What is Wei Dai's Updateless Decision Theory?
post by AlephNeil · 2010-05-19T10:16:51.228Z · LW · GW · Legacy · 70 commentsContents
What is Naïve Decision Theory? When does NDT fail? How Does UDT Deal With These Problems? Is that it? (Doesn't that give the wrong answer to the Smoking Lesion problem?) Why Is It Rational To Act In The Way UDT Prescribes? Addendum: Do Questions About Subjective Probability Have Answers Irrespective Of One's Decision Theory And Utility Function? None 70 comments
As a newcomer to LessWrong, I quite often see references to 'UDT' or 'updateless decision theory'. The very name is like crack - I'm irresistably compelled to find out what the fuss is about.
Wei Dai's post is certainly interesting, but it seemed to me (as a naive observer) that a fairly small 'mathematical signal' was in danger of being lost in a lot of AI-noise. Or to put it less confrontationally: I saw a simple 'lesson' on how to attack many of the problems that frequently get discussed here, which can easily be detached from the rest of the theory. Hence this short note, the purpose of which is to present and motivate UDT in the context of 'naive decision theory' (NDT), and to pre-empt what I think is a possible misunderstanding.
First, a quick review of the basic Bayesian decision-making recipe.
What is Naïve Decision Theory?
You take the prior and some empirical data and calculate a posterior by (i) working out the 'likelihood function' of the data and (ii) calculating prior times likelihood and renormalising. Then you calculate expected utilities for every possible action (wrt to this posterior) and maximize.
Of course there's a lot more to conventional decision theory than this, but I think one can best get a handle on UDT by considering it as an alternative to the above procedure, in order to handle situations where some of its presuppositions fail.
(Note: NDT is especially 'naïve' in that it takes the existence of a 'likelihood function' for granted. Therefore, in decision problems where EDT and CDT diverge, one must 'dogmatically' choose between them at the outset just to obtain a problem that NDT regards as being well-defined.)
When does NDT fail?
The above procedure is extremely limited. Taking it exactly as stated, it only applies to games with a single player and a single opportunity to act at some stage in the game. The following diagram illustrates the kind of situation for which NDT is adequate:

This is a tree diagram (as opposed to a causal graph). The blue and orange boxes show 'information states', so that any player-instance within the blue box sees exactly the same 'data'. Hence, their strategy (whether pure or mixed) must be the same throughout the box. The branches on the right have been greyed out to depict the Bayesian 'updating' that the player following NDT would do upon seeing 'blue' rather than 'orange'--a branch is greyed out if and only if it fails to pass through a blue 'Player' node. Of course, the correct strategy will depend on the probabilities of each of Nature's possible actions, and on the utilities of each outcome, which have been omitted from the diagram. The probabilities of the outward branches from any given 'Nature' node are to be regarded as 'fixed at the outset'.
Now let's consider two generalisations:
- What if the player may have more than one opportunity to act during the game? In particular, what if the player is 'forgetful' in the sense that (i) information from 'earlier on' in the game may be 'forgotten', even such that (ii) the player may return to an information state several times during the same branch.
- What if, in addition to freely-willed 'Player' nodes and random 'Nature' nodes, there is a third kind of node where the branch followed depends on the Player's strategy for a particular information state, regardless of whether that strategy has yet been executed. In other words, what if the universe contains 'telepathic robots' (whose behaviour is totally mechanical - they're not trying to maximize a utility function) that can see inside the Player's mind before they have acted?
It may be worth remarking that we haven't even considered the most obvious generalisation: The one where the game includes several 'freely-willed' Players, each with their own utility functions. However, UDT doesn't say much about this - UDT is intended purely as an approach to solving decision problems for a single 'Player', and to the extent that other 'Players' are included, they must be regarded as 'robots' (of the non-telepathic type) rather than intentional agents. In other words, when we consider other Players, we try to do the best we can from the 'Physical Stance' (i.e. try to divine what they will do from their 'source code' alone) rather than rising to the 'Intentional Stance' (i.e. put ourselves in their place with their goals and see what we think is rational).
Note: If a non-forgetful player has several opportunities to act then, as long as the game only contains Player and Nature nodes, the Player is able to calculate the relevant likelihood function (up to a constant of proportionality) from within any of their possible information states. Therefore, they can solve the decision problem recursively using NDT, working backwards from the end (as long as the game is guaranteed to end after a finite number of moves.) If, in addition to this, the utility function is 'separable' (e.g. a sum of utilities 'earned' at each move) then things are even easier: each information state gives us a separate NDT problem, which can be solved independently of the others. Therefore, unless the player is forgetful, the 'naïve' approach is capable of dealing with generalisation 1.
Here are two familiar examples of generalisation 1 (ii):
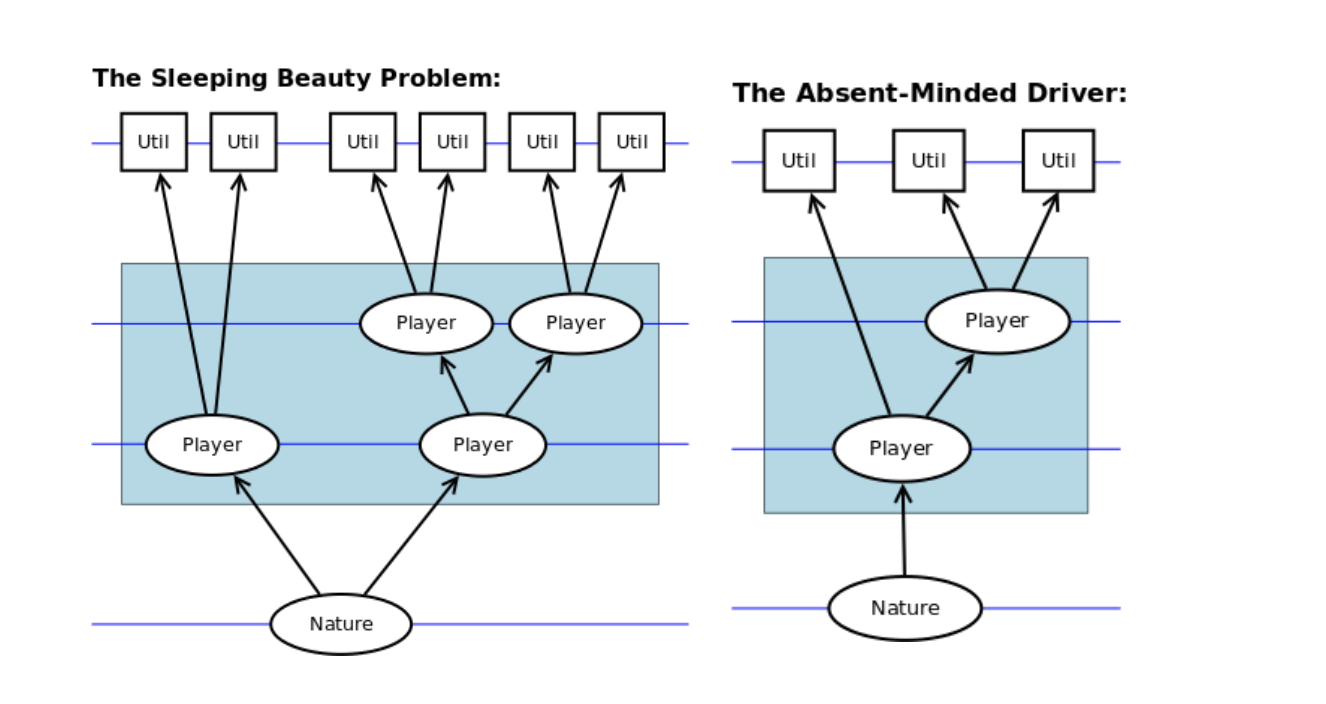
Note: The Sleeping Beauty problem is usually presented as a question about probabilities ("what is the Player's subjective probability that the coin toss was heads?") rather than utilities, although for no particularly good reason the above diagram depicts a decision problem. Another point of interest is that the Absent-Minded Driver contains an extra ingredient not present in the SB problem: the player's actions affect how many player-instances there are in a branch.
Now a trio of notorious problems exemplifying generalisation 2:



How Does UDT Deal With These Problems?
The essence of UDT is extremely simple: We give up the idea of 'conditioning on the blue box' (doing Bayesian reasoning to obtain a posterior distribution etc) and instead just choose the action (or more generally, the probability distribution over actions) that will maximize the unconditional expected utility.
So, UDT:
- Solves the correct equation in the Absent-Minded Driver problem.
- One-boxes.
- Submits to a Counterfactual Mugging.
- Pays after hitchhiking.
Is that it? (Doesn't that give the wrong answer to the Smoking Lesion problem?)
Yes, that's all there is to it.
Prima facie, the tree diagram for the Smoking Lesion would seem to be identical to my diagram of Newcomb's Problem (except that the connection between Omega's action and the Player's action would have to be probabilistic), but let's look a little closer:
Wei Dai imagines the Player's action to be computed by a subroutine called S, and although other subroutines are free to inspect the source code of S, and try to 'simulate' it, ultimately 'we' the decision-maker have control over S's source code. In Newcomb's problem, Omega's activities are not supposed to have any influence on the Player's source code. However, in the Smoking Lesion problem, the presence of a 'lesion' is somehow supposed to cause Player's to choose to smoke (without altering their utility function), which can only mean that in some sense the Player's source code is 'partially written' before the Player can exercise any control over it. However, UDT wants to 'wipe the slate clean' and delete whatever half-written nonsense is there before deciding what code to write.
Ultimately this means that when UDT encounters the Smoking Lesion, it simply throws away the supposed correlation between the lesion and the decision and acts as though that were never a part of the problem. So the appropriate tree diagram for the Smoking Lesion problem would have a Nature node at the bottom rather than an Omega node, and so UDT would advise smoking.
Why Is It Rational To Act In The Way UDT Prescribes?
UDT arises from the philosophical viewpoint that says things like
- There is no such thing as the 'objective present moment'.
- There is no such thing as 'persisting subjective identity'.
- There is no difference in principle between me and a functionally identical automaton.
- When a random event takes place, our perception of a single definite outcome is as much an illusion of perspective as the 'objective present'--in reality all outcomes occur, but in 'parallel universes'.
If you take the above seriously then you're forced to conclude that a game containing an Omega node 'linked' to a Player node in the manner above is isomorphic (for the purposes of decision theory) to the game in which that Omega node is really a Player node belonging to the same information state. In other words, 'Counterfactual Mugging' is actually isomorphic to:

This latter version is much less of a headache to think about! Similarly, we can simplify and solve The Absent-Minded Driver by noting that it is isomorphic to the following, which can easily be solved:

Even more interesting is the fact that the Absent-Minded Driver turns out to be isomorphic to (a probabilistic variant of) Parfit's Hitchhiker (if we interchange the Omega and Player nodes in the above diagram).
Addendum: Do Questions About Subjective Probability Have Answers Irrespective Of One's Decision Theory And Utility Function?
In the short time I've been here, I have seen several people arguing that the answer is 'no'. I want to say that the answer is 'yes' but with a caveat:
We have puzzles like the Absent-Minded Driver (original version) where the player's strategy for a particular information state affects the probability of that information state recurring. It's clear that in such cases, we may be unable to assign a probability to a particular event until the player settles on a particular strategy. However, once the player's strategy is 'set in stone', then I want to argue that regardless of the utility function, questions about the probability of a given player-instance do in fact have canonical answers:
Let's suppose that each player-instance is granted a uniform random number in the set [0,1]. In a sense this was already implicit, given that we had no qualms about considering the possibility of a mixed strategy. However, let's suppose that each player-instance's random number is now regarded as part of its 'information'. When a player sees (i) that she is somewhere within the 'blue rectangle', and (ii) that her random number is α, then for all player-instances P within the rectangle, she can calculate the probability (or rather density) of the event "P's random number is α" and thereby obtain a conditional probability distribution over player-instances within the rectangle.
Notice that this procedure is entirely independent of decision theory (again, provided that the Player's strategy has been fixed).
In the context of the Sleeping-Beauty problem (much discussed of late) the above recipe is equivalent to asserting that (a) whenever Sleeping Beauty is woken, this takes place at a uniformly distributed time between 8am and 9am and (b) there is a clock on the wall. So whenever SB awakes at time α, she learns the information "α is one of the times at which I have been woken". A short exercise in probability theory suffices to show that SB must now calculate 1/3 probabilities for each of (Heads, Monday), (Tails, Monday) and (Tails, Tuesday) [which I think is fairly interesting given that the latter two are, as far as the prior is concerned, the very same event].
One can get a flavour of it by considering a much simpler variation: Let α and β be 'random names' for Monday and Tuesday, in the sense that with probability 1/2, (α, β) = ("Monday", "Tuesday") and with probability 1/2, (α, β) = ("Tuesday", "Monday"). Suppose that SB's room lacks a clock but includes a special 'calendar' showing either α or β, but that SB doesn't know which symbol refers to which day.
Then we obtain the following diagram:

Nature's first decision determines the meaning of α and β, and its second is the 'coin flip' that inaugurates the Sleeping Beauty problem we know and love. There are now two information states, corresponding to SB's perception of α or β upon waking. Thus, if SB sees the calendar showing α (the orange state, let's say) it is clear that the conditional probabilities for the three possible awakenings must be split (1/3, 1/3, 1/3) as above (note that the two orange 'Tuesday' nodes correspond to the same awakening.)
70 comments
Comments sorted by top scores.
comment by Vladimir_Nesov · 2010-05-19T11:08:29.078Z · LW(p) · GW(p)
I believe the discussion of UDT is spot on, and a very good summary placing various thought experiments in its context (though reframing Smoking Lesion to get the correct answer seems like cheating).
I have trouble understanding your second point about Sleeping Beauty (and DT-independent probabilities).
Replies from: AlephNeil↑ comment by AlephNeil · 2010-05-19T11:35:24.168Z · LW(p) · GW(p)
Thanks very much! I'm especially pleased that you thought it was accurate.
As for the second point - yeah it seems everyone wants to disagree with me on that :-/
What I describe (perhaps unclearly) is a 'standard recipe' for attaching meaning to statements about indexical probabilities (like "I am at the second intersection" in the absent-minded driver problem) which doesn't depend on decision theory (except in way I noted as the 'caveat').
Perhaps it may be objected that there are other recipes. (One such recipe might be 'take a random branch that has at least one player node on it, then take a random player-instance somewhere along that branch'. This of course gives 1/2 as the answer the Sleeping Beauty problem.)
I don't really have any 'absolute justification' for mine, except that it gives the solution to an elegant decision problem: "At every player-instance, try to work out which player-instance you are, so as to minimize -log(subjective probability) at that instance." (With it being implicit that your final utility is the sum of all such 'log(subjective probability)' expressions along the branch.)
Replies from: Vladimir_Nesov, Academian, Stuart_Armstrong↑ comment by Vladimir_Nesov · 2010-05-19T12:05:19.547Z · LW(p) · GW(p)
You can of course define probability in a way that doesn't refer to any specific decision theory, thus making it "independent" of decision theories. But probability is useful exactly as half-of-decision-theory, where you just add "utility" ingredient to get the correct decisions out. This doesn't work well where indexical uncertainty or mind copying are involved, because "probabilities" you get in those situations (defined in such a way that the resulting decisions are as you'd prefer, as in justification of probability by a bet) depend more on your preference than normally. In simpler situations, maximum entropy at least takes care of situations you don't terminally distinguish in your values, in a way that is independent on further details of your values.
↑ comment by Academian · 2010-05-19T11:52:25.265Z · LW(p) · GW(p)
Awesome, you even figured out that anthropic indexical belief updating is exactly what minimizes world-expected total surprisal (when non-indexical beliefs about relative world likelihoods are fixed). The proof is just Jensen's inequality :)
That's another thing I've been delaying a top-level post on: an "explaining away" of anthropic updating by classifying precisely which decision problems it gives naive correct solutions to. I expect I'll be too busy for the next couple of months to write it in the detail I'd like, but then you can expect to see some introductory content from me on that... unless you write it yourself, which would be even better!
↑ comment by Stuart_Armstrong · 2010-05-22T08:39:38.941Z · LW(p) · GW(p)
Have you seen Full Non-Idexical Conditioning? (http://www.cs.toronto.edu/~radford/ftp/anth.pdf) Though the theory is mathematically incorrect, it's very nearly right, and it's very similar to your sleeping beaty approach...
comment by PhilGoetz · 2010-05-20T01:59:51.916Z · LW(p) · GW(p)
I was really hoping that a post called "What is UDT?" would explain what UDT is. You've got pages of discussion and diagrams, but only one sentence describing what UDT is.
Replies from: AlephNeil↑ comment by AlephNeil · 2010-05-20T07:26:30.771Z · LW(p) · GW(p)
Yeah, but the thing is: I don't think there is very much to it. (And in fact about 25% of my motivation for writing this is to see whether others will 'correct me' on that.)
If I say "it's extremely simple, it's blurgh" that means among other things "it is blurgh". Not "it is blurgh and whole bunch of other stuff which I'm never going to get round to."
To be fair, one thing I haven't mentioned at all is the concept of logical uncertainty, which plays a critical role in TDT (which was after all the motivation for UDT) and in a number of past threads where UDT was under discussion. But again, I personally don't think we need to go into this to explain what UDT is.
Replies from: PhilGoetz↑ comment by PhilGoetz · 2010-05-20T17:51:02.981Z · LW(p) · GW(p)
The description you gave is not enough for me to have any idea what it is. This seems to defeat the purpose of your post.
Replies from: AlephNeil↑ comment by AlephNeil · 2010-05-20T23:56:29.862Z · LW(p) · GW(p)
So what are you saying?
(a) You disagree that UDT is what I say it is? (b) You don't understand the sentence where I say what UDT is? (c) You take for granted that what I've talked about as UDT is indeed part of UDT but you think all the non-trivial stuff hasn't been touched on?
Replies from: PhilGoetz↑ comment by PhilGoetz · 2010-05-24T21:45:52.399Z · LW(p) · GW(p)
(b). But you don't need to try to explain it - I need to study Wei Dai's posts. After which your post might make perfect sense to me. I was just hoping, from its name, that I wouldn't have to do that.
Replies from: AlephNeil↑ comment by AlephNeil · 2010-05-25T03:58:12.047Z · LW(p) · GW(p)
It's a good idea to look at Wei's posts, of course, but in terms of presentation, the original UDT post is a very long way away from mine, and it won't immediately be evident why I phrased my definition of UDT as I did.
If you want to understand my post purely on its own terms, then the key concept (besides probability and conditional probability) is just that of a game. If we have a one-player game, and we fix the player's strategy, then we obtain a probability distribution over 'branches', and a utility lying at the end of each branch. And these are exactly the ingredients we need to calculate an expected utility. So UDT is simply the instruction 'choose the strategy that yields the greatest expected utility'. The reason why it's "updateless" is that the probability distribution with respect to which we're calculating expected utilities is the 'prior' rather than 'posterior' - we haven't 'conditioned on' the subset of branches that pass through a particular information state.
For each of Newcomb's Problem, Parfit's Hitchhiker, Counterfactual Mugging and the Absent-Minded Driver, there is a sense in which when you 'condition on the blue box' you choose a different strategy than when you don't. (This is paradoxical because, intuitively, what you ought to decide to do at a given time shouldn't depend on whether you're contemplating the decision from afar, timelessly, or actually there 'in the moment'.)
(Technical Note: The concept of 'conditioning on the blue box' can be a bit more complicated than just 'conditioning on an event'. For instance, in the case of Newcomb's problem, you find that one-boxing is optimal if you don't condition on anything, but two-boxing is optimal if you condition on the sigma-algebra generated by the event 'predictor predicts that you will one-box'.)
comment by abramdemski · 2022-09-09T16:41:51.336Z · LW(p) · GW(p)
The images in this classic reference post have gone missing! :(
Replies from: Benito↑ comment by Ben Pace (Benito) · 2022-09-09T17:42:57.022Z · LW(p) · GW(p)
Original images can be seen here.
comment by Morendil · 2010-05-19T10:40:40.155Z · LW(p) · GW(p)
I wish I could say this in a nicer way, but here it is: this post has not clarified UDT for me one bit, and I seem to be more confused now about the topic than I previously was.
The diagrams and lack of explanation of how I'm supposed to interpret them are a large part of why this isn't helpful to me at all.
Replies from: AlephNeil↑ comment by AlephNeil · 2010-05-19T10:52:52.302Z · LW(p) · GW(p)
Thanks - it's helpful even to have negative feedback like this, to get a better idea of where to 'pitch' any future posts I make.
For what it's worth, my post presupposes basic knowledge of probability theory, conditional probabilities and Bayesian reasoning, and enough familiarity with and understanding of the problems mentioned to more or less 'instantly see' how they are related to my diagrammatic depictions.
I guess that won't be very helpful, but I'd be happy to answer any specific questions you may have.
Replies from: cousin_it, Morendil↑ comment by cousin_it · 2010-05-19T10:57:44.179Z · LW(p) · GW(p)
Well, I upvoted both your post and Morendil's comment. I have all the prerequisites you mention, but your diagrams and explanations didn't help me at all. Your post doesn't seem to have any insight that would make anything easier to understand than it was before. But discussion of UDT is always very welcome.
Replies from: AlephNeil↑ comment by AlephNeil · 2010-05-19T11:05:10.537Z · LW(p) · GW(p)
Well, if you understand "choose the strategy that maximizes your unconditional expected utility", with it being implicit that other beings in the universe may be able to 'see' your strategy regardless of whether or not you've executed it yet, then you pretty much understand UDT.
If you already understood this before my post, then it won't have been helpful. If you aren't able to understand that, even after reading my post, but have the prerequisites, then something's going wrong somewhere.
Replies from: SilasBarta↑ comment by SilasBarta · 2010-05-19T11:54:52.821Z · LW(p) · GW(p)
I've only skimmed it so far, and I like the diagrams, but I think they would be helped tremendously by doing something to the Util boxes that indicates their relative goodness.
Replies from: bogus↑ comment by bogus · 2010-05-20T22:50:29.148Z · LW(p) · GW(p)
I agree--AlephNeil, you should add payoffs to the diagrams and perhaps textual descriptions of the games.
I also think that this analysis should be polished up and published in a philosophy or game theory journal, assuming that it's sound and that no one else came up with it before. Newcomb-like problems are much debated in philosophy, and finding a reformulation where the "rational" strategy is to one-box may be a fairly big deal.
Replies from: AlephNeil↑ comment by AlephNeil · 2010-05-21T00:31:35.244Z · LW(p) · GW(p)
Thanks, but it's not my theory - it's by Wei Dai and Vladimir Nesov.
you should add payoffs to the diagrams and perhaps textual descriptions of the games.
Yes, in hindsight this would have made the post much more accessible. Somehow I was imagining that this community has been 'bathed' in these problems for so long that nearly everyone would instantly 'get' the diagrams... or if they didn't then it would be easy and fun to 'fill in the gaps', rather than difficult and confusing.
↑ comment by Morendil · 2010-05-19T11:55:25.307Z · LW(p) · GW(p)
As regards probability it may be useful to think of me as a possibly confused student. This is stuff I'm learning, and there are bound to be gaps in my knowledge.
What do you mean by "unconditional expected utility"?
I understand expectation (probability weighted sum of possible values), I understand utility (measure of satisfaction of an agent's preferences), and I understand conditioning as a basic operation in probability.
In particular, how does your distinction between NDT and UDT play out in numbers in (say) the Sleeping Beauty scenario? How exactly is NDT inadequate there?
Replies from: AlephNeil↑ comment by AlephNeil · 2010-05-19T13:59:05.680Z · LW(p) · GW(p)
The Sleeping Beauty scenario is problematic to discuss because it's posed as a question about probabilities rather than utilities. Let's consider Parfit's Hitchhiker instead. If you'd like some concrete numbers, suppose you get 0 utility if you're left in the desert, 10 if you're taken back to civilisation, but then lose 1 if you have to pay. So the utilities in the 'Util' boxes on my diagram are 9, 10, 0, in that order.
Now, if you have an opportunity to act at all, then you can say with certainty where you are in the tree-diagram: you're at the one-and-only Player node. This corresponds to "I've already been taken to my destination, and now I need to decide whether to pay the driver." Conditional upon being at that node, it's obvious that you maximise your utility by not paying (10 instead of 9).
However, if you make no assumptions about 'the state of the world' (i.e. whether or not you were offered a ride) and ask "Which of the two strategies maximizes my expected utility at the outset?" then the strategy where you pay up will get utility 9, and the one that doesn't will get 0.
So looking at the unconditional expected utility basically means that you deliberately 'forget' the information you have about where you are in the game and just look for "a strategy for the blue box" that will maximize your utility over many start-to-finish iterations of the game.
Replies from: Morendil↑ comment by Morendil · 2010-05-19T16:12:41.442Z · LW(p) · GW(p)
Let's consider Parfit's Hitchhiker instead.
I don't know where the probabilities are supposed to be in that graphical model, so I don't know how to apply my understanding of "expectation". I'm not even sure what I'm supposed to be uncertain about, so I'm not sure how to apply my understanding of "probability".
I don't know what the semantics of nodes and arrows are, either. Labeling the arrows and the "Util" boxes would help.
The Sleeping Beauty scenario is problematic to discuss
That might justify removing it from the OP, or at least moving it out of the critical path across the inferential distance.
because it's posed as a question about probabilities rather than utilities
It isn't clear how you can discuss expectations without discussing probabilities?
In the case of Newcomb's Problem - if Omega is only assumed to have some finite accuracy, say .9 - I can at least start to see how to make it about probabilities and expectations. I'll take a shot at it sometime.
comment by Academian · 2010-05-19T10:55:37.531Z · LW(p) · GW(p)
Thanks for writing this post. I think it's an excellent step toward popularizing UDT/TDT (though I'm still not yet convinced subjective probabilities have a canonical meaning independent of specific decision problems). I recently downloaded some vector graphics software to write a post with much the same content, and much the same motive, so it's a relief to see some of it already written!
Replies from: AlephNeilcomment by martinkunev · 2024-09-27T01:16:10.145Z · LW(p) · GW(p)
This post clarified some concepts for me but also created some confusion:
- For smoking lesion, I don't understand the point about the player's source code being partially written.
- I don't see how sleeping beauty calculates 1/3 probability (there are some formatting errors btw)
comment by Alexander (alexander-1) · 2022-03-14T07:06:44.779Z · LW(p) · GW(p)
Hello, thank you for the post!
All images on this post are no longer available. I'm wondering if you're able to imbed them directly into the rich text :)
comment by [deleted] · 2015-07-07T03:43:51.262Z · LW(p) · GW(p)
Can someone explain this to me in a simpler way? It looks really interesting and I generally assume the premises you've stated for UDT so it may be a useful tool.
Replies from: gjm↑ comment by gjm · 2015-07-07T14:23:57.365Z · LW(p) · GW(p)
UDT says: Instead of choosing actions piecemeal, make a once-for-all choice of how you will behave in all situations. (This choice may affect what happens not only via your actions but also because there may be things in the universe that are able to predict your behaviour and act accordingly.)
That's pretty much it.
More tersely: "Choose strategies, not actions."
What's nice about it: (1) It's simple. (2) In some scenarios (mostly rather implausible ones, but things that resemble them may arise in real life) where other decision theories give "bad" answers (i.e., ones where it seems like different choices would have left you better off) UDT lets you do better than they do.
Example 1: Newcomb's paradox. You are confronted by a superpowered being (conventionally called Omega) who, you have good reason to believe, is fantastically successful in predicting people's actions. It places in front of you two boxes. One is transparent and contains $1. The other is opaque. Omega explains that you may take neither box, either box, or both boxes, that it has already predicted your choice, and that the opaque box contains $1M if Omega predicted you would not take the transparent box and nothing otherwise.
Some decision theories would have you reason as follows: Whatever Omega has done, it has already done and my action now makes no difference to it. Taking the transparent box gets me an extra $1. Taking the opaque box may or may not get me an extra $1M, depending on things now outside my control. So I'll take both boxes. -- And then you almost certainly get just $1.
UDT says: When you are deciding on how you will act in every possible situation, work out what happens for each choice of boxes to take here. The result is (of course) that you should take just the opaque box. So, when the situation actually arises, you take just the opaque box. Omega can reliably predict that you will do so, so you almost certainly get $1M.
Of course you can't really decide ahead of time what you will do in every possible situation. But what you can do is make a commitment that you will always attempt to act as if you had done. So when Omega astonishes you by appearing before you and presenting you with this choice, you can go through the above reasoning even if you've never considered the matter before.
Example 2: Parfit's hitchhiker. You are very rich and utterly selfish, and you are stranded in the desert far from civilization; you will die if you don't get help. A car comes along, you flag it down, and you are surprised to see it being driven by Omega -- who, let's remember, is extremely good at predicting your behaviour. What you would like to say is: "Please, please, please drive me to the nearest city. Then I can get to a bank and give you a big pile of money as a reward for saving my life". But if you follow some varieties of decision theory, then as soon as you're back in the city you will run off and pay Omega nothing; and Omega, having the ability to predict your behaviour, will see this and decline to help. (We shall suppose for the sake of argument that despite Omega's great powers, it is in want of both time and money.)
UDT says: When you are deciding on how you will act in every possible situation, work out what happens for each choice when you get into the city. The result is (of course) that you should pay Omega. So, when the situation actually arises, you pay up. Omega can reliably predict that you will do so, and will almost certainly save your life in order to get the reward.
There is probably no Omega in the real world. But there are other people who are quite good at predicting people's actions; they may be quite good at detecting dishonesty and malicious intent and so forth. Dealing with them may resemble dealing with Omega in some respects.
comment by orthonormal · 2010-05-23T21:17:38.481Z · LW(p) · GW(p)
I like the idea of the graphs, but the way they're drawn is often unenlightening. (E.g. it requires lots of disclaimers on the side, and a paragraph to distinguish Newcomb and the Smoking Lesion.)
Unfortunately, I don't have a better suggestion to offer.
comment by Jonathan_Graehl · 2010-05-21T22:41:57.259Z · LW(p) · GW(p)
Please show your work on your thirder Sleeping Beauty answer, given an observed random bit (α or β upon waking) that's independent of the coin toss. I realize the bit is flipped on Tuesday, which is only observed by Beauty if tails, but a conditionally flipped independent random bit is still independent.
Why is the availability of a random bit necessary and/or sufficient to end the Beauty controversy?
Replies from: AlephNeil↑ comment by AlephNeil · 2010-05-25T11:43:45.269Z · LW(p) · GW(p)
(Sorry for the delay - I'm not notified when someone leaves a top-level comment.)
The halfer can try to argue like this: "SB doesn't gain any information at all upon waking, because she was going to be woken whether the coin was heads or tails. Therefore, since the prior probabilities of heads and tails are 1/2 each, the posterior probabilities must also be 1/2 each." I believe this was neq1's argument in his "Sleeping Beauty Quips" post.
Then the thirder wants to say that the fact that SB gets woken twice in one branch but only once in the other means that, in some weird way, the probability of getting woken given tails was actually 2, rather than 1. So the likelihood function is Heads->1, Tails->2, and when we renormalise we get Heads->1/3 and Tails->2/3.
And naturally the halfer is skeptical, asking "How can you have a probability greater than 1???"
Hence, my devices of the uniform random number in [0,1] and the random bit are designed to 'fix' the thirder's argument - in the sense of no longer having to do something that the halfer will think is invalid.
So now let's consider that random bit.
We have four equally likely branches:
- alpha = Monday, coin = Heads
- alpha = Monday, coin = Tails
- alpha = Tuesday, coin = Heads
- alpha = Tuesday, coin = Tails
Now suppose SB wakes and sees 'alpha'. Then SB now has the information "alpha is one the days on which I was woken". This event is true in branches 1, 2 and 4 but false in branch 3.
In one of those three branches, the coin is heads, and in the other two it is tails. Hence we get our {1/3, 2/3} posterior probabilities for {heads, tails}.
You're asking why this is necessary and/or sufficient to 'end the controversy'. Necessary? Well, if we're prepared to accept the original form of the thirder's argument then of course this device isn't necessary. Sufficient? Yes, unless there's some reason why adding a random bit should alter what SB thinks the probabilities are.
Perhaps neq1 would place great importance on whether or not the Monday and Tuesday instances of SB had exactly the same or slightly different mental states, and say that without the random bit, what we have when SB is woken twice is really a single conscious observer whose mind is split over two days. Personally, I think this is absurd, because sameness or slight-difference of minds has no effects on anything we can observe and is therefore impossible to verify or falsify. (Consider that even if we try to keep the room exactly the same on Tuesday, the Moon will be in a slightly different position, and so SB will be affected differently by its gravity. Perhaps that puts her into a "slightly different" mental state?)
comment by Larks · 2010-05-21T15:46:26.480Z · LW(p) · GW(p)
I found this to be a very helpful article, but a bit more deliberation on the Smoking Lesion problem would be helpful; I looked it up on the wiki, but still don't really understand it, or how it is solved.
Replies from: None↑ comment by [deleted] · 2013-01-17T19:42:39.867Z · LW(p) · GW(p)
In the smoking lesion problem, your choice of whether or not to smoke correlates with whether or not you'll get cancer, but it doesn't cause it (since the gene that causes smoking and cancer is already either with you or not). The correct option is to smoke because you can't, even timelessly/acausally affect whether or not you have the gene (unlike the standard newcomb's problem, in which you don't cause the $1,000,000 to be there by one-boxing, but you do timelessly/acausally affect it).
Replies from: Larkscomment by [deleted] · 2013-01-17T20:09:21.178Z · LW(p) · GW(p)
Not to nitpick, but if the colors correspond to days, shouldn't the left half of the left orange box be blue and the left half of the right blue box be orange? I believe this may affect the answer UDT gives.
comment by Jonathan_Graehl · 2010-05-21T22:38:57.737Z · LW(p) · GW(p)
When you say "uniform random number in the set [0,1]", you mean something isomorphic to a countably infinite sequence of (independent) random bits (each equally likely 0 or 1) . The probability of any particular sequence is then 0. I guess you alluded to this with "probability (or rather density)".
But what's your larger point? Why is it necessary to fix some particular random bits? Couldn't you just as well say I have the ability to generate them if I want them? I guess by having them exist before I ask to see them, you can think of a Player decision node as existing frozen in time (interactions with the world happen only as results of decisions).
Replies from: AlephNeilcomment by gwern · 2010-05-20T13:52:12.886Z · LW(p) · GW(p)
In other words, 'Counterfactual Mugging' is actually isomorphic to:
To?
Replies from: AlephNeil↑ comment by AlephNeil · 2010-05-20T14:00:31.225Z · LW(p) · GW(p)
To the game depicted in the diagram following that sentence.
Which is the game you get by turning the Omega node in 'Counterfactual Mugging' into a Player node.
Which is the following game:
"A coin is tossed. You must either push a button or not. If you push it and the coin was heads then you lose $100. If you push it and the coin was tails then you gain $10000. If you don't push it then nothing happens."
Replies from: gwerncomment by PhilGoetz · 2010-05-20T01:53:52.994Z · LW(p) · GW(p)
What if, in addition to freely-willed 'Player' nodes and random 'Nature' nodes, there is a third kind of node where the branch followed depends on the Player's strategy for a particular information state, regardless of whether that strategy has yet been executed. In other words, what if the universe contains 'telepathic robots' (whose behaviour is totally mechanical - they're not trying to maximize a utility function) that can see inside the Player's mind before they have acted?
Why is this worth considering?
Replies from: AlephNeil↑ comment by AlephNeil · 2010-05-20T07:15:45.638Z · LW(p) · GW(p)
Because this is the 'smallest generalisation' sufficient to permit newcomblike problems (such as the three I mentioned).
Btw, don't read too much into the fact that I've called these things 'robots' because in a sense everything is a robot. What I mean is something like "an agent or machine whose algorithm-governing-behaviour is 'given to us' without us having to do any decision theory". Or if we want to stick more closely to the AI context in which Wei proposed UDT, we're just talking about "another subroutine whose source code we can inspect in order to try to figure out what it does."
Replies from: drcode↑ comment by drcode · 2010-05-20T13:43:44.650Z · LW(p) · GW(p)
I interpreted the question PG was asking as, "why is it worth considering newcomb-like problems?"
(Of course, any philosophical idea is worth considering, but the question is whether this line of reasoning has any practical benefits for developing AI software)
Replies from: AlephNeil↑ comment by AlephNeil · 2010-05-20T14:33:21.937Z · LW(p) · GW(p)
Ah, I see.
I'm not really qualified to give an answer (as I don't have any background in AI) but I'll try anyway: The strategies which succeed in newcomblike problems are in a certain sense 'virtuous'. By expanding the scope of their concern from the immediate indexical 'self' to the 'world as a whole' they realise that in the long run you do better if you're 'honest', and fulfil your 'obligations'. So a decision theory which can deduce and justify the 'right' choices on such problems is desirable.
UDT reminds me of Kant's categorical imperative "Act only according to that maxim whereby you can at the same time will that it should become a universal law."
I think the way in which moral behaviour gradually emerges out of 'enlightened self-interest' is profoundly relevant to anyone interested in the intersection of ethics and AI.
Replies from: Vladimir_Nesov, cousin_it, thomblake, PhilGoetz↑ comment by Vladimir_Nesov · 2010-05-20T15:28:29.544Z · LW(p) · GW(p)
UDT doesn't search the environment for copies of the agent, it merely accepts a problem statement where multiple locations of the agent are explicitly stated. Thus, if you don't explicitly tell UDT that those other agents are following the same decision-making process as you do, it won't notice, even if the other agents all have source code that is equal to yours.
Edit: This is not quite right. See Wei Dai's clarification and my response.
Replies from: AlephNeil↑ comment by AlephNeil · 2010-05-21T01:13:05.822Z · LW(p) · GW(p)
So 'my version' of UDT is perhaps brushing over the distinction between "de facto copies of the agent that were not explicitly labelled as such in the problem statement" and "places where a superbeing or telepathic robot (i.e. Omega) is simulating the agent"?
The former would be subroutines of the world-program different from S but with the same source code as S, whereas the latter would be things of the form "Omega_predict(S, argument)"? (And a 'location of the agent explicitly defined as such' would just be a place where S itself is called?)
That could be quite important...
So I wonder how all this affects decision-making. If you have an alternate version of Newcomb's paradox where rather than OmegaPredict(S) we have OmegaPredict(T) for some T with the same source code as S, does UDT two-box?
Also, how does it square with the idea that part of what it means for an agent to be following UDT is that it has a faculty of 'mathematical intuition' by which it computes the probabilities of possible execution histories (based on the premise that its own output is Y)? Is it unreasonable to suppose that 'mathematical intuition' extends as far as noticing when two programs have the same source code?
Replies from: Vladimir_Nesov, Vladimir_Nesov↑ comment by Vladimir_Nesov · 2010-05-21T18:16:05.592Z · LW(p) · GW(p)
Is it unreasonable to suppose that 'mathematical intuition' extends as far as noticing when two programs have the same source code?
You are right. See Wei Dai's clarification and my response.
↑ comment by Vladimir_Nesov · 2010-05-21T09:29:21.561Z · LW(p) · GW(p)
Since UDT receives environment parametrized by the source code, there is no way to tell what agent's source code is, and so there is no way of stating that environment contains another instance of agent's source code or of a program that does the same thing as agent's program, apart from giving the explicit dependence already. Explicit parametrization here implies absence of information about the parameter. UDT is in a strange situation of having to compute its own source code, when, philosophically, that doesn't make sense. (And it also doesn't know its own source code when, in principle, it's not a big deal.)
So the question of whether UDT is able to work with slightly different source code passed to Omega, or the same source code labeled differently, is not in the domain of UDT, it is something decided "manually" before the formal problem statement is given to UDT.
Edit: This is not quite right. See Wei Dai's clarification and my response.
Replies from: Wei_Dai↑ comment by Wei Dai (Wei_Dai) · 2010-05-21T16:29:23.628Z · LW(p) · GW(p)
[I'm writing this from a hotel room in Leshan, China, as part of a 10-day 7-city self-guided tour, which may help explain my relative lack of participation in this discussion.]
Nesov, if by UDT you mean the version I gave in the article that AlpheNeil linked to in this post (which for clarity I prefer to call UDT1), it was intended that the agent knows its own source code. It doesn't explicitly look for copies of itself in the environment, but is supposed to implicitly handle other copies of itself (or predictions of itself, or generally, other agents/objects that are logically related to itself in some way). The way it does so apparently has problems that I don't know how to solve at this point, but it was never intended that locations of the agent are explicitly provided to the agent.
I may have failed to convey this because whenever I write out a world program for UDT1, I always use "S" to represent the agent, but S is supposed stand for the actual source code of the agent (i.e., a concrete implementation of UDT1), not a special symbol that means "a copy of the agent". And S is supposed to know its own source code via a quining-type trick.
(I'm hoping this is enough to get you and others to re-read the original post in a new light and understand what I was trying to get at. If not, I'll try to clarify more at a later time.)
Replies from: cousin_it, Vladimir_Nesov↑ comment by cousin_it · 2010-05-26T03:09:32.944Z · LW(p) · GW(p)
And S is supposed to know its own source code via a quining-type trick.
This phrase got me thinking in another completely irrelevant direction. If you know your own source code by quining, how do you know that it's really your source code? How does one verify such things?
Replies from: Wei_Dai, Vladimir_Nesov↑ comment by Wei Dai (Wei_Dai) · 2010-05-29T04:16:25.255Z · LW(p) · GW(p)
Here's a possibly more relevant variant of the question: we human beings don't have access to our own source code via quining, so how are we supposed to make decisions?
My thoughts on this so far are that we need to develop a method of mapping an external description of an mathematical object to what it feels like from the inside. Then we can say that the consequences of "me choosing option A" is the logical consequences of all objects with the same subjective experiences/memories as me choosing option A.
I think the quining trick may just be a stopgap solution, and the full solution even for AIs will need to involve something like the above. That's one possibility that I'm thinking about.
Replies from: Vladimir_Nesov, cousin_it↑ comment by Vladimir_Nesov · 2010-05-29T10:14:27.598Z · LW(p) · GW(p)
I guess the ability to find oneself in the environment depends on no strange things happening in the environments you care about (which are "probable"), so that you can simply pattern-match the things that qualify as you, starting with an extremely simple idea of what "you" is, in some sense inbuilt is our minds by evolution. But in general, if there are tons of almost-you running around, you need the exact specification to figure out which of them you actually control.
This is basically the same idea I want to use to automatically extract human preference, even though strictly speaking one already needs full preference to recognize its instance.
↑ comment by cousin_it · 2010-05-29T09:30:49.541Z · LW(p) · GW(p)
Then we can say that the consequences of "me choosing option A" is the logical consequences of all objects with the same subjective experiences/memories as me choosing option A.
Not exactly... Me and Bob may have identical experiences/memories, but I have a hidden rootkit installed that makes me defect, and Bob doesn't.
Maybe it would make more sense to inspect the line of reasoning that leads to my defection, and ask a) would this line of reasoning likely occur to Bob? b) would he find it overwhelmingly convincing? This is kinda like quining, because the line of reasoning must refer to a copy of itself in Bob's mind.
Replies from: Vladimir_Nesov↑ comment by Vladimir_Nesov · 2010-05-29T11:13:49.986Z · LW(p) · GW(p)
This just considers the "line of reasoning" as a whole agent (part of the original agent, but not controlled by the original agent), and again assumes perfect self-knowledge by that "line of reasoning" sub-agent (supplied by the bigger agent, perhaps, but taken on faith by the sub-agent).
↑ comment by Vladimir_Nesov · 2010-05-26T11:25:38.922Z · LW(p) · GW(p)
What is the "you" that is supposed to verify that? It's certainly possible if "you" already have your source code via the quine trick, so that you just compare it with the one given to you. On the other hand, if "you" are a trivial program that is not able to do that and answers "yes, it's my source code all right" unconditionally, there is nothing to be done about that. You have to assume something about the agent.
Replies from: cousin_it↑ comment by cousin_it · 2010-05-26T12:37:53.179Z · LW(p) · GW(p)
"What is the you" is part of the question. Consider it in terms of counterfactuals. Agent A is told via quining that it has source code S. We're interested in how to implement A so that it outputs "yes" if S is really its source code, but would output "no" if S were changed to S' while leaving the rest of the agent unchanged.
In this formulation the problem seems to be impossible to solve, unless the agent has access to an external "reader oracle" that can just read its source code back to it. Guess that answers my original question, then.
↑ comment by Vladimir_Nesov · 2010-05-21T18:14:16.006Z · LW(p) · GW(p)
I understand now. So UDT is secretly ambient control, expressed a notch less formally (without the concept of ambient dependence). It is specifically the toy examples you considered that take the form of what I described as "explicit updateless control", where world-programs are given essentially parametrized by agent's source code (or, agent's decisions), and I mistook this imprecise interpretation of the toy examples for the whole picture. The search for the points from which the agent controls the world in UDT is essentially part of "mathematical intuition" module, so AlephNeil got that right, where I failed.
↑ comment by cousin_it · 2010-05-20T15:36:57.240Z · LW(p) · GW(p)
Newcomblike problems are not required for that. The usual story says that moral behavior emerges from repeated games.
↑ comment by thomblake · 2010-05-20T14:38:20.361Z · LW(p) · GW(p)
I think the way in which moral behaviour gradually emerges out of 'enlightened self-interest' is profoundly relevant to anyone interested in the intersection of ethics and AI.
I agree, with the caveat that what applies to ethics might not apply naturally to Friendliness.
Replies from: cousin_it↑ comment by cousin_it · 2010-05-20T15:36:44.295Z · LW(p) · GW(p)
Newcomb's problem is not required for that. The usual story says that moral behavior emerges from repeated games.
comment by timtyler · 2010-05-19T12:50:02.984Z · LW(p) · GW(p)
Re: "The above procedure is extremely limited. Taking it exactly as stated, it only applies to games with a single player and a single opportunity to act at some stage in the game."
I don't really see what you mean. Your "naive" decision theory updated on sensory input - and then maximised expected utility. That seems like standard decision theory to me - and surely it works fine with multiple actors and iterated interactions.
Replies from: AlephNeil↑ comment by AlephNeil · 2010-05-19T13:24:03.344Z · LW(p) · GW(p)
It's not literally true that the procedure I described knows how to deal with multiple actors. For instance, if "Player 2" is going to act after me, then in order to calculate expected utilities for my actions, I need to have some idea of what Player 2 is going to do. Now, given some particular game, it may or may not be true that there's a straightforward way to divine what Player 2 is going to do, but until we're given such a method, the Bayesian procedure I've described as 'NDT' is stuck.
You might think "well, if Player 2 is the last person to act then surely we can apply 'NDT' to work out Player 2's best decision and then work back to Player 1's decision." But again, this isn't literally true, because we can't calculate a likelihood function unless we know Player 1's strategy.
(However, if Player 2 knows what Player 1's move was then they can calculate a likelihood function after all. This case is similar to the one I describe where a non-forgetful Player plays several times.)
Replies from: timtyler↑ comment by timtyler · 2010-05-19T13:55:24.098Z · LW(p) · GW(p)
Player 2 is part of Player 1's environment. Player 1 calculates their actions in the same way as they calculate the response of the rest of the environment to their actions - by using their model of how the rest of the world behaves.
Replies from: AlephNeil↑ comment by AlephNeil · 2010-05-19T14:05:15.886Z · LW(p) · GW(p)
OK, but typically we're given no information about how Player 2 thinks and simply told what their utility function is. In other words, our 'model' of Player 2 just says "here is a rational actor who likes these outcomes this much."
Now if we can use that 'model' of Player 2 to work out what they're going to do, then of course we're in great shape, but that just means we're solving Player 2's decision problem. So in order to use 'NDT' we first need (possibly some other) decision theory to predict Player 2's action.
Replies from: timtyler↑ comment by timtyler · 2010-05-19T14:25:15.927Z · LW(p) · GW(p)
Agents may have even less information about other aspects of the world - and may be in an even worse position to make predictions about them. Basically agents have to decide what to do in the face of considerable uncertainty.
Anyway, this doesn't seem like a problem with conventional decision theory to me.
Replies from: AlephNeilcomment by [deleted] · 2015-06-06T03:03:47.836Z · LW(p) · GW(p)
This is a reminder to myself to come back to this post