Progress Report 2
post by Nathan Helm-Burger (nathan-helm-burger) · 2022-03-30T02:29:32.670Z · LW · GW · 1 commentsContents
1 comment
In looking at interpretability in transformers (1), I've been looking at the Causal Tracing notebook here: https://rome.baulab.info/ (2)
Expanding on this code somewhat, I made an attempt to increase the 'resolution' of the trace from layer-specific down to neuron-specific. I'm not all that confident yet that my code to do this is correct, since I haven't had a chance to go over it with anyone else yet (please feel free to message me with offers to help review my code). If there are mistakes, I hope that they are small enough ones that the general idea still works once corrected. With that in mind, here's a couple example plots:
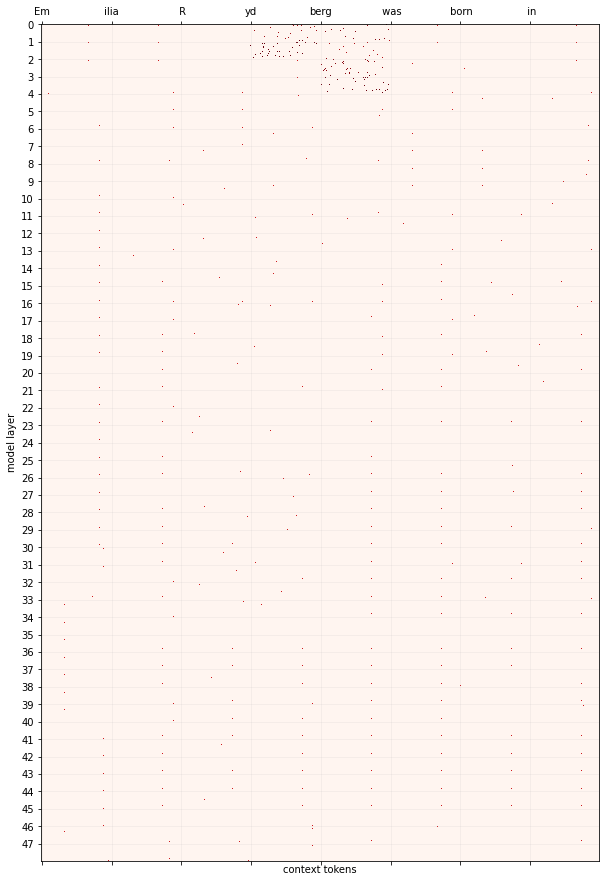

In the plots, each point of red is a specific neuron in an MLP layer in GPT2-xl from Hugging Face. The rectangular shape of the layers in the plot is an arbitrary convenience for visualization (unlike how the shape of layers in a CNN would actually be relevant).
My hope is that I can use this information to collect a dataset of neuron -> context associations which I can then use as edges in a weighted bipartite graph to do clustering of the neurons in the transformer along the same line as what Filan et al. 2021 (3) did in CNNs. I'm running this now, starting with the set of 1200 or so facts given in the demo notebook. It's pretty slow
Notes
- Thanks to my AGI Safety Fundamentals discussion group for sparking ideas and giving reading suggestions, in particular the discussion leader William Saunders.
- Locating and Editing Factual Knowledge in GPT
Kevin Meng*1, David Bau*2, Alex Andonian1, Yonatan Belinkov3
1MIT CSAIL, 2Northeastern University, 3Technion - IIT; *Equal Contribution - Clusterability in Neural Networks
Daniel Filan1, *, Stephen Casper2, *, Shlomi Hod3, *,
Cody Wild1, Andrew Critch1, Stuart Russell
1 comments
Comments sorted by top scores.
comment by Nathan Helm-Burger (nathan-helm-burger) · 2022-03-30T21:28:29.267Z · LW(p) · GW(p)
Looking at a couple hundred of these plots for the MLP neurons, I see two obvious patterns which can occur alone or together/overlapping. One pattern is a 'vertical group', a narrow band that runs through many layers. The other pattern is a 'horizontal group', which is lots of involvement within one layer.
Now I'm generating and looking at plots which do both the MLP neurons and the attention heads.