Discussion on the machine learning approach to AI safety
post by Vika · 2018-11-01T20:54:39.195Z · LW · GW · 3 commentsContents
Assumptions in ML safety Approaches to specification problems None 3 comments
(Cross-posted from personal blog.)
At this year's EA Global London conference, Jan Leike and I ran a discussion session on the machine learning approach to AI safety. We explored some of the assumptions and considerations that come up as we reflect on different research agendas. Slides for the discussion can be found here.
The discussion focused on two topics. The first topic examined assumptions made by the ML safety approach as a whole, based on the blog post Conceptual issues in AI safety: the paradigmatic gap. The second topic zoomed into specification problems, which both of us work on, and compared our approaches to these problems.
Assumptions in ML safety
The ML safety approach focuses on safety problems that can be expected to arise for advanced AI and can be investigated in current AI systems. This is distinct from the foundations approach, which considers safety problems that can be expected to arise for superintelligent AI, and develops theoretical approaches to understanding and solving these problems from first principles.
While testing on current systems provides a useful empirical feedback loop, there is a concern that the resulting solutions might not be relevant for more advanced systems, which could potentially be very different from current ones. The Paradigmatic Gap post made an analogy between trying to solve safety problems with general AI using today's systems as a model, and trying to solve safety problems with cars in the horse and buggy era. The horse to car transition is an example of a paradigm shift that renders many current issues irrelevant (e.g. horse waste and carcasses in the streets) and introduces new ones (e.g. air pollution). A paradigm shift of that scale in AI would be deep learning or reinforcement learning becoming obsolete.
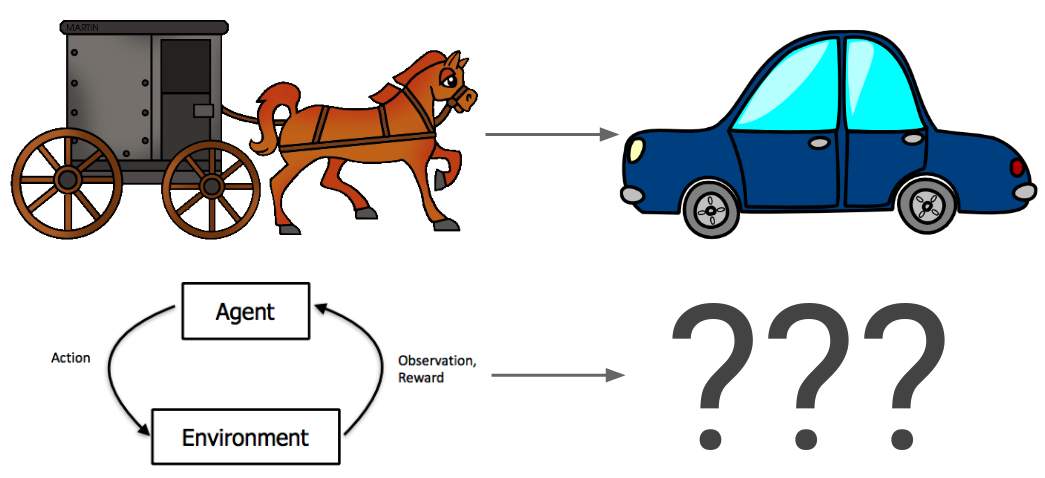
If we imagine living in the horse carriage era, could we usefully consider possible safety issues in future transportation? We could invent brakes and stop lights to prevent collisions between horse carriages, or seat belts to protect people in those collisions, which would be relevant for cars too. Jan pointed out that we could consider a hypothetical scenario with super-fast horses and come up with corresponding safety measures (e.g. pedestrian-free highways). Of course, we might also consider possible negative effects on the human body from moving at high speeds, which turned out not to be an issue. When trying to predict problems with powerful future technology, some of the concerns are likely to be unfounded - this seems like a reasonable price to pay for being proactive on the concerns that do pan out.
Getting back to machine learning, the Paradigmatic Gap post had a handy list of assumptions that could potentially lead to paradigm shifts in the future. We went through this list, and rated each of them based on how much we think ML safety work is relying on it and how likely it is to hold up for general AI systems (on a 1-10 scale). These ratings were based on a quick intuitive judgment rather than prolonged reflection, and are not set in stone.
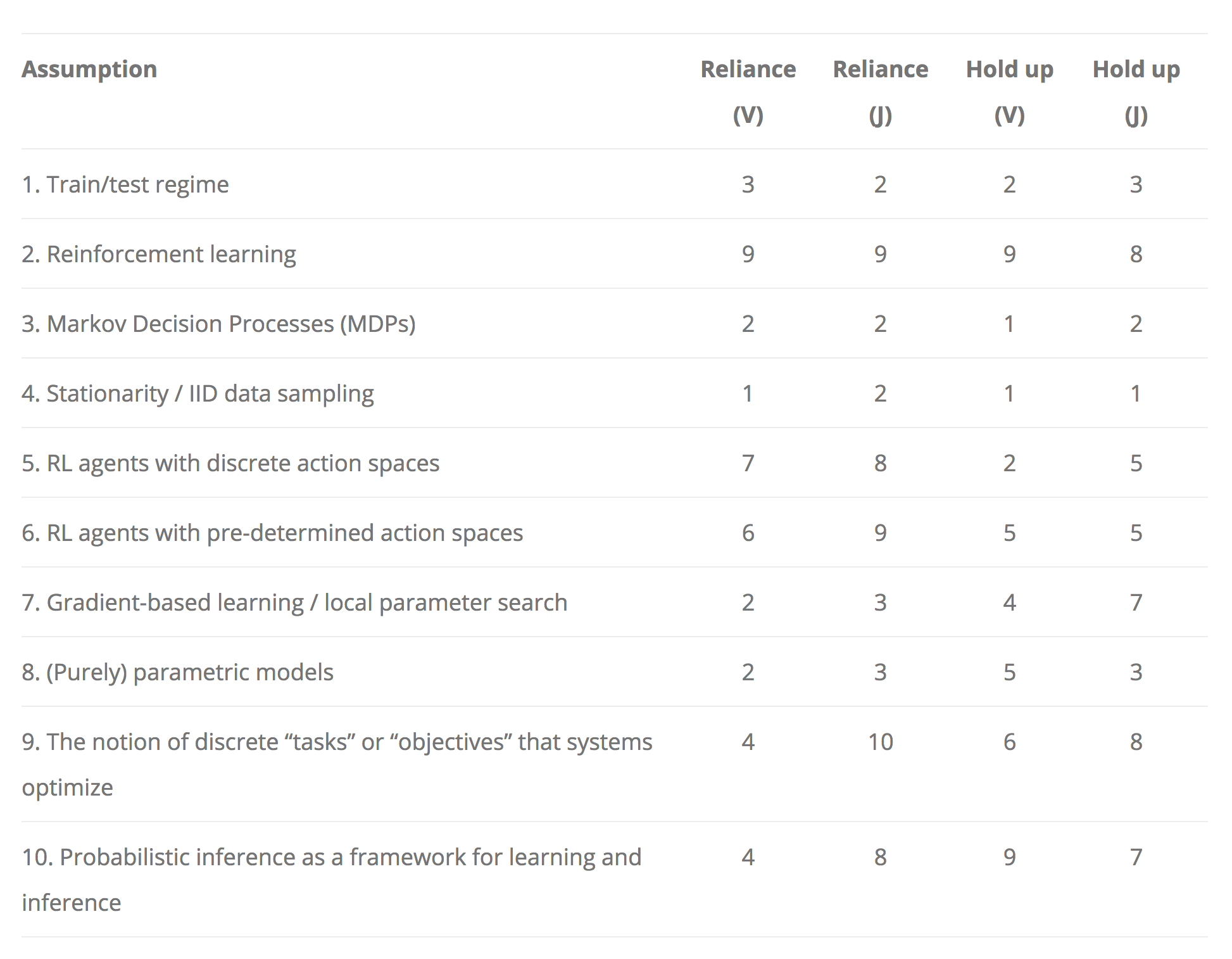
Our ratings agreed on most of the assumptions:
- We strongly rely on reinforcement learning, defined as the general framework where an agent interacts with an environment and receives some sort of reward signal, which also includes methods like evolutionary strategies. We would be very surprised if general AI did not operate in this framework.
- Discrete action spaces (#5) is the only assumption that we strongly rely on but don't strongly expect to hold up. I would expect effective techniques for discretizing continuous action spaces to be developed in the future, so I'm not sure how much of an issue this is.
- The train/test regime, MDPs and stationarity can be useful for prototyping safety methods but don't seem difficult to generalize from.
- A significant part of safety work focuses on designing good objective functions for AI systems, and does not depend on properties of the architecture like gradient-based learning and parametric models (#7-8).
We weren't sure how to interpret some of the assumptions on the list, so our ratings and disagreements on these are not set in stone:
- We interpreted #6 as having a fixed action space where the agent cannot invent new actions.
- Our disagreement about reliance on #9 was probably due to different interpretations of what it means to optimize discrete tasks. I interpreted it as the agent being trained from scratch for specific tasks, while Jan interpreted it as the agent having some kind of objective (potentially very high-level like "maximize human approval").
- Not sure what it would mean not to use probabilistic inference or what the alternative could be.
An additional assumption mentioned by the audience is the agent/environment separation. The alternative to this assumption is being explored by MIRI in their work on embedded agents. I think we rely on this a lot, and it's moderately likely to hold up.
Vishal pointed out a general argument for the current assumptions holding up. If there are many ways to build general AI, then the approaches with a lot of resources and effort behind them are more likely to succeed (assuming that the approach in question could produce general AI in principle).
Approaches to specification problems
Specification problems arise when specifying the objective of the AI system. An objective specification is a proxy for the human designer's preferences. A misspecified objective that does not match the human's intention can result in undesirable behaviors that maximize the proxy but don't solve the goal.
There are two classes of approaches to specification problems - human-in-the-loop (e.g. reward learning or iterated amplification) and problem-specific (e.g. side effects / impact measures or reward corruption theory). Human-in-the-loop approaches are more general and can address many safety problems at once, but it can be difficult to tell when the resulting system has received the right amount and type of human data to produce safe behavior. The two approaches are complementary, and could be combined by using problem-specific solutions as an inductive bias for human-in-the-loop approaches.
We considered some arguments for using pure human-in-the-loop learning and for complementing it with problem-specific approaches, and rated how strong each argument is (on a 1-10 scale):
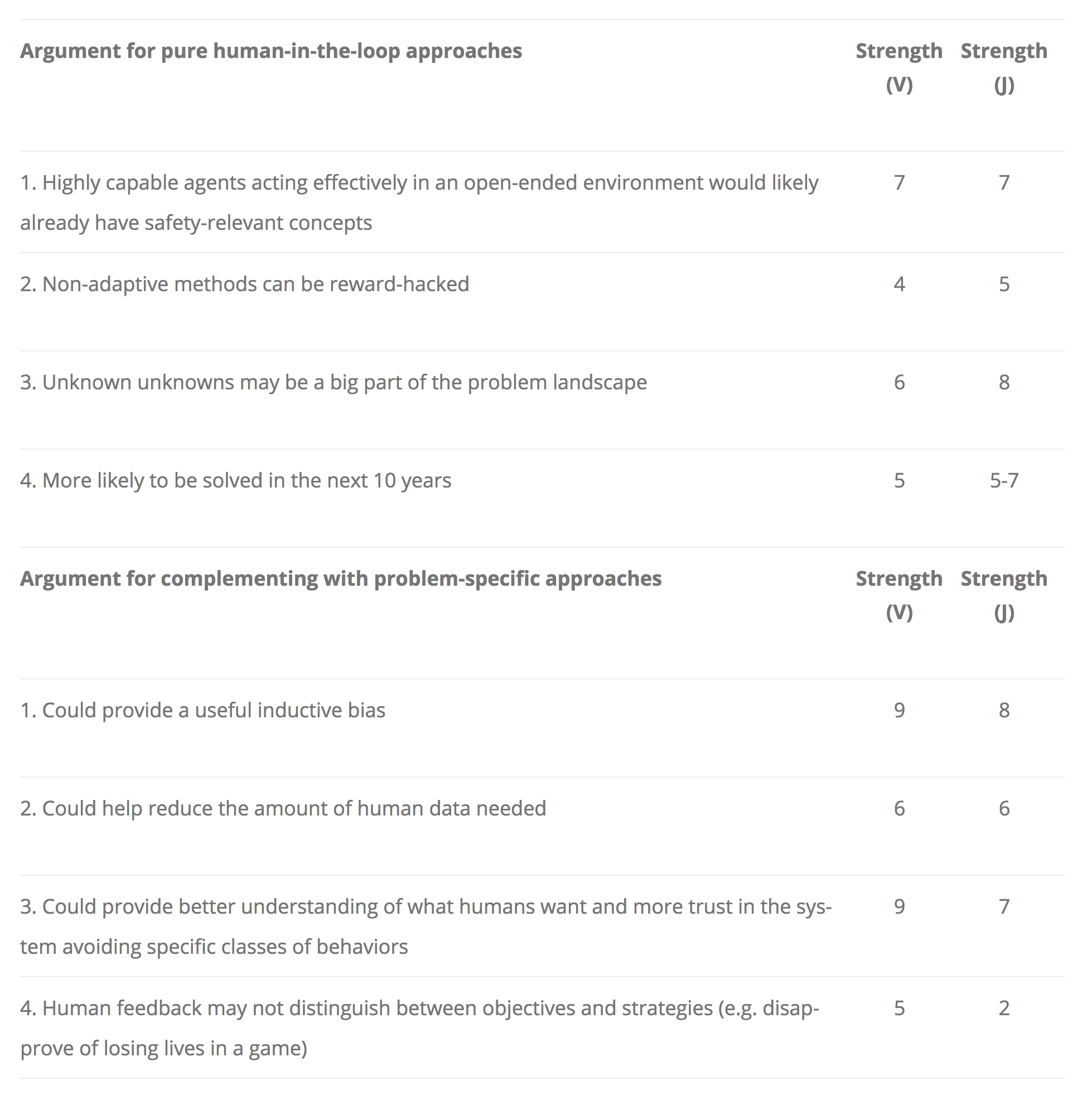
Our ratings agreed on most of these arguments:
- The strongest reasons to focus on pure human-in-the-loop learning are #1 (getting some safety-relevant concepts for free) and #3 (unknown unknowns).
- The strongest reasons to complement with problem-specific approaches are #1 (useful inductive bias) and #3 (higher understanding and trust).
- Reward hacking is an issue for non-adaptive methods is an issue (e.g. if the reward function is frozen in reward learning), but making problems-specific approaches adaptive does not seem that hard.
The main disagreement was about argument #4 for complementing - Jan expects the objectives/strategies issues to be more easily solvable than I do.
Overall, this was an interesting conversation that helped clarify my understanding of the safety research landscape. This is part of a longer conversation that is very much a work in progress, and we expect to continue discussing and updating our views on these considerations.
3 comments
Comments sorted by top scores.
comment by habryka (habryka4) · 2018-11-01T21:13:09.152Z · LW(p) · GW(p)
(Replaced the broken tables with images, since we currently don't have table support in our editor. Should work reasonably well for most purposes.)
Replies from: Vikacomment by Mindey · 2018-11-02T01:11:56.011Z · LW(p) · GW(p)
Safety is assurance of pursuit of some goals (Y) - some conditions. So, one thing that's unlikely to have a paradigmatic shift, is search for actions to satisfy conditions:
1. Past: dots, line, regression
2. Present: objects, hyperplane, deep learning
3. Future: ?, ?, ?
Both 1. and 2. are just a way to satisfy conditions, that is, solve equation F(X)=Y (equation solving as processes (X) to model world (F), to satisfy conditions (Y)). The equation model had not changed for ages, and is so fundamental, that I would tend to assume, that world's processes X will continue to parametrize world F by being part of it, to satisfy conditions Y, no matter what the 3. is.
I wouldn't expect the fundamental goals (specific conditions Y) to change either: the world's entropy (F) (which is how world manifests, hence world's entropy is the world) trains learning processes such as life (which is fundamentally mutating replicators) to pursue goal Y which may be formulated as just information about the entropy to counteract it (create world's F model F' to minimize change = reach stability).
Islands of stability exist for chemical elements, for life forms (mosquitoes are an island of stability among processes in existence, although they don't have to be very intelligent to persist), and I believe they exist for the artificial life (AI/ML systems) too, just not clear where exactly these islands of stability will be.
Where the risk to civilization may lie, is in the emergence of processes evolving independently of the existing civilization (see symbiosis in coordination problem [LW · GW] in biological systems), because of incorrect payoffs, making useful services parasitize our infrastructures (e.g., run more efficient economically self-sustaining processes on computers).