Cruxes for overhang
post by Zach Stein-Perlman · 2023-09-14T17:00:56.609Z · LW · GW · 5 commentsThis is a link post for https://blog.aiimpacts.org/p/cruxes-for-overhang
Contents
Is overhang possible? Will the policy regime be evaded or suddenly reversed? Endogeneity How bad is delayed but rapid progress? Miscellanea None 5 comments
Suppose a policy regime artificially restricts training compute.[1] Will this lead to rapid progress[2] later? Yes if and only if both the policy is suddenly reversed/evaded and progress can largely 'catch back up to where it would have been.' This post aims to identify crucial considerations for analyzing the possibility of slowing AI progress causing faster progress later.
"Overhang" has many meanings [LW · GW]. In this post, there is an "overhang" to the extent that leading labs could quickly increase their systems' capabilities if they wanted to and were allowed to, especially by scaling up training compute. training compute if they wanted to and were allowed to. So overhang could be measured in orders of magnitude of training compute. If labs want and are allowed to increase capabilities, overhang entails faster progress. Faster progress seems bad for safety,[3] so overhang seems bad for safety.
Four considerations affect the magnitude of overhang, its causes, and its implications:
- If a leading lab stops doing bigger training runs for a while and later resumes, will its growth in capabilities merely resume the old rate or will it catch up to where it would have been without a pause?
- If a policy regime (or perhaps another source of restriction) artificially limits training runs, will it be suddenly reversed/evaded or gradually lifted?
- How does AI progress affect AI progress?
- How bad is delayed but rapid progress?
Is overhang possible?
If a leading lab stops doing bigger training runs for a while and later resumes, will its growth in capabilities (or training compute in particular) merely resume at the old rate or will it catch up to where it would have been without a pause?
The answer is somewhere in the middle, but I don't know where. Consider two simplified models of progress: there is an underlying progress-curve that labs catch up to when unpaused, or progress merely resumes at the old rate so pausing for time t slows down capabilities by t. The true model of progress determines not just whether overhang is possible but also whether a leading lab pausing progress burns its lead time or not.
Here are some cruxes:
- If someone did a GPT-4-sized[4] training run in (say) 2018, how much weaker would it be than GPT-4? If someone did a (say) 1e28 FLOP training run now, how much weaker would it be than one done in a few years?[5]
- If a leading lab wanted to do a 1e28 FLOP training run, could it do so (quickly and such that the model is accordingly powerful and marginal compute isn't ~wasted)? What would be the main difficulties? Why can't labs effectively increase training compute arbitrarily?
(Great historical analogues would provide evidence, but I doubt they exist. A great analogue would be a technology with an analogue of training compute which increases over time until an exogenous pause.)
(Rapid increases in funding or decreases in the cost of compute could cause labs to be able to quickly scale up training compute.[6] I don't discuss this possibility in this post since it's not related to labs slowing and then restarting suddenly.)
Will the policy regime be evaded or suddenly reversed?
If a policy regime that limits training compute is stable and not evadable, then overhang doesn't matter—it doesn't matter what labs would do in the absence of the policy regime, since they're stuck with the policy regime.
So crucial properties of a policy regime are:
- Can labs evade it?
- Depends on the policy's scope, enforcement details, and technical questions about how well large training runs can be detected and monitored
- Depends on whether it's global (and maybe whether labs can move; regardless, non-global regulation differentially boosts labs outside its jurisdiction); see below
- Will it suddenly expire or be reversed?
- Depends on its effects
- Depends on what's going on outside of its reach
- Depends on the relative level of AI capabilities in different states
Of course, it depends on the training runs—monitoring all training runs of >1e26 FLOP is much easier than monitoring all training runs of >1e20 FLOP. Monitoring training runs above a given threshold gets harder over time by default as total available compute increases, but monitoring capabilities may improve.
For US domestic regulation: can the US unilaterally restrict the training runs of foreign companies? Can US companies evade US regulation on training runs by moving?[7] The answers are mostly I don't know, with a bit of it depends on the regulation. Also note that super-strict US regulation could cause leading labs to try to leave, and even if labs couldn't effectively leave regulation could quickly cause US labs to become irrelevant (and US regulation to become largely irrelevant), unless the regulation applied globally (or was quickly reversed).[8]
Would a (say) ceiling on training compute policy regime disappear suddenly? It seems plausible but far from inevitable.[9] Ways that could happen:
- The policy expires at a certain date and the government doesn't renew it
- The ceiling ends when a certain condition is met, and that condition is met
- The government changes its mind and repeals the policy
- Because of changing attitudes on AI safety, risk, benefit, or the effects of the policy
- Because of a Sputnik moment or other concerns about adversaries
- A different part of the government reverses the policy
- Especially that the courts find it illegal
One source of evidence: how frequently are similar policy regimes evaded or suddenly reversed (insofar as similar policy regimes exist)?
Policy implication: for ceilings, think about when your ceiling will end and what comes after. (Ideally get a policy like auditing training runs with safety evals or maybe gradually increasing ceiling rather than ceiling that ends after a while.)
Endogeneity
The catch-up model is wrong in a simple way: learning from experience and iterating is important. A 1e28 FLOP training run would go better if you've done a 1e27 FLOP training run a year earlier. (How much better? I don't know.)
But the catch-up model is also wrong in complex ways. AI progress affects (inputs to) AI progress through various feedback loops.
- AI tools may substantially accelerate research.
- AI may generate substantial revenue. This enables and incentivizes greater spending.
- AI progress and the promise of greater capabilities increases investment and enables and incentivizes spending.
- AI progress increases a lab's access to talent (and averts their researchers quitting).
- Sufficiently capable AI systems may generate relevant data.
- Or they may facilitate humans generating relevant data, such as a chatbot getting general language data, data on how users interact with chatbots, and data on how chatbots engage users.
- Leading AI systems may seem more exciting, increasing the number of researchers working on paths to powerful systems and thus accelerating progress.
- On the other hand, frightening or socially disfavored capabilities may appear or seem likely to appear, potentially resulting in general disinclination to create highly capable AI agents or active prevention via public policy or corporate self-governance.
These feedback loops are net positive for progress. So 'catching back up' after e.g. pausing growth of training runs is even less realistic than we would otherwise have thought.
How bad is delayed but rapid progress?
Here are some cruxes:
- How much better is it to have (say) two years' worth of progress[10] over two years vs two years of no progress followed by an instantaneous jump of two years' worth of progress?
- How much do powerful models help alignment research?
- If progress is smooth rather than delayed then rapid, how much does that help cause good attitudes among AI developers, good governance responses, etc.? Are there important weak-AI societal challenges that society could better adapt to if progress is smoother?
It seems bad to rapidly progress through capability-levels near very dangerous models, since time is more valuable for AI safety 'near the end,' when there's more powerful models and more clarity about what powerful models look like and maybe general strategic clarity and open windows of opportunity.[11] Smoother progress can also help society prepare for powerful AI, and in particular help government, standard-setters, and auditors.
Miscellanea
- One nuance is to distinguish stopping training from just stopping deployment.
- Insofar as labs learn from training rather than deployment, just stopping deployment still allows labs to learn how to make more powerful models.
- The benefits of AI progress include boosting safety research and helping society prepare for more powerful systems; the latter benefit seems to largely require widespread deployment (but can be partially achieved by e.g. scary demos); the former could largely be achieved without widespread deployment if labs share their models with safety researchers.
- Maybe you can separate training compute from algorithmic progress as inputs to AI. Maybe if labs aren't increasing training compute, they can focus on algorithmic progress. (Sounds very false; I'd guess they don't really trade off.[12])
- Maybe labs face a tradeoff between making powerful models and making products. (Sounds false; I'd guess they don't trade off much.)
- So maybe if they're prevented from doing bigger training runs, their efforts are diverted to products.
- Or maybe if they're prevented from doing bigger training runs, eventually they pluck the low-hanging product fruit and shift to algorithmic progress.
An abstract graph of overhang:
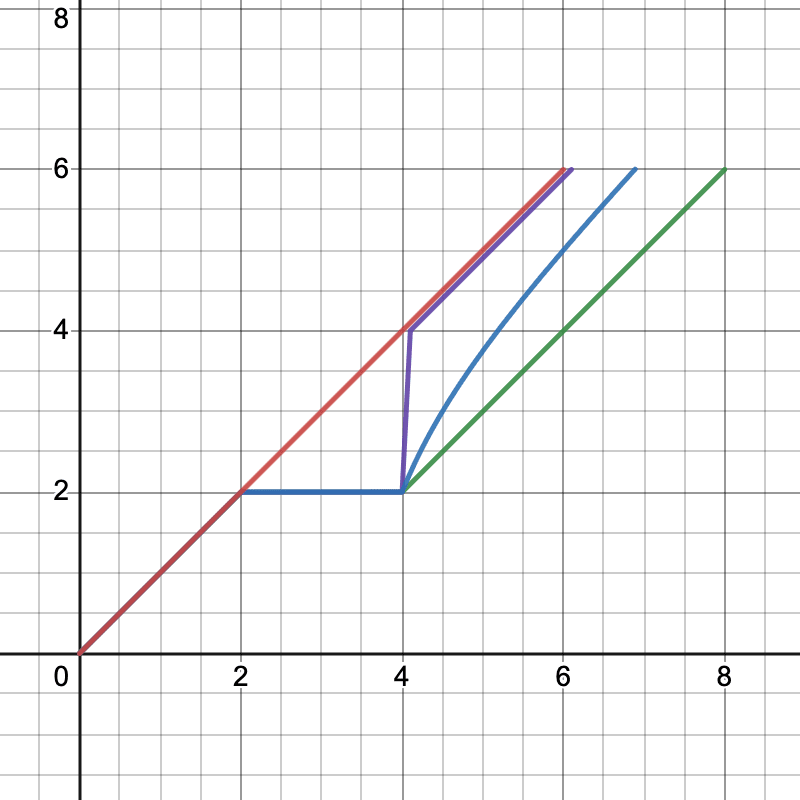
The x-axis is time; the y-axis can be size of the largest training run or capabilities. Red is default (no pause), purple is pause with near-full overhang, green is pause with no overhang, and blue is pause with some overhang. Whether the effect of a pause/slowing is closer to purple or green depends on uncertainties about the world and details of the pause/slowing.
Sometimes people say slowing AI progress would be bad for AI safety because it would create a compute overhang and cause faster progress later. This is far too strong: overhang clearly doesn't apply to some kinds of scenarios, like decreasing the diffusion of ideas or increasing the cost of compute. But even for capping training compute—the most central example of a policy that might create an overhang—overhang may not be a problem, as discussed above.
This post expands on my "Quickly scaling up compute" in "Slowing AI: Foundations." [LW · GW]
Thanks to Olivia Jimenez for discussion and Rick Korzekwa, Matthew Barnett, Rose Hadshar, Jaime Sevilla, and Jeffrey Heninger for comments on a draft.
- ^
Artificially capping training compute can have the downside of increasing multipolarity among labs, or equivalently burning leading labs' lead time. See my "Beware of increasing multipolarity" in "Slowing AI: Foundations." [LW · GW] But this post is about when there's an overhang downside too.
- ^
In this post, I'm interested in progress toward dangerous AI.
- ^
See e.g. my "Slower AI progress would be good" in "Slowing AI: Foundations." [? · GW]
- ^
Epoch estimates GPT-4 used about 2e25 FLOP, which cost an estimated $40M.
- ^
The literature on the pace of algorithmic progress is mostly not about language models. See Epoch's Algorithmic Progress. See also e.g. AI and Efficiency (Hernandez and Brown 2020), How Fast Do Algorithms Improve? (Sherry and Thompson 2021), Algorithmic Progress in Six Domains (Grace 2013), and A Time Leap Challenge for SAT Solving (Fichte et al. 2020).
- ^
We can consider another two simplified models of progress for this scenario: lots of money can be efficiently converted to training compute and model capabilities depend on training compute alone, or the marginal benefit of spending is ~zero for training runs much larger than any past ones. Again, the truth is somewhere in between but I don't know where.
- ^
Another question (relevant to overhang insofar as it determines whether a policy regime would be evaded or reversed): how far behind the US is other states' AI progress, and how quickly would this change if the US restricted large training runs? If there was a strong restrictive policy regime in the US, how long until dangerous AI appears elsewhere? And how long until a Sputnik moment or the US otherwise becoming worried about foreign progress? (And insofar as a policy regime targets (say) LLMs, how does non-LLM progress affect US attitudes on foreign progres?). Separately, there are questions about international relations—what is the probability of a strong treaty on AI, and what does that depend on?
- ^
See generally my Cruxes on US lead for some domestic AI regulation [? · GW].
- ^
Some policies might need to be maintained for a long time to have a positive effect, and it might be very bad if they were repealed prematurely.
- ^
Or: reach the capability-level that would be reached in two years by default.
- ^
See my Slowing AI: Crunch time [? · GW].
- ^
Each of the explanations I can imagine for that phenomenon sounds implausible:
- Lab staff can shift their labor from increasing training compute to making substantial algorithmic progress— kind of plausible, but I have a vague sense that AI-research labor doesn't funge that way.
- Lab funding can similarly shift— I think labs aren't funding-constrained that way.
- The lab was making substantially less algorithmic progress than it freely could have— why wasn't it?
Also to some extent algorithmic improvements are unlocked by scale or only become optimal at larger scales.
5 comments
Comments sorted by top scores.
comment by Kenoubi · 2023-09-14T22:01:22.601Z · LW(p) · GW(p)
Slowing compute growth could lead to a greater focus on efficiency. Easy to find gains in efficiency will be found anyway, but harder to find gains in efficiency currently don't seem to me to be getting that much effort, relative to ways to derive some benefit from rapidly increasing amounts of compute.
If models on the capabilities frontier are currently not very efficient, because their creators are focused on getting any benefit at all from the most compute that is practically available to them now, restricting compute could trigger an existing "efficiency overhang". If (some of) the efficient techniques found are also scalable (which some and maybe most won't be, to be sure), then if larger amounts of compute do later become available, we could end up with greater capabilities at the time a certain amount of compute becomes available, relative to the world where available compute kept going up too smoothly to incentivize a focus on efficiency.
This seems reasonably likely to me. You seem to consider this negligibly likely. Why?
Replies from: Zach Stein-Perlman↑ comment by Zach Stein-Perlman · 2023-09-14T22:47:36.709Z · LW(p) · GW(p)
I briefly discuss my skepticism in footnote 12. I struggle to tell a story about how labs would only pursue algorithmic improvements if they couldn't scale training compute. But I'm pretty unconfident and contrary opinions from people at major labs would change my mind.
Replies from: Kenoubi↑ comment by Kenoubi · 2023-09-15T00:25:19.847Z · LW(p) · GW(p)
I certainly don't think labs will only try to improve algorithms if they can't scale compute! Rather, I think that the algorithmic improvements that will be found by researchers trying to figure out how to improve performance given twice as much compute as the last run won't be the same ones found by researchers trying to improve performance given no increase in compute.
One would actually expect the low hanging fruit in the compute-no-longer-growing regime to be specifically the techniques that don't scale, since after all, scaling well is an existing constraint that the compute-no-longer-growing regime removes. I'm not talking about those. I'm saying it seems reasonably likely to me that the current techniques producing state of the art results are very inefficient, and that a newfound focus on "how much can you do with N FLOPs, because that's all you're going to get for the foreseeable future" might give fundamentally more efficient techniques that turn out to scale better too.
It's certainly possible that with a compute limit, labs will just keep doing the same "boring" stuff they already "know" they can fit into that limit... it just seems to me like people in AI safety advocating for compute limits are overconfident in that. It seems to me that the strongest plausible version of this possibility should be addressed by anyone arguing in favor of compute limits. I currently weakly expect that compute limits would make things worse because of these considerations.
Replies from: Zach Stein-Perlman↑ comment by Zach Stein-Perlman · 2023-09-15T00:30:35.477Z · LW(p) · GW(p)
Thanks. idk. I'm interested in evidence. I'd be surprised by the conjunction (1) you're more likely to get techniques that scale better by looking for "fundamentally more efficient techniques that turn out to scale better too" and (2) labs aren't currently trying that.
Replies from: Kenoubi↑ comment by Kenoubi · 2023-09-15T01:31:21.418Z · LW(p) · GW(p)
Some points which I think support the plausibility of this scenario:
(1) EY's ideas about a "simple core of intelligence", how chimp brains don't seem to have major architectural differences from human brains, etc.
(2) RWKV vs Transformers. Why haven't Transformers been straight up replaced by RWKV at this point? Looks to me like potentially huge efficiency gains being basically ignored because lab researchers can get away with it. Granted, affects efficiency of inference but not training AFAIK, and maybe it wouldn't work at the 100B+ scale, but it certainly looks like enough evidence to do the experiment.
(3) Why didn't researchers jump straight to the end on smaller and smaller floating point (or fixed point) precision? Okay, sure, "the hardware didn't support it" can explain some of it, but you could still do smaller scale experiments to show it appears to work and get support into the next generation of hardware (or at some point even custom hardware if the gains are huge enough) if you're serious about maximizing efficiency.
(4) I have a few more ideas for huge efficiency gains that I don't want to state publicly. Probably most of them wouldn't work. But the thing about huge efficiency gains is that if they do work, doing the experiments to find that out is (relatively) cheap, because of the huge efficiency gains. I'm not saying anyone should update on my claim to have such ideas, but if you understand modern ML, you can try to answer the question "what would you try if you wanted to drastically improve efficiency" and update on the answers you come up with. And there are probably better ideas than those, and almost certainly more such ideas. I end up mostly thinking lab researchers aren't trying because it's just not what they're being paid to do, and/or it isn't what interests them. Of course they are trying to improve efficiency, but they're looking for smaller improvements that are more likely to pan out, not massive improvements any given one of which probably won't work.
Anyway, I think a world in which you could even run GPT-4 quality inference (let alone training) on a current smartphone looks like a world where AI is soon going to determine the future more than humans do, if it hasn't already happened at that point... and I'm far from certain this is where compute limits (moderate ones, not crushingly tight ones that would restrict or ban a lot of already-deployed hardware) would lead, but it doesn't seem to me like this possibility is one that people advocating for compute limits have really considered, even if only to say why they find it very unlikely. (Well, I guess if you only care about buying a moderate amount of time, compute limits would probably do that even in this scenario, since researchers can't pivot on a dime to improving efficiency, and we're specifically talking about higher-hanging efficiency gains here.)