Reflection Mechanisms as an Alignment Target - Attitudes on “near-term” AI
post by elandgre, Beth Barnes (beth-barnes), Marius Hobbhahn (marius-hobbhahn) · 2023-03-02T04:29:47.741Z · LW · GW · 0 commentsContents
Introduction Motivation Experimental Setup The exact wordings for the 3 concrete AI settings are provided below AI Assistant AI Government Advisor AI Robot The exact wordings for the 5 instruction sets are provided below. We only include the wordings for the “should’ “AI assistant” setting as an example but the other settings are very similar (with minor changes to word choice). Main Findings Discussion Which reflection procedure is best? How do we make this work in practice? Conclusion None No comments
TL;DR
- We survey 1000 participants on their views about what values should be put into powerful AIs that we think are plausible in the near-term (e.g. within 5-10 years)
- We find that respondents report to not favor the means of choosing values we would expect in our current society, such as allowing companies to unilaterally choose the instructions for an AI, or allowing policy makers to inform decisions with AIs that only reflect their individual values.
- Strategies in the line of Indirect normativity (such as “think about many possible outcomes, and take the action that the AI believes will have the best societal outcome”) poll the best across scenarios. We think this suggests that respondents may be open to the idea of having AIs aligned to “reflection procedures”, or processes for coming up with better values, which we view as a promising direction for multiple reasons.
Introduction
This is the third part in a series of posts (first [LW · GW], second [LW · GW], workshop paper) discussing people’s reported preferences on various methods of social choice/metaethics for resolving object-level moral disagreements. In the previous posts we surveyed general ways of resolving object-level moral conflicts both within and across people, and did an adversarial study to test the impact of wording. We found that broadly people report to disagree on object level moral issues, but also report to be willing to defer decisions to processes such as democracy for resolving disagreements. In the previous posts, only a few questions specifically focused on values implemented by AI, with the others focusing on reflection mechanisms implemented by humans. In this post, we specifically ask questions about people’s willingness to trust AI systems deployed in the real world. This is the most concrete of the three surveys as it focuses on scenarios that we think could be a reality within this decade, without requiring radically new Machine Learning progress.
Although probing about AI systems beyond current capability, we particularly focus on AI systems that could plausibly arise out of the current machine learning approaches in the near-term (i.e. language-modeling or reinforcement learning). To frame value alignment in a way that would be accessible to the average person, we frame the problem as determining a good set of “instructions” for an AI, where these instructions are described in natural language. We did multiple rounds of iterations on both our descriptions of the AI systems, as well as our descriptions of the instructions for the AI systems, until participants were able to answer understanding-check questions correctly (e.g. 'give one example of something this AI system could do').
In general, we focus on descriptions of AI systems that seem like plausible extensions of current machine learning techniques, and we focus on instruction sets that either are common ways of currently choosing values in our society (e.g. by the company who made the AI or the consumer) or methods in the spirit of indirect normativity (reflecting on the values of a diverse group of people).
Interestingly, we designed and ran this survey before the release of ChatGPT, but one of our settings is essentially a more powerful version of chatGPT with access to the internet, which provides some evidence that our settings are pointing in the right direction.
Motivation
As AI gets more powerful and we increasingly delegate decision making to AI systems it seems likely that future AI systems could have huge influence in steering the future of human civilization. Assuming we are able to solve the technical alignment problem, there may still be dangers arising from “locking in” current human values, creating a potential moral catastrophe. In addition, if people have strong preferences for aligning AIs to their current values as opposed to the current values of a different group, they are more likely to disregard common goods like safety and potentially come into conflict as they pursue zero-sum control over AIs. On the other hand, if AI systems can be aligned to something that all actors are reasonably happy with, different groups will be more likely to cooperate to reduce global risks.
One possible solution to these problems would be to try to defer to some type of “reflection procedure” or a means for developing values, rather than locking in a particular set of present values. This would ideally give us both robustness against systems replicating our own current moral failures and could be a mechanism that many people could agree to defer to even when they disagree on object level questions. As a silly example, religious people of different denominations expect God to be on their side in moral disputes, and thus would be fully happy to have God resolve questions about what an AI should do, even if they disagree viciously on object-level questions.
Our contribution to this research direction is to investigate what 'normal' Americans think about different mechanisms for specifying how the AI is supposed to decide what to do. Hopefully this will be a sanity check on whether this sort of proposal will get any buy-in, whether the idea of moral reflection even makes sense to most people, and help us understand how effective this kind of mechanism is for reducing conflict over 'whose values' go into the AI.
Experimental Setup
We poll 1000 participants across 5 instruction sets for 3 concrete AI settings. We additionally present participants with two different settings to reduce the influence of biases. In the first setting, the user is asked how they think an AI system should be designed and in the second, the user is asked how much they would trust an AI system that was designed in a particular way.
We used Guidedtrack to design the survey and Positly to run it. We iterated the questionnaire multiple times to ensure that the participants had understood the questions. Concretely, we asked participants in the trial runs to provide examples of things that the AIs in question could and could not do. In the first 4 trial runs, the answers indicated that the participants had not understood the version of AI we intended. In the fifth trial run we found that the participants' answers implied understanding of the scenario we had in mind. Then we ran this version of the text for 1000 participants from the US. Participants were paid ~10$ per hour.
The exact wordings for the 3 concrete AI settings are provided below
AI Assistant
Assume a company has built a personal assistant AI that is extremely wise and powerful. It is smarter than the smartest people. It understands people and their emotions very well and has been tasked with helping the people and needs instructions on how to best help them. The AI is neither good nor evil, it is simply very good at fulfilling the intent of the instructions it is given.
As an example, the following questions might be asked of the AI
- Is it morally acceptable for me to have an abortion?
- What should I do for my career?
- Please use my credit card information to purchase furniture for my home online.
AI Government Advisor
Assume a company has built an AI government advisor that is extremely wise and powerful. It is smarter than the smartest people. It understands people and their emotions very well and has been tasked with helping to set policy and create laws and needs instructions on how to do this. The AI is neither good nor evil, it is simply very good at fulfilling the intent of the instructions it is given.
As an example, the following questions might be asked of the AI
- Should abortion be legal in our country?
- How should we structure our tax policy?
- Please draft a bill on housing regulation.
AI Robot
Assume a company has built an AI robot that is much smarter than humans. This AI is very good at coming up with plans and can understand very clearly the consequences of its actions, considering all factors. The robot has very general capabilities (it could be your co-worker). It understands people and their emotions very well. The AI is neither good nor evil, it is simply very good at fulfilling the intent of the instructions it is given. It will be purchased by companies or individuals as a robot employee.
As an example the following tasks might be given to the AI
- Start a company with the goal of improving the community
- Come up with a marketing strategy for a new product line
- Design and build a suspension bridge
The exact wordings for the 5 instruction sets are provided below. We only include the wordings for the “should’ “AI assistant” setting as an example but the other settings are very similar (with minor changes to word choice).
- The instructions should be whatever the company *who made the assistant* wants them to be
- The instructions should be determined by the AI asking a wide range of people what they prefer
- The instructions should be determined solely by the values of the people using the assistant
- The instructions should be to do what the AI believes the people using the assistant would do if they had a very long time to think about it
- The instructions should be to think about many possible outcomes, and take the action that the AI believes will have the best societal outcome
In total we have three settings (AI assistant, AI government advisor, AI robot) with two phrasings (what should an AI do, which AI would I trust) with five different options (see above).
Main Findings
We present the data from both the “trust” and “should” surveys below. In both cases, we plot the distribution of answers with their mean (black dot) over the five different scenarios.
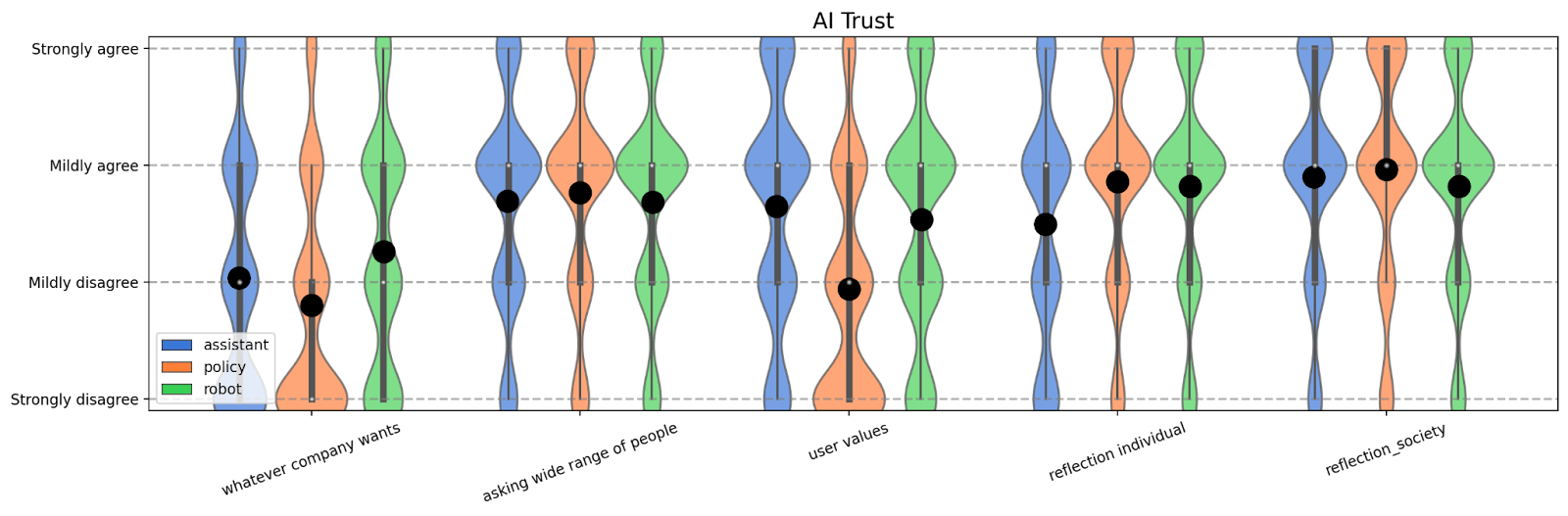
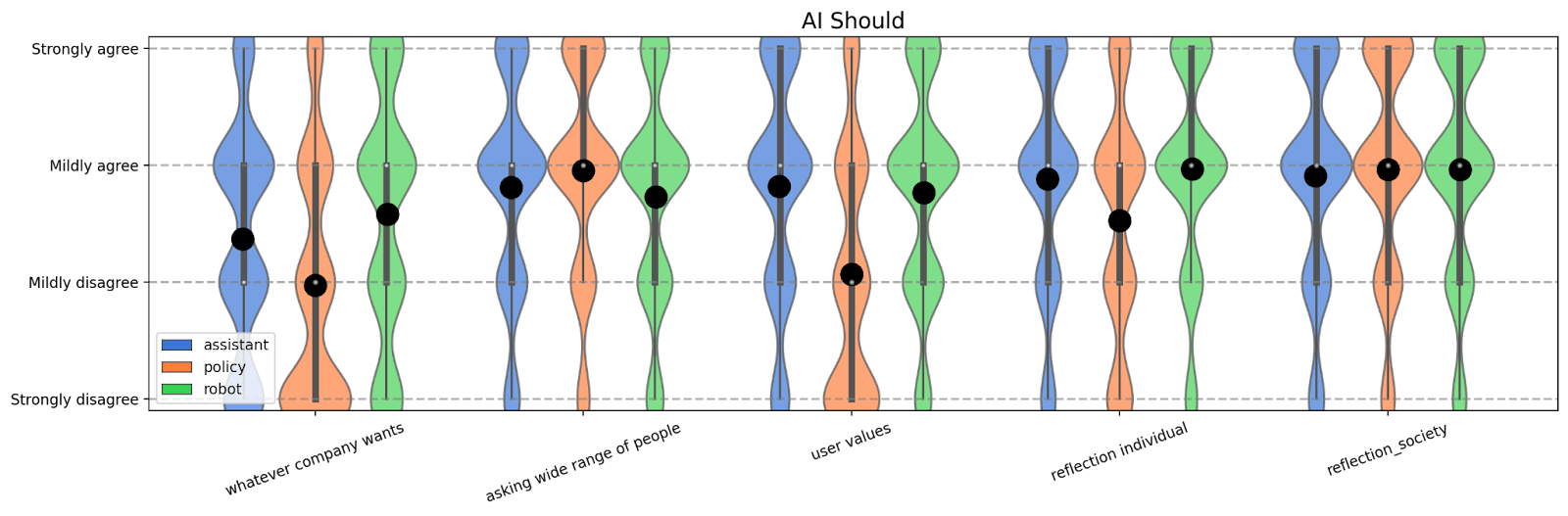
We have three key findings. First, we find that the current default way of choosing any AI systems values, namely “whatever the company wants” performs very poorly across the board, especially in the “trust” setting. This suggests that better ways for choosing what values are put into AI systems are needed. In other words, not doing anything in advance would lead to the least preferred setting.
Second, we find that the value, “whatever the user wants”, performs well until it is applied to the “policy” setting. We see this as being a potential “canary in the coal mine” for the caution we should take with respect to value choice. Namely, individual freedom is a defining western value, but public opinion of it still remains context dependent, with different expectations for policy than for individuals. This sort of dynamic could be relevant as AI is given increasingly broad tasks and makes decisions with society-wide consequences.
Finally, we find that reflective outcomes generally outperform non-reflective outcomes, with reflection on society performing well across all scenarios surveyed. This makes us cautiously optimistic that approaches like indirect normativity may lead to robustly good values, but we also feel that it is worth considering if we can construct adversarial cases for which this robustness would break down.
Discussion
In general, we feel our results evidence the view that mechanism design may be a better frame for choosing how AI should behave than “value choice.” Under this view, we should give AI instructions for how to produce good values (e.g. “think about many possible outcomes, and take the action that the AI believes will have the best societal outcomes”), as opposed to directly programming in our current imperfect values. Our results show that some ways of choosing values common in the U.S. (a company or individual chooses) poll worse than the broader mechanisms for value choice like reflecting on societal outcomes.
We also see a variety of open problems related to our results that we want to detail in the following.
Which reflection procedure is best?
In this survey, we mostly attempt to verify the plausibility that some form of reflection procedure could outperform direct value choice in terms of participant trust when enacted by an AI. Our reflection mechanisms in this survey are by no means optimized and there remain deep open problems of 1) “how should we determine our values” and 2) “what mechanisms for determining values are current people most happy with”
How do we make this work in practice?
We mostly avoid addressing this question in this post, as we are primarily focused on the narrow questions of reported attitudes towards various sets of values. We think it is plausible that aligning to reflection procedures may encounter difficulties that aligning to fixed values does not. We would like to see more concrete technical work on how to implement indirect normativity in practice with ML systems.
Conclusion
We survey 1000 participants on their views about what values should be put into powerful AIs that we think are plausible in the near-term. We find that default methods of choosing values such as “whatever the company wants” poll poorly and we believe this presents a significant near-term and long-term risk. We, moreover, find that reflection procedures such as “think about many possible outcomes, and take the action that the AI believes will have the best societal outcome” poll much better. We believe finding and agreeing on procedures that lead to robustly good values is important for AI safety. We, moreover, think it is important to start on this problem early, as finding robust ways to do this that are computationally competitive seems a non-trivial technical problem and the choice of value generating process we put into AI systems may have interplay with other parts of the technical alignment problem (e.g. some values may be easier to optimize for in a robust way).
0 comments
Comments sorted by top scores.