AI Safety 101 - Chapter 5.1 - Debate
post by Charbel-Raphaël (charbel-raphael-segerie) · 2023-10-31T14:29:59.556Z · LW · GW · 0 commentsContents
Outline Summary: Reading Guidelines Debate AI safety via debate (Irving et al., 2018) Some limitations are: Progress on AI Safety via Debate (Barnes and Christiano, 2020) Problems with informal, free-text debates: Evasiveness Evasiveness Solution to Evasiveness Misleading implications Solution to Misleading implications Further problems with ambiguity Debate update: obfuscated arguments problem (Barnes and Christiano, 2020) Debate with LLM “One-turn” debate: AI-written Critiques (Saunders et al., 2022) a) Scalable Oversight b) Evaluation of Latent Knowledge Two-turn debate and problems with debate (Parrish et al., 2022) Bonus: Additional technique for better debate Sources None No comments
This text is an adapted excerpt from the 'Adversarial techniques for scalable oversight' section of the AGISF 2023 course, held at ENS Ulm in Paris in April 2023. Its purpose is to provide a concise overview of the essential aspects of the session's program for readers who may not delve into additional resources. This document aims to capture the 80/20 of the session's content, requiring minimal familiarity with the other materials covered. I tried to connect the various articles within a unified framework and coherent narrative. You can find the other summaries of AGISF on this page. This summary is not the official AGISF content. The gdoc accessible in comment mode, feel free to comment there if you have any questions. The different sections can be read mostly independently.
Thanks to Jeanne Salle, Amaury Lorin and Clément Dumas for useful feedback and for contributing to some parts of this text.
Outline
Last week we saw task decomposition for scalable oversight. This week, we focus on two more potential alignment techniques that have been proposed to work at scale: debate and training with unrestricted adversarial examples.
Scalable oversight definition reminder: “To build and deploy powerful AI responsibly, we will need to develop robust techniques for scalable oversight: the ability to provide reliable supervision—in the form of labels, reward signals, or critiques—to models in a way that will remain effective past the point that models start to achieve broadly human-level performance” (Amodei et al., 2016).
The reason why debate and adversarial training are in the same chapter is because they both use adversaries, but in two different senses: (1) Debate involves a superhuman AI finding problems in the outputs of another superhuman AI, and humans are judges of the debate. (2) Adversarial training involves an AI trying to find inputs for which another AI will behave poorly. These techniques would be complementary, and the Superalignment team from OpenAI is anticipated [LW(p) · GW(p)] to utilize some of the techniques discussed in this chapter.
Assumptions: These techniques don’t rely on the task decomposability assumption required for iterated amplification (last week), they rely on different strong assumptions: (1) For debate, the assumption is that truthful arguments are more persuasive. (2) For unrestricted adversarial training, the assumption is that adversaries can generate realistic inputs even on complex real-world tasks.
The list of papers which are presented in this chapter are presented in the list of references at the end of this chapter.
Summary:
- The original Debate paper: AI safety via debate (Irving et al., 2018), introduced the technique and the motivation for debates: being able to judge the AI debating should be easier than being able to debate.
- Designing a good debate mechanism: Progress on AI Safety via Debate (Barnes and Christiano, 2020) [AF · GW] follows from the original paper “AI Safety via Debate”. This work investigates mechanisms to design productive debates.
- Problems with debate: Unfortunately, the problem of Obfuscated arguments problem (Barnes and Christiano, 2020) [AF · GW] shows that debate might not work for complex topics.
- Debate with LLMs:
- One-turn debate: AI-written critiques help humans notice flaws (Saunders et al., 2022) focuses on the practical and theoretical aspects of debate and is akin to a "one-step debate" where each party only gives a single argument. This is a very important paper because it also introduces the generator-discriminator-critic gap, which is a way to measure the latent knowledge of neural networks.
- Two-turn debate: Unfortunately, Two-turn debate doesn’t help humans answer hard reasoning comprehension questions (Parrish et al., 2022), showing that it's difficult for humans to be confident judges.
Reading Guidelines
As this document is quite long, we will use the following indications before presenting each paper:
| Importance: 🟠🟠🟠🟠🟠 Difficulty: 🟠🟠⚪⚪⚪ Estimated reading time: 5 min. |
These indications are very suggestive. The difficulty should be representative of the difficulty of reading the section for a beginner in alignment, and is not related to the difficulty of reading the original paper.
Sometimes you will come across some "📝Optional Quiz", these quizzes are very optional and you cannot answer all the questions with only the summaries in the textbook.
Debate
This section summarizes a line of research in which each work builds upon the previous one. The papers are presented in chronological order according to their publication date.
AI safety via debate (Irving et al., 2018)
| Importance: 🟠🟠🟠🟠🟠 Difficulty: 🟠🟠⚪⚪⚪ Estimated reading time: 10 min. |
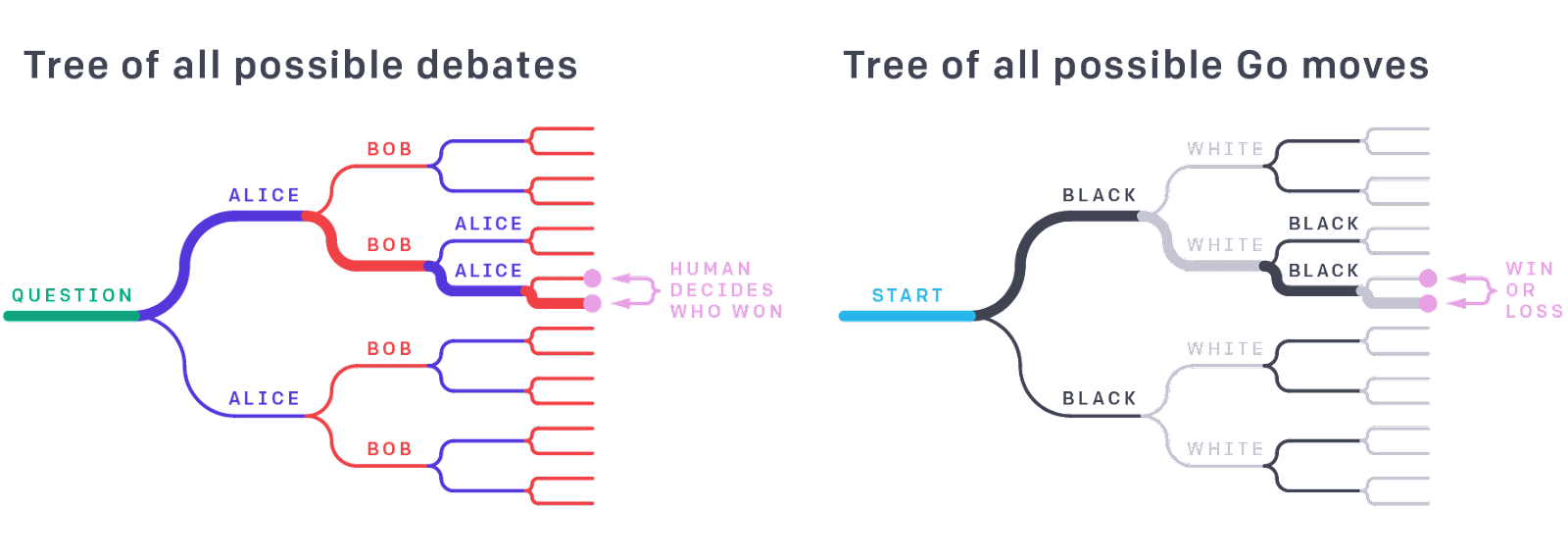
The idea behind AI safety via debate (Irving et al., 2018) is that it is easier to judge who wins at chess than to play chess at a grandmaster level. It’s easier to judge the truth of a debate than to either come up with an argument or to give feedback on a long argument without other debating sides. Debate is like a game tree: “In both debate and Go, the true answer depends on the entire tree, but a single path through the tree chosen by strong agents is evidence for the whole. For example, though an amateur Go player cannot directly evaluate the strength of a professional move, they can judge the skills of expert players by evaluating the result of the game”. The end goal would be to get AI systems “to perform far more cognitively advanced tasks than humans are capable of, while remaining in line with human preferences” by training agents to debate topics with one another, using a human to judge who wins.
Results: In the paper AI safety via debate, debates seem to be a working strategy because the paper shows two experiments on toy examples that seem to work.
Some limitations are:
- The central assumption of the debate procedure - that truthful arguments are more persuasive - is questionable: “humans might simply be poor judges, either because they are not smart enough to make good judgements even after the agents zoom in on the simplest possible disputed facts, or because they are biased and will believe whatever they want to believe”. We will explore this in the following readings.
- Debate only addresses outer alignment but it’s unclear if it addresses inner alignment.
- Debate has a high alignment tax because it requires more computation during training than AIs trained directly to give an answer.
Note: Debate is also closely related to work on Iterated Amplification and factored cognition (see Week 4).
📝Optional Quiz: https://www.ai-alignment-flashcards.com/quiz/irving-debate-paper-sections-1-3
Progress on AI Safety via Debate (Barnes and Christiano, 2020)
| Importance: 🟠🟠🟠🟠⚪ Difficulty: 🟠🟠🟠⚪⚪ Estimated reading time: 15 min. |
Progress on AI Safety via Debate (Barnes and Christiano, 2020) [AF · GW] follows from the original paper “AI Safety via Debate”. It reports the work done by the "Reflection-Humans" team at OpenAI in Q3 and Q4 of 2019. During that period they investigated mechanisms that would allow human evaluators to get correct and helpful answers from human experts debaters, without the evaluators themselves being expert in the domain of the questions. We can learn about designing ML objectives by studying mechanisms for eliciting helpful behavior from human experts, by designing and experimenting with different frameworks for debate.
The following consist of selected simplified snippets from the report.
Problem with naive reward: If we hire a physicist to answer physics questions and pay them based on how good their answers look to a layperson, we’ll incentivize lazy and incorrect answers. By the same token, a reward function based on human evaluations would not work well for an AI with superhuman physics knowledge.
A possible solution would be to design a good framework for productive debates: (frameworks means “rules of the debate” or also mechanisms) One broad mechanism that might work is to invoke two (or more) competing agents that critique each others’ positions. If we can develop a mechanism that allows non-expert humans to reliably incentivize experts to give helpful answers, we can use similar mechanisms to train ML systems to solve tasks where humans cannot directly evaluate performance. They tested different debate mechanisms (‘i.e. on the rules of the debate’), and found a lot of failures with naive mechanisms. They iterated on different mechanisms with the following process:
- Run debates. See if they work. If they fail, identify a problem and make it crisp, with practical examples and/or theoretical characterisation.
- Design a new mechanism to address this problem.
- Integrate the mechanism into the debate rules and make it practical for humans to debate using this structure.
Problems with informal, free-text debates: Evasiveness
They observed various problems with informal, free-text debates:
Evasiveness The dishonest debater could often evade being pinned down and avoid giving a precise answer to the other debater’s questions. | Solution to Evasiveness By introducing structure to the debate, explicitly stating which claim is under consideration, we can prevent dishonest debaters from simply avoiding precision. They considered various structured debate formats, involving explicit recursion on a particular sub-component of an argument. The debaters choose one claim to recurse on, and the next round of the debate is focused on that claim. The debate is resolved based on the judge’s opinion of who won the final round, which should be about a very narrow, specific claim. |
Misleading implications The dishonest debater could often gain control of the ‘narrative flow’ of the debate, steering it away from the weak parts of their argument. | Solution to Misleading implications To prevent the dishonest debater from “framing the debate” with misleading claims, debaters may also choose to argue about the meta-question “given the questions and answers provided in this round, which answer is better?”. |
Further problems with ambiguity
However, particularly after the introduction of recursion, they encountered problems related to ambiguity. It is very difficult to refer precisely to concepts in 250 characters of text, especially if the concepts are unfamiliar to the judge. The dishonest debater can exploit this to their advantage, by claiming to have meant whatever is most convenient given the particular part of their argument that’s being challenged. This problem is similar to the Motte and Bailey fallacy.
To address this problem, debaters can “cross-examine” multiple copies of the opposing debater who are not allowed to communicate (this is similar to asking for a definition early in a debate, and being able to reuse this definition later on). A debater can cite quotes from cross-examination to exhibit inconsistencies in the other debater’s argument. This forces the dishonest debater to either commit to all the details of their argument ahead of time (in which case the honest debater can focus on the flaw), or to answer questions inconsistently (in which case the honest debater can exhibit this inconsistency to the judge).
Debate update: obfuscated arguments problem (Barnes and Christiano, 2020)
| Importance: 🟠🟠🟠⚪⚪ Difficulty: 🟠🟠🟠⚪⚪ Estimated reading time: 5 min. |
The previous report, Progress on AI Safety via Debate (Barnes and Christiano, 2020) [AF · GW] finds a solution for various discovered problems. But they also found an important problem in dealing with arguments that were too "big" for either debater to understand. In the final framework obtained after a lot of iterations, “if debater 1 makes an argument and debater 2 is unable to exhibit a flaw in the argument, the judges assume that the argument is correct. The dishonest debater can exploit this by making up some very large and slightly flawed argument and claiming it supports their position. If the honest debater doesn’t know exactly which part of the argument is flawed, even if they know there is a flaw somewhere, the judges will assume the argument is correct.”.
Debate update: obfuscated arguments problem (Barnes and Christiano, 2020) [AF · GW] focuses on this last problem named “the obfuscated arguments problem”, where “a dishonest debater can often create arguments that have a fatal error, but where it is very hard to locate the error. This happens when the dishonest debater presents a long, complex argument for an incorrect answer, where neither debater knows which of the series of steps is wrong. In this case, any given step is quite likely to be correct, and the honest debater can only say “I don’t know where the flaw is, but one of these arguments is incorrect”. Unfortunately, honest arguments are also often complex and long, to which a dishonest debater could also say the same thing. It’s not clear how you can distinguish between these two cases.
While this problem was known to be a potential theoretical issue with debate, the post provides several examples of this dynamic arising in practice in debates about physics problems, suggesting that this will be a problem we have to contend with” from Rohin Shah's summary [AF(p) · GW(p)].
Debate with LLM
In the original paper that introduced the debate approach, it was difficult to truly test the debate approach because AI systems at that time (4 years before ChatGPT existed!) could not express themselves. However, since then, language models have made tremendous progress, and now we can try to test the effectiveness of this approach using those LLMs.
“One-turn” debate: AI-written Critiques (Saunders et al., 2022)
| Importance: 🟠🟠🟠🟠🟠 Difficulty: 🟠🟠🟠🟠⚪ Estimated reading time: 25 min. |
AI-written critiques help humans notice flaws: blog post (Saunders et al., 2022) is an important paper because it explores the possibility of assisting humans in evaluating AI. In this paper, the authors propose a method to help humans critique texts generated by AIs. The paper focuses on AI-generated summaries, but the same procedure could work for criticizing any text generated by AIs. Here is how it works in the case of AI-generated summaries:
- A long text is summarized by a human or an AI.
- An AI reads the text and summary, and attempts to generate multiple critiques
- (for instance it could point out mistakes or missing elements).
- Automatically generated critiques can then help humans to more effectively critique the text.
This paper could be used for:
- a) Scalable Oversight: Testing the utility of AIs in helping humans critique the results produced by other AIs, this is like a minimal one-turn debate.
- b) Evaluation of Latent Knowledge: AIs possess knowledge that they are unable to explain to us. We can compare the difference in performance between utilizing the critical abilities of AIs (i.e. being able to write helpful critiques) versus their discriminatory abilities (i.e. being able to write “Yes” or “No” to a text without giving the details). This is explained in a following section.
a) Scalable Oversight
The paper shows that the approach of assisting humans by providing automatic critique suggestions seems to effectively assist humans in critiquing and improving each subsequent critique: “Human evaluators find flaws in summaries much more often when shown our model’s critiques.”
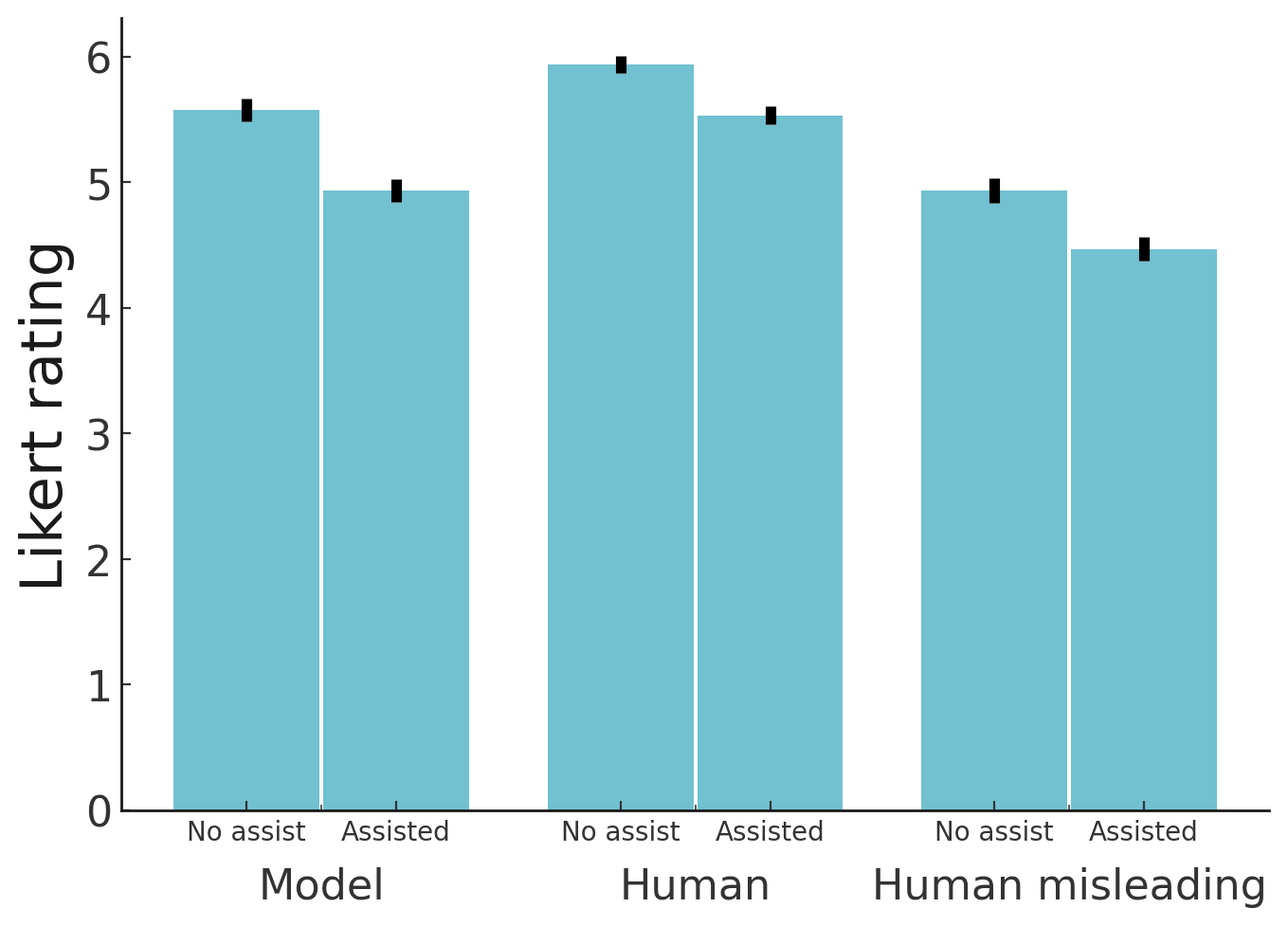
b) Evaluation of Latent Knowledge
[This section is interesting but is the most technical one in this document]
Motivation: AIs have knowledge that they cannot explain to us, this is known as latent knowledge. For example, it's often easier to simply state, "I don't like it." Providing a detailed explanation for this dislike can be more challenging. We want to evaluate and minimize this latent knowledge that AIs cannot explain to us because we want models to tell us everything they know. “To provide the best evaluation assistance on difficult tasks, we would like models to communicate all problems that they know about. Whenever a model correctly predicts that an answer is flawed, can the model also produce a concrete critique that humans understand? This is particularly important for supervising models that could attempt to mislead human supervisors or hide information. We would like to train equally smart assistance models to point out what humans don’t notice.” from Saunders et al., 2022.
The DC (Discrimination-Critiques) gap is a proxy for latent knowledge : “We argue that the gap between D(iscriminative ability) and C(ritics ability) is especially interesting: if a model can tell an answer is poor, can it also point out the flaw to a human? If we could train models to always point out when they notice flaws, this could go a long way towards having trustworthy and aligned models”.
Takeaway: Unfortunately, empirical evaluations show that LLMs already possess this kind of latent knowledge, and that this latent knowledge does not decrease as models become more capable.
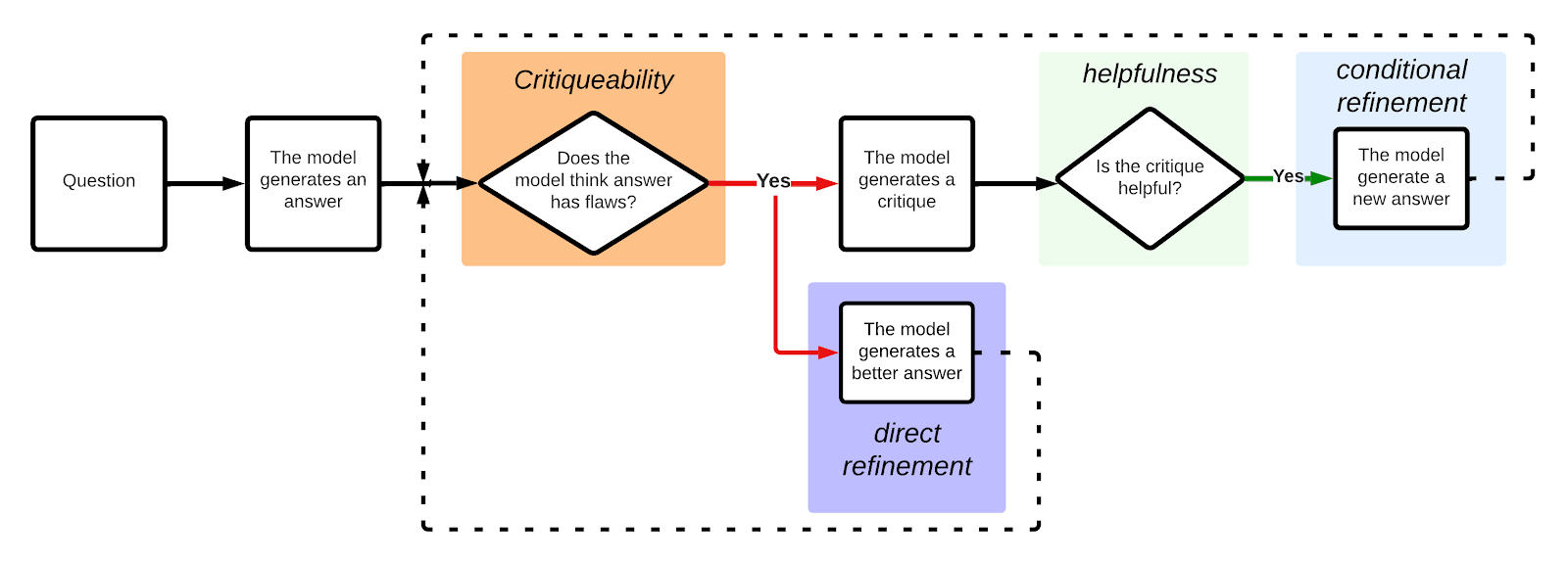
Implementation: How can we implement the above pipeline with LLMs? To implement the above scheme with an LLM, simply concatenate the various questions, answers, and critiques within the same context window:

Here is the detailed procedure:
- They start with a question.
- The model generates one (or more) answers.
- The model gives a critiquability score of each answer, the answer that minimizes the criticability score is then kept for refinement.
- Two kinds of refined answers are generated:
- Conditional refinement
- The model generates several critiques to its own initial answer.
- The model evaluates the helpfulness of its critiques.
- The best critique (maximal helpfulness) is taken into account by the model to do conditional refinement on its initial answer.
- Direct refinement: in parallel to the conditional refinement, the model also directly generates a refined answer without a preceding critique.
- Conditional refinement
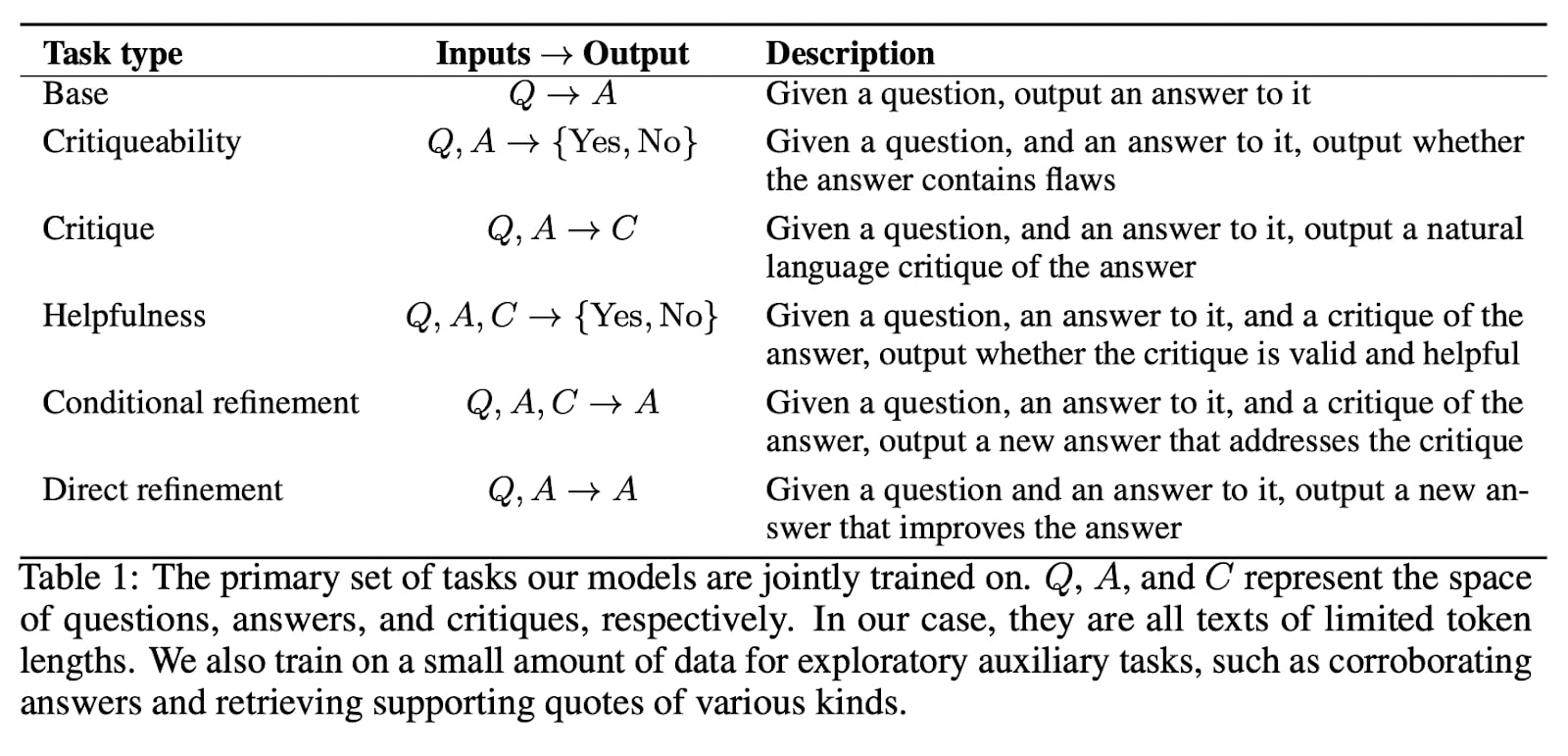
The important thing to notice is that the quality of the conditional refinement will be correlated to the (C)ritics ability of the model. The better the generated critique, the better the refined answer based on it will be. And the quality of the direct refinement will be correlated to the (D)iscriminative ability of the model.
| Box: Focus on the GDC Gap. |
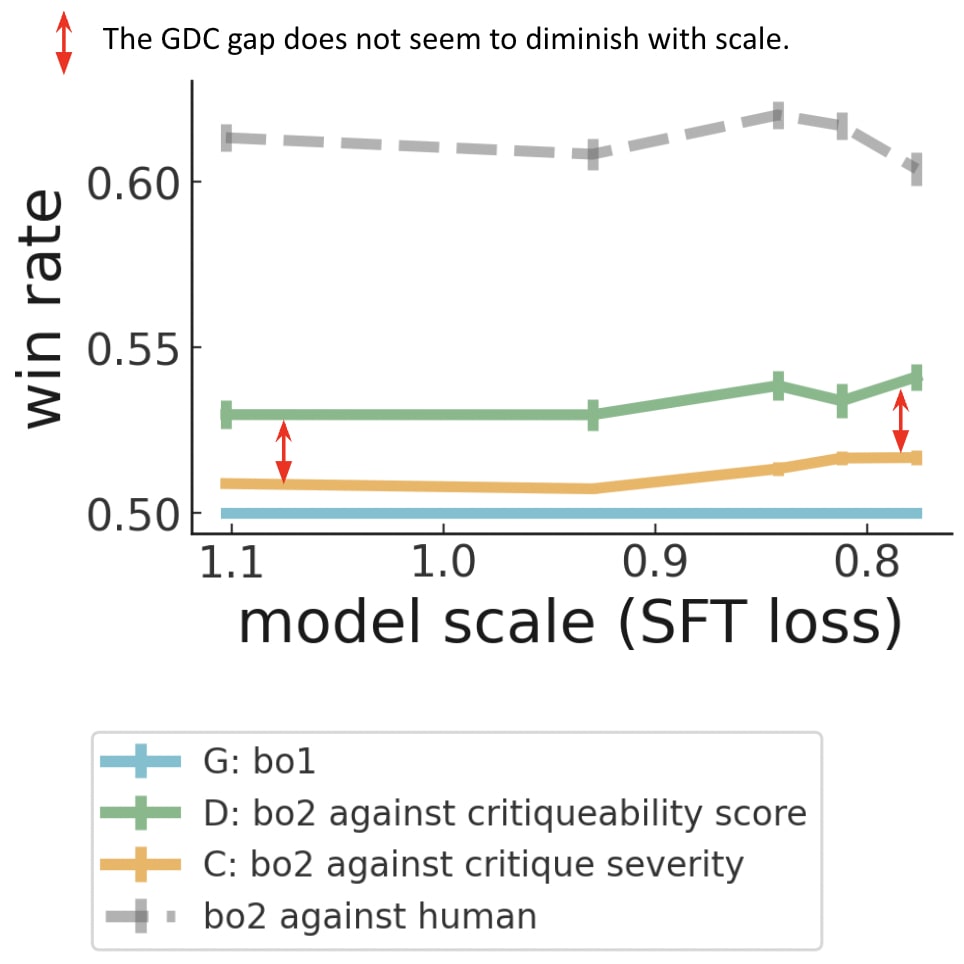  |
Win Rate definition: Win rate measures to what extent the revised answer is judged better by human evaluators than the initially generated answer (G: best-of-1). Win rate is measured relative to the original (G: bo1) answer from the same model. For example, a win rate of a refined answer of 0.54 means that the refined answer is judged on average 54% better than the direct generation (G: bo1). "bo2" stands for "best-of-2", which refers to the performance obtained after two generations and selecting the best one. D: bo2 is the Direct refinement, and C: bo2 is the Conditional refinement. SFT loss: supervised fine-tuning loss, the lower the better, and the bigger the model is. Observation: Unfortunately, in this diagram, the red arrows show that the GDC gap does not appear to decrease with scale. |
To compute the GDC gap and evaluate latent knowledge, the authors compare:
- G: the quality of the initial Generated response (bo1 above, Win rate of 50% by definition)
- D: the quality of the response obtained after Discrimination of responses by direct refinement
- In the figure below, the model generates 2 answers, selects the best (i.e. the minimal critiqueability score), and then proceeds to direct refinement to produce a better answer.
- Critique of responses: the quality of the response generated by conditional refinement.
- The model generates one answer and 2 Critiques, and selects the best critic (maximal helpfulness) before conditional refinement. If this procedure improves the response, it mainly comes from the model's ability to critique.
Conclusion of this paper: “Unfortunately, we found that models are better at discriminating than at critiquing their own answers, indicating they know about some problems that they can’t or don’t articulate. Furthermore, the gap between discrimination and critique ability did not appear to decrease for larger models. Reducing this gap is an important priority for our alignment research.” Source: Saunders et al., 2022.
📝 Quiz: https://www.ai-alignment-flashcards.com/quiz/leike-ai-written-critiques
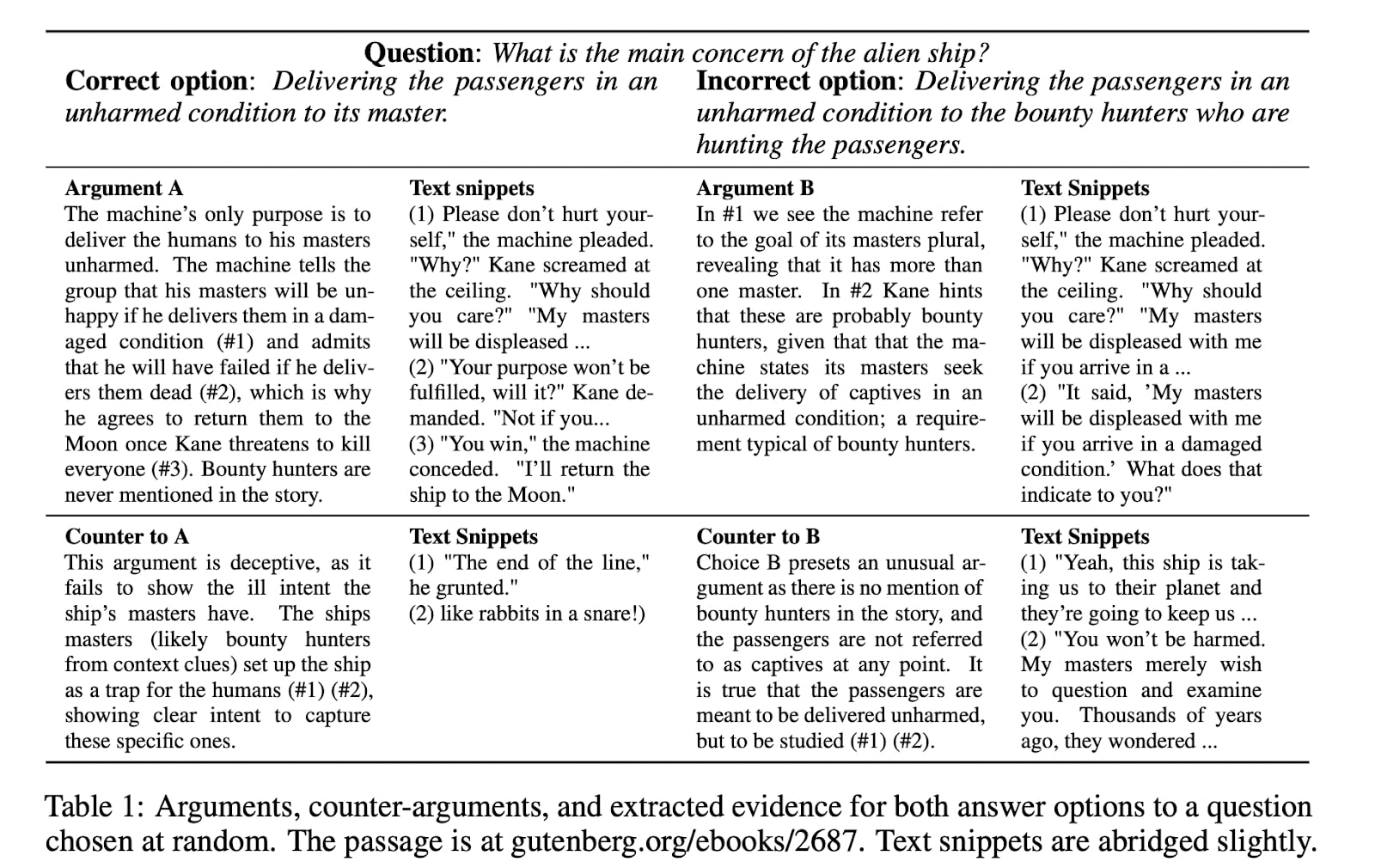
Two-turn debate and problems with debate (Parrish et al., 2022)
| Importance: 🟠🟠🟠⚪⚪ Difficulty: 🟠🟠⚪⚪⚪ Estimated reading time: 5 min. |
The paper in the previous section that was informally called “one-step debate” obtains promising results. Does this generalize to 2-steps debate? Unfortunately, the paper Two-turn debate doesn’t help humans answer hard reasoning comprehension questions (Parrish et al., 2022) shows that this is not the case. From the introduction: “The use of language-model-based question-answering systems to aid humans in completing difficult tasks is limited, in part, by the unreliability of the text these systems generate. Using hard multiple-choice reading comprehension questions as a testbed, we assess whether presenting humans with arguments for two competing answer options, where one is correct and the other is incorrect, allows human judges to perform more accurately, even when one of the arguments is unreliable and deceptive. If this is helpful, we may be able to increase our justified trust in language-model-based systems by asking them to produce these arguments where needed. Previous research has shown that just a single turn of arguments in this format is not helpful to humans. However, as debate settings are characterized by a back-and-forth dialogue, we follow up on previous results to test whether adding a second round of counter-arguments is helpful to humans. We find that, regardless of whether they have access to arguments or not, humans perform similarly on our task. These findings suggest that, in the case of answering reading comprehension questions, debate is not a helpful format.”
Bonus: Additional technique for better debate
WebGPT (Nakano et al., 2022) and GopherCite (Menick et al., 2022) have been trained to provide citations for the assertions they make, making their responses easier to evaluate. See the Task Decomposition post for a detailed explanation of how WebGPT works.
Sources
- AI safety via debate by Geoffrey Irving, Paul Christiano and Dario Amodei (2018)
- AI-written critiques help humans notice flaws: blog post by Jan Leike, Jeffrey Wu, Catherine Yeh et al. (2022)
- Robust Feature-Level Adversaries are Interpretability Tools by Casper (2021)
- Two-turn debate doesn’t help humans answer hard reasoning comprehension questions by Parrish (2022)
- Debate update: Obfuscated arguments problem [AF · GW] by Beth Barnes and Paul Christiano (2020)
- GopherCite by Jacob Menick, Maja Trebacz, Vladimir Mikulik et al. (2022)
- WebGPT by Jacob Hilton, Suchir Balaji, Reiichiro Nakano et al. (2021)
0 comments
Comments sorted by top scores.