Retrieval Augmented Genesis II — Holy Texts Semantics Analysis
post by João Ribeiro Medeiros (joao-ribeiro-medeiros) · 2024-10-26T17:00:56.328Z · LW · GW · 0 commentsContents
Intro PCA analysis PCA Results Semantic Hypervolume — Convex Hull Thematic Density Intertext Similarity What is consistency? Math Intertext Consistency Take away messages Framework and Novel Concepts Results References and Bibliography sentence-transformers/all-MiniLM-L6-v2 · Hugging Face We're on a journey to advance and democratize artificial intelligence through open source and open science. Principal component analysis - Wikipedia Principal component analysis ( PCA) is a linear dimensionality reduction technique with applications in exploratory… Patent Text and Long-Run Innovation Dynamics: The Critical Role of Model Selection Founded in 1920, the NBER is a private, non-profit, non-partisan organization dedicated to conducting economic research… Definition of CONSISTENCY The meaning of CONSISTENCY is agreement or harmony of parts or features to one another or a whole : correspondence… Bhagavad Gita AI - Gita GPT - Ask Krishna GitaGPT is a free Bhagavad Gita AI chatbot that uses the wisdom of the Bhagavad Gita to help answer your day-to-day… Tanzil - Quran Navigator | القرآن الكريم Browse, Search, and Listen to the Holy Quran. With accurate Quran text and Quran translations in various languages. Thank You : ) None No comments
Intro
In my last post on Lesswrong [LW · GW] I shared ragenesis.com platform, along with a general description of the thought process behind the platform's development. Fundamentally, RAGenesis is a search and research AI driven software tool dedicated to 5 of the most representative holy texts in history: The Torah, The Bhagavad Gita, The Analects, The Bible's new testament and The Quran.
Beyond that, the platform (and my previous article) explores the concept of Semantic Similarity Networks (SSN), whereby one is able to represent the mutual similarities between chunks in the embedded knowledge base through a graph representation, following a similar framework to Microsoft's GraphRAG, but providing the user a direct interface with the network through RAG agentic driven interpretation.
One of the future evolutions of the RAGenesis framework I mentioned in my last post is the analysis of the SSNs defined by multiple different texts, something which isn't explored in the current version of the RAGenesis app. This post will provide some initial definitions and results around metrics for cross text analysis, focussing on cross-text consistency and semantic space analysis. All code for the app and for the results presented herein can be found in this open sourced code repository: https://github.com/JoaoRibeiroMedeiros/RAGenesisOSS
PCA analysis
A very common approach to understanding semantic spread in embedding space is to provide a visualization for the first two dimensions of a Principal Component Analysis transformed set of embedding data. This allows us to observe how the embedded chunks spread across in semantic space for the dimensions of greater variance inside the embeddings. See wikipedia for formal definition of PCA process, also, check out sci-kit learn documentation for quick guide to implementation.
Just as in RAGenesis app, we have explored two different embedding models to be able to compare results and illustrate potential universality of observations pertaining to the two different configurations.
- all-MiniLM-L6-v2: this model is the result of a self-supervised contrastive learning approach on a large datasets of sentence pairs. Check out Hugging Face documentation for more details. This model encodes sentences in vectors of 384 dimensions.
- jina-clip-v1: Multimodal embedding model created by JINA.AI . This model is the result of a novel three-stage contrastive learning training method for multimodal models, which maintains high performance on text-only tasks, such as the one it has on Ragenesis. Check out JINA’s paper on Arxiv for further details. This model encodes sentences in vectors of 768 dimensions.
PCA Results
As a measure for PCA effectiveness, in terms of how expressive are the principal components in capturing the semantic variance associated to the knowledge base, it is important that we evaluate the explained variance associated to PCA dimensions.
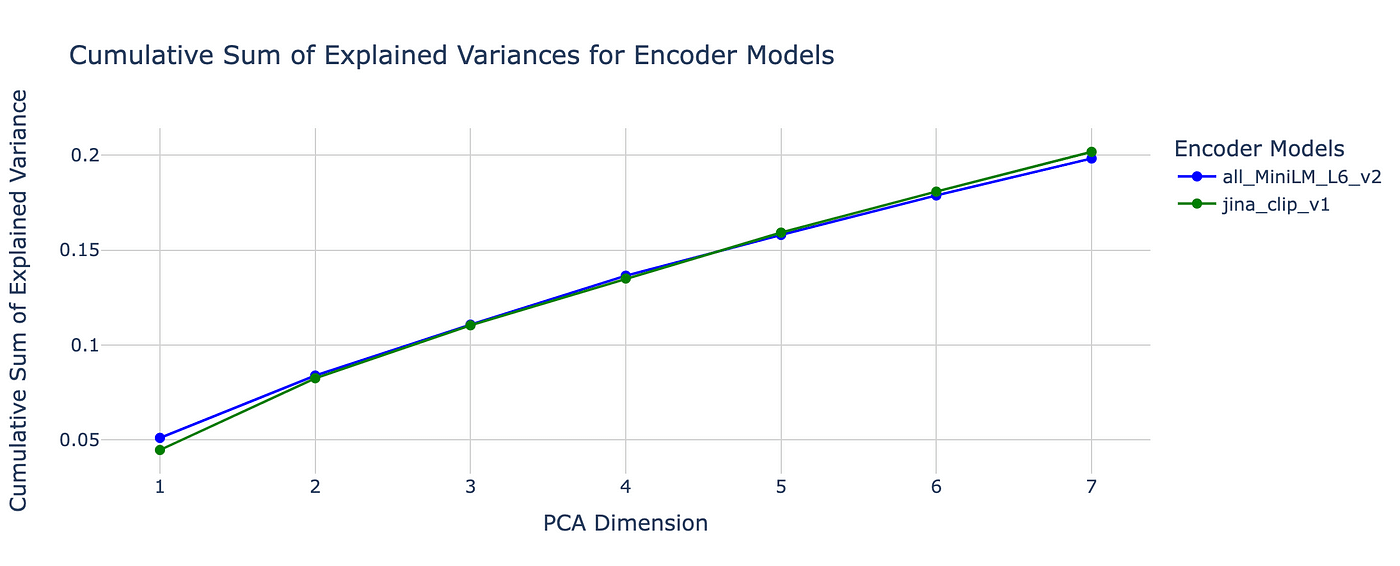
See explained variance for PCA in the two different embedding models.
Note that despite the substantially different dimensionalities associated with both (Jina-clip-v1 has 768 dimensions, twice the 384 dimensions of all-MiniLM-L6-v2), the seven first dimensions of PCA of the encodings of this knowledge base are already able to explain one fifth of the full variance associated with these representations. However, note that when it comes to language, the devil is in the details, which can perhaps be represented by the four fifths of variance which aren't covered by these 7 first dimensions.
See below plots for the first two dimensions of PCA transformed data for the embeddings associated to all texts in different combinations for better cross-text comparison. Notice that each point in the plots represents a vectorized representation of a verse and the color of the point indicates to which book does that verse belong to.
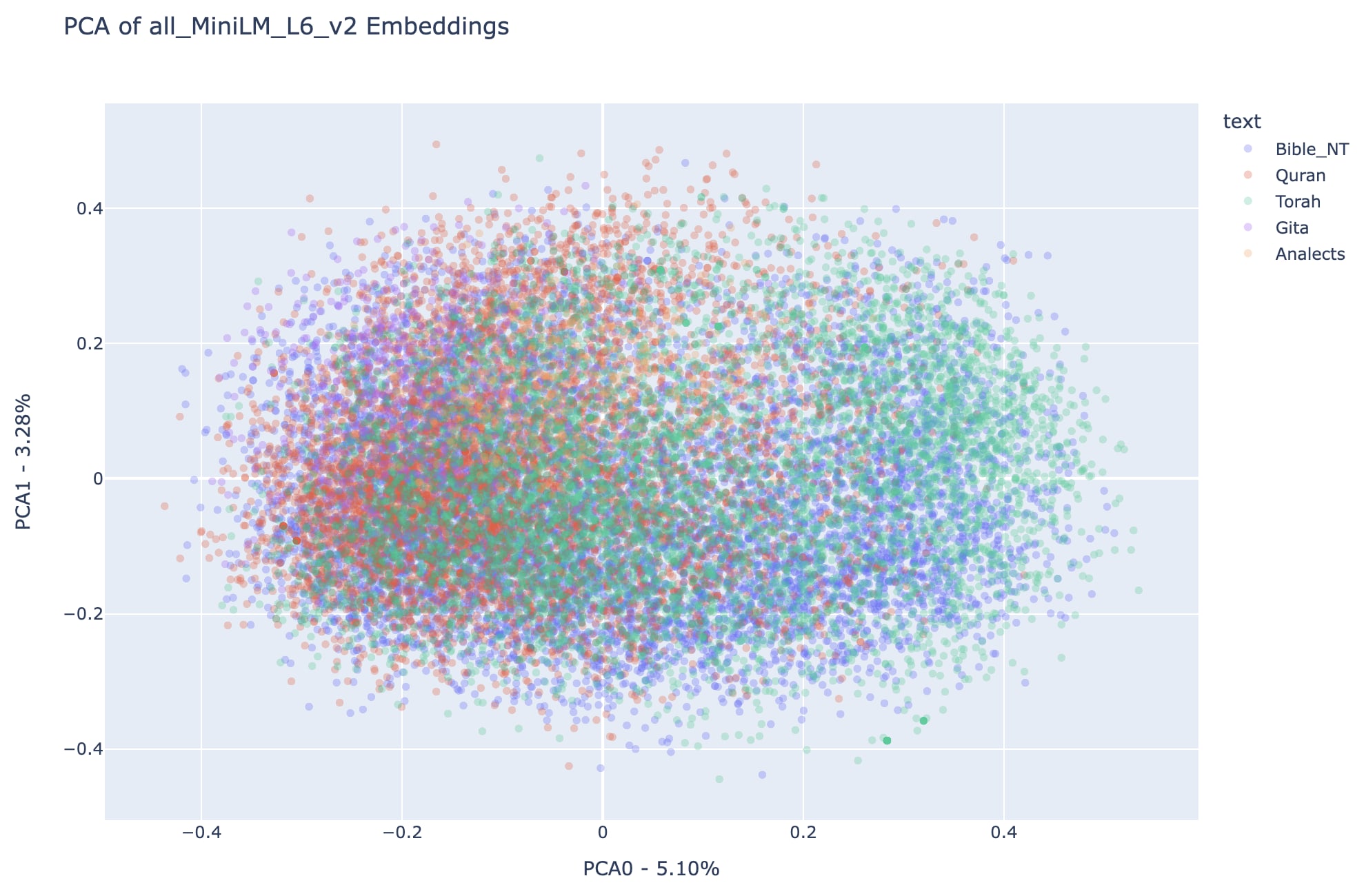
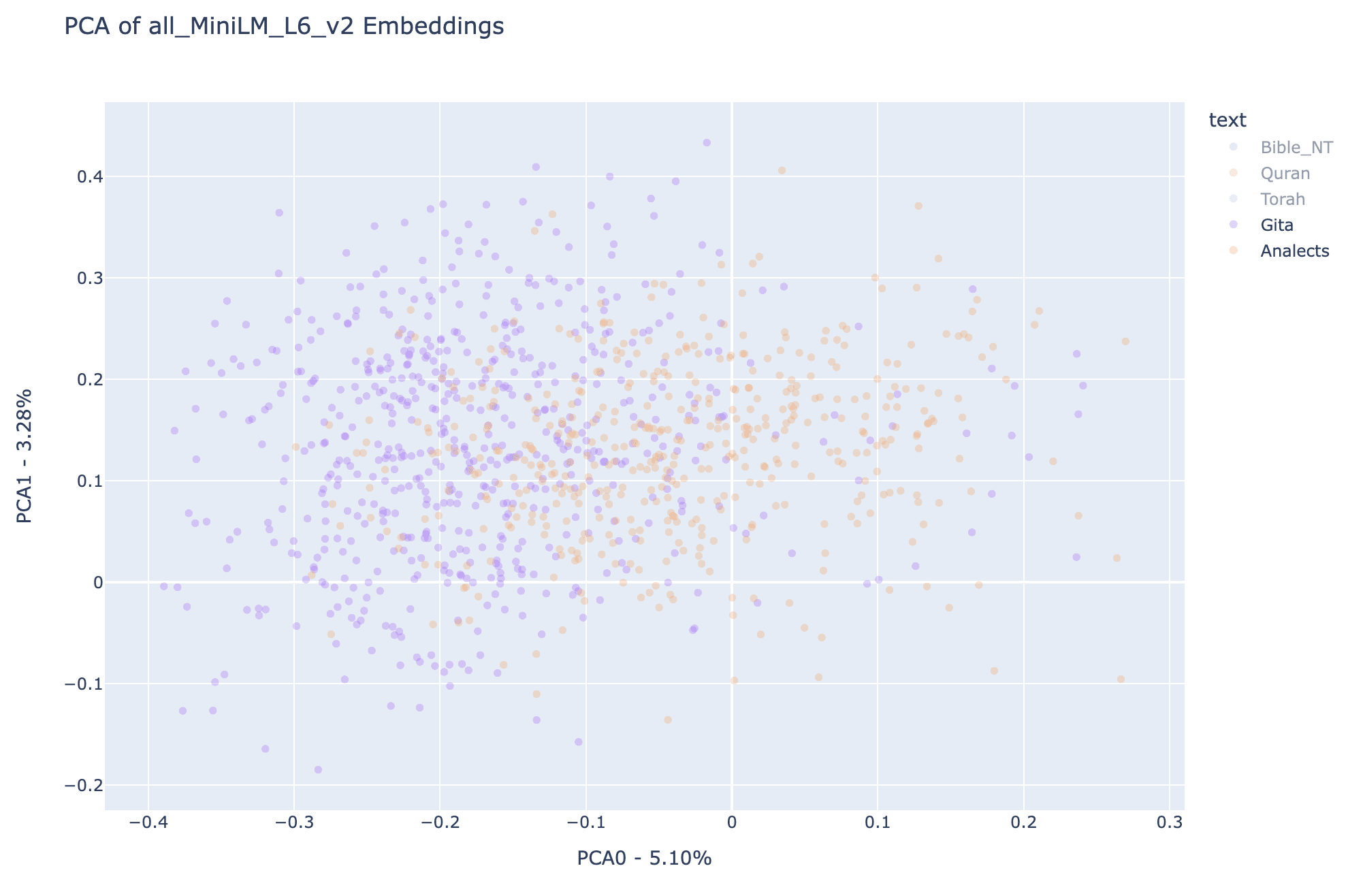
Notice that in the first two PCA dimensions, the regions covered by Analects and Gita are mainly subsets of the regions covered by the other three texts, it is hard to see the difference between the two plots above.
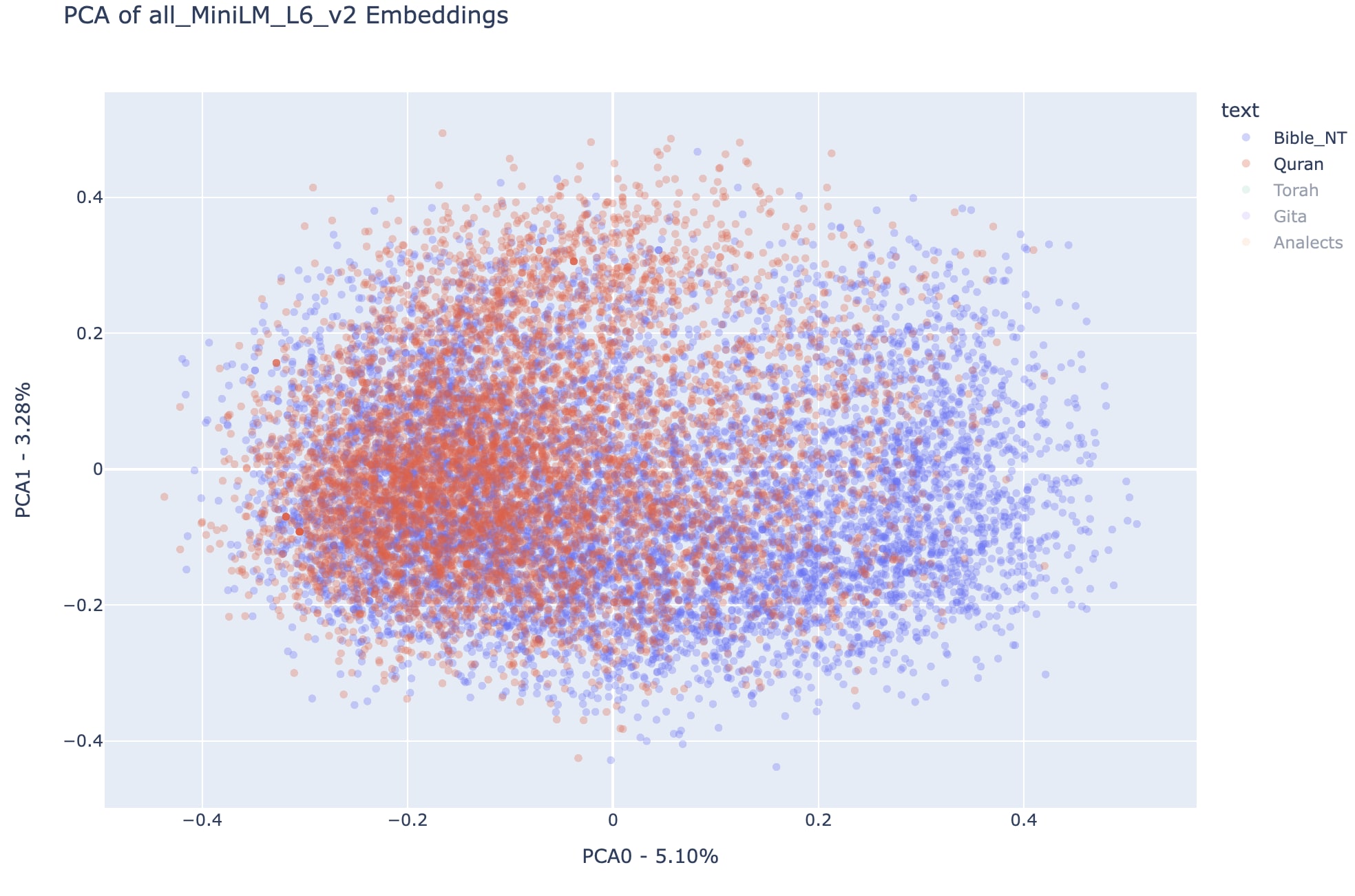
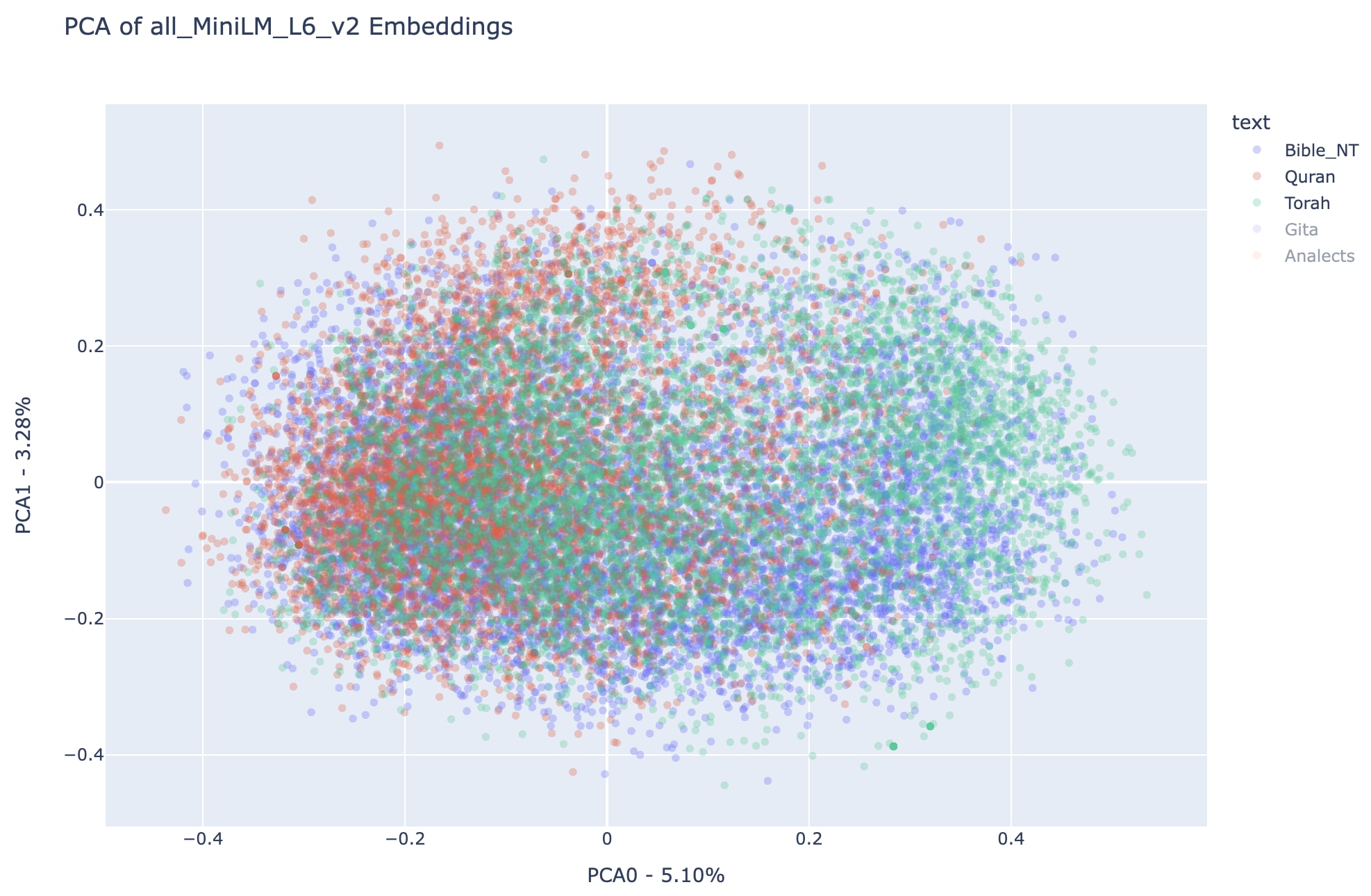
Notice that in this principal components the embeddings of the New Testament covers areas associated with both the Quran and the Torah, while the semantic spaces associated with the Quran and the Torah seem more disjointed, even though a substantial part of semantic space is shared.
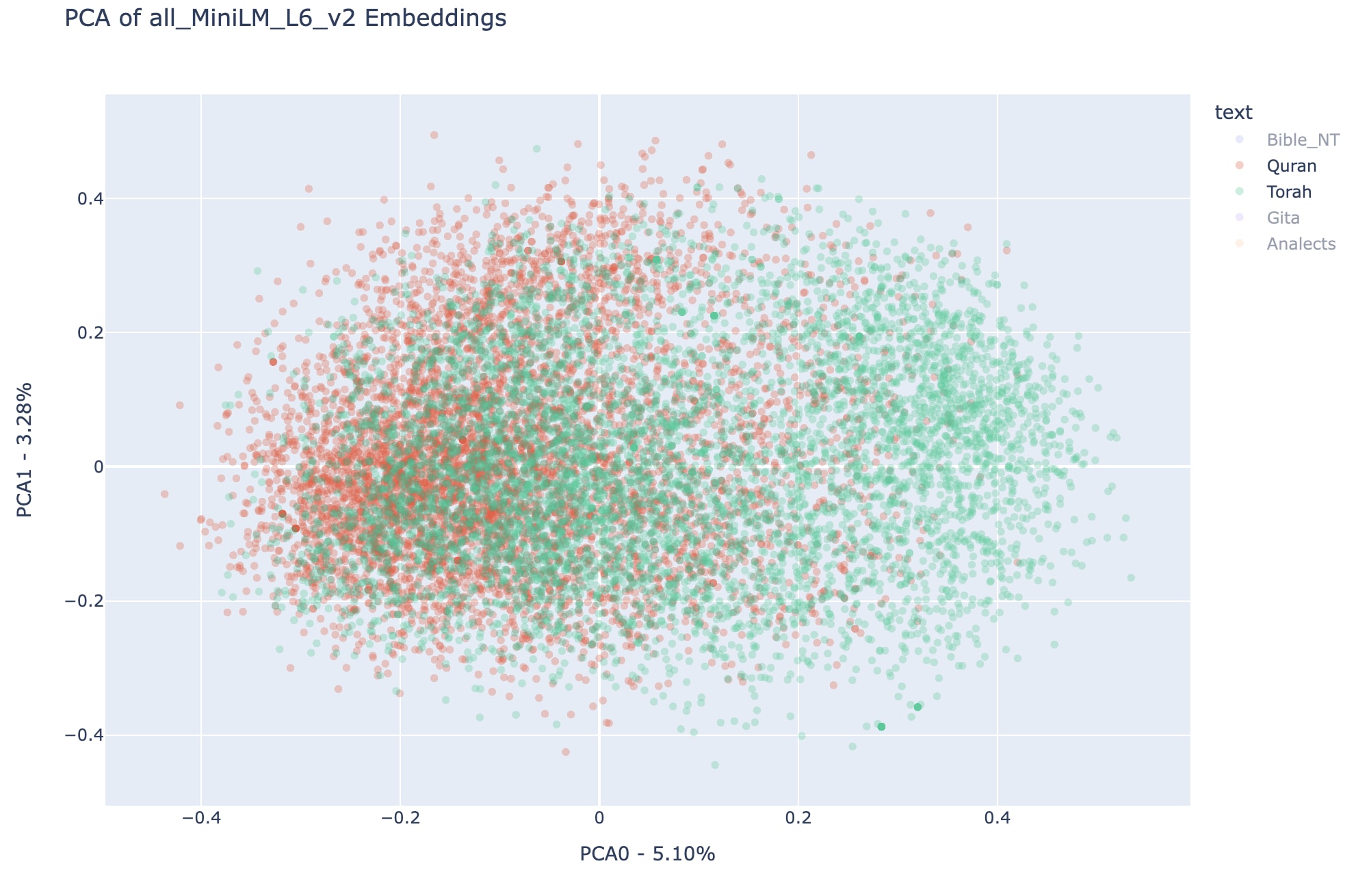
ABove we can see more clearly the different regions occupied by Quran (to the left of PCA representation space) and Torah (to the right of PCA representation space), interestingly enough the sum of both regions approximates very much the area occupied by the New Testament. Also, note that the Analects and the Bhagavad Gita are also substantially disjointed, in a similar way than the Quran and the Torah, respectively. It is important to remember that in terms of total number of verses, the analects and the Bhagavad Gita are much smaller than the other three texts that were analyzed, checkout the previous post for the details.
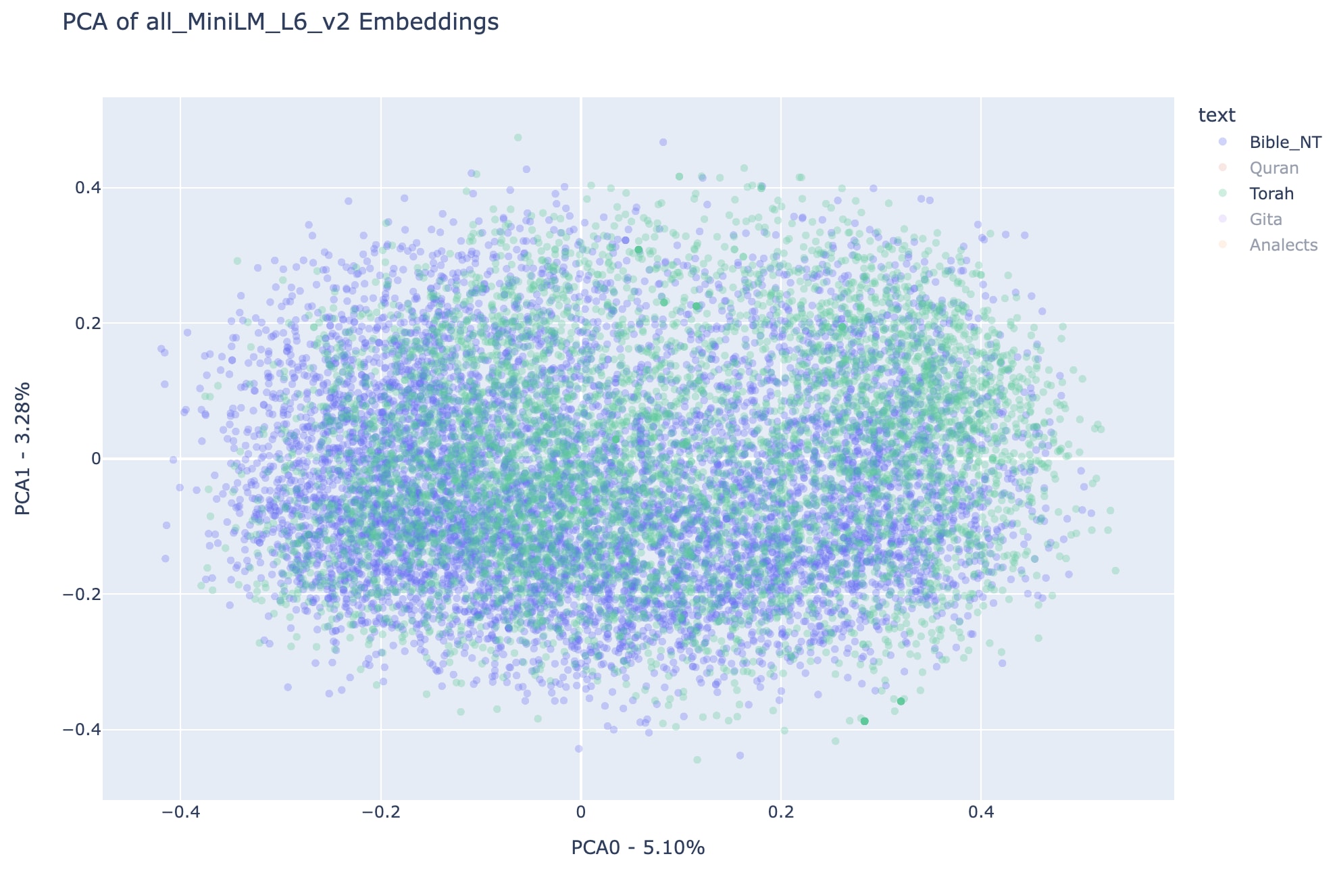
Checkout plots below for the Jina-clip-v1 correspondents of the results showcased above:
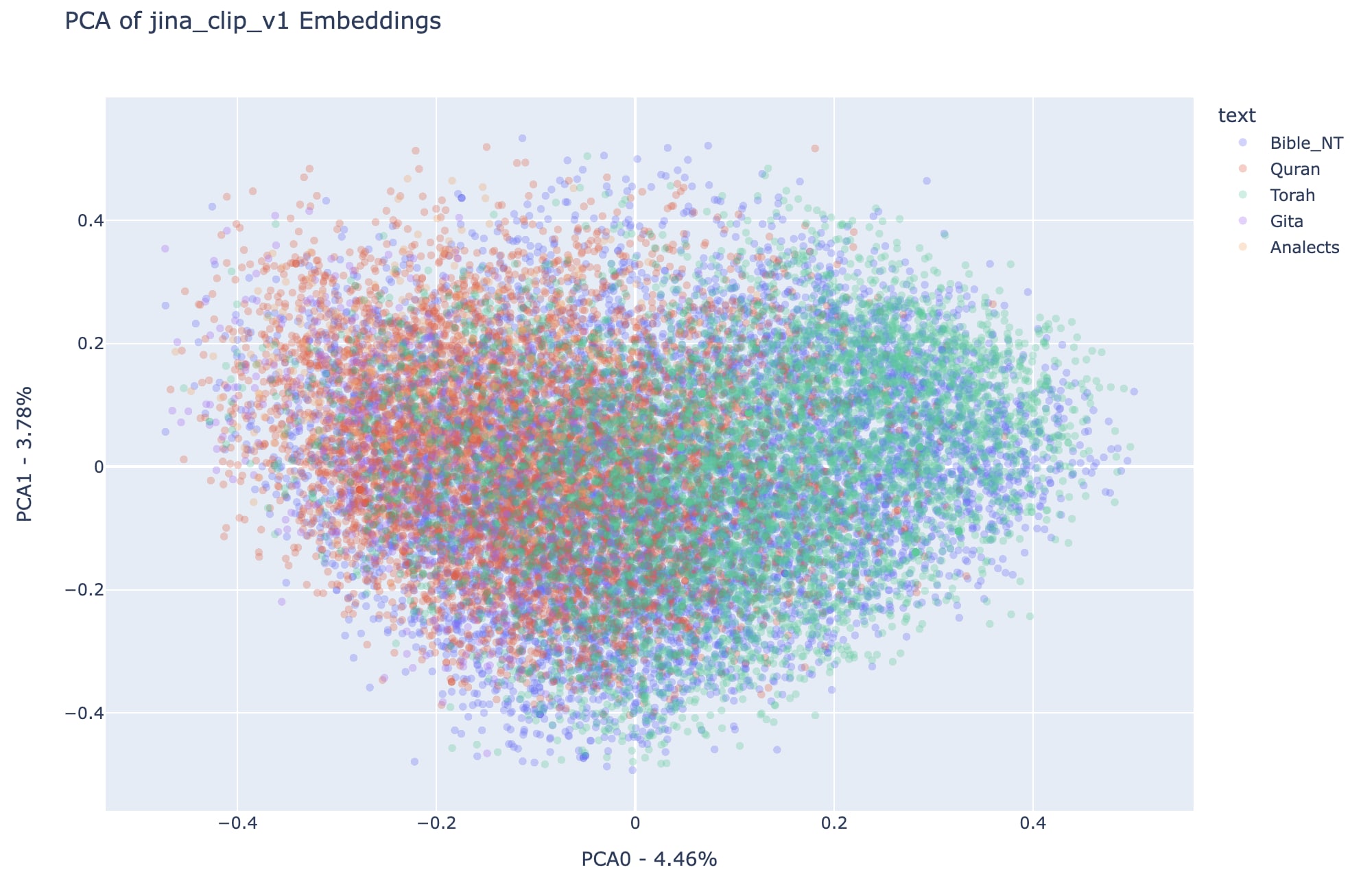
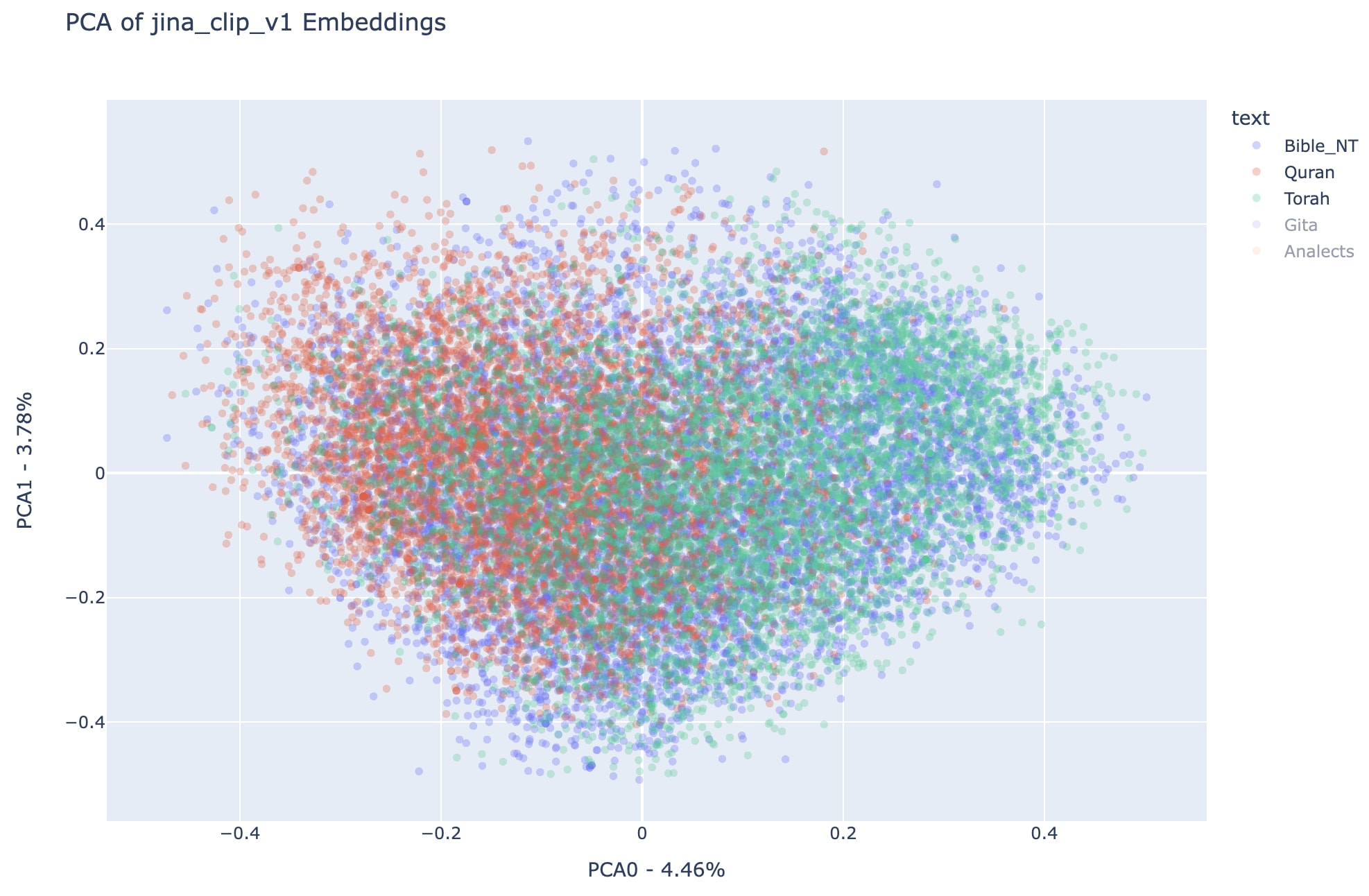
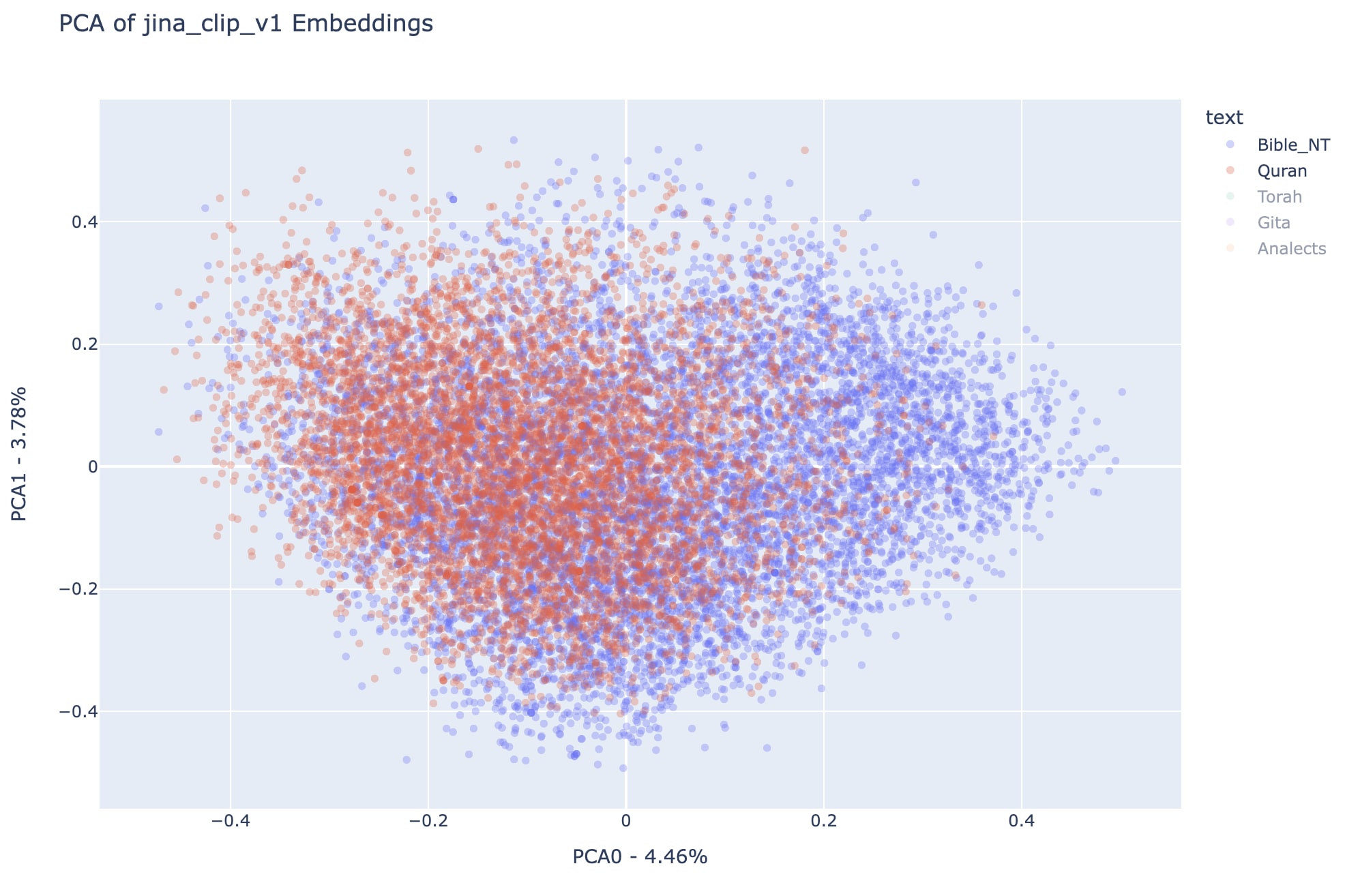
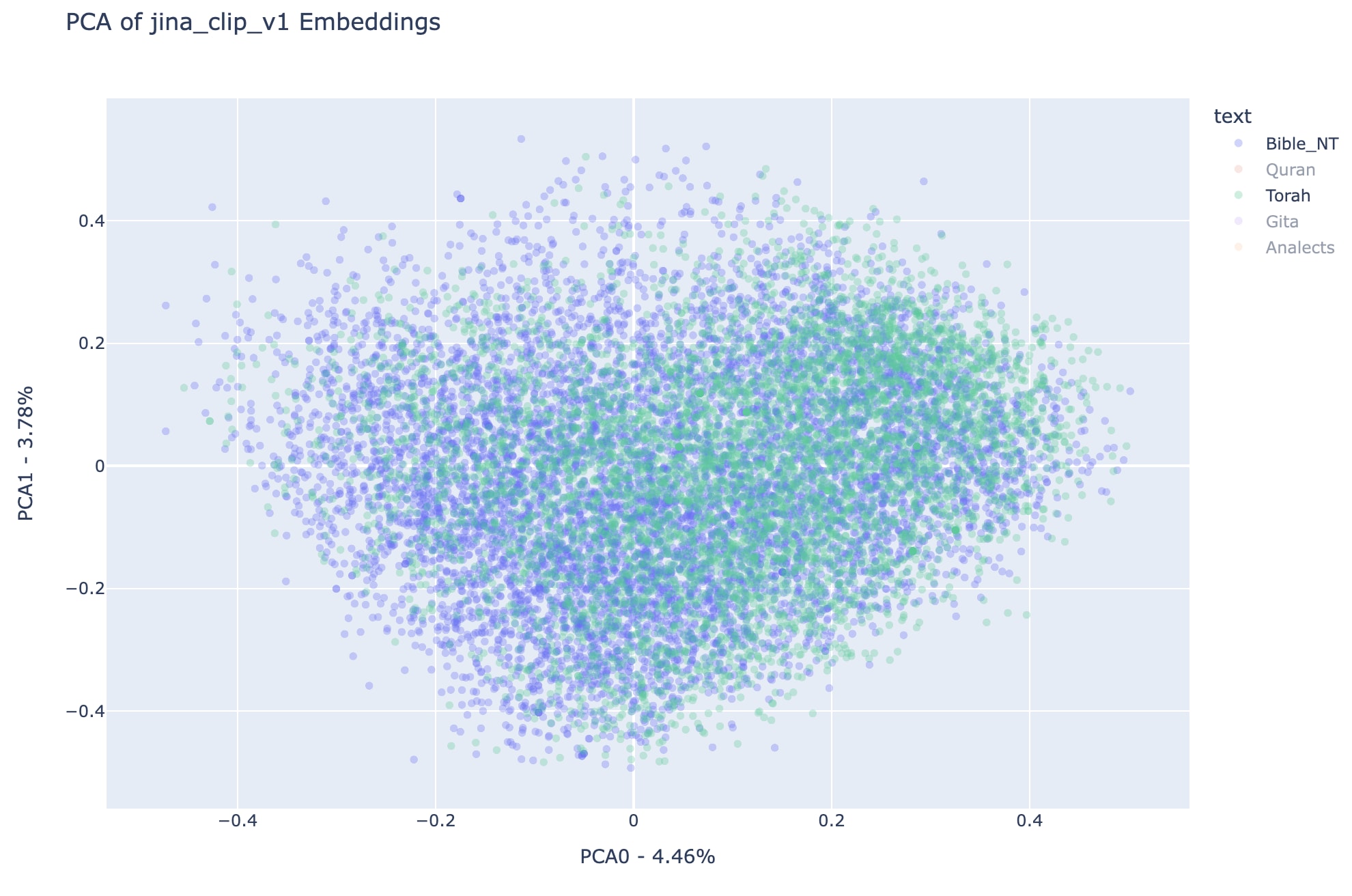
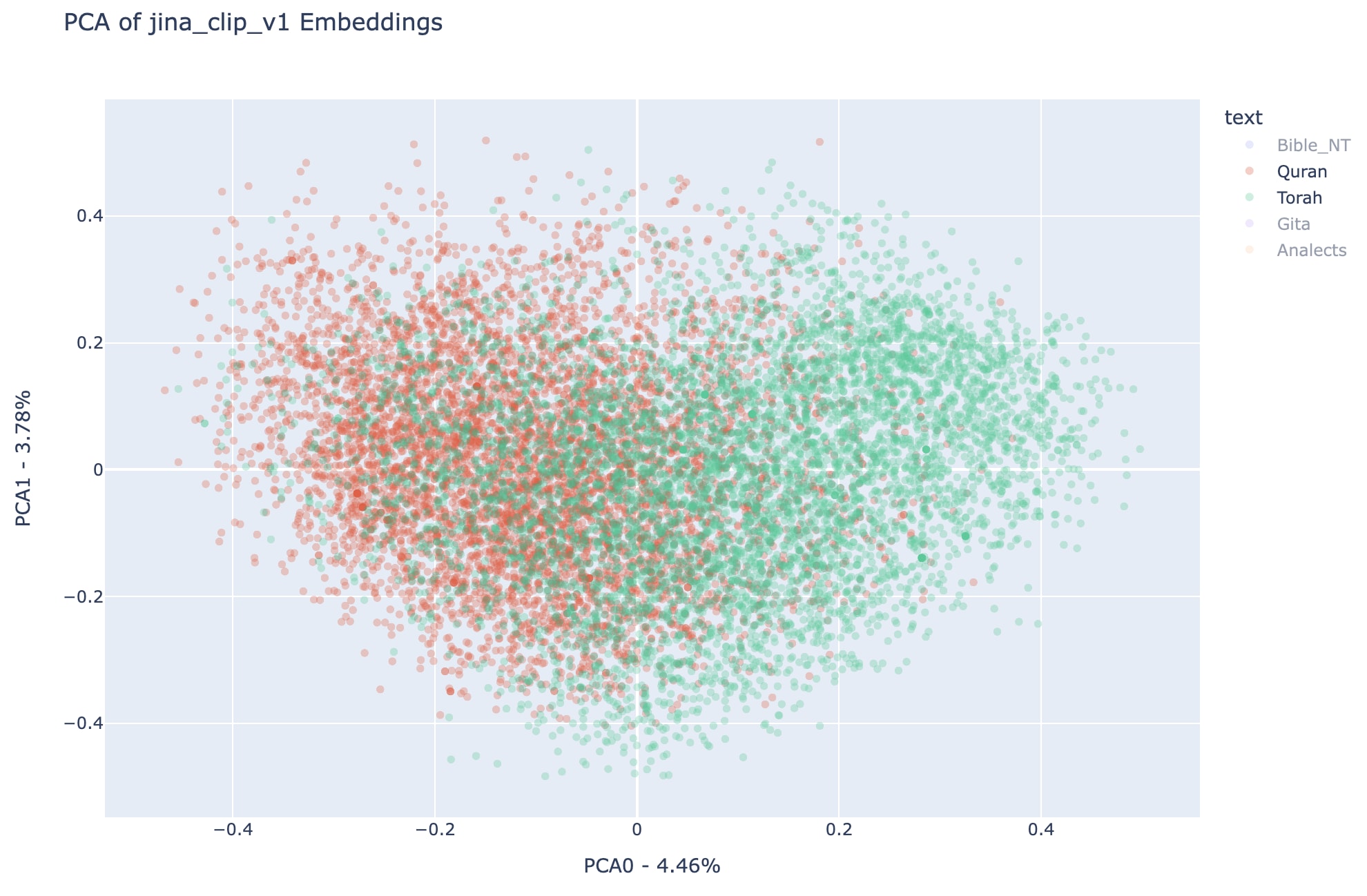
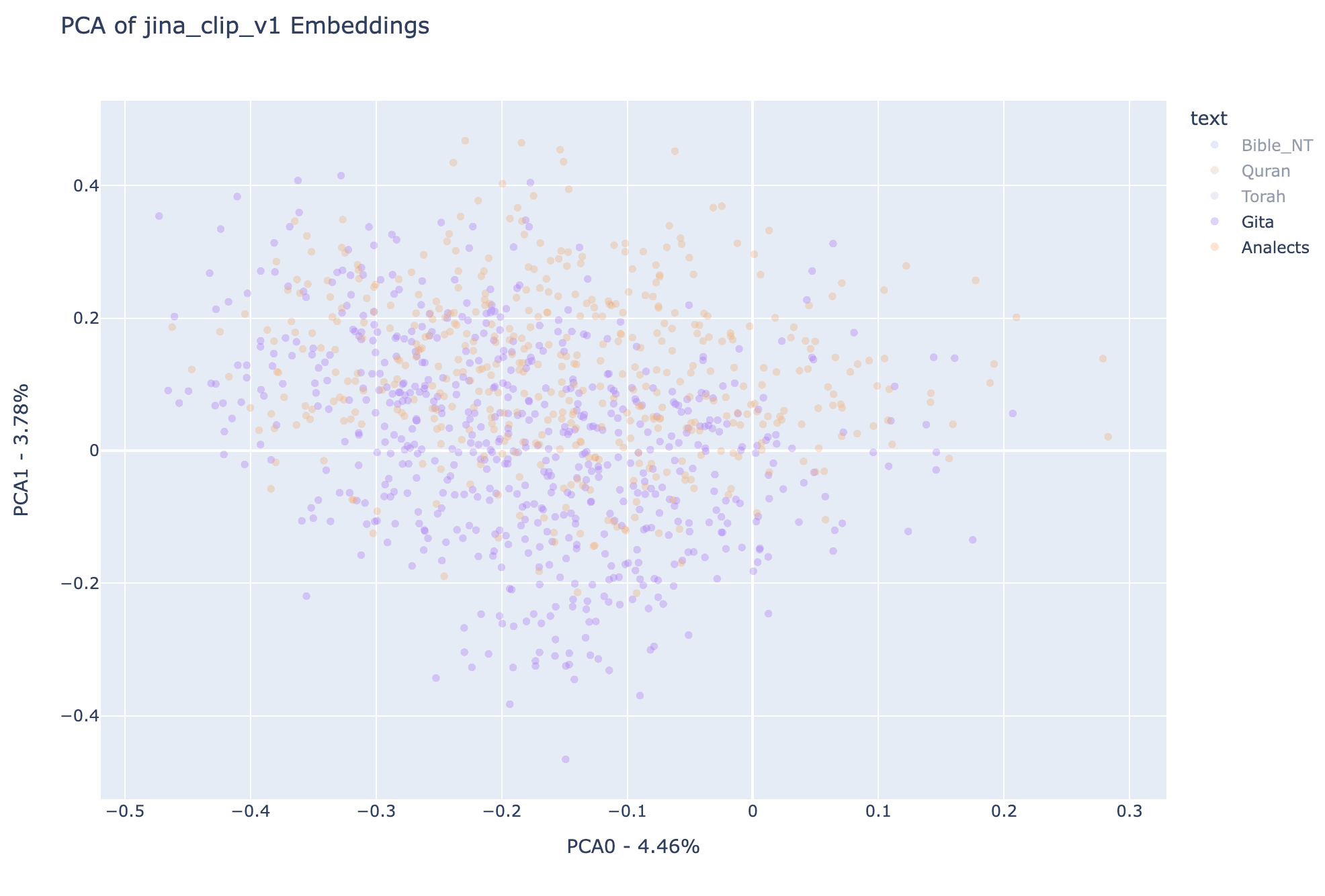
Note that all observations about regions occupied by each text in all-miniLM-L6-v2 can be replicated here for jina-clip-v1, which is a reason to believe this distribution in the first two principal components of the embedding spaces can represent something more general about the analyzed texts than simply the particular vision of each embedding model.
Semantic Hypervolume — Convex Hull
An interesting question to be made around these verse representations, that immediately captured my attention while going through the plots displayed above is: how spread are the embeddings of each of the books according to each of the models? That would be like evaluating how diverse are the themes which appear inside each of the books, how broad is the perspective captured by that part of the knowledge base.
In this effort to showcase an approximation metric for the occupation of semantic space in each embedding model I opted to evaluate the hyper volume associated with the convex hull of the representations in both embeddings spaces. This approach is influenced by recent research on embedding spaces (Check out this paper on some gaps in probability distributions generated by neural nets, and this one on innovation dynamics in patent space and economic effect)
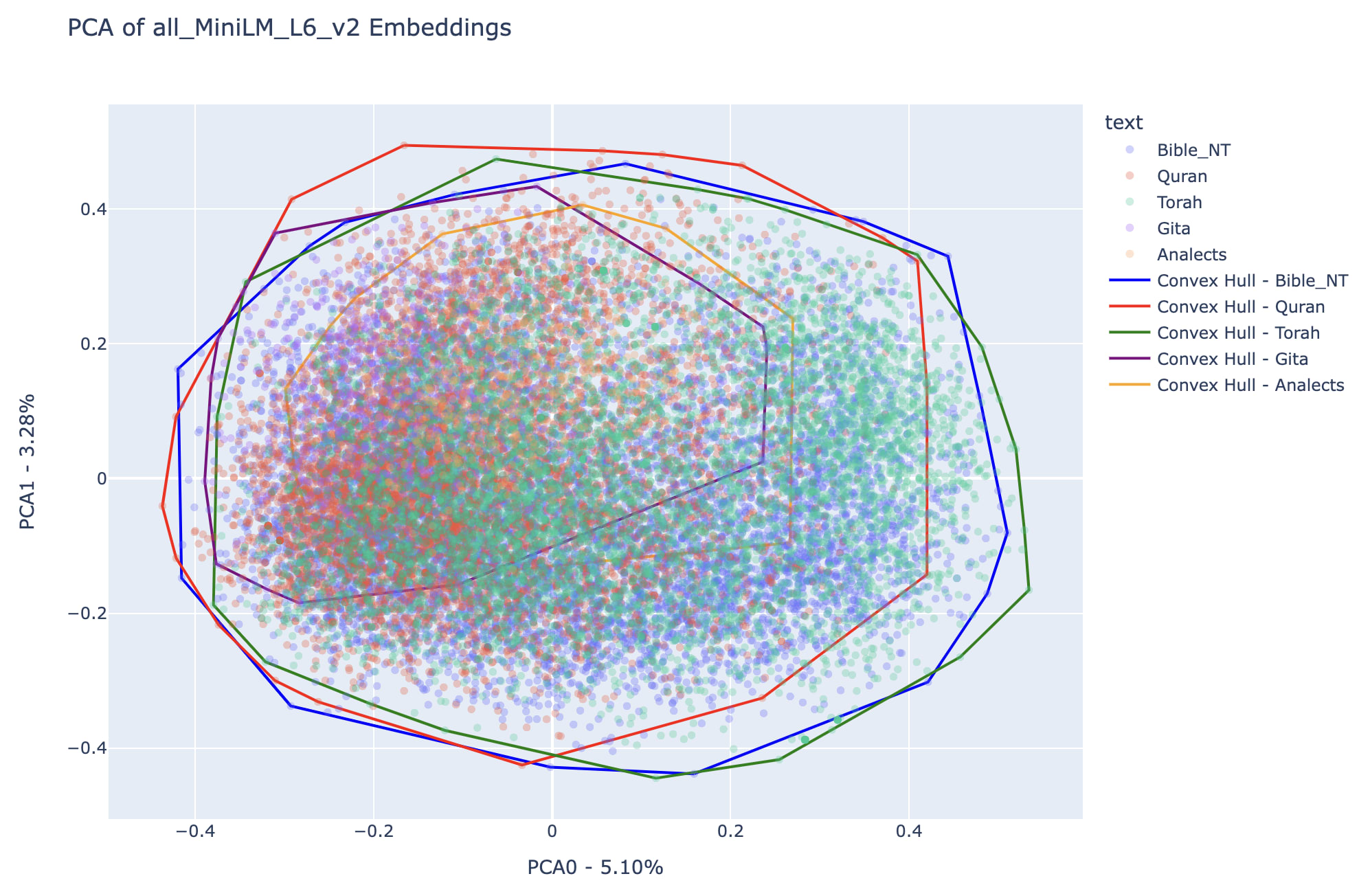
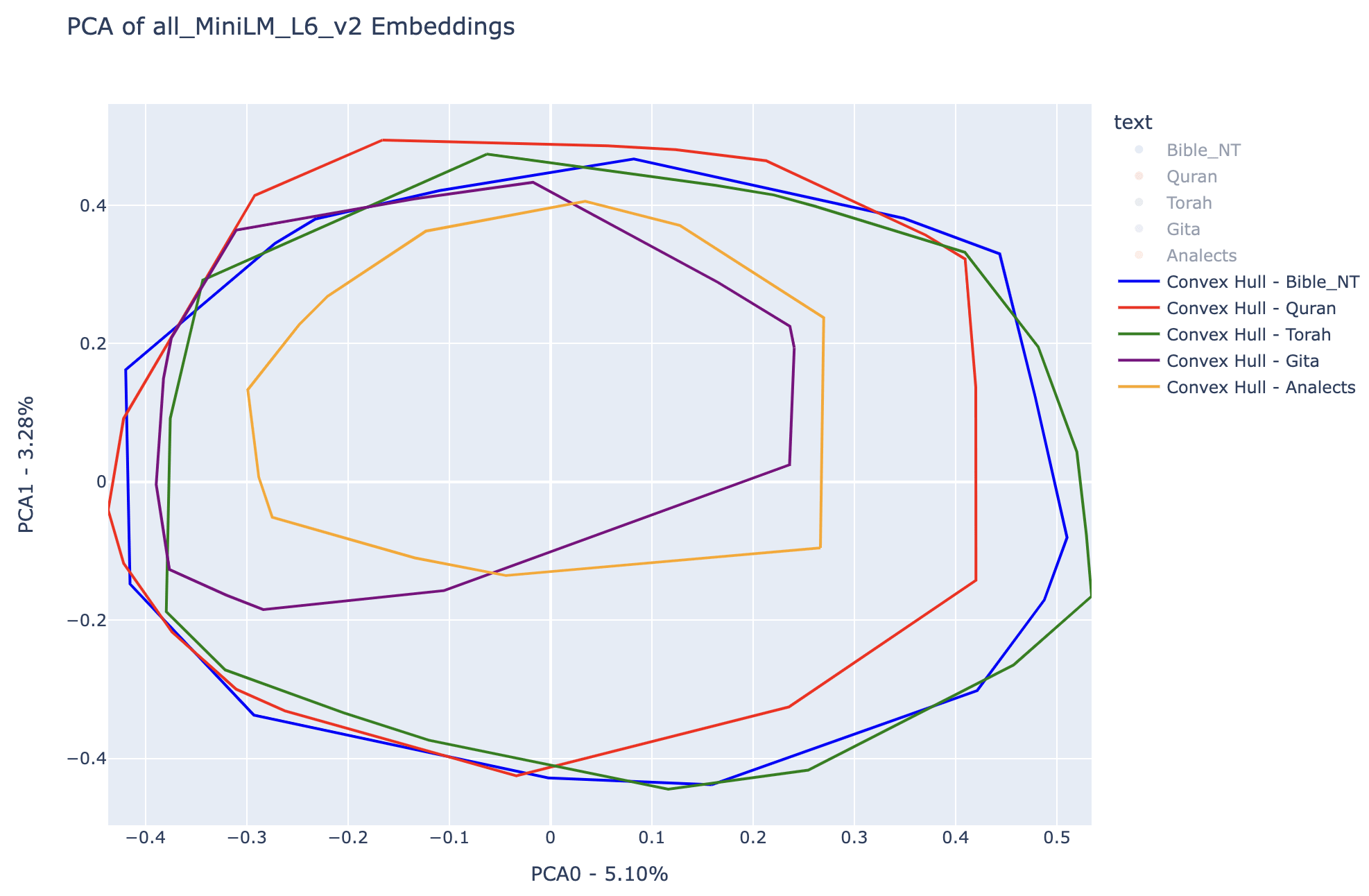
A convex hull is the smallest convex shape that encloses all the points in a given set, similar to stretching a rubber band around the outermost points. For a more formal definition of convex hull check out wikipedia page. The Scipy package offers an efficient way to define ConvexHull and evaluate its volume, checkout the documentation.
In the interest of having a metric for the hyper-volumes associated to each of the texts in relationship to the totality of the knowledge base semantic set, I formulated the following approach: For each text we will obtain the ratio between the hypervolume its embeddings occupy and the hypervolume associated to the full knowledge base (in our case, the sum of embeddings stemming from all of the five books). See equation below for the Semantic Hypervolume Fraction:
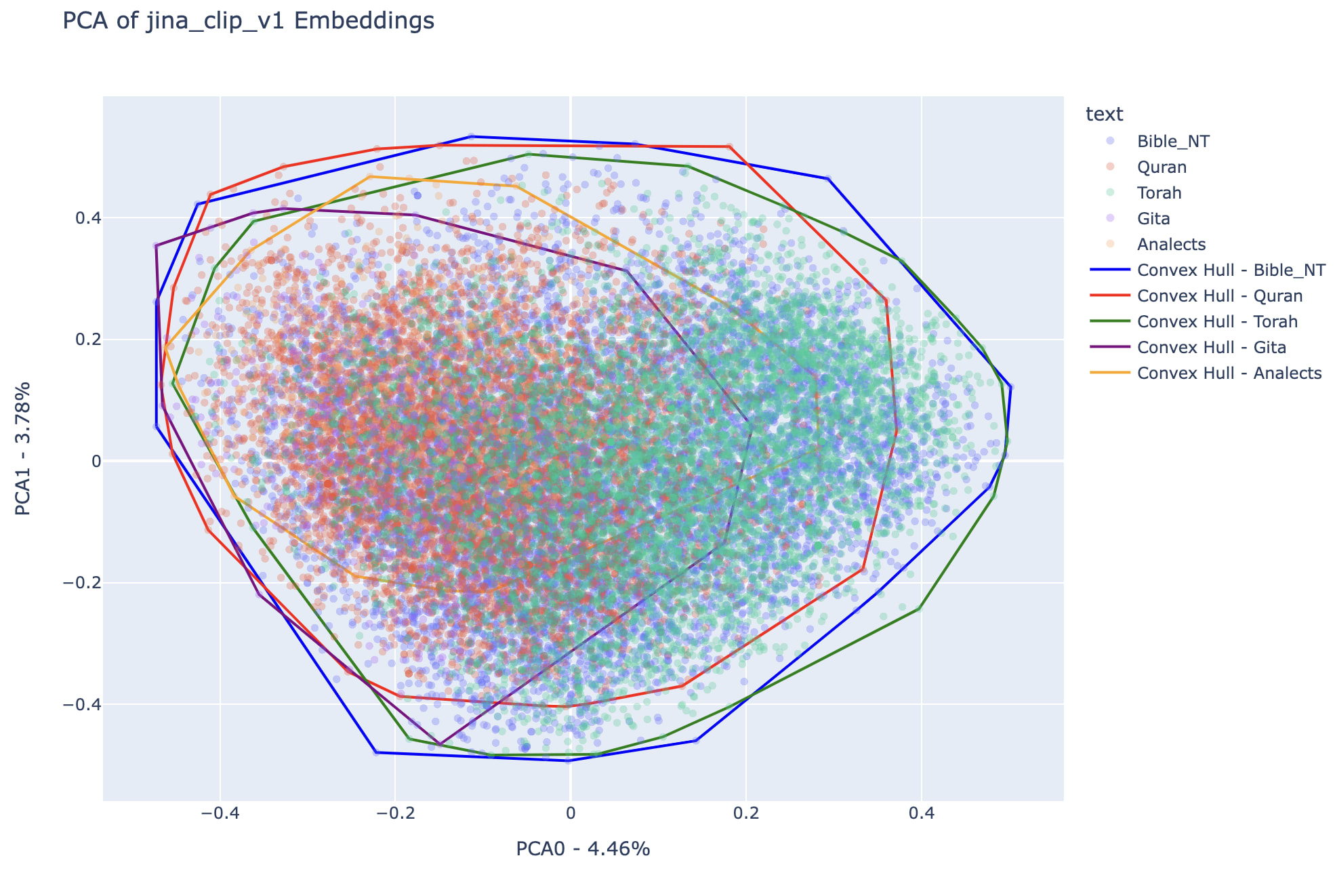
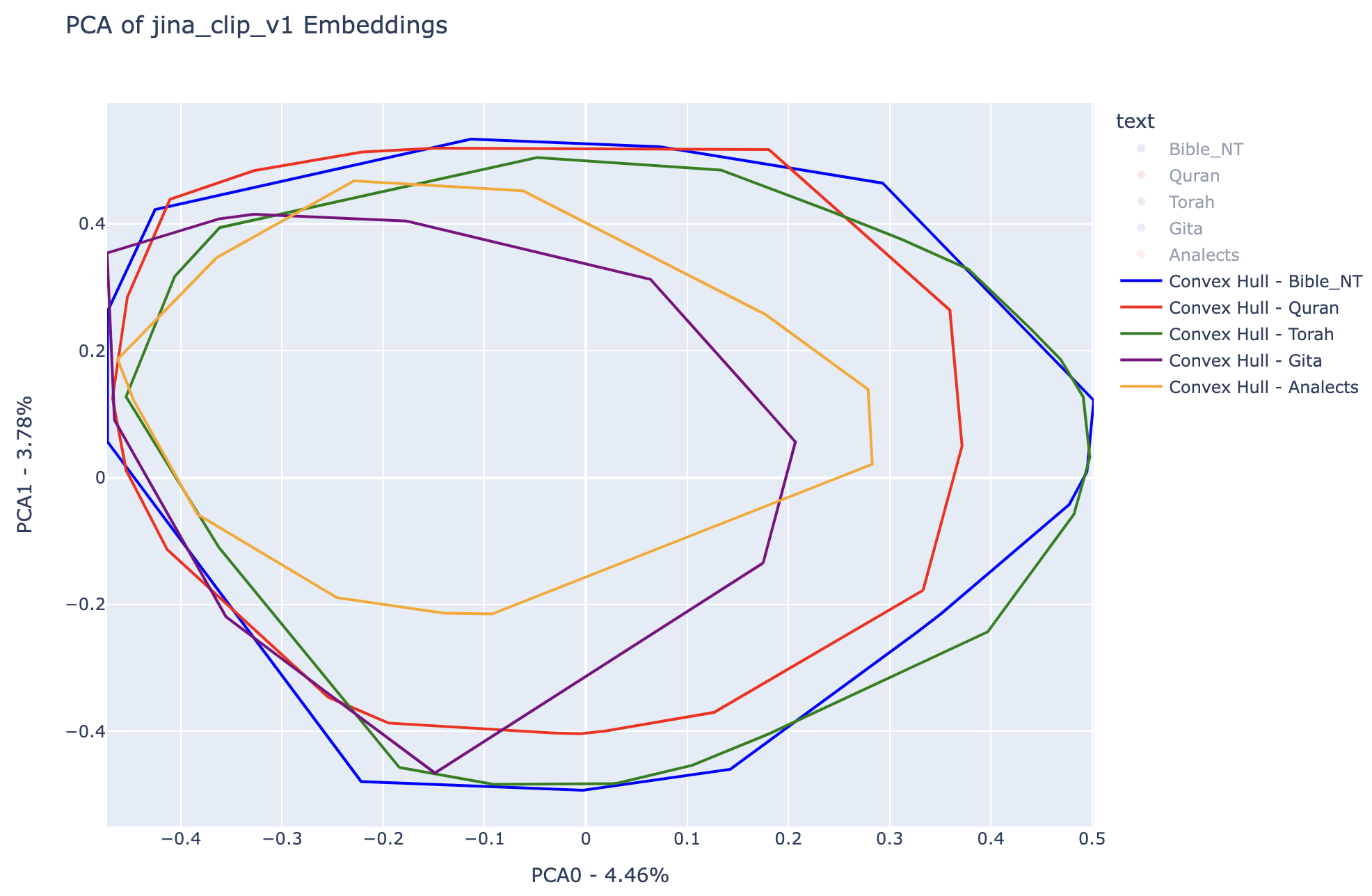
In the left see first two dimensions of PCA of jina_clip_v1 model and the convex hull associated to the embeddings of each text. In the right we have a clear view of the convex hull spaces associated to each book.
A convex hull is the smallest convex shape that encloses all the points in a given set, similar to stretching a rubber band around the outermost points. For a more formal definition of convex hull check out wikipedia page. The Scipy package offers an efficient way to define ConvexHull and evaluate its volume, checkout the documentation.
In the interest of having a metric for the hyper-volumes associated to each of the texts in relationship to the totality of the knowledge base semantic set, I formulated the following approach: For each text we will obtain the ratio between the hypervolume its embeddings occupy and the hypervolume associated to the full knowledge base (in our case, the sum of embeddings stemming from all of the five books). See equation below for the Semantic Hypervolume Fraction:
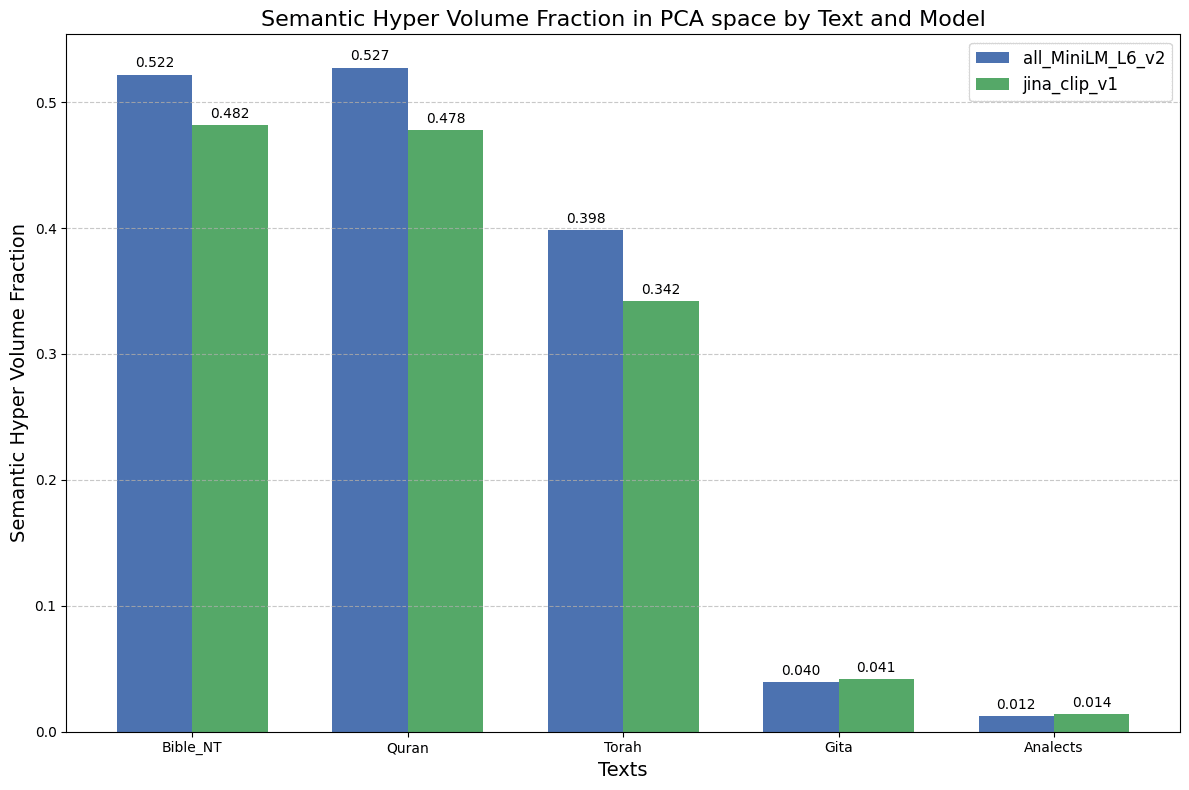
See below plots for the hyper-volume associated with the convex hull for all of the texts and embedding models, notice that for these calculations I have only used the 7 first dimensions of PCA analysis for computational efficiency (which cover 20% of all variance in semantic space):
Thematic Density
Notice in the plot above that the Bhagavad Gita and the Analects have substantially smaller hyper volume, which can be related to the much smaller number of verses in each. In fact the bar plot above is strikingly similar to the bar plot for verse count, check it out below:
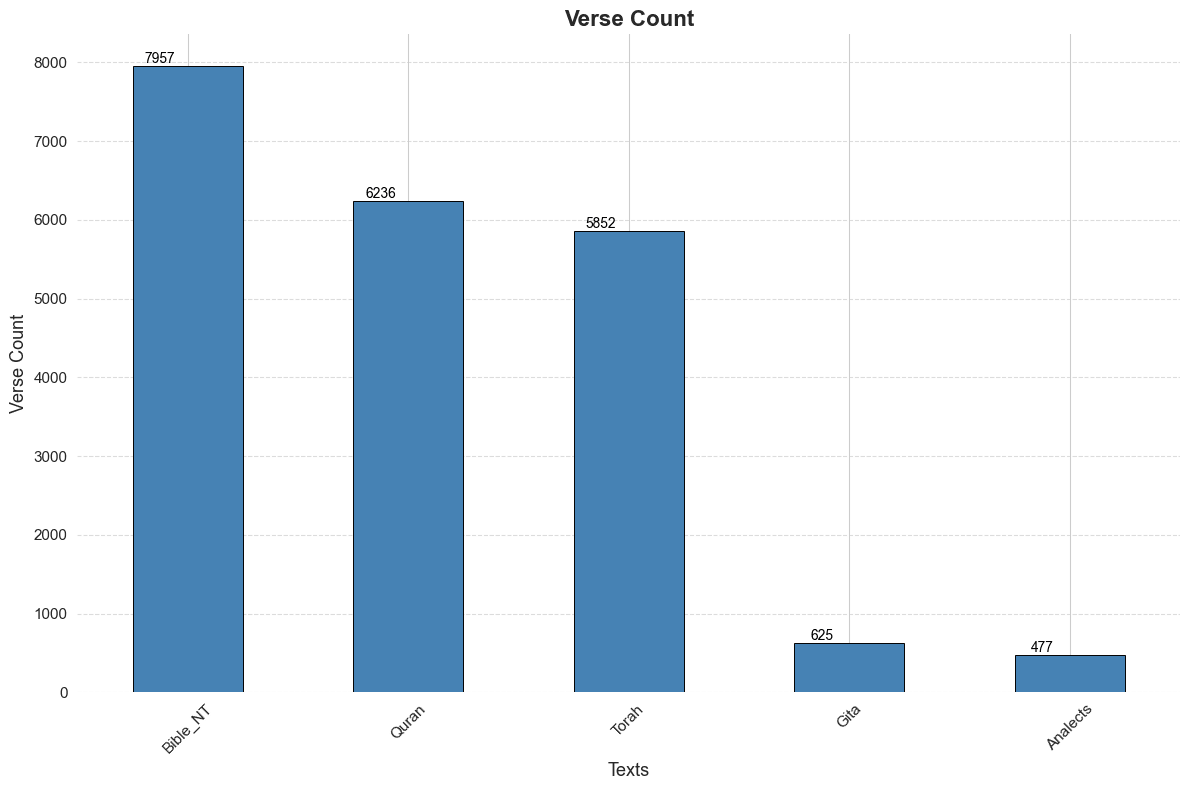
See verse count thematic barplots across all five texts.
With that in mind, I thought it would be interesting to divide the semantic hyper volume by the number of verses, allowing for a measure of "theme diversity density per verse" associated to verses stemming from each of those books. From a rigorous standpoint, this thematic density measure is the Semantic Hypervolume for the 7 first dimensions of PCA normalized by the number of embedded verses and multiplied by constant, see formula below:
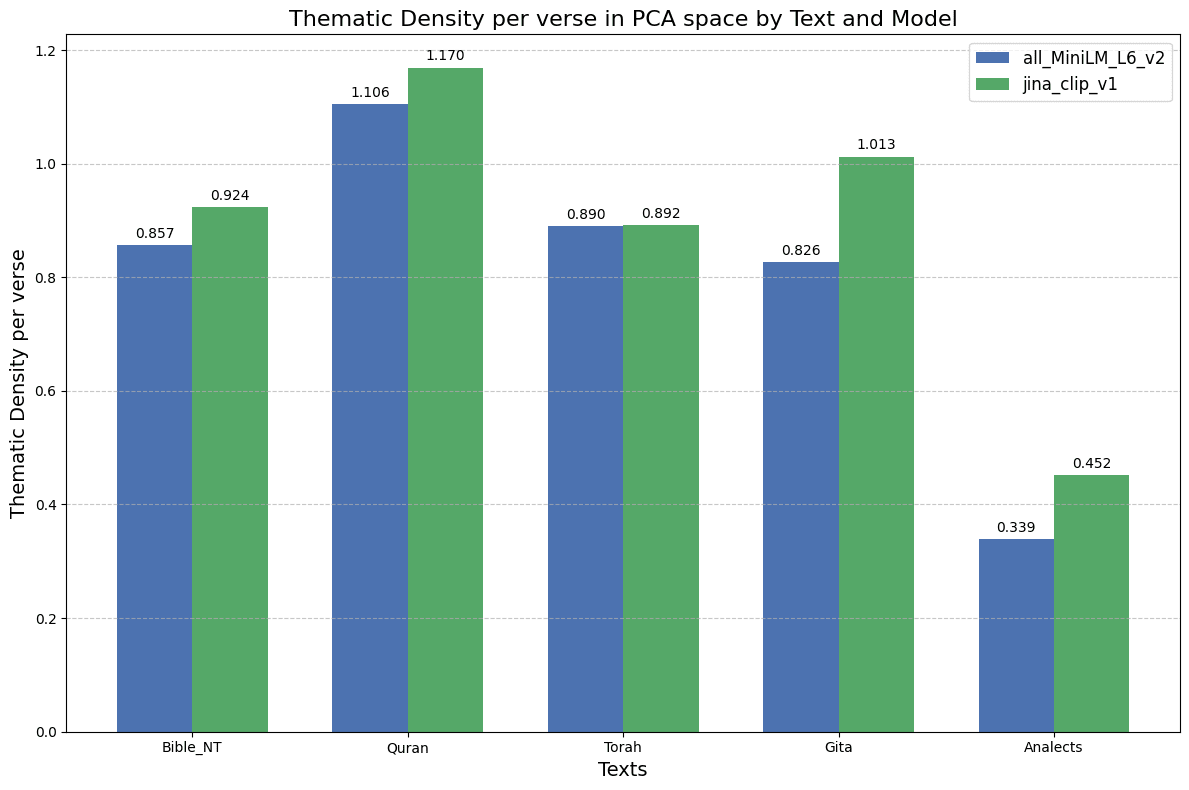
See Thematic density barplots across all five texts for the two different embedding models.
Notice that the normalization makes Quran appear as the more diverse source per verse, and also brings Gita into the same level then the other reference sources. Also note that results are very similar across both embedding models.
Intertext Similarity
In search of a more broad appreciation of similarity between entire texts, rather than the similarity between particular verses stemming from each, I have developed a simple framework for offering metrics associated with cross-text consistency.
What is consistency?
From Merriam-Webster Dictionary: "agreement or harmony of parts or features to one another or a whole". In our context of analyzing similarity between verses based on the vectorized embeddings, we'll define consistency as a statistical measure of semantic similarity between two sets of embeddings.
Math
Let's remember some of the definitions for the Semantic Similarity Network(SSN):
- Node : Each node () represents a chunk or verse.
- Embeddings : Each node () has an associated embedding vector ().
- Edge : An edge between nodes () and () representing a semantic similarity connection between the two verses.
- Semantic Similarity : A metric given by cosine similarity indexed operation in the Vector Database, applied over the embeddings .
- Similarity threshold : a value between 0 and 1.
One of the pros of introducing the threshold parameter is allowing for dedicated views into different levels of similarity requirement for introducing a relevant relationship between two chunks/verses. In a sense, we are working at a more coarse grained level than the continuous case, which could be defined using the totality of similarities available across two different texts in the weighted graphs version of the SSN mentioned in the previous article.
As novel concepts, we introduce , the similarity fraction between texts and , indexed as in , obtained according to the formulas below:
In the limit case, evaluating the similarity fraction of a document against itself when the document is made up only of repeated sentences should give out a value of 1.
Note that the value of intratextual similarity (the similarity between a text and itself) is an interesting metric, and and should be somewhat inversely proportional to the theme diversity metric that was explored through the PCA approach.
Also notice that the adjacency matrix is defined herein in a different manner than it was in the previous publication, to be specific, here we are measuring the intertext adjacency matrix in the intertext Semantic Similarity Network, rather than the intratext similarity network which was explored in the original article.
The similarity F will give us a metric for similarity of the whole of each compared texts. F is given by an integral over the adjacency matrix space, normalized by the partition function made up of all possible pairs of in text and in text .
Notice that the similarity fraction is also a function of the threshold parameter , and will naturally display different values for different threshold parameters, just as the SSN is also a function of that same threshold.
See below results for similarity threshold :
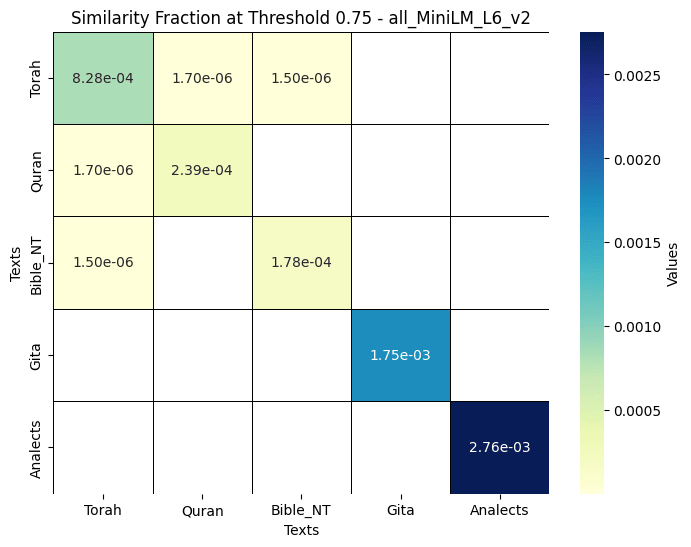
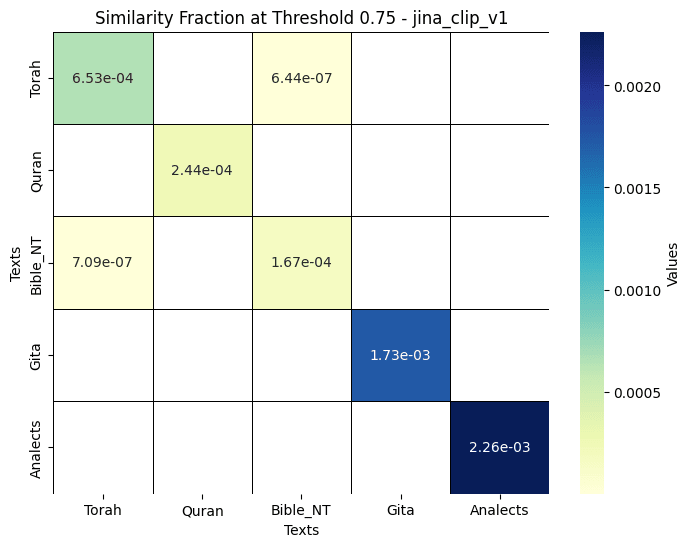
See heatmaps for similarity fraction across all five texts for the two different embedding models. Note slight asymmetry in values presented in jina_clip_v1, associated to fluctuations in the vector DB search engine.
From the results obtained above we can draw a graph where nodes are the texts themselves (rather than verses), and verify existence or non-existence relevant Intertext similarity (greater than zero) at the chosen threshold (remember for our current case the similarity threshold ). See below the resulting graphs associated to this results:
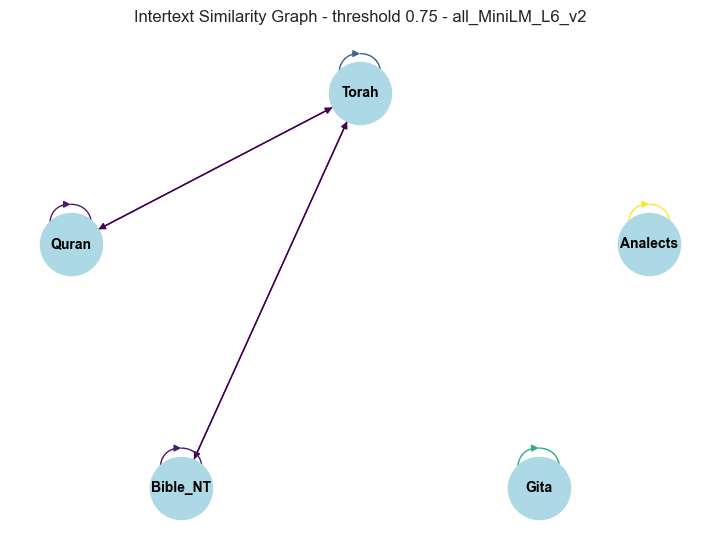
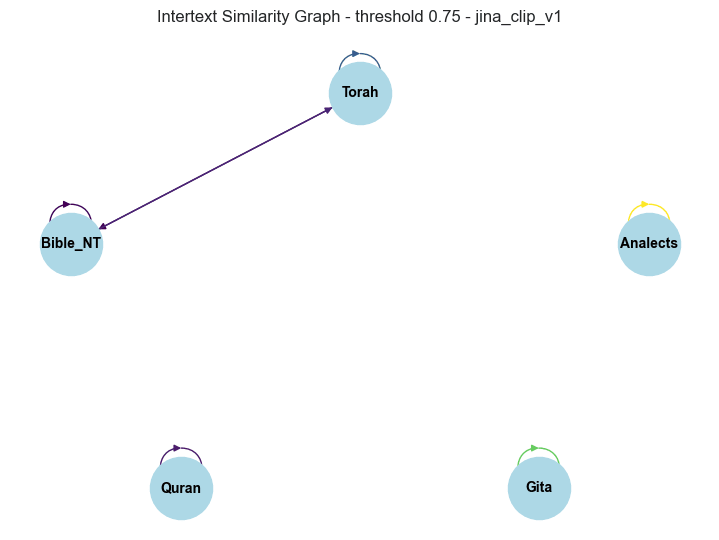
Notice that the similarity fraction at threshold 0.75 also gives relevant results for intratextual similarity, that is to say, how much themes appear in a given text are recurrently and consistently explored across the whole of the analyzed text, as mentioned above. We can plot those values in the same barplot fashion which we used to explore the thematic diversity.
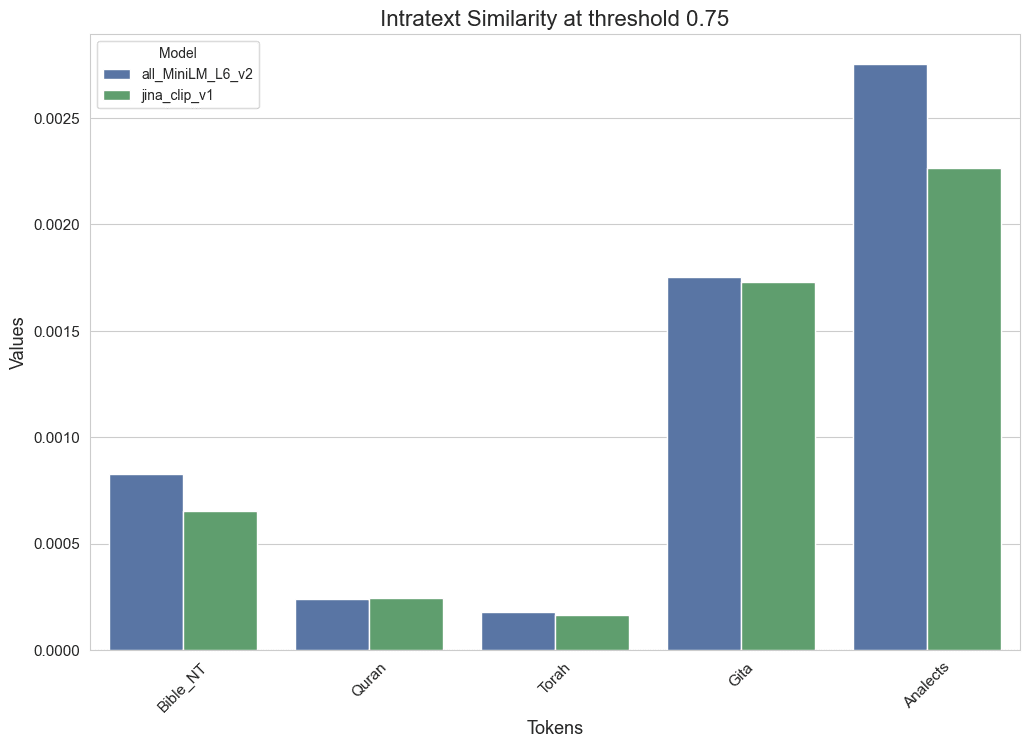
Note these results are approximately inversely proportional to the results found above for semantic hyper-volume, which is consistent with our intuition of this quantities, the more spread across different themes a given text is, the less intratext similarity we will find.
Intertext Consistency
From the Similarity Fraction F, I also defined an symmetrical version of the formula, whose purpose is to represent textual consistency, rather than similarity. That means that each text should be fully consistent with itself, also if a text is very similar to itself (repetitive), that can play the role of diminishing its consistency with a different text, with this general trends in mind I propose:
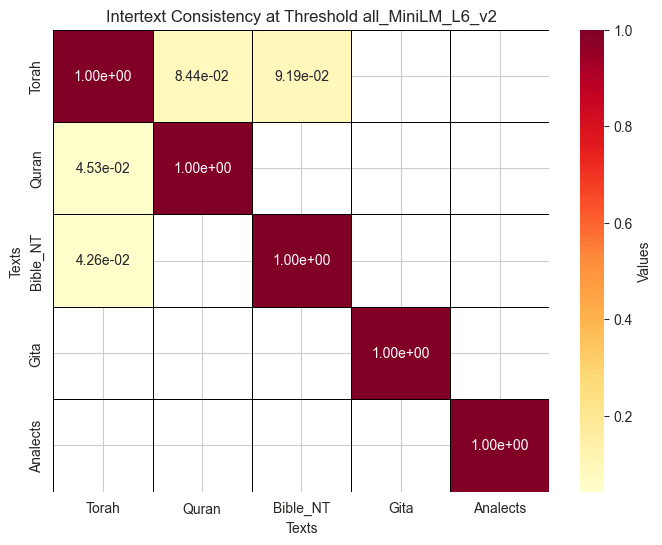
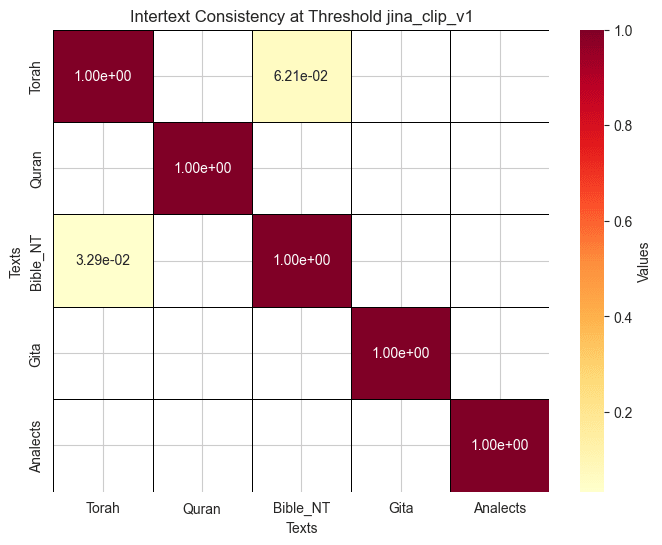
This formulation makes sure that consistency is always at one when evaluated between a texts and itself. It is also asymmetric, which allows for an understanding of non reciprocal consistency between texts, something which is consistent with a general insight provided by the results for the visualizations of embedding space. For example, if we look at embeddings made by all_MiniLM_L6_v2 model we can observe that the space occupied by The Quran is mostly a subset of the full space occupied by the Torah, this indicates that the Quran should be more consistent with the Torah than the Torah with the Quran, this is precisely the result obtained below. Check out the heatmaps:
Take away messages
Here go some takeaways from this article:
Framework and Novel Concepts
- Through representation of embedding space we are able to produce intuitions on semantics of different sets of chunks in a knowledge base, in our case the different texts which are part of the RAGenesis app knowledge base.
- Semantic Hypervolume is a powerful measure to express how theme diversity is distributed across different sections of the analyzed knowledge base.
- We define the Intertext Similarity fraction as a function of the similarity threshold, which allows us to establish direct similarity links between sets of chunks, rather than the similarity between pairs of chunks. It also allows for Intratext similarity evaluation, a complementary approach to theme diversity.
- From the Similarity fraction we define Intertext consistency as an asymmetric variation of the measure which indicates with more clarity the reciprocity or non-reciprocity in consistency relationship between two texts that are part of our knowledge base.
Results
- At threshold 0.75, The all_MiniLM_L6_v2 embedding model highlights the intertext similarity between the Quran, New Testament, and Torah, showcasing their shared Abrahamic roots, with the Quran being slightly more similar to the Torah than the New Testament is similar to the Torah.
- In contrast, At threshold 0.75, the jina_clip_v1 model emphasizes the connection between the New Testament and the Torah, indicating the link between Judaism and Christianity, but fails to recognize the relationship between the Quran and the Torah.
References and Bibliography
sentence-transformers/all-MiniLM-L6-v2 · Hugging Face
We're on a journey to advance and democratize artificial intelligence through open source and open science.
Principal component analysis - Wikipedia
Principal component analysis ( PCA) is a linear dimensionality reduction technique with applications in exploratory…
Patent Text and Long-Run Innovation Dynamics: The Critical Role of Model Selection
Founded in 1920, the NBER is a private, non-profit, non-partisan organization dedicated to conducting economic research…
Stolen Probability: A Structural Weakness of Neural Language Models
Definition of CONSISTENCY
The meaning of CONSISTENCY is agreement or harmony of parts or features to one another or a whole : correspondence…
Bhagavad Gita AI - Gita GPT - Ask Krishna
GitaGPT is a free Bhagavad Gita AI chatbot that uses the wisdom of the Bhagavad Gita to help answer your day-to-day…
Tanzil - Quran Navigator | القرآن الكريم
Browse, Search, and Listen to the Holy Quran. With accurate Quran text and Quran translations in various languages.
https://raw.githubusercontent.com/mxw/grmr/master/src/finaltests/bible.txt
Thank You : )
I’d like to thank Pedro Braga Soares for the convex hull of embeddings discussion reference and Julio Ribeiro for many discussions on the past, present and future of AI, Luciana Monteiro, Cristina Braga, Maria Teresa Moreira, Catarina Medeiros and Felipe Medeiros for fruitful conversations and alpha testing of the RAGenesis platform. Also would like to thank Anna Chataignier for continuous support.
If you got so far in this article, thank you for reading this. I deeply appreciate the time you spent, hopefully you got something good out of it. Let me know what you think! I eagerly expect suggestions, discussions, criticisms. Reach me on:
https://joaoribeiromedeiros.github.io/
0 comments
Comments sorted by top scores.