Direct Preference Optimization in One Minute
post by lukemarks (marc/er) · 2023-06-26T11:52:16.994Z · LW · GW · 3 commentsContents
3 comments
The Direct Preference Optimization (DPO) paper promises a more simple and efficient alternative to proximal policy optimization that is able to void the reward modeling phase, and thus optimize directly for the preferences expressed in preference data. This is achieved through the loss function:
Where:
- is some prompt
- and are the probabilities of the preferred and dispreferred completions under the current model.
- is controls the deviation from the reference policy .
In essence, DPO computes the log probabilities of preferred and dispreferred completions under the current model and optimizes parameters to increase the likelihood of the preferred completions and decrease the likelihood of the dispreferred completions.
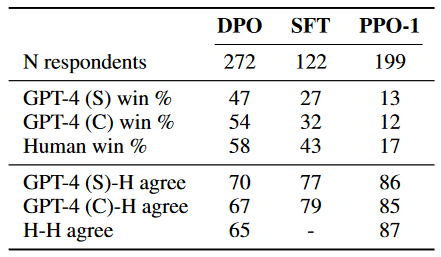
The authors share the following results:
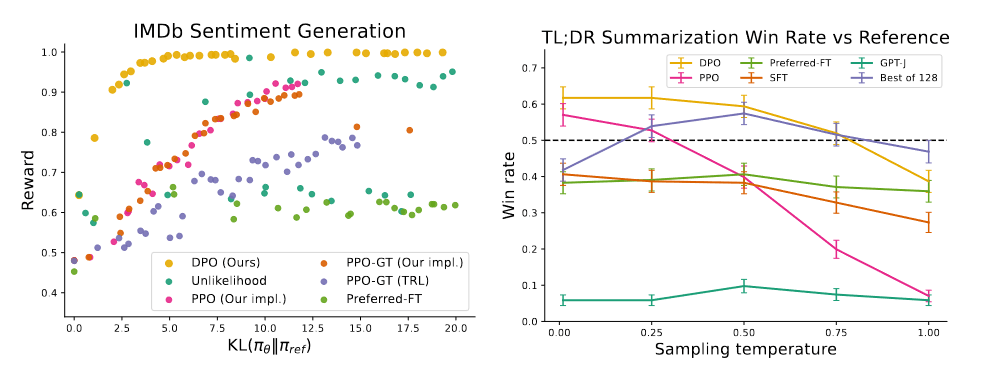
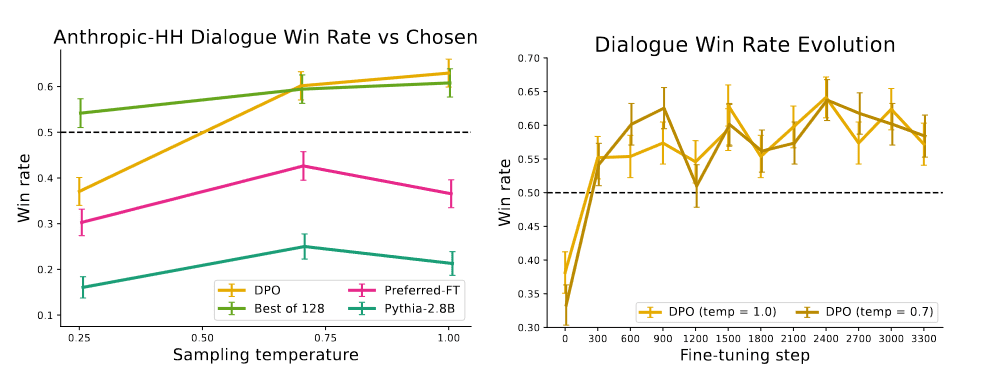
We evaluate different methods by sampling completions on the test split of TL;DR summarization dataset, and computing the average win rate against reference completions in the test set. The completions for all methods are sampled at temperatures varying from 0.0 to 1.0, and the win rates are shown in Figure 2 (right). DPO, PPO and Preferred-FT all fine-tune the same GPT-J SFT model. We find that DPO has a win rate of approximately 61% at a temperature of 0.0, exceeding the performance of PPO at 57% at its optimal sampling temperature of 0.0. DPO also achieves a higher maximum win rate compared to the best of N baseline. We note that we did not meaningfully tune DPO’s β hyperparameter, so these results may underestimate DPO’s potential. Moreover, we find DPO to be much more robust to the sampling temperature than PPO, the performance of which can degrade to that of the base GPT-J model at high temperatures.
I have created a prediction market targeted at forecasting the likelihood that DPO is adopted by a Frontier Lab before Jan 1 2025.
3 comments
Comments sorted by top scores.
comment by Thomas Kwa (thomas-kwa) · 2023-08-18T00:35:18.956Z · LW(p) · GW(p)
DPO seems like a step towards better and more fine-grained control over models than RLHF, because it removes the possibility that the reward model underfits.
Replies from: LawChan↑ comment by LawrenceC (LawChan) · 2023-08-18T01:17:32.834Z · LW(p) · GW(p)
I suspect the underfitting explanation is probably a lot of what's going on given the small models used by the authors. But in the case of larger, more capable models, why would you expect it to be underfitting instead of generalization (properly fitting)?
Replies from: thomas-kwa↑ comment by Thomas Kwa (thomas-kwa) · 2023-08-18T01:56:53.427Z · LW(p) · GW(p)
Maybe the reward models are expressive enough to capture all patterns in human preferences, but it seems nice to get rid of this assumption if we can. Scaling laws suggest that larger models perform better (in the Gao paper there is a gap between 3B and 6B reward model) so it seems reasonable that even the current largest reward models are not optimal.
I guess it hasn't been tested whether DPO scales better than RLHF. I don't have enough experience with these techniques to have a view on whether it does.