Limitations on the Interpretability of Learned Features from Sparse Dictionary Learning
post by Tom Angsten (tom-angsten) · 2024-07-30T16:36:06.518Z · LW · GW · 0 commentsContents
Overview Introduction Ideally-Interpretable Features Example Binary Feature: HTML Closing Paragraph Tag Example Continuous Feature: Daily Temperature Query Generation Case Study: SAE in Towards Monosemanticity Representing a Binary Feature Representing a Continuous Feature Coupled-Features Strategy Summary None No comments
Overview
When I began my attempt to replicate Anthropic's Towards Monosemanticity paper, I had high expectations for how interpretable the extracted features should be. If I judged a feature to be uninterpretable, I attributed this to either sub-optimal sparse autoencoder hyperparameters, a bug in my implementation, or possible shortcomings of dictionary learning. Interpretability of the features was the ultimate feedback on my degree of success or failure. However, I now believe that, even without these factors, that is, even if a sparse autoencoder learned the exact set of features represented by the model, it's possible that a subset of these could be much less interpretable than I had initially expected.
This post presents one way in which features extracted by the experimental setup of Towards Monosemanticity could be 'correct' and yet have lackluster interpretability. I'm a junior researcher, so this post could be an ugly mixture of obvious and incorrect. If so, I prefer aggressive criticism to the absence of feedback.
Introduction
In Towards Monosemanticity [AF · GW], researchers at Anthropic apply a sparse autoencoder (SAE) to the activations appearing immediately after the MLP of a single-layer transformer. Under these conditions, a feature of the learned dictionary will have a contribution to the model logits that must be approximately linear in the feature's activation. This places a restriction on the influence each extracted feature can have over the predicted next-token probability distribution. If the 'true' features the model represents in the layer are linear and decomposable, i.e. are fully described by the linear representation hypothesis, then they too will have this restriction.
In this post, we consider two hypothetical ideally-interpretable features that have no restriction in their effect on the next-token distribution and explore how a single-layer model may represent these idealized features internally. If the model can't encode these idealized features in a manner one-to-one with its internal features, then features that describe the data-generating process in a human-interpretable manner may be mapped to sets of less interpretable model features due to constraints in the model architecture. We show that, in the case of certain continuous ideally-interpretable features, the model indeed cannot represent the feature in a one-to-one manner and discuss how this could hurt interpretability.
Ideally-Interpretable Features
We define an ideally-interpretable set of features as a hypothetical set of decomposable latent variables that exactly describe the data-generating process while being optimally interpretable to humans. We don't assert the existence of such variables in reality, as the points in this post rely only upon the intuition that, given numerous sets of possible features that could describe the data-generating process equally well, some are relatively more interpretable than others. The ideally-interpretable set is a hypothetical extreme of this intuition that helps deliver the key points below.
We now introduce two conveniently contrived examples of ideally interpretable features that sparsely activate over a text dataset.
Example Binary Feature: HTML Closing Paragraph Tag
The first is a binary feature whose value is one when the preceding text is a closing paragraph tag '</p>' within HTML code and zero otherwise. If zero, the feature has no impact on the next-token distribution, but if one, the feature entirely controls the output distribution such that only three tokens are active in fixed ratios:
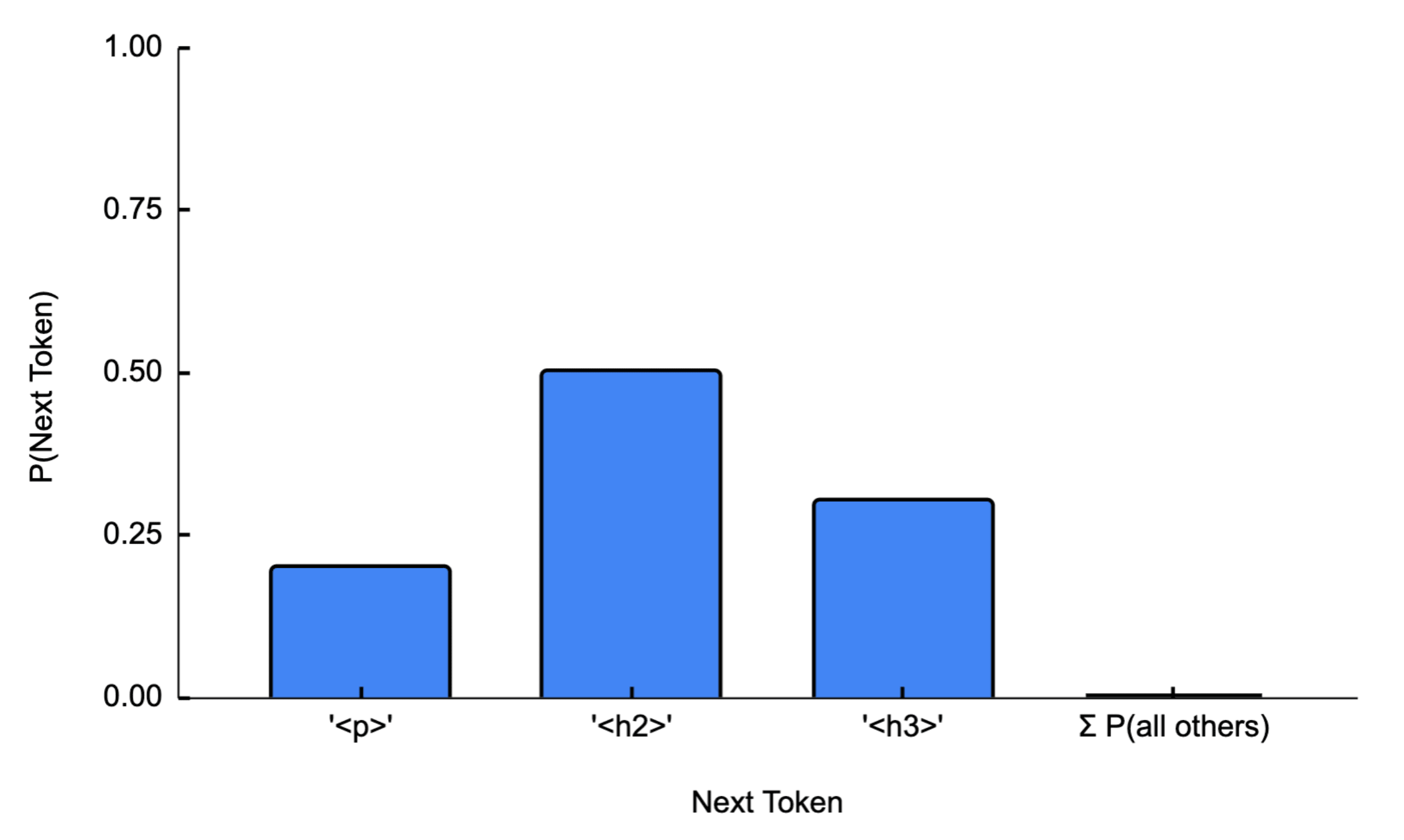
We assume this feature is 'ideally interpretable' in that it cannot be decomposed into one or more features that more clearly and concisely describe the mechanics of the data-generating process.[1]
Example Continuous Feature: Daily Temperature
For the second ideally-interpretable feature, we imagine that a substantial portion of the dataset is devoted to describing the weather on a given day. Many different authors write articles about the weather on many different days, often describing in words how hot or cold it was. Perhaps they mention how fast ice cream melted, or how many layers of clothing individuals wore. Enough detail is given in words to infer the relative temperature on a given day with high accuracy. Finally, the authors commonly write the phrase 'The temperature that day was…' and always complete it with one of three tokens: 'cold', 'mild', or 'hot'.
Behind this process is a measurable latent variable that is continuous, namely the day's average temperature. We assume that this variable is the sole determinant of the next-token probability distribution over the three descriptor tokens when the temperature description phrase is being completed:
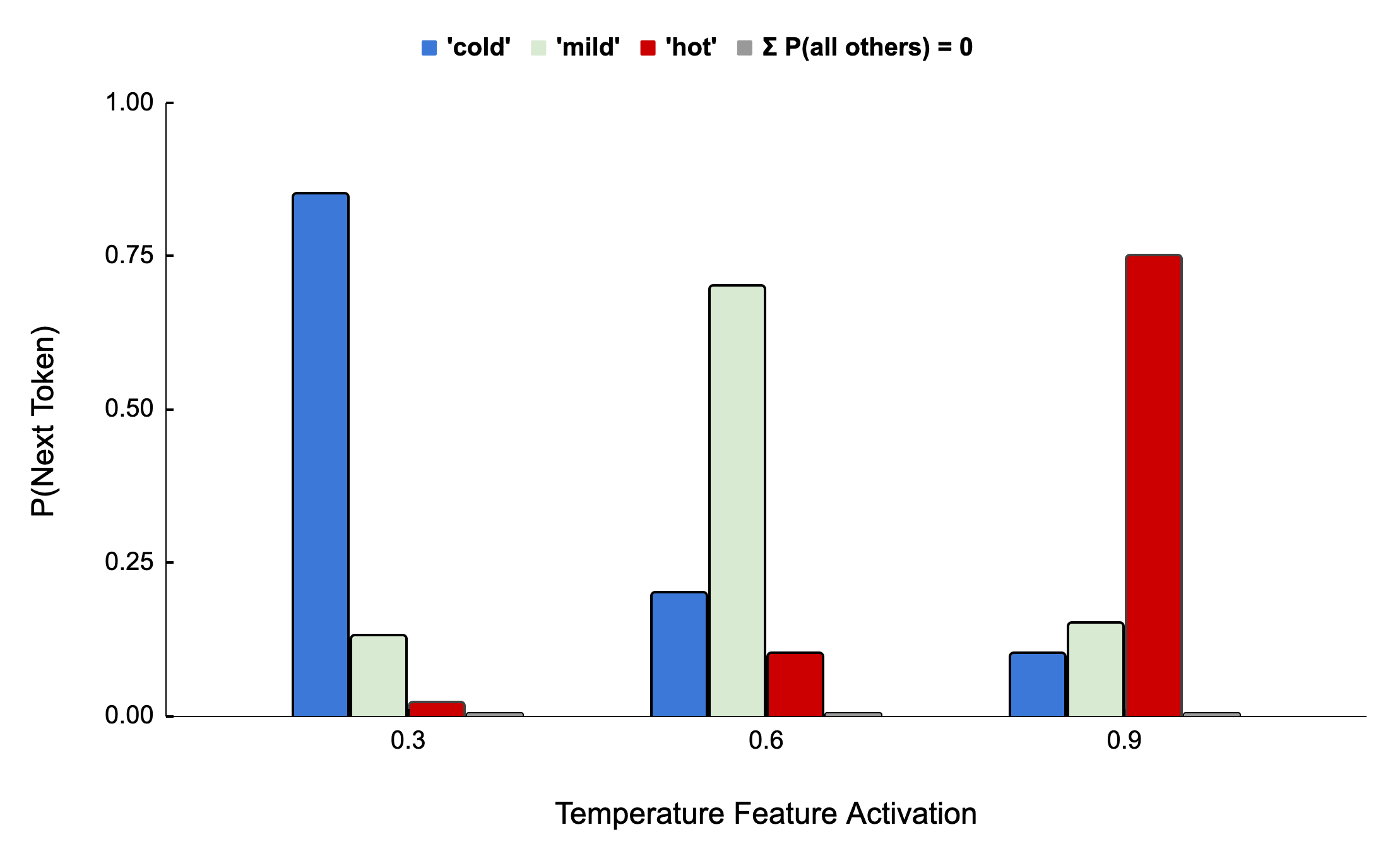
This feature is ideally interpretable because a single number precisely describes the smooth transition between different distributions of words as temperature increases. We can imagine that the feature activation is directly tied to a temperature variable that causes authors to draw words from one of the distributions in Figure 2, making this feature 'ideally interpretable' as compared to any other set of one or more correlated features describing the same statistical structure.
Finally, we assume that the temperature and HTML features activate in a mutually exclusive pattern, with HTML code never appearing alongside weather description text.
Query Generation
For a model trained on data partially described by a given idealized feature (such as one of the two examples above), we can generate a question of the following form:
Could the model, at a particular internal location, represent a given ideally-interpretable feature as a single linear decomposable feature? The answer depends on two factors:
-
Is there enough capacity in earlier layers for the model to encode the ideally-interpretable feature in a linear decomposable form?
-
Is there enough capacity after for a linear decomposable feature to affect the output distribution in a manner consistent with the ideally-interpretable feature's true effect on the output distribution?
The rest of this post will assume the answer to the first point is yes, and instead focus on the second.
Implicit in these questions and our investigation as a whole is the assumption that superposition theory, as described in Toy Models, fully dictates the nature of the trained model's representations. As such, extracted SAE features and 'true' model features have the same constraint of linearity, and any results below can be applied to either.
Case Study: SAE in Towards Monosemanticity
An SAE in Towards Monosemanticity is applied at the last (and only) transformer block's MLP output activations. Ignoring the weak non-linearity introduced by LayerNorm, each extracted feature has a linear effect on the logits determining the next-token output probability distribution.
Let's consider just one of these features, , having an input-dependent feature activation of and a contribution to the model's output logits of when =1. Let be the values of the logits that remain if we zero-ablate only feature by setting , while keeping all other aspects of the model the same. Then, for a given input fed to the model, the probability distribution of the next predicted token, , over the vocabulary is:
The key constraint imposed on linear features found after the last MLP is that the feature can only contribute logits in a fixed proportion determined by the vector . Let's see what restriction, if any, this places on a feature's ability to represent the output effect of our two example ideally-interpretable features.
Representing a Binary Feature
First, we'll consider the binary ideally-interpretable feature discussed above. It activates and fully determines the output distribution (e.g. Figure 1) when the last token is an HTML closing paragraph tag. Only three tokens have a substantial chance of occurring in this case, with all other tokens having approximately zero probability.
Can a model feature fit the output effect of this ideally-interpretable feature? We need only verify that there are enough degrees of freedom for the model feature to fit any fixed set of three probabilities summing to one. We start by approximating the output token distribution with:
We can ignore because has at least one component that is much larger than any of when the binary feature is active. Let be the first component of , the second, and so forth. Also, let the three non-zero probability tokens occupy vocabulary indices 1, 2, and 3 for convenience. When the binary feature is active:
We only need to specify two more equations to fix all three token probabilities. To remove the cumbersome normalization term of softmax, we will specify the distribution by writing two of the probability ratios:
The above two ratios can independently take on any positive values by setting to zero and letting and take on arbitrary negative or positive values. If we can represent any two ratios independently, then our linear feature can represent any arbitrary set of three probabilities, with the first token probability given by:
So,
This shows that a binary model feature with a linear effect on the logits can exactly fit any arbitrary but fixed distribution observed when a binary ideally-interpretable feature is active. The model architecture imposes no constraints in the binary case, and will not impact interpretability. This conclusion isn't particularly surprising given that the linear feature has three independent logits that need to represent only two degrees of freedom.
Representing a Continuous Feature
The situation changes, however, if we imagine continuous ideally-interpretable features such as the one defined earlier. When sufficiently active, the continuous feature has a large enough logit effect that it determines essentially the entire probability distribution (Figure 2) and causes non-zero probabilities among three tokens. Such a feature could smoothly alter the ratios of the three token probabilities following any arbitrary function of a single continuous variable. Can a model feature fit the output effect of this type of ideally-interpretable feature?
Let's look at the functional form of the ratios of probabilities of the three tokens once more. We can borrow the equations derived for the binary case, but this time , so it must appear in the equations. For sufficiently large where this feature dominates in the logits:
As before, is the first component of , and we imagine that the three non-zero probability tokens occupy indices 1, 2, and 3 in the vocabulary.
In the above equations, the terms exponentiated by must be positive and fixed at either < 1 or , and therefore each of the three token probability ratios as a function of must be either exponentially decreasing or exponentially increasing overall the full domain of This shows at least one significant restriction on the types of token distribution effects this feature can represent - the ratio of two token probabilities cannot increase over some domain of and then later decrease over a different domain. This constraint does not apply to an ideally-interpretable feature driving real text probability distributions, and Figure 2 gives an example output effect that a model feature could not represent. Given this, a single model feature constrained to have a linear effect on the output logits cannot always capture the output effect of a continuous ideally-interpretable feature.
Note that adding a bias term to each of the relevant logits does not alter the situation. It merely adds a degree of freedom allowing each token ratio to be scaled by an independent constant. The shapes of the curves remain unaltered. For example:
Coupled-Features Strategy
There is a way for the model to represent non-monotonic ratios of token probabilities, and that is through two or more features firing strongly together when the continuous ideally-interpretable feature is active. In this case, here is what the token probability ratios would look like if two features, , with logit effect , and , with logit effect , were firing at the same time with activations and :
Writing out the ratios:
There are enough degrees of freedom in this case to represent token probability ratios that exponentially decrease over some domain of the ideally-interpretable feature's activation value and then exponentially increase over a different domain (or vice versa). However, now the model has had to map one ideally-interpretable feature to two internal features. If we used an SAE to extract any individual model feature and did not know about the other, we would only see a partial picture of that model feature's role. This situation need not be two features from the same layer. Presumably other complex functions could be represented with the linear model features of two or more layers firing together.
In the single-layer model case, we can imagine that, as a continuous ideally-interpretable feature's functional form gets more and more complex, the model must utilize a combination of more and more coupled internal features to capture the ideally-interpretable feature's effect on the output distribution. As this happens, the interpretability of any individual model feature will degrade as it becomes more akin to a mathematical tool for fitting a function over a small domain, rather than an abstraction efficiently describing the data-generating process.
An interesting outcome of this could be that shallower models need to use more features per ideally-interpretable feature represented. In Towards Monosemanticity, the authors hypothesize that a smaller model will have fewer features, making its dictionary of features easier to fully determine with limited compute. However, the above details of this post could entail that a smaller model has a greater need to map one ideally-interpretable feature into many model features as compared to a larger model. Even though fewer ideally-interpretable features may be represented in the smaller model, the above effect may compensate and wash out any advantage.
Summary
This investigation provides weak evidence for the following concepts:
- Constraints in model architecture can degrade the interpretability of a model's features
- As an extreme, model features become sparsely activating 'function fitting' units rather than representing meaningful properties of the data
- An SAE-extracted model feature can accurately describe model behavior and yet be uninterpretable when considered in isolation
It remains an open question as to how much the above points apply to models trained on real datasets. The broader concept of model features being dictated by model architecture is, in fact, observed in Towards Monosemanticity in the form of 'token in context' features. The authors hypothesize that, to obtain more control over the output distribution, the model opts for a local code ('token in context' feature) instead of using a compositional representation. Due to the constraints of the model architecture, the compositional representation cannot as effectively lower loss, despite being more efficient. Though the 'token in context' feature strategy of the single-layer model doesn't necessarily hurt interpretability for any individual feature, many more features are needed, making the task of understanding the model more cumbersome.
It generally seems like a fruitful area of research to consider how hypothetical features underlying the data-generating process are mapped to features of the model. The nature of this mapping could be critical for interpreting the dictionary elements produced by sparse dictionary learning. If feasible, I hope to further explore this area of research, with a focus on connecting theoretical model limitations to observations in real applications.
In reality, a composition of multiple features (e.g. is a tag, is closing, contains the letter p) could more clearly describe the data-generating process. We're setting aside the question of 'what makes a feature set a preferable description' and simply assert that the proposed feature description is best. Doing so does not affect the points made in this post. ↩︎
0 comments
Comments sorted by top scores.