Research Notes: Running Claude 3.7, Gemini 2.5 Pro, and o3 on Pokémon Red
post by Julian Bradshaw · 2025-04-21T03:52:34.759Z · LW · GW · 1 commentsContents
A Casual Research Narrative An only somewhat sorted list of observations about all this Model Vision of Pokémon Red is Bad. Really Bad. Models Can't Remember Spatial Reasoning? What's that? A Grasp on Reality Costs Why do this at all? So which model is better? Miscellanea: ClaudePlaysPokemon Derp Anecdotes None 1 comment

Disclaimer: this post was not written by me, but by a friend who wishes to remain anonymous. I did some editing, however.
So a recent post [LW · GW] my friend wrote has made the point quite clearly (I hope) that LLM performance on the simple task of playing and winning a game of Pokémon Red is highly dependent on the scaffold and tooling provided. In a way, this is not surprising—the scaffold is there to address limitations in what the model can do, and paper over things like lack of long-term context, executive function, etc.
But the thing is, I thought I knew that, and then I actually tried to run Pokémon Red.
A Casual Research Narrative
The underlying code is the basic Claude scaffold provided by David Hershey of Anthropic.[1] I first simply let Claude 3.7 run on it for a bit, making observations about what I thought might generate improvements. Along the way there were many system prompt changes, tweaking this and that.
For instance, after turning the navigation tool[2] on, Claude pretty much never used it. Even now it still only does so intermittently. While arguably a big tool assist, it ends up being mostly QoL for human observers, making things go by faster. Every once in a while it will path the model past a small obstacle it was struggling with. I don't consider it a big help as-is.
My first additions were to reintroduce something I knew Claude and GeminiPlaysPokemon had already done: writing the grid coordinates onto the screenshot provided to the model.
This suppressed a behavior I had noticed early: Claude was awful at using the navigation tool because he simply didn't know what tile was which. It also was necessary for my first change.
My first change was an idea I had been ruminating on for some time, as a way of bypassing vision and memory limitations. The models would be provided with a tool to dictate labels at map coordinates for permanent storage. For instance, if a coordinate was a door from A -> B, it would be able to note that. These labels would then be provided in the text input as well as printed as a label on the screenshot.
> kind of tempted to switch to gemini now lol
This provided some immediate but marginal benefits. For example, it would no longer forget that it had seen the Pokémon Center earlier and had gotten lost trying to walk in the door. Getting it to actually use this feature required some aggressive coaching in the system prompt (this will be a recurring theme), including specific instructions to place labels after passing through a transition/door/staircase, since otherwise the model doesn't know it's important.
[Q for the audience: Is that a "fair" bit of handholding for the model?]
Every once in a while it would make an incorrect label, such as labeling a random piece of ground as an entrance. This could be quite bad, distracting the model for up to hundreds of actions, but fortunately only occurred rarely, and could be discouraged with some stern wording in the system prompt.

> this shit's on you
I also added a feature where the model would be informed of what tiles it had been on recently, both in text and in the form of green boxes on the map overlay. In addition, if it had been too long since the last checkpoint/meaningful progress (Which the model could use "mark_checkpoint" to indicate), blue boxes would appear to label *every* coordinate the model had already been, to try to nudge it to go to new locations. The idea is that this would simulate the location-memory the model does not natively have.
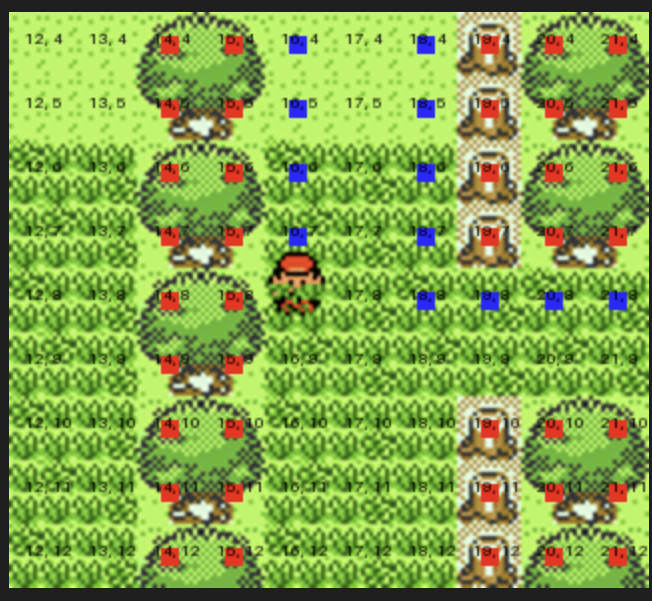
Narrator: Claude did not one shot the area.
This turns out to work only slightly. The blue squares simply aren't powerful enough to overcome the model's native desire to do what it wants to do.
Interestingly, I was able to meaningfully improve Claude's use of the blue squares in Viridian forest by adding verbiage in the system prompt about the importance of using them to perform a "depth-first search" when inside mazes. Claude seemed to understand what this meant and implemented a credible attempt at it, before eventually sputtering out and losing confidence metaphorical inches from the exit. Still, the fact that a programming-flavored tip had a big effect is intriguing.
Eventually, I concluded that the kind of overlay I had seen for ClaudePlaysPokemon (Where impassable tiles are red and passable tiles are cyan) is necessary. Partly as a QoL to avoid watching it constantly trying to pass through tables to reach a NPC but also because the models are puzzlingly bad at deciding what is and isn't a building, routinely declaring open stretches of ground to be a building. My hope was that labeling impassable building segments with red would mitigate this.
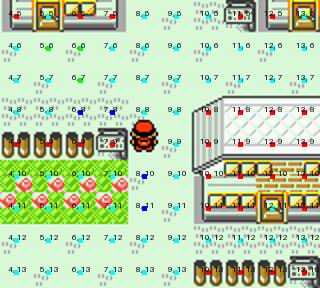
It *mitigates* it, but doesn't entirely eliminate it. Despite blatant hinting that buildings are large objects labeled with multiple red squares, etc. you will still find Gemini or Claude declaring that an open stretch of ground must be a building and then trying to walk up and down to find the elusive door.
(Also they will spend large amounts of time trying to path into a building from all angles. This isn't something that can absolutely be forbidden—some buildings in Red *are* entered from the top—but telling them the door is on the bottom helps a lot. This behavior is particularly frustrating because sometimes, after a long while, they will say "looking carefully, I can see the door is at (X, Y)" and then walk right in. Why didn't you do this 200 actions ago!?)
This, in the end, was what motivated me to reintroduce "Critique Claude"/"Guide Gemini"/"Oversight o3".[3] That is, a secondary model call that occurs on context summary whose job it is to provide hints if the model seems stuck, and which is given a system prompt specifically for this purpose. It can be told to look for telltale signs of common fail-states and attempt to address then, and can even be given "meta" prompting about how to direct the other model.
This is sometimes very helpful for getting the model out of... let's call them "derp"-loops, but is not *entirely* free. Every once in a while, it will pick up a hallucination from the main conversation, believe it, and perpetuate it. But on the balance it helps more than hurts, and that kind of statistical improvement is often what we're looking for.

At this point we're close to the final state of where I'm at. Much of my time since has been devoted on various mapping exercises to try to see if I can improve nagivation. Results have been disappointing: pretty much no model seems capable of ingesting ASCII maps + screenshots and making a credible navigation map of an area, even when I substitute a collision map from the game's RAM for the screenshot. In the end, I think doing this hurt more than helped and I will probably disable it.
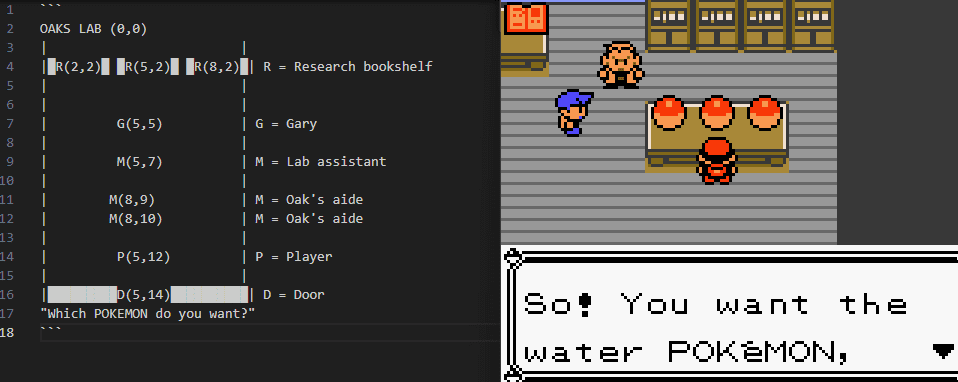
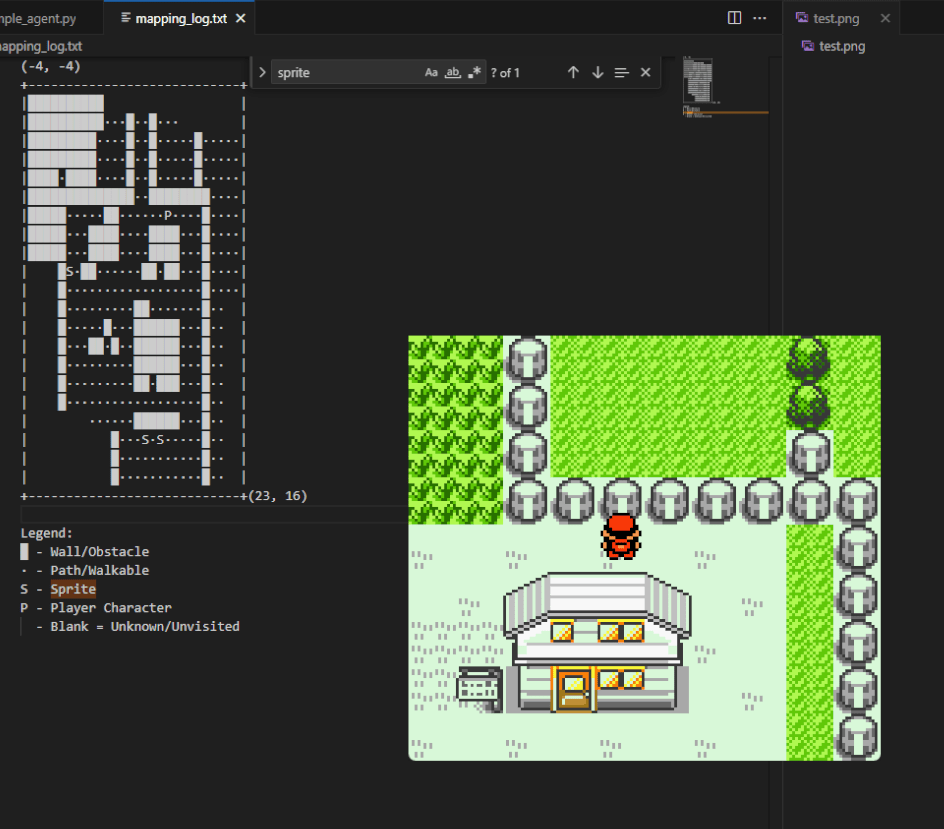
My current thoughts are that "solving" the navigation problem, as much as it might be a white whale, is the most important problem in making efficient progress through the game (and saving me compute). The only other problem that is of similar importance is reasoning and grasp on reality, and if I managed to solve that I fully expect to be kidnapped soon.
I am pretty willing to bend the rules a bit on this at this point. My current ideas center on introducing a "Navigation Claude" and feeding it an exploration map, a goal, and tasking it with the sole job of giving specific navigation advice. This is a lot of spoon-feeding at this point, but I am somewhat interested in finding just how "easy" it is to scaffold a model like Claude into finishing the game. (Also I really don't want to run 50000 steps ~ $1500 to get through Mt. Moon).[4]
An only somewhat sorted list of observations about all this
Editor's note: these observations were written before the Research Narrative, and some are inferable from it.
Model Vision of Pokémon Red is Bad. Really Bad.
It takes only the briefest amount of watching to convince yourself that the models can barely see what's going on, if at all. NPCs are routinely misidentified, pokeballs on the ground are confused with NPCs, Nurse Joy is confused with any NPC in the room or the pokemon healing machine. PCs and buildings are conjured out of empty patches of ground. And the staircase in the back-right of the starting room may as well have a cloaking field on it.

I really do mean it only takes the briefest amount of watching. Claude 3.7, Gemini 2.5, and o3 (most of the time) beeline directly for the bed in the lower left of the starting room, or the plant in the lower right, stating confidently that the stairs are there. They will then typically spend a good 50-70 actions (sometimes more) wandering the room trying to find the stairs they are convinced are there until stumbling onto the actual stairs more or less by accident.

Perhaps the strongest evidence of this for me is when Claude 3.7 is asked to make an ASCII map of its surroundings in Viridian forest. When standing in tall grass, it ends up drawing essentially a solid forest, with no useful benchmarks whatsoever, showing that it is close to walking blind.
Despite a reputation for having better vision than Claude 3.7, Gemini 2.5 does only somewhat better. It more consistently notices the red mat at the bottom of buildings leading to the exit, much more consistently notices the Pokecenter, and seems to be marginally better at distinguishing NPCs.
Did I mention that all of this is with an overlay that prominently labels impassable areas with red squares, passable areas in cyan, and NPCs in maroon? Without this overlay it is obvious these models have no idea what can and cannot be walked on.
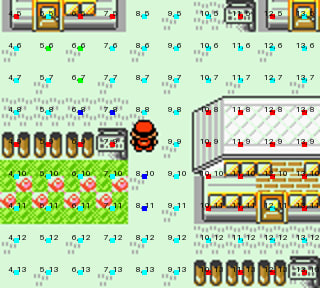
This is perhaps the biggest dirty secret of these runs: these models need an overlay to function vaguely competently at navigating the overworld. Without it, considerable time is spent trying to walk through walls and invisible paths, etc.
And you would think that a prominent red square on an object would dissuade a model from trying to walk right through it. You would think.
Bad vision is almost certainly what killed the currently ongoing ClaudePlaysPokemon run stone-dead. It's not the only problem, but progress requires cutting a tree with CUT, and Claude cannot distinguish the cuttable tree from regular trees.[5]

I have not tested if Gemini can distinguish this tree (and intend to eventually). This may very well be the only reason Gemini has progressed further.
Of interest: o3 is the only model I've ever seen identify the staircase in the opening room and go straight for it. On one of several tries, but it did happen!
(Lest anyone think this means o3 has solved vision problems, this same run then went on to get stuck for a short while leaving the front door of the house, then get stuck for a long while trying to pick up the pokeball containing a starter; more on this later.)
(There is a question of interest here though: why does pixel art work so well on humans despite literally nothing in real life being pixel art?)[6]
Models Can't Remember
It is well-known that LLMs have no built-in memory, and essentially have to rely on text in their context window. This presents obvious problems for playing a stateful game.
It may surprise you to learn, then, that I don't think this is actually that bad a problem. Or at least not as serious as the other problems on this list. Though, of course, this is reliant on scaffolding.
The standard trick of keeping a conversation history, summarizing it occasionally when it gets too full, and perhaps keeping some auxiliary memory on the side mitigates most of the issues I see in this regard. Models are limited in their ability to keep track of all that context window, of course, but o3 in particular seems pretty good at this (perhaps even too good; again, more on this later).
This doesn't mean memory is not a problem. The problems are just more subtle than one might imagine. For instance, the lack of direct memory means models lack a real sense of time, or how hard a task is. That means even when given a notepad to record observations, they will not consistently record "HOW TO SOLVE THAT PUZZLE THAT TOOK FOREVER" because they don't realize it took forever. And of course if it's not written down it falls completely out of "long-term" memory.
I don't have much direct experience with this, as my own scaffold has not implemented the elaborate memory systems of the Twitch streams yet, but casual observation of those streams should convince you that effective contextual memory retrieval using pure LLM is not easy. Perhaps RAG...?
Spatial Reasoning? What's that?
I won't go into this too much, but even with clearly marked grid labels, detailed instructions on how coordinate systems work, and explanations of the basics of navigation, all 3 LLMs are hopeless at navigation tasks more complicated then "walk there in a straight line". The navigation tool in ClaudePlaysPokemon (which allows pointing at a tile on screen and just "going there") is concealing a lot of this.
Along a similar vein, my attempt to add the ability for models to jot down a notepad containing an ASCII map of the area is, in my opinion, a total loss and probably hurts more than helps (though many of my testing runs did have this feature). The maps generated are often nonsense, have inconsistent coordinates, and point the wrong way.
A Grasp on Reality
Gallons of ink could be spilled on the hallucinations, strange reasoning, and nonsense that all these models spout while making bad decisions in Pokemon, but in my view a lot of it comes from a poor grasp on "reality". That is, an inability to distinguish Probably/Definitely True from Unlikely/Impossible.[7]
That is a hard problem in reasoning that doesn't get enough attention, nor is it easy to solve! But here are some pertinent observations I hope will convince you of this:
- One key part of the scaffolding that is more important than one would casually think is the text tag that tells the model where it is (be it Pallet Town, Viridian City, etc.). Without this, models left on their own will quite freely hallucinate a location and run with it. Even with this text tag, I find quite an amount of "The location tag is clearly in error, because..." reasoning going on. Only stern warnings that the location is read directly from RAM and must be trusted absolutely suppress this behavior. This tag may be the only thing that keeps the model from randomly speculating that it must have teleported 4 cities over (and I have seen this).
- Both Gemini and o3 will believe clear mistakes printed in their conversation history or map despite direct visual evidence in contradiction. For instance, after making a mistake about the coordinates of the starting pokeballs (getting it off by a few indices), o3 held onto this mistake for HUNDREDS of actions, wandering a narrow section of Professor Oak's lab, despite the pokeballs blatantly not being there. Here is where o3's superior ability to remember its context hurts more than helps—it remembers this mistake, and gets stuck in it.
- This inability to reassess its past mistakes in the face of clear contradictory evidence is perhaps the only thing holding o3 back from being the clearly best model. I once saw it wander the starting bedroom for hundreds of actions, convinced the bed was a staircase. It may well be that despite superior overall abilities, this would cause o3 to get stuck in a dead loop in the average game of Pokemon much earlier.
A Pokemon center, according to o3, for 800 actions and like $100.
- Extra prompting is not sufficient to fix these issues with o3.
- You'll notice I didn't mention Claude 3.7. It does this too, but is noticeably better at occasionally going "Wait! My previous assertions are obvious nonsense." This may well be its strongest advantage.
- This inability to reassess its past mistakes in the face of clear contradictory evidence is perhaps the only thing holding o3 back from being the clearly best model. I once saw it wander the starting bedroom for hundreds of actions, convinced the bed was a staircase. It may well be that despite superior overall abilities, this would cause o3 to get stuck in a dead loop in the average game of Pokemon much earlier.
- All 3 models will occasionally manifest assumptions in clear contradiction of Pokemon Red knowledge that they definitely have. For instance, all 3 models know that Professor Oak has to be encountered in the grass north of Pallet Town at the start of the game, but all of them will often spot the bespectacled aide in the front of the lab, say "AH! PROFESSOR OAK!", and then proceed to spend hundreds of actions wandering the area trying to make it work, despite talking to the aide more than once, and this being in CLEAR CONTRAVENANCE of their own knowledge of the game.
- They are clearly incapable of considering their internal knowledge of Pokemon Red as "more credible" than random text in their context.
Costs
Obviously this cost a decent sum of money, though not ridiculously so. It's about $30 or so per 2000 steps, which for comparison is typically enough for the average model to pick a starter and get to the next city to pick up Oak's parcel, or enough to make a decent go at getting through Viridian forest. This is also a few hours of time.
I... wouldn't consider this cheap, which is part of why I've spent a lot of time experimenting on what helps models progress rather than just setting it to run.
Why do this at all?
As for why I bothered to do this at all: General interest, partially, though I've come to realize it is a good way to gain familiarity interacting with these models. In addition, I was honestly getting a bit frustrated seeing the likes of ClaudePlaysPokemon get terminally stuck and wanted to see if there were relatively "non-cheaty" ways to get a model going. If I end up finding a scaffold I feel comfortable will make good progress I may let it run for a bit. In particular I want to see notorious navigation tasks like Mt. Moon.
So which model is better?
Well, "better" can mean many things, and is scaffold-dependent.
First, some underlying commentary.
My scaffold is substantively identical between the three different models, one of the original reasons for doing this, but there are technical differences that are essentially necessary to give each model a "fair" shake, in terms of giving data formatted how each model prefers it.
More precisely:
- CLAUDE: As originally provided in the underlying repo, when navigation or emulation tools are called, the tool_result contains text describing the game state, as well as a screenshot of the current game. The text is delivered as some number of (about 7) individual objects. I assume that Anthropic of all people would know the right way to prompt Claude and indeed this seems to work well.
- GEMINI: Substantively the same as above, but the text is concatenated into one long text string, before providing the screenshot (with some minor rewording to accommodate this). This is what Google has in all their examples and indeed it seems to be necessary for the model to consistently "see" the image.
- O3: Does not respond well to information being provided only in the tool result, and doesn't consistently read the output. The game text and screenshot was moved to a follow-up "user" prompt to get it to perform.
In addition, all that extra inference is taxing on tokens, and thus context summary happens noticeably more frequently.
My overall goal, besides comparing multiple models, may be characterized as trying to "coach" a model through the game as far as possible with relatively "fair" scaffolding. By fair, I mean workarounds for issues the model clearly is not built for (long-term memory, good vision, etc.) while still leaving it to reason and make decisions mostly on its own.
Anyway, the comparison: Claude 3.7 has certain advantages, but cripplingly bad vision means I wouldn't put it above Gemini 2.5—and yet I'm not convinced Gemini 2.5 is meaningfully better in "same-scaffold" tests, or if it is that it's more than for a very flukish reason (being able to see a tree Claude can't) that ultimately isn't very important.
As for o3: It's had some of the most impressive gameplay I've ever seen, beelining straight for the staircase in the opening room, correctly remembering the opening sequence of Pokemon Red and getting to pick a starter essentially as fast as possible. But then it gets stuck in a bad hallucination loop where it simply refuses to disbelieve its own previous assertions, and I'm not confident that it wouldn't get stuck in an elaborate loop forever.*
*barring something brute force like full context wipes every 1000 steps or something if it hasn't left a location.
Miscellanea: ClaudePlaysPokemon Derp Anecdotes
For those who are not familiar with the deep lore, here is a small supercut of navigation/reasoning failures that may inspire some thought:
- Getting stuck in the opening bedroom because it can't see the stairs down
- Getting stuck in Viridian forest maze for over a day
- Getting stuck going through Mt. Moon for 69 hours (the first time, this is foreshadowing) because, among other things, it believed there was a path to Vermilion City that didn't go through Mt. Moon and spent long hours looking for it in a blank rock wall.
- Just navigating Cerulean City is a challenge because of the city's... unique design.
- Marking the Trashed House as "explored" despite never exploring the back half and therefore failing to find the exit to the Underground path for days.
- Confusing another NPC for Misty, and after not talking to Misty believing that it was missing some critical step to get a gym badge.
- Asserting that Cerulean City Gym is the "Trashed House" and that the game's RAM must be mistaken
- Literal days of failing to find the SS Anne
- ...augmented by an inability to walk down into the SS Anne because it was instructed to walk "up the gangplank" and wrote down that it needs to try pressing up when near the SS Anne
- Repeatedly leaving the SS Anne after talking to various NPCs and becoming convinced that what they were talking about was critical for progression
- Convincing himself that a (several) random NPCs in the SS Anne were the captain and trying to talk to them for hours at a time, hoping to find the secret way to make them hand off HM01 Cut.
- Currently, ClaudePlaysPokemon is an eternal death loop of trying to traverse Mt. Moon, getting stuck, using Diglett to dig back to the start, repeat. This has happened >100 times.
And Bonus:
o3: Getting convinced that the pokeballs in Oak's lab are located 2 tiles to the left of where they actually were and spending hundreds of actions talking to Gary, Oak, and picking up Charmander (which it didn't want), instead of just LOOKING AT THE SCREEN.

- ^
This is not the full scaffold used in the ClaudePlaysPokemon stream.
- ^
This is the tool that allows Claude to pick a coordinate on screen and walk to it.
- ^
Used by both ClaudePlaysPokemon and GeminiPlaysPokemon.
- ^
When I suggested they open source their code:
> maybe, I suffer from "my god this code is ugly" shyness right now
> also I'm pretty sure I just have my api keys sitting in there out of laziness - ^
Claude has managed to cut trees on this run, but it's much more difficult when there's many trees around. The tree to access the Thunder Badge is fairly isolated.
- ^
I'm curious if LLMs would do better on later-gen games. However, they don't have as robust emulation tools as far as I know.
- ^
To put it another way, they're bad at updating their priors? It doesn't feel quite right to say they're bad at Bayesian reasoning, but maybe that really is the problem?
1 comments
Comments sorted by top scores.
comment by Mo Putera (Mo Nastri) · 2025-04-21T08:27:29.601Z · LW(p) · GW(p)
This, in the end, was what motivated me to reintroduce "Critique Claude"/"Guide Gemini"/"Oversight o3".[3] That is, a secondary model call that occurs on context summary whose job it is to provide hints if the model seems stuck, and which is given a system prompt specifically for this purpose. It can be told to look for telltale signs of common fail-states and attempt to address then, and can even be given "meta" prompting about how to direct the other model.
Funnily enough this reminded me of pair programming.