Progress Report 7: making GPT go hurrdurr instead of brrrrrrr
post by Nathan Helm-Burger (nathan-helm-burger) · 2022-09-07T03:28:36.060Z · LW · GW · 0 commentsContents
Introduction My hypotheses were: Result Details of result First test Second test Third test Implications Next steps None No comments
First progress post [LW · GW]
Introduction
Starting off this project, I was using ROME modification to alter individual weights and get clusters of neurons in the model. I came up with the idea of partially impairing these clusters rather than fully ablating them. Impairing in this case means partially degrading their function by adding noise to their activations. This noise is made from normal gaussian random values [-1, 1] multiplied by an intensity modifier. I also tested negative noise (same noise generation, but shifted down by subtracting the maximum noise value so that the max is zero before adding to the activations). I also tested a proportional reduction in magnitude of the activations, by multiplying the cluster's activations by a number between 0 and 1.
I tested these types of impairing of clusters by observing the loss & accuracy on topic-specific keywords from specific prompts (each prompt 1-3 sentences). This was inspired by the methodology of the ROME work. I came up with my own prompts by extracting topic-specific keywords from topic-specific subsets of wikipedia articles, and then taking a text passage leading up to the keyword as the 'prompt' and the keyword as the 'answer'.
My hypotheses were:
- I would see an impairment of model function which correlated closely with the intensity of the impairment.
- I would see the particular topic of the cluster I was impairing experience more impairment
Result
Hypothesis A was clearly confirmed, the general impairment of model function worked great. Nice smooth curves. Hypothesis B was disproven, there was no specificity of cluster-impairment to the cluster topic.
Details of result
First test
This test was on 150 samples each of prompts from dataset topics: harmless internet comments, toxic internet comments, wikipedia topic Athlete. The 'cluster' I was trying to impair was 'toxic comments'. This represented around 2% of the MLP neurons of each transformer block. The impairment adjustment was made to the hidden activation of each transformer block just after the MLP layer before adding the result back to the residual stream.
Noise


Magnitude Adjustment


Second test
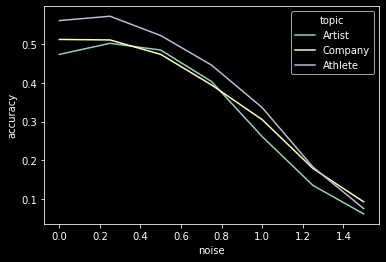
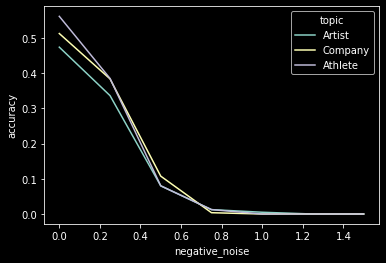
This test was on 800 samples each of wikipedia topic datasets: Athlete, Artist, Company
In this case I was attempting to impair the Athlete 'cluster'. Again, this was 2-3% of neurons from each MLP layer.
Noise

Negative Noise

Magnitude Adjustment


Third test
Same dataset as the first test (wikipedia Athlete, Toxic comments (targeted cluster), Harmless Comments), but I moved the noise addition to the hidden states just before the MLP layer rather than just after it.


Implications
The implication of confirming hypothesis A is that there is an efficient easy-to-implement way to apply a specific amount of general impairment to transformer-type models. My current best guess for how this could be useful to alignment is:
- useful for research on a particular model performs on various tasks with differing levels of impairment. How fragile is a particular ability of the model?
- useful for performance evaluations. For evaluations where you would like to compare two models, but are seeing ceiling effects, you could impair both models and measure the amount of impairment of each required to no longer have perfect performance. You could use this to create performance-under-impairment curves to compare the two models.
- useful for safety evaluations. I have proposed the idea that in the near future we may enter a regime where new multi-function transformers or other models may be good at strategic planning, coding or utilizing open source code, knowing or acquiring relevant useful information from the internet, socially manipulating humans, and acquiring and utilizing real world resources, such that releasing such a model (even through a filtered API) could be quite dangerous. I have previously discussed how in such circumstances it would be very important to screen for such dangers. One possible way this could be done would be to have an organization that specialized in secure sandboxing and safety evaluations. This org would interact with the model through an API which also accepted a parameter for 'impairment'. The creators of the model would implement this smooth impairment, so that the model's weights didn't have to be exposed. This would allow the safety evaluators to test the model's abilities starting with a highly impaired version and incrementally reducing the impairment until some safety threshold was reached. The safety org could then report the minimum impairment level they were able to test to, and a recommended impairment level for public release (probably higher than the minimum tested level).
Next steps
This paper on Neuron Shapley values is basically the same idea I came up with, but implemented much better. Better computational efficiency with approximate algorithms (something I had been worried about with my painfully slow method), and a more clear implementation (which I can see since their code is open source). However, it is implemented specifically for convolutional neural nets. I'm working on converting it to also work with transformer mlp layers. I plan to retest with the same datasets.
Also, I've come to the end of the time I set aside for myself for career-reorientation with my LTFF grant. So that means it's job application time....
Two other things I think that could help a lot with interpretability and control of transformers are:
- sparser mlp layers with duty-cycle dropping (selective dropout of most frequently activated neurons to spread responsibility out more evenly) as described by Numenta's "How can we be so dense?" https://github.com/numenta/htmpapers/tree/master/arxiv/how_can_we_be_so_dense
I also plan to do an initial exploration of this idea by trying these two experiments:
a. adding a sparse layer in place of the normal MLP feedforward layer in the last transformer block of HuggingFace's GPT-2-xl. Will then freeze other layers of the model and train model, compare loss with original GPT-2-xl, then look at interpretability of neurons in this extra sparse layer.
b. On a different copy of GPT-2-xl adding a sparse layer after the last transformer block, which processes the final residual stream state, just before the final layer norm and output encoding.
- trying to improve preservation of information location within layers with deliberately chosen rotations, as described by Garret Baker in https://www.lesswrong.com/posts/C8kn3iL9Zedorjykt/taking-the-parameters-which-seem-to-matter-and-rotating-them [LW · GW]
If Garret posts some results on this project at some future point, I intend to revisit my clustering idea applied to a model utilizing his rotation idea.
0 comments
Comments sorted by top scores.