UML V: Convex Learning Problems
post by Rafael Harth (sil-ver) · 2020-01-05T19:47:44.265Z · LW · GW · 0 commentsContents
Convexity Convex sets Convex functions Jensen's Inequality Guaranteeing learnability A failure of convexity Lipschitzness & Smoothness Surrogate Loss Functions None No comments
(This is part five in a sequence on Machine Learning based on this book. Click here [LW · GW] for part 1.)
The first three posts of this sequence have defined PAC learning and established some theoretical results, problems (like overfitting), and limitations. While that is helpful, it doesn't actually answer the question of how to solve real problems (unless the brute force approach is viable). The first way in which we approach that question is to study particular classes of problems and prove that they are learnable. For example, in the previous post, we've looked (among other things) at linear regression, where the loss function has the form and is linear. In this post, we focus on convex learning problems, where the loss function also has the above form and is convex.
Convexity
We begin with sets rather than functions.
Convex sets
A set (that is part of a vector space) is called convex iff for any two points in that set, the line segment which connects both points is a subset of .
The condition that is part of a vector space is missing in the book, but it is key to guarantee that a line between two points exists. Convexity cannot be defined for mere topological spaces, or even metric spaces. In our case, all of our sets will live in for some .
As an example, we can look at letters as a subset of the plane. None of the letters in this font are quite convex – l and I are closest but not quite there. The only convex symbols in this post that I've noticed are . and ' and | and –.
Conversely, every regular filled polygon with corners is convex. The circle is not convex (no two points have a line segment which is contained in the circle), but the disc (filled circle) is convex. The disc with an arbitrary set of points on its boundary (i.e. the circle) taken out remains convex. The disc with any other point taken out is not convex, neither is the disc with any additional point added. You get the idea. (To be precise on the last one, the mathematical description of the disc is , so there is no way to add a single point that somehow touches the boundary.)
Convex functions
Informally, a function is convex iff the set of all points on and above the function is convex as a subset of , where the dependent variable goes up/downward.

(Here, the middle function () is not convex because the red line segment is not in the blue set, but the left () and the right () are convex.)
The formal definition is that a function is convex iff for all , the equation holds for all . This says that a line segment connecting two points on the graph always lies above the graph.
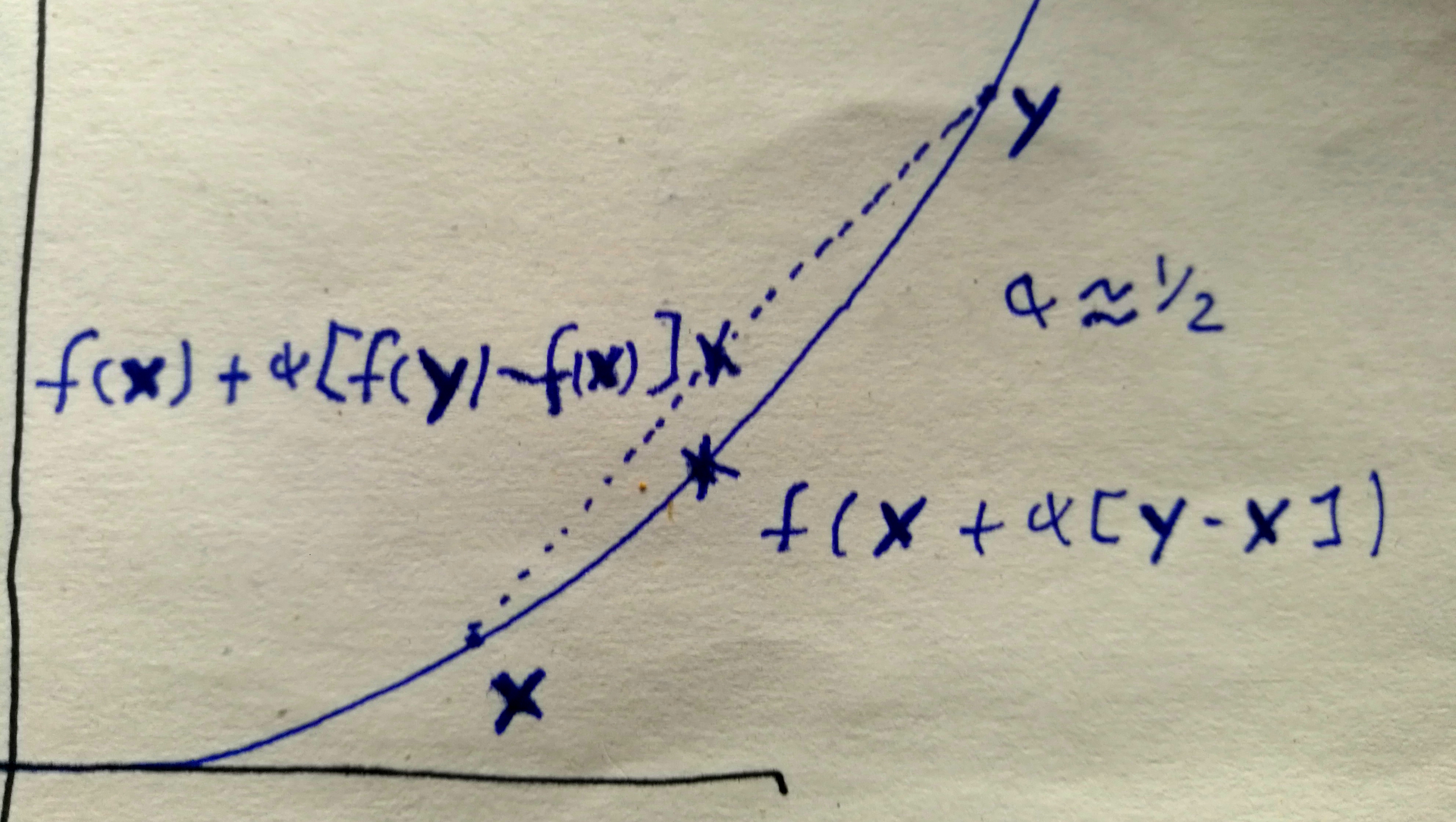
If as was the case in all of my pictures, then is convex iff the little pixie flying along the function graph never turns rightward. This is the case iff is monotonically increasing, which is the case iff for all .
The main reason why convexity is a desirable property is that, for a convex function, every local minimum is a global minimum. Here is a proof:
Suppose that is a local minimum. Then we find some ball around such that for all in the ball (this is what it means to be a local minimum in ). Now let be an arbitrary point in ; we show that its function value can't lie below that of . Imagine the line segment from to . A part of it must lie in our ball, so we find some (small) such that . Then (because is our local minimum), we have that . By convexity of we have , so taken together we obtain the equation
Or equivalently which is to say that which is to say that .
If there are several local minima, then there are several global minima, then one can draw a line segment between them that inevitably cannot go up or down (because otherwise one of the global minima wouldn't be a global minimum), so really there is just one global minimum. This is all about the difference between and . The simplest example is a constant function – it is convex, and everywhere is a global minimum.
Jensen's Inequality
The key fact about convex functions, I would argue, is Jensen's inequality:
Given with , if is convex, then for any sequence , it holds that .
If you look at the inequality above, you might notice that it is almost the definition of linearity, except for the condition and the fact that we have instead of . So convex functions fulfill the linearity property as an inequality rather than an equality (almost). In particular, linear functions are convex. Conversely, concave functions (these are functions where the in the definition of convex functions is a ) also fulfill the above property as an inequality, only the the sign does again turn around. In particular, linear functions are concave. To refresh your memory, here is the definition of convexity:
So to summarize: convex functions never turn rightward, concave functions never turn leftward, and the intersection of both does neither, i.e., always goes straight, i.e., is linear. Looking at convexity and concavity as a generalization of linearity might further motivate the concept.
Terms of the form , which one sees quite often (for example in defining points on a line segment), can be equivalently written as . I think the first form is more intuitive; however, the second one generalizes a bit better. We see that and are given weights, and those weights sum up to . If one goes from 2 weighted values to weighted values (still all non-negative), one gets Jensen's inequality. Thus, the statement of Jensen's inequality is that if you take any number of points on the graph and construct a weighted mean, that resulting point still lies above the graph. See wikipedia's page for a simple proof via induction.
Guaranteeing learnability
Recall that we are trying to find useful solvable special cases of the setting minimize a loss function of the form . This can be divided into three tasks:
(1) define the special case
(2) demonstrate that this special case is indeed solvable
(3) apply the class as widely as possible
This chapter is about (1). (When I say "chapter" or "section", I'm referring to the level-1 and level-2 headlines of this post as visible in the navigation at the left.) The reason why we aren't already done with (1) is that convexity of the loss function alone turns out to be insufficient to guarantee PAC learnability. We'll discuss a counter-example in the context of linear regression and then define additional properties to remedy the situation.
A failure of convexity
In our counter-example, we'll have (note that this is a convex set). Our hypothesis class will be that of all (small) linear predictors, i.e. just . The reason that we only allow small predictors is that our final formulation of the learnable class will also demand that is a bounded set, so this example demonstrates that even boundedness + convexity is still not enough.
We've previously defined real loss functions as taking a hypothesis and returning the real error, and empirical loss functions as taking a hypothesis and a training sequence and returning the empirical error. Now we'll look point-based loss functions (not bolded as it's not an official term, but I'll be using it a lot) which measure the error of a hypothesis on a single point only, i.e. they have the form for some . To be more specific, we will turn the squared loss function defined in the previous post into a point-based loss function. Thus we will have , where the last equality holds because we're in the one-dimensional case. We will only care about two points (all else will have probability mass ), namely these two:

That's the point at the left and one all the way to the right at . With , think of an extremely small positive number, so that is quite large.
If this class were PAC learnable, then there would be a learner such that, for all , if the size of the training sequence is at least , then for all probability distributions over , with probability at least over the choice of , the error of would be at most larger than that of the best classifier.
So to prove that it is not learnable, we first assume we have some learner . Then we get to set some and and construct a probability distribution based on . Finally, we have to prove that fails on the problem given the choices of and and . That will show that the problem is not PAC learnable.
We consider two possible candidates for . The first is which has all probability mass on the point on the left. The second is , which has almost all probability mass on the point , but also has probability mass on the point . As mentioned, will be extremely small; so small that the right point will be unlikely to ever appear in the training sequence.
If the right point doesn't appear in the training sequence, then the sequence consists of only the left point sampled over and over again. In that case, cannot differentiate between and , so in order to succeed, it would have to output a hypothesis which performs well with both distributions – which as we will show is not possible.
Given our class , the hypothesis must be of the form for some . Recall that the classifier is supposed to predict the -coordinate of the points. Thus, for the first point, would be the best choice (since ) and for the second point, would be the best choice (since ).
Now if , then we declare that . In this case (assuming that the second point doesn't appear in the training sequence), there will be a chance of predicting the value , which, since we use the squared loss function, leads to an error of at least , and thus the expected error is at least , which, because is super tiny, is a very large number. Conversely, the best classifier would be at least as good as the classifier with , which would only have error (for the left point), which is about and thus a much smaller number.
Conversely, if , we declare that , in which case the error of is at least , whereas the best classifier (with ) has zero error.
Thus, we only need to choose some and an arbitrary . Then, given the sample size , we set small enough such that the training sequence is less than likely to contain the second point. This is clearly possible: we can make arbitrarily small; if we wanted, we could make it so small that the probability of sampling the second point is . That concludes our proof.
Why was this negative result possible? It comes down to the fact that we were able to make the error of the first classifier with large via a super unlikely sample point with high error – so the problem is the growth rate of the loss function. As long as the loss function grows so quickly that, while both giving a point less probability mass and moving it further to the right, the expected error goes up, well then one can construct examples with arbitrarily high expected error. (As we've seen, the expected error in the case of is at least , i.e. a number that grows arbitrarily large as .)
Lipschitzness & Smoothness
There are at least two ways to formalize a requirement such that the loss function is somehow "bounded". They're called Lipschitzness and Smoothness, and both are very simple.
Lipschitzness says that a function cannot grow too fast, i.e.:
A function is -Lipschitz iff
If is differentiable, then a way to measure maximum growth is the gradient, because the gradient points into the direction of fastest growth. Thus, one has the equivalent characterization:
A differentiable function is -Lipschitz iff for all
However, non-differentiable functions can be Lipschitz; for example, the absolute value function on the real numbers is -Lipschitz.
Conversely, smoothness is about the change of change. Thus, is definitely not smooth since the derivative jumps from to across a single point (smoothness is only defined for differentiable functions). On the other hand, the function is smooth on all of . The formal definition simply moves Lipschitzness one level down, i.e.
A differentiable function is -smooth iff its gradient is -Lipschitz
Which is to say, iff for all . In the one-dimensional case, the gradient equals the derivative, and if the derivative is itself differentiable, then smoothness can be characterized in terms of the second derivative. Thus, a twice-differentiable function is -smooth iff for all .
One now defines the class of convex Lipschitz bounded problems and that of convex smooth bounded problems. They both require that has a structure as a familiar set like , that it is convex and bounded (so would not suffice), and that, for all , the point-based loss function is -Lipschitz (in the former case) or -smooth and nonnegative (in the latter case). If all this is given, the class is called convex Lipschitz bounded with parameters ; or convex smooth bounded with parameters .
In the previous example, the hypothesis could be represented by the set , which is both convex and bounded. (In that example, we thought of it as a set of functions, each of which fully determined by an element in ; now we think of it as the set itself.) Each point-based loss function is convex (and non-negative). However, for any number , the loss function is defined by the rule , and the gradient of this function with respect to (which equals the derivative since we're in the one-dimensional case) is . Since this gets large as gets large, the function is not Lipschitz. Furthermore, the second derivative is . This means that each particular function induced by the point is -smooth, but there is no parameter such that all functions are -smooth.
Surrogate Loss Functions
We are now done with task (1), defining the special case. Task (2) would be demonstrating that both convex Lipschitz bounded and convex smooth bounded problems are, in fact, PAC learnable with no further conditions. This is done by defining an algorithm and then proving that that the algorithm works (i.e., learns any instance of the class with the usual PAC learning guarantees). The algorithm we will look at for this purpose (which does learn both classes) is an implementation of Stochastic Gradient Descent; however we'll do this in the next post rather than now. For this final chapter, we will instead dive into (3), i.e. find an example of how the ability to learn these two classes is useful even for problems that don't naturally fit into either of them.
Recall [LW · GW] the case of binary linear classification. We have a set of points in some high-dimensional space , a training sequence where points are given binary labels (i.e. ) and we wish to find a hyperplane that performs well in the real world. We've already discussed the Perceptron algorithm and also reduced the problem to linear programming; however, both approaches have assumed that the problem is separable.
We're not going to find a perfect solution for the general case, because one can show that the problem is NP-hard. However, we can find a solution that approximates the optimal predictor. The approach here is to define a surrogate loss function, which is a loss function that (a) upper-bounds the real loss , and (b) has nicer properties than the real loss, so that minimizing it is easier. In particular, we would like for it to be a member of one of the two learnable classes we have introduced. Our point-based loss function for has the form , where for a boolean statement is 1 iff is true and 0 otherwise.
Recall that each hyperplane is fully determined by one vector in , hence the notation . If we represent directly as and assume , then the graph of looks like this...

... because in and the homogeneous case, the classifier determined by a single number; if this number is positive it will label all positive points with 1; if it's negative, it will label all negative points with 1. If the -coordinate of the point in question is positive with label or negative with label (i.e. and ; or and ), then the former case is the correct one and we get this loss function. Otherwise, the loss function would jump from 0 to 1 instead.
Obviously, is silly, but it already demonstrates that this loss function is not convex (it makes a turn to the right, and it's easy to find a segment which connects two points of the graph and doesn't lie above the graph). But consider the alternative loss function :

This new loss function can be defined by the rule . In the picture, the horizontal axis corresponds to and we have and . This loss function is easily seen to be convex, non-negative, and not at all smooth. It is also -Lipschitz. Thus, the problem with is not convex Lipschitz bounded, but if we take and also for some , then it does become a member of the convex-Lipschitz-bounded class with parameters and , and we can learn via e.g. stochastic gradient descent.
Of course, this won't give us exactly what we want (although penalizing a predictor for being "more wrong" might not be unreasonable), so if we want to bound our loss (empirical or real) with respect to , we will have to do it via , where the second term is the difference between both loss functions. If is small, then this approach will perform well.
0 comments
Comments sorted by top scores.