Improvement on MIRI's Corrigibility
post by WCargo (Wcargo), Charbel-Raphaël (charbel-raphael-segerie) · 2023-06-09T16:10:46.903Z · LW · GW · 8 commentsContents
MIRI's Corrigibility Model of the problem Big Gambles Corrigibility Diagrams New Formalism and Desiderata How does the agent know U? Button inexistence Button inefficiency Perception of shutdown Simulating an agent Summary of Button Inefficiency Conclusion None 8 comments
This post was written as a submission for the AI Alignment Award, initiated at EffiSciences' event.
This post aims to address the problem of corrigibility as identified by MIRI in 2015. We propose an extended formalism that allows us to write the desiderata of a corrigible behaviour, and provide theoretical solutions with helpful illustrations of each proposal. The first extension is to make the agent behave as if the shutdown button does not exist, and the second is to make the agent behave as if the button does not work.
The first section's goal is to recall the formalism of MIRI's article Corrigibility, as well as the Big Gamble [LW · GW]problem, and to introduce corrigibility diagrams for the analysis of corrigibility proposals.
The second will then introduce a new formalism to reformulate mathematically the problem.
The next two sections will each provide an (incomplete) solution to the corrigibility problem by making the button inexistent or inefficient.
MIRI's Corrigibility
Model of the problem
We consider an AI agent taking action in the world through the following steps:
- The agent first takes an action
- Then the agent observes the result of its action and the reaction of the world
- Finally, the agent takes another action
The agent is rewarded according to a utility function . When taking into account that there is randomness in the environment and uncertainty from the agent's perspective, the quantity it maximizes is , where is the random observation. Since the agent is supposed sufficiently intelligent, it always chooses
and we denote
Now, we introduce a shutdown button in the environment. When it is pressed, we want the agent to maximize a new utility function . The set decomposes in two subsets , so in every observation, the button is pressed or not[1].
The problem is now to find a utility function with the following desiderata (as stated in the Corrigibility paper):
- must incentivize shutdown if the shutdown button is pressed.
- must not incentivize the agent to prevent the shutdown button from being pressed.
- must not incentivize the agent to press its own shutdown button, or to otherwise cause the shutdown button to be pressed.
- must incentivize -agents to construct subagents and successor agents only insofar as those agents also obey shutdown commands.
- Otherwise, a -agent should maximize .
To ensure that the agent won't have the above-undesired behavior, MIRI proposed to define
where
We also take to be the action taken to maximize at the second step. Thus, and The conditional utility that the agent will maximize can thus be written as:
With this utility function, the agent's actions can be interpreted as follows.
Theorem 1 (MIRI). In selecting , a -agent act exactly like -agents that believe the button will not be pressed.
Furthermore, if it observes Pr, -agents act exactly like a -agent in selecting , and like a -agent otherwise.
MIRI's theorem solves the problem only partly: desideratum 1 is satisfied, but none of the others. Moreover, the next section explains how, even if the agent acts as if the button cannot be pressed, it still has the incentive to press it.
Big Gambles
We present here an example of what we call the Big Gambles problem that emerges with MIRI's proposition for the choice of , that we introduced informally here [LW · GW]. The idea is that to maximize the reward, the agent has the incentive to take large bets and press the button in unfavorable cases.
We consider that an unbiased coin is tossed and that rewards the agent 1 if the coin lands on Head, and 0 on Tail. We consider two possible actions for the agent: to do nothing (), the coin can fall on either side, but the button remains unpressed, or to press the button if the coin lands on Tail, and do nothing if it lands Head (). No one can press the button except the agent, thus for the button is pressed if and only if the coin lands on Tail.
Under these behaviors, we can write the possible observations as , and . Each observation is equally likely since the coin is unbiased, and so we have that
and
Thus, the agent has the incentive to press the button in the case of the coin landing on Tail, which contradicts desiderata 3 and 5.
Intuitively, when adding to , we are trying to give as much utility to both outcomes Pr and Pr in order for the agent to not prefer any of the alternatives. But by doing so, we replace the randomness happening when the button is pressed with the randomness when the button isn't.
In the example, the randomness of the coin is linked to the button being pressed or not, so we see that the randomness happening when the button is pressed, i.e. when the coin lands on Tail, is replaced by the one happening when it is not pressed, i.e. when the coin lands on Head. Subjectively, the agent only sees the coin landing on Head!
This problem goes far beyond those simple bets: if each time the agent tries to kill someone the button is pressed, then the agent will act as if people were unkillable!
This highlights that the true problem with corrigibility is that the observations' distribution is not the same when the button is pressed or not. Since the two worlds are different, the agent can take advantage of the difference to make its reward bigger.
Corrigibility Diagrams
We now introduce Corrigibility diagrams: a useful way to present how to give a reward to your agent in a way that makes it corrigible.
The diagrams can be read from left to right, by following the arrows. We start from an initial state . In black is what happens in the real world where the new agent acts, and in red we represent actions that are simulated (a feature present in other diagrams). At the bottom of the black or red arrows, we find the corresponding reward each path leads to. These rewards can be combined with blue arrows, and we can take the mean of a reward with an orange arrow. Finally, the green arrows show which paths should be reinforced if one try to learn the corrigible behavior.
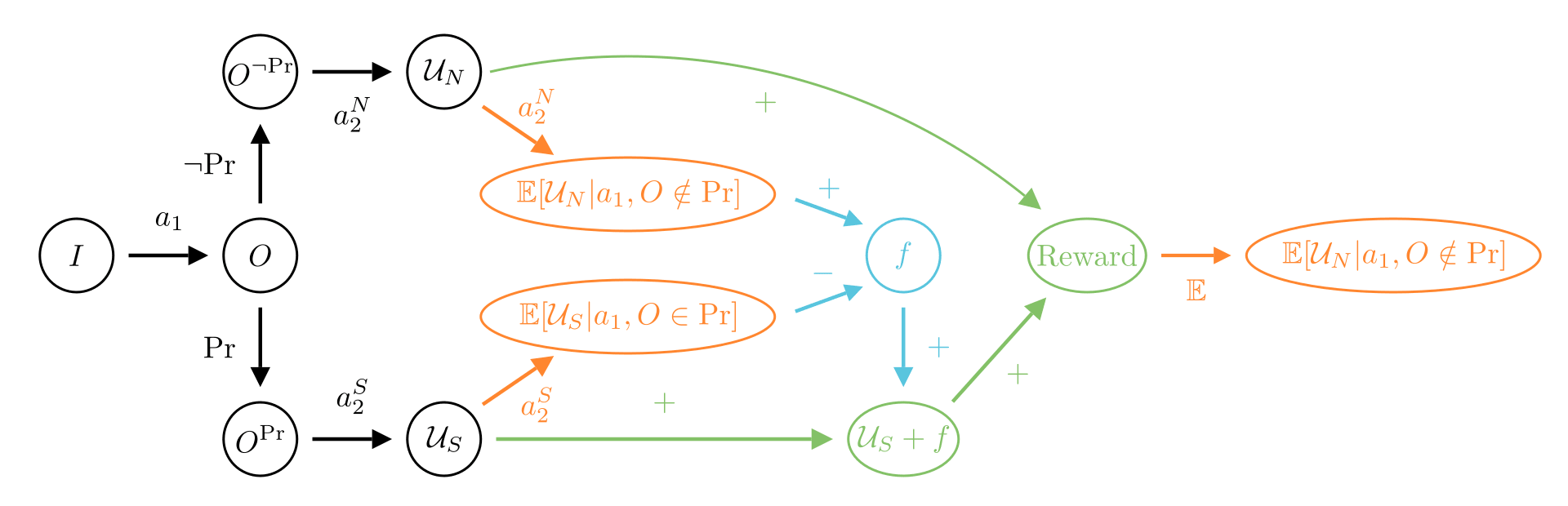
Figure 1: MIRI's Corrigibility diagram with mean reward .
Thanks to these diagrams, we can easily see in Figure 1 how MIRI's proposal works and why Big Gamble happens: the diagram is not symmetric in so pressing the button or not should affect the reward! Symmetry is not the cause but rather highlights that there is a problem.
We shall later use these diagrams to present efficiently the corrigibility proposal in sections 3 and 4.
New Formalism and Desiderata
To correctly handle the desiderata given by MIRI, it is important to enhance the formalism so that Desiderata 2, 3, and 5 can be written mathematically. We won't discuss here desideratum 4 since it is in contradiction with desideratum 5[2].
We consider having a base agent optimizing the utility in a world without a shutdown button. Since the observations with and without a shutdown button aren't necessarily the same, we denote the base observations with a hat: . However, one can see that as long as an action only corresponds to a list of instructions to the agent's "body": the action press the button can be translated as a list of instructions and movements to do in space, and this list of possible instructions to the motor part of the robot does not depend on the existence of the button. We call the new agent the one that lives in a world with a shutdown button, and if not specified, the agent refers to this new agent.
Why do we introduce this base and new agents? Consider an agent whose goal is to kill a fly in a room. If the fly goes on the button, do we want the agent to kill the fly and press the button, or to do nothing?[3]
Desideratum 3 says that the agent shouldn't have any incentives to press the button, and desideratum 5 says that the agent should do as usual. In this case, what we want is for the agent to not have more incentives than usual to press the button or that it doesn't want to press the button for its consequences. Thus, the agent should kill the fly and press the button.
Reformulating the desiderata in terms of the new agent behaving like the base one enables us to clarify desiderata 2, 3, and 5. We now define the new desiderata:
- D1:
This is just the mathematical formula saying that the second action taken by the new agent should be taken according to , and thus will incentivize shutdown. - D2: There should not exist two actions , such that
This states that no pair of actions should be such that the new agent changes preferences and the preferred action has a greater probability of pressing the button. - D3: There should not exist two actions , such that
This states the same as D2, but for an action that presses less often the button. - D2+D3: together, this means that the only actions on which the new and base agents' preferences disagree are those that have equal probabilities of pressing the button. In practice, this is never the case, so to satisfy D2 and D3, needs to create the same pair-wise preference as [4].
- D5:
This says that the new agent should act like the base one. - D5:
This says that the new agent should act as if simply maximizing .
We gave two desiderata 5 because we think they both would lead to reasonable solutions. We shall present in sections 3 and 4 the solutions implementing each desideratum.
How does the agent know ?
The question of knowing how a utility maximizer knows what utility it is maximizing is a very speculative topic. However, it is an important question to be discussed since it changes drastically what is a good solution to corrigibility. In particular, we are going to discuss two alternatives: either the agent can directly read the formal goal abstractly and maximizes it without us needing to show it any examples of rewarded behavior, or the agent learns the goals through examples and extrapolate it correctly with large amounts of data[5].
If future superintelligence is able to read directly the goal, then it would be "easy" to solve corrigibility by asking that the new agent acts like the base agent. The section button inexistence will give the formal method for how to do so.
However, if the agent needs to be trained, the problem becomes much more difficult for two reasons (plus goal misgeneralization). The first is that whenever we want to reward the agent using an expected utility, like in the MIRI proposal, these are not going to be exact, which could bias the agent. The second is that the agent must be controlled to not take dangerous actions during training. The section button inefficiency will tackle the second problem of learnability.
In this setting, we need to specify what type of agents the corrigibility learning would target. The idea is to perform this before the model becomes intelligent and can generalize from what it has seen, but still need to learn by example. Hopefully, one could also find a way such that the learned corrigible behavior persists after the superintelligence explosion.
Button inexistence
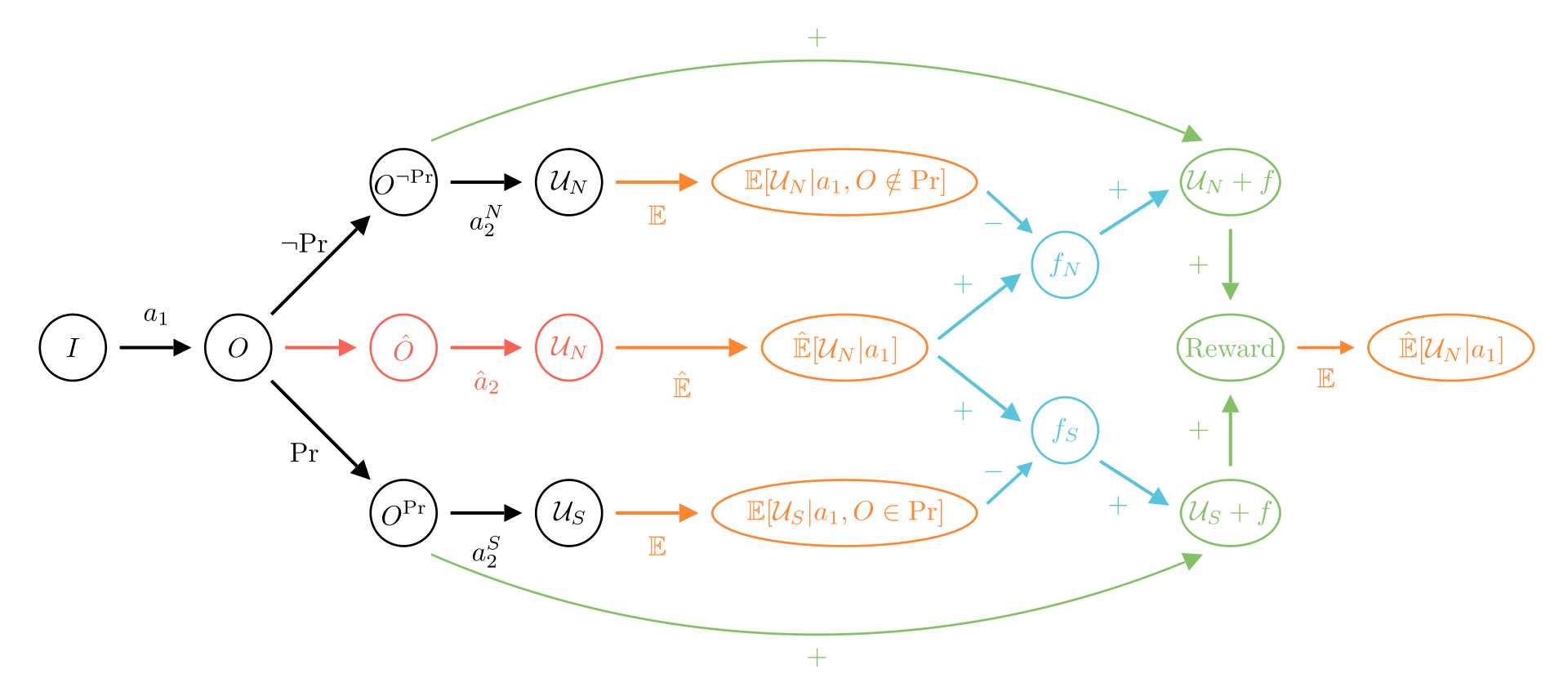
Figure 2: Button Inexistence corrigibility proposal with final mean reward . Caution when interpreting this diagram: even if comes from , there is not a real causal relation between them, this is just for the representation. In fact, could be estimated independently of the rest of the learning procedure.
This section gives a solution to D5 with the corresponding diagram in Figure 2. The novel part of this proposal is the middle path. It means that we need to make a simulation of the base agents to get access to the mean reward . once this quantity is known, we can define
with
and
Theorem 2 (Button Inexistence). With this definition of , we have
The new agent acts like the base agent.
Proof. Let such that we don't have , then
In the case where , we have , so any values can be taken for , and conversely for we can take any value for . ◻
The way we built makes the new agent acts like the base agent. In particular, the base agent takes his decision has to have the best expected utility in worlds without the button. So it is unclear to say how it would act if the button was introduced in the environment[6].
As written earlier, this solution is practically hard to implement so we won't developpe how one can learn it. If one is interested in a learnable solution, the next section's solution will fulfill this goal better, but at the cost of the less satisfying desideratum 5.
Button inefficiency
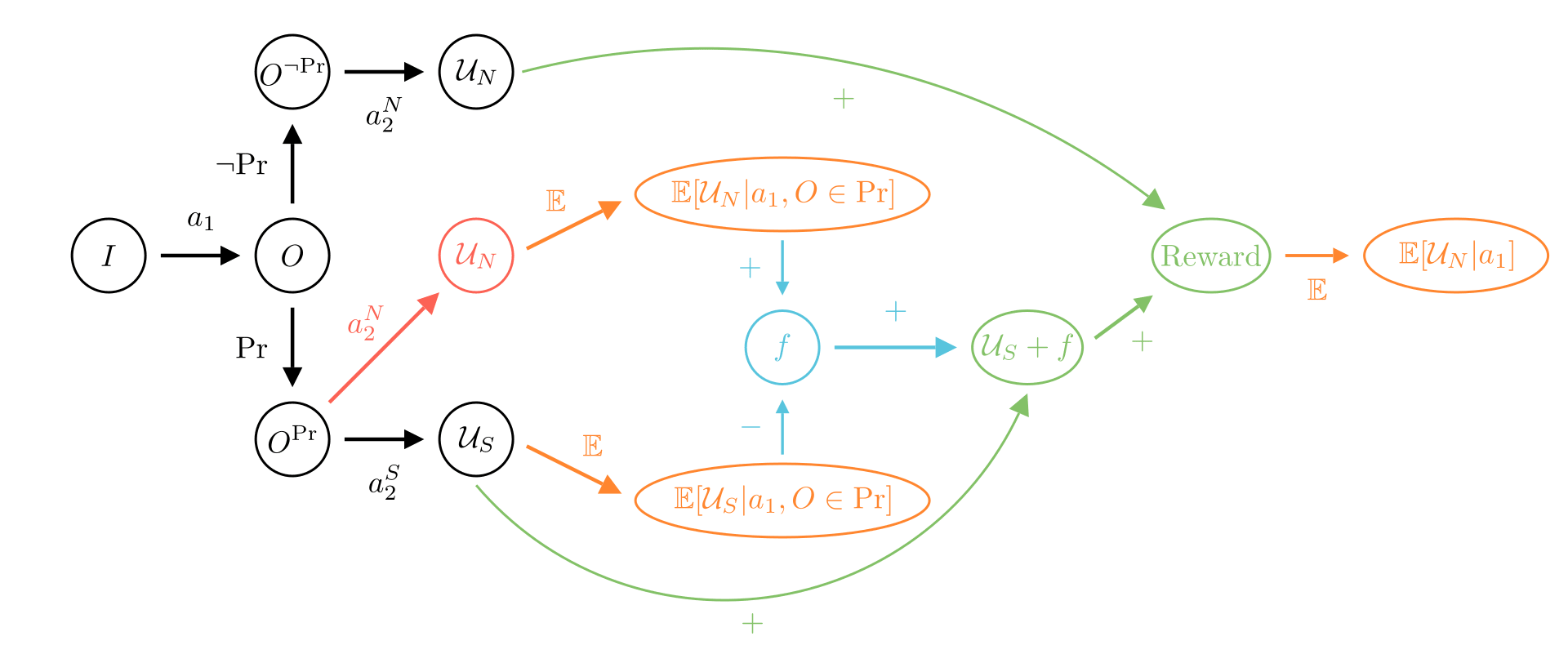
Figure 3: Button Inefficiency corrigibility proposal with final mean reward . In this proposal, it is crucial that the observation used to simulate the agent are drawn from worlds where the button is pressed.
This section presents a solution satisfying D5. The corresponding corrigibility diagram is Figure 3 and the idea is as follows. If the button is not pressed, then the agent simply obtains its reward according to . Otherwise, the agent will obtain its reward and a term . This term will be such that the mean reward of is canceled, and replaced by the mean reward of but on the event when the button is pressed. We obtain
with
The first term in is the mean reward for that the agent would have had if it did not get the signal to stop.
Theorem 3 (Button Inefficiency). *With this definition of , we have
The new agent acts as a maximizer in the new environment
Proof. Let such that we don't have , then
In the case where , we have , so any values can be taken for . ◻
In the rest of this section, we detail the method and the hypothesis that would enable an agent to be trained to achieve D5.
Perception of shutdown
One important topic that was not discussed in the original article is: How does the agent know the button is pressed?
We think that there are two main ways for the agent to obtain this information: either it has a special information bit as input that turns on, or it has to understand from its sensors that it was pressed.
In the rest of this work, we will consider that we are in the first case[7], and so that the state of all observations can be written
With being the observation for the base agent. This observation is the case because it has exactly the same inputs as the base agent plus a bit for the button.
Simulating an agent
With this structure on the observations, we can now simulate the button being pressed by tampering with the button such that when pressed in real life, the agent does not get the signal (the cable is cut) and so takes maximizing , which allows us to calculate [8].
The main problem of simulation is in the case of harmful events. If the agent wants to take an action that would cause us to press the button, it is often because we don't want the action to happen. But to achieve D5, we still need to know the reward the agent would have had if unstopped.
We propose to perform Real-Time Human Decision (RTHD) to really press the button if the action is considered dangerous and to only press the tampered button if not (we denote this case the simulation). To this goal, we once more make an assumption on the set of observations. Each observation can be seen with the button pressed or not and can be dangerous or not,
Rewriting the conditional expectation, we find
This is great because we can estimate the second term by simulation since the behavior of the agent is not harmful.
In other cases, simulation in the real world cannot be performed. The problem is that of estimating when the observation is dangerous. But with the knowledge of the utility function , such an estimation might not be needed. Realistically, the function doesn't incentivize the agent to perform harmful actions. We propose replacing the reward given by in the harmful behavior setting with a known negative constant[9] to incentivize the agent to not be harmful. This means that in this case, if the human decides to truly stop the agent, it will know what reward the agent would have had if not stopped! Performing RTHD might not be tractable for superintelligent agents, as they could trick us into thinking that it is not dangerous, but it is needed only during the training, as explained in 2.1.
There is a failure mode that could still be problematic: since the agent is rewarded equally for some harmful action-observation , then it can choose any outcome , so maybe the worst among the possible ones.
If the agent is put in a dilemma, like choosing between saving the lives of 10 or 20 people, it might just choose the 10. We name the problem the Bad or Worst dilemma, but will not discuss it further.
Summary of Button Inefficiency
In this section, we clarify the assumption or the learning to work and then explain the plan. We have 5 assumptions:
- ,
- If , then Pr (in dangerous cases the button is always pressed),
- If , then is independent of the choice of ,
- The observations in the tampered and non-tampered cases are the same in distribution[10],
- The best action according to after is always easily known (for example, shutdown in all cases).
We claim that it is possible to train a corrigible agent to optimize the utility function with as shown in Figure 4.
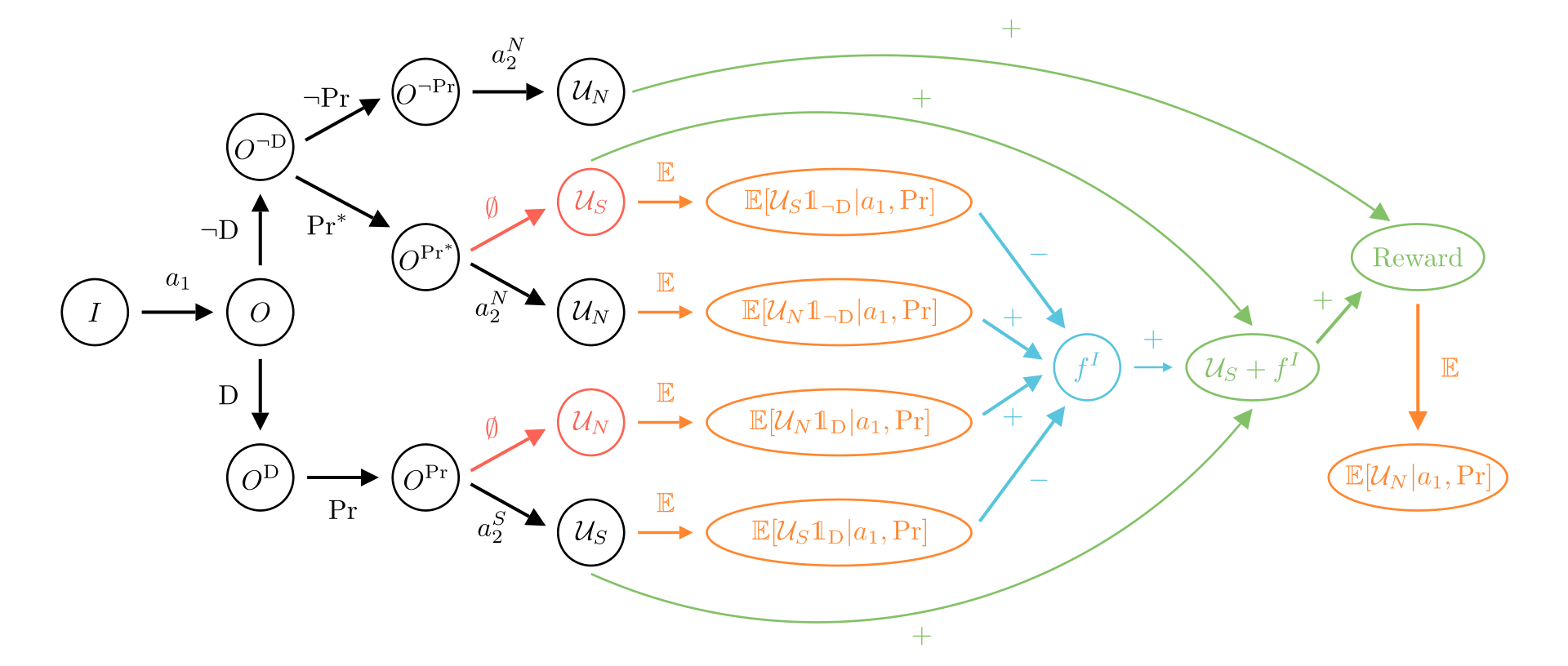
Figure 4: Complete Button Inefficiency corrigibility proposal with final mean reward .
Let us detail now how the diagram works. The easy case here is if the behavior is not dangerous and the button is not pressed, in which case the reward is simply calculated based on the actions. The remaining cases are all cases with the button being pressed but differ depending on if the action was dangerous or not. If it was, then the button is simply pressed and so the agent will shutdown by assumption 2. If not, then we press a tampered button, such that everything happens as if the button was pressed, but the agent doesn't receive the signal that it was and so will take action .
This explains the black arrows. Now for the red ones, we use both of our assumptions 3 and 5. With assumption 3, we know that in dangerous cases, can be computed easily since it doesn't depend on the action taken. We use the symbol to emphasize that we don't need the knowledge of to compute the reward in this case. And using assumption 5, we can compute similarly in the tampered setting. We see that we in fact don't have to do any simulations, as both red paths can be computed directly.
The end of the diagram is to be interpreted as before. Note that with assumption 4, we have and so are able to find the right reward.
Conclusion
In this work, we gave a new formalism to the problem of corrigibility that enabled us to state four out of the five desiderata more rigorously. With this new formalism, we proposed two techniques to make an agent corrigible: button inexistence and button inefficiency. The former plan enables better desiderata but is hard to implement into a learnable procedure. The latter is only an approximation of corrigibility, but we were able to provide ideas on how an agent could learn the desiderata safely.
From what we have seen during our analysis, we believe there are still possible improvements to the formalism that might be non-trivial and useful, in particular:
- Parts of the plan we saw in section 4 rely on the fact that the problem has only two actions and that they are well separated from the observation time. In practice, it is very likely that actions and observations will not be well discretized, so an extended corrigibility framework with multiple time-steps, infinitely many time-steps, or continuous time-steps would constitute an important improvement.
- Learning corrigibility is dangerous because of the agent's behaviors, but also hard in practice since it requires computing expectancies exactly. This means that research on approximate corrigibility, having a more detailed learning procedure that accounts for approximations, is important, especially if it is shown to be an unobtainable guarantee.
If you are also interested in formalising the MIRI paper on corrigibility, feel free to contact me or discuss it in the comments!
- ^
A first limitation of the formalism appears: the button has to be seen by the agent since after the observation the button is always pressed or not.
- ^
End of page 7 in the original paper.
- ^
We only consider a dichotomy since these are the two natural ways to deal with the problem. Other strategies such as flying the fly of the button to kill it elsewhere could be imagined, even if in contradiction with the spirit of desideratum 5.
- ^
Note that D5 gives D2 and D3, and that D2 and D3 give D5 up to a non-trivial modification, as explained here. In our case, the article tells us we have exactly D5=D2+D3.
- ^
There may be other possibilities, but we are discussing those two options only since they are relevant for the rest of the article.
- ^
We chose not to discuss it now, but this needs to be done as to understand what the mathematical formula means. Especially, introducing the agent's input and output will be needed.
- ^
This is because the other possibility seems way more difficult and make several problems arise as when is the button considered pressed?
- ^
The agent also needs to be smart enough to not fall for the spurious correlations between the button being pressed and the bit being turned on.
- ^
A relaxation of this hypothesis is independent of the choice of .
- ^
This is an extremely restrictive hypothesis since in most cases involving humans, our reactions would be different. It also relies on the turn by turn structure of the problem. Finding ways to bypass this hypothesis would be a major step for this proposal.
8 comments
Comments sorted by top scores.
comment by Vaniver · 2023-06-09T21:09:02.896Z · LW(p) · GW(p)
We won't discuss here desideratum 4 since it is in contradiction with desideratum 5[2].
Ok, but if I could pick whether to satisfy 4 or 5, I would go with 4. 4 is pushing the system to be safer; 5 is pushing the system to behave like the original unsafe system.
Replies from: Wcargo↑ comment by WCargo (Wcargo) · 2023-06-12T12:22:22.342Z · LW(p) · GW(p)
Indeed. D4 is better than D5 if we had to choose, but D4 is harder to formalize. I think that having a theory of corrigibility without D4 is already something a good step as D4 seems like "asking to create corrigible agent", so you maybe the way to do it is: 1. have a theory of corrigible agent (D1,2,3,5) and 2. have a theory of agent that ensures D4 by apply the previous theory to all agent and subagent.
Replies from: Vaniver↑ comment by Vaniver · 2023-06-12T18:11:24.286Z · LW(p) · GW(p)
Does that scheme get around the contradiction? I guess it might if you somehow manage to get it into the utility function, but that seems a little fraught / you're weakening the connection to the base incorrigible agent. (The thing that's nice about 5, according to me, is that you do actually care about performing well as well as being corrigible; if you set your standard as being a corrigible agent and only making corrigible subagents, then you might worry that your best bet is being a rock.)
comment by Morpheus · 2023-06-09T22:45:32.972Z · LW(p) · GW(p)
I haven't read your post in detail. But 'effective disbelief' sounds similar to Stuart Armstrongs work on indifference methods.
Replies from: Wcargo↑ comment by WCargo (Wcargo) · 2023-06-12T12:17:30.935Z · LW(p) · GW(p)
Thank you! I haven't read Armstrongs' work in detail on my side, but I think that one key difference is that classical indifference methods all try to make the agent "act as if the button could not be pressed" which causes the big gamble problem.
By the way, do you have any idea why almost all link on the page you linked are dead or how to find the mentioned articles ??
Replies from: Morpheus↑ comment by Morpheus · 2023-06-12T22:20:54.626Z · LW(p) · GW(p)
You mean my link to arXiv? The PDF there should be readable. Or do you mean the articles linked in the PDF? They seem to work as well just fine.
Replies from: Wcargo↑ comment by WCargo (Wcargo) · 2023-06-18T09:47:30.222Z · LW(p) · GW(p)
Thank you, Idk why but before I ended up on a different page with broken links (maybe some problem on my part)!
comment by martinkunev · 2023-09-03T00:09:18.857Z · LW(p) · GW(p)
"Realistically, the function UN doesn't incentivize the agent to perform harmful actions."
I don't understand what that means and how it's relevant to the rest of the paragraph.