Book Review: Reinforcement Learning by Sutton and Barto
post by billmei · 2020-10-20T19:40:52.736Z · LW · GW · 3 commentsContents
What is reinforcement learning How reinforcement learning works Mistakes drive learning Dopamine and Happiness Simulated Experience Simulated Rewards Importance Sampling Conclusion Bibliography None 3 comments
Note: I originally submitted this for the Slate Star Codex (RIP) book review contest, but given the current drama it probably won't happen for a while (if at all), so I decided to share this review with the LW community in the meantime.
Cross-posted on my blog: https://billmei.net/blog/reinforcement-learning
Reinforcement Learning profoundly changed my understanding of the science of happiness, biological evolution, human intelligence, and also gave me unique tactics for rapid skill acquisition in my personal life.
You may not be expecting these conclusions, as on the surface this is a technical textbook for those wishing to learn about reinforcement learning (RL), the subfield of machine learning algorithms powering recent high-profile successes of AIs trouncing human champions like AlphaGo in Go and Watson in Jeopardy.
However, I wrote this review in layman’s terms, and it contains no math, to help disseminate these ideas to people who would be intimidated by the math and unlikely to read it otherwise, as I highlight only the most important (and underrated!) topics from this book that you won’t find elsewhere. If you instead want a comprehensive math-included summary of the book, you can read my detailed notes on each chapter.
What is reinforcement learning
Reinforcement learning is a study of what are the best actions (policy) to take in a given environment (states) to achieve the maximum long-term reward.
I’ve found RL to be the most elegant, first-principles formalization of what it means to “win”. It’s an algorithm that explicitly gives you the optimal actions to take to achieve the goal you define, with zero outside knowledge other than the input environment. Unlike other machine learning algorithms, RL does not require you to specify subgoals (capture the most chess pieces), only the ultimate goal (win at chess).
The Slate Star Codex and LessWrong communities started using Bayes’ theorem [LW · GW] as the principal guide towards finding the truth. Bayes’ theorem is the first-principles formalism of how to evaluate evidence and update your beliefs so that your beliefs will match reality as closely as possible. But ultimately “Rationality is winning” [LW · GW]; the purpose of “Rationality” is not just to have a good epistemology, but to successfully achieve goals in the real world.
Just as Bayes’ theorem is the mathematical foundation for finding the truth, reinforcement learning is the computational foundation for winning.
How reinforcement learning works
To oversimplify, let’s focus on temporal-difference (TD) learning. TD learning uses a value function that estimates how good it is to take a certain action, or how good it is to be in a state: a certain configuration of the environment. For example, in chess it’s generally better (but not always) to have more pieces than your opponent. It’s also generally better (but not always) to take actions that capture pieces than to take actions that result in your pieces being captured.
If the value function predicts that a state is better than it actually is, causing a move that results in losing the game, then we perform one iteration of a TD update which revises the value function downwards on this particular state (and other similar states). Vice-versa if it undervalued a state that later resulted in a win. We call this misestimation a TD error.
The RL agent will then mostly try to play only the actions that lead to board states with the highest estimated value, although it will sometimes play suboptimal actions to avoid getting stuck in local optima using a strategy that I will describe later.
Over many games and many iterations, the value function’s estimate asymptotically converges to the true value of the state (played by some hypothetically perfect player). Then, assuming these estimates are correct, the RL agent can win by simply playing actions that lead to the highest value states. Even if the estimated value does not perfectly match the true value, in most practical cases the estimates become good enough that the agent can still play with superhuman skill.
Mistakes drive learning
What’s interesting about the TD algorithm is that it learns only from its mistakes. If the value function estimates that I will win a game, and then I go on to actually win, then I get a positive reward but the TD error is 0, hence no TD update is performed, and no learning occurs. Therefore, an RL agent that learns quickly won’t always just choose actions that lead to the highest state values, but instead identify states that haven’t been played frequently and try to play in such a way to get to those states to learn about them. While this may cause the agent’s winrate to decrease in the short term, it’s a good way to improve out of local optima as focusing only on a small number of states leaves the agent ignorant about the universe of what’s possible.
This echos the research on how you can acquire skills using “deliberate practice”. The popular “10,000” hours rule oversimplifies the idea of “just practice a lot and you will be good”, as the research of deliberate practice shows that if you’re just doing mindless repetitions of an activity (or worse, winning a lot or having fun at it!), you aren’t actually learning, as it requires struggling through mistakes and constantly challenging yourself at a level just beyond your reach that results in actual learning.
While you may already be familiar with the research on deliberate practice, RL provides a mathematical justification for this concept which further solidified it for me.
Dopamine and Happiness
Dopamine is a neurochemical people commonly associate with pleasure. But dopamine does not actually function this way in biological organisms; instead, it is an error signal. While it may seem like dopamine is analogous to the reward in an RL algorithm, it is not the reward. Instead, dopamine is the TD error.
Echoing Pavlov’s dogs, the book describes a study where researchers (Schultz, Apicella, and Ljungberg, 1993) trained monkeys to associate a light turning on with a reward of a drop of apple juice. They hooked up brain scanners to the monkeys to monitor their dopamine receptor activity. Here’s how those neurons behaved:
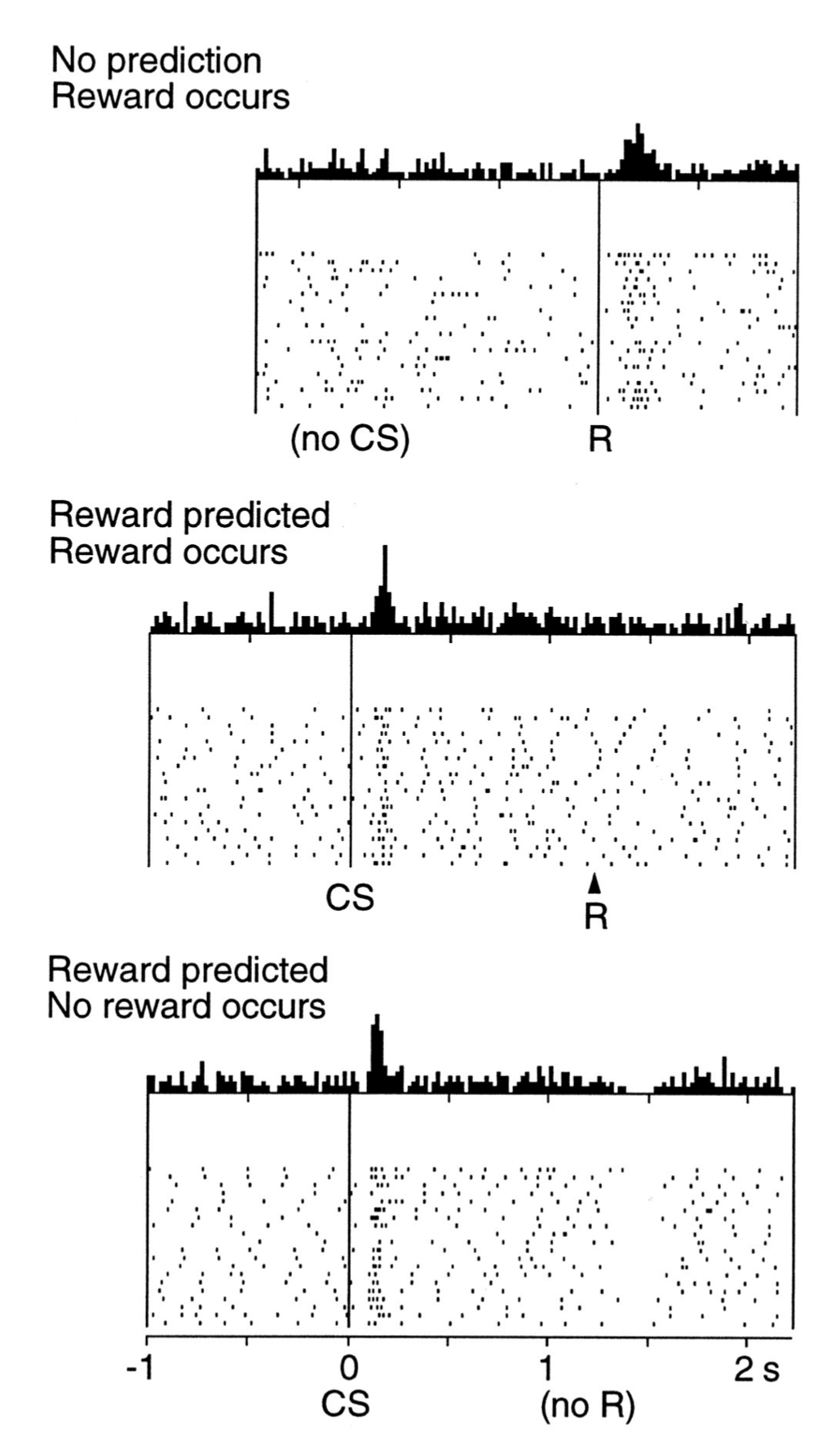
CS: Light turning on
R: Drop of apple juice dispensed
From the diagram, the monkeys get a dopamine spike when the apple juice is surprisingly dispensed without any forewarning from the light. If the light turns on, the monkeys get a dopamine spike right away in anticipation of the upcoming reward, but then no dopamine is produced once the apple juice is actually dispensed. In a third experiment, the light turned on which produced a dopamine spike as expected, but then later no juice was dispensed, which caused the monkey’s dopamine levels to drop below baseline as their expectations were disappointed.
From this it’s clear that dopamine’s purpose is an error signal, not a reward signal. We don’t get any dopamine when our rewards are exactly the same as our expectations, only when the rewards exceed expectations. Conversely, dopamine levels drop when our expectations are high and the rewards are disappointing. Likewise, once an RL agent receives a reward its TD error is positive when the value function undervalued its actions, and negative when it overvalued its actions.
It’s a trope that “happiness equals reality minus expectations”, and while dopamine is not the only neurochemical that contributes to happiness, the implication of this study is the more skilled you get at accurately predicting reality, the less pleasure (and less disappointment) you get from your efforts. Perfect prediction is perfect equanimity.
Another implication is in the psychology of addiction. This phenomenon underlies the behaviour of “chasing the high”; every time you receive a reward, your expectations revise upwards to match reality, so next time the reward needs to be greater to generate the same dopamine response, as receiving the same reward causes no “TD error”.
These conclusions may be unsurprising to you if you are a psychiatrist, but what I found extraordinary is the research and science around dopamine was discovered many years after when the TD algorithm was developed. The RL algorithm designers were totally ignorant about this property of dopamine, yet independently came up with an algorithm for shaping the behaviour of computer agents that looks remarkably similar to how we incentivize behaviour in animals.
Is there a shared computational universe that drives the behaviour of both biological beings and computer algorithms? It certainly looks convincing.
Simulated Experience
In chess you have full knowledge of the environment, but what about tasks where you don’t? Imagine a robot trying to navigate a maze. If this were an animal study we may reward its success with food, but AIs are satisfied to receive rewards as floating point numbers, with greater rewards for faster navigation. At every intersection, the RL agent must decide which corridor to follow to exit the maze.
How can the RL agent know what “state” it’s in when it doesn’t even know what the maze looks like? Any given intersection may look exactly like several others. Worse, what happens if the maze is constantly changing while the agent is in the middle of running it?
In the absence of external sensory information about the real-world maze, the RL algorithm constructs simulated mazes that it runs virtually. Driving a robot through a real maze is slow, but the computer can run thousands of simulated mazes per second.
In the beginning, when the agent knows nothing about the real maze, its simulated mazes will be poor imitations of the real thing, as it lacks data on what mazes are supposed to look like. So the experience it gains from these simulated mazes is worthless.
But slowly, as the robot drives through the real maze and collects increasing ground-truth data about the maze, it can improve its simulated mazes until they become reasonably accurate approximations of the real thing. Now when the algorithm solves a thousand simulated mazes, it gains the experience of having solved a thousand physical mazes, even though in reality it may have only solved a handful.
This is how Monte Carlo Tree Search works (although I oversimplified here for brevity), and it was the key to AlphaGo’s victory over the top human Go players.
In the book Sapiens, Yuval Noah Harari argues that what separates humans from other primates is our ability to imagine events that don’t exist. Our ability to learn from these fictional events is what endows us with intelligence.
If you can daydream about a non-existent lion, then you don’t have to wait to actually encounter a lion to figure out what to do, when it may be too late.
At the risk of inappropriately anthropomorphizing our RL agent, this convinced me that the ability to simulate experience is one of the key building blocks of intelligence, here applied to machines instead of humans.
Simulated Rewards
The ability to simulate experience necessarily also means being able to imagine rewards (or punishments) at the end of those simulated experiences.
Any basic optimization algorithm suffers from the problem of being stuck in local optima. Humans can think globally and creatively because we can delay gratification; we generally don’t always take the greedy step towards rewards, as anyone who does so is seen as more simple-minded or lacking willpower. Conversely, we respect people who have superior self-control, as working towards long-term goals generally leads to more success, health, popularity, etc., thus we perceive these people to be more intelligent.
I want to argue here that our ability to delay gratification is not the result of willpower, but actually a hack. We don’t really delay gratification, instead we substitute a real reward for an imagined one.
In the famous Stanford marshmallow experiment, children who were able to give up a marshmallow to wait 15 minutes in an empty room received 2 marshmallows afterwards. Compared to the kids who didn’t wait, the kids who waited later had improved SAT scores, educational attainment, and other measures of life outcome.
If you watch some videos of this experiment, what’s remarkable is you will notice the most successful kids aren’t the ones who have iron willpower, but instead those who were able to distract themselves by singing songs, playing with their hands, etc.
Thus, the key to long-term planning is not the ability to push back a reward, but instead the ability to be satisfied with an imagined fiction tell yourself of an even greater reward you can receive if you wait.
While I use the terms “fiction”, “simulated”, and “imagined”, it’s important to note that this “synthetic happiness” is not fake. Biologically, psychologically, and computationally, it is in every way as real as “real” happiness. Dan Gilbert, the happiness researcher, presents the data behind this in a TED talk:
We smirk, because we believe that synthetic happiness is not of the same quality as what we might call “natural happiness”.
[…]
I want to suggest to you that synthetic happiness is every bit as real and enduring as the kind of happiness you stumble upon when you get exactly what you were aiming for.
From our RL algorithm’s perspective, its simulated rewards are as real to its value function as the real rewards. The only difference is the real rewards have the ability to change the way the simulation itself is constructed, whenever expectations are violated. The way the math works, the agent’s ability to long-term plan results not from its delaying immediate rewards, but substituting real short-term rewards for simulated long-term rewards that have a larger floating point value.
Simpler animals require Pavlovian training and direct rewards/punishments to influence their behaviour, but you can get a human being to toil away in the fields with only a story about an imagined afterlife.
Importance Sampling
After three moves in chess, there are 100+ million possible board positions and 10120 possible continuations (more than the number of atoms in the universe), only a tiny sliver of which result in a win. To have any hope of getting a good value function with limited computing power, your algorithm must focus on analyzing the most promising (or most common) moves and avoid spending clock cycles on positions that are clearly bad and will never occur in a real game.
But your opinion on what is “good” may differ from someone else’s opinion. An RL agent’s experience in a game is highly path-dependent; if it happens to get lucky with a certain sequence of actions it may overvalue these actions and hence choose them more often than a counterfactual average agent. Thus, how much credit should you give to your own experience vs. others’ experiences? Morgan Housel says “Your personal experiences make up maybe 0.00000001% of what’s happened in the world but maybe 80% of how you think the world works.”
The importance sampling ratio is a modifier used by the RL agent to upregulate or downregulate its value function to reduce the variance from luck, without changing the expected value. It’s calculated using a set of weight parameters that is adjusted based on a behaviour policy, which you can think of as the RL agent’s simulation of what an average agent would do in its stead.
Just as Bayes’ theorem gives you the math for exactly how much you should increase or decrease your confidence in a belief in response to new evidence, importance sampling gives you the math for exactly how much credit you should give to your own experiences versus others’ experiences so you can correct for your narrow slice of reality without throwing up your hands and always deferring to others.
I believe importance sampling is the appropriate response to avoid overcorrecting and, as described in Inadequate Equilibria, to avoid becoming “too modest” to the point where you stop trusting your own intuitions even when they are right.
Conclusion
It may be offbeat to do a book review of a dense, 500-page math textbook, but I found the ideas presented in Reinforcement Learning revolutionary to clarifying my understanding of how intelligence works, in humans or otherwise.
In this review I’ve omitted the math formulas because they are quite involved and any variables I use would be meaningless without a lengthy introduction to them. You don’t need a deep math background to read this book though, it’s written in an approachable style that requires only 1st-year university math and some basic machine learning knowledge to understand, and I believe that is why this is the most popular textbook for beginners to RL.
I highly recommend this book if you are interested in what modern machine learning algorithms are capable of beyond just variations on linear regression and gradient descent. If you have the inclination, I also recommend completing the coding exercises in each chapter—coding up the algorithms helped me feel what was going on as if I were an RL agent myself, and this was the key that allowed me to draw the parallels between human and machine intelligence that I described in this review.
It took me four months to read this book and do the exercises, and I also did it as part of a class I am taking for my Master’s Degree, but it was well worth the investment. This book took me from barely any idea about reinforcement learning to being able to comfortably read the latest RL research papers published on arXiv. Perhaps you’ll also discover something new about AI that you didn’t realize you were missing before.
Bibliography
Schultz, W., Apicella, P., and Ljungberg, T. (1993). Responses of monkey dopamine neurons to reward and conditioned stimuli during successive steps of learning a delayed response task. The Journal of Neuroscience, 13(3), 900–913. doi.org/10.1523/JNEUROSCI.13-03-00900.1993
3 comments
Comments sorted by top scores.
comment by Alexei · 2020-10-21T19:28:24.213Z · LW(p) · GW(p)
Really appreciate the no math summary!
Can you expand more on this or recommend some reading:
“In the beginning, when the agent knows nothing about the real maze, its simulated mazes will be poor imitations of the real thing, as it lacks data on what mazes are supposed to look like. So the experience it gains from these simulated mazes is worthless.
But slowly, as the robot drives through the real maze and collects increasing ground-truth data about the maze, it can improve its simulated mazes until they become reasonably accurate approximations of the real thing. Now when the algorithm solves a thousand simulated mazes, it gains the experience of having solved a thousand physical mazes, even though in reality it may have only solved a handful.”
Replies from: Oscilllator↑ comment by Oscilllator · 2020-10-21T21:20:27.397Z · LW(p) · GW(p)
I think there are two things being talked about here, the ability to solve mazes and knowledge of what a maze looks like.
If the internal representation of the maze is a generic one like a Graph/Tree/whatever then you can generate a whole bunch of fake mazes easily since here a random maze == a random tree, and a random tree is easy to make. The observations that the robot makes about mazes that it does encounter can then be used to inform what type of tree to generate.
For example you would not be likely to observe a 2D maze with four left turns in a row, and so when you are generating your random tree you wouldn't for example generate a tree with four left branches in a row or whatever.
The generation of correct-looking mazes is the "have I got a good understanding of the problem" part of the problem, and the simulation of lots of maze solving events is the "given this understanding, how well can I solve this problem" part of the problem.
Replies from: billmei↑ comment by billmei · 2020-10-22T19:16:43.422Z · LW(p) · GW(p)
Yes, this is the idea! My example here is a highly oversimplified description of Rollout Algorithms, a property of Monte Carlo Tree Search, which you can read more about in Chapter 8.10 in the book.