UML VI: Stochastic Gradient Descent
post by Rafael Harth (sil-ver) · 2020-01-12T21:59:25.606Z · LW · GW · 0 commentsContents
Gradient Descent Stochastic Gradient Descent Deriving an upper-bound on the Error The plan Step 1 Step 2 Step 3 The algebraic stuff Reflections None No comments
(This is part six in a sequence on Machine Learning based on this book. Click here [LW · GW] for part 1.)
Stochastic Gradient Descent is the big Machine Learning technique. It performs well in practice, it's simple, and it sounds super cool. But what is it?
Roughly, Gradient Descent is an approach for function minimization, but it generally isn't possible to apply it to Machine Learning tasks. Stochastic Gradient Descent, which is Gradient Descent plus noise, is a variant which can be used instead.
Let's begin with regular Gradient Descent.
Gradient Descent
Given a function and a point , the gradient of at is the vector of partial derivatives of at , i.e.
So the gradient at a point is an element of . In contrast, the gradient itself (not yet applied to a point) is the function defined by the above rule. Going forward, gradient always means "gradient at a point".
If , then the gradient will be , a number in . It can look like this:
Or like this:
Or also like this:
Point being, if it'll point rightward and if it'll point leftward, also it can have different lengths, but that's it. The idea of gradient descent is that the gradient points into the direction of fastest positive change, thus the opposite of the gradient is the direction of fastest negative change. It follows that, to minimize a function, one can start anywhere, compute the gradient, and then move into the opposite direction.

In the above example, the function goes up, therefore the derivative is positive, therefore the gradient points rightward. Gradient Descent tells us to go into the opposite direction, i.e. leftwards. Indeed, leftward is where the function decreases. Clearly, this is a display of utter brilliance.
Importantly, note that the picture is misleading insofar as it suggests there are more directions than two. But actually, the gradient lives in the domain space, in this case, , not in the Cartesian product of domain space and target space, in this case, . Therefore, it cannot point upward or downward.
As silly as the one-dimensional case is, it quickly becomes less trivial as we increase the dimension. Consider this function (picture taken from Wikipedia):

Again, the gradient lives in the domain space, which is , as this image illustrates nicely. Thus it cannot point upward or downward; however, it can point into any direction within the flat plane. If we look at a point on this function, it is not immediately obvious in which direction one should move to obtain the fastest possible decrease of its function value. But if we look at the little arrows (the gradients at different domain points), they tell us the direction of the fastest positive change. If we reverse them, we get the direction of the fastest negative change.
The following is important to keep in mind: in the context of Machine Learning, the domain space for our loss function is the space of all possibe hypotheses. So the domain is itself a function space. What we want to do is to minimize a function (a loss function) that takes a function (a predictor, properly parametrized), as an argument, and outputs the performance of that predictor on the real world. For example, if we allow predictors of the form for a regression problem, i.e. , our function space could be , where each defines one predictor . Then, there is some well-defined number that evaluates the performance of in the real world. Furthermore, if is differentiable, there is also some well-defined three-dimensional vector . The vector, which lives in , tells us that the real error increases most quickly if we change the predictor in the direction of the gradient – or equivalently, that it decreases most quickly if we change the predictor in the direction opposite to the gradient. This is why we will refer to our elements of by the letters and such; not or .
If the loss function were known, one could thus minimize it by starting with an arbitrary predictor parametrized by , computing the gradient , and then "moving" into the direction opposite to the gradient, i.e. setting , where is a parameter determining the step size. There is no telling how long moving into the direction opposite to the gradient will decrease the function, and therefore the choice of is nontrivial. One might also decrease it over time.
But, of course, the loss function isn't known, which makes regular Gradient Descent impossible to apply.
Stochastic Gradient Descent
As always, we use the training sequence as a substitute for information on the real error, because that's all we have. Each element defines the point-based loss function , which we can actually use to compute a gradient. Here, has to be some familiar set – and to apply the formal results we look at later, it also has to be bounded, so think of .
Now we do the same thing as described above, except that we evaluate the performance of our predictor at only a single point at a time – however, we will use a different point for each step. Thus, we begin with some which defines a predictor , and we will update it each step so that, after step , we have the predictor . To perform step , we take the loss function which maps each onto the error of the predictor on . We compute the gradient of this loss function at our current predictor, i.e. we compute . Then we update by doing a small step in the direction opposite to this gradient. Our complete update rule can be expressed by the equation
The reason why, as the book puts it, Stochastic Gradient Descent can be used to "minimize the loss function directly" is that, given the i.i.d. assumption, the point is an unbiased estimate of the real distribution, and therefore, one can prove that the expected value – with respect to the point – of the gradient we compute equals the gradient of the real loss function . Thus, we won't always update into the right direction, but we will update into the right direction noise. The more steps one does, the lower the expected total noise will be, at least if is decreased over time. (This is so because, if one does random steps from some origin, then as the number of steps increases, even though the expected absolute distance from the origin will increase, the expected relative distance decreases. The expected relative distance is the term , which is an analog to in our case. Then, since we have this consistent movement into the correct direction that grows linearly with "number of steps", the term also decreases, making us likely to converge toward the solution.)
In the context of supervised learning, i.e. where training data is available at all, the only things that needs to hold in order for Stochastic Gradient Descent to be applicable is that (a) the hypothesis class can be represented as a familiar set, and (b) we can compute gradients on the point-based loss functions (in practice, they don't even necessarily need to be differentiable at every point). The remaining question is whether or not it will perform well. The most important property here is certainly the convexity of the loss function because that is what guarantees that the predictor will not get stuck in a local minimum, which could otherwise easily happen (the negative gradient will just keep pushing us back toward that local minimum).
In the previous chapter, we introduced the classes of convex Lipschitz bounded and convex smooth bounded problems. For both of these, one can derive upper-bounds on the expected error of a classifier trained via stochastic gradient descent for a certain number of steps. In the remainder of this chapter, we will do one of those proofs, namely the one for convex smooth bounded problems. This is an arbitrary choice; both proofs are technical and difficult, and unfortunately also quite different, so we're not doing both.
Deriving an upper-bound on the Error
The proof which upper-bounds the expected real error is of the kind that I usually don't work out in detail because it just doesn't seem worth it. On the other hand, I don't want difficult proofs to be excluded in principle. So this will be an experiment of how my style of dissecting each problem until its pieces are sufficiently small works out if applied to a proof that seems to resist intuitive understanding. In any case, working through this proof is not required to understand Stochastic Gradient Descent, so you might end this chapter here.
Now let us begin.
The plan
Recall that we wish are given a problem out of the class of convex smooth bounded [LW · GW] problems (with parameters ), and we run the algorithm defined earlier in this post on our training sequence, . We wish to bound the (expected) real error of .
Meet the problem instance:
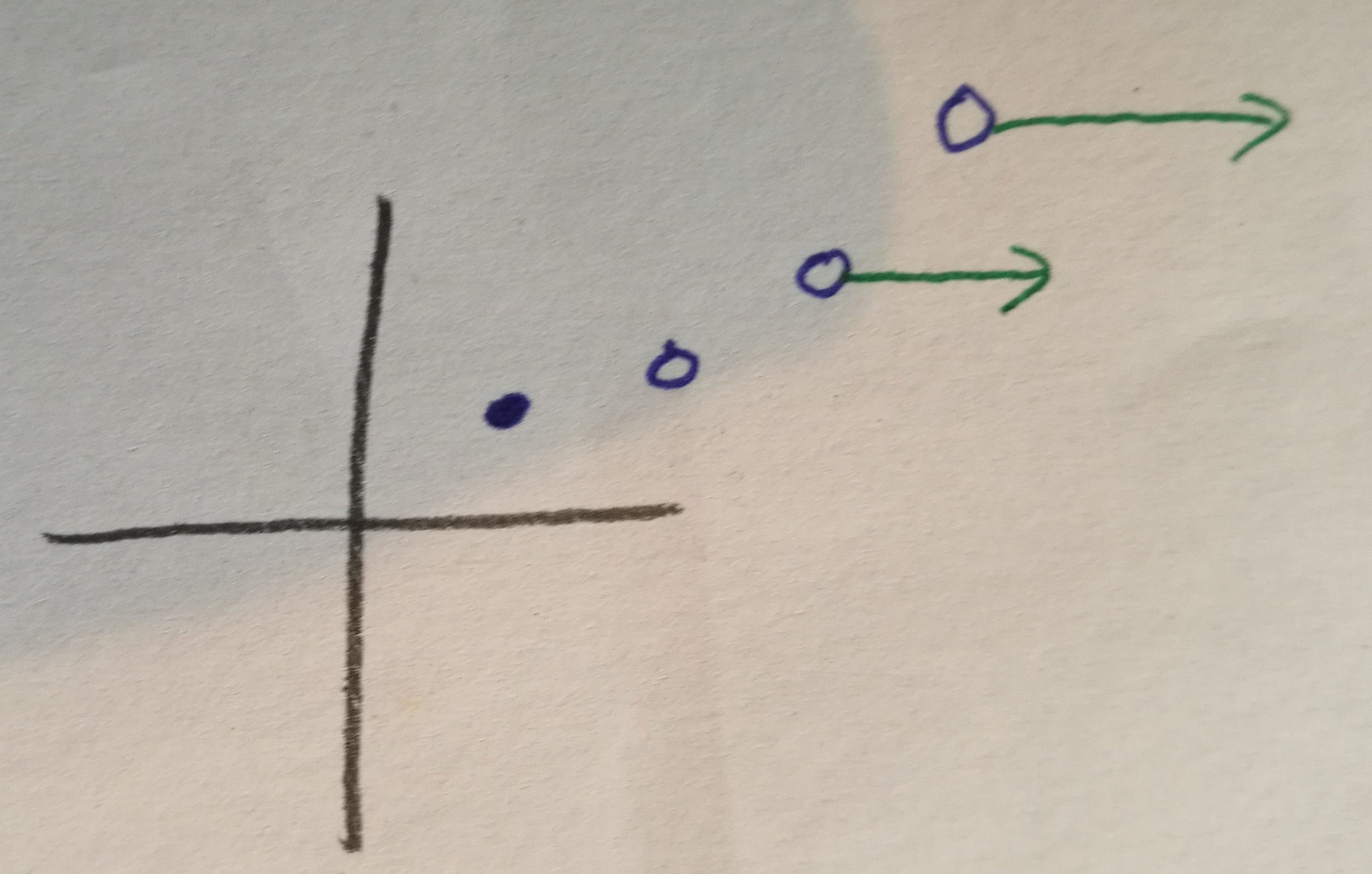
Of course, this is merely the problem instance within the images-world; the symbolic world where the actual proof happens will make no assumptions about the nature of the problem. That said, in the problem instance, we have and , because that's enough to illustrate the steps. Our training sequence (not shown!) consists of two elements, i.e. , this time indexed from 0 to avoid having to write a lot of "". For our hypothesis class, think of , where each defines a simple linear predictor – although going forward, we will pretend as if itself is the predictor. What the picture does show is the predictors through which the algorithm iterates (the highest one is , the second-highest , and the one without a gradient arrow is ). They live in -dimensional space (on the -axis). Their real error corresponds to their position on the -axis. Thus, both the predictors themselves and their errors are monotonically decreasing. The green arrows denote the gradients and . The filled point denotes the optimal predictor .
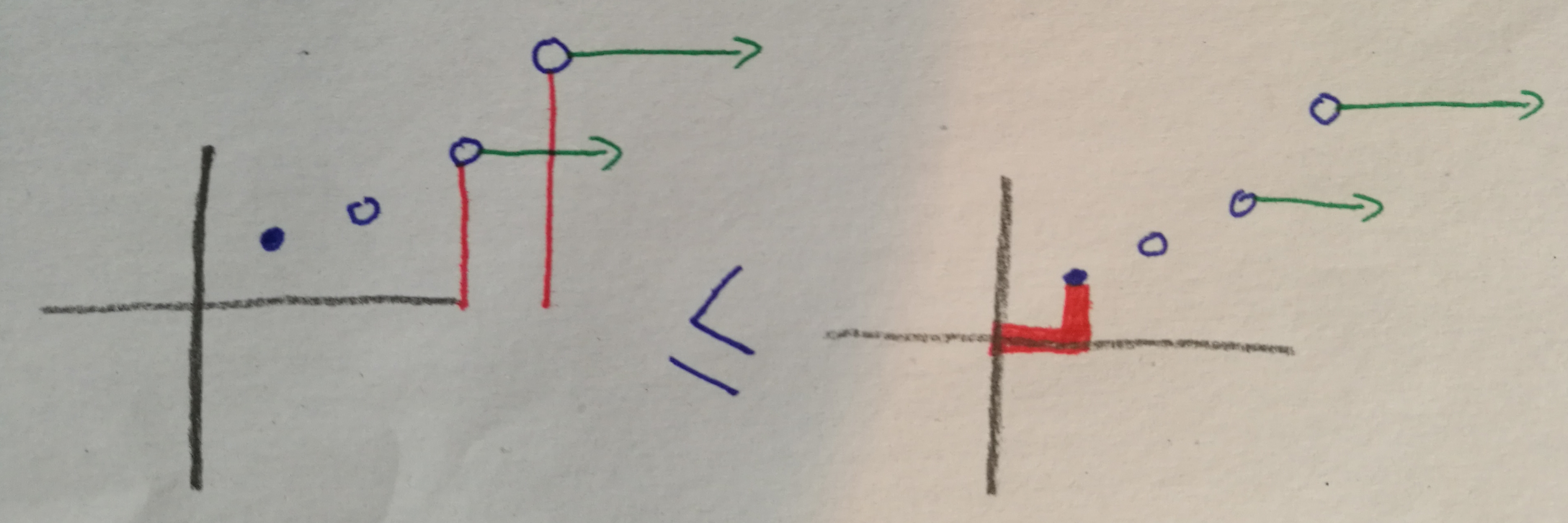
For unspecified reasons – probably because it makes analysis easier, although it could also reduce variance in practice – the precise algorithm we analyze puts out the predictor rather than , even though naively looks like the better choice. In our case, that means we put out . With that in mind, now meet the proof roadmap:

The proof roadmap illustrates what terms we're concerned with (red), and which upper-bounds we're deriving. Dashed lines mean a small factor in front of the term; fat lines mean a large factor. In the beginning, we look at the difference between the error of our output predictor and that of the optimal predictor (leftmost picture). Then we do three steps; in each step, we bound our current term by a different term. First, we bound it in terms of the inner product between the predictors themselves and the gradients. Then, we bound that by times the norm of the gradients plus many times the norm of the optimal predictor, where . Then we bound that by times the total error of our output predictor plus a lot of times the norm of the optimal predictor.
At that point, we've made a circle. Well – not quite, since we started with the difference between the error of the output predictor and that of the optimal predictor (hence why the lines don't go all the way down in picture one) and ended with the total error of the output predictor. But it's good enough. Through algebraic manipulations (adding the error of the optimal predictor on both sides and rescaling), we obtain a bound on the error of our output predictor, in terms of the error of the optimal predictor and the norm of the optimal predictor, i.e.:
And the equation corresponding to this picture will be the theorem statement.
Now we just have to do the three steps, and then the algebraic stuff at the end.
Step 1
We start by bounding the term , which is closely related to but not identical to the real error of the output predictor (it is defined in terms of the point-based loss functions rather than the real error). will be the number of steps, so . Recall the proof roadmap:
The first stop (second picture) is the term , where we write for . This bound applies for each summand individually, and it relies on a fundamental property of convex functions, namely that every tangent remains below the function:
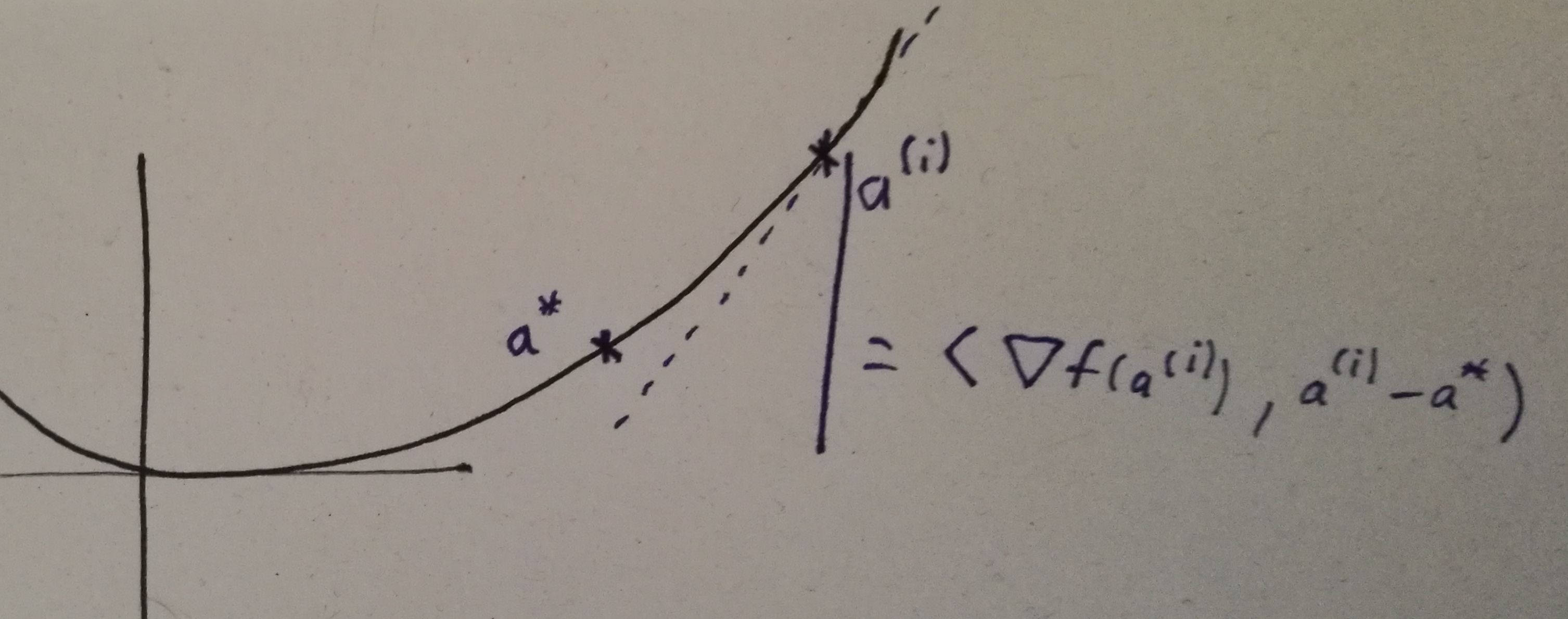
This should be easy enough to believe; let's skip the formal proof and continue.
Step 2
Our current term is . Recall the proof roadmap:
The next stop (third picture) is the term . This will be the hardest step – let's begin by reflecting on what it means.
We wish to bound the inner product of predictors and corresponding gradients with the norm of the gradients and the norm of the final predictor. So what we lose is the values of the predictors themselves. However, these are implicit in the gradients, since they encode how we move toward our final predictor (or equivalently, how we move away from the final predictor). Consequently, we will need to use the update rule, , to prove this result.
Our approach will be to reduce the inner product to the difference between and . Alas,
Or differently written, . Thus, we have
Then, , and the first two elements of this are a telescopic sum, i.e. each segment negates part of the next segment. What remains is , and we can upper bound it as , which is the bound we wanted to have. Here, the disappeared because the algorithm assumes we start with , which I conveniently ignored in my drawings.
Step 3
Our current term is . Recall the proof roadmap:
The next stop (last picture) is the term . This one will also work for each summand separately. We wish to prove that
,
where is from the smoothness definition of our point-wise loss function. So this bound is all about smooth functions. It even has a name: functions with this property are called self-bounded, because one can bound the value of the gradient in terms of the value of the same function.
If one were to prove this formally, one would do so for arbitrary smooth functions, so one would prove that, if , where is convex, and is a -smooth and nonnegative function, then
Recall that is -smooth iff for all and . Now, why is this statement true? Well, if we imagine to model the position of a space ship, then smoothness says that cannot accelerate too quickly, so in order to reach a certain speed, it will gradually have to accelerate towards that point and thus will have to bridge a certain distance. Let's take the one-dimensional case, and suppose we start from and consistently accelerate as fast as we're allowed to (this should be the optimal way to increase speed while minimizing distance). Then and , which means that and ; then . This is reassuring, because we've tried to construct the most difficult case possible, and the statement held with equality.
The formal proof, at least the one I came up with, is quite long and relies on line integrals, so we will also skip it.
The algebraic stuff
We have established that
which can be reordered as
.
At this point, we better have that , otherwise, this bound is utterly useless. Assuming does indeed hold, we can further reformulate this equation as
Rescaling this, we obtain
Dividing this by to have the left term closer to our actual error, we get
.
Now we take expectations across the randomization of the training sequence on both sides. Then the left side becomes the expected real error of our output predictor . The right term doesn't change, because it doesn't depend on . Thus, we have derived the bound
and this will be our final result. By choosing correctly and rearranging, it is possible to define a function such that, for any and upper-bounding the hypothesis class ( cannot be an input since we don't know the optimal predictor ) and any arbitrarily small , if , then the above is upper-bounded by . To be specific, will be given by .
Reflections
Recall that is the parameter from the smoothness of our loss function, is the number of training steps we make (which equals the number of elements in our training sequence), and is the step size, which we can choose freely. In the result, we see that a smaller is strictly better, a larger is strictly better, and will have its optimum at some unknown point. This all makes perfect sense – if things had come out any other way, that would be highly surprising. Probably the most non-obvious qualitative property of this result is that the norm of the optimal predictor plays the role that it does.
The most interesting aspect of the proof is probably the "going around in a circle" part. However, even after working this out in detail, I still don't have a good sense of why we chose these particular steps. If anyone has some insight here, let me know.
0 comments
Comments sorted by top scores.