Progress Report 1: interpretability experiments & learning, testing compression hypotheses
post by Nathan Helm-Burger (nathan-helm-burger) · 2022-03-22T20:12:04.284Z · LW · GW · 0 commentsContents
Intro Current progress Plots Details of dataset and benchmarks: None No comments
Intro
I got a grant from the Long Term Future Fund to refocus my career from data science & machine learning generally, to ai alignment research specifically. I feel most drawn to and suited for the interpretability angle.
I'm also currently in the AGI fundamentals technical course. I had already read most of the readings, but I've been finding the discussions insightful and useful in broadening my perspective.
For my grant-funded time, the two subgoals I am focusing on are:
- improving my skillset / experience with ml interpretability research
- accumulating some evidence of my ability to be a good researcher / research engineer
My current concrete project in pursuit of these goals is to:
1 implement and understand some simple transformers, in line with those described in the research by the Transformer Circuits team ( https://transformer-circuits.pub ).
2. test some simple hypotheses I have on these based on my ideas around revealing natural abstractions through applying transforms to the weights of a pre-trained model. These transforms could include: compression, factorization, clustering then encapsulation, and anything else that occurs to me or gets suggested to me. (some details on my thoughts in this previous post of mine: https://www.lesswrong.com/posts/7vcZTHzjCFE8SbjWF/neural-net-decision-tree-hybrids-a-potential-path-toward [LW · GW] )
Initial steps
- can I apply compression (e.g. using an infoVAE) to information coming from component(s) of the pre-trained model and examine the change in performance on baselines. (hopefully not too much of a drop. I plan to test and compare varying levels of compression to start with.) My hope is to find some representation of the space which is more intuitive to interpret. Related link: https://youtu.be/BePQBWPnYuE
- will the information bottlenecks (e.g. latent layers of the infoVAEs) be useful to examine? Will it either be easier to understand or provide a useful alternate view of the information being added to the residual stream by the relevant component?
- If the answers to the above two points are yes, then can I apply the same method to a larger more complex pre-trained model (e.g. distilGPT-2)
Current progress
I'm now about 5 weeks into working on this.
A lot of the first couple weeks was reading and understanding the work being done by the Transformer Circuits team, other background reading on transformers, and then reading through the code of some example implementations.
In the third and fourth weeks, I have written my own simple implementation of a decoder-only transformer (and learned more in the process), and begun working on benchmarking it with varying hyperparameters, and begun working on implementing the first compression algorithm I want to test on it.
(insert initial benchmark results here)
example plot (won't actually include this specific one, just wanted something here for getting feedback on what sort of format might be useful for my intended audience)
Plots
Plot 1
Training history for a basic 2 layer attention-only decoder with each decoder layer having 12 attention heads.
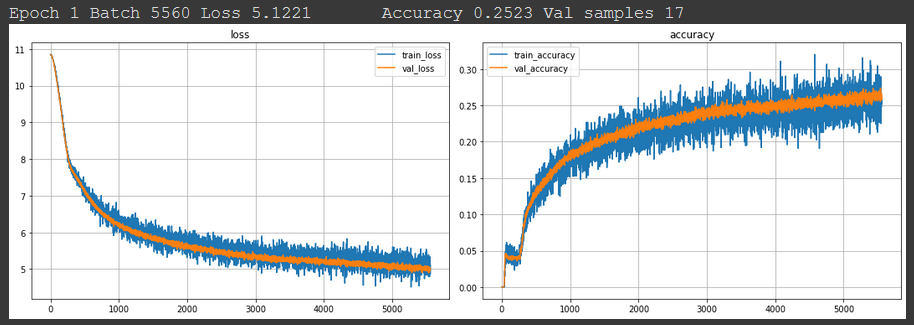
Details of implementation:
{'attention_only': True,
'batch_size': 64,
'd_model': 768,
'decoder_num_layers': 2,
'dimension_of_mlp': 3072,
'dimensions_per_head': 64,
'dropout_rate': 0.1,
'epochs': 2,
'metrics': ['loss', 'accuracy', 'val_loss', 'val_accuracy'],
'model_context_tokens': 20,
'model_name': 'Decoder_2layer_12head_attnOnly_v1',
'num_heads_per_layer': 12,
'vocab_size': 50257}
Plot 2
Training history for a basic 2 layer attention-only decoder with each decoder layer having 12 attention heads and an mlp layer.

Details of Implementation
{'attention_only': False,
'batch_size': 64,
'd_model': 768,
'decoder_num_layers': 2,
'dimension_of_mlp': 3072,
'dimensions_per_head': 64,
'dropout_rate': 0.1,
'epochs': 2,
'metrics': ['loss', 'accuracy', 'val_loss', 'val_accuracy'],
'model_context_tokens': 20,
'model_name': 'Decoder_2layer_12head_mlp_v1',
'num_heads_per_layer': 12,
'vocab_size': 50257}
Details of dataset and benchmarks:
My code for those who are curious: https://github.com/nathanneuro/circuits
I took a combo encoder-decoder from a Tensorflow transformer tutorial, and deleted the encoder part to make it decoder-only like gpt-2. Then I switched the input data to be wikipedia articles and adjusted the params to be closer to what the Anthropic Transformer Circuits team used in their first paper.
Using wikipedia articles from
description link: https://www.tensorflow.org/datasets/catalog/wiki40b
data link: https://tfhub.dev/google/wiki40b-lm-en/1
Used the given train/test split. Using samples of text, 20 words long, drawn from the beginning of each article (after start of first paragraph. First 19 words used as context to predict the 20th.
With each train step validating on randomly drawn samples of articles from the test split
0 comments
Comments sorted by top scores.