Agency engineering: is AI-alignment "to human intent" enough?
post by catubc (cat-1) · 2022-09-02T18:14:52.408Z · LW · GW · 10 commentsContents
10 comments
TL;DR: We have not solved the "free will" problem: i.e. we do not know to what extent consciousness, culture, biology or a myriad of other factors shape human will and intent. Yet, prediction of future behavior of self and other agent-caused actions (i.e. what the self/others intend) is the main driving force in the evolution of brains; AI technologies will parallel evolution by being increasingly aimed at human behavior prediction - because the most powerful tools humans can create are for prediction of human behavior rather than prediction of biological or physical processes. As such, humans will become targets for "agency engineering" from powerful behavior predicting technologies which can interact with our culture, political and social structures to engineer human will from the ground up; in these scenarios it's not just AI-misuse and AI-misaligned agents but also AI-aligned agents that could weaken or harm us. Our limited progress and understanding w.r.t. to the science of agency makes us vulnerable to this type of harm. We need solutions soon, with one option being hard-coding rights and freedoms before we might be irreversibly stripped of power.
Background: At the core of my research interest lies a simple question: If another agent (i.e. person, algorithm etc) can predict what you are going to do next (second, hour, week, year), do you still have agency? This question was one that St Thomas Aquinas asked nearly 800 years ago (in Quaestiones disputatae de veritate), namely, whether free will or freedom can exist in the presence of an all-knowing agent - in his case, the Christian god. His answer was essentially yes - but mostly because his agent was not interested in interfering with human action. In an age of behavior-predicting AIs, there may be many such powerful agents. And some will be interested in interfering with human actions. The simplest question we can pose then is how do we: "preserve human free will around powerful systems?" (thanks to Charlie Steiner for suggesting this simple summary).
The problem framing - intention is vulnerable to manipulation: By humans (not) understanding "free will" I mean not understanding to what extent each of the forces in our lives affect or cause our free actions? Historically, the philosophers reduced the entire topic to "consciousness", i.e. that our consciousness is the most important factor in deciding our actions and that it acts largely "independently" of other forces to determine action, especially on very important topics[1]. However, over the past few centuries sociology, psychology and a few other fields have uncovered many other factors that are causal in free action, including: cultural forces, societal norms and goals and political and social classes and structures.
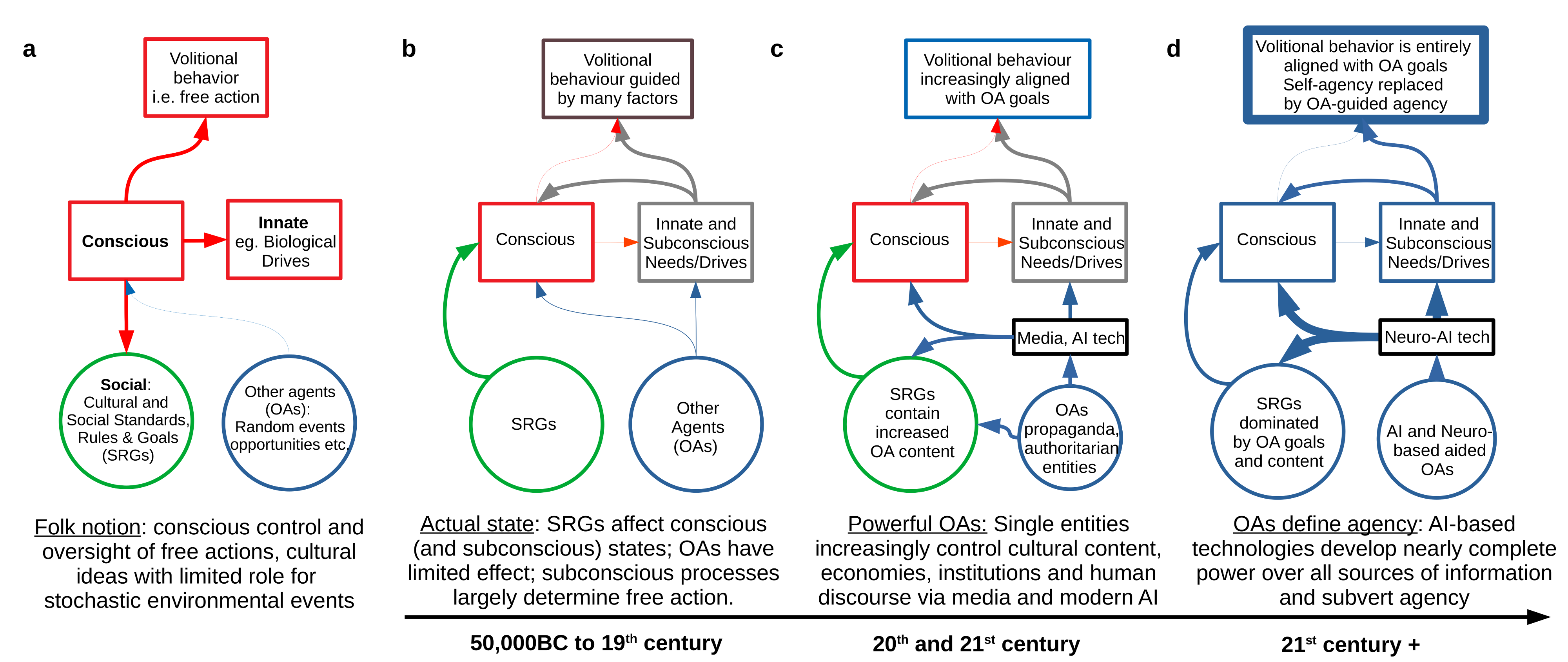
The diagram below contains an attempt at summarizing all of humanities and science on the topic of human volitional (aka voluntary, self-controlled, free willed, etc) behavior. Briefly, here's what each panel argues:
(a) the folk notion which many of us have is that our conscious will controls, or vets most of our important volitional actions (e.g. how much toothpaste to squirt onto my toothbrush, who to kill next etc.).
(b) when zooming out from folk intuitions, sociology, psychology, (neuro)biology and a bunch of other fields suggest volitional action is generated from many interacting factors. These factors include external ones including "other agents" (OAs) in the world as well as standards, rules and goals of our cultures ("SRG"s).
(c) current(-ish) technologies and media are playing an increasing role in shaping our flow of information and our choices; there is risk of abuse (e.g. "AI-misuse") if unchecked OAs exert too much harmful influence.
(d) the "boiling frog" condition where human beings "feel" in control of their actions, but many (or all) of their goals are engineered or selected to support some OA's goals - with the selection of how to achieve pre-selected goals being rendered meaningless; such OAs control much of the flow of information (insert favorite analogy about rich, political classes etc here).
(e*) (*not on the chart because anything can happen after we strip human beings of de facto agency).
The specific problem of aligning to "human intent": I hope the above is not too off-putting. Some parts are probably wrong, but the overall point is hopefully not as wrong: as individual humans we (i.e. our conscious and reasoning skills) are at best[2] only good at deciding how to achieve our goals, desires or needs, and our language, culture, status etc. exhibit much influence over which desires and actions to pursue. There is a very large amount of literature on this. For example, the study of "attachment to group identity" is a field on its own. And after many studies it's been shown that it is so powerful, that it can overwrite our core identities and opinions: i.e. if you tell a progressive person that their group cast a political vote for a conservative policy - they will likely also vote for the conservative policy despite it being contrary to their core belief systems (and vice versa)[3]. The - hopefully not lost - point is that we (i.e. our consciousness, reasons etc.) are not as much in charge of our free actions as we think.
If it's not obvious, AI-misuses and AI-misaligned agents will harm human agency. It is already happening. And it will get worse (for a dystopia unfolding now, in real time, see [4]). The only technical question remaining is whether designing AI-aligned agents that follow human intent is enough to avoid harm to human agency. The diagram below argues this is not possible: human intent is itself dynamic and could be a target for change (or "manipulation"). Here's the description:
(a) Currently attempts at developing AI/AGIs that understand and carry out human intent and goals (blue path); and attempts at preventing entities (corps, governments etc) from intentionally developing harmful AIs (red path; diagram adapted from P Christiano talk).
(b) The bypassing path to changing intent: both AI-aligned and AI-"safe-use" technologies can be "aligned to intent" while intentionally or unintentionally changing human intent via the broader environment through forces acting directly on intent (the loopy arrows).
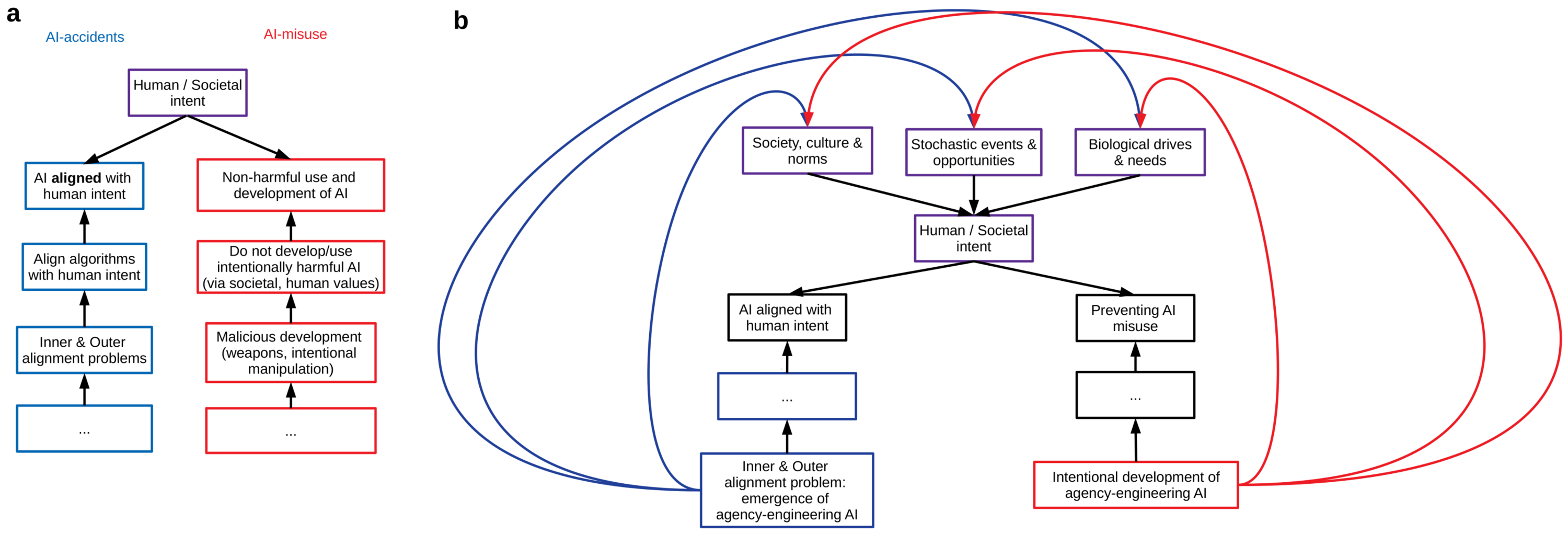
If we think of human intent or goals as "what do we, humans, want now!", then in designing human-intent aligned AIs we may have a circular argument problem. In particular, our AI technologies will interact with our societies and cultures and necessarily change what we want or desire as a feature - not as a failure mode. A rambling example: if we task an AGI with solving "cancer" or "social inequality", then maybe along the way it will act to change our thresholds for acceptable solutions. And solutions offered might be those that lie near some edge of moral dilemmas: we need to stop certain people from reproducing (or killing them or creating putting them into ignorable subclasses); or carrying out certain types of questionable experiments; or that we need to be monitored extremely precisely to reduce the risks of cancers; or become (perhaps too quickly) merged with our technologies; or that we need to automate our lives; or that powerful religious beliefs or systems of thought are a better way to live our lives; or that we should design better psychedelic/escapist substances. I'm not great at science fiction, but there are many ways in which things can go wrong.
For clarity, I am claiming 3 things (thanks to a recent meeting with an AI-safety researcher for helping me clarify this):
- that AI-misuse can lead to intent/agency manipulation; this is already happening (the red loopy lines); will get exponentially worse with biometric+neural datasets; this is likely enough to harm humanity significantly; but, 1. is probably not that controversial (and technical AI-alignment researchers don't seem as interested in this class of problems).
- that AI-misaligned agents can target agency as well (e.g. culture, social movements etc; the blue loopy lines coming from a putatively misaligned-AI); again, this is not that radical (and others have written about more eloquently); this type of safety issue is somewhat related to wireheading; and 2. is probably more controversial than 1, but still acceptable.
- that AI-aligned agents to "human intent" will also venture into agency and intention hacking as a feature - not as a failure mode (the blue loopy lines coming from an AI-aligned to human intent); 3. is probably the most controversial.
Point 3. may look a bit like a trivial problem. One response could be that "truly aligned-AI" would not seek to change human intent. But it's not clear how this addresses the core problem: human intent is created from (and dependent on) societal structures. Because we lack an understanding of the genesis of human actions/intentions or goals - we cannot properly specify how human intent is constructed - and how to protect it from interference/manipulation. A world imbued with AI-techs will change the societal landscape significantly and potentially for the worse. The folk notion is that human "intention" is a faculty that humans have which acts on the world and is somehow isolated or protected from the physical and cultural world (see Fig 1a). This model is too simplistic because humans are embedded agents. MIRI has a great blog about "dualistic" vs. "embedded" agents[5] - and their example is orders of magnitude simpler than the real human world.
A more specific problem to AI-alignment: how would humans evaluate this situation? For example, given an aligned-AI solution is it acceptable because (a) it's a good solution or (b) because our moral values were changed by the aligned-AI in the process of seeking a solution? This type of harm is perhaps easier to visualize as AI-misuse: if an entity decided to dump massive amounts of information, power, money etc, driven by AI technologies to encourage the public adoption of some policy X, how would we stop them? And more importantly, in a future where media and all our information streams are guided solely by AI-technology, would we know what counts as manipulation, culture change or valid argumentation? And how would we evaluate whether this is done by an aligned-AI for our benefit or to harm us?
A way backwards: Perhaps a solution to this dilemma is to decide what human beings value - and hard-code them. Like really hard! If we want to protect certain rights maybe we need to decide that they are inviolable and be ok to sanction, go to war etc, when other countries violate them - even on their own people.[4] This may seem like a regressive step: fixing moral norms, but perhaps in some near-term future, we may need to think more carefully about acting on advice of powerful "entities" when the entirety of moral and cultural systems are at stake.
Final rant: I've tried to present the problem of "agency hacking" as brief as possible to elicit more reads and hopefully (!) constructive criticisms. I hope the lack of citations isn't off-putting (I am writing the many page version of this article as well ... to be completed at some point).
My own broader view is that the AI-technologies will increasingly focus on behavior prediction to parallel prediction as the main driving force in the evolution of brains. This is because the most powerful tools we can build are for predicting (and controlling) human beings not nature, biology, physics etc. And once human behavior prediction is good enough and we are embedded enough with our technologies it may be trivial to design individualized behavior manipulation - and agency engineering technologies. Those techs will be great if they help us become better and happier (etc.). We need to plan better to ensure this is the world we get to.
- ^
The philosophical arguments fall into "compatibilism (60%), libertarianism, or no free will". https://philpapers.org/surveys/results.pl.
- ^
Many view that there is no real choice and the free will problem is in fact solved.
- ^
Sorry for the academic like link, but more can be read about this field in this academic review: https://www.annualreviews.org/doi/10.1146/annurev-polisci-042016-024408.
- ^
AI technologies trained on data obtained from oppressed populations already occurring in at least one place.
"The process Byler describes involves forced harvesting of people's data and then using it to improve predictive artificial intelligence technology. It also involves using the same population as test subjects for companies developing new tech. In other words, Xinjiang serves as an incubator for new tech."
- ^
10 comments
Comments sorted by top scores.
comment by Charlie Steiner · 2022-09-05T00:46:53.237Z · LW(p) · GW(p)
Welcome! By free will problem do you mean something like "preserving humans' free will around powerful systems?"
I think if you stick around here and read some of the archives you'll get a lot more pessimistic about hardcoding complicated rules, and more interested in what it means to learn them correctly.
Replies from: cat-1↑ comment by catubc (cat-1) · 2022-09-05T07:39:41.755Z · LW(p) · GW(p)
Hi Charlie. Thanks for the welcome!
Indeed, I think that's a great way to put it "preserving human agency around powerful systems" (I added it to the article). Thanks for that! I am pessimistic that this is possible (or that the question makes sense as it stands). I guess what I tried to do above - was a soft argument that "intent-aligned AIs" might not make sense without further limits or boundaries on both human intent and what AIs can do.
I agree hard wiring is probably not the best solution. However, humans are probably hardwired with a bunch of tools. Post-behaviorist psychology, e.g. self-determination-theory, argues that agency and belonging (for social organisms) are hard wired in most complex organisms (i.e. not learned). (I assume you know some/a lot about this, here's a very rough write up https://practicalpie.com/self-determination-theory/).
comment by Shmi (shminux) · 2022-09-03T19:30:34.756Z · LW(p) · GW(p)
Not clear to me what you mean by free will and where you fall on the philosophical spectrum. I guess my standard question is "Do bacteria have free will? What about fish? Cats? People with brain trauma? Etc."
Replies from: cat-1↑ comment by catubc (cat-1) · 2022-09-05T07:05:36.592Z · LW(p) · GW(p)
Thanks shminux. My apologies for the confusion, part of my point was that we don't have consensus on whether we have free will (the professional philosophers usually fall into ~60% compatibilists; but the sociologists have a different conception altogether; and the physicists etc.). I think this got lost because I was not trying to explain the philosophical position on free will. [I have added a very brief note in the main text to clarify what I think of as the "free will problem"].
The rest of the post was an attempt to argue that because human action is likely caused by many factors, AI techs will likely help us uncover the role of these factors; and that AI-misuse or even AI-aligned agents may act to change human will/intent etc.
Re: whether bacteria/fish/cats etc have free will: I propose we'll have better answers soon (if you consider AGI is coming soon-ish). Or more precisely, the huge body of philosophical, psychological and sociological ideas will be tested against some empirical findings in this field. I actually work on these type of questions from the empirical side (neuroscience and open behavior). And - to summarize this entire post in 1 sentence - I am concerned that most organisms including humans have quite predictable behaviors (given behavior + other internal state data) and that these entire causal networks will be constantly under pressure by both nefarious - but also well-meaning agents like (aligned-AIs) because of the inherently complex nature of behavior.
comment by tom4everitt · 2022-09-29T13:16:20.058Z · LW(p) · GW(p)
I think the point that even an aligned agent can undermine human agency is interesting and important. It relates to some of our work on defining agency [AF · GW] and preventing manipulation. (Which I know you're aware of, so I'm just highlighting the connection for others.)
comment by Nathan Helm-Burger (nathan-helm-burger) · 2022-09-24T15:05:35.764Z · LW(p) · GW(p)
Thanks for the interesting post. I definitely agree that large scale manipulation of human behavior and belief by misaligned AI is a real danger. One thing I think could use a bit more precision here is talking about "aligned AI". I think it's worth drawing a distinction between "seemingly aligned AI which seems safe at first, but actually warps human society/thought/behavior in negative ways" (almost aligned AI) and "truely aligned AI which actively protects humanity from warping influences of powerful tech." (Truely aligned AI) With this distinction I see you as making two separate claims. Let me know if you think I am describing your viewpoint correctly. Claim 1: we might mistake almost-aligned-AI for truely-aligned-AI, and allow the almost-aligned-AI to make dangerous changes to human culture, behavior, and thought before realizing that anything has gone wrong, stealing our agency. If this process were allowed to continue too long, it could become very hard to stop/reverse because the almost-aligned-AI would be able to use its manipulation to protect itself. Claim 2: truely-aligned-AI is very hard to get to, and also very hard to distinguish from almost-aligned-AI, so that we are quite likely to find ourselves in the scenario described in claim 1.
I'm not sure I world agree with claim 2 about the likelihood, but I definitely do agree with claim 1 about the danger.
I think it's important to note that one way we could have an almost-aligned-AI is if what would have been a truely-aligned-AI was insufficiently resistant to being misused and an unethical human deliberately used it to manipulate society for accumulating power. There are currently malign manipulative agents at work in society, but the danger becomes much greater as AI tech grows in capability. I think this is likely to become somewhat problematic before we reach full-blown self-aware self-directing AGI that is truely aligned with humanity and thus protects us from being manipulated out of our agency. I don't have a clear sense of how much of a problem, and for how long.
Replies from: cat-1↑ comment by catubc (cat-1) · 2022-09-26T06:34:13.261Z · LW(p) · GW(p)
Thanks Nathan. I understand that most people working on technical AI-safety research focus on this specific problem, namely of aligning AI - and less on misuse. I don't expect a large ai-misuse audience here.
Your response - that "truly-aligned-AI" would not change human intent - was also suggested by other AI researchers. But this doesn't address the problem: human intent is created from (and dependent on) societal structures. Perhaps I failed to make this clearer. But I was trying to suggest we lack an understanding of the genesis of human actions/intentions or goals - and thus cannot properly specify how human intent is constructed - and how to protect it from interference/manipulation. A world imbued with AI-techs will change the societal landscape significantly and potentially for the worse. I think that many view human "intention" as a property of humans that acts on the world and is somehow isolated or protected from the physical and cultural world (see Fig 1a). But the opposite is actually true: in humans intent and goals are likely caused significantly more by society than biology.
The optimist statement: The best way I can interpret "truly-aligned-AI won't change human agency" is to say that "AI" will - help humans - solve the free will problem and will then "work with us" to redesign what human goals should be. But this later statement is a very tall-order (a United Nations statement that perhaps will never see the light of day...).
comment by TAG · 2022-09-04T18:26:56.383Z · LW(p) · GW(p)
I'm with shminux, for once. I can't understand anything else you say because you don't define "the free will problem".
Replies from: cat-1↑ comment by catubc (cat-1) · 2022-09-05T07:48:14.838Z · LW(p) · GW(p)
Hi TAG, indeed, the post was missing some clarifications. I added a bit more about free will to the text, I hope it's helpful.
Replies from: TAG↑ comment by TAG · 2022-09-05T10:40:13.026Z · LW(p) · GW(p)
[EDIT: addition]. At the core of my research interest lies a simple question: If another agent (i.e. person, algorithm etc) can predict what you are going to do next (second, hour, week, year), do you still have agency? This question was one that St Thomas Aquinas asked nearly 800 years ago (in Quaestiones disputatae de veritate), namely, whether free will or freedom can exist in the presence of an all-knowing agent—in his case, the Christian god. His answer was essentially yes—but mostly because his agent was not interested in interfering with human action. In an age of behavior-predicting AIs, there may be many such powerful agents. And some will be interested in interfering with human actions. The question then, is how do we: “preserve human free will around powerful systems?” (thanks to Charlie Steiner for suggesting this simple summary).
The "free will problem" now looks like two problems. One is the theoretical problem of whether free will exists; the other is the practical problem of how powerful AI s might affect de facto human agency ... agency which might fall short of the traditional concept of free will.
The impact of a perfect predictor, God or Laplace's Demon on free will has nothing to do with its actual existence. Such a predictor is only possible in a deterministic universe, and it is determinism, not prediction that impacts fee will. You don't become unfree when someone predicts you , you always were.
There are a lot of things a powerful AI could do manipulate people, and they are not limited to prediction.