The silos of expertise: beyond heuristics and biases
post by Stuart_Armstrong · 2014-06-26T13:13:45.385Z · LW · GW · Legacy · 16 commentsContents
Separate silos of expertise Combining expert opinion When is a bias not bad? Option choosing Situation matching Recognition-primed decision making When RPD works, when it doesn't Further reading None 16 comments
Separate silos of expertise
I've been doing a lot of work on expertise recently, on the issue of measuring it and assessing it. The academic research out there is fascinating, though rather messy. Like many areas in the social sciences, it often suffers from small samples and overgeneralising from narrow examples. More disturbingly, the research projects seems to be grouped into various "silos" that don't communicate much with each other, each silo continuing on their own pet projects.
The main four silos I've identified are:

There may be more silos than this - many people working in expertise studies haven't heard of all of these (for instance, I was ignorant of Cooke's research until it was pointed out to me by someone who hadn't heard of Shanteau or Klein). The division into silos isn't perfect; Shanteau, for instance, has addressed the biases literature at least once (Shanteau, James. "Decision making by experts: The GNAHM effect." Decision Science and Technology. Springer US, 1999. 105-130), Kahneman and Klein have authored a paper together (Kahneman, Daniel, and Gary Klein. "Conditions for intuitive expertise: a failure to disagree." American Psychologist 64.6 (2009): 515). But in general the mutual ignoring (or mutual ignorance) seems pretty strong between the silos.
Less Wrongers are probably very familiar with the heuristics and biases approach, so that doesn't need to be rehashed here. Shanteau's silo mainly revolves around estimating when experts are true experts, concluding that the nature of the task attempted is key (see this table for the characteristics of tasks conducive to genuine expertise), and coming up with some indirect measures of expert performance in fields where an objective standard isn't available (Shanteau, James, et al. "Performance-based assessment of expertise: How to decide if someone is an expert or not." European Journal of Operational Research 136.2 (2002): 253-263).
This post will therefore be looking at the last two silos, first at combining expert opinions, and then at the methods that some true experts use to reach decisions. That last silo is of particular interest to Less Wrong, as it contradicts many of the common "biases must be bad" ideas.
Combining expert opinion
Suppose you have a population potentially at risk from an erupting volcano (Aspinall W. & Cooke R.M. 1998. Expert judgement and the Montserrat Volcano eruption. In: Mosleh, Ali & Bari, Robert A. (eds) Proceedings of the 4th International Conference on Probabilistic Safety Assessment and Management PSAM4, September 13th -18th, 1998, New York City, USA. Springer, 2113-2118). As a policy maker, you have to decide what to do about this. So you consult a group of experts, and - BOOM - they give you different predictions. Some involve mass immediate evacuations, some involve waiting and seeing. Some experts are more confident of their judgement that others; some seem more competent, some more respected. What should you do?
Cooke (Cooke, Roger M., and Louis H. J. Goossens. "Expert judgement elicitation for risk assessments of critical infrastructures." Journal of Risk Research 7.6 (2004): 643-656) suggested getting each expert to report a probability distribution Fi, and combining them in a weighted sum to get the final estimate Fc (this is sometimes called the "Delft procedure"). The question is what weights to use; he suggested to score each expert's ability and then to combine the estimates using this score as a weight.
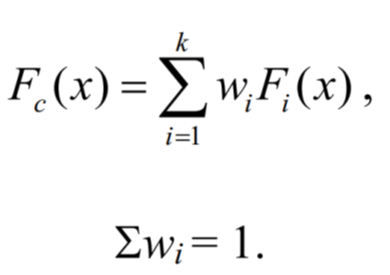
To get the ability score, the experts were given test examples from previous incidents whose outcomes were known, and had to give probability distributions on what they predicted would happen. These distributions were scored according to the product of their calibration (eg whether expert predictions with 90% confidence would actually be true 90% of the time) and their informativeness (how informative their estimate is, as compared with a generic estimate - this is estimated using informational entropy). The idea is that though it is easy to optimise calibration or informativeness separately (everything gets 50% probability versus everything gets 0% or 100%, roughly), only a genuine expert can score high on both. In practice, calibration is somewhat more important in the product as defined, as it can vary by four or more order of magnitude between experts, while informativeness seldom varies by more than three (Aspinall, W. P. "Structured elicitation of expert judgement for probabilistic hazard and risk assessment in volcanic eruptions." Statistics in volcanology 1 (2006): 15-30).
Since experts tend to be experts in narrow domains only (Weiss, David J., and James Shanteau. "Decloaking the privileged expert." Journal of Management and Organization 18 (2012): 300-310), the methods can also be used in a more fine-grained way, if more detailed scoring questions are available. Then experts are given, not a general score, but a domain score on different items of interest to the general predictions (eg one expert might be good at the probability of eruption, another at its likely destructiveness if it does erupt). The probability distributions for each item are then combined in the same way as above.
There are other ways of combining expert opinions. Roger George suggests ways of getting the best performance out of teams of intelligence experts (George, Roger Z. "Fixing the problem of analytical mind-sets: Alternative analysis." International Journal of Intelligence and Counterintelligence 17.3 (2004)), while Barabara Mellers and others suggest that for geopolitical predictions, performance could be improved by training the experts (in scenarios and in probability), by grouping them into teams, and by tracking the best experts from one prediction to the next (Mellers, Barbara, et al. "Psychological strategies for winning a geopolitical forecasting tournament." Psychological science 25.5 (2014): 1106-1115).
When is a bias not bad?
The results of the combining expertise literature might be relatively unknown on Less Wrong, but nothing in it suggests anything radically surprising. Not so the work of Klein and others on Naturalistic Decision Making (Lipshitz, Raanan, et al. "Taking stock of naturalistic decision making." Journal of Behavioral Decision Making 14.5 (2001): 331-352). This analyses the behaviour of experts who would be extremely biased by any objective measure, but who can still perform much better than "classical" decision-makers. Just as a biased estimator can sometimes be statistically better than an unbiased one, a biased expert can outperform an unbiased one. Indeed, this approach doesn't see biases in the negative way we tend to. The availability heuristic seems a bad bias for us, but it can also be a way for an expert to reach very rapid decisions in situations they face repeatedly.
Naturalistic decision making (NDM) seeks to describe how actual experts (firefighters being a standard example) reach decisions. It is so different from classical decision making (CDM), that it's almost a new way of thinking. The main differences are given in this table (terminology changed slightly from the original paper):
| CDM | NDM |
|---|---|
|
Universal Ignores expertise Comprehensive modelling
Backwards-chained from outcome "Ideal" prescriptions Option choosing |
Specific Models expertise Contextual modelling
Forwards-chained decision process Empirical prescriptions Situation matching |
CDM is universal: it considers the situation in the abstract, and would reach the same decision in any situation if the model were the same. If selling bread or invading Russia were similar in the abstract sense, CDM would model their decisions exactly the same way. NDM, however, thinks of them as very separate situations, to be analysed using different tools. This is mainly because CDM ignores expertise (it matters not if the decision maker is an "expert", it matters what they decide) while NDM is all about modelling the actual process of expertise (and generals and bakers are likely to have very different processes). CDM goes through a comprehensive modelling of all options and all possibilities, while NDM can use simpler models, including context dependent ones. CDM is backwards-chained from the outcome: the ideal decision is calculated, and then the steps of the decision made are analysed from that perspective. NDM is forwards-chained: the decision is followed forwards from step to step, seeking to understand the cognitive processes of the decider. CDM gives "ideal prescriptions" (eg in order to better reach the best decision in this model, correct bias X) while NDM - having no ideal outcome to work back from - is limited to empirical prescriptions of what processes seem to work better in certain specific situations.
The last point - the difference between option choosing and situation matching - is the key contrast between the two decision making processes, and will be described in the next section. The most important difference is that NDM almost never compares two options directly.
Recognition-primed decision making
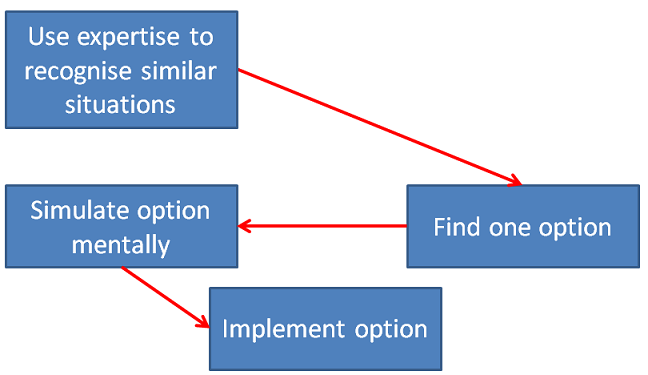
Classical decision making is all about option choosing: here are your options, estimate (or calculate) which of them is best, comparing them to each other on some scale. But naturalistic decision making is all about situation matching: recognising which situation the expert finds themselves in. Once they properly recognise the situation, the proper subgoals and courses of action suggest themselves immediately. A model for this is recognition-primed decision making (Klein, Gary A. A recognition-primed decision (RPD) model of rapid decision making. Ablex Publishing Corporation, 1993).
For instance, upon arriving at a fire, the lead firefighter may assess the problem as a vertical shaft fire in a laundry chute, just getting underway. This situation assessment included plausible goals (believing there was time to put it out before it got out of control), critical cues (needing to find out how far the fire had spread up the shaft), expectancies (believing that the firefighters could get above the fire in time to put it out), and an obvious course of action (sending teams with hoses up to the first and second floors). As soon as they recognised what kind of fire they were dealing wit, the lead firefighter would think of these options immediately.
The way that the right course of action springs to mind immediately is similar to the way that chess experts instinctively generate a good option as their first intuitive guess when looking at a chess position (Klein, Gary, et al. "Characteristics of skilled option generation in chess." Organizational Behavior and Human Decision Processes 62.1 (1995): 63-69).
Does the expert do some assessment on that first option? Yes, they do. It seems that they use their imagination to project that option forwards, using their expertise to spin a story as to what might happen. If that story is acceptable, they implement the option. Schematically, it can look like this:
What about further complications? What if the one option isn't good, if the expert can't recognise the situation, if they get extra information later on?
For extra information, the decision process works in exactly the same way: the expert attempts to update their mental image of the situation, to recognise more precisely what the true situation is like (eg, if they see smoke coming up from under the eves, the lead firefighter now believes the fire has spread up to the fourth floor - a different situation, calling for a different intervention). If they fail to recognise the situation instinctively, a fascinating process commences: the expert attempts to build a mental story, compatible with their expertise, that explains all the data. Once they have a satisfactory mental story, they then proceed as before.
In the rare case where their top option doesn't seem to be acceptable, the expert uses their expertise to generate another option, and then proceeds to simulate that option to check that it is effective. The whole process can be schematically seen as:
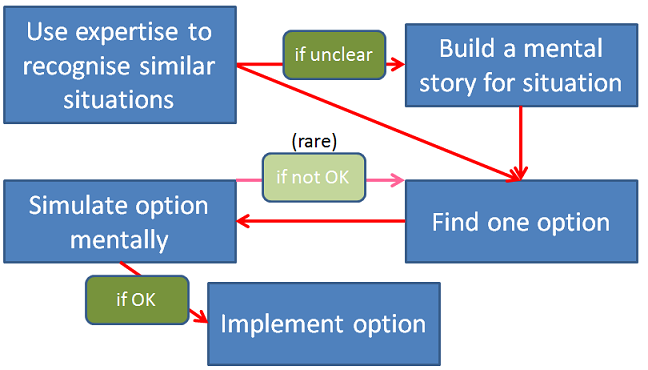
Note again that at no point is an option compared with another.
When RPD works, when it doesn't
So, how does recognition-primed decision making hold up in practice? Well, it's used in many fields, by, for instance, naval ship commander, tank platoon leaders, fire commanders, design engineers, offshore oil installation managers, infantry officers, commercial aviation pilots, and chess players. Experts in the fields use it more than novices, and get better results, so it's certainly of practical use in many settings.
It seems to be at its best when there is reasonable experience to draw upon, when the goals are ill-defined or uncertain, and, most especially, when under time pressure. It works less well in highly combinatorial situations, in situations when justification is needed (ie someone needs to explain why an option was chosen), or when there are multiple competing preferences to reconcile. Most of all, it is not universal: one cannot use it generalise from some situations to very different ones, even if they seem formally similar.
Still, it's a useful reminder that identifying biases is not the certain knockdown that it's sometimes treated to be. Recognition-primed decision making is incredibly biased, with elements that speed or slow down the recognition process having large impacts on the decision. And yet it remains the best approach in many situations. And it's useful as an alternative mental model of decision making to have in the back of one's head.
Further reading
All these papers are of interest to expertise and its use and assessment. A brief summary I wrote of their contents can be found here.
- Aspinall W. & Cooke R.M. 1998. Expert judgement and the Montserrat Volcano eruption. In: Mosleh, Ali & Bari, Robert A. (eds) Proceedings of the 4th International Conference on Probabilistic Safety Assessment and Management PSAM4, September 13th -18th, 1998, New York City, USA. Springer, 2113-2118.
- Aspinall, W. P. "Structured elicitation of expert judgement for probabilistic hazard and risk assessment in volcanic eruptions." Statistics in volcanology 1 (2006): 15-30.
- Aspinall, Willy. "A route to more tractable expert advice." Nature 463.7279 (2010): 294-295.
- Cooke, Roger M., and Louis H. J. Goossens. "Expert judgement elicitation for risk assessments of critical infrastructures." Journal of Risk Research 7.6 (2004): 643-656.
- Dawes, Robyn M. "The robust beauty of improper linear models in decision making." American psychologist 34.7 (1979): 571.
- Doherty, Michael E., et al. "Pseudodiagnosticity." Acta psychologica 43.2 (1979): 111-121.
- Epstein, Ronald M., and Edward M. Hundert. "Defining and assessing professional competence." Jama 287.2 (2002): 226-235.
- Eraut, Michael. "Non‐formal learning and tacit knowledge in professional work." British Journal of Educational Psychology 70.1 (2000): 113-136.
- G Woo "Calibrated expert judgement in seismic hazard activity" Earthquake Engineering, Tenth World Conference (1992).
- Gaeth, Gary J., and James Shanteau. "Reducing the influence of irrelevant information on experienced decision makers." Organizational Behavior and Human Performance 33.2 (1984): 263-282.
- George, Roger Z. "Fixing the problem of analytical mind-sets: Alternative analysis." International Journal of Intelligence and Counterintelligence 17.3 (2004).
- Gilbert, Daniel T. "How mental systems believe." American psychologist 46.2 (1991): 107.
- Goldberg, Lewis R. "Five models of clinical judgment: An empirical comparison between linear and nonlinear representations of the human inference process." Organizational Behavior and Human Performance 6.4 (1971): 458-479.
- Goldberg, Lewis R. "Simple models or simple processes? Some research on clinical judgments." American Psychologist 23.7 (1968): 483.
- Hoyer, William J., George W. Rebok, and Susan Marx Sved. "Effects of varying irrelevant information on adult age differences in problem solving." Journal of Gerontology 34.4 (1979): 553-560.
- Hutchinson, J. Wesley, and Joseph W. Alba. "Ignoring irrelevant information: Situational determinants of consumer learning." Journal of Consumer Research (1991): 325-345.
- Johnston, William A., and Jolynn Wilson. "Perceptual processing of nontargets in an attention task." Memory & cognition 8.4 (1980): 372-377.
- Kahneman, Daniel. Attention and effort. Englewood Cliffs, NJ: Prentice-Hall, 1973.
- Klein, Gary A. A recognition-primed decision (RPD) model of rapid decision making. Ablex Publishing Corporation, 1993.
- Lipshitz, Raanan, et al. "Taking stock of naturalistic decision making." Journal of Behavioral Decision Making 14.5 (2001): 331-352.
- Mellers, Barbara, et al. "Psychological strategies for winning a geopolitical forecasting tournament." Psychological science 25.5 (2014): 1106-1115.
- Parascandola, Mark. "Epistemic risk: empirical science and the fear of being wrong." Law, probability and risk (2010): mgq005.
- Rice, Marion F. "The influence of irrelevant biographical information in teacher evaluation." Journal of Educational Psychology 67.5 (1975): 658.
- Satopää, Ville A., et al. "Combining multiple probability predictions using a simple logit model." International Journal of Forecasting 30.2 (2014): 344-356.
- Shanteau, James, et al. "Performance-based assessment of expertise: How to decide if someone is an expert or not." European Journal of Operational Research 136.2 (2002): 253-263.
- Shanteau, James. "Decision making by experts: The GNAHM effect." Decision Science and Technology. Springer US, 1999. 105-130.
- Shanteau, James. "Expert judgment and financial decision making." Risky business (1995): 16-32.
- Shanteau, James. "How much information does an expert use? Is it relevant?." Acta Psychologica 81.1 (1992): 75-86.
- Sue, Stanley, Ronald E. Smith, and Cathy Caldwell. "Effects of inadmissible evidence on the decisions of simulated jurors: A moral dilemma." Journal of Applied Social Psychology 3.4 (1973): 345-353.
- Troutman, C. Michael, and James Shanteau. "Inferences based on nondiagnostic information." Organizational Behavior and Human Performance 19.1 (1977): 43-55.
- Ungar, Lyle H., et al. "The Good Judgment Project: A Large Scale Test of Different Methods of Combining Expert Predictions." AAAI Fall Symposium: Machine Aggregation of Human Judgment. 2012.
- Weiss, David J., and James Shanteau. "Decloaking the privileged expert." Journal of Management and Organization 18 (2012): 300-310.
- Weiss, David J., and James Shanteau. "Empirical assessment of expertise." Human Factors: The Journal of the Human Factors and Ergonomics Society 45.1 (2003): 104-116.
16 comments
Comments sorted by top scores.
comment by ShardPhoenix · 2014-06-27T04:56:07.133Z · LW(p) · GW(p)
This seems like a good description of how decision-making typically works in practice, but as a counterpoint to the chess example, something commonly told to chess learners is "when you see a good move, look for a better one" - i.e. players are encouraged to explicitly compare moves. Not sure if that still applies to experts or only to amateurs. I've also heard similar advice for other turn-based games.
Replies from: Error↑ comment by Error · 2014-06-27T13:54:39.060Z · LW(p) · GW(p)
It may depend on whether you're playing on a clock, too. Explicit comparison is slow and time can be a cost.
(I hate playing on a clock)
Replies from: None↑ comment by [deleted] · 2014-06-29T04:54:02.989Z · LW(p) · GW(p)
Satisficing seems to be almost exclusive to time sensitive careers.
Replies from: AspiringRationalist↑ comment by NoSignalNoNoise (AspiringRationalist) · 2014-07-13T23:52:06.857Z · LW(p) · GW(p)
All careers are time-sensitive. If there's an acceptable solution that you can implement in a day, you boss generally won't be happy about it if you spend a week implementing a "better" solution.
Replies from: Nonecomment by Ben Pace (Benito) · 2014-06-27T06:34:44.721Z · LW(p) · GW(p)
The content of this post that you deemed somewhat controversial doesn't appear that controversial to me. It looks like an in depth account of your System 1 if you're an expert in an area. I thought this when you used the chess example, because that's perhaps the most common example people use to show how our heuristics aren't always detrimental to our performance, and can in fact be better than system 2 at times.
Thanks for mentioning the different fields of study of expertise by the way. Could you recommend any popular level books that represent these silos? Also, where does Philip Tetlock's "Expert Political Judgement" fit in?
Replies from: Stuart_Armstrong↑ comment by Stuart_Armstrong · 2014-06-27T06:41:40.871Z · LW(p) · GW(p)
It's the fact that it works so well that I deemed surprising.
Tetlock... has done recent work in the combining expertise area.
Replies from: Punoxysm↑ comment by Punoxysm · 2014-06-27T08:01:21.167Z · LW(p) · GW(p)
Tetlock and others:
comment by oge · 2014-06-30T01:08:58.451Z · LW(p) · GW(p)
Nice post, Stuart_Armstrong. FYI there's a typo: "that it's almost a new of thinking" is missing "way".
Replies from: Stuart_Armstrong↑ comment by Stuart_Armstrong · 2014-06-30T10:01:02.325Z · LW(p) · GW(p)
Corrected, thanks!
comment by Error · 2014-06-26T15:22:32.888Z · LW(p) · GW(p)
Well, [recognition-primed decision making] is used in many fields, by, for instance, naval ship commander, tank platoon leaders, fire commanders...
Once upon a time I was an expert in computer repair, and this fits my experience -- but in place of simulating an option mentally, I would try to simulate it physically. For example, I might replace a suspect part with one of the shop spares to test an initial hypothesis. I generated hypotheses mostly by pattern matching the symptoms and sometimes the system brand (or even the customer) to whatever was most available in my own memory.
So that's another area where RPDM gets used. I also play Chess and Go in the manner described by the last graph, although I wouldn't call myself an expert at either.
Replies from: Stuart_Armstrong↑ comment by Stuart_Armstrong · 2014-06-26T18:16:16.948Z · LW(p) · GW(p)
"pattern matching" seems a good description
comment by fortyeridania · 2014-06-30T06:28:08.433Z · LW(p) · GW(p)
Very interesting post.
Experts in the fields use it more than novices, and get better results, so it's certainly of practical use in many settings.
To what degree should the better results be attributed to greater use of RPDM? Another possibility: (a) more experience leads to more effective use of RPDM, and (b) the more effective RPDM is, the more likely a person is to use it. This hypothesis also predicts that experts would have better results and use RPDM more--but the better results would not come simply from the increased use of RPDM. They would more properly be said to come from added experience.
Support for (a) comes from your sentence "It seems to be at its best when there is reasonable experience to draw upon."
comment by [deleted] · 2014-06-29T04:55:33.339Z · LW(p) · GW(p)
It seems what you're describing here is the phenomenon known as satisficing, although the word doesn't appear in the article.
May be a useful keyword if anyone else is interested in looking into it.
Replies from: Stuart_Armstrong↑ comment by Stuart_Armstrong · 2014-06-30T10:00:51.819Z · LW(p) · GW(p)
Added that.
comment by Swimmer963 (Miranda Dixon-Luinenburg) (Swimmer963) · 2014-06-28T23:13:38.116Z · LW(p) · GW(p)
This seems to describe the exact kind of expertise that I'm developing as a critical care nurse. Cool! Someone's studying that!