of the economic activity flows through the Gaia Network, then rogue AIs will have fewer degrees of freedom and attack affordances (e.g., for covert accumulation of resources and scheming) because of the transparency of the Gaia Network, its robustness to model hacking, and the built-in anti-collusion mechanisms.
The convergence and resilience arguments
Will Gaia do what it says on the label? Will it be what we want it to be?
We want to argue that:
- Gaia will converge towards a truthful body of knowledge (the world model) that supports effective and appropriate decision safeguards;
- This world model will be resilient against adversarial behavior.
As we discussed above, formal guarantees are great when possible, but when they involve oversimplifications, they tend to lead to false certainty (the map/territory fallacy). So we ask the reader to consider the following heuristic argument.
Epistemic status: The extensive indirect evidence for this argument puts us at ease, but we’re working to obtain direct evidence: see the “Conclusion” section. Additionally, while the following is very much a “bottom-up” or inductive arguments, we are developing a separate “top-down” argument, regarding the existence and properties of a positive-sum attractor for the world state; the latter we defer to an upcoming, longer paper.[10]
This argument follows two mutually reinforcing parts:
(a) To the extent that contamination can be filtered out or ignored, Gaia will converge towards a truthful body of knowledge;
(b) to the extent that Gaia has truthful knowledge, it will be economical to filter out or ignore arbitrarily large amounts of contamination. It is structurally the same argument that explains why open-source software works, and it's at heart an evolutionary process theory.
Part (a) follows from the classical (Jaynes) view of Bayesian probability as the logic of science. If agents can trust any given state s of Gaia’s knowledge as an approximate representation of the world, they can then use it as a prior for Bayesian updating and share their posteriors on the network, forming a new state s' that is likewise a progressively better representation of the world (and, in principle, this improvement could even be calculated in a consensual way as free energy reduction). In this way, all materially relevant[11] errors in the collective knowledge (whether originally coming from noisy observations or faulty models) will eventually be corrected by further observations, experiments and actions. The general case is that an agent will believe that the content of Gaia is a mixture of knowledge and contaminants, and will attempt to discriminate between the two using trust models (which may, for instance, describe a certain dataset’s probability of being bogus as a function of knowledge about its source’s identity or past behavior.) These, in turn, are just more models on the Gaia Network. So if Gaia is even moderately useful and trustworthy, it will be adopted and contributed to, which makes it more useful and trustworthy.
Part (b) hinges on both the append-only nature of the network’s contents, and the intrinsic reversibility of Bayesian updating[12]. Even in the presence of concerted effort to contaminate the network with bad models (including conspiracies to give high weights to those models), these merely add noise to the network; they don't replace the genuine knowledge already accumulated. Through “revisitation” procedures, agents can roll back through content (model parameters and states), sift the wheat from the chaff, giving higher weights to the high-quality models, and collaboratively down-rating low-quality ones. This imposes an increasing hurdle for sources of low-quality models to contribute, such that, over time, the signal-to-noise ratio improves. Hence, the more contributors engage with the network – indeed, the greater the number and variety of erroneous models it ingests – the more robust it becomes against contaminants. This is analogous to the immune system in biology, where exposure to a variety of threats strengthens the system's ability to identify and neutralise harmful agents.
Furthermore, the economic aspect of part (b) becomes evident when considering the cost-benefit analysis of participating in and maintaining the Gaia Network. As the network becomes more accurate and reliable, the relative cost of filtering out contamination decreases, while the value of accessing the world model increases. This creates a positive feedback loop, encouraging more participation and investment in the network, which in turn enhances its quality and trustworthiness.
The theory of change
Hence, our “master theory of change” is:
- Design the Gaia Network architecture and incentives in such a way that it grows and, as it does so, it will also converge on a truthful world model and be resilient.
- Get it to grow, monitoring truthfulness and resilience and adjusting/governing as it goes.
- Advocate for increased reliance on the Gaia Network for both human and AI decision-making, based on empirical evidence of truthfulness and resilience.
Conclusion
Coming soon: a complete paper, an engineering roadmap, and a research roadmap. These documents will also cover important issues that haven't been mentioned here, such as the design for private and secure inference required for adoption in business domains where such concerns are paramount.
Call to action: build this with us (or, fund us)!
Appendices
The Fangorn prototype of the Gaia Network: decentralised, science-based impact measurement
Digital Gaia developed a demo in the first half of 2023 to show how the Gaia Network can be an effective shared world model for decision-making in land use and agriculture. The demo is based on Fangorn, a prototype implementation of many of the key capabilities of the Gaia Network, specialised for the domain of agroecology.
Slightly simplifying, a Fangorn node is a Gaia agent whose target is a specific polygon of land that “wants to be” a healthy ecosystem. It autonomously selects the appropriate local model and data streams that are relevant for its target land. It performs parameter inference, predicts the future state of the land, and (if the model supports it) recommends actions to optimise the relevant health metrics for the land. And last but not least, it shares the state and the parameters from its local model with its peer Fangorn nodes, using a federated message-passing system in a network topology that mirrors the world model’s hierarchical structure.
This demo was developed in partnership with various organisations, most notably Savimbo, a science and conservation organisation that manages several community-led agroecology projects in Colombia. Digital Gaia also worked with impact certificate marketplaces, and scientists such as agronomists and soil scientists. An LLM conversational loop (ChatGPT with GPT-4) was used to distill relevant scientific and practical knowledge collected from experts, literature and field reports into a hierarchical dynamical model, expressed as probabilistic programming code (Fangorn uses a NumPyro-based DSL). This usage of LLMs corresponds to the roles of elicitors and generators in OAA's functional breakdown [LW · GW].
The resulting probabilistic model consumes observations drawn from the agroecology projects’ self-reported data, combined with public satellite data, and produces a versioned, machine-verifiable assessment: a high-integrity, science-based way to quantify the agroecology project's past and future performance, which can be used by investors, donors and credit buyers to improve the quality of funding decisions, and by scientists. This system can also be used by agroecologists to accelerate scientific research and experimentation, and by practitioners to implement scientifically rigorous practices with a tighter feedback loop.
Due to funding constraints, we have not yet made Fangorn into a production-ready platform, and some crucial elements of the full Gaia Network architecture were not included in the implementation. Nonetheless, it stands as a concrete demonstration that it is possible, valuable and not that difficult to enhance existing, real-world decision-making processes, incentive schemes and scientific workflows by connecting them to a shared world model.
A more extended write-up and Loom walkthrough are also available. Links to the live demo, source code and demo notebooks are available upon request.
Open research questions and risks
The Gaia Network's design is not yet complete, there are a number of open technical questions and uncertainties about it. We postpone a more through discussion of these to the complete paper which will be published soon, but want to mention some of them in brief here.
We also actively invite critical discussion of these question, ideas for solutions, and collaborators to work with us on these problems.
The question of whether Gaia agents should have Infra-Bayesian models (rather than vanilla Bayesian or energy-based models) for scalable risk management is mentioned in the footnote[4].
The message passing sufficiency hypothesis: is message passing alone (cf. "Cooperative Graph Neural Networks", Finkelstein et al., 2023) as the mechanism for Gaia agents to share and aggregate information is sufficient for the Gaia Network to do credit assignment [LW · GW] well and enable agents to learn better models across the abstraction stack while not falling prey of trapped priors [LW · GW]? Or, more expressive mechanisms for credit assignment on interaction graphs are required (Ding et al., 2023)?
The Gaia design (as well as OAA) leaves a theoretical possibility of collusion of silicon life (Gaia agents) against carbon life (humanity and biosphere). However, we believe that some mechanism design could rule out collusion with a very high degree of certainty. The Gaia Network directly embodies (or is amenable to) all six general principles for anti-collusion mechanism design [LW · GW] (agency architecture) proposed by Eric Drexler, though these principles should be further validated via formalisation and proving theorems about the collusion properties of the systems of distributed intelligence. Thus, the development of concrete mechanisms for preventing collusion is an open research task in Gaia (and OAA).
Another related question is whether general, broadly situationally-aware agents (i.e., AGIs) should be allowed to participate in the Gaia Network (i.e., to be Gaia agents). The risk of this (or, at present, uncertainty about the degree of the risk) is that AGIs could subvert the anti-collusion properties of the network. On the one hand, answering this question is not required for building the "Gaia MVP" and realising the OAA goals, which is explicitly not about aligning AGIs, but rather ending the acute risk period and deliberately limiting the proliferation of general agency through compute monitoring. On the other hand, we should recognise that by enabling economic incentives and open competitive environment for the development of Gaia agents (which is by design and the core feature of Gaia relative to OAA, as we see it), we simultaneously create stronger pressure towards updating the Gaia agents into AGIs. This could be seen as an extra risk of Gaia relative to OAA, at least until we have better safeguards against collusion or quantification of the risk.
More philosophical (but nevertheless very important!) questions: how would the Gaia Network affect the future dynamics of individual vs. collective agency and consciousness? And would this impact be net good or net bad? (See the discussion in the footnote[2].) Note that these questions apply to OAA as well as Gaia: OAA also suggest to walk a tightrope between paternalism and open-endedness of human individualism [LW(p) · GW(p)], but I (Roman) am doubtful that such a path exists [LW · GW]. The specific part of OAA that is relevant to this problem is Davidad's solution 5.1.5 to the problem of instrumental convergence [LW · GW], but I'm not sure that it is a successful response.
Thanks to Davidad and Justis Mills for providing feedback on the draft of this post.
- ^
This is also very aligned with Beren Millidge's vision of "Preference Aggregation as Bayesian Inference [LW · GW]".
- ^
In the initial exposition of Gaia in the following sections, we distinguish between
- Gaia agents: computational (or cybernetic, if they are attached to actuators "in the real world", although the distinction between informational/computational actuation and "real world" actuation is very blurred) systems that attach into the Gaia Network via the particular set of standards (that we call Gaia Protocol); and
- stakeholders such as humans, other conscious beings (animals or AIs), and organisations, and collectives who can query the Gaia Network and use its data for arbitrary purposes in the economy and the society.However, in this single-sentence description of Gaia, as well as later in the article, we intentionally blur the distinction between Gaia agents and stakeholders by using the general term agents. This is because, on the deeper inspection, there is actually no bright line between Gaia agents and stakeholders: Gaia agents could be stakeholders themselves. Consider how the Gaia Network (i.e., the Gaia agents in it) attends to the "real world" which includes itself, recursively (or self-reflectively, we should say). See the diagram in the section "Difference in the agentic structure [LW · GW]".
This line of reasoning also leads to very important questions: how would the Gaia Network affect the future dynamics of individual vs. collective agency and consciousness? And would this impact be net good or net bad? We don't have ready answers to these questions, and we postpone their discussion to the complete paper that will be published soon. Cf. the related discussion in Beren Millidge's "BCIs and the ecosystem of modular minds [LW · GW]".
- ^
This conforms with the formalisation of context in Fields, C., & Glazebrook, J. F. (2022). Information flow in context-dependent hierarchical Bayesian inference. Journal of Experimental & Theoretical Artificial Intelligence, 34(1), 111–142. https://doi.org/10.1080/0952813X.2020.1836034
- ^
We are open to Davidad’s arguments [LW(p) · GW(p)] that Infra-Bayesianism can be critical for compositional reasoning about risk. However, we think it’s important to start building the Gaia Network with computational tools that are available today for approximate Bayesian inference and develop the computational infrastructure for Infra-Bayesian inference in parallel. When the latter is production-ready, Bayesian models could be gradually replaced with Infra-Bayesian ones in the Gaia Network. Note that if the agenda of building Infra-Bayesian infrastructure is stalled for some reason, it would still probably be better for robustness to civilisational risks to have “mere Bayesian” Gaia Network deployed in the world than not having any equivalent of such a knowledge and agent network.
- ^
Our reference implementation uses NumPyro, a Python-based probabilistic programming language, which we expect to become a de facto standard.
- ^
The accounting and economic systems are described here without any motivation and arguments for why this design should have attractive properties. This is deferred to the complete paper that will be published soon.
- ^
The step from free energy-based accounting to autonomous, free energy-based price discovery and trading requires additional work and resolution of important questions about fungibility. We have made progress on this but defer a fuller discussion to the forthcoming complete paper.
- ^
The phrase “Modelers would be AI services that generate purely descriptive models of real-world data, inspired by human ideas, and use those models to iteratively grow a human-compatible and predictively useful formal infra-Bayesian ontology […] Some of these [modelers] would be tuned to generate trajectories that are validated by the current formal model but would be descriptively very surprising to humans.” in the original OAA post [LW · GW] may suggest that Davidad might have already thought about overlaying the implementation of world modelling and actuation within the same services to some extent. However, we think that this is a mistake to place these two functions apart even in the functional design, and Gaia pushes for tying sense-making and actuation into close agentic loops across the entire abstraction stack.
- ^
Such Bayesian model hierarchies are called Quantum Reference Frames (QRFs) in the quantum information-theoretic (and quantum Free Energy Principle) ontology developed by Chris Fields and collaborators.
- ^
These these "bottom-up" and "top-down" lines of argumentation roughly correspond to the “low road” and “high road” to active inference in the book by Parr, Pezzulo and Friston.
- ^
The word “materially” here means that if there is knowledge that cannot be gleaned or corrected in this way – as some believe to be the case about the foundations of physics, cosmology, and other fields – it is not relevant to Gaia’s purposes. Similarly, the fact that we may never know the truth about historical facts lost in time is irrelevant here.
- ^
Reversibility is lost when an agent assigns a probability of zero or one to some present or future (predicted) state, which effectively represents infinite confidence in its falsehood or truth, a “belief singularity” from which no evidence can remove it. Procedures for explicit Bayesian updating (or its approximations) are intrinsically safe from this mistake; however, this problem arises implicitly and routinely when, in the course of the modeling process, a model selects an excessively simplistic or rigid structure for the context at hand. By disallowing alternative hypotheses as an initial prior, an agent using such a model is effectively locked into such mistaken and unmovable assumptions straight out of the gate. This is one major reason why the Gaia Network’s design emphasises higher-order, context-aware metamodeling. Also, cf. the discussion of the message passing sufficiency hypothesis in the appendix "Open research questions and risks".
8 comments
Comments sorted by top scores.
comment by Steven Byrnes (steve2152) · 2023-12-24T03:35:24.517Z · LW(p) · GW(p)
I found this whole thing very confusing; I think it would have helped if there were lots and lots of concrete examples spread all around the post. Even if the examples aren't perfectly realistic, it's still better than nothing. Like, when you first mention "Gaia agents", can you list five made-up examples, and explain what value a particular person or institution would get out of building and/or using that Gaia agent? Many things like that.
Replies from: Roman Leventov↑ comment by Roman Leventov · 2023-12-24T13:03:04.052Z · LW(p) · GW(p)
One completely realistic example of an agent is given in the appendix (an agent that recommends actions to improve soil health or carbon sequestration). Some more examples are given in this comment [LW(p) · GW(p)]:
- An info agent that recommends me info resources (news, papers, posts, op-eds, books, videos) to consume, based on my current preferences and demands (and info from other others, such as those listed below, or this agent [LW · GW] that predicts the personalised information value of the comments on the web)
- Scaling to the group/coordination: optimise informational intake of a team, an organisation, or a family
- Learning agent that recommends materials based on the previous learning trajectory and preferences, a-la liirn.space
- Scaling to the group/coordination: coordinate learning experiences and lessons between individual learning agents based on who is on what learning level, availailiity, etc.
- Financial agent that recommends spending based on my mid- and long-term goals
- Equivalent of this for an organisation: "business development agent", recommends an org to optimise strategic investments based on the current market situation, goals of the company, other domain-specific models provided (i.e., in the limit, communicated by other Gaia agents responsible for these models), etc.
- Investment agent recommends investment strategy based on my current financial situation, financial goals, and other investment goals (such as ESG)
- Scaling to the group/coordination: optimise joint investment strategy for income and investment pools a-la pandopooling.com
- Energy agent: decides when to accumulate energy and when to spend it based on the spot energy prices, weather forecast for renewables, and the current and future predicted demands for power
- Scale this to microgrids, industrial/manufacturing sites, etc.
↑ comment by Steven Byrnes (steve2152) · 2023-12-24T13:26:19.889Z · LW(p) · GW(p)
The Gaia network does not currently exist AFAIK, yet it is already possible to build all of those things right now, right? Can you elaborate on what would be different in a Gaia network version compared to my building those tools right now without ever having heard of Gaia?
Replies from: Roman Leventov↑ comment by Roman Leventov · 2023-12-24T14:43:27.679Z · LW(p) · GW(p)
Right now, if the Gaia Network already existed, but there were little models and agents on it, there would be no or little advantages (e.g., leveraging the tooling/infra built for the Gaia Network) in joining the network.
This is why I personally think that the bottom-up approach: building these apps and scaling them (thus building up QRFs) first is somewhat more promising path than the top-down approach, the ultimate version of which is the OAA itself, and the research agenda of building Gaia Network is a somewhat milder version, but still top-down-ish. That's why in the comment [LW(p) · GW(p)] that I already linked to above, the implication is that these disparate apps/models/"agents" are built first completely independently (mostly as startups), without conforming to any shared protocol (like the Gaia protocol), and only once they grow large and sharing information across the domains becomes evidently valuable to these startups, then the conversation about a shared protocol will find more traction.
Then, why a shared protocol, still? Two reasons:
- Practical: it will reduce transaction costs for all the models across the domains to start communicating to improve the predictions of each other. Without a shared protocol, this requires ad-hoc any prospective direction of information sharing. This is the practicality of any platforms, from the Internet itself to Airbnb to SWIFT (bank wires), and Gaia Network should be of this kind, too.
- AI and catastrophic risk safety: to ensure some safety against rogue actors (AI or hybrid human-AI teams or whatever) through transparency and built-in mechanisms, we would want as much economic activity to be "on the network" as possible.
- You may say that this is would be a tough political challenge to convince everybody to conform to the network in the name of some AI safety, but surely this would still be a smaller challenge than to abolish much of the current economic system altogether as (apparently) implied by the "vanilla" Davidad's OAA, and as we discuss throughout the article. In fact, this is one of the core points of the article.
Then, even though I advocate for a bottom-up approach above, there is still a room, and even a need for a parallel top-down activity (given the AGI timelines), so these two streams of activity meet each other somewhere in the middle. This is why we are debating all these blue-sky AI safety plans on LessWrong at all; this is why OAA was proposed, and this is why we are now proposing the Gaia Network.
Replies from: steve2152↑ comment by Steven Byrnes (steve2152) · 2023-12-27T19:43:58.060Z · LW(p) · GW(p)
My friendly suggestion would be to have one or more anecdotes of a specific concrete (made-up) person trying to build a specific concrete AI thing, and they find themselves facing one or more very specific concrete transaction costs (in the absence of Gaia), and then Gaia enters the scene, and then you specifically explain how those specific transaction costs thereby become lower or zero, thanks to specific affordances of Gaia.
I’ve tried to read everything you’ve linked, but am currently unable to generate even one made-up anecdote like that.
(I am not the target audience here, this isn’t really my wheelhouse, instead I’m just offering unsolicited advice for when you’re pitching other people in the future.)
(Bonus points if you have talked to an actual human who has built (or tried to build) such an AI tool and they say “oh yeah, that transaction cost you mentioned, it really exists, and in fact it’s one of our central challenges, and yes I see how the Gaia thing you describe would substantially help mitigate that.”)
Replies from: rafael-kaufmann-nedal, Roman Leventov↑ comment by Rafael Kaufmann Nedal (rafael-kaufmann-nedal) · 2024-01-01T15:20:21.869Z · LW(p) · GW(p)
Hey Steven, I'll answer your question/suggestion below. One upfront request: please let us know if this helps. We'll write a follow-up post on LW explaining this.
As mentioned in the appendix [LW · GW], most of what we wrote up is generalized from concrete people (not made-up, my IRL company Digital Gaia) trying to build a specific concrete AI thing (software to help farmers and leaders of regeneration projects maximize their positive environmental impact and generate more revenue by being able to transparently validate their impact to donors or carbon credit buyers). We talked extensively to people in the ag, climate and nature industries, and came to the conclusion that the lack of transparent, unbiased impact measurement and validation -- ie, exactly the transaction costs you mention -- is the reason why humanity is massively underinvested in conservation and regeneration. There are gazillions of "climate AI" solutions that purport to measure and validate impact, but they are all fundamentally closed and centralized, and thus can't eliminate those transaction costs. In simple terms, none of the available systems, no matter how much money they spent on data or compute, can give a trustworthy, verifiable, privacy-preserving rationale for either scientific parameters ("why did you assume the soil carbon captured this year in this hectare was X tons?") or counterfactuals ("why did you recommend planting soybeans with an alfalfa rotation instead of a maize monoculture?"). We built the specific affordances that we did -- enabling local decision-support systems to connect to each other forming a distributed hierarchical causal model that can perform federated partial pooling -- as a solution to exactly that problem:
- The first adopters (farmers) already get day-1 benefits (a model-based rationale that is verifiable and privacy-preserving), using models and parameters bootstrapped from the state of the art of open transaction-cost-reduction: published scientific literature, anecdotal field reports on the Web, etc.
- The parameter posteriors contributed by the first adopters drive the flywheel. As more adopters join, network effects kick in and transaction RoI increases: both parameter posteriors become increasingly truthful and easier to verify (posterior estimates from multiple sources mostly corroborate each other, confidence bands get narrower).
- Any remaining uncertainty, in turn, drives incentives for scientists and domain experts to refine models and perform experiments, which will benefit all adopters by making their local impact rationales and recommendations more refined.
- As an open network, models and parameters can be leveraged in adjacent domains, which then generate their own adjacencies, eventually covering the entire spectrum of science and engineering. For instance, we have indoor farms and greenhouses interested in our solution; they would need to incorporate not only agronomic models but also energy consumption and efficiency models. This then opens the door to industrial and manufacturing use cases, and so on and so forth...
We validated the first two steps of this theory in a pilot; it worked so well that our pilot users keep ringing us back saying they need us to turn it into production-ready software...
Disclaimer: We did not fully implement or validate two important pieces of the architecture that are alluded to in the post: free energy-based economics and trust models. These are not crucial for a small-scale, controlled pilot, but would be relevant for use at scale in the wild.
↑ comment by Roman Leventov · 2023-12-27T20:16:21.408Z · LW(p) · GW(p)
Thanks for suggestions.
An actual anecdote may look something like this: "We are a startup that creates nutrition assistant and family menu helper app. We collect anonymised data from the users and ensure differential privacy, yada-yada. We want to sell this data to hedge funds that trade food company stocks (so that we can offer the app for free for to our users), but we need to negotiate the terms of these agreements in an ad-hoc way with each hedge fund individually, and we don't have a principled way to come up with a fair price for the data. We would benefit from something like a 'platform' on which we can just publish the API spec of our data and then the platform (i.e., the Gaia Network) takes care of finding buyers for our data and paying us a fair price for it, etc."
Replies from: Roman Leventov↑ comment by Roman Leventov · 2023-12-27T20:21:55.757Z · LW(p) · GW(p)
BTW, this particular example sounds just like Numer.ai Signals, but Gaia Network is supposed to be more general and not to revolve around the stock market alone. E.g., the same nutritional data could be bought by food companies themselves, logistics companies, public health agencies, etc.