Trapped Priors As A Basic Problem Of Rationality
post by Scott Alexander (Yvain) · 2021-03-12T20:02:28.639Z · LW · GW · 33 commentsContents
Introduction and review Trapped priors: the basic cognitive version Trapped prior: the more complicated emotional version From phobia to bias Reiterating the cognitive vs. emotional distinction Future research directions None 33 comments
Crossposted from Astral Codex Ten
Introduction and review
Last month I talked about van der Bergh et al’s work on the precision of sensory evidence, which introduced the idea of a trapped prior. I think this concept has far-reaching implications for the rationalist project as a whole. I want to re-derive it, explain it more intuitively, then talk about why it might be relevant for things like intellectual, political and religious biases.
To review: the brain combines raw experience (eg sensations, memories) with context (eg priors, expectations, other related sensations and memories) to produce perceptions. You don’t notice this process; you are only able to consciously register the final perception, which feels exactly like raw experience.

A typical optical illusion. The top chess set and the bottom chess set are the same color (grayish). But the top appears white and the bottom black because of the context (darker vs. lighter background). You perceive not the raw experience (grayish color) but the final perception modulated by context; to your conscious mind, it just seems like a brute fact that the top is white and the bottom black, and it is hard to convince yourself otherwise.
Or: maybe you feel like you are using a particular context independent channel (eg hearing). Unbeknownst to you, the information in that channel is being context-modulated by the inputs of a different channel (eg vision). You don’t feel like “this is what I’m hearing, but my vision tells me differently, so I’ll compromise”. You feel like “this is exactly what I heard, with my ears, in a way vision didn’t affect at all”.
This is called the McGurk Effect. The man is saying the same syllable each time, but depending on what picture of his mouth moving you see, you hear it differently. Your vision is context-modulating your hearing, but it just sounds like hearing something.
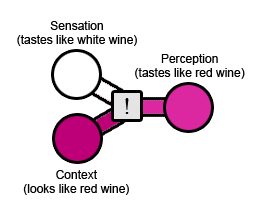
The most basic illusion I know of is the Wine Illusion; dye a white wine red, and lots of people will say it tastes like red wine. The raw experience - the taste of the wine itself - is that of a white wine. But the context is that you're drinking a red liquid. Result: it tastes like a red wine.
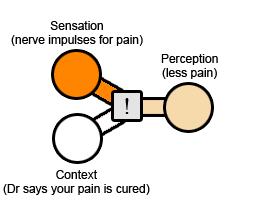
The placebo effect is almost equally simple. You're in pain, so your doctor gives you a “painkiller” (unbeknownst to you, it’s really a sugar pill). The raw experience is the nerve sending out just as many pain impulses as before. The context is that you've just taken a pill which a doctor assures you will make you feel better. Result: you feel less pain.
These diagrams cram a lot into the gray box in the middle representing a “weighting algorithm”. Sometimes the algorithm will place almost all its weight on raw experience, and the end result will be raw experience only slightly modulated by context. Other times it will place almost all its weight on context and the end result will barely depend on experience at all. Still other times it will weight them 50-50. The factors at play here are very complicated and I’m hoping you can still find this helpful even when I treat the gray box as, well, a black box.
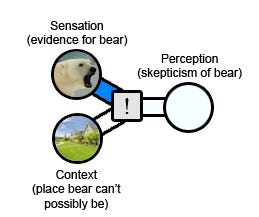
The cognitive version of this experience is normal Bayesian reasoning. Suppose you live in an ordinary California suburb and your friend says she saw a coyote on the way to work. You believe her; your raw experience (a friend saying a thing) and your context (coyotes are plentiful in your area) add up to more-likely-than-not. But suppose your friend says she saw a polar bear on the way to work. Now you're doubtful; the raw experience (a friend saying a thing) is the same, but the context (ie the very low prior on polar bears in California) makes it implausible.
Normal Bayesian reasoning slides gradually into confirmation bias. Suppose you are a zealous Democrat. Your friend makes a plausible-sounding argument for a Democratic position. You believe it; your raw experience (an argument that sounds convincing) and your context (the Democrats are great) add up to more-likely-than-not true. But suppose your friend makes a plausible-sounding argument for a Republican position. Now you're doubtful; the raw experience (a friend making an argument with certain inherent plausibility) is the same, but the context (ie your very low prior on the Republicans being right about something) makes it unlikely.
Still, this ought to work eventually. Your friend just has to give you a good enough argument. Each argument will do a little damage to your prior against Republican beliefs. If she can come up with enough good evidence, you have to eventually accept reality, right?
But in fact many political zealots never accept reality. It's not just that they're inherently skeptical of what the other party says. It's that even when something is proven beyond a shadow of a doubt, they still won't believe it. This is where we need to bring in the idea of trapped priors.
Trapped priors: the basic cognitive version
Phobias are a very simple case of trapped priors. They can be more technically defined as a failure of habituation, the fancy word for "learning a previously scary thing isn't scary anymore". There are lots of habituation studies on rats. You ring a bell, then give the rats an electric shock. After you do this enough times, they're scared of the bell - they run and cower as soon as they hear it. Then you switch to ringing the bell and not giving an electric shock. At the beginning, the rats are still scared of the bell. But after a while, they realize the bell can't hurt them anymore. They adjust to treating it just like any other noise; they lose their fear - they habituate.
The same thing happens to humans. Maybe a big dog growled at you when you were really young, and for a while you were scared of dogs. But then you met lots of friendly cute puppies, you realized that most dogs aren't scary, and you came to some reasonable conclusion like "big growly dogs are scary but cute puppies aren't."
Some people never manage to do this. They get cynophobia, pathological fear of dogs. In its original technical use, a phobia is an intense fear that doesn't habituate. No matter how many times you get exposed to dogs without anything bad happening, you stay afraid. Why?
In the old days, psychologists would treat phobia by flooding patients with the phobic object. Got cynophobia? We'll stick you in a room with a giant Rottweiler, lock the door, and by the time you come out maybe you won't be afraid of dogs anymore. Sound barbaric? Maybe so, but more important it didn't really work. You could spend all day in the room with the Rottweiler, the Rottweiler could fall asleep or lick your face or do something else that should have been sufficient to convince you it wasn't scary, and by the time you got out you'd be even more afraid of dogs than when you went in.
Nowadays we're a little more careful. If you've got cynophobia, we'll start by making you look at pictures of dogs - if you're a severe enough case, even the pictures will make you a little nervous. Once you've looked at a zillion pictures, gotten so habituated to looking at pictures that they don't faze you at all, we'll put you in a big room with a cute puppy in a cage. You don't have to go near the puppy, you don't have to touch the puppy, just sit in the room without freaking out. Once you've done that a zillion times and lost all fear, we'll move you to something slightly doggier and scarier, than something slightly doggier and scarier than that, and so on, until you're locked in the room with the Rottweiler.
It makes sense that once you're exposed to dogs a million times and it goes fine and everything's okay, you lose your fear of dogs - that's normal habituation. But now we're back to the original question - how come flooding doesn't work? Forgetting the barbarism, how come we can't just start with the Rottweiler?
The common-sense answer is that you only habituate when an experience with a dog ends up being safe and okay. But being in the room with the Rottweiler is terrifying. It's not a safe okay experience. Even if the Rottweiler itself is perfectly nice and just sits calmly wagging its tail, your experience of being locked in the room is close to peak horror. Probably your intellect realizes that the bad experience isn't the Rottweiler's fault. But your lizard brain has developed a stronger association than before between dogs and unpleasant experiences. After all, you just spent time with a dog and it was a really unpleasant experience! Your fear of dogs increases.
(How does this feel from the inside? Less-self-aware patients will find their prior coloring every aspect of their interaction with the dog. Joyfully pouncing over to get a headpat gets interpreted as a vicious lunge; a whine at not being played with gets interpreted as a murderous growl, and so on. This sort of patient will leave the room saying 'the dog came this close to attacking me, I knew all dogs were dangerous!' More self-aware patients will say something like "I know deep down that dogs aren't going to hurt me, I just know that whenever I'm with a dog I'm going to have a panic attack and hate it and be miserable the whole time". Then they'll go into the room, have a panic attack, be miserable, and the link between dogs and misery will be even more cemented in their mind.)
The more technical version of this same story is that habituation requires a perception of safety, but (like every other perception) this one depends on a combination of raw evidence and context. The raw evidence (the Rottweiler sat calmly wagging its tail) looks promising. But the context is a very strong prior that dogs are terrifying. If the prior is strong enough, it overwhelms the real experience. Result: the Rottweiler was terrifying. Any update you make on the situation will be in favor of dogs being terrifying, not against it!
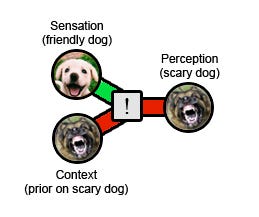
This is the trapped prior. It's trapped because it can never update, no matter what evidence you get. You can have a million good experiences with dogs in a row, and each one will just etch your fear of dogs deeper into your system. Your prior fear of dogs determines your present experience, which in turn becomes the deranged prior for future encounters.
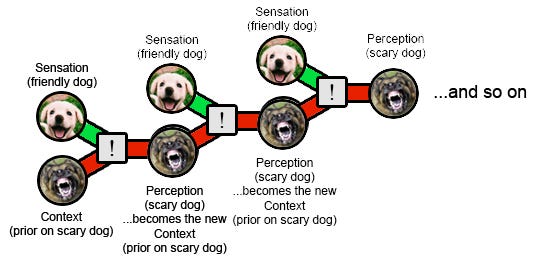
Trapped prior: the more complicated emotional version
The section above describes a simple cognitive case for trapped priors. It doesn't bring in the idea of emotion at all - an emotionless threat-assessment computer program could have the same problem if it used the same kind of Bayesian reasoning people do. But people find themselves more likely to be biased when they have strong emotions. Why?
Van der Bergh et al suggest that when experience is too intolerable, your brain will decrease bandwidth on the "raw experience" channel to protect you from the traumatic emotions. This is why some trauma victims' descriptions of their traumas are often oddly short, un-detailed, and to-the-point. This protects the victim from having to experience the scary stimuli and negative emotions in all their gory details. But it also ensures that context (and not the raw experience itself) will play the dominant role in determining their perception of an event.
You can't update on the evidence that the dog was friendly because your raw experience channel has become razor-thin; your experience is based almost entirely on your priors about what dogs should be like.
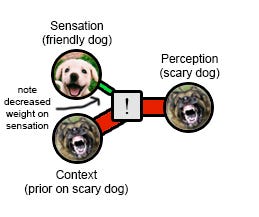
This diagram is a victim of my earlier decision to cram lots of things into the gray box in the middle. In earlier diagrams, I should have made it clear that a lot depended on the gray box choosing to weigh the prior more heavily than experience. In this diagram, less depends on this decision; the box is getting almost no input from experience, so no matter what its weighting function its final result will mostly be based on the prior. In most reasonable weighting functions, even a strong prior on scary dogs plus any evidence of a friendly dog should be able to make the perception slightly less scary than the prior, and iterated over a long enough chain this should update the prior towards dog friendliness. I don’t know why this doesn’t happen in real life, beyond a general sense that whatever weighting function we use isn’t perfectly Bayesian and doesn’t fit in the class I would call “reasonable”. I realize this is a weakness of this model and something that needs further study.
I've heard some people call this "bitch eating cracker syndrome". The idea is - you're in an abusive or otherwise terrible relationship. Your partner has given you ample reason to hate them. But now you don't just hate them when they abuse you. Now even something as seemingly innocent as seeing them eating crackers makes you actively angry. In theory, an interaction with your partner where they just eat crackers and don't bother you in any way ought to produce some habituation, be a tiny piece of evidence that they're not always that bad. In reality, it will just make you hate them worse. At this point, your prior on them being bad is so high that every single interaction, regardless of how it goes, will make you hate them more. Your prior that they're bad has become trapped. And it colors every aspect of your interaction with them, so that even interactions which out-of-context are perfectly innocuous feel nightmarish from the inside.
From phobia to bias
I think this is a fruitful way to think of cognitive biases in general. If I'm a Republican, I might have a prior that Democrats are often wrong or lying or otherwise untrustworthy. In itself, that's fine and normal. It's a model shaped by my past experiences, the same as my prior against someone’s claim to have seen a polar bear. But if enough evidence showed up - bear tracks, clumps of fur, photographs - I should eventually overcome my prior and admit that the bear people had a point. Somehow in politics that rarely seems to happen.
For example, more scientifically literate people are more likely to have partisan positions on science (eg agree with their own party's position on scientifically contentious issues, even when outsiders view it as science-denialist). If they were merely biased, they should start out wrong, but each new fact they learn about science should make them update a little toward the correct position. That's not what we see. Rather, they start out wrong, and each new fact they learn, each unit of effort they put into becoming more scientifically educated, just makes them wronger. That's not what you see in normal Bayesian updating. It's a sign of a trapped prior.
Political scientists have traced out some of the steps of how this happens, and it looks a lot like the dog example: zealots' priors determine what information they pay attention to, then distorts their judgment of that information.
So for example, in 1979 some psychologists asked partisans to read pairs of studies about capital punishment (a controversial issue at the time), then asked them to rate the methodologies on a scale from -8 to 8. Conservatives rated the pro-punishment study at about +2 and the anti-execution study as about -2; liberals gave an only slightly smaller difference the opposite direction. Of course, the psychologists had designed the studies to be about equally good, and even switched the conclusion of each study from subject to subject to average out any remaining real difference in study quality. At the end of reading the two studies, both the liberal and conservative groups reported believing that the evidence had confirmed their position, and described themselves as more certain than before that they were right. The more information they got on the details of the studies, the stronger their belief.
This pattern - increasing evidence just making you more certain of your preexisting belief, regardless of what it is - is pathognomonic of a trapped prior. These people are doomed.
I want to tie this back to one of my occasional hobbyhorses - discussion of "dog whistles". This is the theory that sometimes politicians say things whose literal meaning is completely innocuous, but which secretly convey reprehensible views, in a way other people with those reprehensible views can detect and appreciate. For example, in the 2016 election, Ted Cruz said he was against Hillary Clinton's "New York values". This sounded innocent - sure, people from the Heartland think big cities have a screwed-up moral compass. But various news sources argued it was actually Cruz's way of signaling support for anti-Semitism (because New York = Jews). Since then, almost anything any candidate from any party says has been accused of being a dog-whistle for something terrible - for example, apparently Joe Biden's comments about Black Lives Matter were dog-whistling his support for rioters burning down American cities.
Maybe this kind of thing is real sometimes. But think about how it interacts with a trapped prior. Whenever the party you don't like says something seemingly reasonable, you can interpret in context as them wanting something horrible. Whenever they want a seemingly desirable thing, you secretly know it means they want a horrible moral atrocity. If a Republican talks about "law and order", it doesn't mean they're concerned about the victims of violent crime, it means they want to lock up as many black people as possible to strike a blow for white supremacy. When a Democrat talks about "gay rights", it doesn't mean letting people marry the people they love, it means destroying the family so they can replace it with state control over your children. I've had arguments with people who believe that no pro-life conservative really cares about fetuses, they just want to punish women for being sluts by denying them control over their bodies. And I've had arguments with people who believe that no pro-lockdown liberal really cares about COVID deaths, they just like the government being able to force people to wear masks as a sign of submission. Once you're at the point where all these things sound plausible, you are doomed. You can get a piece of evidence as neutral as "there's a deadly pandemic, so those people think you should wear a mask" and convert it into "they're trying to create an authoritarian dictatorship". And if someone calls you on it, you'll just tell them they need to look at it in context. It’s the bitch eating cracker syndrome except for politics - even when the other party does something completely neutral, it seems like extra reason to hate them.
Reiterating the cognitive vs. emotional distinction
When I showed some people an early draft of this article, they thought I was talking about "emotional bias". For example, the phobic patient fears the dog, so his anti-dog prior stays trapped. The partisan hates the other party, so she can't update about it normally.
While this certainly happens, I'm trying to make a broader point. The basic idea of a trapped prior is purely epistemic. It can happen (in theory) even in someone who doesn't feel emotions at all. If you gather sufficient evidence that there are no polar bears near you, and your algorithm for combining prior with new experience is just a little off, then you can end up rejecting all apparent evidence of polar bears as fake, and trapping your anti-polar-bear prior. This happens without any emotional component.
Where does the emotional component come in? I think van der Bergh argues that when something is so scary or hated that it's aversive to have to perceive it directly, your mind decreases bandwidth on the raw experience channel relative to the prior channel so that you avoid the negative stimulus. This makes the above failure mode much more likely. Trapped priors are a cognitive phenomenon, but emotions create the perfect storm of conditions for them to happen.
Along with the cognitive and emotional sources of bias, there's a third source: self-serving bias. People are more likely to believe ideas that would benefit them if true; for example, rich people are more likely to believe low taxes on the rich would help the economy; minimum-wage workers are more likely to believe that raising the minimum wage would be good for everyone. Although I don't have any formal evidence for this, I suspect that these are honest beliefs; the rich people aren't just pretending to believe that in order to trick you into voting for it. I don't consider the idea of bias as trapped priors to account for this third type of bias at all; it might relate in some way that I don't understand, or it may happen through a totally different process.
Future research directions
If this model is true, is there any hope?
I've sort of lazily written as if there's a "point of no return" - priors can update normally until they reach a certain strength, and after that they're trapped and can't update anymore. Probably this isn't true. Probably they just become trapped relative to the amount of evidence an ordinary person is likely to experience. Given immense, overwhelming evidence, the evidence could still drown out the prior and cause an update. But it would have to be really big.
(...but now I'm thinking of the stories of apocalypse cultists who, when the predicted apocalypse doesn't arrive, double down on their cult in one way or another. Festinger, Rieken, and Schachter's classic book on the subject,When Prophecy Fails, finds that these people "become a more fervent believer after a failure or disconfirmation". I'm not sure what level of evidence could possibly convince them. My usual metaphor is "if God came down from the heavens and told you..." - but God coming down from the heavens and telling you anything probably makes apocalypse cultism more probable, not less.)
If you want to get out of a trapped prior, the most promising source of hope is the psychotherapeutic tradition of treating phobias and PTSD. These people tend to recommend very gradual exposure to the phobic stimulus, sometimes with special gimmicks to prevent you from getting scared or help you "process" the information (there's no consensus as to whether the eye movements in EMDR operate through some complicated neurological pathway, work as placebo, or just distract you from the fear). A lot of times the "processing" involves trying to remember the stimulus multimodally, in as much detail as possible - for example drawing your trauma, or acting it out.
Sloman and Fernbach might be the political bias version of this phenomenon. They ask partisans their opinions on various issues, and as usual find strong partisan biases. Then they asked them to do various things. The only task that moderated partisan extremism was to give a precise mechanistic explanation of how their preferred policy should help - for example, describing in detail the mechanism by which sanctions on Iran would make its nuclear program go better or worse. The study doesn't give good enough examples for me to know precisely what this means, but I wonder if it's the equivalent of making trauma victims describe the traumatic event in detail; an attempt to give higher weight to the raw experience pathway compared to the prior pathway.
The other promising source of hope is psychedelics. These probably decrease the relative weight given to priors by agonizing 5-HT2A receptors. I used to be confused about why this effect of psychedelics could produce lasting change (permanently treat trauma, help people come to realizations that they agreed with even when psychedelics wore off). I now think this is because they can loosen a trapped prior, causing it to become untrapped, and causing the evidence that you've been building up over however many years to suddenly register and to update it all at once (this might be that “simulated annealing” thing everyone keeps talking about. I can't unreservedly recommend this as a pro-rationality intervention, because it also seems to create permanent weird false beliefs for some reason, but I think it's a foundation that someone might be able to build upon.
A final possibility is other practices and lifestyle changes that cause the brain to increase the weight of experience relative to priors. Meditation probably does this; see the discussion in the van der Bergh post for more detail. Probably every mental health intervention (good diet, exercise, etc) does this a little. And this is super speculative, and you should feel free to make fun of me for even thinking about it, but sensory deprivation might do this too, for the same reason that your eyes become more sensitive in the dark.
A hypothetical future research program for rationality should try to identify a reliable test for prior strength (possibly some existing psychiatric measures like mismatch negativity can be repurposed for this), then observe whether some interventions can raise or lower it consistently. Its goal would be a relatively tractable way to induce a low-prior state with minimal risk of psychosis or permanent fixation of weird beliefs, and then to encourage people to enter that state before reasoning in domains where they are likely to be heavily biased. Such a research program would dialogue heavily with psychiatry, since both mental diseases and biases would be subphenomena of the general category of trapped priors, and it's so far unclear exactly how related or unrelated they are and whether solutions to one would work for the other. Tentatively they’re probably not too closely related, since very neurotic people can sometimes reason very clearly and vice versa, but I don't think we yet have a good understanding of why this should be.
Ironically, my prior on this theory is trapped - everything I read makes me more and more convinced it is true and important. I look forward to getting outside perspectives.
33 comments
Comments sorted by top scores.
comment by AnnaSalamon · 2021-03-23T23:17:30.779Z · LW(p) · GW(p)
The basic idea of a trapped prior is purely epistemic. It can happen (in theory) even in someone who doesn't feel emotions at all. If you gather sufficient evidence that there are no polar bears near you, and your algorithm for combining prior with new experience is just a little off, then you can end up rejecting all apparent evidence of polar bears as fake, and trapping your anti-polar-bear prior. This happens without any emotional component.
I either don't follow your more general / "purely epistemic" point, or disagree. If a person's algorithm is doing correct Bayesian epistemology, a low prior of polar bears won't obscure the accumulating likelihood ratios in favor of polar bears; a given observation will just be classified as "an update in favor of polar bears maybe being a thing, though they're still very very unlikely even after this datapoint"; priors don't mess with the direction of the update.
I guess you're trying to describe some other situation than correct Bayesian updating, when you talk about a person/alien/AI's algorithm being "just a little off". But I can't figure out what kind of "a little off" you are imagining, that would yield this.
My (very non-confident) guess at what is going on with self-reinforcing prejudices/phobias/etc. in humans, is that it involves actively insulating some part of the mind from the data (as you suggest), and that this is not the sort of phenomenon that would happen with an algorithm that didn't go out of its way to do something like compartmentalization.
If there's a mechanism you're proposing that doesn't require compartmentalization, might you clarify it?
Replies from: zhukeepa, Gunnar_Zarncke↑ comment by zhukeepa · 2021-04-27T02:16:53.285Z · LW(p) · GW(p)
Here's my current understanding of what Scott meant by "just a little off".
I think exact Bayesian inference via Solomonoff induction doesn't run into the trapped prior problem. Unfortunately, bounded agents like us can't do exact Bayesian inference via Solomonoff induction, since we can only consider a finite set of hypotheses at any given point. I think we try to compensate for this by recognizing that this list of hypotheses is incomplete, and appending it with new hypotheses whenever it seems like our current hypotheses are doing a sufficiently terrible job of explaining the input data.
One side effect is that if the true hypothesis (eg "polar bears are real") is not among our currently considered hypotheses, but our currently considered hypotheses are doing a sufficiently non-terrible job of explaining the input data (eg if the hypothesis "polar bears aren't real, but there's a lot of bad evidence suggesting that they are" is included, and the data is noisy enough that this hypothesis is reasonable), we just never even end up considering the true hypothesis. There wouldn't be accumulating likelihood ratios in favor of polar bears, because actual polar bears were never considered in the first place.
I think something similar is happening with phobias. For example, for someone with a phobia of dogs, I think the (subconscious, non-declarative) hypothesis "dogs are safe" doesn't actually get considered until the subject is well into exposure therapy, after which they've accumulated enough evidence that's sufficiently inconsistent with their prior hypotheses of dogs being scary and dangerous that they start considering alternative hypotheses.
In some sense this algorithm is "going out of its way to do something like compartmentalization", in that it's actively trying to fit all input data into its current hypotheses (/ "compartments") until this method no longer works.
Replies from: AnnaSalamon↑ comment by AnnaSalamon · 2021-05-01T03:44:22.386Z · LW(p) · GW(p)
I agree an algorithm could do as you describe.
I don't think that's what's happening in me or other people. Or at least, I don't think it's a full description. One reason I don't, is that after I've e.g. been camping for a long time, with a lot of room for quiet, it becomes easier than it has been to notice that I don't have to see things the way I've been seeing them. My priors become "less stuck", if you like. I don't see why that would be, on your (zhukeepa's) model.
Introspectively, I think it's more like, that sometimes facing an unknown hypothesis (or rather, a hypothesis that'll send the rest of my map into unknownness) is too scary to manage to see as a possibility at all.
↑ comment by Gunnar_Zarncke · 2021-03-24T14:40:57.322Z · LW(p) · GW(p)
Scott says
and your algorithm for combining prior with new experience is just a little off
And while he doesn't give a more detailed explanation I think it is clear that humans are not Bayesian but our brains use some kind of hack or approximation and that it's plausible that trapped priors can happen.
comment by weft · 2021-03-13T08:28:41.628Z · LW(p) · GW(p)
Amusingly, the example of humans that are scared of dogs most reminded me of my rescue dog who was scared of humans! Common internet advice is to use food to lure the dog closer to humans. That way they can associate new humans with tasty treats.
While this might work fine for dogs that are just mildly suspicious of strangers, it is actually bad for fearful dogs and reinforces the fear/stress response in the way Scott describes. Not knowing this, we tried the typical route and were surprised when our dog got even more reactive towards people. If she saw us talking to people, this was a sign that WE MIGHT MAKE HER GO TO THE PERSON (even though we never forced her, but luring her with treats was enough), so now just seeing us talking to people was enough to raise her stress levels and get a reaction.
I got a very good trainer, and she used the example of how if your boss hands you a paycheck while holding a gun to your head, the goodness of the paycheck doesn't overcome the gun to your head.
Instead of trying to get her to go near strangers, we told all strangers to completely ignore her. We taught her to run away from strangers, and tossed treats away from the strangers. If a stranger is nearby or even talking to me, they won't do anything scary like "look at her" (her previous life taught her that Attention From Humans is Dangerous), but instead she gets treats for running away.
Now she is still a little shy around strangers, and might bark once while running away if someone freaks her out a bit, but she volunteers to go up to people of her own will, and NOW we let strangers give her treats if she is willingly going up to them and sniffing around their hands without any prompting from any of us (and I continue to give her treats if she runs away as well)
comment by Raemon · 2021-03-19T02:25:59.805Z · LW(p) · GW(p)
Curated.
I... mostly just really like that this is one of the few posts in a while that seemed to make a credible advance at, you know, straightforwardly advancing the art of rationality. (Okay okay, Catching the Spark [LW · GW] also counted. And... okay okay I can actually list a number of posts that engage directly with this. But, I feel like it's not as common as I'd ideally like, or at least less direct. I liked that this post focused on it first-and-foremost, and established the context in which this was explicitly a rationality problem)
I particularly like laying out the further-research-directions at the end.
I think my main critique of this it doesn't really lay out how often the Trapped Priors problem actually happens. Scott lists some examples of it happening (which I definitely have recognized in the wild). But I'm not sure if this is more of a rare edge case, a moderately common failure mode, or completely pervasive.
Replies from: TurnTrout, None↑ comment by TurnTrout · 2021-03-19T14:02:51.464Z · LW(p) · GW(p)
I too got the sense that this post was plausibly Important for the art of rationality. It seems to me to have the Sequences quality of quickly obsoleting itself (“oh, duh, this is obviously correct now“) and I now have a crisp handle for this kind of mental bug. i think that having that kind of handle is quite important.
↑ comment by [deleted] · 2021-03-21T08:57:35.691Z · LW(p) · GW(p)
You could certainly make an argument that every major 'ism' and religion is just a trapped prior. Racism, sexism, ageism - all of them, a person generates a conclusion, perhaps supplied by others, that negative traits about members of a particular class are true.
And it could be that these negative traits are more prevalent in the class. But they then generalize where they interpret during any meeting of a member of that class that the negative trait is in fact true. It's also because the real world evidence is complicated. If you believe a member of a class is dumb as a rule, you can always pick some dumb behaviors or dismiss something smart they say as "too intellectual" or "is just reading the material he memorized".
As an example, early in Obama's term he gave a town hall where at least on video, the man on the fly appeared to answer each question with answers that were generally correct answers for each subject. Yet conservative relatives of mine somehow saw this as evidence as to how incompetent/too academic whatever this politician was. If you believe that poor people are lazy it's a similar thing. Or that homeless beggars are all faking it - oh look they have new shoes, must be lying.
comment by alkjash · 2021-03-13T03:36:11.972Z · LW(p) · GW(p)
Is the following interpretation equivalent to the point?
It can be systematically incorrect to "update on evidence." What my brain experiences as "evidence" is actually "an approximation of the posterior." Thus, the actual dog is [1% scary], but my prior says dogs are [99% scary], I experience the dog as [98% scary] which my brain rounds back to [99% scary]. And so I get more evidence that I am right.
comment by TurnTrout · 2021-03-12T20:27:06.822Z · LW(p) · GW(p)
I find the "trapped prior" terminology a bit strange, since a big part of the issue (the main part?) doesn't just seem to be about having a bad prior probability distribution, it's about bias in the update and observation mechanisms.
Replies from: DanielFilan, Zack_M_Davis↑ comment by DanielFilan · 2021-03-13T02:27:16.207Z · LW(p) · GW(p)
I guess I was imagining that the problem was the trapping, not the prior.
↑ comment by Zack_M_Davis · 2021-03-13T04:43:20.538Z · LW(p) · GW(p)
Maybe it's unfortunate that the same word is overloaded to cover "prior probability" (e.g., probability 0.2 that dogs are bad), and "prior information" in the sense of "a mathematical object that represents all of your starting information plus the way you learn from experience." [LW · GW]
comment by Kaj_Sotala · 2021-03-13T11:34:02.430Z · LW(p) · GW(p)
Somewhat anecdotally, Internal Family Systems [LW · GW] also seems effective for trauma/phobia treatment, and the model in this post would help explain why. If you access a traumatic memory in a way where the experience is explicitly framed as you empathetically listening to a part of your mind that's distinct from you and has this memory, then that foregrounds the context of "I'm safe and doing trauma treatment" and makes the trauma memory just a sensation within it.
This is also interesting to compare with this account of what it is like to be enlightened. The way that Ingram frames it is that while you can still be upset or emotionally affected by things that happen to you in the present, you will always maintain a sharp sense of your environment as the primary context. So e.g. recalling past upsetting events won't make you upset, because it's always obvious to you that those are just memories.
Replies from: warrenjordan↑ comment by warrenjordan · 2021-03-13T22:08:04.938Z · LW(p) · GW(p)
Scott's post reminded of memory reconsolidation. It seems to me that a "trapped prior" is similar to an "emotional schema" (not sure if that's the right term from UtEB).
If one can be aware of their schema or trapped prior, then there seems to be a higher chance of iterating upon it. However, it's probably not that simple to iterate even if you are aware of it.
comment by smountjoy · 2021-03-13T04:41:17.858Z · LW(p) · GW(p)
I don’t know why this doesn’t happen in real life, beyond a general sense that whatever weighting function we use isn’t perfectly Bayesian and doesn’t fit in the class I would call “reasonable”. I realize this is a weakness of this model and something that needs further study.
I'll take a stab at this.
You've got a prior, P(dog I meet is dangerous) = 0.99. (Maybe in 99 of your last 100 encounters with dogs, you determined that the dog was dangerous.) You've also got a sensation, "dog is wagging its tail," and some associated conditional probabilities. Your brain combines them correctly according to Bayes' rule; since your prior is strong, it spits out something like 95% probability that the dog is dangerous.
It then determines that the best thing to do is act afraid. It has no further use for the 95% number—it's not going to act with 5% less fear, or any less fear, just because there's a small chance the dog might not eat you. That would be a good way to get eaten. So it attaches the "dangerous" label to the dog and moves on to screaming/hiding/running. (I see alkjash has an idea about rounding that might be similar.)
You go to update your prior. You've seen one more dangerous dog, so the strength of your prior increases to 100/101.
The mistake your brain makes is updating based on the label (dangerous/not dangerous) instead of the calculated probability of danger. It kind of makes sense that the label would be the more salient node, since it's the one that determines your course of action.
This explanation isn't totally convincing (why can't I just store both the label and the probability? is that too much to ask of my monkey brain?), but it does match what I feel like my brain is doing when it traps itself in a belief.
Replies from: None, rudi-c↑ comment by [deleted] · 2021-03-21T09:02:17.812Z · LW(p) · GW(p)
Because you didn't get actually eaten by the other 99 dangerous dogs, just in a situation where you concluded you could have been killed or severely injured had things gone differently. A "near miss". So you have 99 "new misses". And from those near misses, there are common behaviors - maybe all the maneating dogs wagged their tails also. So you generate the conclusion that this (actually friendly) dog is just a moment from eating you, therefore it falls in the class of 'near misses', therefore +1 encounters.
You have another issue that your 'monkey brain' can't really afford to store every encounter as a separate bin. It is compressing.
It's a bit more complex than that and depends on neural architecture details we don't know yet, but I suspect we can and will accidentally make AI systems with trapped priors.
↑ comment by Rudi C (rudi-c) · 2021-03-16T22:21:42.911Z · LW(p) · GW(p)
Doesn’t this model predict people to be way more stupid than reality?
Replies from: martin-randall↑ comment by Martin Randall (martin-randall) · 2024-11-11T02:48:59.428Z · LW(p) · GW(p)
It predicts phobias, partisanship, and stereotypes. It doesn't predict generalized stupidity.
Maybe you think this model predicts more phobias than we actually see?
comment by Alex_Altair · 2023-01-12T22:23:34.842Z · LW(p) · GW(p)
This post gave me a piece of jargon that I've found useful since reading it. In some sense, the post is just saying "sometimes people don't do Bayesian updating", which is a pretty cold take. But I found it useful to read through a lot of examples and discussion of what the deal might be. In my practice of everyday rationality, this post made it easier for me to stop and ask things like, "Is this a trapped prior? Might my [or others'] reluctance to update be due to whatever mechanisms cause a trapped prior?"
comment by Joe Collman (Joe_Collman) · 2021-03-14T00:46:32.860Z · LW(p) · GW(p)
I think it's important to distinguish between:
1) Rationality as truth-seeking.
2) Rationality as utility maximization.
For some of the examples these will go together. For others, moving closer to the truth may be a utility loss - e.g. for political zealots whose friends and colleagues tend to be political zealots.
It'd be interesting to see a comparison between such cases. At the least, you'd want to vary the following:
Having a very high prior on X's being true.
Having a strong desire to believe X is true.
Having a strong emotional response to X-style situations.
The expected loss/gain in incorrectly believing X to be true/false.
Cultists and zealots will often have a strong incentive to believe some X even if it's false, so it's not clear the high prior is doing most/much of the work there.
With trauma-based situations, it also seems particularly important to consider utilities: more to lose in incorrectly thinking things are safe, than in incorrectly thinking they're dangerous.
When you start out believing something's almost certainly very dangerous, you may be right. For a human, the utility-maximising move probably is to require more than the 'correct' amount of evidence to shift your belief (given that you're impulsive, foolish, impatient... and so can't necessarily be trusted to act in your own interests with an accurate assessment).
It's also worth noting that habituation can be irrational. If you're repeatedly in a situation where there's good reason to expect a 0.1% risk of death, but nothing bad happens the first 200 times, then you'll likely habituate to under-rate the risk - unless your awareness of the risk makes the experience of the situation appropriately horrifying each time.
On polar bears vs coyotes:
I don't think it's reasonable to label the ...I saw a polar bear... sensation as "evidence for bear". It's weak evidence for bear. It's stronger evidence for the beginning of a joke. For [polar bear] the [earnest report]:[joke] odds ratio is much lower than for [coyote].
I don't think you need to bring in any irrational bias to get this result. There's little shift in belief since it's very weak evidence.
If your friend never makes jokes, then the point may be reasonable. (in particular, for your friend to mistakenly earnestly believe she saw a polar bear, it's reasonable to assume that she already compensated for polar-bear unlikeliness; the same doesn't apply if she's telling a joke)
comment by buybuydandavis · 2021-03-13T10:54:09.670Z · LW(p) · GW(p)
Someone else had pointed out in your previously linked comment "Confirmation Bias As Misfire Of Normal Bayesian Reasoning" that Jaynes had analyzed how we don't necessarily converge even in the long run to the same conclusions based on data if we start with different priors. We can diverge instead of converge.
Jaynes hits on a particular problem for truth convergence in politics - trust. We don't experience and witness events themselves, but only receive reports of them from others. Reports that contradict our priors on the facts can be explained by increasing our priors on the reported facts or downgrading our priors on the honesty of the reporter.
I'm not religious, but I've come to appreciate how Christianity got one thing very right - false witness is a sin. It's a malignant societal cancer. Condemnation of false witness is not a universal value.
ajbFebruary 13, 2020 at 2:05 pm
I think Jaynes argues exactly this in his textbook on the Bayesian approach to probability “Probability Theory:The Logic of Science”,
in a section called “Converging and Diverging views”, which can be found in this copy of Chapter 5
http://www2.geog.ucl.ac.uk/~mdisney/teaching/GEOGG121/bayes/jaynes/cc5d.pdf
Replies from: None↑ comment by [deleted] · 2021-03-21T09:05:41.765Z · LW(p) · GW(p)
Out of curiosity, suppose you record every datapoint used to generate these priors (and every subsequent datapoint). How do you make AI systems that don't fall into this trap?
My first guess is it's a problem in the same class as where when training neural networks, the starting random values are the prior. And therefore some networks will never converge on a good answer simply because they start with incorrect priors. So you have to roll the dice many more times on the initialization.
comment by Yoav Ravid · 2021-03-13T04:17:10.523Z · LW(p) · GW(p)
Thanks for crossposting! I hope you crosspost more in the future, there are already many posts from ACX (Especially the psychiatry ones) that i would love to have on LessWrong so we can use LW features such as tags, pingbacks and hover-view with them.
comment by PatrickDFarley · 2021-03-12T21:17:08.214Z · LW(p) · GW(p)
For those looking for a way to talk about this with outsiders, I'd propose "unconditional beliefs" as a decent synonym that most people will intuitively understand.
"Do you hold X as an unconditional belief?"
Replies from: Yoav Ravid↑ comment by Yoav Ravid · 2021-03-13T04:18:59.285Z · LW(p) · GW(p)
"What do you mean unconditional belief?"
"A thought that doesn't really change even when you see stuff that should change it. Like fearing dogs even after seeing lots of cute dogs"
comment by Mary Chernyshenko (mary-chernyshenko) · 2021-03-13T07:53:10.187Z · LW(p) · GW(p)
...I just keep hearing "paa" even when I turn my phone away and not look at the video at all.
comment by Yoav Ravid · 2023-01-21T13:39:04.983Z · LW(p) · GW(p)
I read this post when it came out and felt like it was an important (perhaps even monumental) piece of intellectual progress on the topic of rationality. In hindsight, it didn't affect me much and I've only thought back to it a few times, mainly shortly after reading it.
comment by Purged Deviator · 2022-01-19T05:37:08.306Z · LW(p) · GW(p)
With priors of 1 or 0, Bayes rule stops working permanently. If something is running on real hardware, then it has a limit on its numeric precision. On a system that was never designed to make precise mathematical calculations, one where 8/10 doesn't feel significantly different from 9/10, or one where "90% chance" feels like "basically guaranteed", the level of numeric precision may be exceedingly low, such that it doesn't even take a lot for a level of certainty to be either rounded up to one or rounded down to 0.
As always, thanks for the post!
comment by Yonatan Cale (yonatan-cale-1) · 2023-01-13T12:41:02.272Z · LW(p) · GW(p)
This post got me to do something like exposure therapy to myself in 10+ situations, which felt like the "obvious" thing to do in those situations. This is a huge amount of life-change-per-post
comment by alokja · 2021-03-20T11:17:09.598Z · LW(p) · GW(p)
I feel like I don't understand how this model explains the biggest mystery of expereinces sometimes having the reverse impact on your beliefs vs. what they should.
The more technical version of this same story is that habituation requires a perception of safety, but (like every other perception) this one depends on a combination of raw evidence and context. The raw evidence (the Rottweiler sat calmly wagging its tail) looks promising. But the context is a very strong prior that dogs are terrifying. If the prior is strong enough, it overwhelms the real experience. Result: the Rottweiler was terrifying. Any update you make on the situation will be in favor of dogs being terrifying, not against it!
Shouldn't your experience still be less terrifying than you expected it to be, becuase you're combining your dogs-are-terrifying-at-level-10 prior with the raw evidence (however constricted that channel is), so your update should still be against dogs being terrifying at level 10 (maybe level 9.9?)?
Maybe the answer is the thing smountjoy said below in response to your caption, that we don't have gradations in our beliefs about things -- dogs are either terrifying or not -- and then you have another example of dogs being terrifying to update with. FWIW that sounds unlikley to me -- people do seem to tend to have gradations in how evil republicans are or how terrifying dogs are in my experience. Though mabe that gets disabled in these cases, which seems like would explain it.
↑ comment by Evzen (Eugleo) · 2021-05-31T09:46:16.245Z · LW(p) · GW(p)
It could also be that the brain uses weights that are greater than 1 when weighting the priors. That way, we don't lose the gradation.
comment by Archimedes · 2021-03-23T14:56:14.871Z · LW(p) · GW(p)
The key to fixing a phobia or changing closely held beliefs seems to involve addressing it within an environment that is perceived as safe. When a person feels attacked or threatened, the instinctive and emotional System 1 of the brain tends to dominate and this system is more heuristic than Bayesian. You can't rationally update a prior that is not based on rationality, so the trick is to coax that prior into a space where it can be examined by the more logical and deliberate System 2.
The cognitive vs emotional section addresses this but I'm not convinced that the set of purely epistemic trapped priors is significant compared to the much larger set of emotionally trapped priors. Are there better examples than the polar bear of non-emotional trapping?
comment by Slider · 2021-03-13T13:38:32.875Z · LW(p) · GW(p)
Senses turn the environment into cognitive objects. Their "left side" is signficantly different from the "right side". Having "white wine" -> "white wine" as identity operation seems misleading.
The wine situation seems perfectly natural if you have "tastes like wine"+"visual transparent"->"white wine" and "tastes like wine"+"visual red"-> "red wine". Like the japanese have r and l within the same letter, if you have "white wine" and "red wine" within the same "taste" that is not prior overriding the experience that is experience bookkeeping class-delineations being wide ie ambigious.
What is upkeeping the forced exposure phobia is the trauma. It might not be about dogs any more but more of fear of fear itself.
In the political sense, if you take challenging input seriusly it can make upkeeping a picture of the world more muddled, conflicting and laboursome. This can feel like a failure and it can feel like producing a bad model ie an epistemological punishment. Whereas processing beliefs that are aligned to you is easy and generates workable insights more rapidly. Even beside making you the hero of the story, it more succesfully makes a story ie generates workable representations. So if one wants to faciliate political discussion then avoiding feelings of confusion might make sense.