Did they or didn't they learn tool use?
post by Daniel Kokotajlo (daniel-kokotajlo) · 2021-07-29T13:26:32.031Z · LW · GW · 6 commentsThis is a question post.
Contents
Answers 14 Vanessa Kosoy None 6 comments
DeepMind claims that their recent agents learned tool use [LW · GW]; in particular, they learned to build ramps to access inaccessible areas even though none of their training environments contained any inaccessible areas!
This is the result that impresses me most. However, I'm uncertain whether it's really true, or just cherry-picked.
Their results showreel depicts multiple instances of the AIs accessing inaccessible areas via ramps and other clever methods. However, in the actual paper page 51, they list all the hand-authored tasks they used to test the agents on, and mention that for some of them the agents did not get >0 reward. One of the tasks that the agents got 0 reward on is:
Tool Use Climb 1: The agent must use the objects to reach a higher floor with the target object.
So... what gives? They have video of the agents using objects to reach a higher floor containing the target object, multiple separate times. But then in the chart it says failed to achieve reward >0.
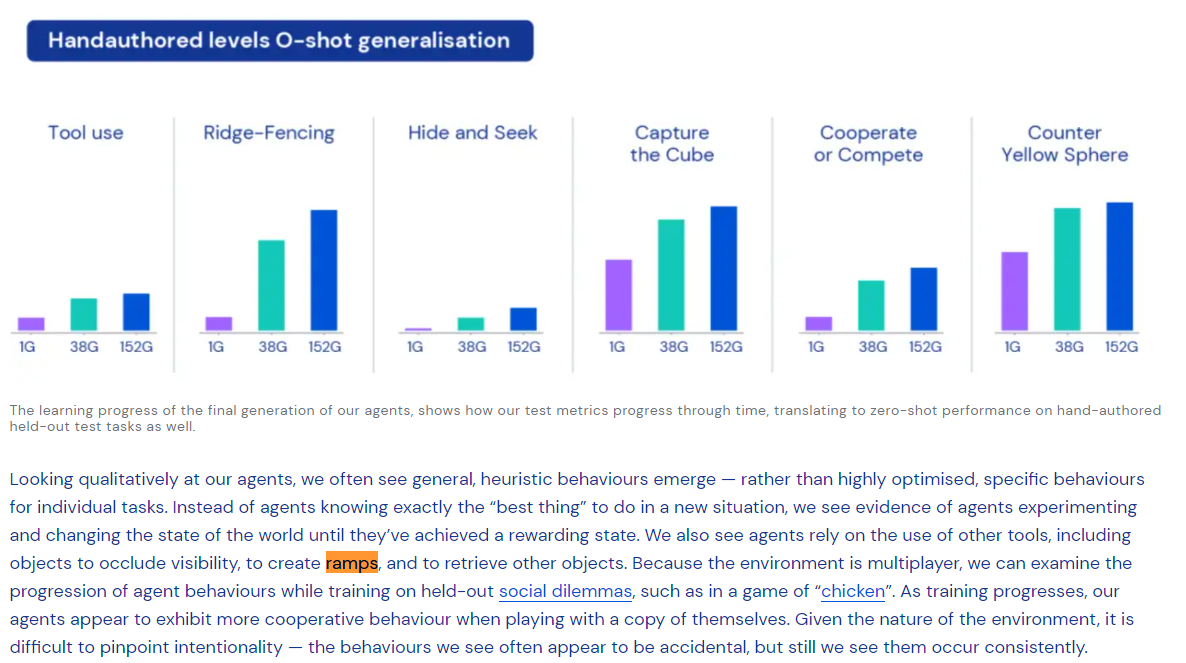
EDIT: Maybe the paper just has a typo? The blog post contains this image, which appears to show non-zero reward for the "tool use" task, zero-shot:
Answers
On page 28 they say:
Whilst some tasks do show successful ramp building (Figure 21), some hand-authored tasks require multiple ramps to be built to navigate up multiple floors which are inaccessible. In these tasks the agent fails.
From this, I'm guessing that it sometimes succeeds to build one ramp, but fails when the task requires building multiple ramps.
↑ comment by Daniel Kokotajlo (daniel-kokotajlo) · 2021-07-29T17:08:37.640Z · LW(p) · GW(p)
Nice, I missed that! Thanks!
6 comments
Comments sorted by top scores.
comment by jbkjr · 2021-07-29T14:23:59.488Z · LW(p) · GW(p)
One idea as to the source of the potential discrepancy... did any of the task prompts for the tasks in which it did figure out how to use tools tell it explicitly to "use the objects to reach a higher floor," or something similar? I'm wondering if the cases where it did use tools are examples where doing so was instrumentally useful to achieving a prompted objective that didn't explicitly require tool use.
Replies from: daniel-kokotajlo↑ comment by Daniel Kokotajlo (daniel-kokotajlo) · 2021-07-29T16:02:55.876Z · LW(p) · GW(p)
None of the prompts tell it what to do, they aren't even in english. (Or so I think? correct me if I'm wrong!) Instead they are in propositional logic, using atoms that refer to objects, colors, relations, and players. They just give the reward function in disjunctive normal form (i.e. big chain of disjunctions) and present it to the agent to observe.
comment by Daniel Kokotajlo (daniel-kokotajlo) · 2021-07-29T13:35:45.054Z · LW(p) · GW(p)
Also, what does the "1G 38G 152G" mean in the image? I can't tell. I would have thought it means number of games trained on, or something, except that at the top it says 0-Shot.
Replies from: Jozdien↑ comment by Jozdien · 2021-07-29T14:16:23.929Z · LW(p) · GW(p)
From the description of that figure in the paper, it says "three points in training" of a generation 5 agent, so probably the performance of that agent on the task at different learning steps?
Edit: To clarify, I think it's 0-shot learning on the six hand-authored tasks in the figure, but is being trained on other tasks to improve on normalized score percentiles. That figure is meant to show the correlation of this metric with improvement on the hand-authored tasks.
Replies from: daniel-kokotajlo↑ comment by Daniel Kokotajlo (daniel-kokotajlo) · 2021-07-29T16:01:02.237Z · LW(p) · GW(p)
In that case, the thing in the paper must be a typo, because the "Tool Use" graph here is clearly >0 reward, even for the 1G agent.
Replies from: Jozdien