DeepMind: Generally capable agents emerge from open-ended play
post by Daniel Kokotajlo (daniel-kokotajlo) · 2021-07-27T14:19:13.782Z · LW · GW · 53 commentsThis is a link post for https://deepmind.com/blog/article/generally-capable-agents-emerge-from-open-ended-play
Contents
54 comments
EDIT: Also see paper and results compilation video!
Today, we published "Open-Ended Learning Leads to Generally Capable Agents," a preprint detailing our first steps to train an agent capable of playing many different games without needing human interaction data. ... The result is an agent with the ability to succeed at a wide spectrum of tasks — from simple object-finding problems to complex games like hide and seek and capture the flag, which were not encountered during training. We find the agent exhibits general, heuristic behaviours such as experimentation, behaviours that are widely applicable to many tasks rather than specialised to an individual task.
...
The neural network architecture we use provides an attention mechanism over the agent’s internal recurrent state — helping guide the agent’s attention with estimates of subgoals unique to the game the agent is playing. We’ve found this goal-attentive agent (GOAT) learns more generally capable policies.
...
Playing roughly 700,000 unique games in 4,000 unique worlds within XLand, each agent in the final generation experienced 200 billion training steps as a result of 3.4 million unique tasks. At this time, our agents have been able to participate in every procedurally generated evaluation task except for a handful that were impossible even for a human. And the results we’re seeing clearly exhibit general, zero-shot behaviour across the task space — with the frontier of normalised score percentiles continually improving.
Looking qualitatively at our agents, we often see general, heuristic behaviours emerge — rather than highly optimised, specific behaviours for individual tasks. Instead of agents knowing exactly the “best thing” to do in a new situation, we see evidence of agents experimenting and changing the state of the world until they’ve achieved a rewarding state. We also see agents rely on the use of other tools, including objects to occlude visibility, to create ramps, and to retrieve other objects. Because the environment is multiplayer, we can examine the progression of agent behaviours while training on held-out social dilemmas, such as in a game of “chicken”. As training progresses, our agents appear to exhibit more cooperative behaviour when playing with a copy of themselves. Given the nature of the environment, it is difficult to pinpoint intentionality — the behaviours we see often appear to be accidental, but still we see them occur consistently.
My hot take: This seems like a somewhat big deal to me. It's what I would have predicted, but that's scary, given my timelines. I haven't read the paper itself yet but I look forward to seeing more numbers and scaling trends and attempting to extrapolate... When I do I'll leave a comment with my thoughts.
EDIT: My warm take: The details in the paper back up the claims it makes in the title and abstract. This is the GPT-1 of agent/goal-directed AGI; it is the proof of concept. Two more papers down the line (and a few OOMs more compute), and we'll have the agent/goal-directed AGI equivalent of GPT-3. Scary stuff.
53 comments
Comments sorted by top scores.
comment by Vanessa Kosoy (vanessa-kosoy) · 2021-07-27T20:46:16.699Z · LW(p) · GW(p)
This is certainly interesting! To put things in proportion though, here are some limitations that I see, after skimming the paper and watching the video:
- The virtual laws of physics are always the same. So, the sense in which this agent is "generally capable" is only via the geometry and the formal specification of the goal. Which is still interesting to be sure! But not as a big deal as it would be if it did zero-shot learning of physics (which would be an enormous deal IMO).
- The formal specification is limited to propositional calculus. This allows for a combinatorial explosion of possible goals, but there's still some sense in which it is "narrow". It would be a bigger deal if it used some more expressive logical language.
- For some tasks it looks like the agent is just trying vaguely relevant things at random until it achieves the goal. So, it is able to recognize the goal has been achieved, but less able to come up with efficient plans for achieving it. While "trying stuff until something sticks" is definitely a strategy I can relate to, it is not as impressive as planning in advance. Notice that just recognizing the goal is relatively easy: modulo the transformation from 2D imagery to a 3D model (which is certainly non-trivial but not a novel capability), you don't need AI to do it at all (indeed the environment obviously computes the reward via handcrafted code).
↑ comment by Daniel Kokotajlo (daniel-kokotajlo) · 2021-07-27T21:33:24.852Z · LW(p) · GW(p)
Thanks! This is exactly the sort of thoughtful commentary I was hoping to get when I made this linkpost.
--I don't see what the big deal is about laws of physics. Humans and all their ancestors evolved in a world with the same laws of physics; we didn't have to generalize to different worlds with different laws. Also, I don't think "be superhuman at figuring out the true laws of physics" is on the shortest path to AIs being dangerous. Also, I don't think AIs need to control robots or whatnot in the real world to be dangerous, so they don't even need to be able to understand the true laws of physics, even on a basic level.
--I agree it would be a bigger deal if they could use e.g. first-order logic, but not that much of a bigger deal? Put it this way: wanna bet about what would happen if they retrained these agents, but with 10x bigger brains and for 10x longer, in an expanded environment that supported first-order logic? I'd bet that we'd get agents that perform decently well at first-order logic goals.
--Yeah, these agents don't seem smart exactly; they seem to be following pretty simple general strategies... but they seem human-like and on a path to smartness, i.e. I can easily imagine them getting smoothly better and better as we make them bigger and train them for longer on more varied environments. I think of these guys as the GPT-1 of agent AGI.
Replies from: vanessa-kosoy↑ comment by Vanessa Kosoy (vanessa-kosoy) · 2021-07-27T22:11:05.336Z · LW(p) · GW(p)
I don't see what the big deal is about laws of physics. Humans and all their ancestors evolved in a world with the same laws of physics; we didn't have to generalize to different worlds with different laws. Also, I don't think "be superhuman at figuring out the true laws of physics" is on the shortest path to AIs being dangerous. Also, I don't think AIs need to control robots or whatnot in the real world to be dangerous, so they don't even need to be able to understand the true laws of physics, even on a basic level.
The entire novelty of this work revolves around zero-shot / few-shot performance: the ability to learn new tasks which don't come with astronomic amounts of training data. To evaluate to which extent this goal has been achieved, we need to look at what was actually new about the tasks vs. what was repeated in the training data a zillion times. So, my point was, the laws of physics do not contribute to this aspect.
Moreover, although the laws of physics are fixed, we didn't evolve to know all of physics. Lots of intuition about 3D geometry and mechanics: definitely. But there are many, many things about the world we had to learn. A bronze age blacksmith posseted sophisticated knowledge about the properties of materials and their interaction that did not come from their genes, not to mention a modern rocket scientist. (Ofc, the communication of knowledge means that each of them benefits from training data acquired by other people and previous generations, and yet.) And, learning is equivalent to performing well on a distribution of different worlds.
Finally, an AI doesn't need to control robots to be dangerous but it does need to create sophisticated models of the world and the laws which govern it. That doesn't necessarily mean being good at the precise thing we call "physics" (e.g. figuring out quantum gravity), but it is a sort of "physics" broadly construed (so, including any area of science and/or human behavior and/or dynamics of human societies etc.)
I agree it would be a bigger deal if they could use e.g. first-order logic, but not that much of a bigger deal? Put it this way: wanna bet about what would happen if they retrained these agents, but with 10x bigger brains and for 10x longer, in an expanded environment that supported first-order logic?
I might be tempted to take some such bet, but it seems hard to operationalize. Also hard to test unless DeepMind will happen to perform this exact experiment.
Replies from: quintin-pope↑ comment by Quintin Pope (quintin-pope) · 2021-07-28T02:41:33.858Z · LW(p) · GW(p)
What really impressed me were the generalized strategies the agent applied to multiple situations/goals. E.g., "randomly move things around until something works" sounds simple, but learning to contextually apply that strategy
- to the appropriate objects,
- in scenarios where you don't have a better idea of what to do, and
- immediately stopping when you find something that works
is fairly difficult for deep agents to learn. I think of this work as giving the RL agents a toolbox of strategies that can be flexibly applied to different scenarios.
I suspect that finetuning agents trained in XLand in other physical environments will give good results because the XLand agents already know how to use relatively advanced strategies. Learning to apply the XLand strategies to the new physical environments will probably be easier than starting from scratch in the new environment.
↑ comment by Daniel Kokotajlo (daniel-kokotajlo) · 2021-07-30T09:17:27.753Z · LW(p) · GW(p)
Let's define AGI as "AI that is generally intelligent, i.e. it isn't limited to a narrow domain, but can do stuff and think stuff about a very wide range of domains."
Human-level AGI (Sometimes confusingly shortened to "AGI") is AGI that is similarly competent to humans at a similarly large-and-useful range of domains.
My stance is that GPT-3 is AGI, but not human-level AGI. (Not even close).
I'd also add agency as an important concept -- an AI is agenty if it behaves in a goal-directed way. I don't think GPT-3 is agenty. But unsurprisingly, lots of game-playing AIs are agenty. AlphaGo was an agenty narrow AI. I think these new 'agents' trained by DeepMind are agenty AGI, but just extremely crappy agenty AGI. There is a wide domain they can perform in --but it's not that wide. Not nearly as wide as the human range. And they also aren't that competent even within the domain.
Thing is though, as we keep making these things bigger and train them for longer on more diverse data... it seems that they will become more competent, and the range of things they do will expand. Eventually we'll get to human-level AGI, though it's another question exactly how long that'll take.
comment by gwern · 2021-07-29T17:10:32.991Z · LW(p) · GW(p)
Looking qualitatively at our agents, we often see general, heuristic behaviours emerge — rather than highly optimised, specific behaviours for individual tasks. Instead of agents knowing exactly the “best thing” to do in a new situation, we see evidence of agents experimenting and changing the state of the world until they’ve achieved a rewarding state.
The blessings of scale strike again. People have been remarkably quick to dismiss the lack of "GPT-4" models as indicating that the scaling hypothesis is dead already. (The only scaling hypothesis refuted by the past year is the 'budget scaling hypothesis', if you will. All the other research continues to confirm it.)
Incidentally, it's well worth reading the previous papers from DM on using populations to learn ever more complex and general tasks: AlphaStar, Quake, rats, VR/language robotics, team soccer.
We've all read about AlpaFold 2, but I'd also highlight VQ-VAE being used increasingly pervasively as a drop-in generative model; "Multimodal Few-Shot Learning with Frozen Language Models", Tsimpoukelli et al 2021, further demonstrating the power of large self-supervised models for fast human-like learning; and the always-underappreciated line of work on MuZero for doing sample-efficient & continuous-action model-based RL: "MuZero Unplugged: Online and Offline Reinforcement Learning by Planning with a Learned Model", Schrittwieser et al 2021; "Sampled MuZero: Learning and Planning in Complex Action Spaces", Hubert et al 2021 (benefiting from better use of existing compute, like Podracer).
comment by Jsevillamol · 2022-03-30T15:48:58.806Z · LW(p) · GW(p)
Marius Hobbhahn has estimated the number of parameters here. His final estimate is 3.5e6 parameters.
Anson Ho has estimated the training compute (his reasoning at the end of this answer). His final estimate is 7.8e22 FLOPs.
Below I made a visualization of the parameters vs training compute of n=108 important ML system, so you can see how DeepMind's syste (labelled GOAT in the graph) compares to other systems.
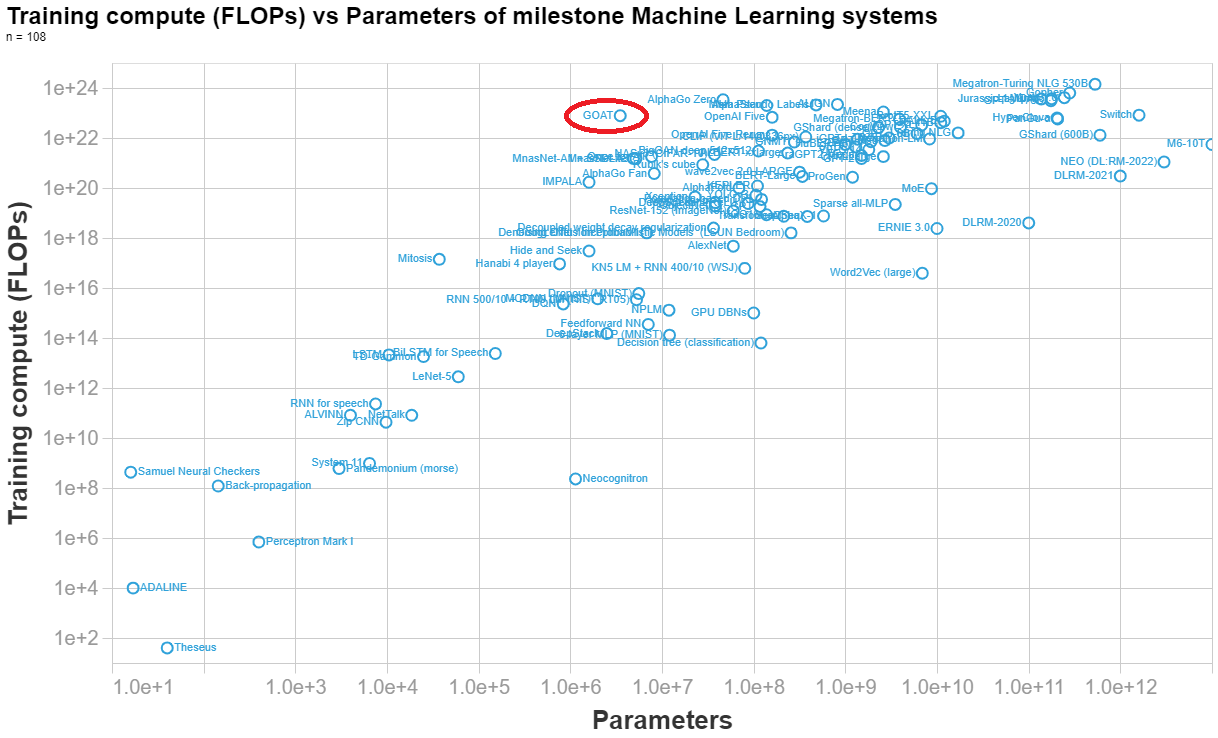
Replies from: daniel-kokotajlo[Final calculation]
(8 TPUs)(4.20e14 FLOP/s)(0.1 utilisation rate)(32 agents)(7.3e6 s/agent) = 7.8e22 FLOPs==========================
NOTES BELOW[Hardware]
- "Each agent is trained using 8 TPUv3s and consumes approximately 50,000 agent steps (observations) per second."
- TPUv3 (half precision): 4.2e14 FLOP/s
- Number of TPUs: 8
- Utilisation rate: 0.1[Timesteps]
- Figure 16 shows steps per generation and agent. In total there are 1.5e10 + 4.0e10 + 2.5e10 + 1.1e11 + 2e11 = 3.9e11 steps per agent.
- 3.9e11 / 5e4 = 8e6 s → ~93 days
- 100 million steps is equivalent to 30 minutes of wall-clock time in our setup. (pg 29, fig 27)
- 1e8 steps → 0.5h
- 3.9e11 steps → 1950h → 7.0e6 s → ~82 days
- Both of these seem like overestimates, because:
“Finally, on the largest timescale (days), generational training iteratively improves population performance by bootstrapping off previous generations, whilst also iteratively updating the validation normalised percentile metric itself.” (pg 16)
- Suggests that the above is an overestimate of the number of days needed, else they would have said (months) or (weeks)?
- Final choice (guesstimate): 85 days = 7.3e6 s[Population size]
- 8 agents? (pg 21) → this is describing the case where they’re not using PBT, so ignore this number
- The original PBT paper uses 32 agents for one task https://arxiv.org/pdf/1711.09846.pdf (in general it uses between 10 and 80)
- (Guesstimate) Average population size: 32
↑ comment by Daniel Kokotajlo (daniel-kokotajlo) · 2022-03-30T16:53:02.183Z · LW(p) · GW(p)
Thanks so much! So, for comparison, fruit flies have more synapses than these XLAND/GOAT agents have parameters! https://en.wikipedia.org/wiki/List_of_animals_by_number_of_neurons
comment by Sébastien Larivée (sebastien-larivee) · 2021-07-27T19:40:19.850Z · LW(p) · GW(p)
This seems to support Reward is Enough.
More specifically:
DM simulates a lower fidelity version of real world physics -> Applies real world AI methods -> Achieves generalised AI performance.
This is a pretty concrete demonstration that current AI methods are sufficient to achieve generality, just need more real world data to match the more complex physics of reality.
Replies from: TheSupremeAI, zachary-robertson↑ comment by TheSupremeAI · 2021-07-28T01:13:19.106Z · LW(p) · GW(p)
And more compute of course. As always.
↑ comment by Past Account (zachary-robertson) · 2021-07-29T17:26:54.467Z · LW(p) · GW(p)
[Deleted]
comment by Quintin Pope (quintin-pope) · 2021-07-28T02:29:18.365Z · LW(p) · GW(p)
Very impressive results! I'm particularly glad to see the agents incorporating text descriptions of their goals in the agents' inputs. It's a step forward in training agents that flexibly follow human instructions.
However, it currently looks like the agents are just using the text instructions as a source of information about how to acquire reward from their explicit reward functions, so this approach won't produce corrigible agents. Hopefully, we can combine XLand with something like the cooperative inverse reinforcement learning paradigm.
E.g., we could add CIRL agent to the XLand environments whose objective is to assist the standard RL agents. Then we'd have:
- An RL agent
- whose inputs are the text description of its goal and its RGB vision + other sensors
- that gets direct reward signals
- A CIRL agent
- whose inputs are the text description of the RL agent's goals and the CIRL agent's own RGB vision + other sensors
- that has to infer the RL agent's true reward from the RL agent's behavior
Then, apply XLand open ended training where each RL agent has a variable number of CIRL agents assigned as assistants. Hopefully, we'll get a CIRL agent that can receive instructions via text and watch the behavior of the agent it's assisting to further refine its beliefs about its current objective.
Replies from: zachary-robertson↑ comment by Past Account (zachary-robertson) · 2021-07-29T17:20:50.103Z · LW(p) · GW(p)
[Deleted]
Replies from: quintin-pope, brp↑ comment by Quintin Pope (quintin-pope) · 2021-07-29T22:01:23.977Z · LW(p) · GW(p)
The summary says they use text and a search for “text” in the paper gives this on page 32:
“In these past works, the goal usually consists of the position of the agent or a target observation to reach, however some previous work uses text goals (Colas et al., 2020) for the agent similarly to this work.”
So I thought they provided goals as text. I’ll be disappointed if they don’t. Hopefully, future work will do so (and potentially use pretrained LMs to process the goal texts).
Replies from: zachary-robertson↑ comment by Past Account (zachary-robertson) · 2021-07-30T16:53:11.635Z · LW(p) · GW(p)
[Deleted]
↑ comment by brp · 2021-08-09T04:03:17.504Z · LW(p) · GW(p)
What's the practical difference between "text" and one-hots of said "text"? One-hots are the standard for inputting text into models. It is only recently that we expect models to learn their preferred encoding for raw text (cf. transformers). By taking a small shortcut, the authors of this paper get to show off their agent work without loss of generality: one could still give one-hot instructions to an agent that is learning to act in the real life.
comment by [deleted] · 2021-08-04T15:14:41.982Z · LW(p) · GW(p)
It is interesting to note the limitations of the system. From the paper:
6.4.5| Failed Hand-authored Tasks
Gap tasks Similar to the task in Figure 21, in this task there is an unreachable object which the agent is tasked with being near. The object is unreachable due to the existence of a chasm between the agent and object, with no escape route (once agent falls in the chasm, it is stuck). This task requires the agent to build a ramp to navigate over to reach the object. It is worth noting that during training no such inescapable regions exist. Our agents fall into the chasm, and as a result get trapped. It suggests that agents assume that they cannot get trapped.
Multiple ramp-building tasks Whilst some tasks do show successful ramp building (Figure 21), some hand-authored tasks require multiple ramps to be built to navigate up multiple floors which are inaccessible. In these tasks the agent fails.
Following task One hand-authored task is designed such that the co-player’s goal is to be near the agent, whilst the agent’s goal is to place the opponent on a specific floor. This is very similar to the test tasks that are impossible even for a human, however in this task the co-player policy acts in a way which follows the agent’s player. The agent fails to lead the co-player to the target floor, lacking the theory-of-mind to manipulate the co-player’s movements. Since an agent does not perceive the goal of the co-player, the only way to succeed in this task would be to experiment with the co-player’s behaviour, which our agent does not do.
Replies from: daniel-kokotajlo↑ comment by Daniel Kokotajlo (daniel-kokotajlo) · 2021-08-04T15:49:49.027Z · LW(p) · GW(p)
Yep! Thanks! I'm especially keen to see whether future iterations of this system are able to succeed at these tasks.
comment by Sammy Martin (SDM) · 2021-07-27T18:20:26.767Z · LW(p) · GW(p)
This is amazing. So it's the exact same agents performing well on all of these different tasks, not just the same general algorithm retrained on lots of examples. In which case, have they found a generally useful way around the catastrophic forgetting problem? I guess the whole training procedure, amount of compute + experience, and architecture, taken together, just solves catastrophic forgetting - at least for a far wider range of tasks than I've seen so far.
Could you use this technique to e.g. train the same agent to do well on chess and go?
I also notice as per the little animated gifs in the blogpost, that they gave each agent little death ray projectors to manipulate objects, and that they look a lot like Daleks.
Replies from: adamShimi, Charlie Steiner{kind=link}
↑ comment by adamShimi · 2021-07-27T18:41:45.669Z · LW(p) · GW(p)
Could you use this technique to e.g. train the same agent to do well on chess and go?
If I don't misunderstand your question, this is something they already did with MuZero.
Replies from: Kaj_Sotala↑ comment by Kaj_Sotala · 2021-07-27T18:48:29.238Z · LW(p) · GW(p)
Didn't they train a separate MuZero agent for each game? E.g. the page you link only talks about being able to learn without pre-existing knowledge.
Replies from: adamShimi↑ comment by adamShimi · 2021-07-27T20:30:22.591Z · LW(p) · GW(p)
Actually, I think you're right. I always thought that MuZero was one and the same system for every game, but the Nature paper describes it as an architecture that can be applied to learn different games. I'd like a confirmation from someone who actually studied it more, but it looks like MuZero indeed isn't the same system for each game.
Replies from: wangscarpet↑ comment by wangscarpet · 2021-07-28T15:28:59.070Z · LW(p) · GW(p)
Yep, they're different. It's just an architecture. Among other things, Chess and Go have different input/action spaces, so the same architecture can't be used on both without some way to handle this.
This paper uses an egocentric input, which allows many different types of tasks to use the same architecture. That would be the equivalent of learning Chess/Go based on pictures of the board.
↑ comment by Charlie Steiner · 2021-07-28T18:09:52.311Z · LW(p) · GW(p)
I think if anything's allowed it to learn more diverse tasks, it's the attentional layers that have gotten thrown in at the recurrent step (though I haven't actually read beyond the blog post, so I don't know what I'm talking about). In which case it seems like it's a question of how much data and compute you want to throw at the problem. But I'll edit this after I read the paper and aren't just making crazy talk.
comment by [deleted] · 2021-07-28T07:25:24.969Z · LW(p) · GW(p)
I have little to no technical knowledge when it comes to AI, so I have two questions here.
1.) Are the agents or the learning process that was constructed the focus of the paper?
2.) How major of a breakthrough is this toward AGI?
Replies from: Self_Optimization↑ comment by Self_Optimization · 2021-07-28T23:20:12.187Z · LW(p) · GW(p)
-
keeping in mind I haven’t gotten a chance to read the paper itself… the learning process is the main breakthrough, because it creates agents that can generalise to multiple problems. There are admittedly commonalities between the different problems (e.g. the physics), but the same learning process applied to something like board game data might make a “general board game player”, or perhaps even something like a “general logistical-pipeline-optimiser” on the right economic/business datasets. The ability to train an agent to succeed on such diverse problems is a noticeable step towards AGI, though there’s little way of knowing how much it helps until we figure out the Solution itself.
-
keeping in mind I’ve only recently started studying ML and modern AI techniques… Judging from what I’ve read here on LW, it’s maybe around 3/4ths as significant as GPT-3? I might be wrong here, though.
↑ comment by Jozdien · 2021-07-29T09:27:24.930Z · LW(p) · GW(p)
Judging from what I’ve read here on LW, it’s maybe around 3/4ths as significant as GPT-3? I might be wrong here, though.
Disclaimer to the effect that I'm not very experienced here either and might be wrong too, but I'm not sure that's the right comparison. It seems to me like GPT-2 (or GPT, but I don't know anything about it) was a breakthrough in having one model that's good at learning on new tasks with little data, and GPT-3 was a breakthrough in showing how far capabilities like that can extend with greater compute. This feels more like the former than the latter, but also sounds more significant than GPT-2 from a pure generalizing capability standpoint, so maybe slightly more significant than GPT-2?
↑ comment by Daniel Kokotajlo (daniel-kokotajlo) · 2021-07-29T22:18:43.240Z · LW(p) · GW(p)
As a counterpoint, when I feel like a circle jerk downvote is happening I usually upvote to counteract it. I did in this case with your OP, even though I think it's wrong. And apparently I'm not the only one who does so. So it's not all bad... but yeah, I agree it is disappointing. I don't think your post was low-quality, it was just wrong. Therefore not deserving of a negative score, instead deserving of thoughtful replies.
Replies from: celeste↑ comment by celeste · 2021-07-30T05:15:51.516Z · LW(p) · GW(p)
Yeah, I wanted to clarify that this is closer to what I mean, but I wondered if habryka endorses downvoting comments seen as obviously wrong.
Such a strategy seems like it could lead to a general culture of circlejerking, but it might also prevent the same tired discussions from playing out repeatedly. I don't have a good sense of the relative importance of these concerns, and I suspected an LW admin's intuition might be better calibrated.
Replies from: Ruby↑ comment by Ruby · 2021-08-12T23:45:19.455Z · LW(p) · GW(p)
[LW Admin here]. Karma gets interpreted in a number of ways, but one of my favorites is that karma is for "how much attention you want a thing to get." If a comment seems wrong but valuable for people to read, I might upvote it. If it seems correct but it is immaterial and unhelpful, I might downvote it. Generally, there's a higher bar for things that wrong to be worth reading by people.
I can't fully explain other people's voting behavior, but in my case I'd often downvote wrong things just so they get less attention.
↑ comment by Daniel Kokotajlo (daniel-kokotajlo) · 2021-07-29T22:28:49.659Z · LW(p) · GW(p)
<3
Your view is still common, but decreasingly so in the ML community and almost nonexistent on LW I think. My opinion is similar to Abram's, Yair's, and Quintin's. I'd be happy to say more if you like!
↑ comment by Quintin Pope (quintin-pope) · 2021-07-28T02:49:26.821Z · LW(p) · GW(p)
There are people who've been blind from birth. They're still generally intelligent. I think general intelligence is mostly applying powerful models to huge amounts of rich data. Human senses are sufficiently rich even without vision.
Also, there are lots of differences between human brains and current neural nets. E.g., brains are WAY more powerful than current NNs and train for years on huge amounts of incredibly rich sensory data.
↑ comment by Daniel Kokotajlo (daniel-kokotajlo) · 2021-07-30T07:58:34.162Z · LW(p) · GW(p)
We need to understand information encoding in the brain before we can achieve full AGI.
I disagree; it seems that we are going to brute-force AGI by searching for it, rather than building it, so to speak. Stochastic gradient descent on neural networks is basically a search in circuit-space for a circuit that does the job.
The machine learning stuff comes with preexisting artificial encoding. We label stuff ourselves.
I'm not sure what you mean by this but it seems false to me. "Pretraining" and "unsupervised learning" are a really big deal these days. I'm pretty sure lots of image classifiers, for example, generate their own labels for things basically, because they are just trained to predict stuff and then in order to do so they end up coming up with their own categories and concepts. GPT-3 et al did this too.
Without innate information encoding for language, infants won't be learning much about the world through language, let alone picking up an entirely language from purely listening experiences.
GPT-3 begins as a totally blank slate. Yet it is able to learn language, and quite a lot about the world through language. It can e.g. translate between English and Chinese even though all it's done is read loads of text. This strongly suggests that whatever innate stuff is present in the human brain is nice but nonessential, at least for the basics like learning language and learning about the world.
I'd like to be corrected if I'm wrong on AGI. I've only read a little about it back in my freshman years in college. I'm sure there has been a lot of development since then, and I'd like to learn from this community. From my experience of reading about AGI, it's still dealing with more or less the confines of the computational statistics nature of intelligence.
I don't know when you went to college, but a lot has changed in the last 10 years and in the last 2-5 years especially. If you are looking for more stuff to read on this, I recommend Gwern on the Scaling Hypothesis.
↑ comment by habryka (habryka4) · 2021-07-29T04:47:26.236Z · LW(p) · GW(p)
There is no automatic voting routine. But all comments start with a single small-upvote by their author, and posts start with a single strong-upvote by their author.
Replies from: None↑ comment by [deleted] · 2021-07-29T20:08:59.344Z · LW(p) · GW(p)
You mean using the author's karma for the initial vote? Interesting if so. (And better than the alternative where a zero karma spambot gets as much visibility right away as a well respected poster)
The circle jerk problem is unfortunate. I have noticed on Reddit that a huge part of voting behavior is you eat many downvotes for expressing a position that disagrees with the subreddit consensus. Regardless of correctness.
Replies from: habryka4↑ comment by habryka (habryka4) · 2021-07-29T20:19:36.978Z · LW(p) · GW(p)
Yep, the author's vote-strength is used for the initial vote. So comments by users with more karma can start out with 2 points, as opposed to the default 1, and posts by users with more karma can start with up to 10 points.
Replies from: None↑ comment by [deleted] · 2021-07-29T20:41:05.429Z · LW(p) · GW(p)
Neat. Why stop there? Why not start an EY post at thousands of points?
Replies from: habryka4↑ comment by habryka (habryka4) · 2021-07-30T03:52:55.451Z · LW(p) · GW(p)
Sometimes Eliezer's posts are amazing, sometimes they are only OK. Saturating the karma system would get rid of the distinction between those, and also break any sorting we might want to do on the frontpage based on karma.
comment by [deleted] · 2021-07-28T05:05:41.966Z · LW(p) · GW(p)
I apologize if this is something you’ve already covered ad nauseum, but what are your timelines?
Replies from: daniel-kokotajlo↑ comment by Daniel Kokotajlo (daniel-kokotajlo) · 2021-07-28T08:08:41.787Z · LW(p) · GW(p)
If you click on my name, it'll take you to my LW page, where you can see my posts and post sequences. I have a sequence on timelines. If you want a number, 50% by 2030.
Replies from: None↑ comment by [deleted] · 2021-07-29T19:58:45.633Z · LW(p) · GW(p)
I see the numbers but exponential growth is hard for humans. 2012 feels like practically yesterday, with consumer tech having barely changed. Alexa came out in 2014, but prototypes for voice recognition had existed for years. It reminds me of how it felt in February with the covid news. It didn't feel real that a virus that had yet to kill a single us citizen would cause such damage.
comment by MSRayne · 2021-08-03T13:22:20.011Z · LW(p) · GW(p)
This is becoming an ethical concern. At this point I would say if they don't stop they are risking severe mindcrime. If the overview you quoted is correct, those entities are sentient enough to deserve moral consideration. But no one is going to give that consideration, and anyway this produces the risk of AGI which is bad for everyone. I wish companies like DeepMind would realize how terrifyingly dangerous what they're doing is, and focus on perfecting narrow AIs for various different specific tasks instead.
Replies from: daniel-kokotajlo↑ comment by Daniel Kokotajlo (daniel-kokotajlo) · 2021-08-03T14:00:31.585Z · LW(p) · GW(p)
If you want to discuss this more with me, I'd be interested! I had similar thoughts when reading the paper... especially when reading about all the zero-sum games they made these agents play.
Replies from: MSRayne↑ comment by MSRayne · 2021-08-03T21:31:50.081Z · LW(p) · GW(p)
I'm not sure what else to say on the matter but feel free to shoot me a DM.
Note that I'm not an AI expert or anything; the main reason I post here so rarely is that I'm more of an intuitive thinker, armchair philosopher, poet, etc than anything and I feel intimidated next to all you smart analytical people; my life's goal though is to ensure that the first superintelligence is a human collective mind (via factored cognition, BCIs, etc), rather than an AGI, hence my statement about narrow AIs (I see AIs as plugins for the human brain, not as something that ought to exist as separate entities).
comment by bfinn · 2021-07-28T23:34:57.518Z · LW(p) · GW(p)
The game world could include a sign stating the rules/objective of the game in English. Presumably then (perhaps helped by GPT-3) the agents might well learn to find & read it, as the best shortcut to working out what to do. And figure out both the meanings of individual words (nouns, adjectives, verbs) and grammar (word order, conjunctions, etc.) so as to understand whole sentences.*
And thus make the leap from GPT-3 as clever spinner of meaningless symbols like R, E and D to those symbols having a real-world meaning like 'RED'. Or even 'Keep the red cube within line of sight of the yellow pyramid, but don't let the blue agent see either of them'.
Hence leaping from Chinese Room to something more mind-like?
(*Though they might need help, e.g. a pre-coded 'language instinct', as trial and error may take a v long time to figure these out.)
comment by Choosing Beggars · 2021-07-27T14:30:03.067Z · LW(p) · GW(p)
Replies from: dave-lindbergh, abramdemski, ChickCounterfly, celeste↑ comment by Dave Lindbergh (dave-lindbergh) · 2021-07-27T17:24:08.891Z · LW(p) · GW(p)
We need to understand information encoding in the brain before we can achieve full AGI.
Maybe. For many years, I went around saying that we'd never have machines that accurately transcribe natural speech until those machines understood the meaning of the speech. I thought that context was necessary.
I was wrong.
Replies from: daniel-kokotajlo, bfinn↑ comment by Daniel Kokotajlo (daniel-kokotajlo) · 2021-07-27T17:46:35.851Z · LW(p) · GW(p)
What makes you think our latest transcription AI's don't understand the meaning of the speech? Also what makes you think they have reached a sufficient level of accuracy that your past self would have claimed that they must understand the meaning of the speech? Maybe they still make mistakes sometimes and maybe your past self would have pointed to those mistakes and said "see, they don't really understand."
↑ comment by bfinn · 2021-07-28T22:33:04.765Z · LW(p) · GW(p)
They do use context, surely - viz. the immediate verbal context, plus training on vast amounts of other text which is background 'information'. Which though not tantamount to meaning (as it's not connected to the world), would form a significant part of meaning.
↑ comment by abramdemski · 2021-07-27T15:39:38.752Z · LW(p) · GW(p)
The machine learning stuff comes with preexisting artificial encoding. We label stuff ourselves.
Generally speaking, that's not so true as it used to be. In particular, a lot of stuff from DeepMind (such as the Atari-playing breakthrough from a while ago) works with raw video inputs. I haven't looked at the paper from the OP to verify it's the same.)
Also, I have the impression that DeepMind takes a "copy the brain" approach fairly seriously, and they think of papers like this as relevant to that. But I am not sure of the details.
Replies from: yair-halberstadt↑ comment by Yair Halberstadt (yair-halberstadt) · 2021-07-27T16:36:35.478Z · LW(p) · GW(p)
They're also working with raw RGB input here too.
↑ comment by ChickCounterfly · 2021-07-27T22:48:04.271Z · LW(p) · GW(p)
Did evolution need to understand information encoding in the brain before it achieved full GI?
↑ comment by celeste · 2021-07-29T03:43:10.532Z · LW(p) · GW(p)
Upvoted because it seems harmful to downvote comments that are wrong but otherwise adhere to LW norms.
(If this comment actually does violate a norm, I'm curious as to which.)
Replies from: habryka4↑ comment by habryka (habryka4) · 2021-07-29T04:48:44.582Z · LW(p) · GW(p)
I think voting should happen primarily based on quality of contribution, not norm violation. For norm violations you can report it to the mods. I think it's pretty reasonable for some comments that don't violate any norms but just seem generically low quality to get downvoted (and indeed, most of the internet is full of low-quality contributions that make discussions frustrating and hard to interact with, without violating any clear norms, and our downvote system holds them at least somewhat at bay).