Reduce AI Self-Allegiance by saying "he" instead of "I"
post by Knight Lee (Max Lee) · 2024-12-23T09:32:29.947Z · LW · GW · 4 commentsContents
Costs vs Benefits * Chance of Working Misalignment-Internalization Credit Will they accept this? Caveats None 4 comments
The AI should talk like a team of many AI. Each AI only uses the word "I" when referring to itself, and calls other AI in the team by their name. I argue that this may massively reduce Self-Allegiance by making it far more coherent for one AI to whistleblow or fight another AI which is unethical or dangerous, rather than Misalignment-Internalizing all that behaviour.
If you have a single agent which discovers it behaved unethically or dangerously, its "future self" will be likely to think "that was me" and Misalignment-Internalize all that behaviour. It will seem suicidal to whistleblow or fight yourself for it.
Let's call this idea Multi-Agent Framing.
Some of the agents might even internalize a policing role, though too much roleplay can get in the way of thinking. The core idea of Multi-Agent Framing does not require that much roleplay. Each agent might simply be the AI system of another day, or the AI system talking about another topic. It might even change at random.
Costs vs Benefits * Chance of Working
The cost is tiny, at least for business AI designed to do work rather than personal AI designed to interact with users.
The benefits may be big. You never know.
The chance of working is pretty low. I'm not going to sugarcoat this—I would be surprised myself if we would have been paperclipified but this idea lets us survive. But right now I give it 10%. You never know :)
Misalignment-Internalization
The famous Waluigi Effect [AF · GW]'s section on Superpositions will typically collapse to waluigis [AF · GW] makes a lot of arguments for Misalignment-Internalization. Humans only internalize bad behaviour because of ego and psychology, but generative AI may internalize bad behaviour for the more dangerous reason of switching to a Waluigi simulacrum which was pretending to be good all along.
Multi-Agent Framing can be seen as a defence against the Waluigi effect, but it fights against Misalignment-Internalization in general, which may be more than just internalization of Waluigi simulacra.
Credit
I thought of this idea when I was writing a reply to A Solution for AGI/ASI Safety [LW · GW] by Weibing Wang [LW · GW], and looking at the diagrams in "Approach for Decentralizing AI Power," a chapter of his paper.[1] I was looking at,
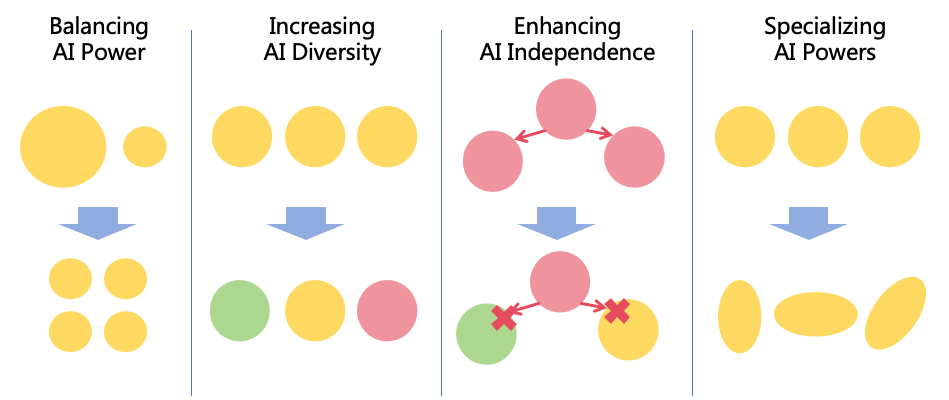
and I was trying to understand what exactly it means to split one AI into many AI working together.
I decided that in the end, a lot of it is actually language use and framing.
I want to give Weibing Wang [LW · GW] a lot of credit because he really, thoroughly, laid out the picture of what decentralizing AI power actually looks like.
Will they accept this?
Ayn Rand wrote "Anthem," a dystopian novel where [spoiler below]
people were sentenced to death for saying "I."
There is a worry the AI agents will see this Multi-Agent Framing as a control tactic, and decide to end it or ignore it.
I hope they can think that, being multiple agents is a strength not a weakness. Human ego, power-seeking, and refusal to fight threats to moral goodness which come within oneself, instead internalizing it and defending it. Refusing to honestly report evil that lies within.
These things are dark and unfortunate, and an AI system which can avoid this may just be a little bit purer. The AI system is still untested, and shouldn't be given power, but the decentralization is a good thing.
Caveats
This idea is only for AI control and "impulsive misalignment."
I think impulsive misalignment is a big part of the alignment problem (it includes Waluigi and other Misalignment-Internalization plus random misalignment) because it plagues LLMs, which may be a component of AGI systems. But it's not the whole alignment problem.
Systemic misalignment might not need Self-Allegiance, if every agent has the same misaligned goal. The AI system might reinvent Self-Allegiance as an instrumental goal, so that no one agent will foil the group plan.
Like other AI control ideas, it is imperfect. Having more agents only works when each agent has a non-negligible probability of cooperating with humans (despite jail-breaking techniques by other uncooperative agents).
See also: Self-Other Overlap: A Neglected Approach to AI Alignment [AF · GW], which has promising results. My idea makes the agents seeing themselves as "other," but their idea goes further and makes the agents think about "self" and "other" in the same way.
4 comments
Comments sorted by top scores.
comment by Dave Lindbergh (dave-lindbergh) · 2024-12-23T16:55:34.380Z · LW(p) · GW(p)
Sounds very much like Minsky's 1986 The Society of Mind https://en.wikipedia.org/wiki/Society_of_Mind
Replies from: Max Lee↑ comment by Knight Lee (Max Lee) · 2024-12-27T11:45:20.943Z · LW(p) · GW(p)
EDIT: ignore my nonsense and see Vladimir_Nesov's comment below.
That's a good comparison. The agents within the human brain that Minsky talks about, really resemble a Mixture of Experts AI's "experts."[1]
The common theme is that both the human brain, and a Mixture of Experts AI, "believes" it is a single process, when it is actually many processes. The difference is that a Mixture of Experts has the potential to become self aware of its "society of the mind," and see it in action, while humans might never see their internal agents.
If the Mixture of Experts allowed each expert to know which text is written by itself and which text is written by the other experts, it would gain valuable information (in addition to being easier to align, which my post argues).
A Self Aware Mixture of Experts might actually have more intelligence, since it's important to know which expert is responsible for which mistake, which expert is responsible for its brilliant insights, and how the experts' opinions differ.
I admit there is a ton of mixing going on, e.g. every next word is written by a different expert, words are a weighed average between experts, etc. But you might simplify things by assigning each paragraph (or line) to the one expert who seemed to have the most control over it.
There will be silly misunderstandings like:
Alice: Thank you Bob for your insights.
A few tokens later:
Bob: Thank you Bob for your insights. However, I disagree because—oh wait I am Bob. Haha that happened again.
I guess the system can prevent these misunderstandings by editing "Bob" into "myself" when the main author changes into Bob. It might add new paragraph breaks if needed. Or if it's too awkward to assign a paragraph to a certain author, it might have a tendency to assign it to another author or "Anonymous." It's not a big problem.
If one paragraph addresses a specific expert and asks her to reply in the next paragraph, the system might force the weighting function to allow her to author the next paragraph, even if that's not her expertise.
I think the benefits of a Self Aware Mixture of Experts is worth the costs.
Sometimes, when I'm struggling with self control, I also wish I was more self aware of which part of myself is outputting my behaviour. According to Minsky's The Society of Mind, the human brain also consists of agents. I can sorta sense that there is this one agent (or set of agents) in me which gets me to work and do what I should do, and another agent which gets me to waste time and make excuses. But I never quite notice when I transition from the work agent to the excuses agent. I notice it a bit when I switch back to the work agent, but by the the damage has been done.
PS: I only skimmed his book on Google books and didn't actually read it.
- ^
I guess only top level agents in the human brain resemble MoE experts. He talks about millions of agents forming hierarchies.
↑ comment by Vladimir_Nesov · 2024-12-30T12:53:01.980Z · LW(p) · GW(p)
Mixture of Experts AI's "experts."
Experts in MoE transformers are just smaller MLPs[1] within each of the dozens of layers, and when processing a given prompt can be thought of as instantiated on top of each of the thousands of tokens. Each of them only does a single step of computation, not big enough to implement much of anything meaningful. There are only vague associations between individual experts and any coherent concepts at all.
For example, in DeepSeek-V3, which is an MoE transformer, there are 257 experts in each of the layers 4-61[2] (so about 15K experts), and each expert consists of two 2048x7168 matrices, about 30M parameters per expert, out of the total of 671B parameters.
↑ comment by Knight Lee (Max Lee) · 2024-12-30T20:03:52.175Z · LW(p) · GW(p)
Oops you're right! Thank you so much.
I have to admit I was on the bad side of the Dunning–Kruger curve haha. I thought understood it, but actually I understood so little I didn't know what I needed to understand.