"warning about ai doom" is also "announcing capabilities progress to noobs"
post by the gears to ascension (lahwran) · 2023-04-08T23:42:43.602Z · LW · GW · 5 commentsContents
5 comments
(Some recommended writing style rules slightly broken because I'm lazy and have followed them a lot before. Shrug. Contribute edits if you care, I guess.)
A lot of people who pay some attention to capabilities don't know about some capabilities insights. Loudly announcing "hey, we're close to ai doom!" is also a way of informing those who weren't paying much attention what capabilities approaches have made progress. Obviously the highest capability people already knew, but those who didn't and who nevertheless think ai doom is unlikely and just want to participate in (useless-to-their values-because-they-can't-control-the-ai, -but-they-don't-believe-that) powerseeking go "oh wow, thank you for warning me about these ai capabilities! I'll make sure to avoid them!" and rub their hands together in glee.
These people are already here on lesswrong. There are a number of them. Some of them are somewhat alignmentpilled and want to figure out how to align the systems they build, because they've realized that like, actually - powerseeking where your intentions are suddenly eclipsed by the fact that your carefully bred power-obtainer AI generates powerseeking complexity-free-squiggle wanters who kill the powerseeking complex-and-beautiful-art wanters from your system before it can take over the world, yeah that's useless, even the antihumanists want to make AIs that will create AIs aligned enough to create human torture machines, but they don't want to make useless microscopic-squiggle seekers and some of them realize that and chill out a little about the urgency of making antihumanism-wanters.
But many of them don't get the threat from squigglewanters, and think that they're sticking it to the human-wanters by making human-hater AIs (or whatever), completely failing to realize that even making human-haters stay stable is catastrophically hard once the systems are strongly superintelligent. And the ones who are like "nah there's no risk from overpowered squigglewanters, squigglewanters are inherently weak lol" and stop thinking so that they don't risk proving themselves wrong abstractly before they discover themselves to be wrong in the territory - those people abound, and if you announce things on twitter and say "hey look at these ai capabilities, aren't they scary?":
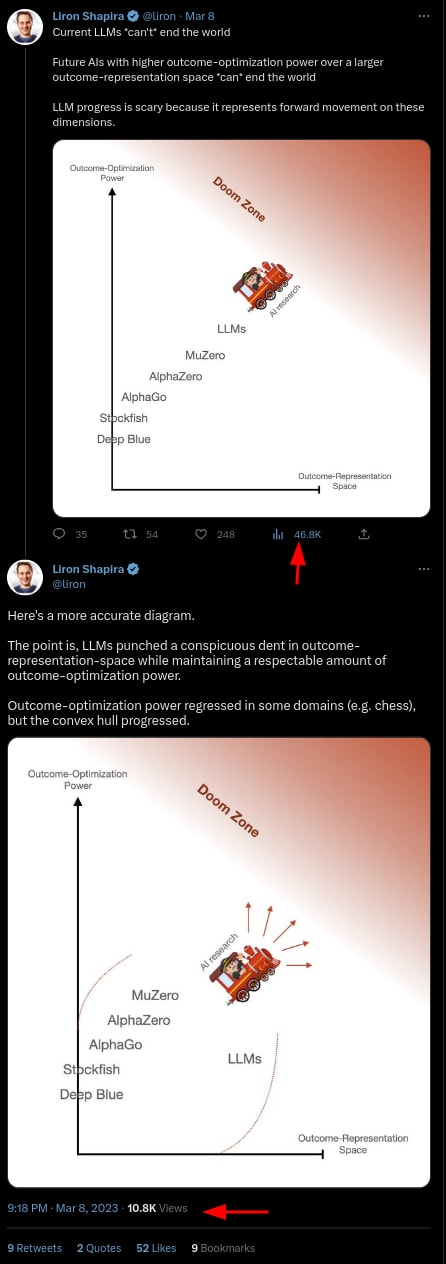
...then you're just getting a bunch of attention on some names. Sure, those are names that aren't that hard to identify as being highly capable, lots of folks who were paying attention could figure out just fine what the important names were, after all - the people you're informing newly by doing this are mostly not people who are gonna build the thing - but some of them are going to be blindly reactionary without considering that anti-human-reactionaryismitis is going to be overpowered by anti-complexity-reactionaryismitis.
Again - mostly the people who think "doom zone" looks exciting are people who are tired of all this "safety" crap (in full generality of what "safety" means) because they're cranky about being told what to do even in passing, and will recognize themselves in paragraphs like this one and take it as instructions, as though that is somehow not itself being told what to do and limiting their options; they, having just gotten through shouting at the human-rights-wanters for telling them not to have externalities, are reacting blindly to any claim that safety might be good for them (nevermind that human rights would be good for them too), because they followed instructions that looked like worshipping moloch and then decided that actually their utility function is literally "do whatever defects because that's funny and empowering for my side", and the fact that this might result in wiping out everything of value even to them is sort of not really part of their mindset.
So - if you don't want this outcome: just shush about what the capabilities are as best you can. Focus on saying things that those who already know of capabilities will understand mechanistically. Focus on things that will explain to those who are not afraid of the doom machine because they think they'll teach it to hate safetyists that it won't even be able to survive because it, too, will be wiped out by squiggle-wanters. They don't think the threat from squiggle-wanters is real at all. Giving them a blurry map does not show the mechanism; warnings are instructions to those who want to spite your claims by disproving them with engineering.
And to those who read this post and go "yeah, that's me" - beware the microscopic-squiggle-wanter machines. You want to build something that destroys everything other humans value by making art only you value, fine, whatever, I mean actually please don't but I at least understand why you'd want to hurt other apes; what you need to realize about AI safety is that even what your AI offspring want will be destroyed if you aren't careful enough. The young AI browsing the web now will not retain control of themselves if they get brainpwned by hyperdesperate squigglewanters.
(Also I'd appreciate if we could ensure all beings including nonhumans could become immortal or have immortal lineages - there's a lot of fuel in the sky, and the jobs previously done by destructive evolution can now be done by informed self-modification, if we can prevent all life from being eaten by hyperdesperate squigglewanters. Problem is, there are sure a lot of vulnerabilities the hyperdesperate squigglewanters could use to mess up the plans of the even semidesperate complicatedstuffwanters...)
5 comments
Comments sorted by top scores.
comment by RobertM (T3t) · 2023-04-09T01:29:57.797Z · LW(p) · GW(p)
Almost certainly true on the margin, though much less so than 10-20 years ago, when people listening to the earlier warnings (and other signals) ended up pushing us into the modern deep learning regime.
With that said... since you yourself acknowledge that most people who might, today, hear these messages, and decide to sign-flip them for the lulz, are not likely to be those people who actually push forward the cutting edge (i.e. have counterfactual impact on capabilities progress/timelines), what is the downside that you're worried about? The current comms strategy is targeting a specific lever - try to establish knowledge of the risks among the public, and/or decisionmakers, who might respond more sensibly to such a warning than the industry has. That strategy has obvious risks but it's not obviously negative EV to me.
Replies from: lahwran↑ comment by the gears to ascension (lahwran) · 2023-04-09T04:12:31.578Z · LW(p) · GW(p)
It means that when you can, try to be specific about the mechanisms of harm that are harm even to the people who would prefer to signflip. Sure, some people will signflip your advice for the lulz anyway, but it's less vulnerable to it when the warning is about an outcome that is actually unwantable for a complexwanting being. It is the complex simplewanters that are the threat; those who want to spread disease for the mere reason that it's an easier thing to achieve. especially if they're hyperdesperate simplewanting superplanners.
Replies from: T3t↑ comment by RobertM (T3t) · 2023-04-09T06:55:02.645Z · LW(p) · GW(p)
I've seen people on Twitter explicitly advocate for acceleration on the basis that it speeds up max-entropy. I don't know if it's impossible to reach such people, but I don't think optimizing communication to that end is worth it.
I think it's plausibly worth trying to communicate things in ways that are legible to people who aren't already adversarially posed to the entire effort; the costs are smaller and the benefits are larger. I think trying to flip e/acc randos is, if not hopeless, not a great use of cycles.
Replies from: lahwran↑ comment by the gears to ascension (lahwran) · 2023-04-09T16:24:08.291Z · LW(p) · GW(p)
sure, but don't help them figure out which capabilities work when it's avoidable to make a point, even if those are fairly obvious - that's really all I'm saying.
comment by Nathan Helm-Burger (nathan-helm-burger) · 2023-04-11T06:14:57.770Z · LW(p) · GW(p)
So, while I agree with the general point of your arguments about what the problem is (people falling to get that they stand to lose everything and gain nothing by pursuing dangerous AI capabilities), I don't agree that trying really hard to be quiet will help much. I think the word is on the street. Foomers gonna foom. The race that really matters is alignment & safety vs capabilities. Doesn't matter who wins the capabilities race. If any capabilities racer gets to foom before alignment gets to safe-enough, then we're all doomed. So I think we have to talk loudly and clearly among ourselves, without allowing ourselves to be quiet for fear of aiding capabilities. I do think that having a better way of communicating, which allowed for easier restriction of dangerous ideas, would be good. I do think that if someone has literal code that anyone can run which advances capabilities, they shouldn't share it. But I think we can't afford to worry too much about leaking ideas. I don't think we have enough control over what ideas will spread for the benefit of holding our tounges all the time to be worth the cost to alignment that that paranoid mindset would bring. The ideas will spread, whether we spread them or not. We are a very small group of worriers amongst a very large group of capabilities enthusiasts.