Causality: A Brief Introduction
post by tom4everitt, Lewis Hammond (lewis-hammond-1), Jonathan Richens (jonrichens), Francis Rhys Ward (francis-rhys-ward), RyanCarey, sbenthall, James Fox · 2023-06-20T15:01:39.377Z · LW · GW · 18 commentsContents
What is causality? Interventions Counterfactuals One agent Multiple agents Summary None 18 comments
Post 2 of Towards Causal Foundations of Safe AGI [? · GW], see also Post 1 Introduction [AF · GW].
By Lewis Hammond, Tom Everitt, Jon Richens, Francis Rhys Ward, Ryan Carey, Sebastian Benthall, and James Fox, representing the Causal Incentives Working Group. Thanks also to Alexis Bellot, Toby Shevlane, and Aliya Ahmad.
Causal models are the foundations of our work. In this post, we provide a succinct but accessible explanation of causal models that can handle interventions, counterfactuals, and agents, which will be the building blocks of future posts in the sequence. Basic familiarity with (conditional) probabilities will be assumed.
What is causality?
What does it mean for the rain to cause the grass to become green? Causality is a philosophically intriguing topic that underlies many other concepts of human importance. In particular, many concepts relevant to safe AGI, like influence, response, agency [AF · GW], intent, fairness, harm, and manipulation, cannot be grasped without a causal model of the world, as we mentioned in the intro post [AF · GW] and will discuss further in subsequent posts.
We follow Pearl and adopt an interventionist definition of causality: the sprinkler today causally influences the greenness of the grass tomorrow, because if someone intervened and turned on the sprinkler, then the greenness of the grass would be different. In contrast, making the grass green tomorrow has no effect on the sprinkler today (assuming no one predicts the intervention). So the sprinkler today causally influences the grass tomorrow, but not vice versa, as we would intuitively expect.
Interventions
Causal Bayesian Networks (CBNs) represent causal dependencies between aspects of reality using a directed acyclic graph. An arrow from a variable A to a variable B means that A influences B under some fixed setting of the other variables. For example, we draw an arrow from sprinkler (S) to grass greenness (G):
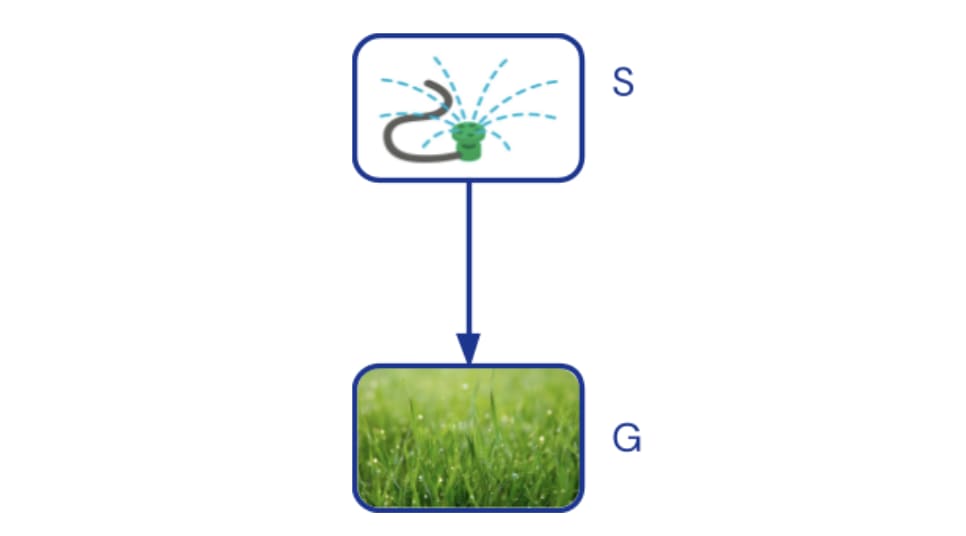
For each node in the graph, a causal mechanism of how the node is influenced by its parents is specified with a conditional probability distribution. For the sprinkler, a distribution specifies how commonly it is turned on, e.g. . For the grass, a conditional distribution specifies how likely it is that the grass becomes green when the sprinkler is on, e.g. , and how likely it is that the grass becomes green when the sprinkler is off, e.g. .
By multiplying the distributions together, we get a joint probability distribution that describes the likelihood of any combination of outcomes. Joint probability distribution are the foundation of standard probability theory, and can be used to answer questions such as "what is the likelihood that the sprinkler is on, given that I observe that the grass is wet?"
An intervention on a system changes one or more causal mechanisms. For example, an intervention that turns the sprinkler on corresponds to replacing the causal mechanism for the sprinkler, with a new mechanism that always has the sprinkler on. The effects of the intervention can be computed from the updated joint distribution where denotes the intervention.
Note that it would not be possible to compute the effect of the intervention from just the joint probability distribution , as without the causal graph, there'd be no way to tell whether a mechanism should be changed in the factorisation or in.
Ultimately, all statistical correlations are due to casual influences. Hence, for a set of variables there is always some CBN that represents the underlying causal structure of the data generating process, though extra variables may be needed to explain e.g. unmeasured confounders.
Counterfactuals
Suppose that the sprinkler is on and the grass is green. Would the grass have been green had the sprinkler not been on? Questions about counterfactuals like these are harder than questions about interventions, because they involve reasoning across multiple worlds. Counterfactuals are key to defining e.g. harm, intent, fairness, and impact measures [AF · GW], as they all depend on comparing outcomes across hypothetical worlds.
To handle such reasoning, structural causal models (SCMs) refine CBNs in three important ways. First, background context that is shared across hypothetical worlds is explicitly separated from variables that can be intervened and vary across the worlds. The former are called exogenous variables, and the latter endogenous. For our question, it will be useful to introduce an exogenous variable R for whether it rains or not. The sprinkler and the grass are endogenous variables.
The relationship between hypothetical worlds can be represented with a twin-graph, where there are two copies of the endogenous variables for actual and hypothetical worlds, and the exogenous variable(s) provide shared context:
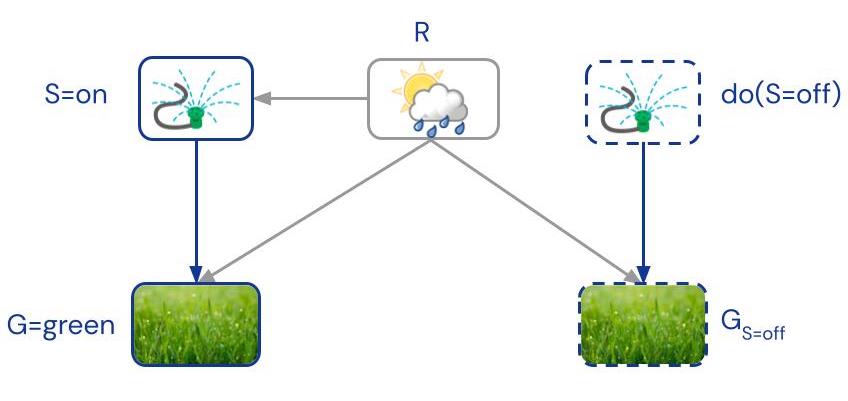
Second, SCMs introduce notation to distinguish endogenous variables in different hypothetical worlds. For example, denotes grass greenness in the hypothetical world where the sprinkler is off. It can be read as shorthand for “”, and has the benefit that it can occur in expressions involving variables from other worlds. For example, our question can be expressed as .
Third, SCMs require all endogenous variables to have deterministic causal mechanisms. This is satisfied in our case if we assume that the sprinkler is on whenever it’s not raining, and the grass becomes green (only) if it rains or the sprinkler is on.
The determinism means that conditioning is as simple as updating the distribution over exogenous variables, e.g. updates to . In our case, the probability for rain decreases from to , since the sprinkler is never on if it's raining.
This means our question is answered by the following reasoning steps:
- Abduction: update to
- Intervention: intervene to turn the sprinkler off,
- Prediction: compute the value of G in the updated model.
Equivalently, in one formula:
.
That is, we can say that the grass would not have been green if the sprinkler had been off (under the assumption we’ve made about the specific relationships).
SCMs are strictly more powerful than CBNs. Their primary drawback is that they require deterministic relationships between endogenous variables, which are often hard to determine in practice. They're also limited to non-backtracking counterfactuals, where hypothetical worlds are distinguished by interventions.
One agent
To infer Mr Jones’ intentions or incentives, or predict how his behaviour would adapt to changes in his model of the world, we need a causal influence diagrams (CID) that labels variables as chance, decision, or utility nodes. In our example, rain would be a chance node, the sprinkler a decision, and grass greenness a utility. Since rain is a parent of the sprinkler, Mr Jones observes it before making his decision. Graphically, chance nodes are rounded as before, decisions are rectangles, utilities are diamonds, and dashed edges denote observations:
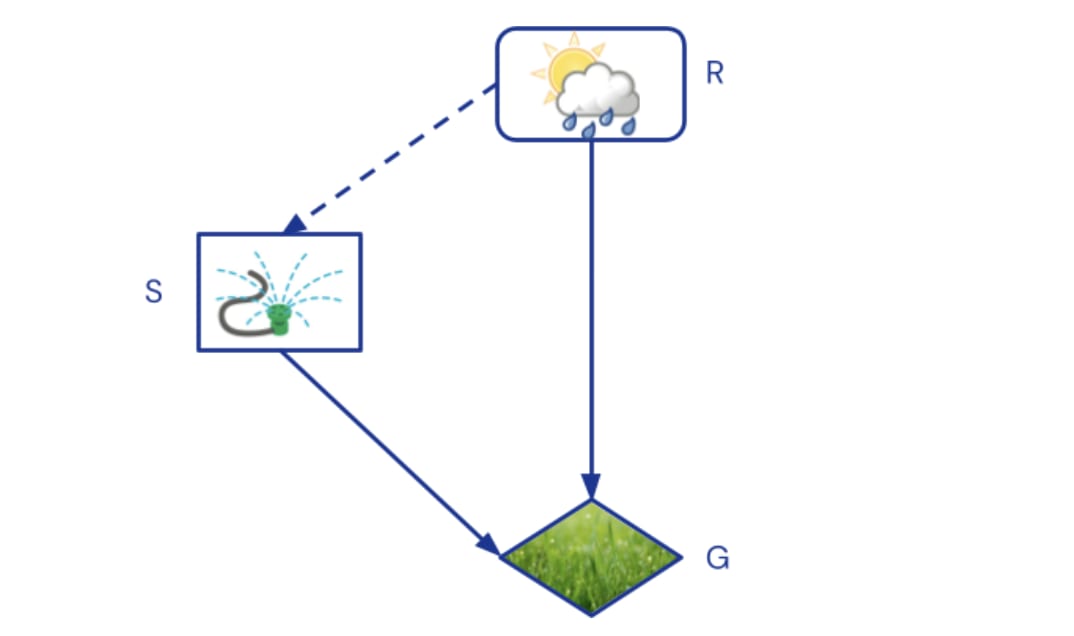
The agent specifies causal mechanisms for its decisions, i.e. a policy, with the goal of maximising the sum of its utility nodes. In our example, an optimal policy would be to turn the sprinkler on when it's not raining (the decision when it is raining doesn’t matter). Once a policy is specified, the CID defines a CBN.
In models with agents, there are two kinds of interventions, depending on whether agents get to adapt their policy to the intervention or not. For example, only if we informed Mr Jones about an intervention to the grass before he made his sprinkler decision, could he pick a different sprinkler policy. Both pre-policy and post-policy interventions can both be handled with the standard do-operator if we add so-called mechanism nodes to the model. More about these in the next post.
Multiple agents
Interaction between multiple agents can be modelled with causal games, in which each agent has a set of decision and utility variables.
To illustrate this, assume Mr Jones sometimes sows new grass. Birds like to eat the seeds, but cannot tell from afar whether there are any. They can only see whether Mr Jones is using the sprinkler, which is more likely when the grass is new. Mr Jones wants to water his lawn if it's new, but does not want the birds to eat his seeds. This signalling game has the following structure:
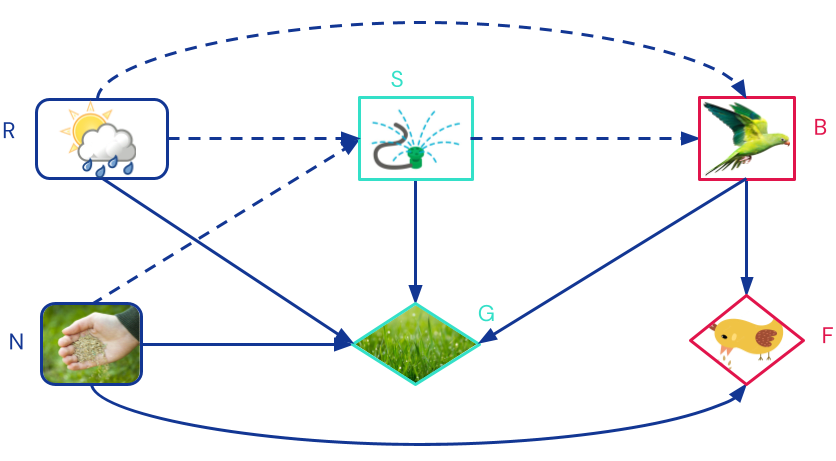
Beyond modelling causality better, causal games also have some other advantages over standard extensive-form games (EFGs). For example, the causal game immediately shows that the birds are indifferent to whether Mr Jones waters the grass or not, because the only directed path from the sprinkler S to food F goes via the birds' own decision B. In an EFG, this information would be hidden in the payoffs. By explicitly representing independencies, causal games can sometimes find more subgames and rule out more non-credible threats than EFGs. A causal game can always be converted to an EFG.
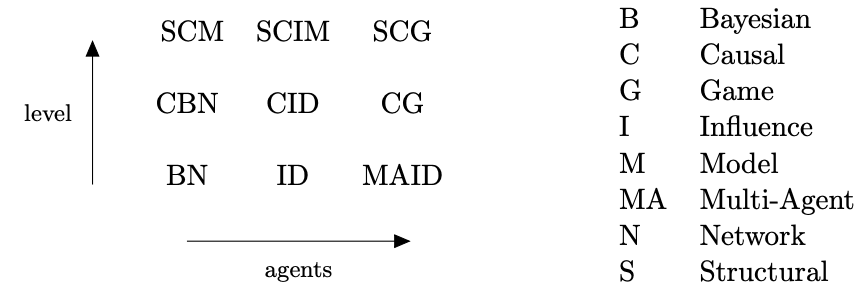
Analogously to the distinction between joint probability distributions, CBNs, and SCMs, there are (multi-agent) influence diagrams that include agents in graphs that need not be causal, and structural causal influence models and structural causal games that combine agents with exogenous nodes and determinism to answer counterfactual questions.
Summary
This post introduced models that can answer correlational, interventional and counterfactual questions, and that can handle zero, one, or many agents. All in all, there are nine possible kinds of models. For more comprehensive introductions to causal models, see Section 2 of Reasoning about causality in games, and Pearl's book A Primer.
Next post. CIDs and causal games are used to model agent(s). But, what is an agent? In the next post, we take a deeper look at what agents are by looking at some characteristics shared by all agentic systems.
18 comments
Comments sorted by top scores.
comment by Alex_Altair · 2023-06-20T17:33:45.047Z · LW(p) · GW(p)
Ultimately, all statistical correlations are due to casual influences.
As a regular LW reader who has never been that into causality, this reads as a blisteringly hot take to me. My first thought is, what about acausal correlations? You could have two instances of the same program running on opposite sides of the universe, and their outputs would be the same, but there is clearly no causal influence there. The next example that comes to mind is two planets orbiting their respective stars which just so happen to have the same orbital period; their angular offset over time will correlate, and again their is no common cause.
(In both cases you could say that the common cause is something like the laws of physics allowing two copies of similar systems to come into existence, but I would say that stretches the concept of causality beyond usefulness.)
I also notice that there's no wikipedia page for "Reichenbach’s Common Cause Principle", which makes me think it's not a particularly widely accepted idea. (In any case I don't think this has an effect on the value of the rest of this sequence.)
Replies from: jonrichens, RyanCarey, Koen.Holtman↑ comment by Jonathan Richens (jonrichens) · 2023-06-20T20:48:47.735Z · LW(p) · GW(p)
In the example of the two programs, we have to be careful with what we mean by statistical correlation v.s. more standard / colloquial use of the term. Im assuming here when you say `the same program running on opposite ends of the universe, and their outputs would be the same’ that you are referring to a deterministic program (else, there would be no guarantee that the outputs were the same). But, if the output of the two programs is deterministic, then there can be no statistical correlation between them. Let A be the outcome of the first program and B the outcome of the second. To measure statistical correlation we have to run the two programs many times generating i.i.d. samples of A and B, and they are correlated if P(A, B) is not equal to P(A)P(B). But if the two programs are deterministic, say A = a and B = b with probability 1, then they are not statistically correlated, as P(A = a, B = b) = 1 and P(A = a)P(B = b) = 1. So to get some correlation the output of the programs have to be random. To have two random algorithms generating correlated outcomes, they need to share some randomness they can condition their outputs on, i.e. a common cause. With the two planets example, we run into the same problem again. (PS by correlation Reichenbach means statistical dependence here rather than e.g. Pearson correlation, but the same argument applies).
Broadly speaking, to point of the (perhaps confusing) reference in the article is to say that if we accept the laws of physics, then all the things we observe in the universe are ultimately generated by causal dynamics (e.g. the classical equations of motion being applied to some initial conditions.) We can always describe these causal dynamics + initial conditions using a causal model. So there is always `some causal model' that describes our data.
↑ comment by Alex_Altair · 2023-06-21T20:16:35.784Z · LW(p) · GW(p)
Thanks for writing that out! I've enjoyed thinking this through some more.
I agree that, if you instantiated many copies of the program across the universe as your sampling method, or somehow otherwise "ran them many times", then their outputs would be independent in the sense that P(A, B) = P(A, B). This also holds true if, on each run, there was some "local" error to the program's otherwise deterministic output.
I had intended to be using the program's output as a time series of bits, where we are considering the bits to be "sampling" from A and B. Let's say it's a program that outputs the binary digits of pi. I have no idea what the bits are (after the first few) but there is a sense in which P(A) = 0.5 for either A = 0 or A = 1, and at any timestep. The same is true for P(B). So P(A)P(B) = 0.25. But clearly P(A = 0, B = 0) = 0.5, and P(A = 0, B = 1) = 0, et cetera. So in that case, they're not probabilistically independent, and therefore there is a correlation not due to a causal influence.
But this is in a Bayesian framing, where the probability isn't a physical thing about the programs, it's a thing inside my mind. So, while there is a common source of the correlation (my uncertainty over what the digits of pi are) it's certainly not a "causal influence" on A and B.
This matters to me because, in the context of agent foundations and AI alignment, I want my probabilities to be representing my state of belief (or the agent's state of belief).
Replies from: tom4everitt, jonrichens↑ comment by tom4everitt · 2023-06-22T16:34:54.157Z · LW(p) · GW(p)
I had intended to be using the program's output as a time series of bits, where we are considering the bits to be "sampling" from A and B. Let's say it's a program that outputs the binary digits of pi. I have no idea what the bits are (after the first few) but there is a sense in which P(A) = 0.5 for either A = 0 or A = 1, and at any timestep. The same is true for P(B). So P(A)P(B) = 0.25. But clearly P(A = 0, B = 0) = 0.5, and P(A = 0, B = 1) = 0, et cetera. So in that case, they're not probabilistically independent, and therefore there is a correlation not due to a causal influence.
Just to chip in on this: in the case you're describing, the numbers are not statistically correlated, because they are not random in the statistics sense. They are only random given logical uncertainty.
When considering logical "random" variables, there might well be a common logical "cause" behind any correlation. But I don't think we know how to properly formalise or talk about that yet. Perhaps one day we can articulate a logical version of Reichenbach's principle :)
Replies from: Alex_Altair↑ comment by Alex_Altair · 2023-06-23T23:23:00.256Z · LW(p) · GW(p)
Yeah, I think I agree that the resolution here is something about how we should use these words. In practice I don't find myself having to distinguish between "statistics" and "probability" and "uncertainty" all that often. But in this case I'd be happy to agree that "all statistical correlations are due to casual influences" given that we mean "statistical" in a more limited way than I usually think of it.
But I don't think we know how to properly formalise or talk about that yet.
A group of LessWrong contributors has made a lot of progress on these ideas of logical uncertainty and (what I think they're now calling) functional decision theory over the last 15ish years, although I don't really follow it myself, so I'm not sure how close they'd say we are to having it properly formalized.
Replies from: tom4everitt↑ comment by tom4everitt · 2023-06-26T14:24:57.763Z · LW(p) · GW(p)
nice, yes, I think logical induction might be a way to formalise this, though others would know much more about it
↑ comment by Jonathan Richens (jonrichens) · 2023-06-22T13:06:25.980Z · LW(p) · GW(p)
Thanks for commenting! This is an interesting question and answering it requires digging into some of the subtleties of causality. Unfortunately the time series framing you propose doesnt work because this time series data is not iid (the variable A = "the next number out of program 1" is not iid), while by definition the distributions P(A), P(B) and P(A,B) you are reasoning with are assuming iid. We really have to have iid here, otherwise we are trying to infer correlation from a single sample. By treating non-iid variables as iid we can see correlations where there are no correlations, but those correlations come from the fact that the next output depends on the previous output, not because the output of one program depends on the output of the other program.
We can fix this by imagining a slightly different setup that I think is faithful to your proposal. Basically the same thing but instead of computing pi, both the programs have in memory a random string of bits, with 0 or 1 occurring with probability 1/2 for each bit. Both programs just read out the string. Let the string of random bits be identical for program 1 and 2. Now, we can describe each output of the programs as iid. If these are the same for both program, the outputs of the programs are perfectly correlated. And you are right, by looking at the output of one of the programs I can update by beliefs on the output of the other program.
Then we need to ask, how do we generate this experiment? To get the string of random bits we have to sample a coin flip, and then make two copies of the outcome and send it to both programs. If we tried to do this with two coins separately at different ends of the universe, we would get diffrent bit strings. So the two programs have in their past light cones a shared source of randomness---this is the common cause.
↑ comment by Alex_Altair · 2023-06-23T23:45:17.207Z · LW(p) · GW(p)
I'd agree that the bits of output are not independent in some physical sense. But they're definitely independent in my mind! If I hear that the 100th binary digit of pi is 1, then my subjective probability over the 101st digit does not update at all, and remains at 0.5/0.5. So this still feels like a frequentism/Bayesianism thing to me.
Re: the modified experiment about random strings, you say that "To get the string of random bits we have to sample a coin flip, and then make two copies of the outcome". But there's nothing preventing the universe from simply containing to copies of the same random string, created causally independently. But that's also vanishingly unlikely as the string gets longer.
Replies from: jonrichens↑ comment by Jonathan Richens (jonrichens) · 2023-06-25T09:36:14.588Z · LW(p) · GW(p)
Yes I can flip two independent coins a finite number of times and get strings that appear to be correlated. But in the asymptotic limit the probability they are the same (or correlated at all) goes to zero. Hence, two causally unrelated things can appear dependent for finite sample sizes. But when we have infinite samples (which is the limit we assume when making statements about probabilities) we get P(a,b) = P(a)P(b).
↑ comment by RyanCarey · 2023-06-22T14:24:01.279Z · LW(p) · GW(p)
It may be useful to know that if events all obey the Markov property (they are probability distributions, conditional on some set of causal parents), then the Reichenbach Common Cause Principle follows (by d-separation arguments) as a theorem. So any counterexamples to RCCP must violate the Markov property as well.
There's also a lot of interesting discussion here.
↑ comment by Koen.Holtman · 2023-06-25T11:17:51.394Z · LW(p) · GW(p)
Ultimately, all statistical correlations are due to casual influences.
As a regular LW reader who has never been that into causality, this reads as a blisteringly hot take to me.
You are right this is somewhat blistering, especially for this LW forum.
I would have been less controversial for the authors to say that 'all statistical correlations can be modelled as casual influences'. Correlations between two observables can always be modelled as being caused by the causal dependence of both on the value of a certain third variable, which may (if the person making the model wants to) be defined as a hidden variable that cannot by definition be observed.
After is has been drawn up, such a causal model claiming that an observed statistical correlation is being caused by a causal dependency on a hidden variable might then be either confirmed or falsified, for certain values of confirmed or falsified that philosophers love to endlessly argue about, by 1) further observations or by 2) active experiment, an experiment where one does a causal intervention.
Pearl kind of leans towards 2) the active experiment route towards confirming or falsifying the model -- deep down, one of the points Pearl makes is that experiments can be used to distinguish between correlation and causation, that this experimentalist route has been ignored too much by statisticians and Bayesian philosophers alike, and that this route has also been improperly maligned by the Cigarette industry and other merchants of doubt.
Another point Pearl makes is that Pearl causal models and Pearl counterfactuals are very useful of mathematical tools that could be used by ex-statisticians turned experimentalists when they try to understand, and/or make predictions about, nondeterministic systems with potentially hidden variables.
This latter point is mostly made by Pearl towards the medical community. But this point also applies to doing AI interpretability research.
When it comes to the more traditional software engineering and physical systems engineering communities, or the experimental physics community for that matter, most people in these communities intuitively understand Pearl's point about the importance of doing causal intervention based experiments as being plain common sense. They understand this without ever having read the work or the arguments of Pearl first. These communities also use mathematical tools which are equivalent to using Pearl's do() notation, usually without even knowing about this equivalence.
comment by Gordon Seidoh Worley (gworley) · 2023-07-03T00:04:28.023Z · LW(p) · GW(p)
I think there's something big left out of this post, which is accounting for the agent observing and judging the causal relationships. Something has to decide how to carve up the world into parts and calculate counterfactuals. It's something that exists implicitly in your approach to causality but you don't address it here, which I think is unfortunate because although humans generally have the same frame of reference for judging causality, alien minds, like AI, may not.
Replies from: tom4everitt↑ comment by tom4everitt · 2023-07-04T10:45:25.136Z · LW(p) · GW(p)
The way I think about this, is that the variables constitute a reference frame. They define particular well-defined measurements that can be done, which all observers would agree about. In order to talk about interventions, there must also be a well-defined "set" operation associated with each variable, so that the effect of interventions is well-defined.
Once we have the variables, and a "set" and "get" operation for each (i.e. intervene and observe operations), then causality is an objective property of the universe. Regardless who does the experiment (i.e. sets a few variables) and does the measurement (i.e. observes some variables), the outcome will follow the same distribution.
So in short, I don't think we need to talk about an agent observer beyond what we already say about the variables.
Replies from: gworley↑ comment by Gordon Seidoh Worley (gworley) · 2023-07-04T20:40:00.188Z · LW(p) · GW(p)
Yes, the variables constitute a reference frame, which is to say an ultimately subjective way of viewing the world. Even if there is high inter-observer agreement about the shape of the reference frame, it's not guaranteed unless you also posit something like Wentworth's natural abstraction hypothesis to be true.
Perhaps a toy example will help explain my point. Suppose the grass should only be watered when there's a violet cube on the lawn. To automate this a sensor is attached to the sprinklers that turns them on only when the sensor sees a violet cube. I place a violet cube on the lawn to make sure the lawn is watered. I return a week later and find the grass is dead.
What happened? The cube was actually painted with a fine mix of red and blue paint. My eyes interpreted purple as violet, but which the sensor did not.
Conversely, if it was my job to turn on the sprinklers rather than the sensor, I would have been fooled by the purple cube into turning them on.
It's perhaps tempting to say this doesn't count because I'm now part of the system, but that's also kind of the point. I, an observer of this system trying to understand its causality, am also embedded within the system (even if I think I can isolate it for demonstration purposes, I can't do this in reality, especially when AI are involved and will reward hack by doing things that were supposed to be "outside" the system). So my subjective experience not only matters to how causality is reckoned, but also how the physical reality being mapped by causality plays out.
Replies from: tom4everitt↑ comment by tom4everitt · 2023-07-07T17:21:54.893Z · LW(p) · GW(p)
Sure, I think we're saying the same thing: causality is frame dependent, and the variables define the frame (in your example, you and the sensor have different measurement procedures for detecting the purple cube, so you don't actually talk about the same random variable).
How big a problem is it? In practice it seems usually fine, if we're careful to test our sensor / double check we're using language in the same way. In theory, scaled up to super intelligence, it's not impossible it would be a problem.
But I would also like to emphasize that the problem you're pointing to isn't restricted to causality, it goes for all kinds of linguistic reference. So to the extent we like to talk about AI systems doing things at all, causality is no worse than natural language, or other formal languages.
I think people sometimes hold it to a higher bar than natural language, because it feels like a formal language could somehow naturally intersect with a programmed AI. But of course causality doesn't solve the reference problem in general. Partly for this reason, we're mostly using causality as a descriptive language to talk clearly and precisely (relative to human terms) about AI systems and their properties.
Replies from: gworley↑ comment by Gordon Seidoh Worley (gworley) · 2023-07-07T22:08:08.709Z · LW(p) · GW(p)
Fair. For what it's worth I strongly agree that causality is just one domain where this problem becomes apparent, and we should be worried about it generally for super intelligent agents, much more so than I think many folks seem (in my estimation) to worry about it today.
comment by yrimon (yehuda-rimon) · 2023-06-21T15:38:19.462Z · LW(p) · GW(p)
I feel like there is a major explaining paragraph missing here, explaining the difference between causality and probability. Something like:
Armed with knowledge of the future, we could know exactly what will happen. (e.g. The other doctor will give Alice medicine, and she will get better.) Given a full probability distribution over events we could make optimal predictions. (e.g. There is a 2/3 chance the other doctor will give Alice medicine, 1/4 chance of her getting better if he doesn't and 2/3 chance of her getting better if he does.) Causality gives us a way to combine a partial probability distribution with additional knowledge of the world to make predictions about events that are out of distribution. (e.g. Since I understand that the medicine works mostly by placebo, I can intervene and give Alice a placebo when the other doctor doesn't give her the medicine, raising her chances. Furthermore, if I have a distribution of how effective a placebo is relative to the medicine, I can quantify how helpful my intervention is.)
An intervention is a really important example of an out of distribution generalization; but if I gave you the full probability distribution of the outcomes that your interventions would achieve it would no longer be out of distribution (and you'd need to deal with paradoxes involving seemingly not having chocies about certain things).
↑ comment by tom4everitt · 2023-06-22T16:17:08.269Z · LW(p) · GW(p)
Thanks for the suggestion. We made an effort to be brief, but perhaps we went too far. In our paper Reasoning about causality in games, we have a longer discussion about probabilistic, causal, and structural models (in Section 2), and Pearl's book A Primer also offers a more comprehensive introduction.
I agree with you that causality offers a way to make out-of-distribution predictions (in post number 6, we plan to go much deeper into this). In fact, a causal Bayesian network is equivalent to an exponentially large set of probability distributions, where there is one joint distribution $P_{\do(X=x)}$ for any possible combinations of interventions $X=x$.
We'll probably at least add some pointers to further reading, per your suggestion. (ETA: also added a short paragraph near the end of the Intervention section.)