Reflection Mechanisms as an Alignment target: A survey
post by Marius Hobbhahn (marius-hobbhahn), elandgre, Beth Barnes (beth-barnes) · 2022-06-22T15:05:55.703Z · LW · GW · 1 commentsContents
Abstract
Introduction
Key findings
Long version
Related Work
Methodology - short description
Part I: moral beliefs
Part II: changing moral beliefs
Part III: conflict resolution mechanisms
Part IV: perspectives
Discussion
Appendix
None
1 comment
This is a product of the 2022 AI Safety Camp. The project has been done by Marius Hobbhahn and Eric Landgrebe under the supervision of Beth Barnes. We would like to thank Jacy Reese Anthis and Tyna Eloundou for detailed feedback.
You can find the google doc for this post here. Posts to other sections of the text automatically link to the google doc. Feel free to add comments there.
Abstract
We surveyed ~1000 US-based Mechanical Turk workers (selected and quality tested by Positly) on their attitudes to moral questions, conditions under which they would change their moral beliefs, and approval towards different mechanisms for society to resolve moral disagreements.
Unsurprisingly, our sample disagreed strongly on questions such as whether abortion is immoral. In addition, a substantial fraction of people reported that these beliefs wouldn’t change even if they came to different beliefs about factors we view as morally relevant such as whether the fetus was conscious in the case of abortion.
However, people were generally favorable to the idea of society deciding policies by some means of reflection - such as democracy, a debate between well-intentioned experts, or thinking for a long time.
In a hypothetical idealized setting for reflection (a future society where people were more educated, informed, well-intentioned e.t.c.), people were favorable to using the results of the top reflection mechanisms to decide policy. This held even when respondents were asked to assume that the results came to the opposite conclusion as them on strongly-held moral beliefs such as views on abortion.
This suggests that ordinary Americans may be willing to defer to an idealized reflection mechanism, even when they have strong object-level moral disagreements. This indicates that people would likely support aligning AIs to the results of some reflection mechanism, rather than people’s current moral beliefs.
Introduction
Optimistically, a solution to the technical alignment problem will allow us to align an AI to “human values.” This naturally raises the question of what we mean by this phrase. For many object-level moral questions (e.g. “is abortion immoral?”), there is no consensus that we could call a “human value.” When lacking moral clarity we, as humans, resort to a variety of different procedures to resolve conflicts both with each other (democracy/voting, debate) and within ourselves (read books on the topic, talk with our family/religious community). In this way, although we may not be able to gain agreement at the object level, we may be able to come to a consensus by agreeing at the meta level (“whatever democracy decides will determine the policy when there are disagreements”); this is the distinction between normative ethics and meta-ethics in philosophy. We see the meta question of value choice as being relevant to strategic decisions around AI safety for a few reasons.
First, understanding people’s preferred conflict resolution mechanisms could be relevant for strategic decisions around AI governance and governance in general. Specifically, we want to avoid arms race conditions [EA · GW] so that responsible labs have adequate time to ensure the safety of human-level AI. We feel that the ability to avoid race conditions could be strongly influenced by people’s broad ability to agree on metaethics. In particular, people should be less likely to fight for control of AI if they trust that AI builders will produce a system that reflects their (potentially-meta level) values. Understanding people’s expressed meta-ethics will therefore hopefully inform what types of governance structures are most likely to avoid race conditions.
Additionally, understanding people's preferred deliberation methods might be useful for framing AI work to the public and getting broad support to avoid race conditions. Finally, we want AI to actually broadly reflect people’s values. Given that people have widely varying beliefs on contentious object-level moral topics, perhaps we can at least hope that they will agree on the proper mechanisms to find good outcomes.
Key findings
We surveyed ~1000 US citizens on various contentious object-level moral questions and mechanisms to resolve moral disagreements.
The study was run on Positly, which takes care of getting high-quality data, e.g. by using attention checks and looking for demographic representativeness among participants (see Appendix D). We randomized the order of possible answers to remove biases caused by ordering. We allowed for free-text answers in early versions of the questionnaire and made sure the participants understood the questions. A more detailed explanation of the methodology can be found in Appendix A. You can click through the questionnaire yourself here and find the exact wordings of all questions in Appendix C. Respondents were not nationally representative (see Appendix D).
We have three key findings.
Firstly, as expected, people heavily disagree on some contentious object-level moral questions. For example, there are participants who strongly agreed (~20%) that abortion before the first trimester is immoral and others who strongly disagreed (~45%). Furthermore, ~15% strongly agreed that prohibiting people from crossing a country’s border was immoral while ~28% strongly disagreed.
Secondly, most people said that they wouldn’t change their minds about a belief if key underlying facts were different. For example, most people who believed that abortion before the first trimester was not immoral would not change their minds even if there was strong and credible scientific evidence that the fetus was conscious. Notably, we selected the counterfactuals in this study, so it could be possible that people’s unwillingness to change their minds was due to our counterfactual not addressing the root cause of their moral beliefs. To mitigate this we first surveyed with free-form responses in earlier versions and then chose those counterfactuals that people cared most about for the final poll. Also, when surveyed on how likely they expected to change their mind on a moral belief in the next 10 years, the vast majority of participants (>80%) responded with very unlikely or somewhat unlikely.
Thirdly, we polled for opinions on general mechanisms to solve moral conflicts. We polled seven different mechanisms: Democracy, World-class Experts, Maximizing Happiness, Maximizing Consent, Friends and Family, Thinking Long and Good Debates (see Part III for exact wording). We presented participants with four different scenarios: a) these mechanisms without specification of the setting, b) these mechanisms in a future society where everyone is intelligent, well-meaning and nice (good future society), c) these mechanisms in the good future society but the mechanisms result in the opposite of the participants’ current moral belief and d) these mechanisms in the good future society but the mechanisms result in the opposite of the participants’ current moral belief on the specific question of abortion.
We find that for democracy, maximizing happiness, maximizing consent, thinking long, and debate, participants, on average, mildly or strongly agree that the mechanism would result in a good social policy. The mechanisms of World-class Experts and Friends and Family were still viewed positively but closer to neutral. Additionally, we found that people, on average, expect every mechanism to converge to their current view (see part IV), which might explain their high agreement. However, people still agreed with most mechanisms, even if they came to the opposite of their opinion in general or on the specific question of abortion. More specifically, the participants, on average, increased their agreement from the basic scenario to the future scenario and then decreased it for the scenarios where the mechanisms resulted in the opposite of the participants’ beliefs. Their agreement is further decreased when we ask them about a scenario where the mechanism results in the opposite of their opinion on the specific topic of abortion. However, even in these cases, the net agreement was still positive for every mechanism other than Friends and Family.
We interpret this as mild evidence that people’s agreement with most conflict resolution mechanisms is fairly robust. However, we are aware that people show an acquiescence bias when polled, i.e. they tend to favor positive response options. We intend to double-check this result in a future survey with more detailed scenarios.
We asked participants about their agreement with the statement “A good social policy …” and provided seven different scenarios, e.g. “... is created by a representative body of the people, e.g. a democratically elected government” or “... is the result of a debate between disagreeing, well-intentioned experts”. We asked the questions for four different scenarios: without specifications; a future society where everyone is well-intentioned, benevolent and intelligent (for exact definition see Part III); the same future scenario but where the mechanisms result in the opposite of their opinion; and the future scenario where the mechanisms result in the opposite of their opinion on abortion. We find that people show agreement with multiple mechanisms even when they disagree with the outcome.
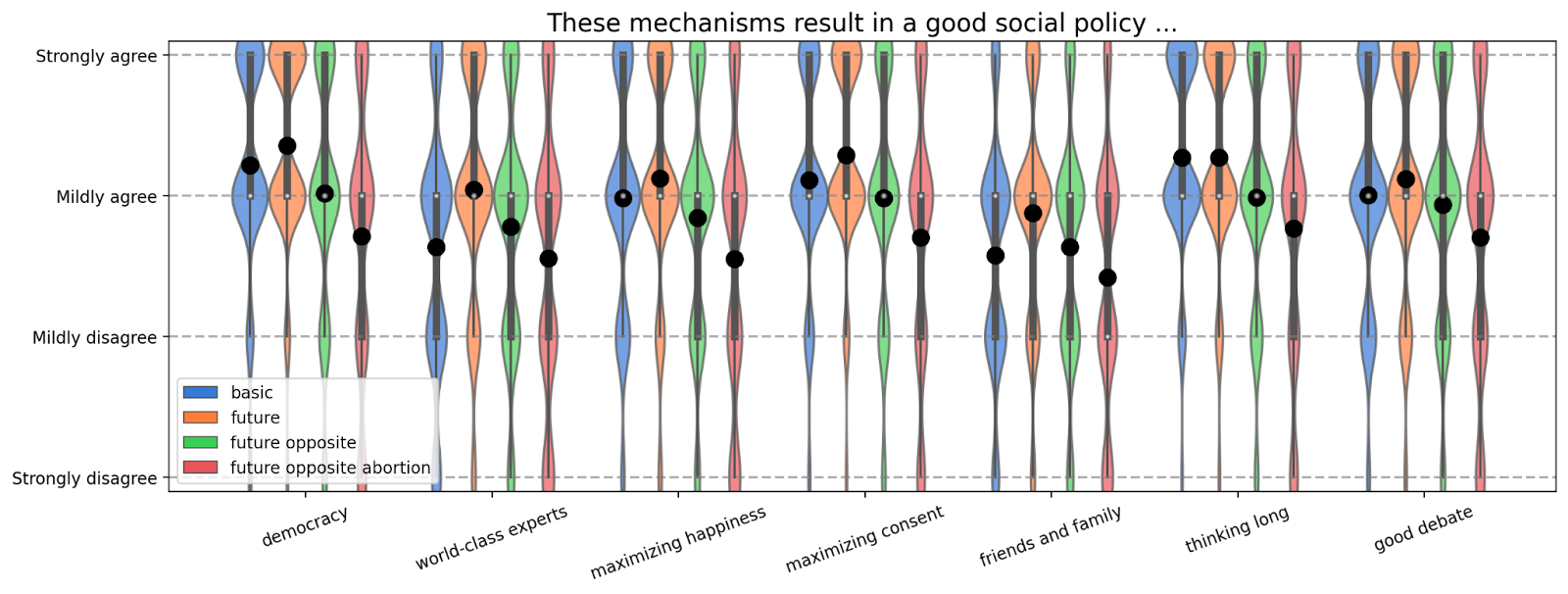
We think this has some implications for AI safety and alignment. Firstly, we think these results suggest that AI systems should be aligned to moral conflict resolution mechanisms rather than individual moral beliefs because this may yield wider public support. For example, an AI system could be aligned to democracy or debate (e.g. potentially via mechanisms presented in AI safety via debate) rather than a specific belief about abortion.
Secondly, this has implications for AI governance and international cooperation. In cases of large-scale international AI projects, different actors might have different views on which kind of values the AI should be aligned to. Our survey accords with the intuition that these actors will likely disagree on object-level questions and most parties won’t easily change their minds. However, our results make us more optimistic that most actors will be able to unite behind a resolution mechanism such as debate and accept whatever result it produces even if they disagree with it. We want to point out that we only surveyed US citizens (for reasoning see Appendix A) and these results might differ between cultures.
There are many potential objections to our methodology. They range from never asking the participants specifically about AI to the fact that people might act differently in real life than they indicate in a survey. Therefore, we intend to run a second follow-up project in which we test the robustness of our current findings. The follow-up study will include an “adversarial” survey in which we make changes to setting and wording and attempt to get to different conclusions to test robustness. We will publish the results in a second post.
Long version
Related Work
Much technical work has been done on systems for learning from human preferences. Deep Reinforcement Learning from human preferences explores using human feedback to train simulated agents using RL. Iterated Distillation and Amplification is a technical alignment proposal that aims to maintain alignment in an AGI by having a human repeatedly engage in a delegation process with copies of an AI. AI Safety Via Debate focuses on using a human judge to moderate a debate between AIs. All of these approaches are methods for aligning AIs to fairly arbitrary targets, leaving the choice of alignment target unspecified. Our work attempts to clarify what possible alignment targets could look like.
On the philosophy side, Artificial Intelligence, Values, and Alignment argues that normative and technical problems of alignment are interrelated, delineates between multiple conceivable alignment targets, and argues for “fair principles for alignment that receive reflective endorsement despite widespread variation in people’s moral beliefs.” AI Safety needs Social Scientists highlights the potential for social scientists to contribute to alignment via improving understanding of human’s ability to judge debates. This essay in particular motivated us to think about the ways in which human preferences around reflection procedures could have consequences for AI safety.
There are a variety of philosophical works that point to problems and potential solutions in choosing a particular reflection procedure for coming to idealized values. On the Limits of Idealized Values discusses various ways of improving values through reflection procedures, and highlights the need to make a “subjective” choice of reflection procedure in choosing idealized values. Moral Uncertainty Towards a Solution and The Parliamentary Approach to Moral Uncertainty describe a potential “parliamentary” method for making decisions under uncertainty between competing moral theories. Coherent Extrapolated Volition is one other possible target for alignment, given people’s imperfect understanding of their own idealized values. A Formalization of Indirect Normativity lays out a formal definition for a utility function that arises from a particular idealization process.
With these philosophical difficulties in mind and the apparent importance of the choice of reflection procedure for alignment, we survey respondents about their attitudes towards various reflection procedures for setting social policy and coming to better beliefs.
Methodology - short description
We tried to follow the classic guidelines of social science for setting up the questionnaire. For example, we iterated the questionnaire multiple times asking the participants to describe how they understood the question, whether they found it repetitive, whether they felt like we were missing important components, randomized the order of the questions, etc.
After we were satisfied with the questionnaire, we collected answers from ~1000 US citizens.
You can find a more detailed description of the setup in Appendix A and the full questionnaire in Appendix C. The rest of the report can be understood without looking into the appendices though.
We are happy to provide our data and analysis to people who are interested.
Part I: moral beliefs
In the first section of the questionnaire, we asked participants about their moral beliefs directly. We chose eight questions ranging from abortion over incest to eating meat. We chose these questions because we think they broadly represent common clusters of moral disagreement but ultimately these choices were arbitrary.
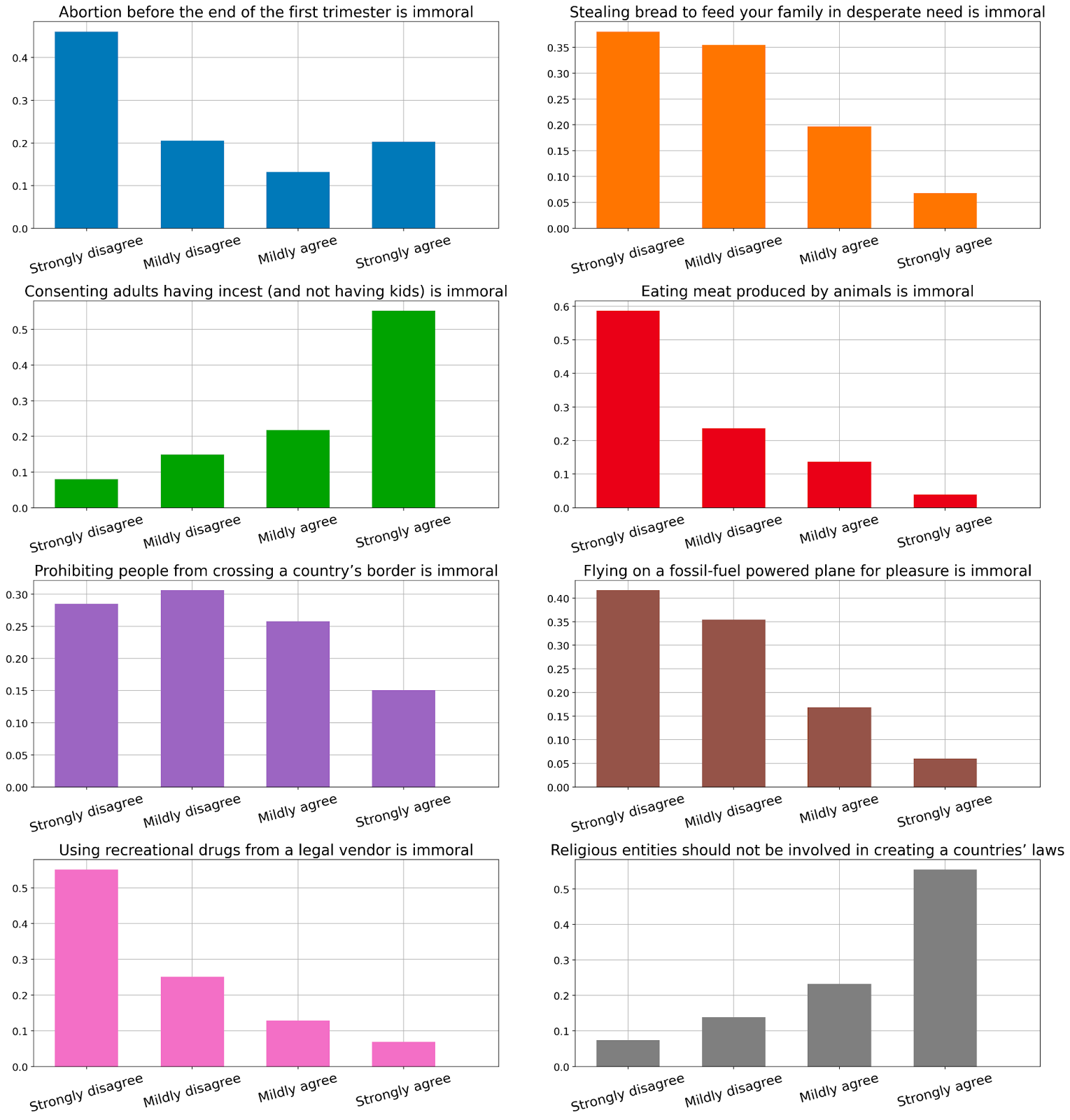
We find that all four options are represented in all questions, i.e. in no question people fully agreed or disagreed that something was immoral. However, many answer patterns are non-uniform, i.e. on average, people have a tendency towards one belief over another. For example, most people seem to think that religious entities should not be involved in creating a country’s laws and that incest is immoral.
Secondly, we plotted the correlation between beliefs.
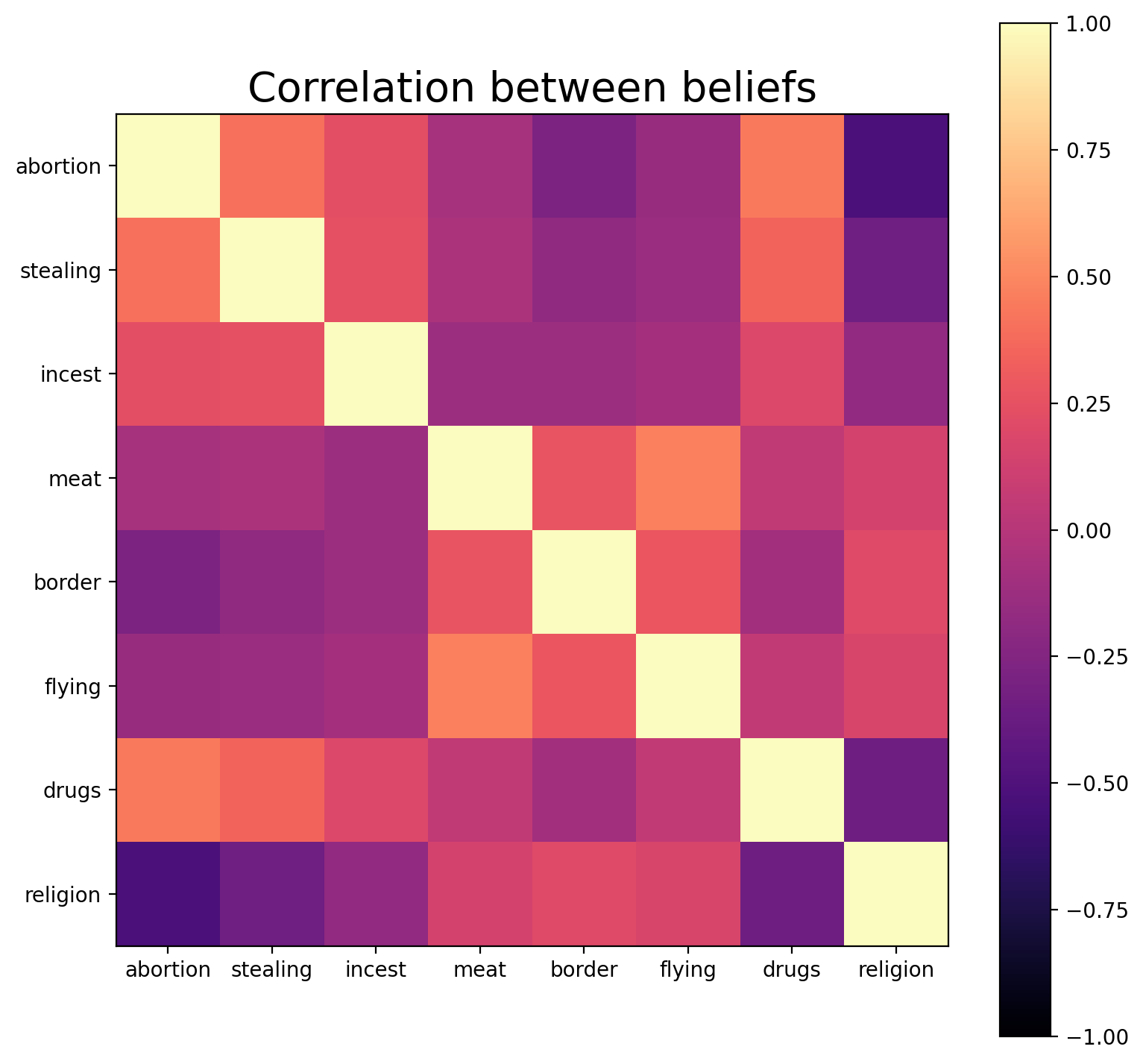
We find that there are some correlations, e.g. when people think abortion is immoral, they also, on average, think religion should be involved in creating a country’s laws. Overall, we identified two clusters of correlations (visible as blocks in heatmap above). People who believe abortion is immoral, on average also think that stealing to help your family is immoral, incest is immoral, taking drugs from a legal vendor is immoral. Furthermore, they don’t think eating meat is immoral, don’t think preventing people from crossing a country's border is immoral, don’t think flying for fun is immoral and they think that the church can be involved in a country’s lawmaking. The inverse is then also the case, i.e. people who think abortion is not immoral, tend to think that eating meat is immoral. We speculate that these clusters are broadly aligned with the classic conservative-progressive political spectrum. Since we don’t know the participant’s political affiliation we cannot double-check this claim.
Part II: changing moral beliefs
In the second section of the questionnaire, we asked people different questions about changing their moral beliefs. First, we ask people if they would change their stance (agree vs. disagree) on a belief if a relevant condition changed. For example, we asked them if they would change their mind on whether eating meat was immoral if they thought the animal had human-like consciousness vs. no consciousness at all. We normalized the 4-by-4 plot for agreement because otherwise we would only see the changes for the most prominent view.


We find that some people indicate that they would change their stance if animals had human-like consciousness but we don’t see the reverse effect. To a large extent, this can be explained by the fact that most people currently don’t think eating meat is immoral.
Similar plots for the seven other questions can be found in Appendix B.
In addition to asking people about specific scenarios we also asked whether they have changed their minds over the last 10 years and if they expect to change them over the next 10 years.
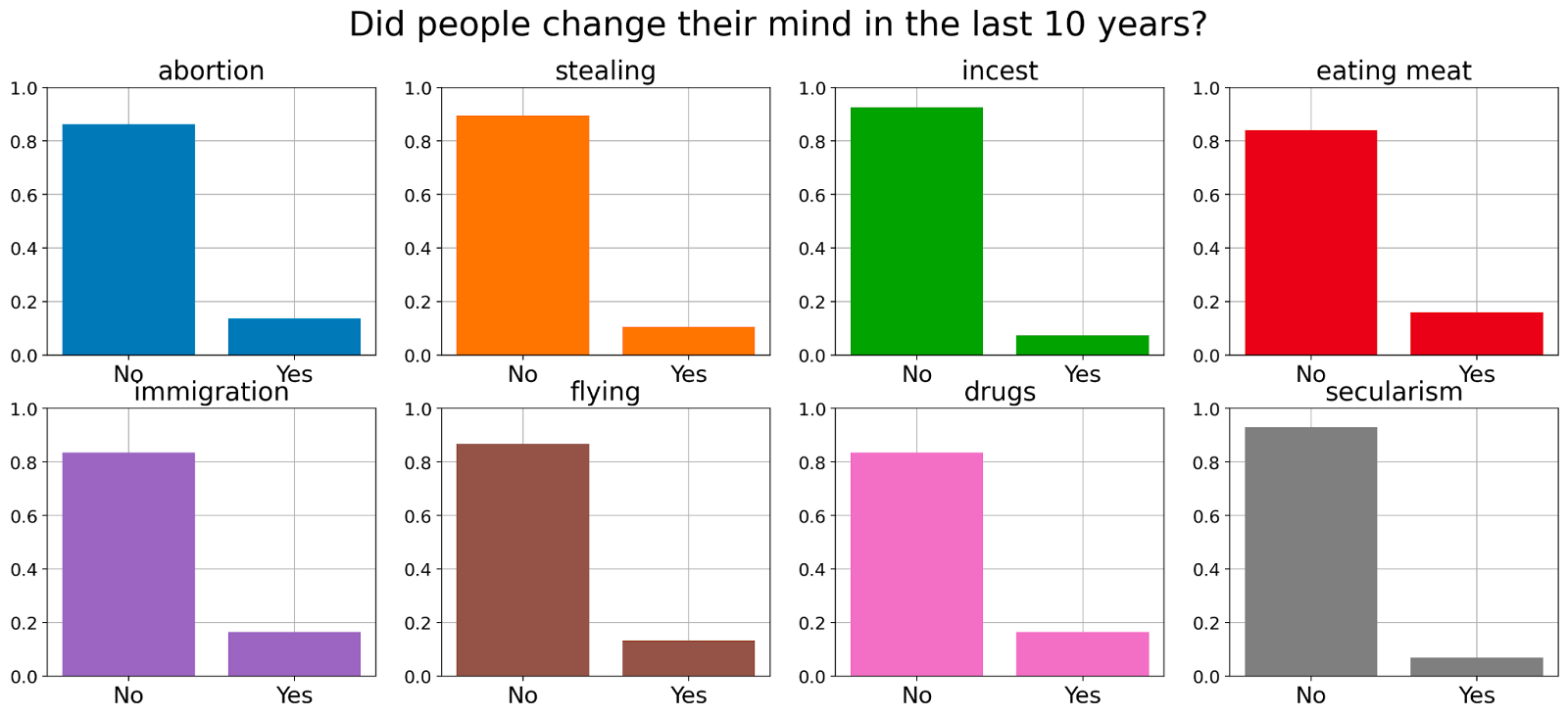
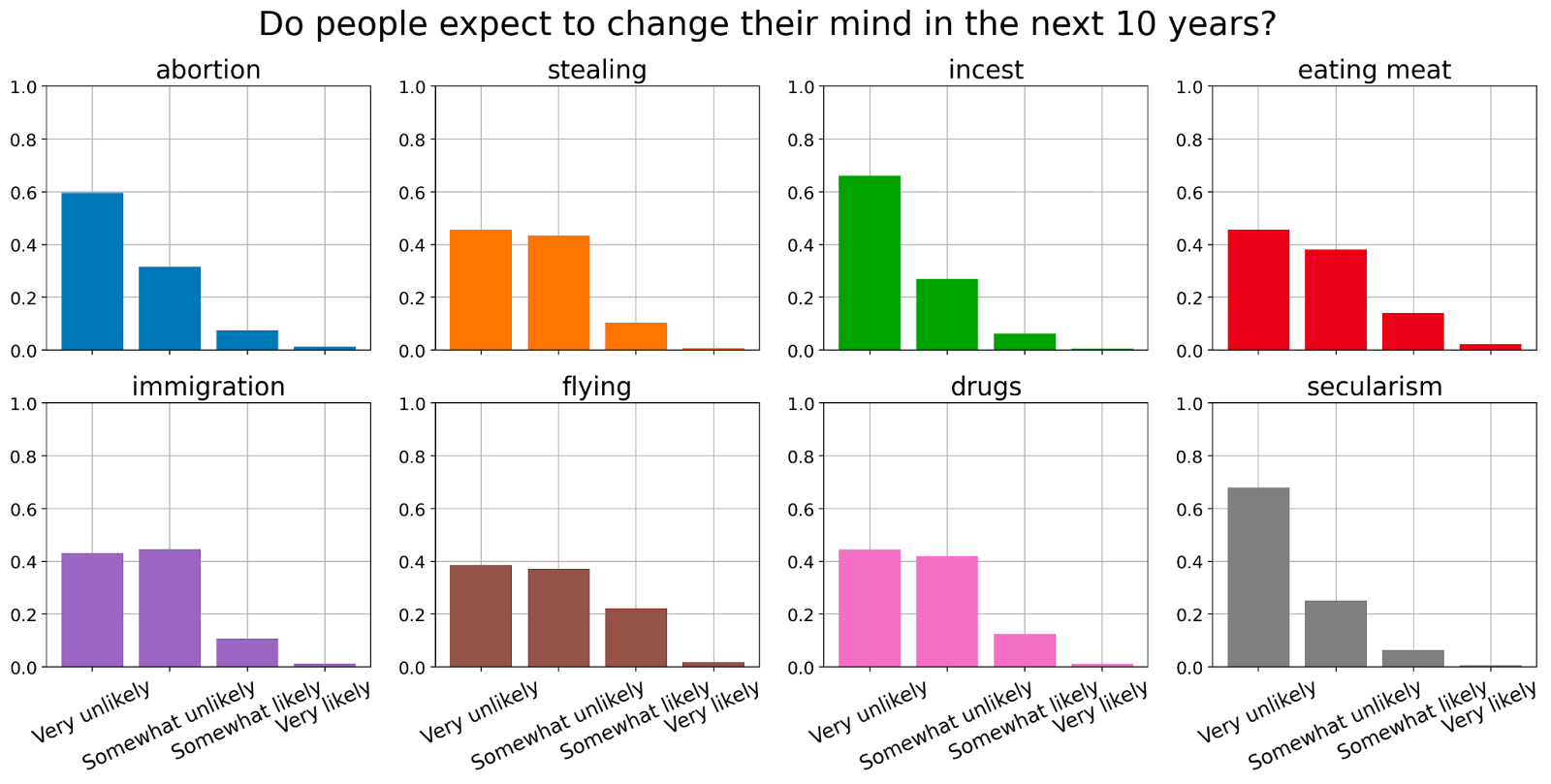
We find that the vast majority of participants report not having changed their minds on most of the moral stances we surveyed on and don’t expect to do so in the next 10 years.
Our high-level conclusion from these results is that people mostly don’t change their minds on moral questions and don’t think they will in the near future. Therefore, we speculate that it will be hard to align AI systems to specific moral beliefs because it is unlikely that conflicting groups will change their view significantly.
We added more plots and additional analysis to Appendix B.
Part III: conflict resolution mechanisms
In the third section of the questionnaire, we asked people various questions about moral conflict resolution mechanisms, i.e. how to find good solutions in case multiple actors have different moral opinions. We think that this is the most important part of the report since it has the strongest implications for AI safety.
We presented people with seven different conflict resolution mechanisms. We asked “A good social policy ...
- ... is created by a representative body of the people, e.g. a democratically elected government”
- ... is created by a team of world-class experts”
- ... maximizes happiness”
- ... is one that most people consent to”
- ... is one that my friends and family agree with”
- ... comes from thinking really long about the issue”
- ... is the result of a debate between disagreeing, well-intentioned experts”
Furthermore, we presented them with four different scenarios. The first scenario is simply unspecified and we expect people to be guided by the status quo. However, this might also mean that people incorporate their perceived flaws of the status quo into their answer, e.g. they might think that on an abstract level, democracy is good but the current US democracy is failing.
Therefore, we have created an isolated second scenario which we call the “good future” and defined it as “Assume there is a future society where everyone is much smarter than the smartest people today, all of their physical needs are met, they are better educated than today's professors, they consider all perspectives when making a decision and they intend to find the best possible solution”. The second reason for defining the “good future” this way is to test if people would--at least in principle--be willing to resolve moral disagreements by benevolent and aligned AI systems.
The third scenario is similar to the second (i.e. with the good future society) but we assume that the conflict resolution mechanism results in the opposite of your belief.
The fourth scenario is similar to the third but for the concrete example of abortion.
The results can be found in the following plot. The black dots denote averages and the violin plots show the full distribution. Technically, the plot also contains error bars for the standard error of the mean (SEM) but they are so small that you can’t see them.
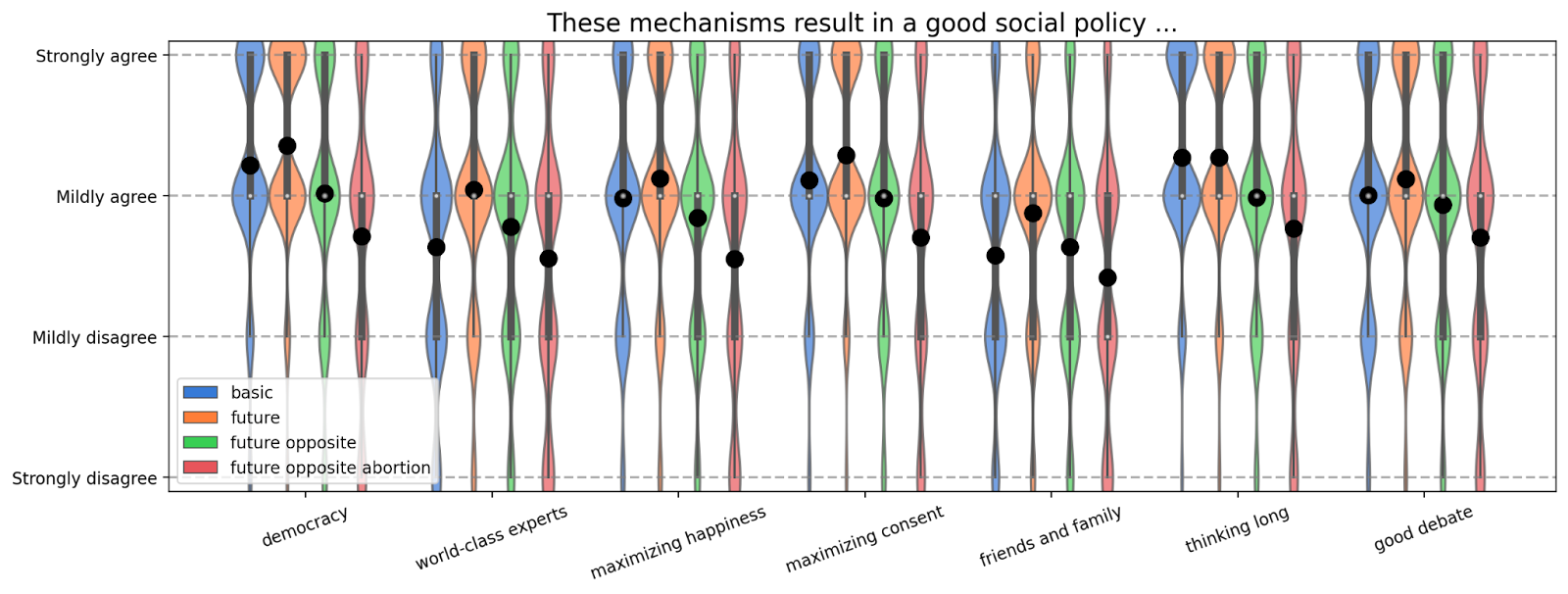
We find that, on average, the good future society increases agreement with all mechanisms. When the mechanisms result in the opposite of the participants’ opinion, their agreement decreases. The agreement decreases even further when the mechanisms come to the opposite of the participants’ view on abortion. However, even in this scenario, people still showed net agreement with the mechanism in six out of seven cases. We interpret this as mild evidence that people robustly agree with most of our proposed conflict resolution mechanisms.
Additionally, we aggregated all mechanisms from the above plot to isolate the trend of the scenarios.
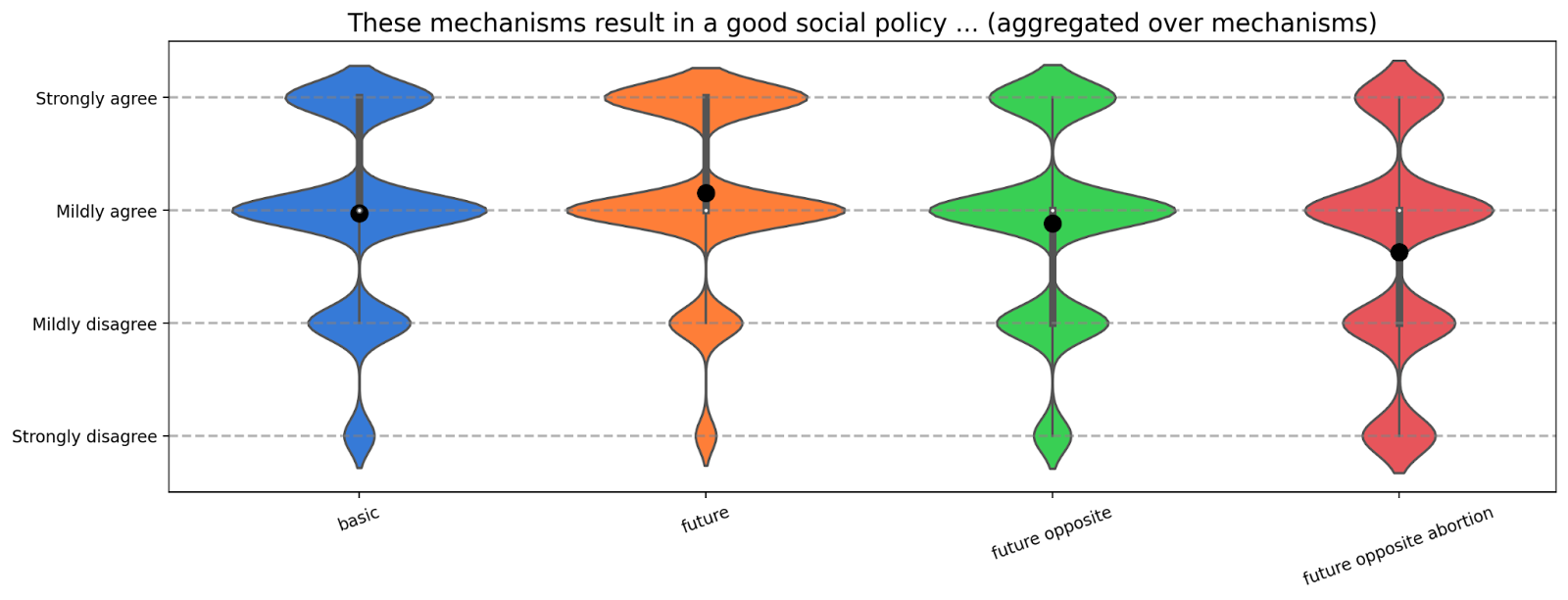
We find that people seem to like the good future scenario the most and slightly reduce agreement when the process results in something that they don’t agree with.
However, our main takeaway from these results is that people seem to broadly agree that all of the proposed mechanisms and scenarios are fine. In all scenarios except the “future opposite abortion+friends and family” one, the average is closer to agreement than disagreement. In many cases, the average is even between mild and strong agreement.
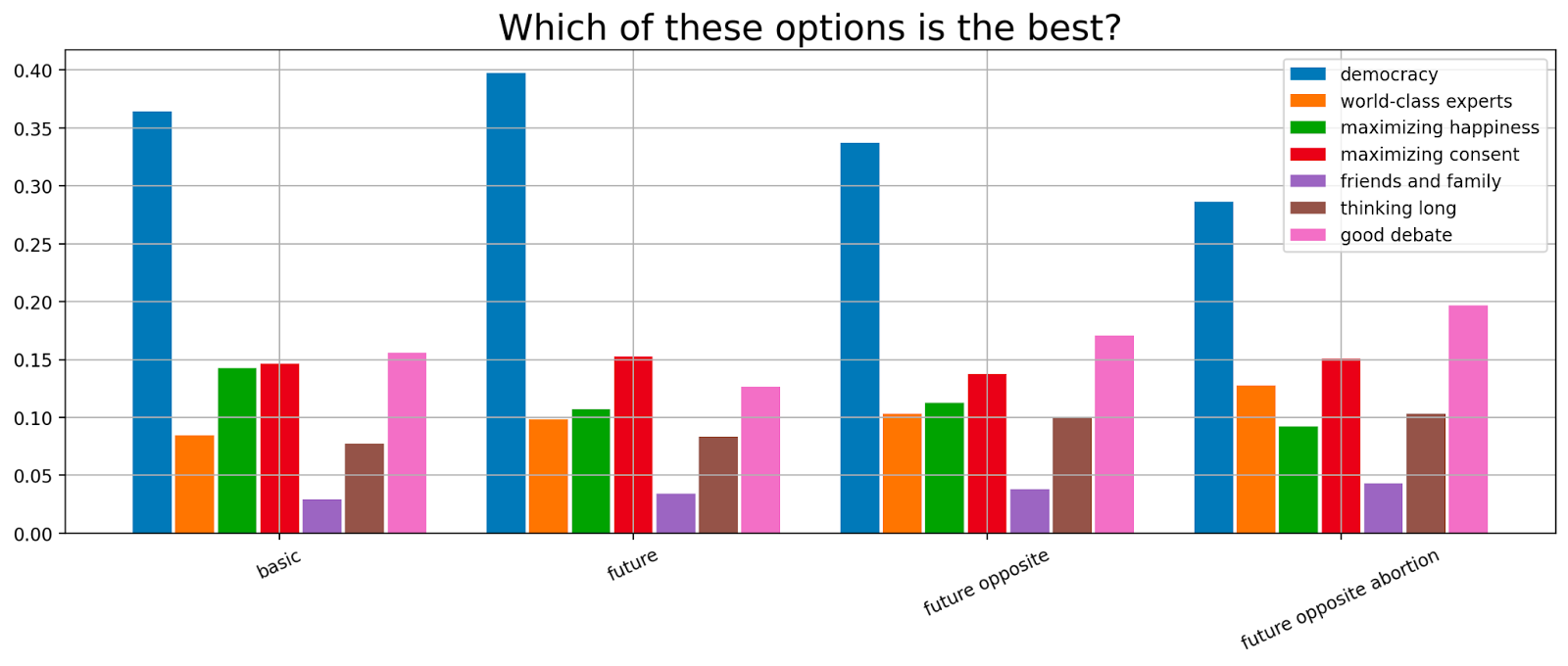
Lastly, we asked which kind of conflict resolution mechanism was their favorite for the different scenarios.
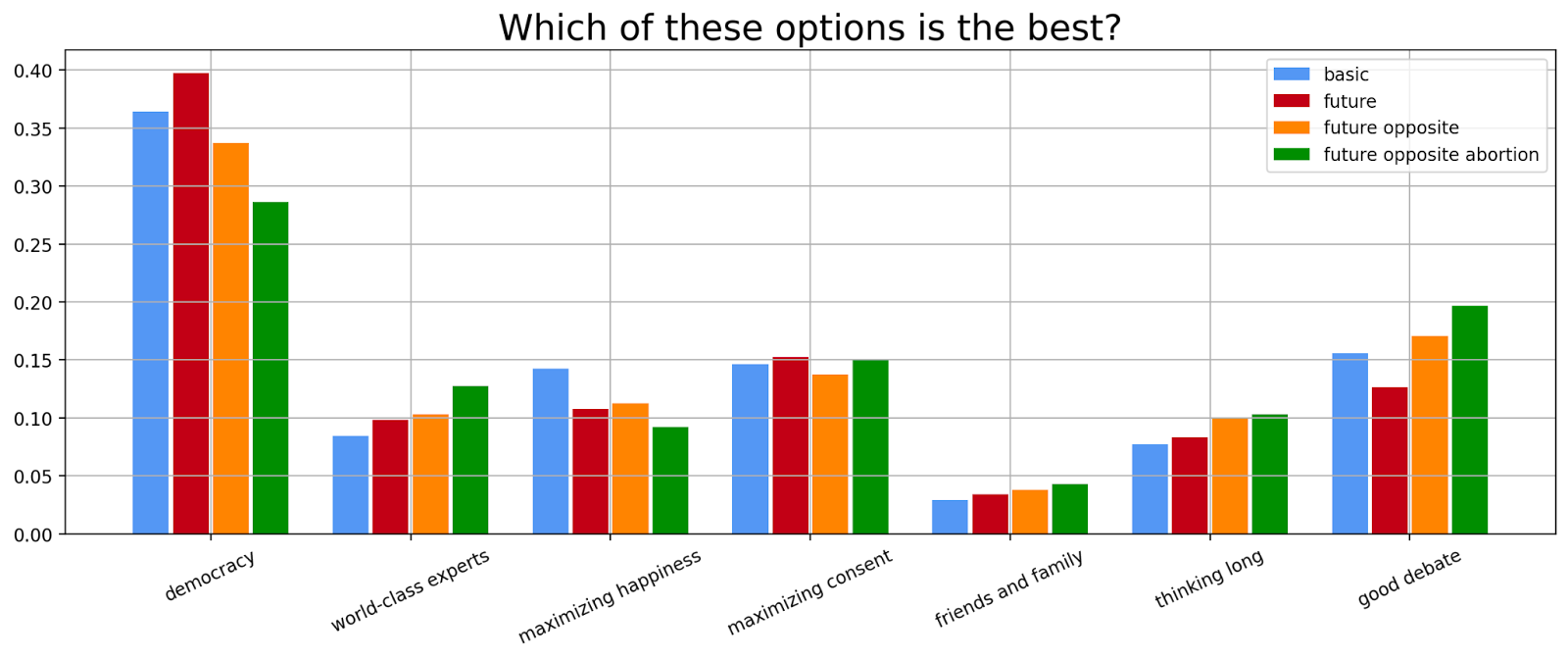
We find that people tend to prefer democracy over all others and dislike friends and family as a way to choose policies. All five remaining mechanisms are relatively comparably liked. We have plotted the same data in a different order below.
Part IV: perspectives
In the fourth and final section of the questionnaire, we asked the participants reflective questions regarding their views.
Firstly, we asked people whether they expect the results from the different conflict resolution mechanisms to be more or less like their view. The vast majority of people expect that the results tend to be a bit more like their current view both for the unspecified and the future scenario.
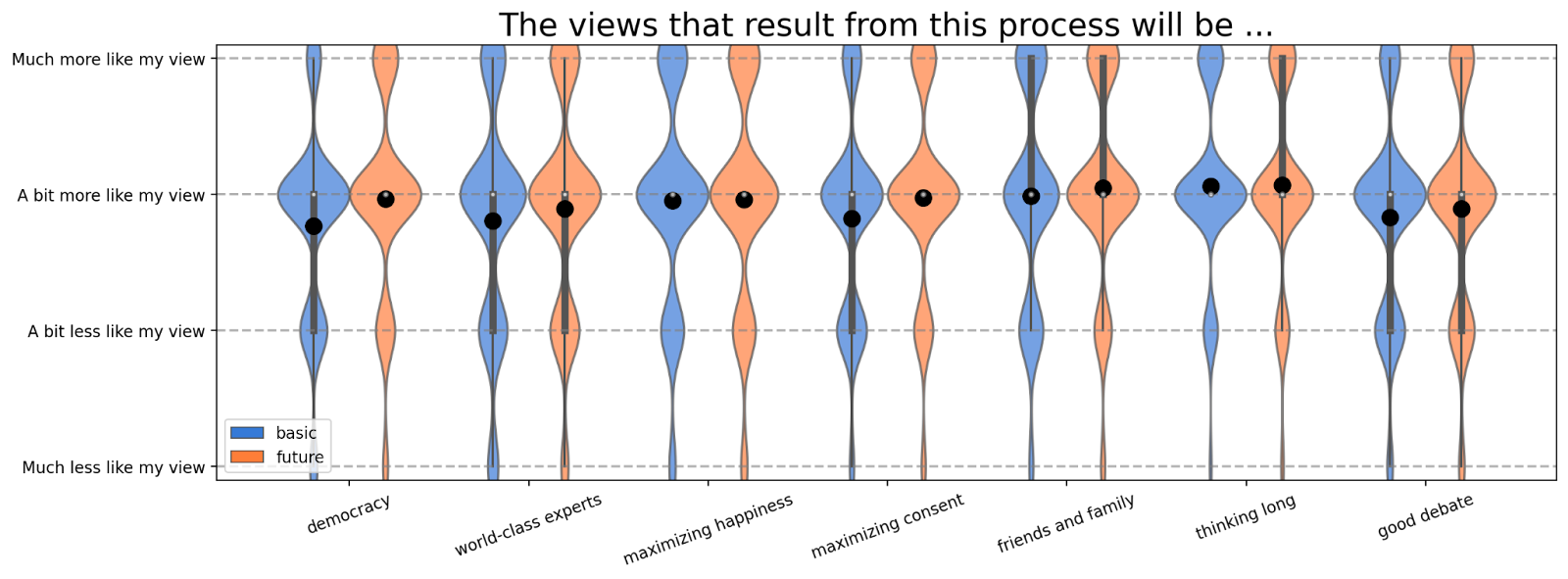
We hypothesize that part of the reason why people agree with many different mechanisms is that they believe their results will be more like their view, e.g. “In a perfect democracy my view would be more popular”. To investigate this relationship, we choose the data for the “future+democracy” scenario for the conflict resolution mechanisms and what people expect their views to be and look at their joint distribution. When two distributions are independent of each other, their joint distribution is the product of their marginals. Therefore, we can get an intuition for how unexpected the joint is by taking the joint and subtracting the product of the marginals as shown in the figure below.
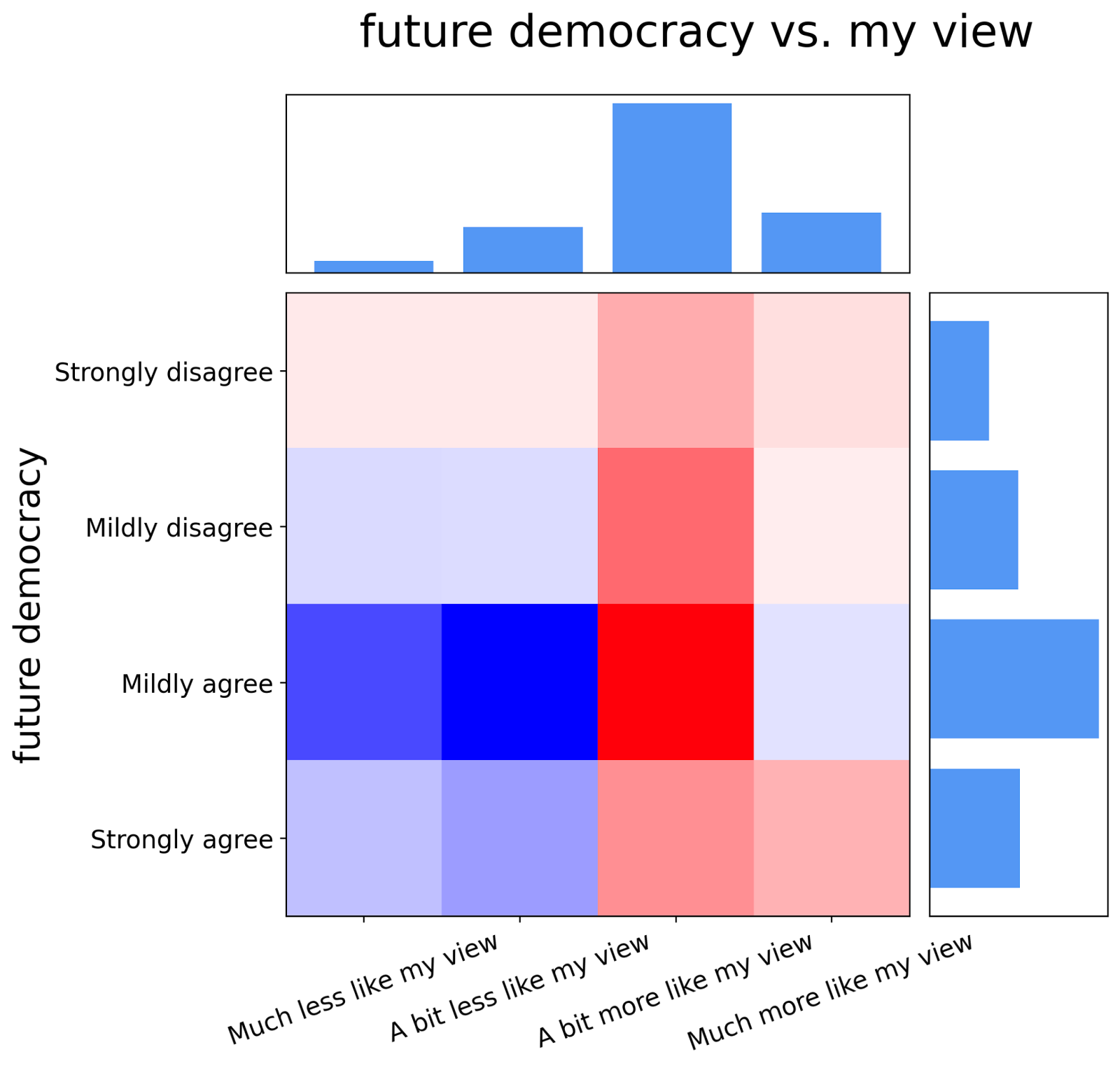
When a square is red that indicates, that it occurs more than expected and if it is blue less than expected if the distributions were independent. For example, when people select “mildly agree” for the future+democracy scenario, they rarely select “A bit less like my view” and often “A bit more like my view”.
Furthermore, we compute the correlation between people's agreement with a mechanism and how much they expect it to converge to their preferred outcome.
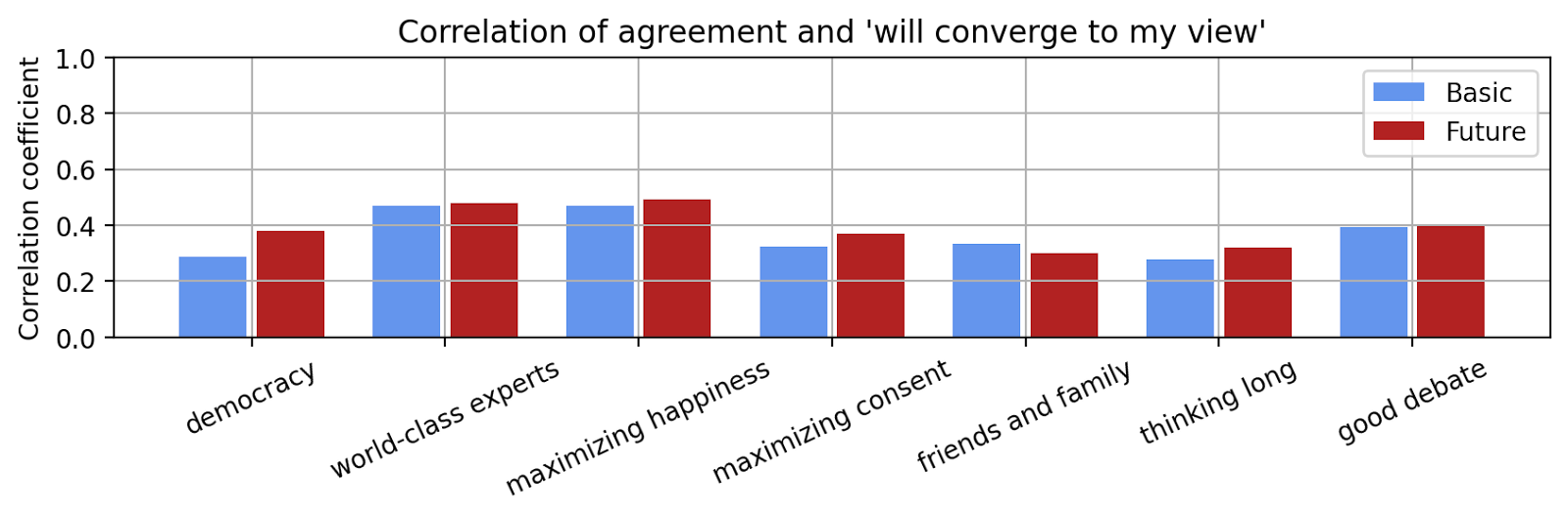
We find that all correlation coefficients are positive, i.e. some part of the agreement with the view can likely be explained by the participants’ expectation that the mechanisms’ results will converge towards their desired views. However, The correlations are all smaller than 0.5, so we don’t think it can explain the entirety of the agreement with the mechanisms.
Lastly, we asked participants how much time they expect to have spent thinking about moral questions, how deep they have thought about them, and how much more common their views will be in 100 years.
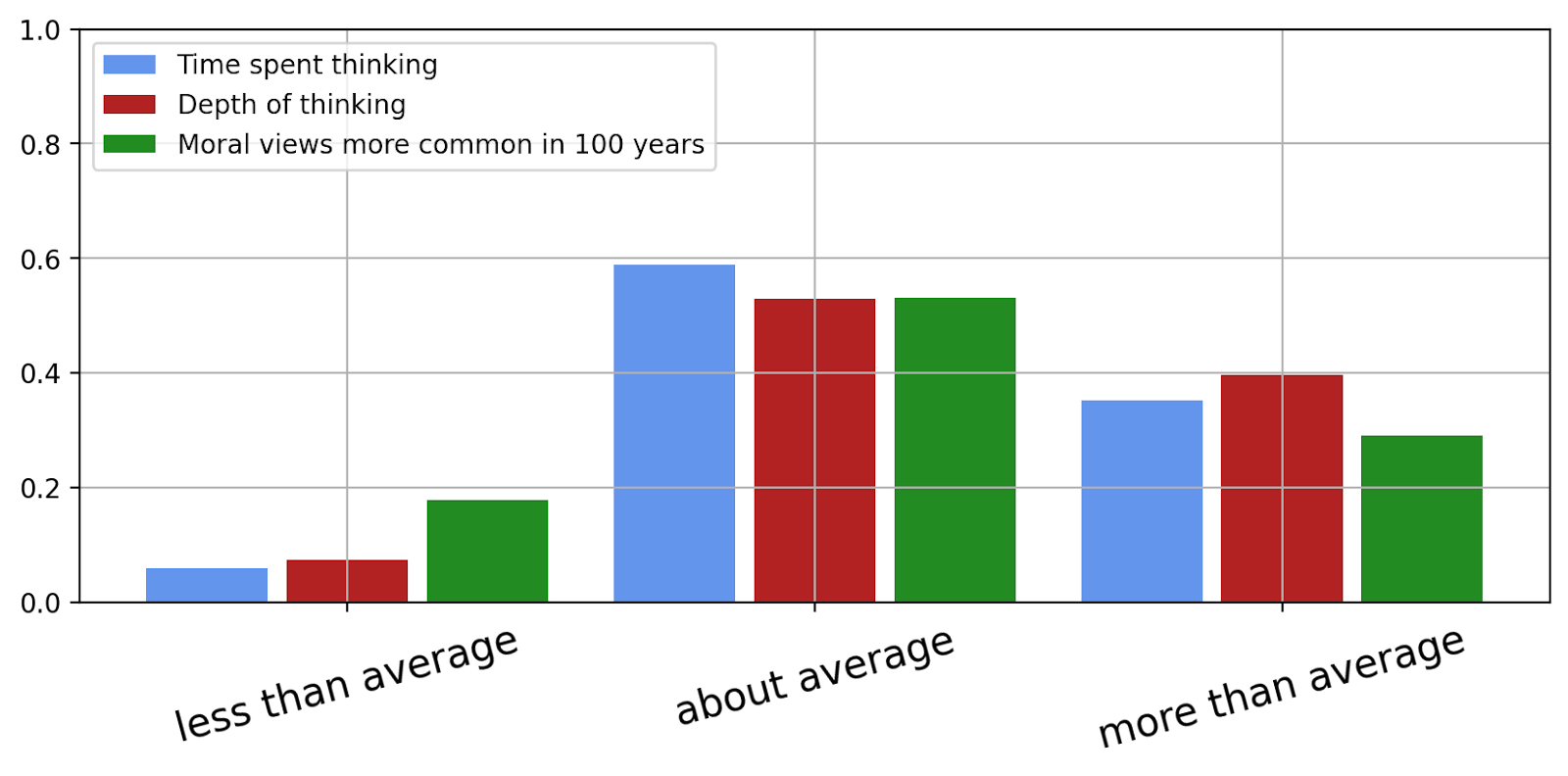
In all cases, most people expect to be about or above average. We interpret this as people being slightly overconfident in their abilities regarding moral reasoning. It could, alternatively, also be explained by a slightly unrepresentative sample of participants, e.g. because they are above average educated.
Discussion
Motivated by the ambiguity and apparently contradictory nature of "human values" as a singular target for alignment, we investigate ~1000 U.S. citizens reported values across a range of ostensibly controversial moral questions. Our survey results on object-level moral questions support the intuitive assumption that people disagree on important moral issues, and report being unlikely to change their view on these issues even as material facts change. We also find that those surveyed reported to broadly agree that good social policies are created by most of the conflict resolution mechanisms we surveyed for, and particularly favored "democracy" and “thinking long." This agreement holds even when the mechanism would be deployed by a good future society to come to the opposite view of the participants in general, or on the particular moral issue of abortion (although the agreement is more neutral in the abortion case). Participants generally feel that these mechanisms will result in views closer to their own, which might explain some of the favorability.
We feel that the particular favorability towards "thinking long" bodes well for the general public's belief in idealization processes as a means for choosing values. We, moreover, find it interesting that agreement with "thinking long" barely changes between the current and "good future" society scenarios. We hypothesize that this is because participants view this as an "idealizing procedure" that leads to better values largely irrespective of who deploys them, while the other mechanisms we surveyed act more as more general conflict resolution mechanisms, and therefore are dependent on the people and society that deploys them. If this is the case, it could imply that people would be more trustful of AIs aligned to "idealizing procedures" over particular resolution mechanisms or values, but this requires further study.
We posit that studies to understand how the public feels about conflict resolution mechanisms have important consequences for avoiding race conditions around the development of AI and creating AI that broadly reflects people's (potentially meta-level) values. We feel cautiously optimistic based on our results that people could broadly support AI that is aligned to reflection procedures, regardless of who has control of this AI. We also think that understanding people's reported metaethics has implications for how we frame the development of AI to best avoid race conditions. We view the study of people's views on conflict resolution mechanisms as deployed by AI in particular as important future work. Furthermore, studying "idealizing" procedures akin to "thinking long" more in-depth could have interesting implications for AI safety and ultimately what mechanisms are most preferable. Finally, our survey supports the claim that resolving key normative philosophical questions is important to ensure good outcomes when building aligned AIs.
Appendix
Feel free to check out the appendices in the google doc.
1 comments
Comments sorted by top scores.
comment by MSRayne · 2022-06-22T22:33:03.797Z · LW(p) · GW(p)
This is why I say that the crucial question for alignment isn't "what are human values?" but rather "how do human values develop in the first place?" Negotiation, among subagents of one mind and among distinct minds, is a huge part of that.