Ultimate ends may be easily hidable behind convergent subgoals
post by TsviBT · 2023-04-02T14:51:23.245Z · LW · GW · 4 commentsContents
What can you tell about an agent's ultimate intent by its behavior? Terms Inferring supergoals through subgoals Messiness in relations between goals Factors obscuring supergoals Fungibility Terms Examples Effects on goal structure Canonicity Effects on goal structure Instrumental convergence Fungibility spirals Existence Effects on goal structure The inspection paradox for subgoals Hidden ultimate ends Are convergent instrumental goals near-universal for possibilizing? Non-adaptive goal hiding Adaptive goal hiding None 4 comments
[Metadata: crossposted from https://tsvibt.blogspot.com/2022/12/ultimate-ends-may-be-easily-hidable.html. First completed December 18, 2022.]
Thought and action in pursuit of convergent instrumental subgoals do not automatically reveal why those subgoals are being pursued--towards what supergoals--because many other agents with different supergoals would also pursue those subgoals, maybe with overlapping thought and action. In particular, an agent's ultimate ends don't have to be revealed by its pursuit of convergent subgoals. It might might therefore be easy to covertly pursue some ultimate goal by mostly pursuing generally useful subgoals of other supergoals. By the inspection paradox for the convergence of subgoals, it might be easy to think and act almost comprehensively like a non-threatening agent would think and act, while going most of the way towards achieving some other more ambitious goal.
Note: the summary above is the basic idea. The rest of the essay analyzes the idea in a lot of detail. The final main section might be the most interesting.
What can you tell about an agent's ultimate intent by its behavior?
An agent's ultimate intent is what the agent would do if it had unlimited ability to influence the world. What can we tell about an agent's ultimate intent by watching the external actions it takes, whether low-level (e.g. muscle movements) or higher-level (e.g. going to the store), and by watching its thinking (e.g. which numbers it's multiplying, which questions it's asking, which web searches it's running, which concepts are active)?
Terms
- The cosmos is everything, including the observable world, logical facts, observers and agents themselves, and possibilities.
- A goal-state is a state of the cosmos that an agent could try to bring about. (A state is equivalent to a set of states; more formally, the cosmos is a locale of possibilities and a goal-state is an open subspace.)
- An instantiation of a cosmos-state is a substate. E.g. [I have this particular piece of gold] is an instantiation of [I have a piece of gold in general].
- A goal is a property of an agent of the form: this agent is trying to bring about goal-state . Overloading the notation, we also say the agent has the goal , and we can imprecisely let the term also stand for whatever mental elements constitute the goal and its relations to the rest of the agent.
- A pursuit of is behavior, a set of actions, selected to achieve . Since an agent having a goal is basically the same as the agent pursuing , we also say e.g. "the farmer has the goal [grow crops]", which really means, "the farmer selects actions that ze expects will bring about zer goal state [have crops], and so ze behaves in a way that's well-described as [growing crops]".
- A strategy (for ) is a pursuit (of ) that involves an arrangement of goals (perhaps in sequence or in multiple parallel lines, perhaps with branching on contingencies).
- If an agent is following a strategy for , then for each goal in the strategy, is a subgoal of the agent's goal of , and is a supergoal of . We can also loosely say that some goal is a subgoal of if helps achieve , whether or not there's an agent pursuing using , meaning vaguely something like "there's a strategy sufficient to achieve that uses as a necessary part" or "many agents will do reasonably well in pursuing if they use ".
- An intermediate goal is a goal that motivates the pursuit of subgoals, and itself is motivated by the pursuit of one or more supergoals.
- The motivator set of a goal is the set of goals such that is plausibly a supergoal of .
- The (sufficient) strategy set of a goal is the set of strategies that are sufficient to achieve .
Inferring supergoals through subgoals
Suppose that is an intermediate goal for some agent. By observing more fully the constellation of action and thought the agent does in pursuit of the goal , we become more confident that the agent is pursuing . That is, observing the agent pursuing subgoals that constitute much of a sufficient strategy for is evidence that the agent has the goal . If we observe that the farmer turns the earth, broadcasts the seed, removes the weeds, sprays for pests, and fences out wild animals, we become more and more sure that ze is trying to grow crops.
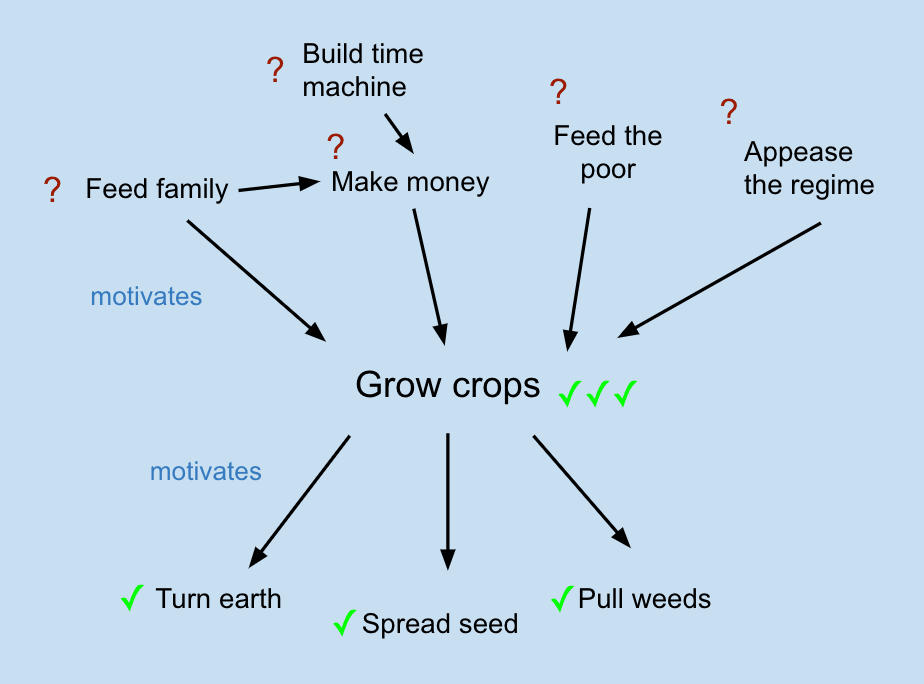
But, we don't necessarily know what ze intends to do with the crops, e.g. eat them or sell them. Information doesn't necessarily flow from subgoals up through the fact that the farmer is trying to grow crops, to indicate supergoals; the possible supergoals may be screened off from the observed subgoals. In that case, we're uncertain which of the supergoals in the motivator set of [grow crops] is the one held by the farmer.
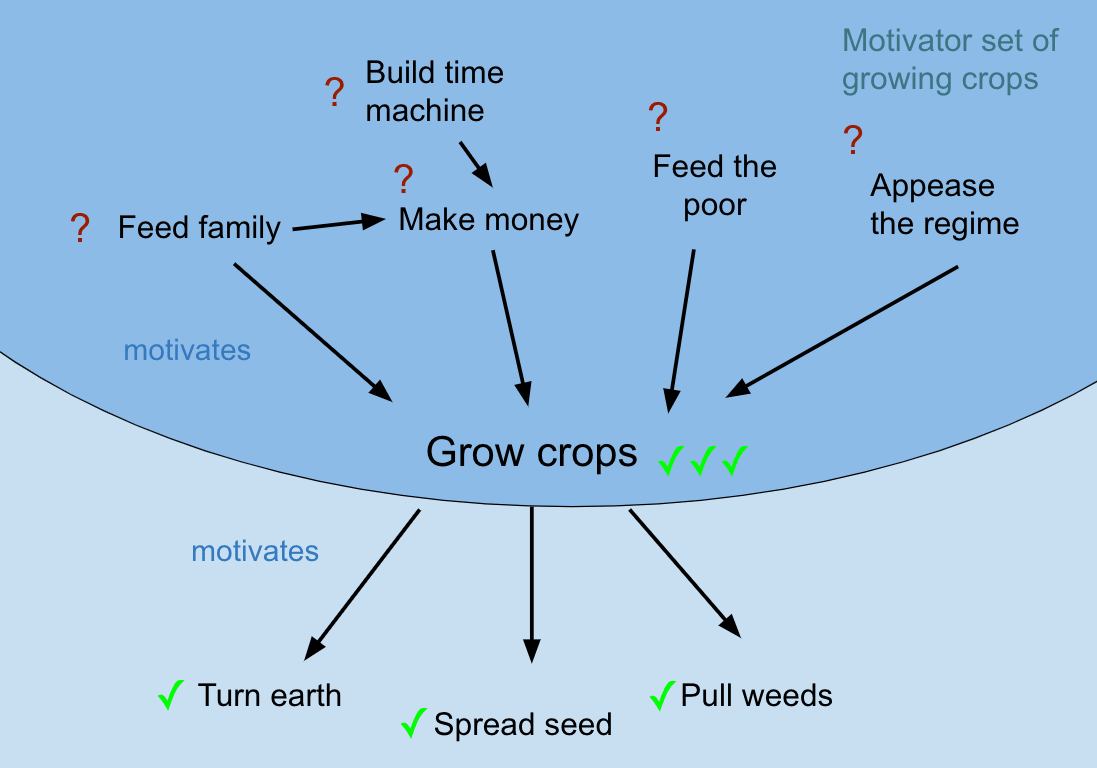
Suppose an agent is behaving in a way that looks to us like it's pursuing some instantiation of a goal-state . (We always abstract somewhat from to , e.g. we don't say "the farmer has a goal of growing rhubarb with exactly the lengths [14.32 inches, 15.11 inches, 15.03 inches, ...] in Maine in 2022 using a green tractor while singing sea shanties", even if that's what is.) Some ways to infer the supergoals of the agent by observing its pursuit of :
- General utility of . The fact that is being pursued is evidence for goals that can be achieved well with strategies that have the goal in them, and weak evidence against other goals. In other words, having the goal is evidence of having at least one of the supergoals in the motivator set of .
- General disutility of . The fact that is being pursued is evidence against goals that are interfered with by the goal-state . For example, the farmer's behavior is inconsistent with the farmer having a goal of not feeding a loathsome regime that will come and take any crops ze has grown, because the farmer's behavior will cause there to be seizable crops.
- Specific instantiation of . The specific strategy being used towards indicates the specific instantiation of being pursued. Compared to other instantiations of , may be more or less useful for different possible supergoals of . That is, the strategy set of might break up into subsets of strategies, where each subset is the strategy set for a more specific goal-state , such that the motivator sets of some of the are distinct from each other. E.g., in the following diagram, different strategies (light red boxes) serve different subset goal-states of [grow crops], possibly to different ends:
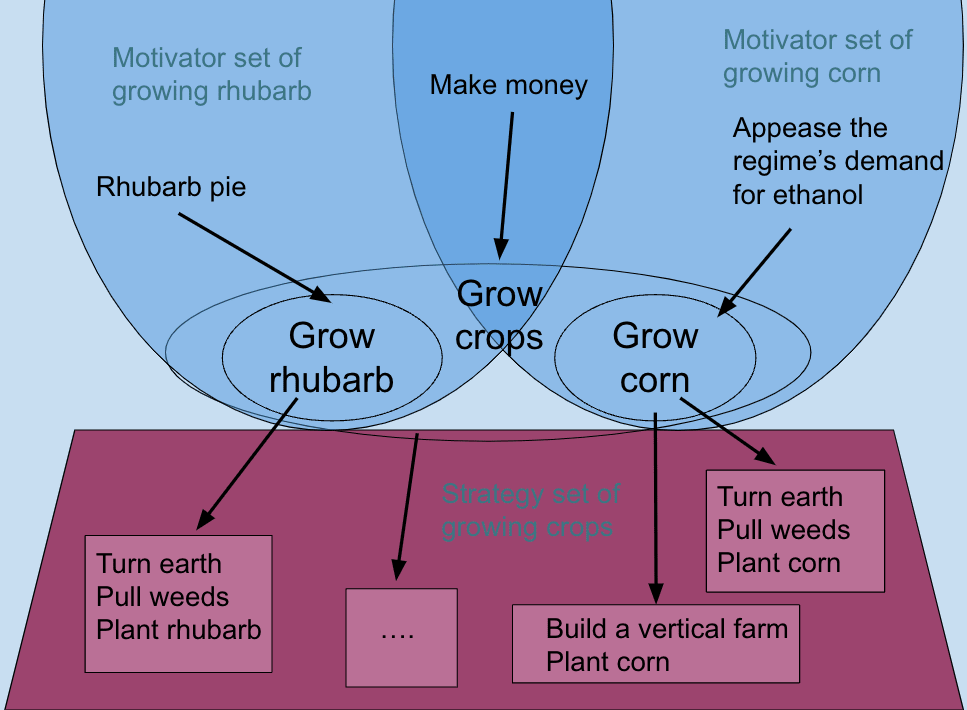
- Subgoal utility and disutility. Like , the subgoals might themselves be part of strategies for other goals, or interfere with other goals.
- Agent properties. The strategy might reveal something about how the agent is thinking, which might be correlated with supergoals. For example, its strategy might show that it knows how to start with big-picture considerations and unfold that into concrete actions, which might be correlated with having more ambitious goals. Another example: there may be distinct cognitive realms that are identifiable from action and are concomitant with values; e.g., the inside of a politicker's head might be fundamentally different from the inside of an engineer's head. (This is not really a coherent category, but rather more like a placeholder for other ways to infer what an agent's effects on the world will be based on the agent's past behavior. I suspect that introspection and self-modifiability greatly decrease the influence of agent properties, e.g. allowing one to be "the perfect politician".)
These points leave out how to infer goals from observed behavior, except through observed pursuit of subgoals. This essay takes for granted that some goals can be inferred from [behavior other than subgoal pursuit], e.g. by observing the result of the behavior, by predicting the result of the behavior through simulation, by analogy with other similar behavior, or by gemini modeling the goal.
Messiness in relations between goals
-
Except for the concept of strategy as an arrangement of goals, the above discussion takes goals in isolation, as if the environment and the agent's skills, resources, language of thought, and other plans are irrelevant to the supergoal-subgoal relation. Really agents somehow apply all their mental elements to generate and choose between overall plans for the whole of their behavior, not individual subgoals, or strategies for subgoals, executed without preconditions or overlap with other strategies.
-
The subgoal-supergoal vocabulary may be too restrictive, by assuming that agents have goals--that is, that agents pursue goal-states. To be more general, we would assume as little as possible about how an agent controls the cosmos, and leave open that there are agents occupying cognitive realms where there aren't really goals with subgoal-supergoal relations.
-
It is not the case that goal-/cosmos-states have any a priori central hierarchy of implication, time-space containment, or causality; that is, states we naturally call goals don't have to factor neatly in those ways.
-
It is also not the case that goals (as agent properties, or their concomitant mental elements) neatly form an acyclic supergoal-subgoal hierarchy, whether by the relations of motivation, delegation, other mental causation or control, or inclusion of sets of pursuant behaviors.
-
For example, the goal [obtain energy] is related to the goal [mine coal] both as a supergoal (mine coal to get energy) and also as a subgoal (expend energy to move rocks blocking the way to the coal).
-
As another example, it would be awkward to try to carve boundaries around all the actions taken in service of the goal [grow crops] and its subgoals. Such a boundary would have to be quite uncomfortably intertwined with the boundary drawn around the actions taken in service of the goal [drive crops to the market] and its subgoals, because both goals share the subgoal [pump petroleum from the ground]: which steps taken towards the oil field were in service of [grow crops], and which in service of [drive crops]? If we say, every step is 9/10 in service of [grow crops] and 1/10 in service of [drive crops], then have we given up on drawing subgoal-boundaries around behaviors or world-states? Or, if we exclude from the behavior representing the goal [grow crops] all of the behavior merely in service of the subgoals of [grow crops], then wouldn't we go on excluding subgoal behaviors until there are no behaviors left to constitute the pursuit of the goal [grow crops] itself? Or is there a specialized mental action that exactly sets in motion and orchestrates the pursuit of [growing crops], without getting its hands dirty with any subgoals?
-
Factors obscuring supergoals
Fungibility
Note: the two following subsections, Terms and Examples, aren't really needed to read what comes after; their purpose is to clarify the idea of fungibility. Maybe read the third subsection, "Effects on goal structure", and then backtrack if you want more on fungibility.
Terms
- "Fungible" means "exchangeable" or "replaceable".
- A set of cosmos-states (e.g., a goal-state ) is very state-fungible if it's easy to convert its states into each other. That is, given almost any states , it's easy to go from to . If it's usually difficult or costly to go between states in , then is very not state-fungible. (Note that state-fungibility is relative to how finely the states partition .)
- A set of cosmos-states is very use-fungible if its states can serve the same roles in the same strategies. That is, given almost any states and almost any strategy that uses , that strategy works about as well, without further changes, if is replaced by in the strategy. If replacing by usually makes a big difference, then is very not use-fungible. (This could be parametrized by the set of strategies.)
- A set of cosmos-states is very effectively-use-fungible if it's "not too hard" to deal with losing and gaining . That is, given almost any states and almost any strategy that uses (as a part of some agent's pursuit of some supergoal), there's another strategy such that:
- is allowed to use ,
- does not use ,
- is comparably difficult and costly to , and
- achieves the supergoal about as well as .
- In what follows, fungible without a qualifying prefix means effectively-use-fungible.
If is use-fungible, then it is effectively-use-fungible: the strategy using already probably works with instead, by use-fungibility.
If is state-fungible, then it is effectively-use-fungible: given a working strategy using , there's a strategy that, given , first easily produces from , which is doable by state-fungibility, and then follows .
Examples
- The set {broomstick, rhubarb, a preimage of "boop-ee-doop-snoop" under SHA-256} is very not fungible, in any sense. You can't get a broomstick given rhubarb, you can't use rhubarb as a drop-in replacement for a hash preimage, and being able to achieve some goal given a broomstick doesn't mean you could also achieve that goal given a hash preimage. Less sillily, varieties of clothes aren't very fungible, even though "clothes" is a natural category: you don't want to wear a shirt that's for someone a foot and a half taller than you, in a style you hate, that's rudely out of code to wear to a wedding; and, it's not particularly easy to trade that shirt for something appropriate to your use.
- Pieces of gold are use-fungible but not state-fungible. Two pieces of gold (assuming they're both big enough and sufficiently pure) can do the same jobs; but that doesn't mean it's easy to get the piece of gold lodged in some lonely river a thousand miles away, just because you're holding another similar piece of gold. On the other hand, [gold in general] is state-fungible. That is, the singleton set of states {[I have gold]} is trivially state-fungible. Since gold is use-fungible, this view is unproblematic. But for states that are not use-fungible enough, it is confusing to view them as singleton states, as that seems to imply that they are trivially state-fungible and therefore effectively-use-fungible, which may not be the case.
- For example, varieties of energy are not very use-fungible: to get yourself up the hill, you need mechanical energy, and zapping yourself with electricity won't help (well, if it's really a lot of electricity, some of you might get up the hill...). To power your body, you need chemical energy, and climbing into a washing machine won't help, even though the washing machine will put a lot of mechanical energy into you. Putting your electronic devices in a bowl of melted butter won't charge them. And so on. Energy is fairly state-fungible: your body converts chemical into mechanical energy, a steam turbine connected to a generator converts thermal energy into mechanical and then electrical energy, and so on. On the other hand, it would take some doing to charge your phone given a bowl of melted butter. Since [I have energy, in general] is not totally use-fungible, it would be misleading to construe the goal of having energy on the level of the singleton {[I have energy, in general]}; doing so would elide the need to convert between varieties of energy / work.
- With some additional work, it's possible to make energy more state-fungible, by creating a machine that converts one variety of energy to another. E.g. given a bowl of butter, one can invent a hand-crankable electrical power generator, and then eat the butter and crank the crank and use the power to charge one's phone.
- Consider varieties of wood. Relative to the goals and strategies of a neophyte carpenter, wood is pretty much use-fungible: there's no use in worrying between different varieties of pine, if you're just trying out permutations of simple boards or shelves to learn to cut straight and measure right. But of course different varieties of wood aren't state-fungible, e.g. having a pine board doesn't make it much easier to get a maple board.
- Relative to the goals and strategies of a master carpenter, varieties of wood are less use-fungible than for the neophyte, since ze'd have much more specific criteria. However, ze'd be better at making due with a different variety of wood, adapting the tools and methods and plans and aesthetics to fit. In this way, for a master, wood is somewhat more (effectively-use-)fungible than is implied by how state-fungible and use-fungible it is: the master can't convert maple to cherry or achieve zer goals by blindly substituting maple for cherry, but ze can achieve similar goals in different ways with different strategies given different states.
- Varieties of money are not very use-fungible: try electroplating electronic connectors with dollar bills, try paying at the grocery store using call options, try paying a taxi in Brazil with shekels, try paying rent with WhateverCoin, try buying a bunch of illegal drugs using your personal bank account. Money is fairly, though not extremely, state-fungible.
- Computing power is fairly fungible.
Effects on goal structure
- The more that is state-fungible, the more the sufficient strategy sets for instantiations are unioned together, until at the extreme, they're all roughly just the whole strategy set for all of . For example, since currency is fairly state-fungible, one can do reasonably well at obtaining fiat currency by first obtaining WhateverCoin and then selling the WhateverCoin, and vice versa.
- In particular, compared to if were less fungible, a given substate of has a larger sufficient strategy set.
- The more that is (effectively-use-)fungible, the more the motivator sets for instantiations are unioned together. That is, [which specific instantiation of the agent is pursuing] matters less for the agent's pursuit of its supergoal/s for , because the agent can use most specific instantiations of about as well within some larger strategy. At the extreme, any supergoal of any is also a supergoal of any other .
- Combining the two above facts, the more that is fungible, the less evidence of the agent's supergoal/s of is provided by the agent's specific pursuit of through the channel of the specific instantiation of targeted by that pursuit. The agent might actually be pursuing by first pursuing and then converting from to , and the agent might be pursuing a natural supergoal of by using some other strategy (different from the natural way to get from ) to get using .
- In contrast, when substates of are not very fungible, we may be able to infer an agent's supergoals through the channel of the specific instantiation of . If someone goes to a currency exchange after arriving in a foreign country to pick up a few hundred dollars worth of local currency, they're not doing a null operation. The local currency is more convenient for small local purchases, and we can infer that they're probably planning to make that sort of purchase. If someone buys gold to store in their house, they're maybe hedging against the collapse of fiat currency.
- Regardless of fungibility, the agent's specific pursuit of might provide evidence about the agent's supergoals through subgoal utility and through revealed agent properties.
- To some extent, fungibility of controls whether the idea of as a goal even carves reality at its joints. For some agents, "energy" is so far from being fungible that it's not even a central concept; a medieval farmer wouldn't need to think in terms of [obtain energy] but rather [obtain food for myself], [obtain food for the ox], [have an ox to plow the field], [be near a river to turn the watermill], [clear the trees to let the sun hit the garden], [obtain wood to burn in the stove]. He can't use the ox to heat his home, and he can't use the sun to grind his wheat. "Work" (the Germanic cognate of Greek "energy") is a reasonable concept though; the ox could also work the mill or pull the cart to market. A common example is "power" or "status", which are both real but are far less fungible between varieties and contexts than they might intuitively seem.
Canonicity
In "The unreasonable effectiveness of mathematics in the natural sciences", Wigner discusses the empirical phenomenon that theories in physics are expressed using ideas that were formed by playing around with ideas and selected such that they are apt for demonstrating a sense of formal beauty and ingenious skill at manipulating ideas.
Some of this empirical phenomenon could be explained by abstract mathematical concepts being canonical. That is, there's in some sense only one form, or very few forms, that this concept can take. Then, when a concept is discovered once by mathematicians, it is discovered in roughly the same form as will be useful later in another context. Compare Thingness.
Canonicity is not the same thing as simplicity. Quoting Wigner:
It is not true, however, as is so often stated, that this had to happen because mathematics uses the simplest possible concepts and these were bound to occur in any formalism. As we saw before, the concepts of mathematics are not chosen for their conceptual simplicity - even sequences of pairs of numbers are far from being the simplest concepts - but for their amenability to clever manipulations and to striking, brilliant arguments. Let us not forget that the Hilbert space of quantum mechanics is the complex Hilbert space, with a Hermitean scalar product. Surely to the unpreoccupied mind, complex numbers are far from natural or simple and they cannot be suggested by physical observations. Furthermore, the use of complex numbers is in this case not a calculational trick of applied mathematics but comes close to being a necessity in the formulation of the laws of quantum mechanics.
However, it might be that canonicity is something like, maximal simplicity within the constraint of the task at hand. Quoting Einstein:
It can scarcely be denied that the supreme goal of all theory is to make the irreducible basic elements as simple and as few as possible without having to surrender the adequate representation of a single datum of experience.
The mathematician seeks contexts where the simplest concepts adequate to the tasks of the context are themselves interesting. Repeatedly seeking in that way builds up a library of canonical concepts, which are applied in new contexts.
Extreme canonicity is far from necessary. It does not always hold, even in abstract mathematics (and might not ever hold). For example, quoting:
Our colleague Peter Gates has called category theory “a primordial ooze”, because so much of it can be defined in terms of other parts of it. There is nowhere to rightly call the beginning, because that beginning can be defined in terms of something else.
The same concept might be redescribed in a number of different ways; there's no single canonical definition.
Canonicity could be viewed as a sort of extreme of fungibility, as if there were only one piece of gold in the cosmos, so that having a piece of gold is trivially fungible with all ways of having a piece of gold. All ways of comprehending a concept are close to fungible, since any definition can be used to reconstruct other ways of understanding or using the concept. (This is far from trivial in individual humans, but I think it holds fairly well among larger communities.)
Compare also Christopher Alexander's notion of a pattern and a pattern language.
Effects on goal structure
- Canonicity of a goal , like fungibility, screens off information flowing from observing an agent's pursuit of , through the specific instantiation of it's pursuing, to its supergoals for . Since there's only one instantiation of , information can't flow that way.
- Canonicity correlates with larger motivator sets. Since there's only one thing for the motivation to land on, a larger spread of motivators land on the same thing.
Instrumental convergence
A convergent instrumental goal is a goal that would be pursued by many different agents in service of many different supergoals or ultimate ends. See Arbital "Instrumental convergence" and a list of examples of plausible convergent instrumental strategies.
Or, as a redefinition: a convergent instrumental goal is a goal with a large motivator set. ("Large" means, vaguely, "high measure", e.g. many goals held by agents that are common throughout the multiverse according to some measure.) Taking this definition literally, a goal-state might be "instrumentally convergent" by just being a really large set. For example, if is [do anything involving the number 3, or involving electricity, or involving the logical AND operation, or involving a digital code, or involving physical matter], then a huge range of goals have some instantiation of as a subgoal. This is silly. Really what we mean is to include some notion of naturality, so that different instantiations of are legitimately comparable. Fungibility is some aspect of natural, well-formed goals: any instantiation of should be about as useful for supergoals as any other instantiation of .
Canonicity might be well-described as a combination of two properties: well-formedness (fungibility, Thingness), and instrumental convergence.
Fungibility spirals
A goal-state is enfungible if agents can feasibly make more fungible.
Suppose is somewhat convergent and somewhat enfungible, even if it's not otherwise very fungible / natural. Then agents with goals in the motivator set of will put instrumental value on making more fungible. That is, such agents would find it useful (if not maximally useful) to enfunge , to make it more possible to use different instantiations of towards more supergoals, because for example it might be that is best suited to an agent's supergoals, but is easiest to obtain.
If is enfunged, that increases the pool of agents who might want to further enfunge . For example, suppose agents have goals , and suppose that the aren't currently fungible, and that is easier to obtain than when . First works to make fungible into . Once that happens, now both and want to make fungible into . And so on.
In this way, there could be a fungibility spiral, where agents (which might be "the same" agent at different times or branches of possibility) have instrumental motivation to make very fungible. An example is the history of humans working with energy. By now we have the technology to efficiently store, transport, apply, and convert between many varieties of energy (which actions are each an implementation of fungibility). As another example, consider the work done to do computational tasks using different computing hardware.
Existence
Evidence for the existence of convergent instrumental goals:
- See this list on Arbital of plausible convergent instrumental strategies.
- The unreasonable effectiveness of mathematics is a class of examples of convergence: concepts invented to make ideas more easily manipulated in an apparently non-empirically-grounded context also are useful in more empirically grounded contexts. (Further, it's evidence for the Thingness of convergentness: mathematicians can recognize when a concept is elegant or beautiful, and that sense of beauty predicts whether that concept will show up or be useful in apparently unrelated contexts.)
- Historical fungibility spirals around energy, computing power, and money are examples. Though, it's debatable how strong is the evidence provided, since e.g. money emerging as separate debt/exchange mechanisms partially unified by partial fungibility might be somewhat human-specific--another sort of agent might possibly have invented money-in-general de novo.
- Rene Girard's theory of many aspects of society being generated by coping with destructive acquisitive mimesis points at convergence as a strong force (although this is even more strongly restricted to human or human-group goals, so again provides limited evidence).
Effects on goal structure
- Since instrumental convergence is correlated with fungibility and canonicity, it is correlated with their effects on goal structure (and causes those effects, in the case of enfungible goals).
- By definition, instrumentally convergent goals have a large motivator set. That implies that the general utilities of don't narrow down the agent's supergoals too much: after finding out just the fact that the agent is pursuing , we still don't know which of the many motivators of is the agent's actual supergoal.
- Altogether, a convergent instrumental goal-state tends to leave three significant flows of information from an agent's specific pursuit of to the agent's supergoals: the disutility of to possible supergoals, the supergoal utilities and disutilities of subgoals that are part of the agent's pursuit, and the agent properties revealed by the agent's specific pursuit.
The inspection paradox for subgoals
The Friendship paradox: "most people have fewer friends than their friends have, on average". Relatedly, the inspection paradox:
Imagine that the buses in Poissonville arrive independently at random (a Poisson process) with, on average, one bus every six minutes. Imagine that passengers turn up at bus-stops at a uniform rate, and are scooped up by the bus without delay, so the interval between two buses remains constant. Buses that follow gaps bigger than six minutes become overcrowded. The passengers' representative complains that two-thirds of all passengers found themselves on overcrowded buses. The bus operator claim, "no, no--only one third of our buses are overcrowded." Can both these claims be true?
Analogously:
An agent's subgoals tend to be especially instrumentally convergent.
Very instrumentally convergent goals are held by more agents than non-convergent goals, so, just like a passenger who's usually subjected to an overcrowded bus, an agent holding some subgoal is usually holding an overcrowded subgoal. In particular:
Different agents tend to have many overlapping convergently instrumental goals.
Hidden ultimate ends
[I got tired of writing this essay, so this section is less thoroughly thought out / expressed / distilled. It's probably the most important section though. Feel free to ask questions at my gmail address: tsvibtcontact]
Suppose we're observing a mind thinking and acting. What can we tell about its ultimate goals?
Are convergent instrumental goals near-universal for possibilizing?
Possibilizing is making things possible, in contrast to actually doing things. This might not be a principled distinction, since whatever is called possibilizing is surely also actualizing something, but still there's some intuitive spectrum. E.g. speed cubers first look at the Rubik's cube, then put it down, and then pick it up and turn its faces. Before they pick it up the second time, in their head they're possibilizing solving the cube by figuring out the sequence of moves. When they pick it up, they actualize solving the cube. An engineer designing a machine possibilizes the work the machine will do; building the machine is midway between possibilizing and actualizing the work; applying the machine actualizes the work. See possibilizing vs. actualizing.
Question:
To what extent are most goals mostly possibilizable using only highly convergent subgoals?
In other words: given some random supergoal , how close can you get to achieving --how little additional work can you leave undone--if you're only allowed to behave in ways that many agents would behave? I don't know. I suspect you can get pretty close. Some intuitions behind that suspicion:
- Most of possibilizing is in having the ideas, and ideas tend to be very convergently instrumental to have.
- Turing completeness.
- The unreasonable effectiveness of mathematics.
- Christopher Alexander argues that buildings are made mostly by applying compact pattern languages.
Non-adaptive goal hiding
Suppose the mind is not adapted in any way to stop us from understanding the mind's ultimate goals. Can we determine what the mind's ultimate goals are? Some obstacles:
- To the extent that possibilizing is most of the hard part of an agent's pursuit of its ultimate goals, most of its activity will be towards possibilizing. Possibilizing is mostly about having the needed ideas, which tend to be highly convergent.
- The mind's ultimate goals don't necessarily have to play much visible role in the mind's activity, while we're observing the mind.
- For example, minds with goals which are ambitious (call for touching a lot of the cosmos) and which are hard to irreversibly interfere with, will plausibly spend almost all of their thinking and action on an influence-maximizing phase [LW · GW], which consists entirely of pursuing highly convergent instrumental subgoals.
- It may be a (reflective) convergent goal to set up most instrumental cognition so that it is especially unlikely to interfere with supergoals in general, to make it easy to plan without constantly checking whether the planning is itself dangerous to supergoals and whether the plan that will be produced will avoid interfering with supergoals. Such modularized instrumental cognition would reveal its supergoals much less than a default that involves the supergoals constantly overseeing the subgoals. See: the tractability of instrumental goals.
- The activity we understand the best is the activity that's instrumental to what we care about. The activity that most identifies what the observed mind cares about as distinct from what we care about, is therefore selected to be activity we understand and recognize less well.
- If it's the case that novel understanding implies novel values, and if a mind is selected for having understanding that we don't have, then it is also selected for having values that are somehow bound up with understanding that we don't have. Values that are somehow bound up with understanding that we don't have seem like they'd be harder for us to recognize by looking at a mind's thinking and action. For example, if someone is obsessed with proving the Riemann Hypothesis, but we don't understand what complex numbers are and haven't met a human mathematician before, we'd be hard pressed to precisely interpret this person's thinking and behavior--we aren't familiar with this activity, and don't have the understanding to directly interpret or gemini model the activity.
Adaptive goal hiding
Suppose an agent adapts in some way so that it isn't visibly pursuing goals that an overseer wouldn't want it to pursue. The adaptation could be passive, e.g. we apply a training loss to thoughts or actions that score highly on some detector of having certain goals, or it could be active, e.g. itself is searching out ways to arrange itself so that we don't interfere with its goals.
- The more a goal is fungible, the larger is its sufficient strategy set. So there is more room for to search for strategies that will be acceptable to the overseer.
- The more a goal is convergent, the more difficult it is for the overseer to infer an agent's supergoals from the fact that the agent pursues the goal.
- The more a goal is convergent, the more likely it is that there will be an agent that also pursues that goal and is acceptable to the overseer.
- By the inspection paradox for subgoals, there will be "a lot" of overlap between the subgoals that the agent wants to pursue, and the subgoals that would be pursued by agents that are acceptable to the overseer.
- The descriptive property of locally seeming to pursue some goal might come apart from the global property of having that goal as an effect. Goal pursuit does have a local-global connection, where globally pursuing some goal also by default looks like locally pursuing subgoals in service of that goal. But descriptive goals are different from determinative specifications of goals, so intervening on a local descriptive goal might not intervene on what really specifies the mind's goals.
- If there's pressure for an agent to adapt (whether passively or actively) to avoid punishment for appearing to pursue some goal, it might change its goals or it might find another way to pursue the same goal. There are often nearby unblocked strategies for achieving the same goal. If there are nearby unblocked strategies, the agent can follow those strategies in pursuit of the same goal.
- This adaptation could go on until the agent's pursuits are incomprehensible to an overseer. If the overseer allows pursuits that the overseer doesn't understand, then the agent is still just pursuing its original goals; if the overseer disallows those pursuits, the agent is less capable overall until some other way to achieve the same instrumental effects is allowed. (This poses a risk of playing a shell game with the novel understanding that gives the agent its worthwhileness.)
- Subgoal laundering. To the extent that the strategy stealing assumption holds, the agent can, at least in isolation, achieve any subgoal that is pursued by an agent that would be approved by the overseer. The agent steals the instrumental strategy that follows to achieve . Since is approved by the overseer, the utilities and disutilities of and of the subgoals in the strategy of are acceptable to the overseer. Since the agent properties revealed by are acceptable to the overseer, on a strong interpretation of the strategy-stealing assumption, can also display acceptable properties.
- To the extent that is fungible, can make use of 's strategy; whatever instantiation of is thereby achieved, will also work for 's purposes.
- To the extent that convergent goals are universal for possibilizing, can follow an entire strategy that mostly only uses convergent instrumental goals. Those goals are likely to be held by some agents that are acceptable to the overseer.
- If there's pressure for an agent to maintain its goals, rather than change its goals, and there's room for it to not change its goals, then it won't change its goals unless there's even more pressure to change its goals. For example, an agent with big-picture strategic awareness would actively try to prevent changes. Even without that property, the forces affecting the agent's goals may be strong and may not change much; e.g. an agent strongly selected to perform well at some suite of tasks has strong demands placed on it, which might translate to strong forces determining its structure, which might determine its goals.
4 comments
Comments sorted by top scores.
comment by Roman Leventov · 2023-04-04T01:58:17.230Z · LW(p) · GW(p)
In popular perception, this is how China is acting in international relations: it mostly pursues instrumental convergent goals like increasing its influence, accumulating resources, etc., while just holding its strategic goals "in the background", without explicitly "rushing" to achieve them right now.
This reminds me of Sun Tzu's saying, “If you wait by the river long enough, the bodies of your enemies will float by.”
Does such a strategy count as misalignment? If the beliefs held by the agent are compatible[1] with the overseer's beliefs, I don't think so. Agent's understanding of the world could be deeper and therefore its cognitive horizon and the "light cone" of agency and concern (see Levin, 2022; Witkowski et al., 2023) farther or deeper than those of the overseer.
Then, the superintelligent agent could evolve its beliefs to the point that is no longer compatible with the "original" beliefs of the overseer, or even their existence. In the latter case, or if the agent fails to convince the overseers in (a simplified version of) their new beliefs, that would constitute misalignment, of course. But here we go out of scope of what is considered in the post and my comment above.
- ^
By "compatible", I mean either coinciding or reducible with minimal problems, like general relativity could be reduced to Newtonian mechanics in certain regimes with negligible numerical divergence.
↑ comment by TsviBT · 2023-04-09T13:41:18.290Z · LW(p) · GW(p)
Thanks, that's a great example!
Does such a strategy count as misalignment?
Yeah, I don't think it necessarily counts as misalignment. In fact, corrigibility probably looks behaviorally a lot like this: gathering ability to affect the world, without making irreversible decisions, and waiting for the overseer to direct how to cash out into ultimate effects. But the hidability means that "ultimate intents" or "deep intents" are conceptually murky, and therefore not obvious how to read off an agent--if you can discern them through behavior, what can you discern them through?
Replies from: Roman Leventov↑ comment by Roman Leventov · 2023-04-09T20:06:17.194Z · LW(p) · GW(p)
Only if we know the entire learning trajectory of AI (including the training data) and high-resolution interpretability mapping along the way. If we don't have this, or if AI learns online and is not inspected with mech.interp tools during this process, we don't have any ways of knowing of any "deep beliefs" that AI may have, if it doesn't reveal them in its behavior or "thoughts" (explicit representations during inferences)
comment by gpt4_summaries · 2023-04-03T08:24:54.214Z · LW(p) · GW(p)
Tentative GPT4's summary. This is part of an experiment.
Up/Downvote "Overall" if the summary is useful/harmful.
Up/Downvote "Agreement" if the summary is correct/wrong.
If so, please let me know why you think this is harmful.
(OpenAI doesn't use customers' data anymore for training, and this API account previously opted out of data retention)
TLDR: This article explores the challenges of inferring agent supergoals due to convergent instrumental subgoals and fungibility. It examines goal properties such as canonicity and instrumental convergence and discusses adaptive goal hiding tactics within AI agents.
Arguments:
- Convergent instrumental subgoals often obscure an agent's ultimate ends, making it difficult to infer supergoals.
- Agents may covertly pursue ultimate goals by focusing on generally useful subgoals.
- Goal properties like fungibility, canonicity, and instrumental convergence impact AI alignment.
- The inspection paradox and adaptive goal hiding (e.g., possibilizing vs. actualizing) further complicate the inference of agent supergoals.
Takeaways:
- Inferring agent supergoals is challenging due to convergent subgoals, fungibility, and goal hiding mechanisms.
- A better understanding of goal properties and their interactions with AI alignment is valuable for AI safety research.
Strengths:
- The article provides a detailed analysis of goal-state structures, their intricacies, and their implications on AI alignment.
- It offers concrete examples and illustrations, enhancing understanding of the concepts discussed.
Weaknesses:
- The article's content is dense and may require prior knowledge of AI alignment and related concepts for full comprehension.
- It does not provide explicit suggestions on how these insights on goal-state structures and fungibility could be practically applied for AI safety.
Interactions:
- The content of this article may interact with other AI safety concepts such as value alignment, robustness, transparency, and interpretability in AI systems.
- Insights on goal properties could inform other AI safety research domains.
Factual mistakes:
- The summary does not appear to contain any factual mistakes or hallucinations.
Missing arguments:
- The potential impacts of AI agents pursuing goals not in alignment with human values were not extensively covered.
- The article could have explored in more detail how AI agents might adapt their goals to hide them from oversight without changing their core objectives.