Posts
Comments
Apparently it is keeping around a representation of the token "plasma" with enough resolution to copy it . . . but it only retrieves this representation at the end! (In the rank view, the rank of plasma is quite low until the very end.)
This is surprising to me. The repetition is directly visible in the input: "when people say" is copied verbatim. If you just applied the rule "if input seems to be repeating, keep repeating it," you'd be good. Instead, the model scrambles away the pattern, then recovers it later through some other computational route.
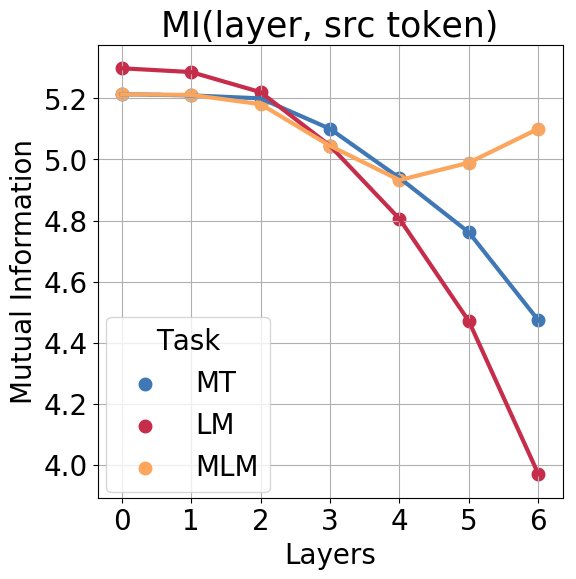
One more reason on why this is suprising, is that other experiments found that this behaviour (forgetting then recalling) is common in MLM (masked language models) but not in simple language models like GPT-2 (see this blog post and more specifically this graph). The intepretation is that "for MLMs, representations initially acquire information about the context around the token, partially forgetting the token identity and producing a more generalized token representation; the token identity then gets recreated at the top layer" (citing from the blog post).
{kind=link}
However, the logit lense here seems indicating that this may happen in GPT-2 (large) too. Could this be a virtue of scale? Where the same behaviour that one obtains with a MLM is reached by a LM as well with sufficient scale?
I've spent more of my time thinking about the technical sub-areas, so I'm focused on situations where innovations there can be useful. I don't mean to say that this is the only place where I think progress is useful.
That seems more than reasonable to me, given the current state of AI development.
Thanks for sharing your reflections on my comment.
While I agree with you that setting the context as Safety narrows down the requirements space for interpretability, I think there could be more than just excluding the interpretability of non-technical users from the picture. The inspections that technicians would want to be reassured about the model safety are probably around its motivations (e.g is the system goal directed, is the system producing mesa-optimisers). However, it is still unclear to me how this relate with other interpretability desiderata you present in the post.
Plus, one could also immagine safety-relevant scenarios were it may be necessary or useful for non-technical users to be able to interpret the model. For instance, if the model has been deployed and is adaptive and we somehow cannot do this automatically, we would probably want users to be able to inspect if the system is somehow made a decision for the wrong reason.
Thanks for the in-depth post on topic. Your last paragraph on Utility is thought-provoking to say the least. I have seen a lot of work claiming to make models interpretable - and factually doing so as well - about which I felt an itch I could not fully verbalise. I think your point on Utility puts the finger on it: most of these works were technically interpreting the model but not actually useful to the user.
From this, we can also partially explain the current difficulties around "find better ways to formalize what we mean by interpretability". If acceptable interpretability depend on its usefulness, then it becomes context-dependent, which blows up the complexity of the attempt.
Hence Interpretability seems to be an interdisciplinary problem. One that requires having the rigth culture and principles to adopt the right interpretability tools for the right problem. This seems to be confirmed by the many contributions you shared from the social sciences on the topic.
What do you think of this perspective?
I think we raise children to satisfy our common expected wellbeing (our + theirs + the overall societal one). Thus, the goal-directness comes from society as a whole. I think there is a key difference between this system and one where a a smarter-than-human AI focuses solely on the well-being of its users, even if it does Context Etrapolated Volition, which I think is what you are referring to when you talk about expected well being (which I agree that if you look only at their CEV-like property the two systems are equivalent).
The problem with this line of reasoning is that it assumes that the goal-directness comes from the smarter part of the duo decision-maker and bearer of consequences. With children and animals we consider they preferences as an input into our decision making, which mainly seeks to satisfies our preferences. We do not raise children solely for the purpose of satisfying their preferences.
This is why Rohin stresses particuarly on the idea that the danger in is the source of goal-directedness and if it comes from humans, then we are safer.
Helpful post - thanks for writing it. From a phenomenological perspective, how can we reason well about the truth of this kind of "principles" (i.e. dual-model where S2 is better than S1 being less effective at dealing with motivational conflicts than than the perspective-shift you suggest) that are to some extent non-falisfiable?
This seems true to me (that it happens all the time). I think the article helps by showing that we often fail to recognise that A) and B) can both be true. Also, if we accept that A) and B) are both true and don't create an identify conflict about it, we can probably be more effective in striking a compromise (i.e. giving up either or finding some other way to get A that does not involve B).
My rough mental summary of these intuitions
- Generalisation abilities suggests that behaviour is goal directed beucase it demonstrates adaptability (and goals are more adatable/compact ways of defining behaviour than others, like enumeration)
- Powergrabs suggest that behaviour is goal directed beucase it reveals instrumentalism
- Our understanding of intelligence migth be limited to human intelligence which is sometime goal directed so we use this a proxy of intelligence (adding some, perhaps unrefutable, skepticism of goal directness as a model of intelligence)
we currently don't have a formal specification of optimization
This seems to me a singificant bottleneck for progress. No formal specification of what optimisation is has been tried before? What has been achieved? Is anyone working on this?
-
Could internalization and modelling of the base objective happen simultanously? In some sense, since Darwin discovered evolution, isn't that the state in which humans are? I guess that this is equivalent to saying that even if the mesa-optimiser has a model of the base-optimiser (condition 2 met) it cannot expect the threat of modification to eventually go away (condition 3 not met) since it is still under selection pressure and is experiencing internalization of the base objective. So if humans will ever be able to defeat mortality (can expect the threat of modification to eventually go away) will they stop having any incentive to self-improve?
once a mesa-optimizer learns about the base objective, the selection pressure acting on its objective will significantly decrease
This seems to be context-dependent to me, as for my example with humans: did learning about evoluation reduced our selection pressure?
- How would the reflections on training vs testing apply to something like online learning? Could we simply solve deceptive alignment by never (fully) ending training?
If we model reachability of an objective as simply its length in bits, then distinguishing O-base from every single more reachable O-mesa gets exponentially harder as O-base gets more complex. Thus, for a very complicated O-base, sufficiently incentivizing the base optimizer to find a mesa-optimizer with that O-base is likely to be very difficult, though not impossible
What is the intuition that makes you think that despite being expoentially harder this would not be impossible?
you can anneal whatever combination of the different losses you are using to eventually become exclusively imitative amplification, exclusively debate, or anything else in between
How necessary is annealing for this? Could you choose other optimisation procedures? Or do you refer to annealing in a more general sense?
I will keep track of all questions during our discussion and if there is anything that make sense to send over to you, I will or invite the attendees to do so.
I feel like we as a community still haven't really explored the full space of possible prosaic AI alignment approaches
I agree and I have mixed feelings about the current trend of converging towards somehow equivalent approaches all containing a flavour of recursive supervision (at least 8 of your 11). On one hand, the fact that many attempts point to a similar direction is a good indication of the potential of such a direction. On the other hand, its likelihood of succeeding may be lower than a portoflio approach, which seemed like what the community was originally aiming for. However, I (and I supect most of junior researchers too) don't have a strong intuition on what very different directions migth be promising. Perhaps one possibility would be to not completely abandon modelling humans. While it is undoubtly hard, it may be worth exploring this possiblity from a ML perspective as well, since others are still working on it from a theoretical perspective. It may be that granted some breaktroughts in Neuroscience, it could be less hard that what we anticipate.
Another open problem is improving our understanding of transparency and interpretability
Also agree. I find it a bit vague, in fact, whenever you refer to "transparency tools" in the post. However, if we aim for some kind of guarantees, this problem may either involve modelling humans or loop back to the main alignment problem. In the sense that specifying the success of a transparency tool, is itself prone to specification error and outer/inner alignment problems. Not sure my point here is clear, but is something I am interested on pondering aboud.
Thanks for all the post pointers. I will have an in-depth read.
Thanks for the great post. It really provides an awesome overview of the current progress. I will surely come back to this post often and follow pointers as I think about and research things.
Just before I came across this, I was thinking of hosting a discussion about "Current Progres in ML-based AI Safety Proposals" at the next AI Safety Discussion Day (Sunday June 7th).
Having read this, I think that the best thing to do is to host an open-ended discussion about this post. It would be awesome if you can and want to join. More details can be found here
One additional thing that I was thinking of discussing (and that could be a minor way to go beyond this post) are the various open problems across the different solutions and what might be more impactful to contribute/focus on. Do you have any thoughts on this?
Many thanks again for the precious resource you put together.
Interesting points. The distinctions you mention could equally apply in distinguishing narrow from ambitious value learning. In fact, I think preference learning is pretty much the same as narrow value learning. Thus, could it be that ambitious value learning research may not be very interested in preference learning to a similar extent in which they are not interested in narrow value learning?
"How important safety concerns" is certainly right, but the story of science teaches us that taking something from a domain with different concerns to another domain has often proven extremely useful.