A Numerical Model of View Clusters: Results
post by Shmi (shminux) · 2019-04-14T04:21:00.947Z · LW · GW · 0 commentsThis is a link post for https://quantitativephilosophy.wordpress.com/2019/04/13/separation-and-clustering-of-views-playing-around/
Contents
No comments
As promised in the last post [LW · GW], here are some results of the simulation.
So now that the hard work is done, let’s see what the model gives us. I cheated a bit and adjusted the defaults to show something reasonable. You can see the hand-fudged coefficients in the code, if you feel like.
You can also play with the live model yourself here.
So, let’s have a look:
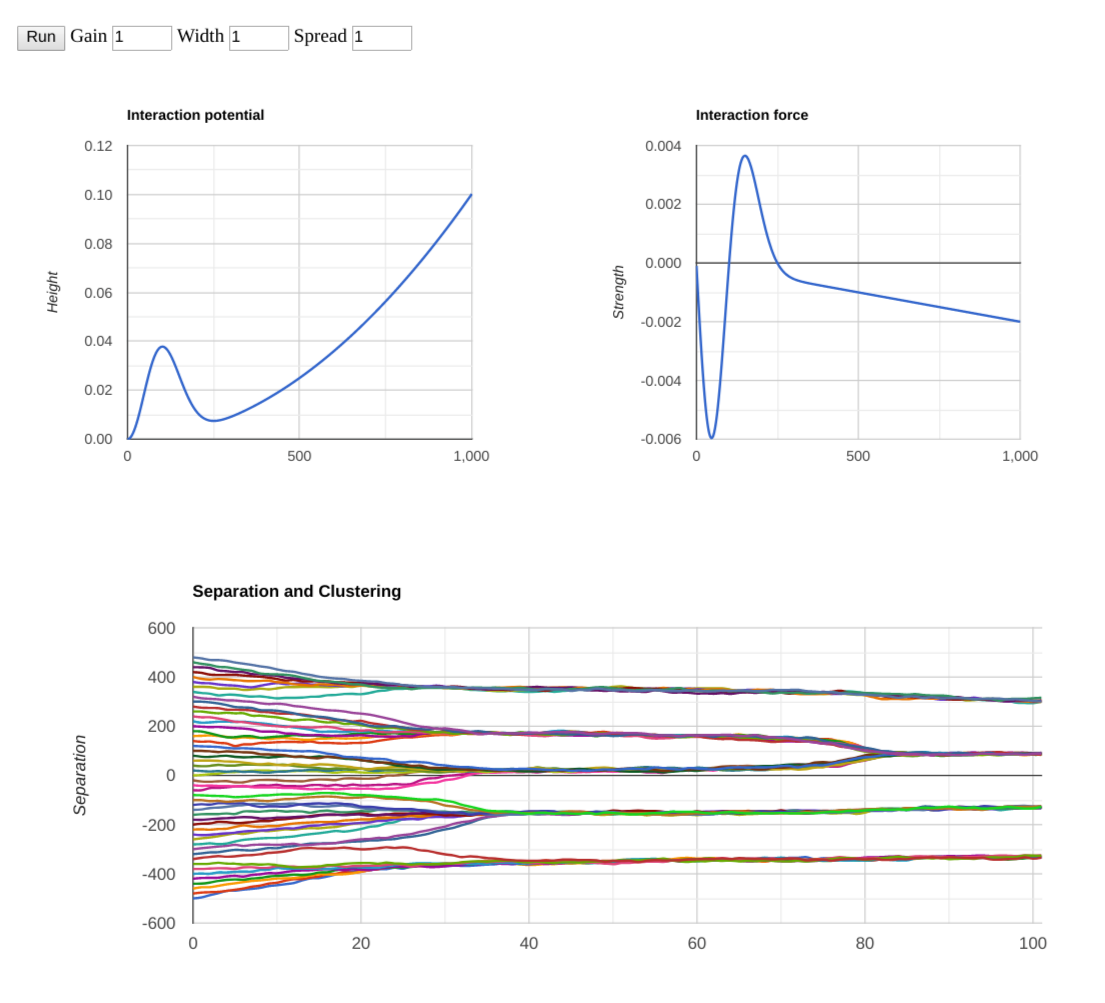
equilibrium separation is about 220 points.
To recap the original setup, we have a single dimension of views, starting with the uniform distribution. This corresponds to the horizontal axis on the top two graphs (“potential” and “force”), and to the vertical axis on the bottom graph (the time evolution of clustering and alienation of views). Note that each time step on the graph corresponds to 1000 steps in the code, i.e. the whole length of the simulation is 100,000 steps.
The basic results are not very surprising:
- People with the views closest to each other converge, with those on the fence taking awhile to pick a side, but eventually being pulled (and pushed) toward one of the view clusters.
- The separation between prevalent views corresponds to the equilibrium between repulsion of an outgroup and attraction of what one may thing as universal values.
- The number of view clusters roughly corresponds to the initial separation spread (1000 in this example) divided by the equilibrium distance.
Here is another couple of run with the same parameters:
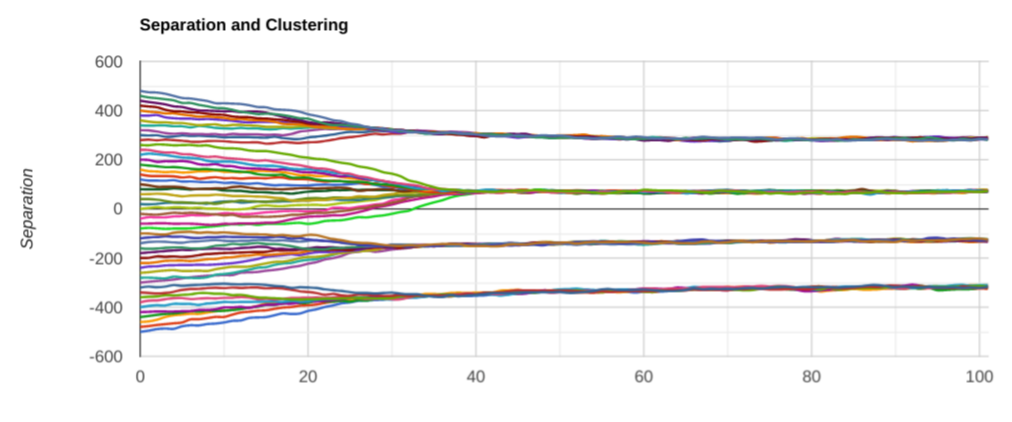
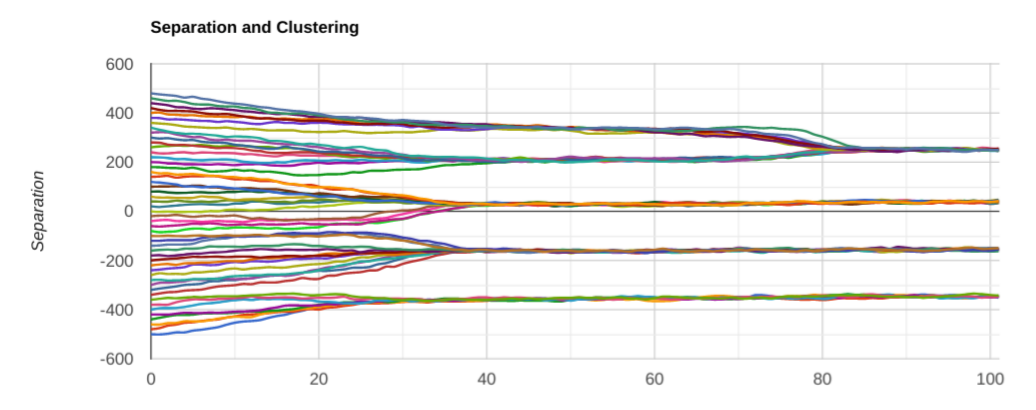
It is interesting to notice that, while we eventually end up with just 4 clusters, sometimes there is an intermediate metastable equilibrium with 5 view clusters, and eventually the closest two merge together.
Let’s play around with the parameters a little more. Upping the gain models how strong the attraction/repulsion feelings are. Here are a couple of runs with the “feelings” being twice as intense:
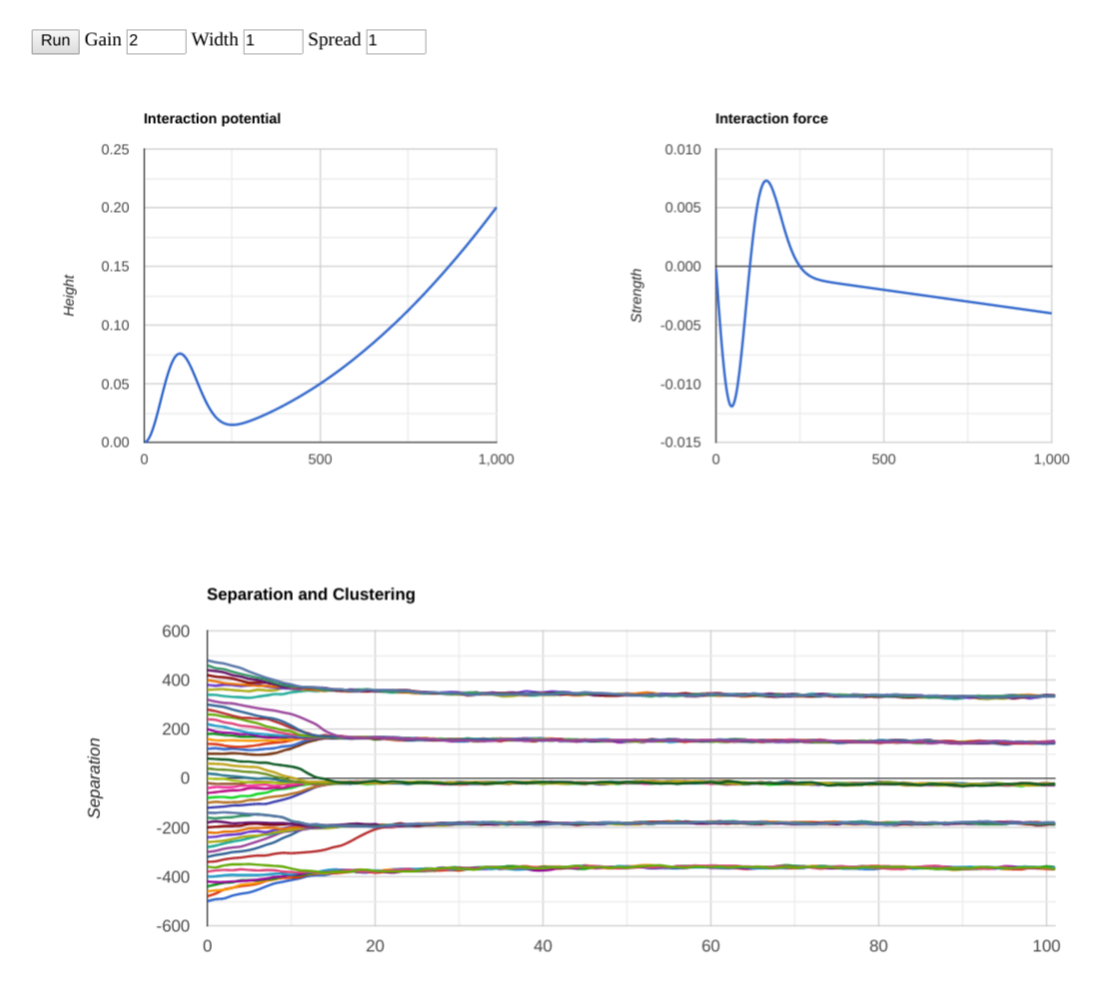
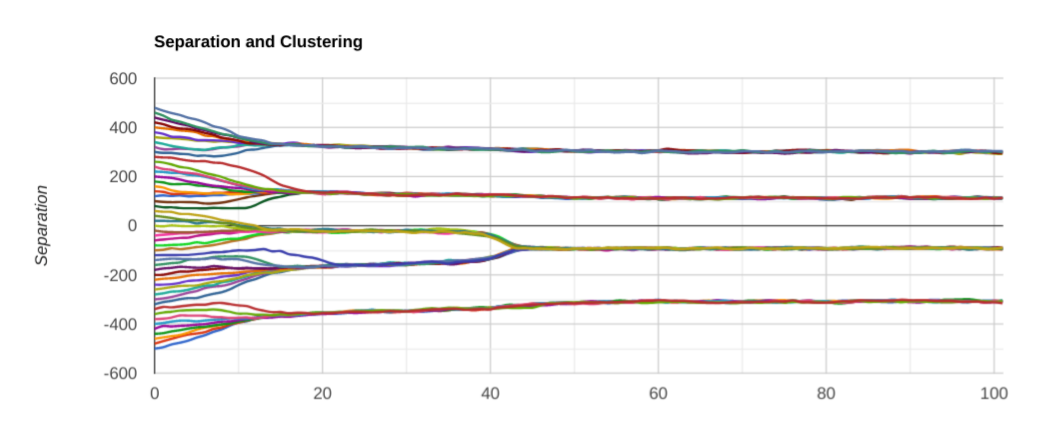
It looks like the clustering happens faster when the feelings are more intense, not very surprising. The number of clusters does not seem to be affected, though. What if instead of changing the intensity, we play with the “width”, meaning how quick the repulsive feelings subside after enough separation. Why should they subside? Scott Alexander discussed it in I Can Tolerate Anything Except The Outgroup:
You wouldn’t celebrate Osama’s death, only Thatcher’s. And you wouldn’t call ISIS savages, only Fox News. Fox is the outgroup, ISIS is just some random people off in a desert. You hate the outgroup, you don’t hate random desert people.
So, let’s see what changes if we play with the width (“distance”) of the attraction/repulsion feelings. Double vs. half:
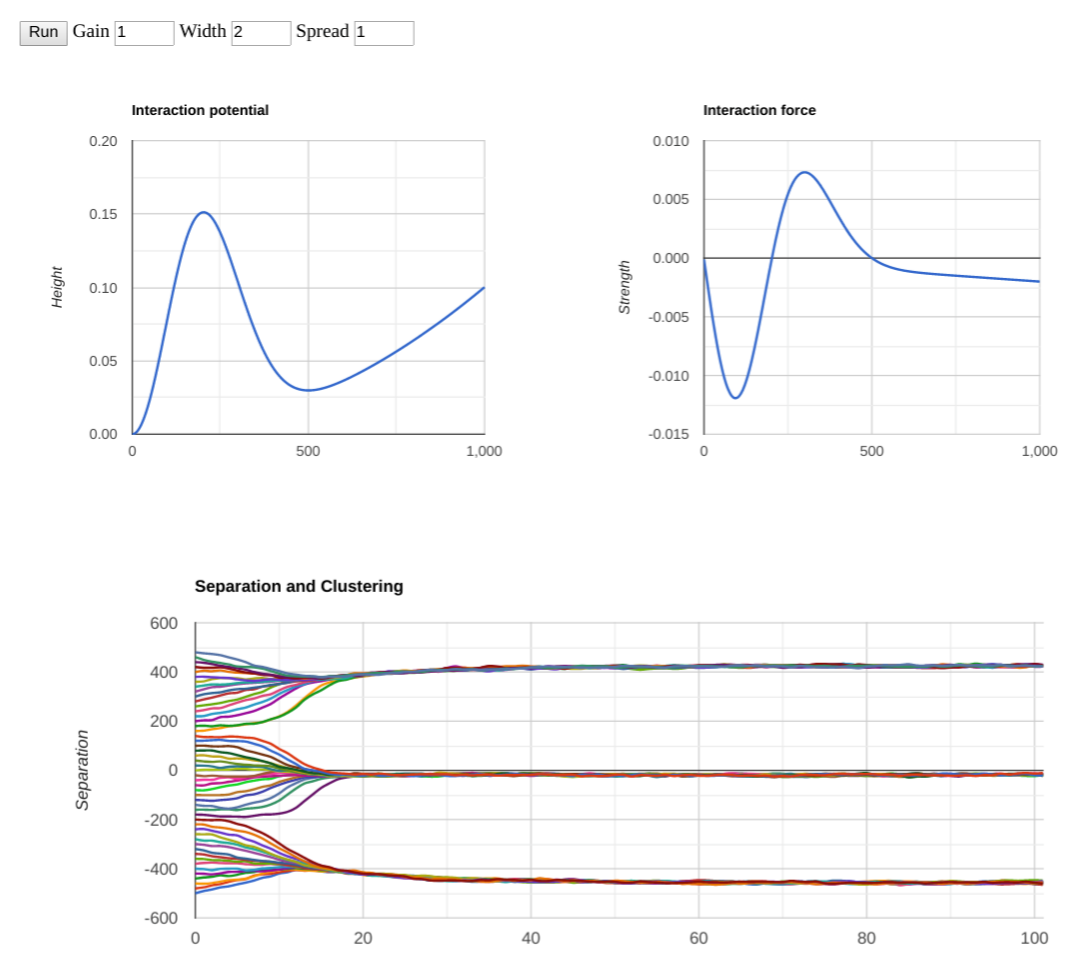
So, unsurprisingly, the separation of the view clusters increases to match the width increase. And, given that we didn’t touch the initial spread, we ended up with 3 clusters instead of 4 or 5. Now to see what happens if we reduce the width. A priori one would expect the final separation to narrow, and the number of view clusters to increase to roughly the ratio of the initial separation to the equilibrium separation. Here is one run:
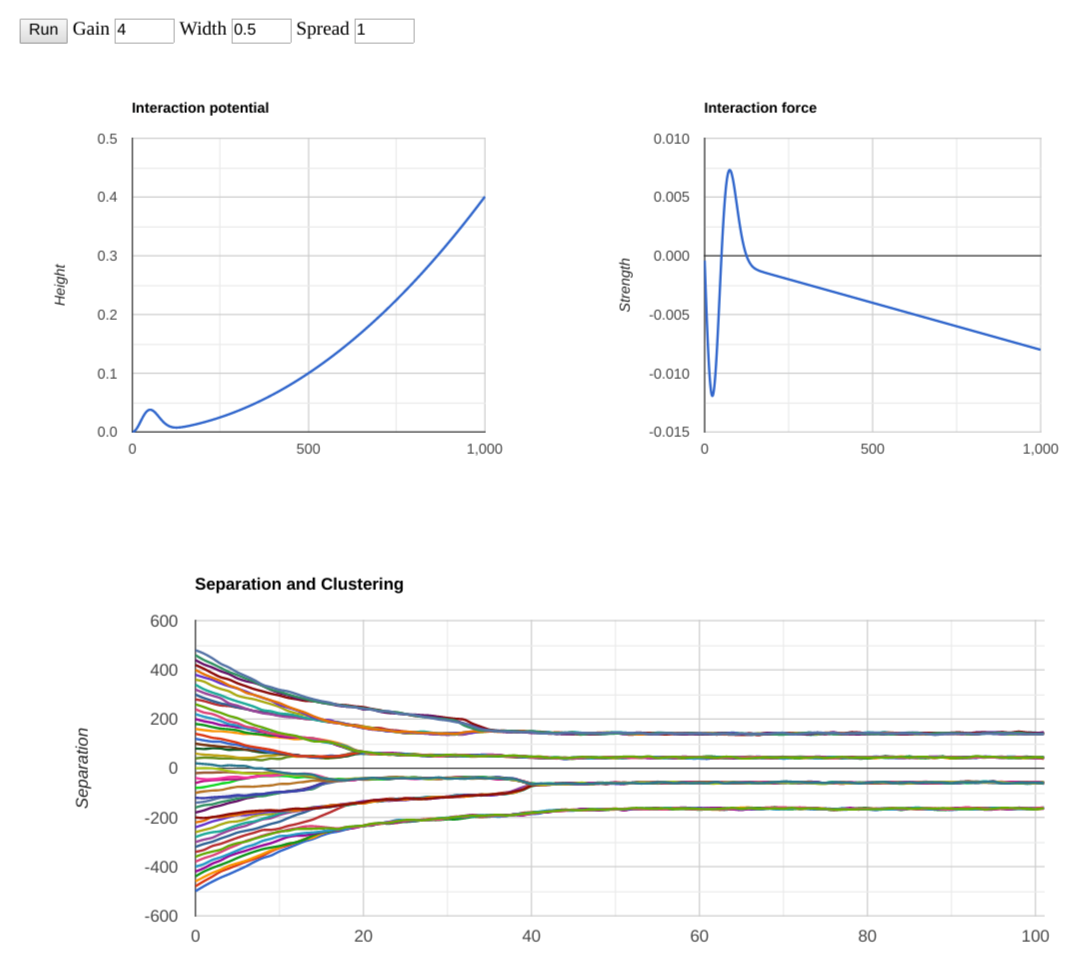
Note that I had to crank up the overall gain to keep the force roughly the same. And the separation between clusters did indeed get smaller, as predicted. But! Something I didn’t expect happened: we only ended up with 4 clusters instead of 8 or so. Let’s try another couple of runs:
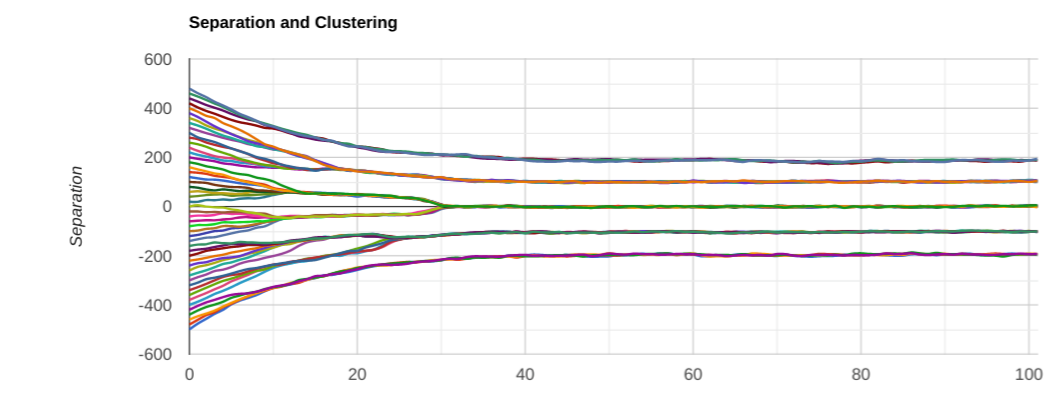
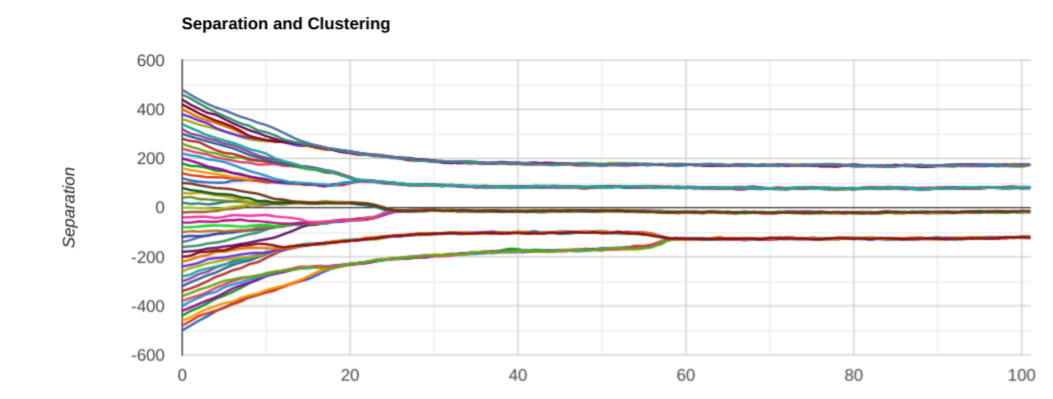
This time we ended up with 5 clusters, then 4 again. A few more runs show that, just like before, we mostly end up with 4 clusters, but sometimes with 5. Why? I have no good explanation of it at this point. It contradicts my initial intuition. Is my intuition wrong? Is there a bug in the model? That’s the beauty of doing numerical simulations: sometimes you see something unexpected, and then have to figure out why. And, unlike in real-life, it is easy to play with the models and parameters, and see what affects what and how, instead of committing a cardinal philosophical sin: using open-loop logic with no feedback.
So, this was an exercise in quantitative philosophy, if you wish. Which, in my opinion, should be an essential complement to the usual qualitative philosophy.
0 comments
Comments sorted by top scores.