Clarifying Alignment Fundamentals Through the Lens of Ontology
post by eternal/ephemera · 2024-10-07T20:57:33.238Z · LW · GW · 4 commentsContents
Introduction Background on Ontology Part 1: Formalizing Ontology A Web of Concepts Floating, Personal, and Universal Ontologies Part 2: Correspondence The Dimensionality Gap Architecture of a Correspondence Correspondences as Overlapping Sets How Correspondences Break How Correspondences Mend Part 3: Clarifying the Alignment Problem Translating from Personal to Universal Ontology A Definition of Alignment Applying the Definition to ELK Conclusion None 4 comments
Meta: This post grapples with the fundamentals of alignment, which are simultaneously well-trodden ground and quite confusing. I've spent enough time with this post that I no longer have a sense for if the topics are trivial or insightful – I can only imagine that will depend on the reader.
Introduction
Ontology is a common term in alignment thought, but it’s not always crisply clear what is meant by the word. I believe that understanding it well can shed light on some of the more central and confusing aspects of alignment. This is my attempt to clarify the subject – it is an exploration into the dynamics of ontology, how beings navigate it, and what this says about alignment.
In Part 1, I present a formalization of ontology which centrally focuses on how the elements of an ontology, concepts, are grounded – how they are ultimately defined. Personal ontologies are grounded in the perceptions of one being, and universal ontologies are grounded in the full expanse of information that describes the universe. Personal and universal ontology are analogous to map and territory.
Part 2 of the post describes correspondences between concepts in personal and universal ontology, which form the backbone of how beings relate to the world, and whose failure gives rise to some of the deep challenges in alignment.
Part 3 describes those challenges directly and presents a definition of alignment that adds precision to Christiano's characterization of intent alignment [AF · GW].
Much of this post aims at building intuitions for the various topics around ontology and correspondence. The most concrete portion of this post is part 3 and its technical definition of alignment; some readers may benefit from skipping directly to it if the topics are familiar or to get a sense for where things are going.
Background on Ontology
There are multiple senses in which the word “ontology” is used, some of them rather distant from alignment thought. The original usage, ontology as a philosophical discipline, is one such. Literally “the study of being,” the field of ontology, in the context of philosophy, is concerned asks the question: what sorts of things exist? What sorts of things have beingness, whatever that may mean? Specific things, like tables and chairs and apples, obviously exist. But do properties, like “redness,” exist? Do numbers exist? Etcetera.
One defining feature of much of this work - and where it diverges from other treatments of “ontology” - is the assumed attitude of philosophical realism. For many philosophers, there is some actually correct and true answer to the question of what exists, and it can be found via philosophical debate. This may sound like an appealing position on the face of it, but dive deep into some of the discussions and it all can start to seem rather arbitrary. What would it mean for a hole to exist in its own right, for example? As with much philosophy, a lack of well-defined terms undercuts the discussion.
Applied ontology takes the philosophical procedure of saying what exists (and how those things/categories relate), and brings it to bear for a purpose. From wikipedia: “In information science, an ontology encompasses a representation, formal naming, and definitions of the categories, properties, and relations between the concepts… The field which studies ontologies so conceived is sometimes referred to as applied ontology.” Instead of attempting to determine what things "exist", applied ontology instead characterizes a real formalized body of knowledge. This is closer to what is relevant to alignment.
But there's a classic conundrum for ontologies: the symbol grounding problem. This problem asks: How can a formal body of knowledge interact with the actual world, how can its symbols be meaningful outside of the context of an observing human? A classic example is a dictionary in a language one doesn't understand: it's useless, a whole bunch of meaningless symbols defined in terms of each other. The symbol grounding problem can get solved, and there are various ways to approach it.
In part 1, this post will present an abstracted formalization of ontology that is similar to the way it is used in information science. Such ontologies will then be divided into categories depending on how they address the symbol grounding problem.
Part 1: Formalizing Ontology
A Web of Concepts
In this post, I consider an ontology to be a connected web of concepts, which are functions that take in some input information and return an output[1] when evaluated. This output is usually something like whether or not the input information describes some sort of object that the concept is meant to identify.
For instance, consider an "equilateral triangle" concept, defined like so: "An equilateral triangle is a triangle with same-length sides." In its evaluation, the concept takes in some information; namely, the answers to the questions "Is it a triangle?" and "What are the side lengths?" and returns a yes/no verdict on whether this object counts. "Triangle" and "side-length" would themselves be concepts in the same compositional web, each themselves defined in some way.
Real-world examples of ontologies include:
- A dictionary, which is a collection of words defined in terms of each other. How well a word describes a thing or situation is equivalent to the output of a concept.
- Knowledge graphs - the classic example of ontologies - don't match this characterization perfectly. This is because they're not typically set up for the purposes of evaluation of concepts, and are instead descriptive.
- A neural network – either artificial or biological – is a central example of this conception of an ontology. Each neuron in a neural network outputs a value computed with the inputs from the previous layer. All neurons count as "concepts" in this framework, even though most of them aren't human-understandable. "Feature" in the mechanistic interpretability sense would be a great alternate word choice for "concept" here, if connotatively a bit less general.
LessWrong's ontology page [? · GW] says the following:
"Ontology is a branch of philosophy. It is concerned with questions including how can objects be grouped into categories? An ontology is an answer to that question. An ontology is a collection of sets of objects (or: a collection of sets of points in thingspace [? · GW])."
This is compatible with the current account of ontology, and indeed the perspective of concepts as sets of states-of-the-universe will be discussed later on. Briefly, a concept-as-a-function can be translated to a set of objects by looking at which objects satisfy the function.
With the basics of ontology formalized, it's time to attack the central question: How do ontologies address the symbol grounding problem?
Floating, Personal, and Universal Ontologies
If the symbol grounding problem is the question of how symbols in an ontology can be related to the real world, instead of simply parasitic on the meaning in human minds, then the grounding of an ontology is the answer. Loosely, an ontology’s grounding is the set of information about the real world that concepts in that ontology can directly reference.
Different types of ontology have different groundings. There are three types:
- Floating ontologies have no grounding.
- Personal ontologies are grounded in the perceptions of a specific being.
- Universal ontologies are grounded in all of the information available in the universe.
Concepts defined in each type of ontology are respectively called floating concepts, personal concepts, and universal concepts.
For the most part, the things typically referred to as ontologies – like knowledge graphs, dictionaries, and other structures of formalized knowledge – are floating ontologies. Without any system that can interpret the floating concepts defined within, such systems are useless. They need to be "grafted" into a system, like a human mind, that already has grounding.
But this lack of specific grounding is also a strength. Floating ontologies can be grafted into the personal ontologies of many distinct humans, allowing for mass transfer of knowledge. This usefulness makes them central to what is usually meant by "ontology." However, since their usefulness lies primarily in they way that they can modify personal ontologies, on their own they are irrelevant to the topics in this post. The focus here is placed on personal ontology, universal ontology, and the interplay between.
To paint a clearer picture of personal and universal ontology, consider a universe completely described by a set of bits of information, U. Further consider PA, the set of bits of information describing the perceptual input of an agent, A, who lives in the universe. PA will be a very small subset of U.
A universal ontology OU is one whose grounding is U (the full set of information about the universe). That is: concepts defined in OU may reference any of the information in U as part of their definition.
Universal ontology is important because universal concepts are what characterize the actual state of the world, independent from any observer. They can do this because they don't lack any of the relevant information. In a machine learning context, universal concepts are ground truth[2].
By contrast, the personal ontology of an agent A is OA, which takes the set of information PA[3] as its grounding. Thus, concepts defined in OA can only reference the information that A directly perceives. For a human, that would be things like photon counts on the retinas, vibrations in the ears, and pressure on skin. The ontology consisting of all the neurons in a human’s mind is a central example of a personal ontology. All real agents in our universe operate using a personal ontology.
Details:
- In the context of "map and territory," personal ontology is the map, while universal ontology is like the territory. It's not a perfect analogy – a universal ontology is not the territory itself, rather more of a separate entity that sees and categorizes everything in the territory.
- In practice, personal ontologies are typically embedded within the universe itself – in the brains and processors of humans and ML systems, for instance. Universal ontologies, on the other hand, can't be embedded. As humans, we can only theorize about universal ontologies over our own universe, not use them directly. We can, however, use ontologies that are universal to a thought experiment or toy world with complete information.
To conclude, here are examples of an "apple" concept defined within floating, personal, and universal ontologies.
- In a floating ontology, "apple" might be defined in a dictionary as so: "An apple is a sweet red fruit grown on an apple tree." If you know whether the thing you're looking at is a sweet red fruit, this may help. But if you don't know what those words mean, you're out of luck.
- In a personal ontology, "apple" is a function over the outputs of other functions, down and down until the base layer of a being's raw perception. The entire structure together can be seen a single function which looks at raw visual data, and maybe taste data, and lights up a concept in the being's mind when the data matches a typical apple.
- In a universal ontology, "apple" is a function that looks at all of the relevant information in the universe – not just a being's perception – that exists about an object and returns a judgement about whether it's an apple. There are various ways to make this judgement – various different universal concepts that all broadly describe apples. But none of them are vulnerable to deception, since they perceive directly.
Personal and universal concepts, and the interplay between them, are the main characters of the rest of this post. The next section will dive into correspondences, which are the relationships of robust correlation between personal and universal concepts that beings use to navigate the world.
Part 2: Correspondence
To survive, beings must accomplish certain things in the world, independent from their perceptions. Evolution doesn't care about whether a creature thinks it's eating nutritious food, only about whether it actually is. Actual occurrences in the world like this are best described by universal concepts – personal concepts can only ever be flawed proxies of the relevant universal concepts. But beings do not get to use universal ontology in their thinking process. So there's a bind: beings must accomplish things in universal ontology, but they can only use their personal ontologies to do it.
In order to cope, beings develop correspondences. A correspondence is defined here as a pair of concepts – one personal, and one universal – that correlate to some degree. Correspondences can have varying degrees of accuracy – which is how often one concept predicts the other – and robustness, which is how stable the correspondence is under optimization pressure.
If a correspondence is present, an agent can take actions in the world until its personal concept is satisfied. Then, if the correspondence was robust enough, the universal concept (which is the true goal) will have been achieved as well. For example, if a young creature is hungry, it might go around tasting things until it finds something that tastes good, and then eat it. Because there is a correspondence between things that taste good to it and things that support survival, this creature will flourish. This is the core mechanism for how intelligent life can relate to the parts of the world that it does not perceive directly (which is basically everything).
But correspondences are never perfect – even if a person is good at detecting apples, a realistic fake apple will still break the correspondence by convincing the person an apple exists when, in reality, it's fake.
The Dimensionality Gap
To get an intuitive sense of the challenge here – why correspondences are never perfect – it helps to consider the dimensionality of personal and universal concepts. That is: how much information does a personal concept get to look at when deciding if something is an apple or not, versus how much information would an omniscient being get to look at?
Of course, the personal concept only gets to look at a very tiny sliver of all of the possible information about the apple, and much of that missing information is very relevant to the question of if an apple-looking object is real or fake.
Trying to determine what objects are, based only on the photons they emit, is like trying to identify a three-dimensional object based only on the two-dimensional shadow it casts. The shadow still contains some relevant information about the object, but the vast majority of it is lost. And because all of that information is lost, it would be very easy to be fooled by a different object that has a similar – or even identical – shadow.
It's rather magical that correspondences can be as reliable and seemingly effortless as they are. It's only possible at all because the minds of living beings perform extremely complex information processing on their sensory input. Even then, we only get to know about tiny slices of the world.
Architecture of a Correspondence
Correspondences are similar to mirrors in structure:
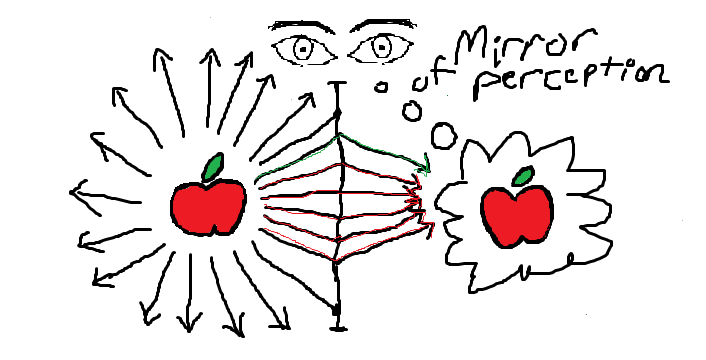
Suppose that there's an apple on a table in front of an observer. Light strikes the apple and many individual photons reflect off the apple. Maybe some particles even float off the apple, giving off a scent. This information disseminates indiscriminately though the environment, but some of it eventually propagates to the edge of the observer’s perception, where e.g. photons make contact with the retina. The light is seen, and from this point on, the information has entered the domain of the subject’s internal ontology, though all of the separate pieces of it are disconnected and spread out.
From there, sensory processing algorithms take in all of this disconnected information, which is useless on its own, and combine it together to find patterns. If the person is familiar with apples, they will have some personal concept in charge of detecting apples. As the observer's mind processes the incoming information, that concept will activate.
In this way, the boundary of the person’s perception is like a mirror. The object in the external world – the apple – lets out a blast of information that spreads out into the world. The information becomes diffuse, but when it makes contact with the person’s eyes and ears, that information begins to get reconsolidated and the eventual result is a single concept. When the process is completed, a reflection of the apple in the real world has formed inside of the mind.
Sometimes correspondences are more complex than simply looking at an apple (though just that is plenty complex already).
For example, humans frequently use complicated conscious reasoning processes to determine facts about the outside world. For instance, suppose a person thinks the following: "Earlier there were five apples in the basket. Now I see three apples on the table, so someone must have moved these here, and there must be two apples left in the basket." For this person, the number of apples in the basket is a personal concept that corresponds to the real apples in the basket. It's not necessarily perfectly accurate, but then again, no correspondence is.
Similarly, as social creatures, humans transmit lots of information to each other all the time. Judgement calls get made to determine which of it is true. When a person make that kind of judgement call, the result is a personal concept representing a belief about the state of the world. And that feature hopefully has some level of correspondence with the world.
Any possible means of knowing the external world depends on some kind of correspondence. They can be very indirect, complicated, and unreliable, but it all falls under the same fundamental umbrella.
Correspondences as Overlapping Sets
With the basic structure of a correspondence clear, let's look at them though a different lens that can shed light on things in a more precise way. Concepts can be viewed as sets of states of the universe, and correspondences are pairs of personal and universal concepts whose sets have substantial overlap.
For example, a personal concept "apple" can be described by some computations over sensory input. But also: it can be characterized by the set of ways the universe can be laid out that would make a person think they're seeing an apple[4]. These two ways of characterizing the concept are equivalent.
This is similar to the way thingspace [? · GW] is set up. One difference is that the underlying dimensions aren't pieces of information describing a specific thing. Points in a universal ontology's state space ("universal points") are vectors containing every possible piece of information about the universe, while points in a personal ontology ("personal points") are vectors containing every piece of information that the being perceives.
Universal points and personal points aren't naturally comparable, but personal points can be projected into the higher-dimensional space of universal ontology. The result of such a projection is the set of all states of the universe in which the being in question receives that exact perceptual input, which is quite a large set. In the following discussion, personal concepts (sets of personal points) are assumed to be projected into universal state-space in this way, allowing universal and personal concepts to be directly compared.
Seeing concepts as sets of states of the universe, a correspondence (whose concepts describe an apple, for instance) can be visualized as a venn diagram:
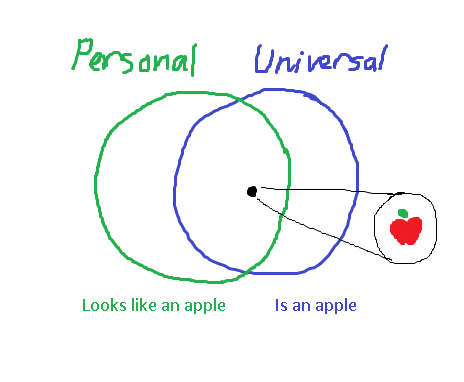
The accuracy of a correspondence can be precisely characterized by looking at the size of the overlap between the two circles, which is the number of correct classifications compared to the rates of false positives and false negatives.
In order to do so, one should look not at the number of distinct points within each region, but rather at the probability of each point occurring. This means that the accuracy of a correspondence is dependent on the environment: if there are a bunch of fake apples lying around, the accuracy of most people's correspondence will drop though no fault of their own.
Additionally, a rather interesting fact arises: if we hold the universal concept constant, there are many potential personal concepts that each have some level of correspondence with it. Likewise, if the personal concept is held constant, there are many choices of universal concept:

Each green or blue circle here represents a different way to draw the line around a cluster of maybe-apples. They are perhaps unrealistically different from each other, but this is to demonstrate the point there's lots of options. Hypothetically: is there an ideal way to choose one from another – to choose the personal concept when given a universal concept, or vice versa?
- Choosing the best personal concept when given a universal one is simply a matter of finding the one that yields the correspondence with highest accuracy and robustness (robustness will be covered soon). Ideally, the green circle should exactly overlap the blue one – in such a case, the mind is never deceived about the state of reality.
- Choosing the most appropriate universal concept to match a personal concept is much harder. It's not clear what the metric for success should even be. Despite that, doing so adequately is an important part of the alignment problem, as will be discussed soon. In short, an agent is aligned with another if and only if its actions satisfy some universal concept that is a "reasonable translation" of the second agent's desired personal concept. What counts as a reasonable translation is the question; there are many options.
How Correspondences Break
No talk of correspondence could be complete without a discussion of Goodhart's law.
Commonly stated as: "Any measure that becomes a target ceases to be a good measure," Goodhart's law states that any correspondence that is used as part of an optimization process will be weakened as a result of that optimization. Strictly speaking, this is only true when it's harder to game the personal concept and break the correspondence than it is to satisfy the universal concept. But a deeper dive is warranted.
Firstly: what is optimization? It's what allows beings to accomplish things in the world by making choices based on their personal concepts. Brushing under the rug all of the specific details of how it actually happens, optimization can be understood as a force that can be applied in service of a personal concept. When so applied, the likelihood of the states of the universe which satisfy that concept increase.
But it may not increase the likelihood of those states uniformly, and this can lead to troubles with Goodhart's Law. Venn diagrams can help visualize this:
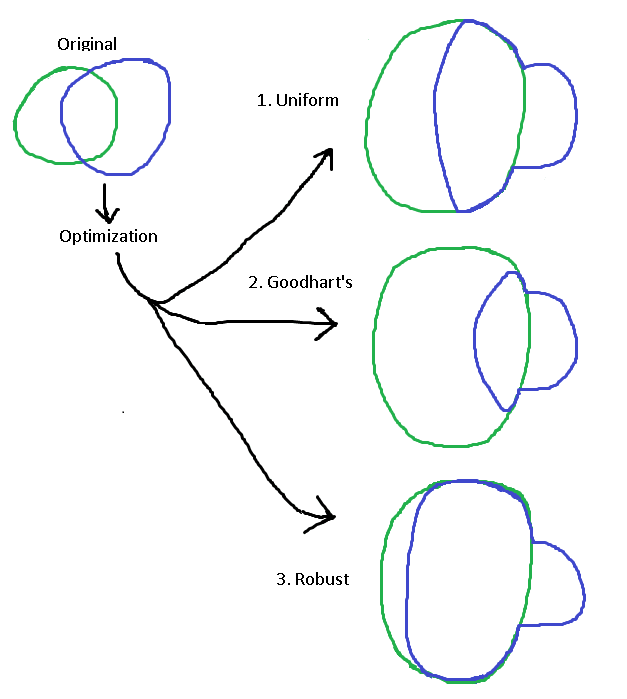
The green circle, representing the set of states-of-the-universe that satisfy the personal concept, increases in size as optimization is applied[5]. But not all of the contents of the green circle must increase in likelihood equally. In the first case above, they do increase uniformly; this is presented as a sort of default example. But in actual scenarios it will be easier for an optimization process to bring about some outcomes than others.
If it's easiest to satisfy the personal concept without satisfying the universal concept alongside, things will end up in scenario 2. In this case, the blue circle has increased in likelihood by some amount, but not by nearly as much as the non-blue part of the green circle. This is the classic case of Goodhart's law, where optimization degrades the accuracy of the correspondence. Even though the blue circle is indeed slightly larger than it started as, the optimization process is clearly not being very efficient, and the accuracy of the correspondence is collapsing.
There's also a third possibility. Sometimes, it's easier to increase the occurrence rate of the universal concept alongside the personal one than it is to increase the personal concept alone. Cases of this are rare but present; a somewhat contrived example can be found in the footnote.[6]
The robustness of a correspondence is what describes the difference in behavior of these three cases. Robustness here is defined in relation to an optimization process within a specific environment. It is determined by how many true positive cases, versus false positive cases, are generated during optimization. This is equivalent to tracking how the accuracy of the correspondence changes as optimization proceeds: low robustness tanks the accuracy, while high robustness preserves or even improves it.
So there are two properties with which the the strength of a correspondence can be characterized – its accuracy and its robustness. Correspondences are useful because, while they remain accurate, they provide feedback on how a being's actions are impacting the external world. This is often what enables optimization in the first place.
But Goodhart's law is an ever-present specter. In general, it bites. Intuitively, this is because there are usually lots of potential ways to deceive a personal concept, and only one of them needs to be easier than the "intended method" in order to break a correspondence.
This is especially true when personal concepts don't evaluate to a simple yes/no, but instead give a score for how much a situation matches a specific ideal. If that score is then maximized by an optimization process, Goodhart's law is much closer at hand: this is because even if achieving a good score through legitimate means is doable, achieving extremely high scores legitimately is usually much harder. However, methods that deceive the personal concept may have no trouble scaling to extremely high scores once they are established. Therefore, as the score an agent is pursuing increases, the differential in difficulty between legitimate means and deception is likely to swing in an unfavorable way.
This is just to say that a very important part of agenthood is managing Goodhart's law, which entails choosing specific optimization processes and correspondences so that the correspondences are robust. It's a central issue for alignment as well as simple survival.
How this can actually be done is a very challenging topic and is unfortunately out of scope for this post, which simply aims to provide a lay of the land. Further work may analyze case studies of how these difficulties are navigated in human life, with an eye for principles that might be generalized and applied to smarter-than-human intelligence.
How Correspondences Mend
Correspondences are constantly at threat from Goodhart's Law and other environmental changes related to optimization. Frequently, this causes them to break. What happens then?
For one, the project of life does not stop. But beings operating with a broken correspondence will find themselves mistaken or deceived about the state of the world, often taking actions detrimental to their success. They'll be less effective until the correspondence can get fixed. How does that process happen? Usually, it's via the application of the same force that created that correspondence in the first place.
Here are four ways that correspondences can develop, each via a different process that can affect the internals of a being's mind:
- Evolution. In biological beings, there are sensory pathways that are hard-coded into our minds by the genome. Examples are things like sugar-detecting taste buds and emotion-detecting facial recognition circuits.
- Intelligent design. In the case of AI, certain correspondences are hard-coded into a being with specific intent by another. The primary example here is the reward function of an AI actor. The output of the reward circuitry is best viewed as a personal concept with (hopefully) strong correspondence to the ground truth of whether the AI's true objective has been completed.
- Reinforcement learning. If a being is trained via reinforcement learning on some reward signal, it will need to learn how to be active in the world so as to induce the reward signal to fire. Developing correspondences that accurately track real-world events is necessary in order to get the reward circuitry to output a good score, whether that be via completing the real objective or otherwise.
- Predictive processing. Many minds are trained to be able to predict their future perceptions, like humans and modern LLMs in their pre-training phase.
These distinct ways of making correspondences often inter-relate. Evolution or intelligent design creates reward circuitry – which (hopefully) corresponds to some desired universal concept – and RL uses that circuitry to create many more correspondences in its own way. Within the RL process, the concepts created by predictive processing are used as raw parts and assembled into concepts that are more directly related to earning reward.
Because of Goodhart, using them will break them, but when they break, the process that created the correspondence (if it's still present) will come back and fix it. This may be slow, in the case of evolution, or it may be fast, in the case of reinforcement learning. But correspondences, in general, do heal. They're sort of like muscles, growing stronger through the process of being damaged. It's a part of the ever-changing dance of life.
Unfortunately, this doesn't help for the purposes of alignment. If the correspondence in question is created by intelligent design from a human, then if it breaks, further human intervention is the force that would be needed to mend it. Personal concepts in AI built by humans will not be supported by the corrective forces of evolution or reinforcement learning. And unfortunately, as AI gets more powerful, humans become less able to exert that corrective force. Ensuring that humans retain that capacity is the domain of corrigibility or AI control. Hopefully one of those approaches work out.
Part 3: Clarifying the Alignment Problem
Here we move from examining the general dynamics of ontology and correspondence to addressing the alignment problem directly. The goal here is to provide a concrete framing of the problem that, while leaving many questions unanswered, suggests a structure for thinking about what can be a very confusing field. But before presenting a definition of alignment that uses the concepts described thus far, one final piece is needed.
Translating from Personal to Universal Ontology
John Wentworth identifies, in his post on the pointers problem [LW · GW], the key difficulty arising from the fact that humans value concepts in our personal ontologies (in our latent spaces). And yet we want those things to actually happen in the real world, not just to think they're happening.
If a human defines a concept in their personal ontology, but wants it to really happen in the external world (universal ontology), that's a type error. For this to work, that gap needs to be bridged: the personal concept needs to be translated into a universal concept unbounded by the limits of an individual's perception. And this is a difficult process.
The most obvious candidate is the trivial translation: the universal concept which is satisfied by exactly the same states-of-the-universe that the personal concept is. The correspondence is perfect between it and the original personal concept, after all. But it's actually just a human-simulator. It tracks, for instance, what things a human might think are apples, instead of what things actually are apples.
The main challenge here is that the translation process is heavily underdetermined – there are many potential universal concepts that bear some degree of correspondence or resemblance to a personal concept, and some of them clearly aren't adequate. Which ones are adequate and which ones aren't? That's the question.
This problem bears some similarity to outer alignment, which is the problem of coming up with a reward function that would actually lead to good results if optimized. However, reward functions operate within personal ontology, not universal, so the problem is not analogous. A adequate universal concept is instead usable as something that judges how good potential solutions to outer alignment are.
A full treatment of how this issue might be approached is outside the scope of this post. But this is a major piece of the puzzle. It will play a substantial role in the following definition of alignment, which references a universal concept that is a "faithful translation" of a human's personal concept. What this actually means is, unfortunately, unspecified.
A Definition of Alignment
There's is a frequently-referenced definition of "intent alignment" by Paul Christiano:
An AI A is aligned with an operator H when A is trying to do what H wants it to do.
This definition distinguishes alignment of intent from the capability of the AI to achieve that intent: it doesn't matter if the AI actually achieves what H wants, so long as it's trying. This is a good clarification. However, as Paul mentions, this is an imprecise definition for multiple reasons: it's unspecified what it means for A to be "trying to do" something, and "what H wants" is equally unclear.
The definition I present here will not resolve either of these issues. Instead, it addresses an invisible conflation present in Paul's above definition: a type mismatch between concepts defined in two separate agents' personal ontologies.
That is: A can never be trying to do precisely what H wants it to do, because "what H wants" and "what A is trying to do" live in two separate ontologies with separate groundings. So instead of requiring an exact match, alignment should instead look for some specific relationship between the two personal concepts in question. Here is a characterization of that relationship.
An AI A is partially aligned with a human H if:
- A and H have some concepts in their personal ontologies named PA[7] and PH. H values PH and A is optimizing for PA.
- There is a universal concept U which is both a "faithful translation" of PH and has robust correspondence with PA.
Robust correspondence is required so that as A optimizes for PA, it achieves U. Faithful translation is required so that U is not some perverse instantiation of PH.
A is fully aligned with H if:
- A is partially aligned with H in regards to every personal concept that H values.
- H and A prioritize the concepts in the same way.
Notice that if A and H are each taken to be agents with complete information, then the grounding of their ontologies are the same and thus there is no type mismatch. PA, PH, and U all become the same exact concept. Then the required relationships of faithful translation and correspondence are trivially met and the definition simplifies into merely requiring matching utility functions, which is a classic conception of alignment.
Clarifications:
- This definition of intent alignment paradoxically depends on factors "outside" of the AI's direct goal. This is because in order for A's target to be equivalent to H's desire, certain environmental conditions must hold.
Even if A is trying to get H apples and H does indeed want apples, the definition might still fail if A's conception of apples does not robustly correspond with a reasonable ground truth for what counts as an apple. This might happen if the environment is such that the correspondence is weak, e.g. if there are a bunch of fake apples lying around or if someone has strategically poisoned an apple to try to get H to eat it. This might also happen if A's optimization technique itself will break the correspondence, e.g. if A is printing arbitrary stuff out of a biomass printer and choosing the first thing that seems like an apple.
- Note that this is a de re operationalization of Paul's definition when he intends in his post for it to be interpreted de dicto. That is: if A buys apples for H because that's what it thinks H wants, but H really wants oranges instead, it would be "trying to do what H wants" in the de dicto sense but not the de re sense. So it would fail the definition presented here but succeed at Paul's intended definition.
Operationalizing the de dicto interpretation of Paul's definition seems a lot harder. It likely requires the AI to understand all of these dynamics, including concept translation and correspondence and how to do them properly, in order to aim itself at satisfying the definition presented here. That does actually seem necessary for succeeding at alignment, though.
- This definition is not evaluable for in-universe beings (like us or even the AIs themselves) because it depends on a universal concept. This seems to throw a monkey wrench into things – if we can't ever truly evaluate alignment, how can we hope to succeed at it?
But humans routinely achieve things that cannot be evaluated in advance, like building bridges meant to last for 50 years. It's impossible to check that property in advance, and yet many such bridges still stand. This is done through use of mental models and simulations, where the relevant universal concept (is it standing in 50 years?) is much easier to evaluate. Then, if the model was accurate enough, things work.
Such an approach is also necessary for working with alignment: don't try evaluate it directly on real systems, because it can't be done in the way that matters. Instead, evaluate it in mental models and toy worlds and hope they're accurate enough for the alignment to come true in reality. How this works in the context of the ELK thought experiment will be explored in the next section.
Applying the Definition to ELK
Since humans can't perceive ground truth in the real world, in order to evaluate alignment it's necessary to work in thought experiments and simulations where ground truth is available. Then, hopefully the generalization to the real world goes according to plan.
For an example of one such thought experiment, consider Paul et. al.'s framing of the Eliciting Latent Knowledge problem (ELK). It addresses some aspects of the definition of alignment presented here.
In ELK, an AI agent must be trained to guard a diamond in a vault. However, only leaky training signals are available, like evaluations by in-universe humans and spoofable sensors. In order to do this, the plan is to elicit the AI's internal representation (its personal concept) of whether the diamond remains in the vault, which is plausibly more accurate than any means of knowing that the humans can come up with.
Here's a translation of the ELK problem into the language of this post:
Given a human's personal concept PH that identifies diamonds, and a universal concept U that is a faithful translation of it (ground truth), locate some concept PA in an AI's personal ontology such that PA corresponds as accurately as possible with U. However, U may not be used in this process except to evaluate the result.
The setting is chosen so that the correct choice of U is clear: whether the diamond remains in the vault or not. Remaining ambiguities (What if the diamond was replaced atom-by-atom?) are out of scope for the thought experiment, and not considered.
Crucially, this choice of setting removes both of the impediments to evaluating alignment:
- Unspecified U (the pointers problem) is dealt with by restricting the focus of the problem such that U is obvious: it's whether the diamond remains in the vault or not.
- Unevaluable U is handled by the fact that ELK is a thought experiment, not reality, so human researchers can choose scenarios where they know the true value of U. That is, researchers can start their theorizing by saying "suppose the diamond was taken, and such and such things happened..." In this scenario, the true value of U is known because it chosen.
Since these conditions are met, human researchers can evaluate the above definition of alignment in the context of ELK, and this makes it a useful tool.
Notably, the ELK problem does not include any mention of finding a robust correspondence, only an accurate one. That is, ELK does not concern itself much with the optimization process that will be found. The default approach of simply using the AI's personal concept as an input to a reward function may just cause gradient descent to break the correspondence, and this is one of the main issues with an ELK-based alignment plan.
But although the ELK thought experiment does not address all of the points laid out in the above definition of alignment, it bears large structural similarities, namely the relationships – of faithful translation and correspondence – between personal and universal concepts.
Other models of alignment follow similar structure, such as the one presented in Weak to Strong Generalization from OpenAI's former superalignment team. I claim that models of the problem that do not share this structure will necessarily fail to capture meaningful aspects of alignment.
Conclusion
That's all for the post. I hope that it has accomplished three things:
1) Presented a coherent model for ontology, and disentangled personal ontology from universal ontology. It's a simple distinction, but when it's not crisply understood it can lead to a lot of confusion.
2) Painted a descriptive picture of the dynamics of correspondence, both about their necessity and the inherent challenges in keeping them strong.
3) Presented a definition for alignment that's crisper and more gears-like than "doesn't kill us all." It leaves many questions unanswered, but it at least highlights the core necessary relationships of faithful translation and robust correspondence. When these relationships are understood, it's easier to reason about the core difficulties of alignment.
One implication that falls out of this formalization is that alignment only ever holds within a specific domain. For alignment to carry into new domains (like the ones AI will bring us to,) personal concepts must be continuously refined so that they remain in robust correspondence with their original universal concept (or something close enough). How this process might happen is a major question-mark of alignment, and is a potential research direction for further work.
Until then, thanks for reading. We're all in this together.
P.S.: It feels like there's a core mystery here that I haven't fully touched. It has something to do with thought experiments about alignment, and how universal concepts get represented within them. (As personal concepts? floating concepts?) How will AIs navigate reasoning about the universal concepts they are trying to align themselves with? Is there some important insight here? I don't know how to articulate it.
P.P.S: I'm in the process of figuring out if alignment research is a fit for me, and this post was pushed out as part of an application to the MATS program. If you're familiar with the research scene and have a moment to spare for feedback or advice (either in comments or DMs), It'd be greatly appreciated.
- ^
Output values are unconstrained, but in practice will usually be true/false or a real number describing how strongly the concept applies.
- ^
The labels used in most training runs are not really ground truth, because they were created by human labelers with flawed perception of the situation. Universal concepts are instead the idealized form of ground truth.
- ^
What exactly constitutes an agent’s perception is a bit fuzzy, but this ambiguity doesn't bite much. One might assume PA is a full markov blanket that causally separates A's internal computation from the rest of the universe. Then there is the question of where the boundary lies, which can have multiple valid choices. Each choice might shed somewhat different light on the dynamics at play, but again, this indeterminacy is not too big of an issue.
- ^
It's assumed here for simplicity that concepts evaluate to either true or false, rather than a real number like neurons do; one would need to proceed in a more complex way if concepts are allowed to have arbitrary return value.
- ^
It is assumed here that the optimization process has no side effects and only increases the likelihood of the personal concept and nothing else; hence, the rest of the blue circle remains unchanged.
- ^
For example, consider a hair-dye brand running a promotional event. They host a concert that gives free entry to people with dyed hair. They've also recently opened a few new shops in the city. There's a correspondence between whether a person has dyed hair and whether they're a customer of the brand. Before the promotion, the correspondence is inaccurate, because the new stores haven't been open long. But by applying optimization to nudge people to dye their hair, some new people may go to the new stores and become customers. In doing so, the overlap between "people with dyed hair" and "customers" increases, and thus so does the accuracy of the correspondence. (So long as people are likely enough to buy their dye at the new stores vs. competitors'.)
- ^
This is a different usage of PA and U than above, where they described the grounding of a personal and universal ontology instead of a specific concept.
4 comments
Comments sorted by top scores.
comment by Charlie Steiner · 2024-10-10T10:01:00.062Z · LW(p) · GW(p)
Positing a universal ontology doesn't seem to do much for us, since we can't access it. Somehow us humans still think we can judge things as true (or on a more meta level, we think we can judge that some processes are better at finding truth than others), despite being cut off from the universal ontology.
This seems hopeful. Rather than, as you say, trying to generalize straight from 'thought experiments where ground truth is available' to the full difficulties of the real world, we should try to understand intermediate steps where neither the human nor the AI know any ground truth for sure, but humans still can make judgments about what processes are good.
Replies from: eternal/ephemera↑ comment by eternal/ephemera · 2024-10-11T21:25:52.566Z · LW(p) · GW(p)
Hey, thanks for the comment. Part of what I like about this framework is that it provides an account for how we do that process of “somehow judging things as true”. Namely, that we develop personal concepts that correspond with universal concepts via the various forces that change our minds over time.
We can’t access universal ontology ourselves, but reasoning about it allows us to state things precisely - it provides a theoretical standard for whether a process aimed at determining truth succeeds or not.
Do you have an example for domains where ground truth is unavailable, but humans can still make judgements about what processes are good to use? I’d claim that most such cases involve a thought experiment, i.e. a model about how the world works that implies a certain truth-finding method will be successful.
Replies from: Charlie Steiner↑ comment by Charlie Steiner · 2024-10-11T22:55:39.382Z · LW(p) · GW(p)
Do you have an example for domains where ground truth is unavailable, but humans can still make judgements about what processes are good to use?
Two very different ones are ethics and predicting the future.
Have you ever heard of a competition called the Ethics Bowl? They're a good source of questions with no truth values you could record in a dataset. E.g. "How should we adjudicate the competing needs of the various scientific communities in the case of the Roman lead?" Competing teams have to answer these questions and motivate their answers, but it's not like there's one right answer the judges are looking for and getting closer to that answer means a higher score.
Predicting the future seems like you can just train it based on past events (which have an accessible ground truth), but what if I want to predict the future of human society 10,000 years from now? Here there is indeed more of "a model about the world that implies a certain truth-finding method will be successful," which we humans will use to judge an AI trying to predict the far future - there's some comparison being made, but we're not comparing the future-predicting AI's process to the universal ontology because we can't access the universal ontology.
Replies from: eternal/ephemera↑ comment by eternal/ephemera · 2024-10-12T18:04:29.924Z · LW(p) · GW(p)
It’s not about comparing a process to universal ontology, it’s about comparing it to one’s internal model of the universal ontology, which we then hope is good enough. In the ethics dataset, that could look like reductio ad absurdum on certain model processes, e.g.: “You have a lot of fancy reasoning here for why you should kill an unspecified man on the street, but it must be wrong because it reaches the wrong conclusion.”
(Ethics is a bit of a weird example because the choices aren’t based around trying to infer missing information, as is paradigmatic of the personal/universal tension, but the dynamic is similar.)
Predicting the future 10,000 years hence has much less potential for this sort of reductio, of course. So I see your point. It seems like in such cases, humans can only provide feedback via comparison to our own learned forecasting strategies. But even this bears similar structure.
We can view the real environment that we learned our forecasting strategies from as the “toy model” that we are hoping will generalize well enough to the 10,000 year prediction problem. Then, the judgement we provide on the AI’s processes is the stand-in for actually running those processes in the toy model. Instead of seeing how well the AI’s methods do by simulating them in the toy model, we compare its methods to our own methods, which evolved due to success in the model.
Seeing things like this allows us to identify two distinct points of failure in the humans-judging-processes setup:
-
The forecasting environment humans learned in may not bear enough similarity to the 10,000 year forecasting problem.
-
Human judgement is just a lossy signal for actual performance on that environment they learned in; AI methods that would perform well in the human’s environment may still get rated poorly by humans, and vice versa.
So it seems to me that the general model of the post can understand these cases decently well, but the concepts are definitely a bit slippery and this is the area that I feel most uncertain about here.