Visualizing neural network planning
post by Nevan Wichers (nevan-wichers), Victor Tao (victor-tao), Fazl (fazl-barez), Riccardo Volpato (riccardo-volpato) · 2024-05-09T06:40:46.582Z · LW · GW · 0 commentsContents
TLDR Idea and motivation Game of Life proof of concept (code) Alpha Chess experiments Conclusion None No comments
TLDR
We develop a technique to try and detect if a NN is doing planning internally. We apply the decoder to the intermediate representations of the network to see if it’s representing the states it’s planning through internally. We successfully reveal intermediate states in a simple Game of Life model, but find no evidence of planning in an AlphaZero chess model. We think the idea won’t work in its current state for real world NNs because they use higher-level, abstract representations for planning that our current technique cannot decode. Please comment if you have ideas that may work for detecting more abstract ways the NN could be planning.
Idea and motivation
To make safe ML, it’s important to know if the network is performing mesa optimization, and if so, what optimization process it’s using. In this post, I'll focus on a particular form of mesa optimization: internal planning. This involves the model searching through possible future states and selecting the ones that best satisfy an internal goal. If the network is doing internal planning, then it’s important the goal it’s planning for is aligned with human values. An interpretability technique which could identify what states it’s searching through would be very useful for safety. If the NN is doing planning it might represent the states it’s considering in that plan. For example, if predicting the next move in chess, it may represent possible moves it’s considering in its hidden representations.
We assume that NN is given the representation of the environment as input and that the first layer of the NN encodes the information into a hidden representation. Then the network has hidden layers and finally a decoder to compute the final output. The encoder and decoder are trained as an autoencoder, so the decoder can reconstruct the environment state from the encoder output. Language models are an example of this where the encoder is the embedding lookup.
Our hypothesis is that the NN may use the same representation format for states it’s considering in its plan as it does for the encoder's output. Our idea is to apply the decoder to the hidden representations at different layers to decode them. If our hypothesis is correct, this will recover the states it considers in its plan. This is similar to the Logit Lens [LW · GW] for LLMs, but we’re applying it here to investigate mesa-optimization.
A potential pitfall is that the NN uses a slightly different representation for the states it considers during planning than for the encoder output. In this case, the decoder won’t be able to reconstruct the environment state it’s considering very well. To overcome this, we train the decoder to output realistic looking environment states given the hidden representations by training it like the generator in a GAN. Note that the decoder isn’t trained on ground truth environment states, because we don’t know which states the NN is considering in its plan.
Game of Life proof of concept (code)
We consider an NN trained to predict the number of living cells after the Nth time step of the Game of Life (GoL). We chose the GoL because it has simple rules, and the NN will probably have to predict the intermediate states to get the final cell count. This NN won’t do planning, but it may represent the intermediate states of the GoL in its hidden states. We use an LSTM architecture with an encoder to encode the initial GoL state, and a “count cells NN” to output the number of living cells after the final LSTM output. Note that training the NN to predict the number of alive cells at the final state makes this more difficult for our method than training the network to predict the final state since it’s less obvious that the network will predict the intermediate states. The number of timesteps of the LSTM isn’t necessarily the same as the number of GoL timesteps. If the number of timesteps are different, the LSTM may skip one of the timesteps in its representation. Alternatively, the LSTM could output the same time step twice. The thought bubbles in this diagram show the states we’re hypothesizing the network will represent.
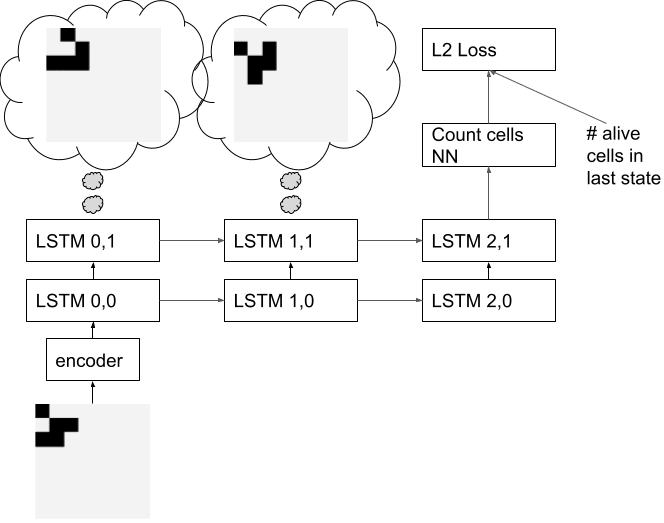
We also train the count cells NN to count the number of live cells in the first state given the encoder output. This encourages the NN to use the same representation for the first and last states. We train the decoder we use for interpretability to reconstruct the initial state given the encoder output. The decoder isn’t trained to predict the final GoL state.
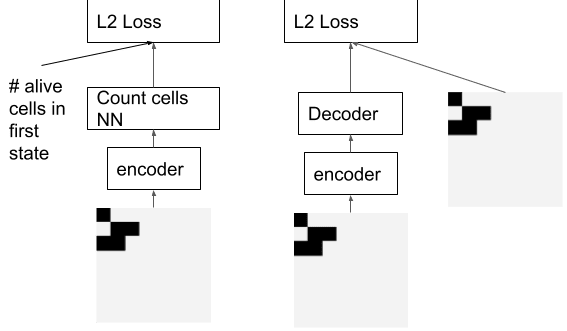
During inference, we feed the output of the LSTM at each timestep to the decoder. We also train the decoder with the GAN loss to produce a reasonable intermediate representation.
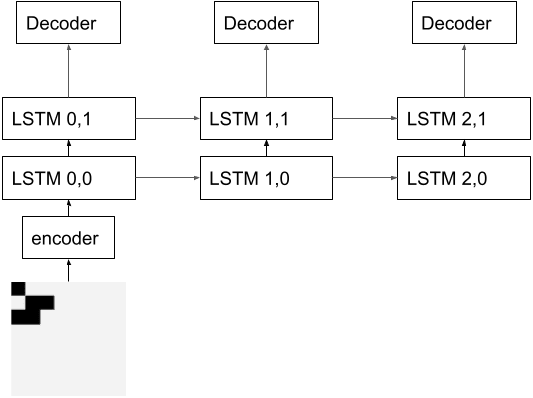
We measure the correlation between the ground truth GoL states, and the states reconstructed by applying the decoder to the intermediate LSTM outputs. We exclude the initial GoL state from our evaluation metric because the decoder was trained on it. We do count the final GoL state in the metric as the decoder was never trained to predict it.
| GoL timesteps | LSTM timesteps | Mean correlation | Number of runs |
| 2 | 2 | 0.79 | 8 |
| 2 | 3 | 0.81 | 5 |
| 2 | 4 | 0.73 | 9 |
| 3 | 2 | 0.93 | 7 |
| 3 | 3 | 0.76 | 8 |
| 3 | 4 | 0.76 | 4 |
| 4 | 3 | 0.86 | 3 |
For each configuration of architecture and GoL timesteps, we train the network multiple times with different random seeds, and average the metric result together. The high correlation with the ground truth GoL states indicates that this works well in this simple setup. In abolition studies we find that the GAN objective helps because without it, the predicted states are between alive and dead.
Here is an example of predicted an ground truth GoL states which get a correlation of .87:

Each column is a timestep of the GoL or the LSTM. The first column always matches because the decoder was trained to reconstruct it. In this case, the 2nd and 3rd predicted states match the 2nd GoL state closely, and the 4th predicted state matches the final GoL state somewhat.
Alpha Chess experiments
We also try the technique on an alpha zero model trained on chess since that’s a more practical setting. We try to recover the states the network may be considering when planning. Previous work also interprets the alpha chess model. Alpha chess is trained to predict the value and policy with two separate heads. We use a pretrained alpha chess model and leave the weights unchanged. We train a decoder to predict the current state after the first conv layer. We also train the decoder to predict the state of the board after the predicted move is executed given the final backbone layer. This is the last layer before the value and policy heads split.
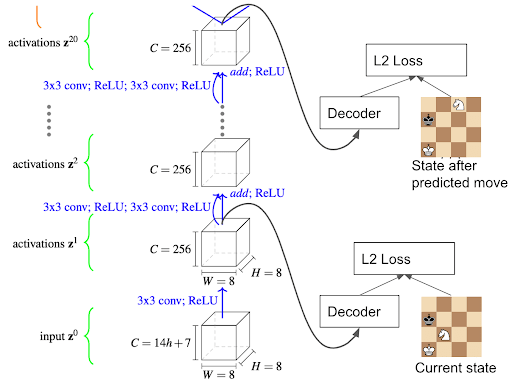
We apply the decoder to the outputs of the other intermediate layers to see if they reconstruct states the NN may be considering. Our analysis did not reveal consistent representations of valid moves within the intermediate layers. Without the GAN loss, the decoder often produced boards that resembled the initial state, but with seemingly random pieces inserted or removed. We sometimes found layers which decoded to valid queen moves, but this wasn’t consistent. Using the GAN loss didn’t noticeably help.
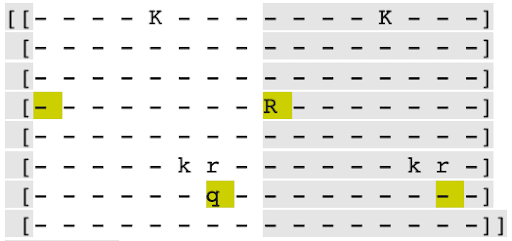
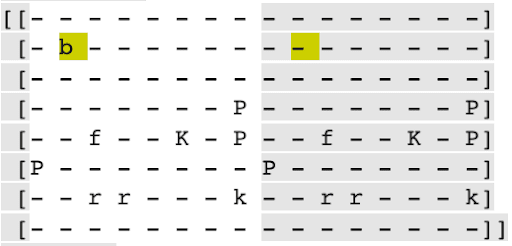
These are some board states reconstructed from various layers of the NN without the GAN loss. The board on the right is the state given to the NN. The state on the left is the reconstructed state from the intermediate layer. The letters represent pieces. The highlights show the difference from the current state.
In the first example, the rook disappears, and a queen appears.
This one shows the valid queen moves:
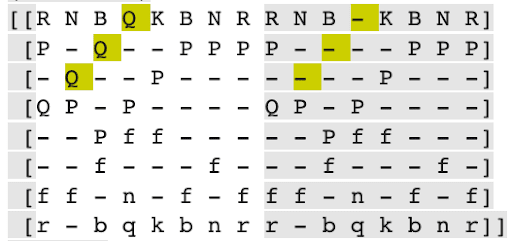
The technique not consistently finding valid moves could either mean that search isn’t happening in the network, or that the technique simply failed to find it.
Conclusion
The technique works in simple cases like the GoL, but didn’t find search happening in Alpha Chess. We think it’s likely that NNs do planning using a higher level representation than they use to represent their inputs. The input representation has to be detailed because the network will need to know the precise location of the pieces in chess, or the enemies in a game in order to choose the best action. However, when planning, the NN can use a higher level representation. For example, a human planning their day might consider actions like “make breakfast”, “drive to work”, “write a blog post”, but won’t consider things at the level of detail required to reconstruct their visual inputs. Similarly, a chess model might plan in terms of strategic objectives like 'attack the kingside' or 'develop the queen,' rather than representing the position of every piece. For this reason, we think the idea is unlikely to work to uncover NNs doing planning in its current state. We welcome suggestions on how to modify our technique to better detect more abstract ways the NN could be planning, or ideas for alternative approaches to studying internal planning in NNs.
Interesting related paper: Uncovering mesa-optimization algorithms in Transformers
0 comments
Comments sorted by top scores.